Ovum analyst, Tony Baer and Striim Co-founder and CTO, Steve Wilkes discuss the need for hybrid open source data platforms, which combine open source with proprietary IP for a more cost-effective data management solution.
Download the full paper here: The Real Costs and Benefits of Open Source Data Platforms
To learn more about the Striim platform, go here.
Unedited Transcript:
Welcome and thank you for joining us for today’s Webinar. My name is Katherine and I will be serving as your moderator. The presentation today is entitled The Real Costs and Benefits of Open Source Data Platforms. We are honored to have as our first speaker, Tony Baer, principal analyst at Ovum. Ovum is a market leading research and consulting firm focused on helping digital service providers thrive in the connected digital economy. Okay. Tony leads Ovum’s big data research area focusing on how big data must become a first class citizen in the data center it organization and the business. Okay. Joining Tony is Steve Wilkes Co-founder and CTO of Striim. Steve has served in several technology leadership roles prior to founding Striim, including heading up the advanced technology group at GoldenGate Software and leading Oracle’s cloud data integration strategy. Okay. Throughout the event, please feel free to submit your questions in the Q & A panel located on the right hand side of your screen. Tony and Steve, we’ll address all questions after the presentation wraps up. With that, it is my pleasure to introduce Tony Bear.
Okay. Thank you Katherine and thank you everybody for taking time out of your day to join us in our discussion on the real costs and benefits of open source of data platforms. Um, this is one of those perennial topics that we get questions from our clients, and I have to basically give my similar gratification with Striim for giving us the opportunity to come to share this discussion with you. The fact is that open source is obviously not a new phenomenon in the software market, but the fact is is that in the area, especially the areas that I personally cover, which is data management and big data, it’s just almost impossible to avoid running into open source. And so very frequently I get questions from clients about basically the reliability, the value, and the role of open source versus proprietary software.
Now, of course, basically this issue is as old for instance, as Linux itself. I remember covering the emergence of Linux back almost 20 years ago. And it basically proves the viability of this new alternative model to software development that today is becoming more and more, at least in my area, the norm. In fact, very often when the first questions I asked when Icome across new software firms is: is your product available as open source? So with that said, let’s take a look at what we’ll be talking about over the next hour or so. First of all, take a look at it. Essentially, why are we having this discussion? Why open source? What’s the draw, and then we’ll cut to the chase, which is really looking at the cost and benefits.
And then we’ll look at some real life examples. Where were these costs and benefits played out? And then we’ll then conclude with the takeaways. And spoiler alert, our take on this is that really is that a hybrid model that combines the innovation of open source with the reliability. And last mile of proprietary really is the most successful model and the most viable model for enterprise software. OK, let’s go the races here. So first part is why we’re having this conversation. There’s no question that open source is becoming more and more routine. A routine basically occurrence in the software world. And Black Duck software, which is a software firm that basically provide services that basically helps enterprises track their licenses so they don’t have any IP violations in terms of when they use when they utilize open source code, they conduct annual survey on what they call the future of open source if they’ve been doing this for probably at least about the better part of a decade or so.
And they do this with their partner, with partner organization to our bridge partners and they basically survey, but you know, a bunch of folks in to see basically, to look at how open source is being used in some of the key issues on it. And these were some of the results from the most recent survey, which was published. It was 2016 so it was published earlier this year. And it found that, you know, the use of open source grew 65% among this sample group over the past year. So pretty significant uptick. And so where was most of the open source, what types of software did you know tend to be open source? What tend to be used the most and what they found that, and this is gonna be a key thoughts and carrying on to this discussion, it was basically in commodity building blocks.
So in areas like operating systems, I mean vendors used to basically compete on operating systems and then Linux essentially the advent of Lenny’s really show that the value add is further up on the stack. And so of course today for instance, like Microsoft is no longer defined as a Windows company. So offering systems was a key area. It probably has two reasons, but also data platforms and development tools that can be, we saw most of the use of open source and then they asked the respondents what was the driver, why do you use open source? And the biggest reason was freedom from vendor lockin. Now this part, this next question which is on participation in the open source community, this to me is an outlier which showed that the group that Black Duck surveyed was probably not of enterprises in general because about two thirds of this group based important, they actually contributed to open source projects from our research.
We’ve found that most enterprises that use open source do not necessarily contribute; you really couldn’t scale this number out. It’s not like two thirds of all enter two thirds of the global 2000 contribute. But they certainly amongst this group was a high contribution rate, higher active participation rate. But this next point I thought was very interesting and actually potentially a cause for concern, which is, they asked about governance and basically half of the companies that responded have no formal selection or approval policies for open source software. The question is, would you see the same thing with conventional proprietary software? And so that’s an area where obviously I think there’s still a lot of best practices to be alert or a lot of lessons to be learned, so what has made open source successful?
And so the key watchword on this slide is community successful constructs, communities freed success. That means that when you have a community of critical mass, we have enough folks that are participating in it. So it’s broad enough based on the activity, it’s sufficiently critical mass that good things happen. And for instance, among the benefits when you have a successful open source community is that community members, they will get this steer, you know, it’s a meritocracy. They get to steer where, you know, where the software it goes. It’s not a member, a matter of basically hoping that a vendor realizes their needs or feels their pain and responds, no. The community basically in essence votes on this, at least the people who are contributors.
And in terms of when you have a critical mass community, the velocity of code commits is very high. And along with that, with a large community, because again, you’re tapping into what is theoretically the world’s largest virtual software R&D organization, both to get tested and caught and solved a lot more quickly. So that’s what happens when things work out, right? Not, I mean, not all open source projects are successful. Not all the open source communities aren’t successful. So in this page, we have a few examples. Some of the poster children that really, you know, that really made this myth reality. Linux is the obvious one that’s really kind of the grandfather lecture. Just actually the exception that proves the rule, which was at Linux, even though it’s community had basically someone at the top who had just pretty much, I won’t say unquestioned moral authority, but basically very widely accepted moral authority.
