The utilization of predictive analytics has revolutionized nearly every industry, but perhaps none have experienced its transformative impact quite as profoundly as logistics. In an era marked by rapid technological advancements and ever-increasing customer expectations, the ability to accurately predict demand and efficiently mitigate risks can make or break logistics operations. Predictive analytics offers a powerful solution.
By leveraging predictive analytics, logistics companies can optimize supply chain processes, enhance customer satisfaction, and achieve significant cost savings. From forecasting demand to managing operational risks, predictive analytics provides invaluable insights that empower organizations to make data-driven decisions in real-time.
What are Predictive Analytics in Logistics?
Predictive analytics in logistics involves utilizing statistical algorithms and machine learning techniques to analyze historical data. By identifying patterns within this data, it becomes possible to make accurate predictions about various aspects of the business, including future demand, supply chain disruptions, and operational efficiencies.
In the logistics industry, the power of predictive analytics lies in its ability to enable companies to adopt a proactive rather than reactive approach to strategizing. This allows for:
- Optimized resource allocation
- Improved overall efficiency
- Enhanced customer satisfaction
- Effective risk mitigation
How do Predictive Analytics Work?
The success of your predictive analytics tools hinges upon the quality and comprehensiveness of your data.
Because predictive analytics leverages historical data and applies advanced statistical modeling, data mining techniques, and machine learning (ML) algorithms to identify patterns and predict future outcomes, data quality should be your priority.
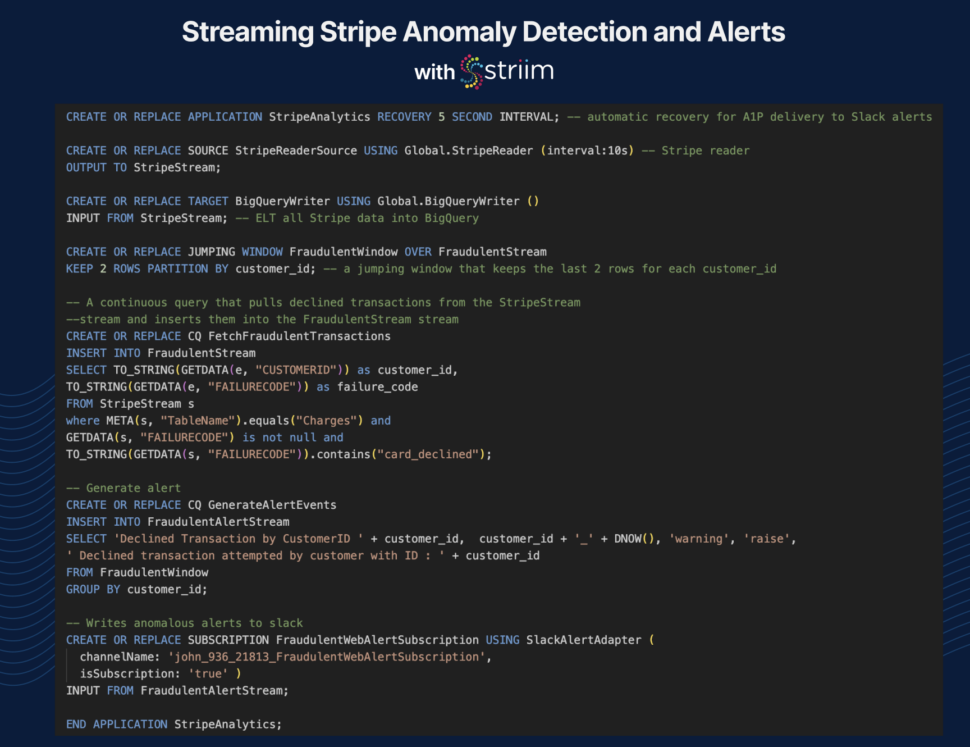
To ensure your team leverages the most current data, data streaming is essential. Batch processing, while capable of handling large data volumes at scheduled intervals, lacks the immediacy needed for real-time decision-making. In contrast, data streaming offers continuous, real-time integration and analysis, ensuring predictive models always use the latest information. This makes it the superior option for timely and impactful insights — making it ideal for predictive analytics.
Here’s the process.
- Data Collection and Integration: Data is gathered from various sources, including sensor and IoT data, transportation management systems, transactional systems, and external data sources such as economic indicators or traffic data. Accurate predictions require seamless data integration, ensuring timeliness, completeness, and consistency.
