

If you’re comparing DataOps vs DevOps for a practical digital transformation approach, you’re engaging in the wrong debate. Sure DevOps has revolutionized how companies deliver software. But, DataOps is transforming how companies utilize data. So instead, the better question should be: How can I use both DevOps and DataOps to enhance the value I deliver to my customers?
Regardless of the size of your enterprise or the industry you operate in, a good understanding of DevOps and DataOps principles, differences, use cases, and how they fit together is instrumental to accelerating product development and improving your technology processes.
What is DevOps?
Development Operations (or DevOps) combines principles, technologies, and processes that improve and accelerate an organization’s capacity to produce high-quality software applications, allowing it to evolve and improve products faster than traditional software development methods.
How DevOps Fits Into The Technology Stack
Fundamentally, DevOps is about improving the tools and processes around delivering software. In the traditional software development model, the development and operations teams are separate. The development team focuses on designing and writing software. The operations team handles other processes not directly related to writing code, such as software deployments, server provisioning, and operational support. However, the disadvantages to this approach are that the development team has to depend on the operations team to ship out new features, which leads to slower deployments.
Additionally, when bug fixes and problems arise, the operations team has to depend on the development team to resolve them; this leads to a longer time to detect and resolve issues and ultimately affects software quality. Consequently, the DevOps model came as a solution to these pain points.
In a DevOps model, the development and operations teams no longer work in isolation. Often, these two teams combine into a single unit where the software engineers work on the entire application cycle, from development and testing to deployment and operations, to deliver the software faster and more efficiently. Larger companies often have specialized “DevOps engineers” whose primary purpose is to build, test, and maintain the infrastructure and tools that empower software developers to release high-quality software quickly.
What is DataOps?
Data Operations (or DataOps) is a data management strategy that focuses on improving collaboration, automation, and integration between data managers and consumers to enable quick, automated, and secure data flows (acquisition, transformation, and storage) across an organization. Its purpose is to deliver value from data faster by enabling proper data management and bringing together those who require data and those who operate it, removing friction from the data lifecycle.
How DataOps Fits Into The Technology Stack
The primary purpose of DataOps is to deliver value from data faster by streamlining and optimizing the management and delivery of data, thereby breaking down the traditional barriers that prevent people from accessing the data they need.
According to a recent study by VentureBeat, lack of data access is one of the reasons why 87% of data science projects never make it to production. For instance, data consumers like data scientists and analysts responsible for utilizing data to generate insights depend on data operators such as database administrators and data engineers to provide data access and infrastructure. For example, take a data scientist who has to rely on a data engineer to clean and validate the data and set up the required environment to run the ML(machine learning) models. In this case, the faster the data scientists get their requirements met, the quicker they can start delivering value on projects.
Additionally, a data scientist who doesn’t understand how the data engineer collected and prepared their data will waste time making inferences out of the noise. Similarly, a data engineer who doesn’t understand the use cases of their data will create unusable data schemas and miss crucial data quality issues. Consequently, the DataOps process came to mitigate these data pain points.
DataOps takes this cluttered mess and turns it into a smooth process where data teams aren’t spending their time trying to fix problems. Instead, they can focus on what matters: providing actionable insights. DataOps relies heavily on the automation capabilities of DevOps to overcome data friction. For example, suppose the processes such as server provisioning and data cleaning are automated. A data scientist can easily access the data they need to run their models, and analysts can run reports in minutes and not days. Larger companies often have specialized “DataOps engineer” roles whose purpose is to automate data infrastructure needs and build, create and deploy tools that help data consumers utilize data quickly to deliver value to the enterprise.
DataOps and DevOps: Overlapping Principles
DevOps and DataOps share some underlying principles. They require a cultural shift from isolation to collaboration. They both depend heavily on tools and technologies for process automation, and they both employ agile methodologies that support incremental delivery. As such, both DevOps and DataOps represent a sweeping change to the core areas of culture, process, and technology.
- Culture: DevOps and DataOps require a change in culture and mindset, focused on collaboration and delivering value instead of isolation and performing functions. In both cases, every team works together towards a common goal – delivering value. DevOps is about removing the barriers that prevent software from being deployed fast. For DataOps, it is breaking down obstacles that prevent people from managing and accessing data quickly.