It’s pretty unusual. But the rest of these projects like Apache Hadoop and Apache Spark, also very broad based communities and tend to be better examples of this model in practice. So great debate here. Why open source, why proprietary now the why open source. Those points on the left basically where the chief points that were identified in that Black Duck software survey. And again it kind of reinforces what we’ve said in the previous page, which is that why didn’t you know what accompanies yourself? You know, why the enterprise is used open source? Because they perceive that when an open source project is successful that the quality will be better. These are things that the code quality will be better. They also feel that basically that the features will be competitive because it is vetted by the community. So therefore there is definitely a groundswell, a critical mass market that wants and needs these features and will therefore be motivated incentive to basically improve and fix them.
And of course along with that, because essentially open source, you’re not restricted by basically a vendor licensed where they own the source code is that you have the ability to fix it and customize it, you know, to well and of course it’s gonna depend on the open source license. There are dozens of them out there, but in general, if you’re looking at some of the most popular licenses today tend to be patterned off the Apache license, which allows you to add basically value add on top of the open source code. Um, that pretty much is the case. Now, why proprietary? Well, in many cases, open source projects by their very nature are going to be very narrow and specific. And so therefore they’re not necessarily unified solutions. You have to put the pieces together. That’s what vendors do. And in turn they have their unique intellectual property.
But also what’s very important is that they provide accountability. So it’s essentially they give you one throat to choke, so to speak. Also as they put together a solution. Therefore basically they’re ultimately accountable for security and chances are with vendor’s software, the security should theoretically cover all the functionality in that particular software product, there’s ultra proceeded customer focus that basically successful software companies basically follow the customers. Now again, when you look at these points, there are always gonna be exceptions to every rule. The world is not black and white. But the answer essentially the debating points between open source and proprietary. So one other point though that was not actually among the top responses from the blacktop survey is that a lot of folks believe that with open source that it’s going to provide them cost savings.
A good example of this is that I had a field as a query from one of our enterprise clients who are based out in Singapore. I think they were like a big banking institution. This is like about four or five years ago and is when Hadoop was still new and the perception was to do open source. And so this client they were looking at what types of packages would work on open source. And I went to the court with them, but I asked them that what was driving was they said, well, we would like to get rid of our Oracle software because Hadoop is free. I said, well, not exactly. And they said, you know, who are you going to have to maintain this? I said, well, we’re going to hire consultants.
And so basically what a lot of the rest of this discussion about is going to be basically, you know, we’re going to talk about the perceived cost savings, but we’ll then look at what statements are real and what costs are real. And so cut to the chase here. What do we think is the answer? Well, what we found from our experience in looking at open source software products is that the best recipe for success typically is a hybrid type of model. Very often it used to be called open core where the core of the technology or the colonel would be open source, but then around it, the bender would surround it with their own value add and some of the advantage of that, well of course there’s a value here. There’s a value to the vendor that they don’t have to reinvent the wheel.
A good example of that are the folks who are sponsoring this called Striim. They have basically a hybrid solution. When it came time to choose a messaging system or to develop messaging. They realize that technology already exist in open source and that is not part of their core value ads. So rather than spend their time having to reinvent a messaging system, they showed zero MQ. It also gives you the chance to leverage commodity infrastructure as a lot of open source software typically is designed to do today. Another good advantage of this model is that it gives you both the vendor and the customer, the chance to harness the innovation that’s coming from the open source community.
Especially with the latest common building blocks also, and this is very important, not just in the vendor but also to the customer, but its commercial viability in that it’s kind of like silver. You know, the, the metaphor I’m taking up here as a surgery was successful with the patient, died, well maybe have great software by the vendors give me such great deal. They can’t make money on it. Ultimately it’s not going to be of much value to you because of that vendor is not viable. You’re not going to have anybody to support it. So ultimately it is in not just the vendors interests to be commercially viable, that’s also in the customer’s interest. And so basically this is where the role of unique IP becomes very critical and also becomes very critical because the vendor is best situated to deliver that enterprise.
Then there’s also what we call the last mile of functionality and that’s where, for instance you have these common building blocks, but at the end you need to do that integration. Like with Striim they did that integration with Oracle at the log level, they do that change data capture. That’s not the type of thing that’s going to be very viable for an open source community because that’s going to be a very narrow purpose project. And so therefore you need to go narrow. But deep there is that does not suit itself to open source. So that was again, that basically is why we see the hybrid model being most viable and will return back to us. It really does give you the best of both worlds. So given that they’re not all open source projects are alike and at the risk of or of oversimplifying guilty as charged, we are oversimplifying here.
We’ve basically shown two ends of the spectrum because there are many different types of models on one end as they’ve been your led on the other end is the community side. And the vendor lead is basically where the vendor essentially owned. You know, they basically put the source code out out on someplace like GitHub. But the vendor ultimately basically leads that project. It’s not only, you know, it’s not governed by any type of community. Then this is the other side of, you know, the other extreme, which is the community led words, you know, hosted by a foundation such as Apache, the premise with the gold standard of open source communities. So what’s basically the difference in the vendor? Can you in the technology vendor led project and the good example that you know when they say something like Mongo DB is that the vendor essentially makes the roadmap decisions on where the product goes.