- Data Preprocessing: Data is cleaned and transformed into a suitable format for analysis. Cleaning involves removing duplicates, handling missing values, and correcting errors. Data transformation includes normalizing data, encoding categorical variables, and aggregating data at the appropriate granularity. Feature engineering involves creating new variables (features) that can improve the predictive power of the models.

The next phase is model development. Predictive models are developed using various techniques, including regression analysis, time series analysis, and machine learning algorithms such as decision trees, neural networks, and clustering. From there, the models learn from historical data to identify patterns.
In the logistics industry, common predictive models might include demand forecasting models, which predict future product demand based on historical sales data and external factors like seasonal trends, and risk management models, which identify potential supply chain disruptions by analyzing historical incidents and external risk indicators.
From there, the models are validated using a subset of data to ensure they’re capable of accurately predicting outcomes on unseen data. After, models are deployed into production environments where they can process real-time data streams. Continuous monitoring and maintenance are essential to ensure the models remain accurate over time.
As new data becomes available, models may need to be retrained to adapt to changing patterns. This process, referred to as continuous or incremental learning, enables models to adapt to changing patterns, trends, and anomalies in real time.
Lastly, predictive models generate forecasts and risk assessments that business leaders use to inform decision-making processes. Demand predictions enable proactive inventory management, reducing stockouts and overstock situations. Risk predictions allow for preemptive actions to mitigate potential supply chain disruptions.
What are the Challenges of Implementing Predictive Analytics in Logistics?
While leveraging predictive analytics offers numerous benefits, it is not without its challenges. Here are some hurdles that logistics companies may encounter in their efforts to implement predictive analytics effectively:

Poor Data Quality
One significant obstacle logistics teams need to overcome in their journey to effectively implement predictive analytics is related to poor data quality. Specifically:
- Incomplete Data: Missing or incomplete data can lead to inaccurate predictions and insights.
- Inconsistent Data: Inconsistent data formats and standards can complicate data integration and analysis.
- Dirty Data: Data with errors, duplicates, or irrelevant information can skew predictive models.
- Lack of Historical Data: Insufficient historical data can limit the ability to identify patterns and make accurate predictions.
Batch Processing
Another common issue logistics companies encounter is related to outdated data. To address this challenge effectively, transitioning from batch processing to stream processing is crucial. Stream processing ensures better data quality, making it more suitable for predictive analytics utilization.
- Latency: Batch processing involves processing data at scheduled intervals, which can delay decision-making and reduce the timeliness of insights.
- Data Staleness: Information processed in batches can become outdated quickly, impacting the accuracy of predictive models.
- Scalability Issues: Handling large volumes of data in batches can be resource-intensive and challenging to scale effectively.
- Integration Complexity: Integrating batch-processed data with real-time systems can be complex and require significant effort.
Integration with Existing Systems
In the realm of logistics, the seamless integration of predictive analytics poses a significant challenge for companies already entrenched in existing systems. Balancing innovation with operational continuity is key to leveraging predictive insights effectively.
- Compatibility: Ensuring compatibility between predictive analytics tools and existing IT infrastructure can be challenging.
- Data Silos: Breaking down data silos to enable seamless data flow across different systems and departments is essential but often difficult.
- Real-time Data Integration: Achieving real-time data integration from various sources, such as IoT devices and transportation management systems, requires advanced technology and processes.
How to Use Predictive Analytics in Logistics

So, how do you use predictive analytics in the logistics industry? There are two main use cases that can uplevel your company’s success.
Forecasting Demand
Accurate demand forecasting is crucial for maintaining optimal inventory levels and ensuring timely deliveries. At its core, predictive analytics in logistics involves the comprehensive collection and integration of diverse data sources. These encompass historical sales data, current market trends, pertinent economic indicators, and even real-time weather forecasts.
Once this information is gathered, it undergoes meticulous preprocessing and refinement through sophisticated feature engineering techniques. This step is pivotal in ensuring data consistency and relevance, essential for the accuracy of subsequent predictive models.
The heart of the process lies in training advanced machine learning models on this refined dataset. These models are designed to extrapolate from historical patterns and current contextual factors, predicting future demand with increasing precision over time.