- Process: DevOps and DataOps require an end-to-end revision of traditional methods focusing on automation and continuous improvement. Both DevOps and DataOps leverage continuous integration and delivery(CI/CD) in their processes. In the case of DevOps, the software is merged into a central repository, tested, built, and deployed to various environments(test and production). In the case of DataOps, CICD involves setting up workflows that automate various data processes such as uploading, cleaning, and validating data from source to destination.
- Technology. DevOps and DataOps rely heavily on tools to provide complete automation for different workflows(development, testing, deployment, monitoring). For DevOps, tools such as Jenkins and Ansible help automate the entire application lifecycle from development to deployment. In the case of DataOps, platforms like Apache Airflow and DataKitchen help organizations control their data pipelines from data orchestration to deployment. Additionally, data integration tools like Striim automate data integration from multiple sources, helping organizations quickly access their data.
DataOps vs DevOps: Differences and Use Cases
Although DevOps and DataOps have similarities, one mistake companies make when comparing them is thinking they are the same thing. They tend to take everything they have learned about DevOps, apply it to “data,” and present it as DataOps; this misconception can add needless complexity and confusion and fails to reap the benefits of DataOps processes. Some differences between DevOps and DataOps are:
- DevOps focuses on optimizing the software delivery; DataOps focuses on optimizing data management and access.
- DevOps involves primarily technical people- software engineers, testers, IT operations team. In contrast, the participants in DataOps are a mix of technical(data engineers, data scientists) and non-technical people (business users and other stakeholders).
- DevOps requires somewhat limited coordination once set up. However, because of the ever-changing nature of data, its use cases (and everyone who works with it). DataOps requires the consistent coordination of data workflows across the entire organization.
While foundationally, the concepts of DevOps serve as a starting point for DataOps, the latter involves additional considerations to maximize efficiency when operating data and analytical products.
Each approach has its unique strengths, making it the best choice for different scenarios.
Top DevOps Use Cases
- Faster development of quality software: One of the top use cases of DevOps is in shipping software products faster. Google’s 2021 State of DevOps report stated that DevOps teams now deploy software updates 973x more frequently than traditional development teams. Additionally, Netflix reported faster and more quality software deployments after switching to DevOps. They implemented a model where all software developers are “Full cycle developers” and responsible for the entire application lifecycle. The result was a boost in the speed of software deployments from days to hours.
- Improved Developer Productivity: Organizations that have implemented DevOps have seen an increase in the productivity of their development teams. By automating the underlying infrastructure to build, test and deploy applications, developers can focus on what matters – building quality solutions. By implementing DevOps practices, Spotify boosted its developer productivity by 99%. Time to develop and deploy websites and backend services went from 14 days to 5 minutes.
Top DataOps Use Cases
- Accelerates Machine Learning and Data Analytics Workloads: The main goal of DataOps is to remove barriers that prevent people from accessing data. A recent survey by McKinsey reported that organizations spend 80 percent of their analytics time on repetitive tasks such as preparing data. When such repetitive tasks are automated, data consumers like data scientists and data analysts can access data faster to perform machine learning and data analytics workloads. In a recent case study by Data Kitchen, pharmaceutical company Celgene saw improvements in the development and deployment of analytics processes and the quality of the insights after implementing DataOps. Visualizations that took weeks/months were now taking less than a day.
- Improved Data Quality: Ensuring data quality is of utmost importance to any enterprise. In a study by Gartner, organizations surveyed reported that they lose close to $15 million per annum due to poor data quality. By implementing DataOps practices, companies can improve the quality of data that flows through the organization and save costs. In 2019, Airbnb embarked on a data quality initiative to rebuild the processes and technologies of their data pipelines. They automated the data validation and anomaly detection by leveraging tools that enabled extensive data quality and accuracy in their data pipelines.
- Maintain Data Freshness Service Level Agreements: Data has entered a new stage of maturity where data teams must adhere to strict Service Level Agreements (SLAs). Data must be fresh, accurate, traceable, and scalable with maximum uptime so businesses can react in real time to business events and ensure superior customer experiences. By incorporating DataOps practices, companies can ensure that data is dispersed across business systems with minimal latency. For example, Macy’s uses Striim to meet the demands of online buyers by replicating inventory data with sub-second latency, allowing them to scale for peak holiday shopping workloads.
Use Both DevOps and DataOps For The Best Of Both Worlds
Both DevOps and DataOps teams depend on each other to deliver value. Therefore, companies get the best success by incorporating DevOps and DataOps in their technology stack. The result of having both DevOps and DataOps teams working together is accelerated software delivery, improved data management and access, and enhanced value for the organization.