Whereas the community side, the community basically it’s a merit and meritocracy. Now that being said, reality is not black and white in that we’ve noticed that a number of vendors that have hit, you know, basically led their own projects have also, we’ll start to basically dabble in community on community side as as well. And the same as is true with vendors who basically deal with community projects and ready go off and actually a vendor might lead a project initially type it in their own phase or their own matter of kind of like incubation. The difference basically is that regulated led open source products in many ways aren’t like proprietary software products. The difference here though is that the coat and the roadmaps are publicly of are, are publicly available. That’s basically the difference. Again, it’s not to say that one model is better than the other.
For instance, from Mongo DB and its customers that the vendor led model works very well for Spark to do, you know, Linux community model would prove quite successful. So now let’s basically look a little more detail at the cost of savings and we’ll start with the good news and I’m kind of like paraphrasing the old Meineke Muffler commercial and yeah, I originally had a better picture here, but what the quality was crappy. So we’ll go with the screaming babies, but I’m not going to pay a lot for this software. The thing was thought with open source is that the cost model changes. You don’t pay for the software itself. So it doesn’t matter how much software you use or download, you’re not paying a perpetual license or subscription for the software itself.
On the other hand, open source software, just because you can get that software free doesn’t mean open source software is free. It’s freely available, but it’s not great is one way or another you’re gonna pay it. And the preferred model is worry. Basically you go with a commercial open source provider that brokers that packages a distribution and does all the integration of all the open source modules and hopefully does some of that last mile stuff. And they’re basically the typical model is that you pay a subscription for support. That’s actually a fairly familiar model because it’s kind of like proprietary software where you’re paying it. It’s kind of like the annual maintenance part of what you do with proprietary software. The only difference is you’re not paying that upfront cost of capital costs of per of a perpetual license for vendors. The savings are and avoid reinventing wheels as we mentioned before.
And we gave the example of Striim and with their use of an open source messaging, you know, technology as part of their solution or enterprise is as mentioned, there’s no professional licensing. And so therefore you eliminate that, that upfront capital costs, you’re taking advantage typically of commodity technology. Most open source gets popular because the technology is affordable and it works on affordable technology. You know, typically for instance, like, you know, x eight, six machines for instance. And along with that, there are, it has basically, you know, altered pricing expectations and that’s kind of where that picture kind of comes in. I talked to you do folks and they would love to, you know, be able to get the multiples, you know, charge the multiples that like all the enterprise software folks like the Microsofts and the Oracles of the world, you know, have historically charged, but realistically their market is not going to put up with that.
And so what we see the Hadoop market as being in the few hundreds of millions, it’s nowhere close to the existing enterprise database market, which is in which is well north of 10 billion. And you know, even as do princess matures, it will never get to that 10 billion mark basically because the community expects or the customer base expects the lower cost software. However, what we need to point out, and we’re going to talk about this more on the next page on the next slide on the terms of cost, is that the savings picture is going to differ between whether you use what we call raw open source, where you’re going directly to the community website and downloading those packages or projects versus whether you basically subscribe to a vendor. Um, you know, with support distributions, which you mentioned down here, when you typically subscribe to an open source and software vendor, most of them, the vast majority of them are actually following the hybrid open core model.
By the way, there is some proprietary technology there anyway. Okay, so let’s go into those costs. We’re going to look at it from the standpoint of raw open source where you go to, you know,the project site you bite you, you don’t bother going through a vendor, you don’t pay for distribution, uh, or you don’t pay subscription, you know, a forced distribution. And here basically the picture is very similar to that of basically implementing your own homegrown software. The only difference is you didn’t write the original software. You’re probably going to be wearing a lot of others and stuff as a result of this. But that’s another story. But the advantage of course is that you get the flexibility of dealing with it. What’s in essence, a best of breed strategy because you’re picking and choosing your open source projects, but you’re also bearing integration costs as well.
Security is going to vary by open source project. It’s going to be more complete in some than others than prisons. You know, some security technologies, you know, some security projects may not necessarily support all the open source projects that you want to implement. So the key headache for organizations that basically go this raw and you know, no open source in the wild download route is that they need to harmonize the security and integrate all of the pro integrate all the software. By the way, there’s also the fear of obsolescence. I’ll admit it’s not exclusive to open source because you can basically get a vendor product and that vendor goes out of business. Well that’s all she wrote. The same thing can happen in open source. Just because the software is still up there in a website doesn’t mean that it’s not been put out extended life support, um, or end of life support should site.
And so this is very typical of the growing pains and maturing technologies. Cause some are gonna be winners and some are going to be not in that sense, you’re making bets that are very similar with proprietary software as well. But it’s not saying that people I think really think very heavily about was open source because I think, well it’s free. So there is something at risk there. And then there’s the question of extensibility, which is that because many open source projects are very narrow in scope that they’ll require additional functionality. And so we’ve going to go onto a few real life examples here to kind of bear out what we’re talking about here. And this is the case of a bank that implemented a cyber security solution. Then they put it up and then they basically they went the route of basically of debt of basically going through open source projects in the wild.
And so they implemented Storm, which is a data flow routing. The open source project and what’s storm for streaming and Metron for security analytics and Kebana which goes along with, you know, which actually is a related to elastic search or basically it’s for visualizing log analytics. They also had a gooey alert UI when I’m actually surprised they don’t see up here is elastic search. I would have assumed that would be part of it as well. Um, but anyway, um, this was essentially, you know, putting together a bunch of these projects don’t give us between this and homegrown software. They didn’t write the original projects, but the otherwise had to bear the full load of having to integrate all this stuff and patch it. And it basically, this is, you know, this cybersecurity solution was not trivial.
