Organizations are grappling with the increasing complexity and diversity of their data sources. Traditional approaches often fall short in addressing the challenges posed by disparate data silos, and there arises a need for a more cohesive and integrated solution. Enter Data Fabric — a paradigm that promises a unified, scalable, and agile approach to managing the intricacies of modern data.
What is Data Fabric?

Data Fabric is a comprehensive data management approach that goes beyond traditional methods, offering a framework for seamless integration across diverse sources. It is not a standalone product but comprises key elements, including data integration, ensuring the smooth merging of data; data quality, maintaining high data standards; metadata management, organizing and understanding data context; and security, safeguarding data integrity. Together, these four elements form a cohesive fabric, unifying disparate data sources and providing organizations with a holistic and coherent perspective on their data landscape.
The 4 Key Pillars of Data Fabric

Data Integration: Breaking Down Silos
At the core of Data Fabric is the imperative need for seamless data integration. This element ensures the smooth merging of data from various sources, fostering a unified and comprehensive view. By dismantling data silos, organizations can promote collaboration and unlock valuable insights that were previously hidden in isolated pockets of information.
Data Quality: Building Trust in Information
Maintaining high standards for data quality such as accuracy, consistency, and reliability is paramount. By upholding data quality, organizations can trust the information they rely on for decision-making, fostering a data-driven culture built on dependable insights.
Metadata Management: Navigating the Data Landscape
Effective metadata management is the key to navigating the vast data landscape. This element involves organizing and understanding the context of data, enhancing discoverability and interpretability. With well-managed metadata, users can gain insights into the origin, structure, and relationships of integrated data, facilitating more informed decision-making.
Security: Safeguarding Data Integrity
Security is a non-negotiable aspect of the Data Fabric approach. It involves implementing robust measures to safeguard the integrity of data. By ensuring confidentiality and reliability through stringent security protocols, organizations can protect their data from unauthorized access, instilling trust in their data management practices.
How Striim Supports Data Fabric Implementation
While there are various ways to build a data fabric, the ideal solution simplifies the transition by complementing your existing technology stack. Striim serves as the foundation for a data fabric by connecting with legacy and modern solutions alike. Its flexible and scalable data integration backbone supports real-time data delivery via intelligent pipelines that span hybrid cloud and multi-cloud environments.

- Real-Time Data Integration
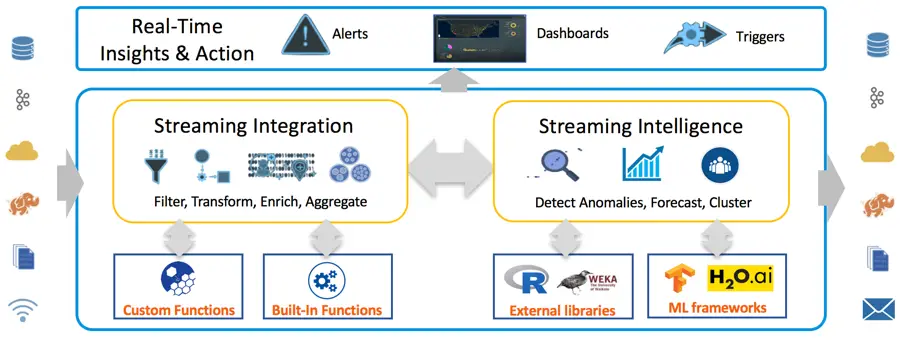
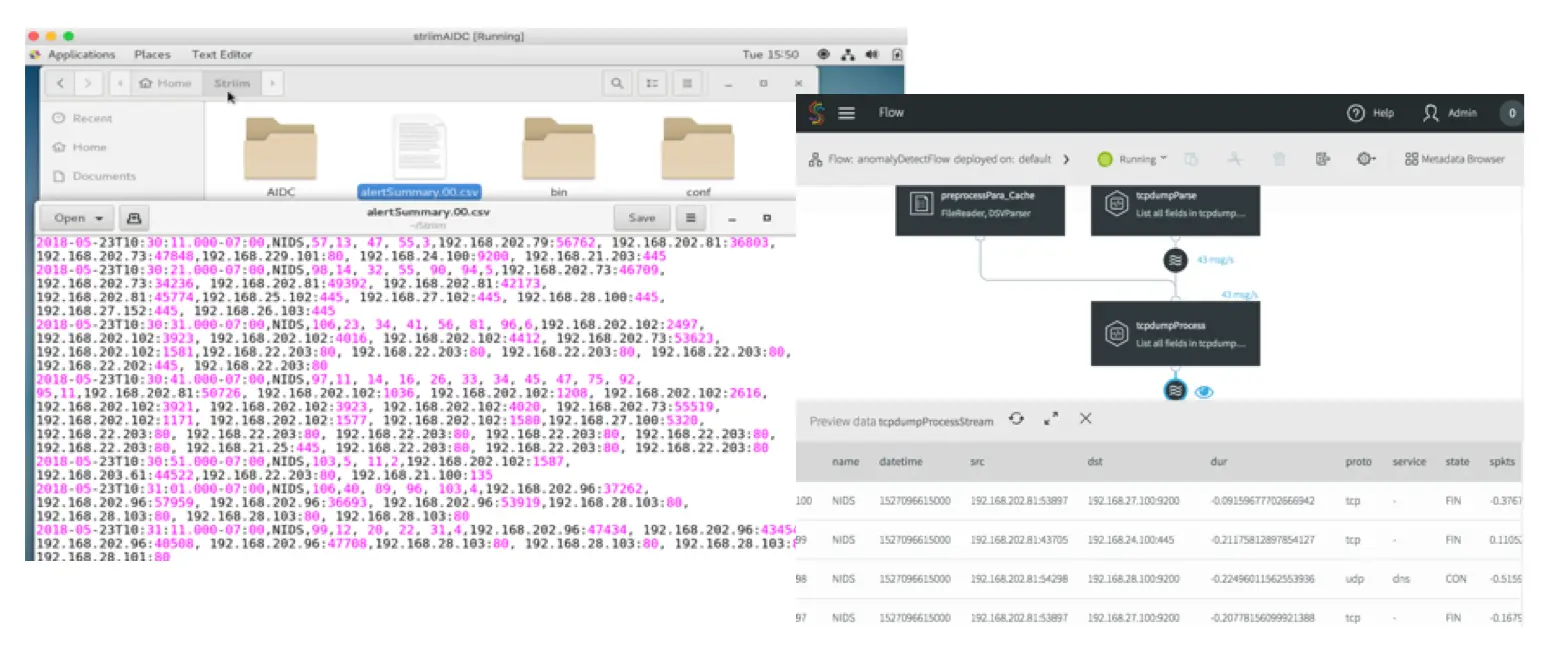
Striim provides a powerful streaming integration platform that aligns and employs change data capture (CDC) and streaming data processing to ensure data is captured and processed promptly, minimizing latency and delivering timely insights. Striim continuously ingests transaction data and metadata from on-premise and cloud sources. An in-memory streaming SQL engine transforms, enriches, correlates, and analyzes transaction event streams. - Enhanced Data Quality
