
sad fsa sadff se
Month: April 2026
test sd asdfa sdes
sda asdf asdf s sae
SQL Server to BigQuery: Real-Time Replication Guide

SQL Server has developed a reputation as the backbone of enterprise operational data. But when it comes to analytics, operational systems weren’t designed for complex queries or transformations. To build advanced analytics and AI applications, enterprises are increasingly turning to Google BigQuery.
Ripping and replacing your legacy operational databases isn’t just risky; it’s highly disruptive. Instead of migrating away from SQL Server entirely, data leaders increasingly want ongoing, continuous integration between their operational stores and their cloud analytics environments.
The future of analytics and machine learning hinges on fresh, low-latency data. If your BigQuery dashboards and AI models rely on data that was batched overnight, you aren’t making proactive decisions, you’re just documenting history. To power modern, event-driven applications, enterprises need real-time, cloud-native pipelines.
This guide covers the why, the how, and the essential best practices of replicating data from SQL Server to BigQuery without disrupting your production systems.
Key Takeaways
- Integrate, don’t just migrate: Enterprises choose to integrate SQL Server with BigQuery to extend the life of their operational systems while unlocking cloud-scale analytics, AI, and machine learning.
- Real-time is the modern standard: While there are multiple ways to move data into BigQuery—from manual exports to scheduled ETL—real-time replication using Change Data Capture (CDC) is the most effective approach for enterprises demanding low latency and high resilience.
- Architecture matters: Following established best practices and leveraging enterprise-grade platforms ensures your SQL Server to BigQuery pipelines remain reliable, secure, and scalable as your data volumes grow.
Why Integrate SQL Server with BigQuery
Modernizing your enterprise data architecture doesn’t have to mean tearing down the foundation. For many organizations, SQL Server is deeply embedded in daily operations, powering ERPs, CRMs, and custom applications consistently for years.
Integrating SQL Server with BigQuery is an ideal way to extend the life and value of your database while simultaneously unlocking BigQuery’s massive scale for analytics, AI, and machine learning.
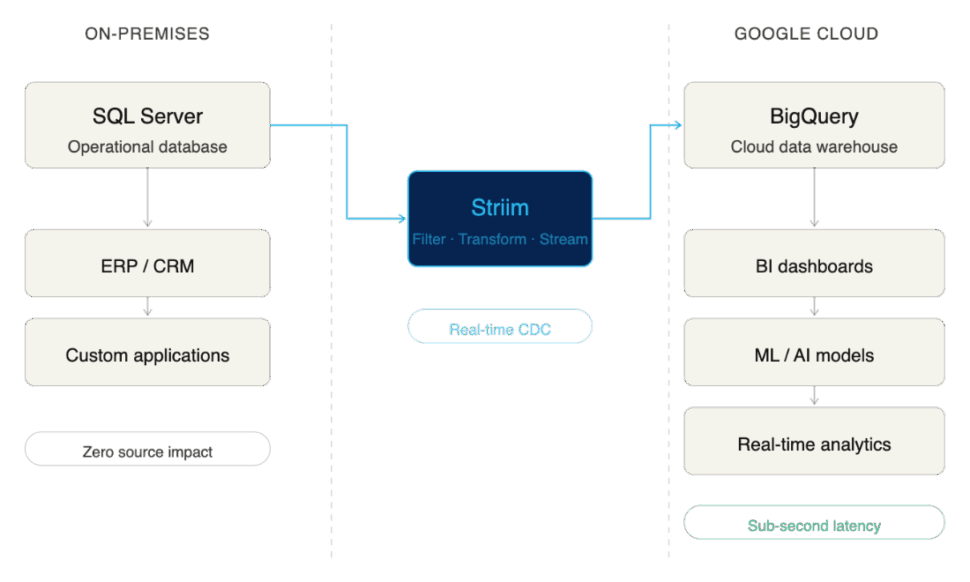
Here are the primary business drivers compelling enterprises to integrate SQL Server with BigQuery:
Unlock Real-Time Analytics Without Replacing SQL Server
Migrating away from a legacy operational database is often a multi-year, high-risk endeavor. By choosing integration over migration, enterprises get the “reward” of modern analytics in a fraction of the time, without disrupting the business. You land with the best of both worlds: the operational stability of SQL Server and the elastic, real-time analytical power of BigQuery.
Support Business Intelligence and Machine Learning in BigQuery
SQL Server is adept at handling high-volume transactional workloads (OLTP). However, it wasn’t built to train AI models or run complex, historical business intelligence queries (OLAP) without severe performance degradation. BigQuery is purpose-built for this exact scale. By replicating your SQL Server data to BigQuery, you give your data science and BI teams the context-rich, unified environment they need to do their best work without bogging down your production databases.
Reduce Reliance on Batch ETL Jobs
Historically, moving data from SQL Server to a data warehouse meant relying on scheduled, batch ETL (Extract, Transform, Load) jobs that ran overnight. But a fast-paced enterprise can’t rely on stale data. Integrating these systems modernizes your pipeline, allowing you to move away from rigid batch windows and toward continuous, real-time data flows.
Common Approaches to SQL Server-BigQuery Integration
Moving data from SQL Server to BigQuery is not a one-size-fits-all endeavor. The method you choose fundamentally impacts the freshness of your data, the strain on your source systems, and the ongoing operational overhead for your data engineering team.
While there are multiple ways to connect the two systems, they generally fall into three categories. Here is a quick comparison:
| Integration Method | Integration Method | Integration Method | Integration Method | Integration Method | Integration Method | Integration Method |
| Batch / Manual | Days / Hours | Low | High (Manual intervention) | Very Low | Low upfront, high hidden costs | Poor. Best for one-off ad-hoc exports. |
| ETL / ELT | Hours / Minutes | Medium | Medium (Managing schedules/scripts) | Medium | Moderate | Fair. Good for legacy reporting, bad for real-time AI. |
| Real-Time CDC | Sub-second | Medium to High (Depending on tool) | Low (Fully automated, continuous) | Very High | Highly efficient at scale | Excellent. The gold standard for modern data architectures. |
Let’s break down these approaches and explore their pros and cons.
Batch Exports and Manual Jobs
The most basic method of integration is the manual export. This usually involves running a query on SQL Server, dumping the results into a flat file (like a CSV or JSON), moving that file to Google Cloud Storage, and finally loading it into BigQuery using the bq command-line tool or console.
- Pros: It’s incredibly simple to understand and requires virtually no specialized infrastructure.
- Cons: Painfully slow, highly prone to human error, and completely unscalable for enterprise workloads. This method can’t handle schema changes, and by the time the data lands in BigQuery, it is already stale.
ETL and ELT Pipelines
Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) have been the industry standard for decades. Using custom scripts or platforms like Google Cloud Data Fusion or SQL Server Integration Services (SSIS), data engineers automate the extraction of data from SQL Server, apply necessary transformations, and load it into BigQuery.
- Pros: Highly automated and capable of handling complex data transformations before or after the data hits BigQuery.
- Cons: ETL and ELT pipelines traditionally run on schedules (e.g., nightly or hourly). These frequent, heavy queries can put significant performance strain on the source SQL Server database. More importantly, because they rely on batch windows, they cannot deliver the true real-time data required for modern, event-driven business operations.
Real-Time Replication with Change Data Capture (CDC)
For modern enterprises, real-time replication powered by Change Data Capture (CDC) has emerged as the clear gold standard.
Instead of querying the database directly for changes, CDC works by reading SQL Server’s transaction logs. As inserts, updates, and deletes happen in the source system, CDC captures those discrete events and streams them continuously into BigQuery.
- Pros: CDC delivers sub-second latency, ensuring BigQuery is an always-accurate reflection of your operational data. Because it reads logs rather than querying tables, it exerts almost zero impact on SQL Server’s production performance. It is continuous, resilient, and built to scale alongside your business.
- Cons: Building a CDC pipeline from scratch is highly complex and requires deep engineering expertise to maintain transaction consistency and handle schema evolution. (This is why enterprises typically rely on purpose-built CDC integration platforms rather than DIY solutions).