Acquired about 45 engineers and it cost about 20, 30 million to basically maintain, keep us working over about five or six year period. And the big pain points there were, they were there gaps, you know, at the last mile, especially with end to end security which required that custom, you know, last mile development. Another example is there is a communication service provider and trying to extend a call center application. And so they use several open source projects, flume for data in motion for routing data, reading data flow, essentially logstash, which is for collecting and transforming lug with a lot of data and elastic search. Hey, founded here, didn’t leave it off the list and this was actually a much more modest solution. Five practitioners, you know, just quiet five practitioners caught in the neighborhood of 3 million plus or minus that were five or six years.
Key caps here though again were that last mile, which is with change data capture, integration with the customer databases is where their call center. Basically you want to know what’s basically that, you know, what’s happening with the customer. And that required a lot of costly extra development and a lot of costing maintenance. And our last example here is dealing with unplanned adolescents. This is a credit card processing firm that was doing, had a real time transaction processing application. And in this case, again, this was a very, on the surface it looked like are very successful, quick hit. Um, they use spring XD, which is a component for building data pipelines. And it was, you know, I mean it was very quick to inland just a couple of months, you know, not that many engineers. So on the face of it, it served their purposes for what they were doing.
A problem is that the vendor pulls the plug on it when they went to a different strategy. And so the vendor place spring XD project on end of life as a result of that, you know, the credit card company was back at square one. And so, and again, there’s that, I will say the same problem can have with proprietary software as well. But I think the important point here is that just because it’s open source, doesn’t mean it’s going to be successful. And this case actually just like you depend on a vendor for product mode routes for proprietary software. Well this is the case of a vendor led open source project and this case the vendor pulls the plug.
So what tends to work with open source as we said, it basically works best with commodity technology, which draws a critical mass target audience of developers and prospective customer. Do you guys serve a wide enough market to build a big enough community? Um, it had and that also the algae is extensible and the licensing is extensible and that’s where that the Apache license has proven very popular because it does allow you to add your own value add on top of the open source. It doesn’t require you to give it back to the open structure. I mean, like a lot of the earlierGen one licenses like the GPL licenses, which were the original licenses, um, in the open source world. Um, and but deal is that what you’re looking at, and again, it’s got to be critical mass technology so it’s not written for an overly narrow use case and it’s not hardwired to any specific platform.
And the API APIs are published and freely available and they’re open and ideally, yeah, if you have those a open API, hopefully it’s an avoid best of breed integration issues. Um, but again, that’s another reason why we believe the hybrid model is best. We’ll get to that in a sec or get back to that in a sec. But where do we say proprietary software? Where’s proprietary IP really come in? Well, where we really see it happening is, especially at the application business logic level. Now of course, see every rule, there are exceptions. Yes, there should be CRM, a customer relationship management system, but for the most part we’ve not seen a lot of open source of the application level. And there’s really a good reason for that, which is that that’s where businesses want to differentiate themselves in terms of how they do business.
And so do you want to basically, even though obviously we have applications software that has not commoditized this a bit. The differentiation is too specific to really make it well suited for an open source project. I mean you don’t want to get a lowest common denominator solution for your business. Um, we’ve also found it’s very good for niche technologies and solutions where basically the market, the addressable market is too small. Therefore the addressable community of developers is going to be too small to really support an open source projects such as doing let’s say a connector to a data, you know, a connector to a, to a log into logging system of a database. And that again ties into this last one if unique and custom integration use cases. So what we see here is that proprietary IP as best for differentiating enterprise solutions, also good for and to, and security because basically, you know, a vendor can basically take trucks and making sure all those gaps are filled.
It’s, that’s going to be kind of, it’s going to come basically kind of hit or miss when you have a community. Also this also polished user experiences in UI. And I think it’s not because you can’t open source that. I think it’s probably because the dates are of developers that I don’t really think in terms of functionality and maybe I’m building some stereotypes here, but we’ve just not seen misery experiences as being the type of thing that you open. That’s open source. And yes we do see some goalies on various social source projects but they’re really polished once. I think it’s, that’s really uh, that’s really where the vendor comes in and keep it and you know, with the exception of let’s say certain categories of products like were apple made, it is named UI is usually not the um, is not the, uh, you know, I guess the, you know, the show stopper and also again, last mile of integration and consistent SLS.
That’s where you really gonna to account on a vendor to really make sure that essentially the trains run on time and that and also has all the tracks connect anyway. So in general, we believe that using hybrid open core for solutions for last mile is differentiated intellectual property. But at the same time you get to get the best of both worlds by leveraging community building blocks. It’s essentially we’re commodity meets enterprise grade and so the takeaways and all this is that, you know, we’re not saying don’t use open source, we’re saying this is open source where it’s appropriate, but when you do so keep your eyes open, it’s open source is not send out honestly free. So look at the real cost commercially some and you’re either going to pay that cost either through subscriptions with commercially supported, um, you know, annual subscriptions, which is pretty much like paying maintenance for conventional software and it’s all, or you’re going to be paying for it in terms of all the spadework you have to do when you implement rural open stores out in the wild.
It’s a lot like doing again, your homegrown software hybrid open core approach we found to be the most reliable and the most viable model for enterprise software because we said it combines the best of both worlds. It keeps the vendor in business, which means that it keeps, it gives you the assurance that you’re going to have a vendor, they’re a throat to choke and someone there to support your software. Um, but yet it also taps the rapid innovation and the open source community to come the economies of a commodity software, but yet at the same time you get that unique IP and last one integration and security. So that pretty much wraps up my part of the conversation at this point. I like to turn it over to Steve.