By generating precise demand forecasts, logistics companies gain the strategic advantage of optimizing their inventory management processes. This optimization not only reduces costs associated with overstocking or stockouts but also enhances overall operational efficiency. Additionally, improved inventory management translates directly into better customer service levels, as companies can meet demand more reliably and consistently.
By leveraging predictive analytics for demand forecasting, logistics enterprises are empowered to navigate market dynamics proactively. This capability not only supports agile decision-making but also fosters a competitive edge in an increasingly complex global marketplace.
Risk Mitigation
Risk mitigation through predictive analytics plays a pivotal role in ensuring your logistics company can make proactive decisions that safeguard your organizational resilience and operational continuity.
Central to this process is the comprehensive analysis of historical disruption data combined with real-time information sourced from GPS tracking, weather reports, and live news feeds. By integrating these diverse data sources, logistics companies can assess the likelihood and potential impact of various risks such as natural disasters, geopolitical events, supplier delays, or transportation bottlenecks.
To effectively prioritize these risks, your team will employ statistical models and machine learning algorithms. These tools analyze patterns within the data and proactively identify critical vulnerabilities within the supply chain. These insights empower decision-makers to allocate resources proactively, strengthening preparedness and response capabilities.
Predictive maintenance also represents a crucial component of risk mitigation strategies in logistics organizations. By leveraging IoT sensors and predictive models, companies can forecast equipment failures before they occur. This proactive approach enables scheduled maintenance interventions, thereby minimizing unplanned downtime and optimizing operational efficiency.
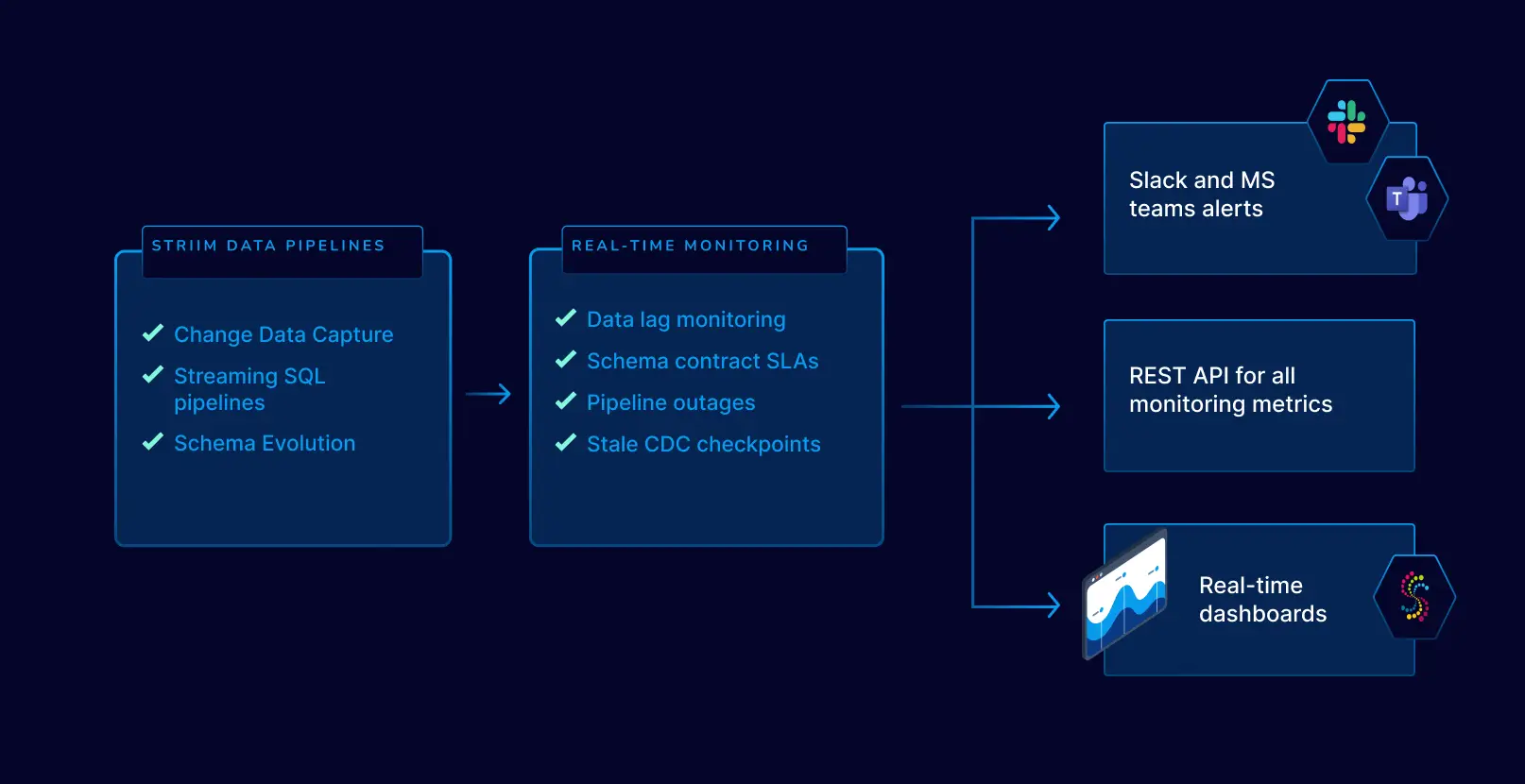