Striim incorporates robust data quality measures such as validation rules and data cleansing processes. By enforcing data quality standards throughout the integration pipeline, Striim ensures the integrity and accuracy of data. Fresh data guarantees the latest insights on operational data to make profitable real-time decisions. - Metadata-Driven Architecture
Rich metadata management is at Striim’s core platform. It captures and utilizes metadata, including information on data lineage, quality, and transformations, providing a solid backbone for guiding activities within the data management system. - Scalability and Flexibility
Striim’s architecture is inherently modular, allowing for infinite scalability by adding more processing and storage resources as needed and without any additional planning or cost to execute so you can save time and money. Whether a database schema changes, a node fails, or a transaction is larger than expected — Striim’s Intelligent Integration pipelines take corrective actions the instant a problem arises. - Security Measures
Striim ensures end-to-end security in data streaming and integration. It offers encryption protocols, access controls, and monitoring features to safeguard sensitive information, addressing the security concerns. Striim’s hybrid and multi-cloud vault securely stores passwords, secrets, and keys. It also integrates seamlessly with third-party vaults such as HashiCorp. - AI Innovation Support
Striim serves as a crucial component for organizations aiming to harness the power of Artificial Intelligence (AI). Its seamless integration capabilities align with Data Fabric’s role as a bedrock for AI initiatives, providing a unified view essential for training robust machine learning models.
Empowering GenAI Innovation
Data Fabric has emerged as a pivotal framework that goes beyond integration, offering a comprehensive solution for organizations aiming to harness the power of AI. At its core, Data Fabric serves as the bedrock for AI initiatives by seamlessly integrating diverse data sources, providing a unified view essential for training robust machine learning models. Organizations leveraging the synergies of GenAI and data fabric can unlock a multitude of advantages. By enabling natural language access, these technologies empower organizations to democratize data, offering a ChatGPT-like interface for seamless queries. Addressing the complexities of data integration in hybrid and multi-cloud environments, generative AI and LLMs streamline real-time integration through automated code generation, supporting dynamic entity resolution and automated data mapping. Leveraging vector databases, these technologies enable groundbreaking similarity searches based on connected context within the data fabric, fostering data intelligence and uncovering untapped data assets. Furthermore, they address the critical challenge of real-time data quality by automating anomaly detection, data cleansing, and validation, ensuring a heightened overall data quality. Finally, in the realm of data security and governance, GenAI and data fabric automate processes such as discovery, classification, categorization, and data access in real time, establishing a foundation for secure and governed data management.
Implementation Strategies for Data Fabric in Your Organization
While the promises of Data Fabric are compelling, the road to implementation requires careful consideration and strategic planning. Organizations embarking on the journey of adopting Data Fabric should begin by conducting a comprehensive assessment of their existing data landscape. Understanding the current state of data sources, quality, and integration points is crucial to formulating an effective implementation strategy.