Well, thank you Tony. I’m going to start by introducing Striim, talk a little bit about our platform and doing that to provide context for the discussion around open source in this hybrid open source model because you know, the Striim as a company building our platform, any intelligent software company, if it’s been built already, then why build it? Again, we going into the discussions around that and how important it was to integrate pieces of open source into the platform. So Striim has been around for around five years now. We have a mature technology that’s been in production with customers for more than three years. And we are continually evolving and releasing new updates to the platformc, adding new functionality, new connections, etc. And Striim provides a full end to end streaming data integration and analytics platform. So what the platform does in a nutshell is you to collect data continually from a whole variety of enterprise sources, things that may be inherently streaming, like message buses and sensors that continue data in, in real time.
And then things that you may not think of as streaming like files for example. Um, so with files you, you know, we will collect the data at the end end of the file as it’s written and stream that it in real time. And in databases, most people think of those as a historical record of what’s happened in the past. But we use a change data capture technology to see what’s happening in the database in real time. Yeah. Those inserts updates and deletes as they’re happening and stream those out. So once you’ve done continuous data collection, you have real time a memory data streams. And the simplest thing you can do with the platform is just deliver that somewhere else. So from a streaming integration perspective, you can take stuff that’s being written into our database, for example, and stream that onto Kafka or take your web bug files from on premise and stream those out into uh, Amazon S3 or Azure, SQL db in the cloud.
That’s kinda an a thing that you can do with the platform. But typically our customers are doing more than that and that requires some degree of processing. So we have this ability to do in memory, SQL based continuous queries that can process that data and analyze that data. And this in conjunction with a time series windows and an in memory data grid allow you to do things like transforming the data, uh, from one form to another, filtering it, uh, aggregating it. So looking at, you know, the last minutes worth of data or the last a hundred events and the last entry for each one of these records, etc, and also enriching the data. And that’s where the memory dating creed comes in because you need to load large amounts of data into memory reference data and then join that with the streaming data in real time as things are passing through.
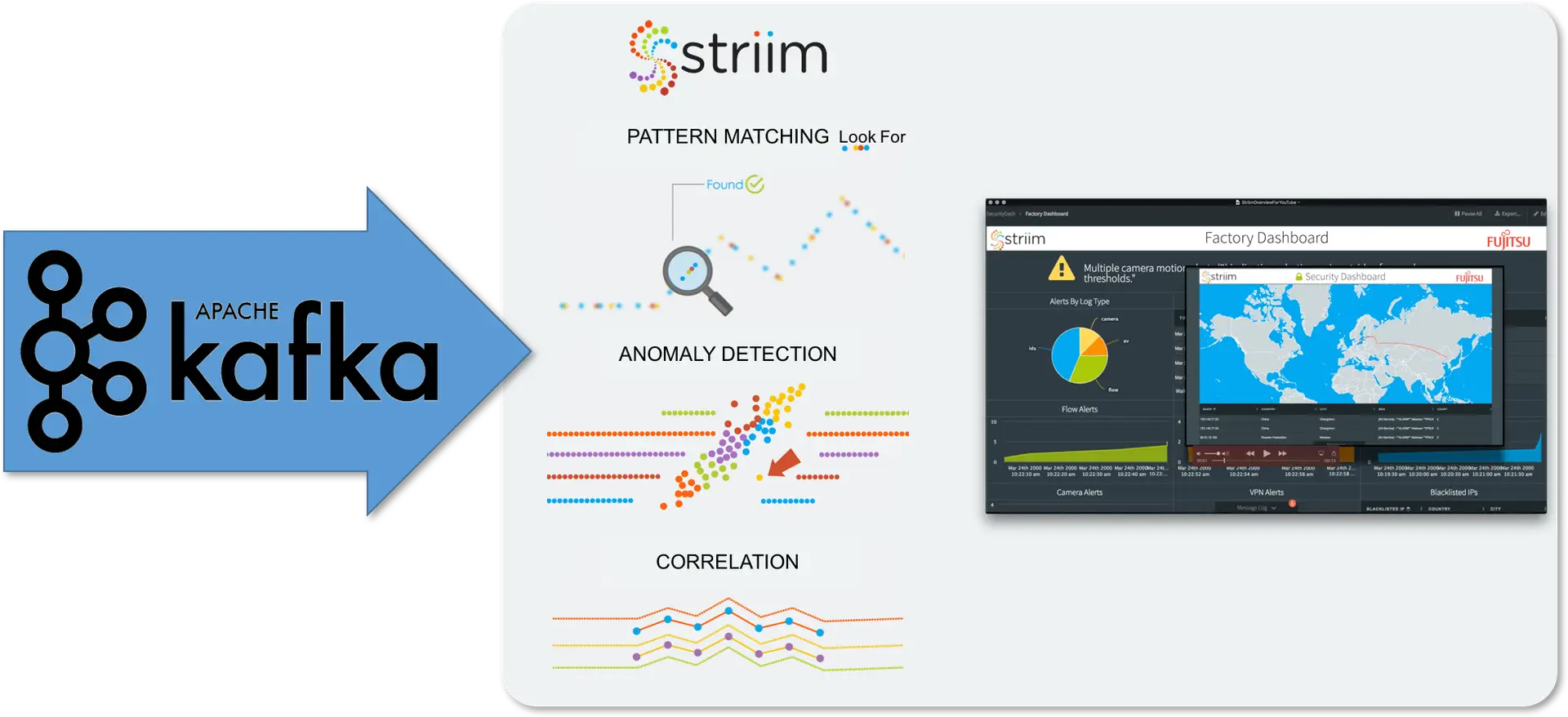
So that’s kind of how you can process data and get it into a form you want before delivering it. An example would be if you’re reading change data from your nicely normalized database. Yeah. And say it’s an audit detailed table, you’re just gonna see a whole bunch of ids, you know, order Id, this customer Id, this item Id this. And if you’re just delivering that to say, that’s not gonna mean much to the people reading the data from Kafka. So in Richmond typically will be, you’d load reference data into memory and then join that. And so now instead of those ideas do get the older information, the customer information, the item information that’s all written out. And so you can now do more intelligent analytics and talking about analytics, we have the capability of doing um, in memory statistical analysis on anomaly detection, pattern detection through a complex event processing syntax and correlation across data streams and across windows.