Challenges of SQL Server to BigQuery Replication
While continuous CDC replication is the gold standard, executing it across enterprise environments comes with its own set of complexities.
Here are some of the primary challenges enterprises face when connecting SQL Server to BigQuery, and the risks associated with failing to address them.
Managing Schema and Data Type Differences
SQL Server and Google BigQuery use fundamentally different architectures and data types. For example, SQL Server’s DATETIME2 or UNIQUEIDENTIFIER types do not have exact 1:1 equivalents in BigQuery without transformation.
If your replication method doesn’t carefully map and convert these schema differences on the fly, you risk severe business consequences. Data can be truncated, rounding errors can occur in financial figures, or records might be rejected by BigQuery entirely. Furthermore, when upstream SQL Server schemas change (e.g., a developer adds a new column to a production table), fragile pipelines break, causing damaging downtime.
Handling High-Volume Transactions at Scale
Enterprise operational databases process millions of rows an hour, often experiencing massive spikes in volume during peak business hours.
Your replication pipeline must be able to handle this throughput using high parallelism without overwhelming the network or suffocating BigQuery’s ingestion APIs. If your architecture bottlenecks during a traffic spike, latency increases exponentially. What should have been real-time analytics suddenly becomes hours old, resulting in stale insights exactly when the business needs them most.
Ensuring Consistency and Accuracy Across Systems
Yes, replication is about moving new data (INSERT statements). But beyond that, to maintain an accurate analytical environment, your pipeline must capture and precisely replicate every UPDATE and DELETE exactly as they occurred in the source database.
Transaction boundaries must be respected so that partial transactions aren’t analyzed before they are complete. If your pipeline drops events, applies them out of order, or fails to properly hard-delete removed records, your target database will drift from your source. Enterprises require exact match confidence between SQL Server and BigQuery; without it, analytical models fail and compliance audits become a nightmare.
Balancing Latency, Performance, and Cost
Achieving true, sub-second latency is immensely powerful, but if managed poorly, it can cause your cloud costs to spiral. For example, streaming every single micro-transaction individually into BigQuery can trigger higher ingestion fees compared to micro-batching.
Enterprises need to balance speed with efficiency. They need the flexibility to stream critical operational events in real-time, while smartly batching less time-sensitive data to optimize Google Cloud costs.
Because of the deep complexity of schema evolution, transaction consistency, and cost-optimization at scale, relying on basic scripts or generic ETL tools often leads to failure. Not every tool is built to solve these specific challenges, which is why enterprises must carefully evaluate their replication architecture.
Best Practices for Enterprise-Grade Replication
Building a custom DIY pipeline might work for a single, low-volume table. But enterprise replication is a different beast entirely. Many organizations learn the hard way that missing key architectural elements leads to failed projects, spiraling cloud costs, or broken dashboards.
To ensure success, your replication strategy should be built on proven best practices. These also serve as excellent criteria when evaluating an enterprise-grade integration platform.
Start With Initial Load, Then Enable Continuous Replication
The standard architectural pattern for replication requires two phases: first, you must perform a bulk initial load of all historical data. Once the target table is seeded, the pipeline must seamlessly transition to CDC to keep the target synced with new transactions. Doing this manually is notoriously difficult and often results in downtime or lost data during the cutover.
- How Striim helps: Striim supports this exact pattern out of the box. It handles the heavy lifting of the one-time historical load and seamlessly transitions into real-time CDC replication, ensuring zero downtime and zero data loss.
Design for High Availability and Failover
Enterprises cannot afford replication downtime. If a network connection blips or a server restarts, your pipeline shouldn’t crash and require a data engineer to manually intervene at 2:00 AM. Your architecture requires built-in fault tolerance, strict checkpoints, and automated retries to keep pipelines inherently resilient.
- How Striim helps: Striim pipelines are architected for high availability. With features like exactly-once processing (E1P) and automatic state recovery, Striim ensures your pipelines meet rigorous business continuity needs without requiring custom engineering.
Secure Pipelines to Meet Compliance Standards
Moving operational data means you are inevitably moving sensitive information. Whether it’s PII, financial records, or healthcare data, regulatory expectations like HIPAA, GDPR, and SOC2 are non-negotiable. Your replication architecture must guarantee end-to-end encryption, granular access controls, and strict auditability.
- How Striim helps: Striim provides enterprise-grade security features by default, so compliance isn’t an afterthought. Data is encrypted in flight, and built-in governance features ensure that sensitive customer data can be detected and masked before it ever enters BigQuery.
Monitor, Alert, and Tune for Performance
“Set and forget” is a dangerous mentality for enterprise data infrastructure. To guarantee service-level agreements (SLAs) and maintain operational efficiency, you need continuous observability. This means actively tracking metrics, retaining logs, and configuring alerts so your team is proactively notified of latency spikes or throughput drops.
- How Striim helps: Striim features a comprehensive, real-time monitoring dashboard. It makes it effortless for engineering teams to track pipeline health, monitor sub-second latency, and visualize throughput in one centralized place.
Optimize BigQuery Usage for Cost Efficiency
Real-time replication is valuable, but inefficient streaming can drive up BigQuery compute and ingestion costs unnecessarily. To maintain cost efficiency, data engineering teams should leverage BigQuery best practices like table partitioning and clustering, while intelligently tuning batch sizes based on the urgency of the data.
- How Striim helps: Striim’s pre-built BigQuery writer includes highly configurable write strategies. Teams can easily toggle between continuous streaming and micro-batching, helping enterprises perfectly balance high-performance requirements with cloud cost efficiency.
Why Enterprises Choose Striim for SQL Server to BigQuery Integration
Striim is purpose-built to solve the complexities of enterprise data integration. By leveraging Striim, organizations can reliably replicate SQL Server data into Google BigQuery in real time, securely, and at scale. This allows data leaders to confidently modernize their analytics stack without disrupting the critical operational systems their business relies on.
Striim delivers on this promise through a robust, enterprise-grade feature set:
- Log-Based CDC for SQL Server: Striim reads directly from SQL Server transaction logs, capturing inserts, updates, and deletes with sub-second latency while exerting virtually zero impact on your production database performance.
- Configurable BigQuery Writer: Optimize for both speed and cost. Striim’s pre-built BigQuery target allows teams to configure precise batching or streaming modes, ensuring efficient resource utilization in Google Cloud.
- Inherent High Availability: Designed for mission-critical workloads, Striim includes automated failover, exactly-once processing (E1P), and state recovery to ensure absolute business continuity during replication.
- Enterprise-Grade Security: Compliance is built-in, not bolted on. Striim ensures data is protected with end-to-end encryption, granular role-based access controls, and features designed to meet strict HIPAA, GDPR, and SOC2 standards.
- Comprehensive Real-Time Monitoring: Data engineering teams are empowered by unified dashboards that track replication health, monitor latency metrics, aggregate logs, and trigger alerts to ensure you consistently meet stringent internal SLAs.
- Accessible Yet Advanced Configuration: Striim pairs a rapid, no-code, drag-and-drop user interface for quick pipeline creation with advanced, code-level configuration options to solve the most complex enterprise data transformation use cases.
Ready to break down your data silos? Try Striim for free or book a demo today to see real-time replication in action.
FAQs
What are the cost considerations when replicating SQL Server data into BigQuery?
The primary costs involve the compute resources required for extraction (usually minimal with log-based CDC) and the ingestion/storage fees on the BigQuery side. Streaming data record-by-record into BigQuery can trigger higher streaming insert fees. To optimize costs, enterprises should use a replication tool that allows for intelligent micro-batching and leverages BigQuery partitioning strategies.
How do enterprises keep replication secure and compliant?
To maintain compliance with frameworks like SOC2 or HIPAA, enterprises must ensure data is encrypted both in transit and at rest during the replication process. It is also critical to use platforms that offer role-based access control (RBAC) and data masking capabilities, ensuring sensitive PII is obscured before it ever lands in the cloud data warehouse.