Collaboration between IT and business units is key during the implementation phase. Data Fabric is not just a technological solution but a holistic framework that requires alignment with the organization’s business goals. Engaging stakeholders from various departments ensures that the Data Fabric implementation is tailored to meet the specific needs and objectives of the organization.
Additionally, organizations should adopt an iterative approach to implementation, focusing on quick wins and gradually expanding the scope. This allows for continuous feedback and adjustments, ensuring that the Data Fabric evolves alongside the changing needs of the organization.
Real-World Applications of Data Fabric with Striim
To illustrate the real-world impact of Data Fabric, let’s explore a few use cases across different industries.
Revolutionize Patient Care: Seamless Data Integration in Healthcare
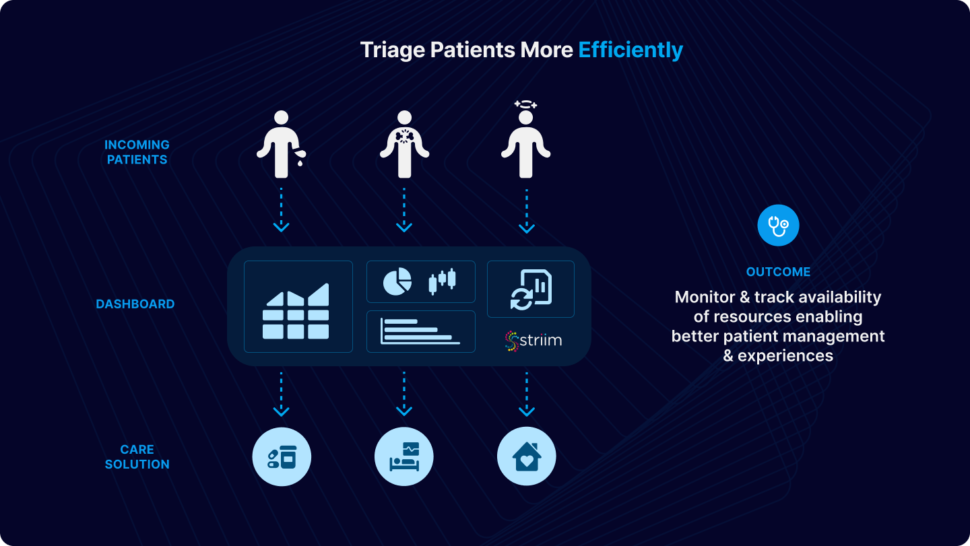
Healthcare institutions grapple with fragmented patient data across various systems. Implementing Data Fabric unifies electronic health records, diagnostic tools, and wearable device data in real time. This results in a comprehensive patient view, enhancing medical decision-making, personalized treatment plans, and accelerating medical research for breakthrough innovations.
Elevate Customer Experience: Real-time Insights in Retail Operations
Retail giants aim to enhance customer experience by integrating data from multiple sources, including sales transactions, customer behaviors, and inventory levels. With Data Fabric, the organization achieves real-time data integration, optimizing pricing strategies, improving inventory management, and ultimately delivering a seamless and personalized retail experience.
Ensure Regulatory Compliance: Robust Data Management in Financial Services
Financial institutions face the challenge of meeting stringent regulatory requirements. Data Fabric is implemented to ensure compliance by integrating and managing data with a focus on security and accuracy. This not only streamlines compliance processes but also enhances risk assessment, fraud detection, and personalized customer services in the fast-paced financial landscape.
Enhance Drug Discovery: Data Integration in Pharmaceutical Research
In the pharmaceutical industry, research teams grapple with the integration of diverse datasets critical for drug discovery. Data Fabric accelerates drug development by seamlessly integrating data from clinical trials, research studies, and external sources. This unified data approach promotes collaboration, data-driven decision-making, and accelerates the pace of innovation in pharmaceutical research.
Optimize Supply Chain: Real-time Data for Manufacturing and Logistics
Manufacturing companies seek to optimize their supply chain by integrating data from production processes, logistics, and inventory management. Data Fabric enables real-time data processing, providing a unified and up-to-date view of the entire supply chain. This results in improved operational efficiency, reduced lead times, and enhanced agility in responding to market demands.
Transforming Data Challenges with Data Fabric and Striim
The advent of Data Fabric emerges as a transformative force, offering a unified, scalable, and agile solution to the burgeoning challenges posed by disparate data sources. Comprising essential elements such as data integration, data quality, metadata management, and security, Data Fabric transcends traditional limitations. This cohesive framework not only breaks down data silos but also fosters a culture of collaboration, enabling organizations to make informed decisions based on a unified and comprehensive data landscape.
Ready to build a global and agile data environment that can track, analyze, and govern data across applications, environments, and users? Start using Striim for free today and scale limitlessly!