And this enables you to look for things that happen at the same point of time or within the rate, the time range and also to look things I co located in, in the same geographic location for example. So doing this correlation is an important aspect of almost all of the analytics use cases that we see. Then on top of all of this processing, as I mentioned, is happening through the sequel based queries. You can then build visualizations all using our platform. So real time dashboards, you can trigger a workflows, you can generate alerts to notify people that things are happening and we have ways of integrating third party machine learning directly into the streaming data flows as well for realtime scoring and inference. That’s basically what the platform does. It’s uh, in memory streaming integration on analytics platforms, it’s everything from continuous data collection, processing, analytics and delivery.
Yeah. And this suits different categories of use cases. It’s a piece of middleware that enables you to do a whole bunch of different things. So on the real-time data integration side, we have customers that are delivering data real time into a data lake for example, after processing it and getting into a form that they want or integrating on premise and cloud, keeping a cloud database up to date with an on premise database for hybrid cloud initiatives or doing IoT edge processing. On top of that we have the analytics type applications where your customers are doing things like fraud detection or a cybersecurity monitoring where you analyzing lots of different data feeds and anti money laundering and location based solutions where people move locations really, really quickly. So you need to have real time insight into what’s happening. And that’s where a streaming platform really comes into play because you can process the data as it’s being produced.
And then we have the customers that have built dashboards and this is typically used for building and monitoring real time metrics and key performance indicators in order to real time quality monitoring, a SLA monitoring, etc. And these use cases across many, many industries. I’m not going to go into all of these cause that’ll take up another couple of hours, but we have use cases across lots of different industries on, you know, we touch lots of different departments within those organizations as well. The key differentiators of our platform are that it is a full end to end platform that does everything from collection, processing, analytics, delivery and visualization of real-time data that is designed to be easy to use. So it’s very fast to build and deploy these applications. We have a UI for drag and drop building of data flows. We have the SQL like language that enables you to use a whole bunch of different types of uh, your, your internal resources, whether they’re developers or business analysts or data scientists to actually build out these data flows.
Okay. We are enterprise grade and that means that we are inherently clustered, scalable, reliable with, you know, full tolerance and exactly once processing and recovery built into the platform. And we have end to end security and we can integrate with a whole bunch of things. You know, so we work with the top three cloud platforms, the top three big data platforms. We have changed there to capture for the major databases. We have deep integration with Apache Kafka and other open source solutions. So that’s the platform in a nutshell. And it’s going to important to kind of understand that within the context of how this works with opensource. So now imagine you didn’t have Striim and you needed to build a streaming data framework or platform from open source. And this is kind of the process that we went through as well. So we’re talking from experience here and how to build such a platform.
Well inherently you’re going to be taking data from sources, moving it to targets and doing stuff in the middle. As I mentioned, that stuff can be quite complex and it requires a lot of different categories of software. And so in order to move data render class, so you have a high speed message infrastructure in order to load large amounts of reference data into memory, you need a distributed in memory data grid or cash to store the results you need distributed results, storage. And then you have data collection. That livery and the processing of the data. You have to have some way of developing the solutions and visualizing the solutions. Those will have different categories of open stores that you need. Yeah. And we’ll just add a few in here so you can get an idea. But every single one of these categories has, you know, a large number of different pieces of open source that you can choose from.
And that isn’t the end game, right? Those are just some pieces that you need. And in order to get it all to work, he needs some glue code around all of this to handle all of the enterprise grade stuff. That clustering, scalability, reliability, security and management that enables all these pieces to work together and to scale together to be reliable together a single security policy across all of them. And then you need a layout as i enables your developers to actually build the applications. Cause this is just the framework, the platform, there’s no solutions yet. So, um, the goal of this as an enterprise would be that you’re building something that enables people to build analytics or integration much more quickly. And so you need a abstraction layer, an API connectivity in the web server and things like that. Yeah. So that’s all the pieces.
And that’s kind of the pieces we looked at as well when we were building an app platform. Well, so if you look at the process involved in that if you’re going to build this from open source, uh, first of all, you need to design it. We just did that. We had a diagram that showed the various pieces that we were looking at UI deeper than that in reality. But that’s an idea. And then for each component of open source that you’re interested in, you have to look at the different options. So identify what open source is available in each of the categories and evaluate each one. You may have performance requirements, scalability requirements, overhead requirements, uh, even, you know, software language requirements. You know, I want everything to be Java, I want everything to be javascript and it’s kind of hard to mix the two.
Okay. Then you need to build the integration and build the glue code and the layers around all of that. As your integrating things, you might find that some things don’t work together. So you may have to go and identify different components that you’re going to use. Then you go into testing and of course testing like results in changes that might result in, you have to change things up because things don’t work once you have as built, you’re going to have to maintain it. And some of the things that Tony mentioned, if the open source software that you’ve chosen is upgraded in some way and it changed its APIs and you know, thankfully know Kafka is now finally out of Beta is a one o uh, after all this time. But up until now, the APS were changing all the time. And so every upgrade you went, every version you went, you may have to modify all your, the integration code to work with the new API.