How does replication impact day-to-day operations in SQL Server?
If you use traditional query-based ETL methods, replication can cause significant performance degradation on the SQL Server, slowing down the applications that rely on it. However, modern Change Data Capture (CDC) replication reads the database’s transaction logs rather than querying the tables directly. This approach exerts virtually zero impact on the source database, keeping day-to-day operations running smoothly.
What is the best way to scale SQL Server to BigQuery replication as data volumes grow?
The most effective way to scale is by utilizing a distributed, cloud-native integration platform designed for high parallelism. As transaction volumes from SQL Server spike, the replication architecture must be able to dynamically allocate compute resources to process the stream without bottlenecking. Ensuring your target writer is optimized for BigQuery’s bulk ingestion APIs is also crucial for handling massive growth.
How do I replicate SQL Server to BigQuery using Striim?
Replicating data with Striim is designed to be straightforward. You start by configuring SQL Server as your source using Striim’s CDC reader, which manages the initial historical load. Next, you select BigQuery as your target, mapping your schemas and applying any necessary in-flight transformations via the drag-and-drop UI. Finally, you deploy the pipeline, and Striim seamlessly transitions from the initial load into continuous, real-time replication.
What makes Striim different from other SQL Server to BigQuery replication tools?
Unlike basic data movement scripts or legacy batch ETL tools, Striim is a unified integration and intelligence platform built specifically for real-time, enterprise-grade workloads. It goes beyond simple replication by offering in-flight data processing, exactly-once processing (E1P) guarantees, and built-in AI governance capabilities. This ensures data isn’t just moved, but arrives in BigQuery validated, secure, and ready for immediate analytical use.
How can I test Striim for SQL Server to BigQuery replication before rolling it out company-wide?
The best approach is to start with a targeted pilot project. Identify a single, high-value SQL Server database and set up a Striim pipeline to replicate a subset of non-sensitive data into a sandbox BigQuery environment. You can leverage Striim’s free trial to validate the sub-second latency, test the monitoring dashboards, and confirm the platform meets your specific enterprise requirements before a full-scale rollout.
Real-Time Data: What It Is, Why It Matters, and How to Architect It

Most enterprise data is stale before anyone acts on it. Batch pipelines run overnight, dump the information into a warehouse, and teams analyze it the next day. That approach was perfectly fine when business moved at the speed of weekly reports. Today, it’s no longer enough.
When your customer profile updates after the buyer has left your site, you’ve missed the window for personalization. When your fraud detection runs on data that’s six hours old, you aren’t preventing fraud. You’re just documenting it. Legacy batch workflows and siloed systems trap your most valuable assets in the past, leaving you to react to history rather than shape the present.
Real-time data is no longer a luxury. It’s a foundational requirement for scaling AI, meeting modern customer expectations, and driving agile operations. With cloud adoption accelerating, IoT networks expanding, and AI systems demanding massive volumes of fresh context to function properly, the pressure to modernize is intense.
The market has already recognized this reality. According to McKinsey, 92% of business leaders plan to increase investment in real-time data analytics in the near future. The mandate is clear: enterprises must move from historical reporting to instant intelligence.
To help you navigate this transition, we’ll break down exactly what real-time data is, how modern streaming architectures work, and what you need to look for when evaluating a platform to power it.
What Is Real-Time Data?
At its core, real-time data is information that is captured, processed, and made available for action within milliseconds or seconds of being generated.
But “fast” is only half the equation. The true definition of real-time data hinges on its actionability. It’s the difference between reading a report about a spike in fraudulent transactions from yesterday, and automatically blocking a fraudulent transaction the moment a credit card is swiped. Real-time data is the foundational fuel for live decision-making, automated operations, and in-the-moment personalization at enterprise scale.
To understand how this data flows through an organization, it can be helpful to distinguish between two common types:
- Event data: These are discrete, specific actions or state changes. Examples include a customer placing an order, a database record being updated, or a user clicking “Add to Cart.”
- Stream data: This is a continuous, unending flow of information. Examples include IoT sensor readings from a jet engine, ongoing server log outputs, or live financial market tickers.
Capitalizing on both event and stream data requires a shift away from traditional request-response setups toward an event-driven architecture. Instead of downstream systems (like analytics dashboards, machine learning models, or operational applications) constantly asking your database, “anything new here?”, event-driven architectures automatically push the data forward the instant an event occurs.
Common Misconceptions About Real-Time Data
Because “real-time” is a highly sought-after capability, the term has been heavily diluted in the market. Many legacy architectures have been rebranded as real-time, but under the hood, they fail to deliver true immediacy.
Let’s clear up a few common misconceptions:
- Scheduled batch jobs running every 5–15 minutes: Shrinking your batch window is not the same as streaming. Micro-batching might feel faster for daily reporting, but 15 minutes is still a lifetime when you are trying to power dynamic pricing, live customer support agents, or fraud detection.
- Polling-based updates labeled as “event-driven”: If your architecture relies on constantly querying a source database to check for new records, it’s inherently delayed. Worse still, polling puts a massive, unnecessary compute strain on your source systems.
- CDC-only pipelines with no transformation guarantees: Change Data Capture (CDC) is a powerful way to ingest data, but simply moving raw database logs from Point A to Point B isn’t enough. If your pipeline lacks the ability to filter, enrich, and transform that data in motion, you’re not delivering decision-ready context, you’re just shifting the processing bottleneck to your target data warehouse.
If your data is delayed, duplicated, or depends on polling, your system isn’t real-time. It’s just fast batch.
Why Real-Time Data Matters
Today, enterprises are moving beyond batch processing because the window to act on data has vanished. Users, customers, and automated systems don’t wait for nightly ETL jobs to finish. They demand immediacy.
Real-time data powers much more than a faster BI dashboard. It is the connective tissue for smarter AI, frictionless customer experiences, and instant operational decisions.
For executive leadership, this is no longer just a data engineering concern—it is a strategic capability. Real-time data accelerates time-to-decision, slashes operational risk, and serves as the non-negotiable foundation for AI and automation at scale.
Here is how real-time data translates into tangible business benefits:
Use Case |
Business Benefit |
| Fraud detection in financial apps | Stop threats before they cause financial damage, rather than tracking losses post-incident. |
| Live personalization in retail | Improve conversion rates and Customer Lifetime Value (CLTV) by recommending products while the buyer is actively browsing. |
| Real-time supply chain tracking | Optimize logistics, dynamically reroute shipments, and reduce costly downtime. |
| AI model feedback loops | Improve model accuracy and reduce drift instantly by feeding AI fresh, context-rich data streams. |
| Predictive maintenance for IoT | Minimize equipment failures by detecting anomalies in sensor data before a breakdown occurs. |
How Modern Real-Time Data Architectures Work
Understanding the value of real-time data is one thing; but architecting a system to deliver it is no mean feat. At its best, real-time architectures function a bit like an intelligent nervous system, capturing changes instantly, processing them in motion, and routing the exact right context to the systems that need it.
To see how this works in practice, let’s walk through the lifecycle of a real-time data pipeline, from the moment an event occurs to the moment it drives a business outcome.

Data Ingestion and Change Data Capture (CDC)
The first step is capturing the data the instant it is created. In legacy batch systems, this usually meant running heavy queries against operational databases, which drained compute resources and slowed down applications.
Ideally this is avoided through the use of Change Data Capture (CDC). CDC is a non-intrusive method that reads a database’s transaction logs silently in the background. Whether a customer updates their address or a new order is placed, CDC captures that exact change in milliseconds without impacting the performance of your source systems (like Oracle, PostgreSQL, or SQL Server).
Beyond databases, a robust ingestion layer also continuously streams event data from APIs, application logs, and IoT sensors across complex hybrid and multi-cloud environments.
In-Stream Processing, Transformation, and Enrichment
Ingesting data in real time is useless if data is simply dumped, raw and unformatted into a data warehouse. To make data decision-ready, it must be processed in motion.