As you begin your digital transformation journey, choose Striim. Striim makes it easy to continuously ingest and manage all your data from different sources in real-time for data warehousing. Sign up for your free trial today!



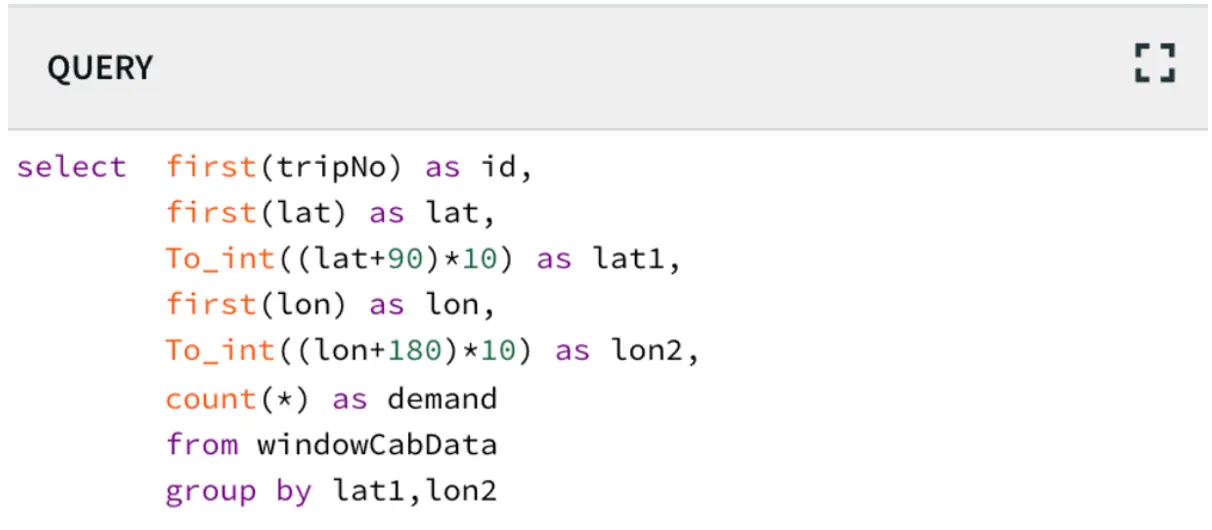
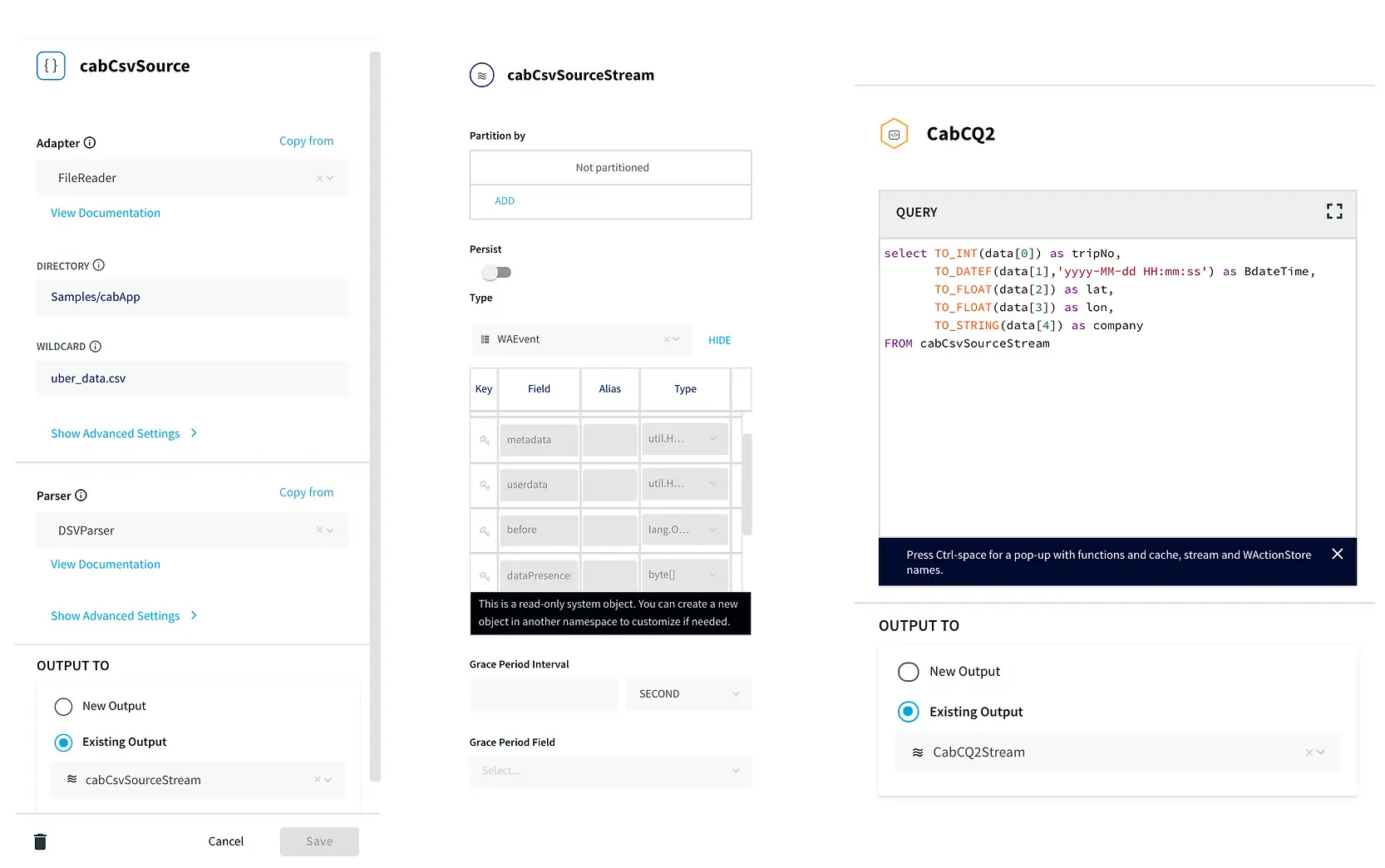