And the other case that Tony mentioned was the open source is deprecated. Maybe they’re not going to fix any bugs in anymore. It’s contributed contributors left, they’ve all moved on to the next big thing. Um, in that case, you may just have to replace your piece of open source, which means you now have to identify a new one and goes through the evaluation process and the reintegration process. So you have to do all of that. Um, and also get support if there are any bugs that you find and go to the community or the vendor to fix things. And you need to do all of that, um, before you can start to build your applications. Um, and so that’s quite an involved process and that’s why you talk about these large timeframes that are involved in a lot of these open source projects. You’re talking even with something basic, you know, six months to a year before we can even start to get any results out of it.
Whereas if you download that platform, we’ve done all this already and so you’re literally just installing Striim and then you can start building the applications and you’ll talk to as support and we will manage all the issues with all the open source. So we include that enables you to kind of build your applications faster and gets to deployment. At faster if we look at what our platform looks so I can, how we’ve integrated open source and we have things at the edge, you know, so we have sources, targets in our platform that integrate with open source pieces including Kafka, HDFS, flume, HBS, hive, et cetera. All of the things you’d expect if you’re reading data or writing data somewhere. But then we also have pieces of open source within our platform and we went through that identification and evaluation process and or to choose the best of breed in all of these cases and integrate them together.
We have two different versions of messaging. We have a high speed messaging and it runs in network speed that utilizes a Java version of zero MQ and Cryo. We have the persistent heights be messaged infrastructure, uh, for recovery purposes and application decoupling purposes. We use Kafka for that. It’s built into the product ships with the product. We have Hazelcast that manages clustering metadata management and control. We have an implementation of j cash in memory data grid for high speed, uh, look ups and very fine grain control over where data is stored, um, across the cluster. And we utilize the last day, uh, Tony will be happy, as I mentioned last week, again, uh, for distributed results storage. So those are all the pieces of open source that we, we have chosen. Um, there are a lot more supporting classes I couldn’t possibly fit in here.
You know, like JSON parser for example. Um, there’s lots more of those, but you know, they’re not going to major, major components that are their own software category by themselves. Um, then of course we built all of the glucose, so we had to work out how do we do scalability, the distributed technology clustering, failover across all of these species. So they all work together. Uh, how do we manage reliability and exactly the ones processing all the way from sources to targets. How do we have a single security policy, role based security and encryption across all of these things and full management and monitoring interface APIs, UI that enables you to control this is a whole platform rather than individual pieces. We have a full set of API APIs, whether they’re through ask scripting language, JDBC IDFC rest API as a websocket cpis that enables you to connect with the platform.
But then we also have a whole bunch of secret sauce that all the pieces that are enabled to continuous data collection, whether it’s from devices, big data, databases, etc, through change data capture and continuous data delivery. Um, all those things that you see on the other side. And then the real key is SQL based processing and analytics, which is our own intellectual property. Um, that leads you to do the filtering, transform aggregation enrichment; do complex event processing, anomaly detection and correlation. And that’s, you know, a piece of the platform that we currently hold a patent for. Um, I was told you mentioned, you know, on top of that you very yourself and see, uh, UIs either in open source software or even within the enterprise. Not many enterprises that are building a data processing platform are going to take the time to build a drag and drop UI or a command line interface or some other easy way to actually build the applications.
Yeah, they’re going to rely on developers to write code to build the applications. So we provide a drag and drop UI for building data flows, um, doing all the analytics and for building the dashboards. And so I’ve seen all of that. So that’s kind of how we incorporate open source into our platform, but our customers don’t have to worry about it. And if one of these pieces was decommissioned, it was no longer supported or there were major books in it, then we handle that for the customer. They don’t have to have developers on call the $3 million spent to keep people, uh, maintaining and upgrading the platform continually. No. So a unique it includes is change data capture that enables you to get data from databases in real time as it’s happening and also enables you to handle things like changes in Schema. So if the tables structure changes that we can modify how we write things out to do pool capital for example.
Okay. Uh, in memory distributed processing, which is a patented technology. Yeah. The enables you to, uh, have the SQL based processing happening across the cluster and intelligently route things across the cluster and join things with this distributed cash and handle a full tolerance and exactly once processing, um, with rollback and recovery, uh, that enables you to scale the applications and also trust that they’re going to work and pick up where they left off. If you know, for example, you’ve lost the entire cluster. Um, so these are some key things that we’ve added in and on top of that kind of UI and dashboard builder, they, as we mentioned, you rarely get from open source.
We are recognized by the industry for doing a lot of innovative, innovative work, both on kind of streaming analytics and on Iot. And also a great place to work and we’re very happy about that one. Just very quickly, um, drill down into a couple of these customer stories. No, we have a customer who’s built out an anti-piracy solution. Um, it’s useful, um, video feeds, etc, and the media customers and enables kind of real time monitoring of the usage of a feeds media and correlates multiple logs in real time. It’ll just to identify is a really a subscriber or not. And why did they choose us? Well, they looked at a number of different open source log analytics products. They had some concerns about the amount of people that it would involve to maintain it. They estimated that if they hadn’t used that platform, they would have had to have triple the size of the team to actually do the development and ongoingly maintain and keep the platform up to date.
And also some kind of limitations with single open source solutions that they could have chosen for this and kind of the integration that it needed to do. So we were chosen because we had, in addition to the log capture, change data capture from the Oracle database, we have the SQL processing language that enabled them to use what they wouldn’t ordinarily have thought of as developers who people in the analytics team to kind of build out some of the data flows. And we had is great visualization that they could use for monitoring. And we could easily integrate with the existing code that they had for a machine learning solution. A second case is a leading credit card network. And what they needed to do was to very quickly identify potential threats. And if you have lots and lots of security applications out there, you know, a large number of different types of security logs, you’re gonna end up with alerts from all of them.