Instead of waiting for data to land before cleaning it, modern stream processing engines allow you to filter, aggregate, and enrich the data while it is still in the pipeline. For example, a streaming pipeline can instantly join a live transaction event with historical customer data to provide full context to a fraud detection model.
This layer is also critical for enterprise security and governance. With in-stream processing, you can detect and mask sensitive Personally Identifiable Information (PII) before it ever reaches a downstream analytics tool, ensuring strict compliance with regulations like GDPR or HIPAA without slowing down the pipeline.
Delivery to Analytics, AI/ML, and Operational Systems
Once the data is captured, cleaned, and enriched, it must be delivered to its final destination, often simultaneously to multiple targets.
A modern architecture routes this continuous flow of high-quality data into cloud data warehouses and data lakes (such as Snowflake, Databricks, or Google BigQuery) for immediate analytics. Simultaneously, it can feed directly into live operational applications, BI dashboards, or machine learning models, creating the real-time feedback loops required for agentic AI and automated decision-making.
Key Components of a Real-Time Data Architecture
Real-time data systems rely on multiple interconnected layers to function reliably. Because these architectures demand constant uptime, high throughput, and fault tolerance, they can be incredibly complex to build and maintain from scratch. Attempting to stitch together open-source tools for each layer often results in a fragile “Franken-stack” that requires a dedicated team just to keep it running.
Effective architecture streamlines these layers into an integrated approach. Here are some of the foundational components that make it work:
Source Systems and Connectors
Your architecture is only as good as its ability to integrate with where your data lives. This requires robust, pre-built connectors that can ingest data continuously from a wide variety of sources, including:
- Operational databases (Oracle, PostgreSQL, SQL Server, MySQL)
- Message queues (Apache Kafka, RabbitMQ)
- Cloud services and enterprise applications (Salesforce, SAP)
- IoT devices and edge sensors
Crucially, these connectors must support hybrid and multi-cloud ingestion. A modern pipeline needs to be able to seamlessly read a transaction from an on-prem Oracle database, process it, and securely deliver it to Snowflake in AWS, without missing a beat.
Stream Processing Engines and Frameworks
This is the brain of the operation, where raw streams are transformed into valuable insights. Advanced stream processing relies on core concepts like:
- Event time vs. processing time: Understanding whether an event is processed based on when it actually occurred in the real world versus when it hit the system.
- Windowing: Grouping continuous streams of data into logical time buckets (e.g., aggregating all clicks in a 5-minute window).
- Exactly-once semantics (E1P): Guaranteeing that no matter what happens (e.g., a network failure), every single event is processed once and only once—preventing data duplication or loss.
While frameworks like Apache Flink or Kafka Streams are powerful, they often require writing complex custom code in Java or Scala. Striim takes a more approachable, developer-friendly route: offering integrated processing with a familiar streaming SQL interface. This allows data engineers to build and deploy complex transformations in minutes, completely bypassing the need for highly specialized, custom-coded pipelines.
Targets: Data Warehouses, Data Lakes, and Applications
Once processed, data needs to land where it can drive value. High-performance connectors must instantly route data to popular analytical destinations like Snowflake, Databricks, and Google BigQuery.
But real-time architecture isn’t just about feeding analytics. It’s also about reverse-engineering that value back into operations. By streaming enriched data into operational databases (like PostgreSQL) or directly into applications, you enable real-time alerts, instant UX updates, and the continuous feedback loops necessary to keep AI models accurate and relevant.
Supporting Tools: Monitoring, Governance, and Compliance
In a real-time environment, you cannot afford to find out about a broken pipeline tomorrow. You need comprehensive supporting tools to track data flow health, pipeline performance, and schema evolution (e.g., what happens if a column name changes in the source database?).
Governance is essential, especially for ML and AI pipelines consuming sensitive customer data.
This is why patching together separate tools is risky. Striim mitigates this by offering a unified platform with native connectors, in-flight transformation logic, and enterprise-grade observability built directly into the system. You get continuous visibility, access control, and audit logging out of the box, ensuring your pipelines remain performant, secure, and compliant.
Challenges of Working with Real-Time Data
Real-time data promises unparalleled speed and agility, but executing it well requires careful planning and the right tooling. Moving data in milliseconds across distributed systems introduces a host of engineering hurdles that batch processing simply doesn’t face.
Let’s look at the most common challenges teams encounter, and what it takes to overcome them.
Latency, Consistency, and Fault Tolerance
When building streaming pipelines, terms like “speed” aren’t specific enough. Teams must manage three distinct metrics:
- Processing latency: How fast the engine executes transformations.
- End-to-end latency: The total time it takes a record to travel from the source database to the target application.
- Throughput: The volume of data the system can handle over a given time period.
Ensuring high throughput with low end-to-end latency is difficult, especially when you factor in the need for consistency. When networks partition or target systems experience downtime, how do you prevent data loss or duplication? Striim addresses this through a fault-tolerant architecture that relies on automated checkpointing and robust retry mechanisms, ensuring exactly-once processing (E1P) even during system failures.
Data Quality, Governance, and Observability
A broken pipeline will trigger an alert, but a functioning pipeline that silently delivers bad data has the potential to quietly destroy your analytics applications and AI models.
Real-time data is highly susceptible to issues like schema drift (e.g., an upstream developer drops a column from an Oracle database), duplicate events, and missing context. Ensuring data contracts are upheld in motion is critical. Striim’s comprehensive observability features, including inline validation and rich data lineage, act as an active governance layer. They help you troubleshoot bottlenecks, validate payloads, and prevent bad data from propagating downstream.
Integration Complexity and Operational Overhead
The biggest hidden cost of a real-time initiative is the DIY “Franken-stack.” Piecing together standalone open-source tools for CDC, message brokering, stream processing, and data delivery (e.g., Debezium + Kafka + Flink + Airflow) creates massive operational overhead.
These fragmented architectures demand highly specialized engineering talent just to keep the lights on. Striim drastically reduces this integration burden through an all-in-one platform approach. By providing pre-built templates, an intuitive UI-based configuration, and automated recovery, Striim ensures your engineers spend their time building high-value business use cases, rather than babysitting infrastructure.
Best Practice Tips to Maximize the Value of Real-Time Data
Transitioning from batch to streaming is a significant architectural shift. Unfortunately, many data teams struggle to scale their real-time efforts due to poor upfront planning, tool sprawl, and a lack of clear business goals.
Drawing from our experience deploying Striim across Fortune 500 companies, here are three proven best practices to ensure your real-time initiatives deliver maximum value without overwhelming your engineering teams.
Start with High-Impact Use Cases
When adopting real-time data, it’s tempting to try and migrate every historical batch job at once. Don’t boil the ocean. Instead, identify workflows that genuinely require and benefit from sub-second updates—such as fraud alerts, live customer journeys, or continuous AI pipelines.
Start by implementing one critical, high-visibility pipeline. For example, leading retailers like Macy’s rely on Striim to process high-volume transaction data in real time, dramatically optimizing inventory management and customer experiences. By proving value quickly on a targeted use case, you build organizational trust and momentum for broader adoption.

Design for Scale and Resilience Early
A pipeline that works perfectly for 1,000 events per second might completely collapse at 100,000. When architecting your system, plan for high event volume, failover, and schema evolution from day one.
Relying on manual load balancing or bespoke scripts for recovery will inevitably lead to downtime. Instead, lean on a platform with built-in scalability and automated retry logic. Striim is designed to handle bursty, unpredictable workloads dynamically, automatically managing load distribution and micro-batching where appropriate so your system remains resilient even under massive traffic spikes.
Use a Unified Real-Time Data Platform
The instinct for many engineering teams is to build their own streaming stack using a collection of specialized open-source tools—for instance, combining Debezium for CDC, Kafka for message brokering, Flink for transformation, and Airflow for orchestration.
While these are powerful tools individually, stitching them together creates a fragile infrastructure with massive maintenance overhead and painstakingly slow time to value. A unified real-time data platform like Striim eliminates this complexity. By consolidating ingestion, transformation, and delivery into a single, cohesive environment, you drastically reduce your integration burden, ensure consistent governance, and benefit from built-in monitoring—allowing your team to focus on building high-value products, not maintaining data plumbing.