Real-time monitoring systems further enhance risk management efforts by continuously tracking potential disruptions. These systems are designed to detect anomalies and trigger alerts in response to emerging threats. Early warnings enable logistics teams to implement dynamic rerouting strategies, adjusting transportation routes or supplier networks swiftly to circumvent potential disruptions.
Ultimately, the proactive application of predictive analytics in risk mitigation ensures a resilient supply chain ecosystem. By preemptively addressing potential disruptions and maintaining service levels despite uncertainties, logistics companies can enhance customer satisfaction, reduce operational costs, and sustain competitive advantage in a volatile global market landscape.
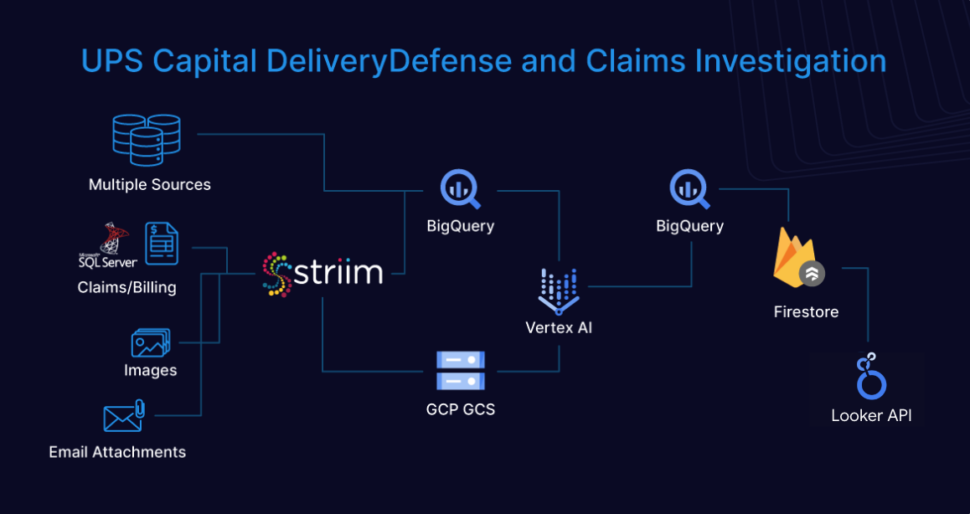
Take UPS, for instance. The surge in package theft due to more online shopping overwhelmed traditional security measures and data management systems, which showcased significant operational vulnerabilities. The lack of real-time data processing hindered UPS Capital’s risk management, affecting operational efficiency, consumer trust, and financial performance, underscoring the need for a sophisticated solution. That’s where Striim came into play.
UPS Capital integrated Striim’s real-time data streaming with Google BigQuery’s analytics to enhance delivery security through immediate data ingestion and real-time risk assessments. This integration allowed advanced analytics and machine learning to predict delivery risks and optimize logistics strategies. The DeliveryDefense™ Address Confidence system then used this data to assign confidence scores to delivery locations, improving predictive accuracy and managing delivery risks more efficiently than ever before.
Leverage Striim to Garner Real-Time, High-Quality Data
If you’re ready to tap into the power of predictive analytics, it’s time to leverage Striim to garner real-time, high-quality data that will fuel informed decision-making and drive operational excellence in your logistics operations. Book a demo with us today to see for yourself the difference Striim can make for your team.