And if you get an alert, security analysts will have to manually fill down and correlate and look at, um, what else is happening. So if you get a port scan from a certain IP address, what else is that IP address doing? And they’d have to manually correlate and look across the whole bunch of different mugs. So they’re using our platform to pre correlate across all the logs and identify things, uh, have activity in more than one place or with certain rules around that that enabled them to identify high priority potential threats and act on those much more quickly, uh, reduced the amount of time that you have to spend looking at data because we would pre correlate all the data. I’m a really enables him to pretty quickly see everything that they need in order to make decisions. And they chose us. Um, cause they, they, you try things before they built a python application that did things with a four hour window, so it was four hours behind.
And they wanted this information as soon as possible in real time. They looked at two different types of open source. Um, one of them, the one that they worked on first. That was the story that Tony told that got de supported as they spent a year of development, unfortunately. So then, yeah, looked again, uh, options. One of the open source things that they did, the identification and evaluation and testing that one didn’t scale. Um, as, as they needed, I was talking 10 billion events a day, a that needs a process and they just couldn’t get that performance. So this other piece of open source, um, and it also didn’t have all the required features they needed and they chose us because we have this, uh, necessary scalability and also the sequel based processing and analytics so they could built out of the state of affairs and update them and build additional applications really quickly.
So key takeaways really are that this blended approach does all that work that you would need to do to identify and evaluate and choose and integrate and maintain all of those bits of open source and provides it all for you without you having to worry about abstracted away so that you can use it very easily. But also it key integrates with open source. You may have chosen already, so if you already have your own Capitan class so you don’t have to use the one we ship with, we can integrate with that. Um, as if it was ours. Um, if you already have Hadoop we can read and write from that for you. Um, but you, our solution is also enterprise grade and you can get started much faster and more cost efficiently. And you know, we basically take the best of open source that we have chosen that we have gone through all that process and bundle it with a unique IP. That office is patented technology for realtime integration analytics provides you the UI for building everything, the ease of use end to end security, reliability and scalability and gives you this ability to build dashboards and visualizations in a single platform. So that’s the end of my part of the presentation and we will now open it up for the Q. And. A
Thanks so much Dave and Tony. I’d like to remind everyone to submit your questions via the Q&A panel on the right hand side of your screen. While we’re waiting, I’ll mention that a link to the recording of today’s Webinar will be emailed to you within the next day or so. Feel free to share this link with your colleagues. Now let’s turn to our questions. Our first question is, does CDC need to be turned on in the database for Striim to handle CDC from it?
That’s a great question. And the answer is yes. Um, but we can help you with that. You know, so different databases have different requirements for enabling change data capture. You know, Oracle for example, needs supplemental logging turned on. Um, see my SQL requires you have a been logged, etc. Um, but if you’re using our platform, you using a UI using our wizards, when you make that initial connection into the database, we will check all of that for you and we will tell you if you don’t have the correct things configured and if you don’t what you need to do in order to achieve that. So, um, yeah, it does have to be turned on but we can help you with it.
Great. Thanks. Our next question, um, when it comes to real time data integration, how does Striim differ with other products in the market? Okay.
Okay. Um, what you’ve just seen in the presentation, hopefully, um, if we are a full end to end platform, right? So, um, we can do real time integration and other people talk about real time integration as well. Um, you know, there are solutions out there that can do change data capture into Kafka, right? But if you look at a little bit underneath the covers, what they mean is that they are doing change data capture and they’re writing exactly that data into Kafka. Um, there’s no processing available. There’s no, uh, enrichment. There’s no, uh, advanced features available within that, you know, so, um, because people talk about real time integration, streaming integration kind of as a marketing piece, it doesn’t mean that they’re necessarily doing everything that you need, you know, to try to achieve that. Yeah. So it’s really our completeness that is the big differentiator that we have all these data sources to turn anything into a data stream.
We have all of the processing in sequel. You don’t need developers to write Java code or Java script. They’ll see sharp to actually do all of the processing of the data. We have a lot of different data targets and you can take one source CDC and push that into Kafka cloud database, a blob storage and Hadoop all within a single data flow. You don’t, you know, it’s very easy to build these things out that we have. Um, some, some of that is some videos on that as well, you know, so, um, it’s really the completeness of the platform and plus because you now have things streaming, if you want to move to do real time analytics, you’re perfectly positioned to do that and our platform can help you with that too.
Excellent. Thanks Steve. Our next question, does Striim take care of upgrades of all the underlying open source technologies? For example, if I upgrade to the latest Striim version, I get the latest compatible open source technologies.
So, um, it depends on kind of the integration point, right? So if you’re talking about sources and targets, things that we connect to, then we’re always trying to keep up to date with whatever it is our customers are requiring. And that may not be the last, last version of everything. Um, it, it could be the previous, the last three depends on what has got market traction, but we will always support our customers, ensure that they can connect with whatever they have already. Um, if it’s something that it’s an integral part of our platform that is completely hidden from customers. Um, we have our own mechanisms by which we choose when to upgrade. Um, and it obviously depends on kind of stability, security, amend to API changes, uh, integration, effort, etc. So we may not always be shipping with the last release of something within our platform, but we got to keep things current because we obviously want to take advantage of any bug fixes and security fixes that have gone in.
And if customers points at the point something out to us. Yeah. And that concern, for example, about a security hole in one of the pieces that we incorporate, um, then that’s obviously something that we can patch and fix quickly. So the, uh, that was a long answer. The short answer is it depends.
Perfect. I think that also addresses our next question. I regret that we’re out of time. If we did not get to your specific question, we will follow up with you directly within the next few hours. On behalf of Tony and Steve, I would like to thank you again for joining us for today’s discussion. Have a great rest of your day.