How to Evaluate a Real-Time Data Platform
To evaluate a real-time data platform, you must rigorously assess its ability to provide true sub-second latency, native CDC, in-stream transformation capabilities, multi-cloud flexibility, and built-in enterprise governance.
The data tooling landscape is crowded, and many vendors have simply rebranded legacy or micro-batch workflows as “real-time.” Selecting the wrong architecture introduces massive hidden risks: delayed insights, operational outages, eroded data quality, and mounting integration overhead.
To separate the platforms built for true streaming from optimized batch in disguise, use these buyer questions to guide your evaluation:
Performance, Scalability, and Latency Guarantees
Can your existing platform maintain consistent sub-second latency and high throughput under unpredictable, bursty workloads?
Many retrofitted systems degrade under heavy load or force your teams to batch data to stabilize performance, breaking the real-time promise entirely. Your platform must handle high volumes gracefully. For example, Striim’s architecture consistently delivers predictable latency, achieving sub-2-second end-to-end delivery even at massive enterprise scales of 160 GB per hour.
Stream-First Architecture and CDC Support
Is the system truly event-driven, or does it rely on polling or micro-batching under the hood?
A true real-time architecture begins with native CDC ingestion, not staged pipelines or scheduled extraction jobs. You need a platform that reads transaction logs directly. Look for a solution that can capture changes from mission-critical systems like Oracle, SQL Server, and PostgreSQL while they are in motion, with absolutely zero disruption or compute strain on the source databases.
Built-In Transformation and SQL-Based Analytics
Can your team enrich and transform data as it flows, or are you forced to stitch together standalone tools like Flink, dbt, and Airflow?
Batch-based post-processing is too late for modern use cases like live personalization or fraud detection. In-stream transformation is a strict requirement. To avoid heavy engineering overhead, prioritize platforms like Striim that leverage a familiar, SQL-based interface. This allows teams to filter, mask, and enrich data in motion without writing bespoke, complex Java or Scala code.
Cloud-Native, Hybrid, and Multi-Cloud Support
Does the platform adapt to your existing architecture, or does it force a rip-and-replace migration?
A modern real-time data platform should provide seamless data movement across cloud and on-prem systems. This is especially critical for enterprise teams operating across global regions or undergoing gradual cloud modernizations. Striim deployments natively span AWS, Azure, GCP, and hybrid environments, ensuring data flows without any tradeoffs in latency or system resilience.
Monitoring, Security, and Compliance Readiness
Does your stack provide continuous visibility and control?
Without comprehensive observability, silent failures, undetected data loss, and compliance gaps are inevitable. DIY data stacks rarely include built-in governance features, which introduces massive audit risks and model drift for AI applications. Effective real-time platforms must provide real-time observability, granular role-based access control (RBAC), in-flight encryption, and audit logging—features that are non-negotiable for industries like financial services and healthcare.
Why Leading Companies Choose Striim
Real-time data is the baseline for the next generation of enterprise AI and operational agility. However, achieving it shouldn’t require your engineering teams to manage fragile, disjointed infrastructure.
Striim is the only unified Integration and Intelligence platform that offers real-time ingestion, processing, transformation, and delivery in a single, cohesive environment. Built as a streaming-first architecture, Striim eliminates the complexity of DIY data pipelines by providing sub-second CDC, intuitive SQL-based transformation logic, cloud-native scale, and enterprise-grade observability straight out of the box.
Leading enterprises rely on Striim to turn their data from a historical record into a live, competitive advantage. Companies like American Airlines and UPS Capital use Striim to power their most critical operations, reducing latency from hours to milliseconds, optimizing logistics, and unlocking entirely new revenue streams.
Ready to see the difference a unified real-time data platform can make for your architecture?
Get started for free or book a demo today to explore Striim with one of our streaming data experts.
Data Modernization Tools: Top Platforms for Real‑Time Data
The enterprise AI landscape has moved into execution mode. Today, data leaders face urgent board-level pressure to deliver measurable AI outcomes, and to do it fast.
But there remains a fundamental disconnect. For all their ambition, enterprise leaders cannot power modern, agentic AI systems with batch-processed data that’s hours or even days old. Legacy pipelines and fragmented data silos aren’t just an IT inconvenience; they are actively bottlenecking advanced analytics and AI initiatives. Models trained on stale, unvalidated data provide unreliable insights at best, and financially damaging outcomes at worst.
Turning data from a static liability into a dynamic asset requires platform modernization: a shift in approach to how data is moved, validated, and stored. This requires systems capable of capturing data the instant it’s born, processing it mid-flight, and landing it safely in modern cloud environments.
In this guide, we break down the leading data modernization tools into two core categories: platforms that move and validate data (such as Striim, Oracle GoldenGate, and Confluent) and platforms that store and manage data (such as Databricks, Snowflake, and BigQuery). We will compare their features, pricing models, and ideal use cases to help you build a real-time data foundation you can trust.
Key Takeaways
- Data modernization tools fall into two main categories: platforms that move and validate data (e.g., Striim, Confluent, Fivetran HVR) and platforms that store and manage data (e.g., Databricks, Snowflake, BigQuery).
- The most effective modernization strategies pair a real-time data movement and validation layer with modern cloud storage so analytics, AI, and reporting are continuously fed with accurate, up-to-date data.
- When evaluating tools, it’s critical to look beyond basic migration. Prioritize real-time capabilities (CDC), breadth of connectors, in-flight governance and validation, scalability, and total cost of ownership.
- Striim stands out by combining high-performance CDC, streaming, and Validata-powered data validation to ensure that data arriving at your destination is both sub-second fast and completely trustworthy.
- Choosing the right mix of data movement and storage tools helps organizations modernize faster, reduce risk from data drift, and unlock high-impact agentic AI use cases.
What are Data Modernization Tools?
Data modernization tools are the foundational infrastructure used to move an enterprise from legacy, batch-based data processing to unified, real-time data architectures. They act as the bridge between siloed operational databases and modern cloud platforms.
Instead of relying on nightly ETL (Extract, Transform, Load) batch jobs that leave your analytics and AI models running on yesterday’s information, modern tools continuously capture, process, and deliver data the instant it is born.
Broadly, these tools fall into two distinct but complementary categories:
- Data Movement and Validation (The Pipeline): Platforms like Striim, Confluent, and Oracle GoldenGate capture data at the source, transform it mid-flight, and validate its accuracy before it ever lands in a database.
- Data Storage and Management (The Destination): Platforms like Databricks, Snowflake, and Google BigQuery provide the highly scalable, cloud-native environments where data is stored, queried, and used to power machine learning models.
Benefits of Data Modernization Tools
Legacy batch pipelines create data latency measured in hours or days. This is no longer acceptable when modern fraud detection, dynamic pricing, and agentic AI models require sub-second freshness and guaranteed consistency.
Here’s what enterprise-grade data modernization platforms deliver:
1. Breaking Down Data Silos
When internal teams isolate data sources, critical business decisions get stalled. Data modernization tools democratize data management by unifying disparate systems. Using Change Data Capture (CDC) and streaming architecture, these platforms break down data silos and make real-time intelligence accessible across the entire enterprise.
2. Powering Agentic AI and Machine Learning
You can’t build autonomous, agentic AI systems based on stale data. To be effective, AI needs real-time context. Modernization platforms feed your LLMs, feature stores, and vector databases with continuous, fresh data. This is what allows enterprises to move their AI initiatives out of the pilot phase and into production-grade execution.
3. Unlocking Sub-Second, Operational Decisions
Eliminate the latency of batch processing. Event-driven architectures support sub-second data freshness for dynamic pricing engines, real-time recommendation systems, and operational ML models. This enables your business to capitalize on fleeting market opportunities and respond to customer behavior in the moment.