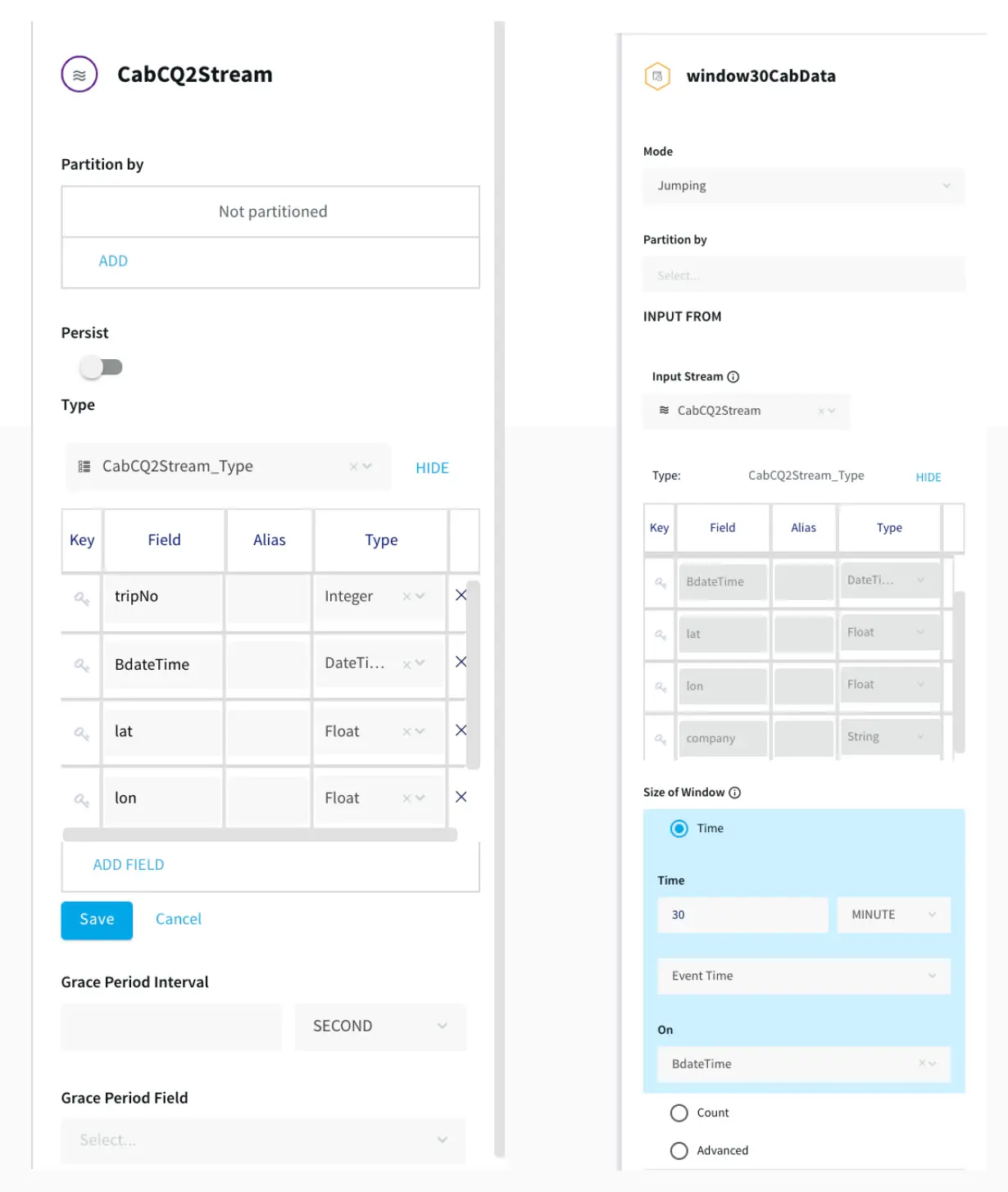
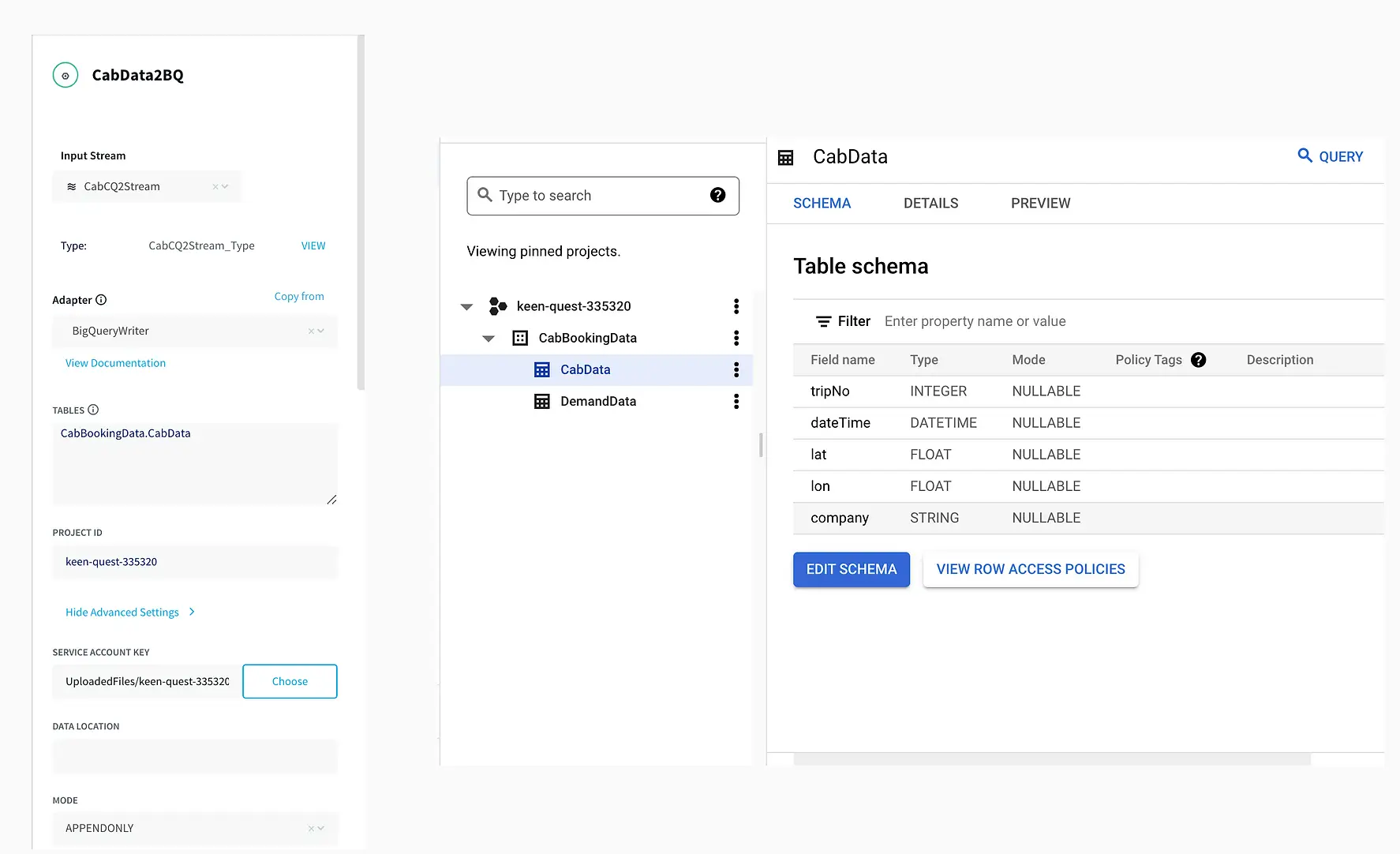
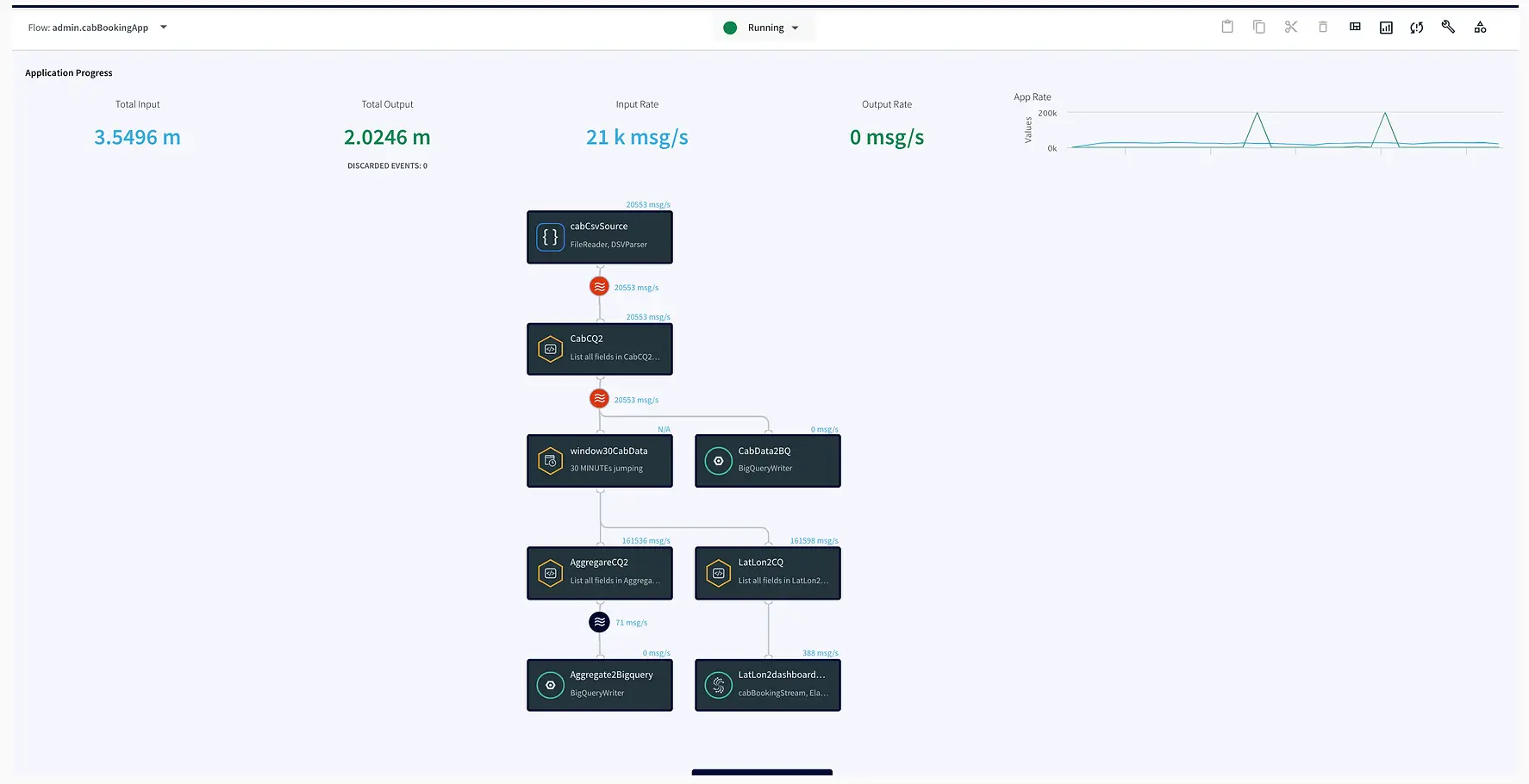