4. Ensuring In-Flight Governance and Compliance
Modern tools don’t just move data; they ensure it’s trustworthy and can be put to good use the moment it’s born. Enterprise-grade platforms implement data validation at scale, providing row-level reconciliation, drift detection, and automated quality checks mid-flight. This prevents costly downstream failures while ensuring your data pipelines comply with SOC 2, GDPR, and HIPAA frameworks.
Top 5 Data Modernization Tools for Data Integration and Streaming
If you’re modernizing your data architecture, your first priority is the pipeline: extracting data from legacy systems and delivering it to cloud destinations without introducing latency or corruption.
The following five platforms represent the leading solutions for real-time data movement, change data capture, and in-flight processing.
1. Striim

Striim is a unified integration and intelligence platform that connects clouds, data, and applications through real-time data streaming. Designed to process over 100 billion events daily with sub-second latency, Striim embeds intelligence directly into the data pipeline, allowing organizations to operationalize AI at enterprise scale.
Key Products and Features
- Real-Time Change Data Capture (CDC): Captures database changes the instant they occur and streams them to target destinations, maintaining continuous synchronization with exactly-once processing (E1P) and zero impact on source systems.
- Validata (Continuous Data Validation): Embeds trust into high-velocity data flows. Validata compares datasets at scale with minimal database load, identifying discrepancies and ensuring data accuracy for compliance-heavy operations (HIPAA, PCI) and model training.
- In-Flight Stream Processing: Provides in-memory, SQL-based transformations, allowing users to filter, enrich, and format data while it is in motion.
- AI-Native Functionality: Embeds intelligence directly into the stream. Striim enables AI agents to generate vector embeddings, detect anomalies in real time, and govern sensitive data before it reaches the destination.
- 150+ Pre-Built Connectors: Seamlessly integrates legacy databases, modern cloud data warehouses, and messaging systems out of the box.
Key Use Cases
- Agentic AI & ML Data Foundations: Provides continuous, cleansed replicas of data in safe, compliant zones so AI models and intelligent agents get fresh context without exposing production systems.
- Real-Time Fraud Detection: Analyzes high-velocity transactional data from multiple sources to identify suspicious patterns and trigger instant alerts before financial loss occurs.
- Zero-Downtime Cloud Migration: Striim’s CDC and Validata combination provides end-to-end visibility into data accuracy during system transitions, enabling seamless cutovers to modern cloud infrastructure.
Pricing Striim scales from free experimentation to mission-critical enterprise deployments:
- Striim Developer (Free): For learning and prototypes. Includes up to 25M events/month and trial access to connectors.
- Striim Community (Free, Serverless): A no-cost sandbox to validate early PoCs.
- Serverless Striim Cloud: Fully managed SaaS with elastic scale. Usage-based pricing on metered credits.
- Dedicated Cloud / Striim Platform: Custom pricing for private cloud or self-hosted deployments requiring maximum control.
Who It’s Ideal For Striim is built for enterprise organizations (Healthcare, Financial Services, Retail, Telecommunications) that require sub-second data delivery, robust compliance, and embedded data validation to power operational efficiency and real-time AI initiatives. Pros
- Unmatched Speed: True sub-second, real-time data processing for time-critical applications.
- Built-in Trust: The Validata feature ensures data integrity and audit readiness natively within the pipeline.
- AI-Ready: Goes beyond basic ETL by generating vector embeddings and governing data mid-flight.
- Ease of Use: Intuitive, SQL-based interface and automated schema evolution speed up deployment.
Cons
- Learning Curve: While SQL-based, mastering advanced stream processing architectures can take time.
- Enterprise Focus: Built for enterprise scale: Striim may not be an ideal fit with mid-sized or small companies.
2. Oracle GoldenGate
Oracle GoldenGate is a legacy giant in the data replication space. It’s a data comparison and verification tool that identifies discrepancies between source and target datasets, heavily optimized for the Oracle ecosystem.
Key Products and Features
- GoldenGate Core Platform: Enables unidirectional and bidirectional replication with support for complex topologies.
- Oracle Cloud Infrastructure (OCI) GoldenGate: A fully managed, cloud-based service for orchestrating replication tasks.
- Oracle GoldenGate Veridata: Compares source and target datasets to identify discrepancies concurrently with data replication.
Key Use Cases
- Disaster Recovery: Maintains synchronized copies of critical data across locations for business continuity.
- Zero Downtime Migration: Facilitates slow, gradual cutovers between legacy systems and new databases without disrupting business operations.
Pricing
- Pricing varies heavily by region and deployment. OCI lists GoldenGate at approximately $1.3441 per OCPU hour, but enterprise agreements are notoriously complex.
Who It’s Ideal For Large enterprises already deeply entrenched in the Oracle ecosystem that need high-fidelity replication across mission-critical, traditional databases. Pros
- Reliability: Highly stable in large scale production environments.
- Oracle Native: Strong performance when replicating from Oracle to Oracle.
Cons
- Cost and Complexity: Expensive licensing models and massive resource consumption.
- Steep Learning Curve: Requires highly specialized, hard-to-find technical expertise to configure, tune, and maintain.
3. Qlik (Talend / Qlik Replicate)

Following its acquisition of Talend, Qlik has positioned itself as a broad data integration and analytics platform. It offers a wide suite of tools for data movement, governance, and business intelligence dashboards.
Key Products and Features
- Qlik Replicate: Provides real-time synchronization using log-based CDC for operational data movement.
- Talend Data Fabric: Unifies, integrates, and governs disparate data environments.
- Qlik Cloud Analytics: AI-powered dashboards and visualizations for business users.
Key Use Cases
- Data Pipeline Automation: Automates the lifecycle of data mart creation.
- Multi-Cloud Data Movement: Facilitates data transfer between SaaS applications, legacy systems, and modern lakehouses.
Pricing
- Qlik operates on complex, tiered pricing. Cloud Analytics starts at $200/month for small teams, scaling to custom enterprise pricing. Data integration features (Qlik Replicate/Talend) require custom enterprise quoting.
Who It’s Ideal For Medium-to-large enterprises looking for an all-in-one suite that handles both the data engineering pipeline (Talend) and the front-end business intelligence visualizations (Qlik Analytics). Pros
- Broad Ecosystem: Offers everything from pipeline creation to front-end dashboarding.
- Connectivity: Strong library of supported endpoints for both legacy and cloud systems.
Cons
- Fragmented Experience: Integrating the legacy Qlik and Talend products can be challenging.
- Dated Interface: Users frequently report that the Java-based UI feels outdated and cumbersome for everyday workflows.
4. Fivetran HVR

While Fivetran is known for its simple, batch-based SaaS product, Fivetran HVR (High-Volume Replicator) is its self-hosted, enterprise-grade offering. HVR uses CDC technology to streamline high-volume replication for complex data architectures.
Key Products and Features
- Log-Based CDC: Captures and replicates database changes for high-volume environments.
- Distributed Architecture: Supports complex remote or local capture options.
- Fivetran Dashboard Integration: Attempts to bring Fivetran’s classic ease-of-use to the HVR infrastructure.
Key Use Cases
- Database Consolidation: Keeping geographically distributed databases synchronized.
- Large-Scale Migrations: Moving massive on-premises workloads to cloud environments like AWS or Azure.
Pricing
- Usage-Based (MAR): Fivetran relies on a Monthly Active Rows (MAR) pricing model. You are charged based on the number of unique rows inserted, updated, or deleted.
Who It’s Ideal For Large enterprises with strict compliance requirements that demand a self-hosted replication environment, and teams already comfortable with Fivetran’s broader ecosystem. Pros
- High Throughput: Capable of handling large data loads.
- Customizable: Granular control over data integration topologies.
Cons
- Unpredictable Costs: The MAR pricing model can lead to massive, unexpected bills, especially during required historical re-syncs or when data volumes spike.
- Complexity: Significantly more difficult to deploy and manage than standard Fivetran.
5. Confluent

Built by the original creators of Apache Kafka, Confluent is a cloud-native data streaming platform. It acts as a central nervous system for enterprise data, enabling teams to build highly scalable, event-driven architectures.
Key Products and Features
- Confluent Cloud: A fully managed, cloud-native Apache Kafka service.
- Confluent Platform: A self-managed distribution of Kafka for on-premises environments.
- Apache Flink Integration: Enables real-time stream processing and data transformation.
Key Use Cases
- Event-Driven Microservices: Building scalable, fault-tolerant messaging between application services.
- Legacy System Decoupling: Acting as an intermediary data access layer between mainframes and modern apps.
Pricing
- Confluent Cloud utilizes a highly granular usage-based model involving eCKU-hours (compute), data transfer fees, and storage costs. Basic tiers start nominally free but scale aggressively into custom Enterprise pricing based on throughput.
Who It’s Ideal For Engineering-heavy organizations building complex, custom microservices architectures that have the technical talent required to manage Kafka-based ecosystems. Pros
- Kafka: A widely popular solution for managed Apache Kafka.
- Scale: Capable of handling high throughput for global applications.
Cons
- Heavy Engineering Lift: Kafka concepts (topics, partitions, offsets) are notoriously difficult to master. It requires specialized engineering talent to maintain.
- Runaway Costs: The granular pricing model (charging for compute, storage, and networking separately) frequently leads to unpredictable and high infrastructure bills at scale.
Top 4 Data Modernization Tools for Storing Data
While pipeline tools extract and move your data, you need a highly scalable destination to query it, build reports, and train models. The following four tools represent the leading solutions for storing and managing data in the cloud. However, it is vital to remember: these platforms are only as powerful as the data feeding them. To unlock real-time analytics and AI, organizations must pair these storage destinations with a high-speed pipeline like Striim.
1. Databricks

Databricks pioneered the “lakehouse” architecture, bringing the reliability of a data warehouse to the massive scalability of a data lake. Built natively around Apache Spark, it is highly favored by data science and machine learning teams.
Key Products and Features
- Data Intelligence Platform: Unifies data warehousing and AI workloads on a single platform.
- Delta Lake: An open-source storage layer that brings ACID transactions and reliability to data lakes.
- Unity Catalog: Centralized data governance and security across all data and AI assets.
- MLflow: End-to-end machine learning lifecycle management, from experimentation to model deployment.
Key Use Cases
- AI and Machine Learning: Building, training, and deploying production-quality ML models.
- Data Engineering: Managing complex ETL/ELT pipelines at a massive scale.
Pricing
- Databricks charges based on “Databricks Units” (DBUs)—a measure of processing capability per hour. Rates vary heavily by tier, cloud provider, and compute type (e.g., standard vs. photon-enabled), plus your underlying cloud infrastructure costs.
Pros
- Unified Lakehouse: Eliminates the need to maintain separate data lakes and warehouses.
- Native AI/ML: Unmatched tooling for data scientists building complex machine learning models.
Cons
- Cost Management: Granular DBU pricing combined with underlying cloud costs can easily spiral out of control without strict governance.
- Steep Learning Curve: Demands strong Spark and data engineering expertise to optimize properly.
2. Snowflake

Snowflake revolutionized the industry with its cloud-native architecture that separated compute from storage. This meant organizations could scale their processing power up or down instantly without worrying about storage limits.
Key Products and Features
- The Data Cloud: A fully managed, serverless infrastructure requiring near-zero manual maintenance.
- Snowpark: Allows developers to execute non-SQL code (Python, Java, Scala) natively within Snowflake.
- Snowflake Cortex: Managed, AI-powered functions to bring LLMs directly to your enterprise data.
- Zero-Copy Cloning: Share live data across teams and external partners without actually moving or duplicating it.
Key Use Cases
- Analytics and BI: High-speed SQL querying for enterprise reporting dashboards.
- Data Monetization: Sharing live data securely with partners via the Snowflake Marketplace.
Pricing
- Snowflake uses a consumption-based model based on “Credits” for compute (ranging from ~$2.00 to $4.00+ per credit based on your edition) and a flat fee for storage (typically around $23 per TB/month).
Pros
- Zero Operational Overhead: Fully managed; no indexes to build, no hardware to provision.
- Concurrency: Automatically scales to handle thousands of concurrent queries without performance degradation.
Cons
- Batch-Oriented Ingestion: While tools like Snowpipe exist, Snowflake is not inherently designed for native, sub-second streaming ingestion without external CDC tools.
- Runaway Compute Costs: If virtual warehouses are left running or queries are poorly optimized, credit consumption can skyrocket.
3. Google BigQuery

Google BigQuery is a fully managed, serverless enterprise data warehouse. It allows organizations to run lightning-fast SQL queries across petabytes of data, seamlessly integrated with Google’s broader AI ecosystem.
Key Products and Features
- Serverless Architecture: Decoupled storage and compute that scales automatically without infrastructure management.
- BigQuery ML: Train and execute machine learning models using standard SQL commands directly where the data lives.
- Gemini Integration: AI-powered agents to assist with pipeline building, natural language querying, and semantic search.
Key Use Cases
- Petabyte-Scale Analytics: Rapid querying of massive datasets for enterprise BI.
- Democratized Data Science: Allowing analysts who only know SQL to build and deploy ML models.
Pricing
- On-Demand: You are charged for the bytes scanned by your queries (approx. $6.25 per TiB).
- Capacity (Slot-Hour): Pre-purchased virtual CPUs for predictable workloads. Storage is billed separately (approx. $0.02 per GB/month for active storage).
Pros
- Massive Scalability: Seamlessly handles petabytes of data without any cluster provisioning.
- Ecosystem Synergy: Perfect integration with Google Cloud tools like Looker and Vertex AI.
Cons
- Pricing Complexity: The “bytes scanned” model means a poorly written query on a massive table can cost hundreds of dollars instantly.
- Schema Tuning Required: Requires careful partitioning and clustering to keep query costs low.
4. Microsoft Azure (Data Ecosystem)

For enterprises deeply invested in the Microsoft stack, modernizing often means moving legacy SQL Server integration workflows into the cloud via Azure Data Factory (ADF) and landing them in Azure Synapse Analytics or Microsoft Fabric.
Key Products and Features
- Azure Data Factory: A fully managed, serverless data integration service with a visual drag-and-drop pipeline builder.
- SSIS Migration: Native execution of existing SQL Server Integration Services (SSIS) packages in the cloud.
- Azure Synapse Analytics: An enterprise analytics service that brings together data integration, enterprise data warehousing, and big data analytics.
Key Use Cases
- Hybrid Cloud Integration: Connecting on-premises SQL databases with cloud SaaS applications.
- Legacy Modernization: Moving off on-premises SSIS infrastructure to a managed cloud environment.
Pricing
- Azure Data Factory utilizes a highly complex, consumption-based pricing model factoring in pipeline orchestration runs, data movement (DIU-hours), and transformation compute (vCore-hours).
Pros
- Visual Interface: Excellent low-code/no-code pipeline builder for citizen integrators.
- Microsoft Synergy: Unbeatable integration for teams migrating from on-premises SQL Server.
Cons
- Limited Real-Time: ADF is primarily a batch orchestration tool. Achieving true real-time streaming requires stringing together additional services (like Azure Event Hubs and Stream Analytics).
- Billing Complexity: Because costs are spread across pipeline runs, data movement, and compute, predicting the final monthly bill is notoriously difficult.
Choosing the Right Data Modernization Tool
Modernizing your data stack is not just about moving information into the cloud. It is about ensuring that data arrives accurately, in real time, and in a form your teams can trust to power agentic AI and mission-critical workloads.
The storage platforms outlined above—Databricks, Snowflake, BigQuery, and Azure—are incredible analytical engines. But they cannot function effectively on stale data.
If your priority is to feed these modern destinations reliably, quickly, and securely, Striim is the most complete pipeline option. Striim’s combination of high-performance CDC, sub-second stream processing, and Validata for continuous reconciliation gives you end-to-end control over both data movement and data quality. This means you can modernize faster while actively reducing the risk of broken pipelines, silent data drift, and compliance failures.