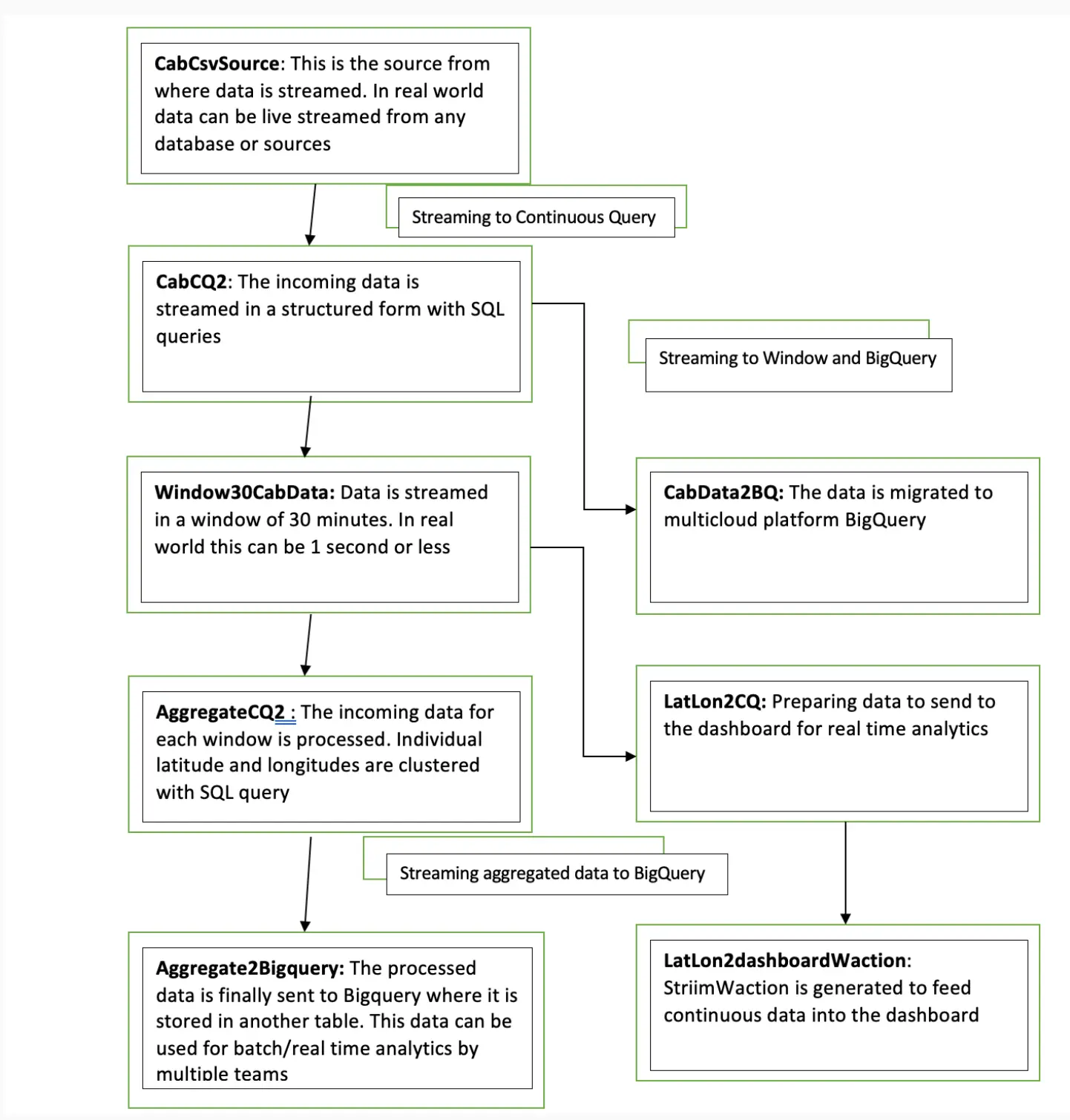



 Data has become one of the
Data has become one of the 