For organizations that want to modernize with confidence and bring their enterprise into the AI era, Striim provides the trusted, real-time foundation you need.
Book a Demo Today to See Striim in Action
FAQs About Data Modernization Tools
- What are data modernization tools, and why do they matter? Data modernization tools replace legacy, batch-based systems with cloud-native architectures. They handle real-time data movement, validation, governance, and storage, allowing you to power analytics and AI without undertaking a complete infrastructure rebuild.
- How do data streaming tools differ from data storage tools? Movement tools (like Striim) extract and validate data mid-flight the moment it is created. Storage tools (like Snowflake or Databricks) act as the highly scalable destination where that data is kept, queried, and analyzed. A modern stack requires both.
- What should I look for when evaluating data modernization tools? Look beyond basic cloud migration. Prioritize true real-time capabilities (log-based CDC), a wide breadth of pre-built connectors, in-flight data validation to guarantee trust, and an architecture that scales without hidden operational costs.
- How do data modernization tools support AI and advanced analytics? Agentic AI and ML models cannot survive on batch data from yesterday. Modernization tools automate the ingestion, transformation, and validation of data in real time, ensuring your AI systems are reasoning with accurate, current context.
- Where does Striim fit in a data modernization strategy? Striim is the intelligent bridge between your legacy systems and your modern cloud destinations. By delivering sub-second CDC, mid-flight transformations, and continuous Validata checks, Striim ensures your analytics and AI tools are always fed with fresh, fully compliant data.
MongoDB to Databricks: Methods, Use Cases & Best Practices

If your modern applications run on MongoDB, you’re sitting on a goldmine of operational data. As a leading NoSQL database, MongoDB is an unparalleled platform for handling the rich, semi-structured, high-velocity data generated by web apps, microservices, and IoT devices.
But operational data is only half the equation. To turn those raw application events into predictive models, executive dashboards, and agentic AI, that data needs to land in a modern data lakehouse. That is where Databricks comes in.
The challenge is getting data from MongoDB into Databricks without breaking your architecture, ballooning your compute costs, or serving your data science teams stale information.
For modern use cases—like dynamic pricing, in-the-moment fraud detection, or real-time customer personalization—a nightly batch export isn’t fast enough. To power effective AI and actionable analytics, you need to ingest MongoDB data into Databricks in real time.
If you’re a data leader or architect tasked with connecting these two powerful platforms, you likely have some immediate questions: Should we use native Spark connectors or a third-party CDC tool? How do we handle MongoDB’s schema drift when writing to structured Delta tables? How do we scale this without creating a maintenance nightmare?
This guide will answer those questions. We’ll break down exactly how to architect a reliable, low-latency pipeline between MongoDB and Databricks.
What you’ll learn in this article:
- A comprehensive trade-offs matrix comparing batch, native connectors, and streaming methods.
- A selection flowchart to help you choose the right integration path for your architecture.
- A POC checklist for evaluating pipeline solutions.
- A step-by-step rollout plan for taking your MongoDB-to-Databricks pipeline into production.
Why Move Data from MongoDB to Databricks?
MongoDB is the operational engine of the modern enterprise. It excels at capturing the high-volume, flexible document data your applications generate: from e-commerce transactions and user sessions to IoT telemetry and microservice logs.
Yet MongoDB is optimized for transactional (OLTP) workloads, not heavy analytical processing. If you want to run complex aggregations across years of historical data, train machine learning models, or build agentic AI systems, you need a unified lakehouse architecture. Databricks provides exactly that. By pairing MongoDB’s rich operational data with Databricks’ advanced analytics and AI capabilities, you bridge the gap between where data is created and where it becomes intelligent.
When you ingest MongoDB data into Databricks continuously, you unlock critical business outcomes:
- Faster Decision-Making: Live operational data feeds real-time executive dashboards, allowing leaders to pivot strategies based on what is happening right now, not what happened yesterday.
- Reduced Risk: Security and fraud models can analyze transactions and detect anomalies in the moment, flagging suspicious activity before the damage is done.
- Improved Customer Satisfaction: Fresh data powers hyper-personalized experiences, in-the-moment recommendation engines, and dynamic pricing that responds to live user behavior.
- More Efficient Operations: Supply chain and logistics teams can optimize routing, inventory, and resource allocation based on up-to-the-minute telemetry.
The Metrics That Matter To actually achieve these outcomes, “fast enough” isn’t a strategy. Your integration pipeline needs to hit specific, measurable targets. When evaluating your MongoDB to Databricks architecture, aim for the following SLAs:
- Latency & Freshness SLA: Sub-second to low-single-digit seconds from a MongoDB commit to visibility in a Databricks Delta table.
- Model Feature Lag: Under 5 seconds for real-time inference workloads (crucial for fraud detection and dynamic pricing).
- Dashboard Staleness: Near-zero, ensuring operational reporting reflects the current, trusted state of the business.
- Cost per GB Ingested: Optimized to minimize compute overhead on your source MongoDB cluster while avoiding unnecessary Databricks SQL warehouse costs for minor updates.
Common Use Cases for MongoDB to Databricks Integration
When you successfully stream MongoDB data into Databricks, you move beyond a static repository towards an active, decision-ready layer of your AI architecture.
Here is how data teams are leveraging this integration in production today:
Feeding Feature Stores for Machine Learning Models
Machine learning models are hungry for fresh, relevant context. For dynamic pricing models or recommendation engines, historical batch data isn’t enough; the model needs to know what the user is doing right now. By streaming MongoDB application events directly into Databricks Feature Store, data scientists can ensure their real-time inference models are always calculating probabilities based on the freshest possible behavioral context.
Real-Time Fraud Detection and Anomaly Detection
In the financial and e-commerce sectors, milliseconds matter. If a fraudulent transaction is committed to a MongoDB database, it needs to be analyzed immediately. By mirroring MongoDB changes into Databricks in real time, security models can evaluate transactions against historical baselines on the fly, triggering alerts or blocking actions before the user session ends.
Customer Personalization and Recommendation Engines
Modern consumers expect hyper-personalized experiences. If a user adds an item to their cart (recorded in MongoDB), the application should instantly recommend complementary products. By routing that cart update through Databricks, where complex recommendation algorithms reside, businesses can serve tailored content and offers while the customer is still active on the site, directly driving revenue.
Operational Reporting and Dashboards
Executive dashboards shouldn’t wait hours or days for updates. Supply chain managers, logistics coordinators, and financial officers need a single source of truth that reflects the current reality of the business. Streaming MongoDB operational data into Databricks SQL allows teams to query massive datasets with sub-second latency, ensuring that BI tools like Tableau or PowerBI always display up-to-the-minute metrics.
Methods for Moving MongoDB Data into Databricks
There is no single “right” way to connect MongoDB and Databricks; the best method depends entirely on your SLA requirements, budget, and engineering bandwidth.
Broadly speaking, teams choose from three architectural patterns. Here is a quick summary of how they stack up:
Integration Method |
Speed / Data Freshness |
Pipeline Complexity |
Scalability |
Infrastructure Cost |
AI/ML Readiness |
| Batch / File-Based | Low (Hours/Days) | Low | Medium | High (Compute spikes) | Poor |
| Native Spark Connectors | Medium (Minutes) | Medium | Low (Impacts source DB) | Medium | Fair |
| Streaming CDC | High (Sub-second) | High (if DIY) / Low (with managed platform) | High | Low (Continuous, optimized) | Excellent |
Let’s break down how each of these methods works in practice.
Batch Exports and File-Based Ingestion
This is the traditional, manual approach to data integration. A scheduled job (often a cron job or an orchestration tool like Airflow) runs a script to export MongoDB collections into flat files—typically JSON or CSV formats. These files are then uploaded to cloud object storage (like AWS S3, Azure Data Lake, or Google Cloud Storage), where Databricks can ingest them.
- The Pros: This approach is conceptually simple and requires very little initial engineering effort.
- The Cons: Batched jobs are notoriously slow. By the time your data lands in Databricks, it is already stale. Furthermore, running massive query exports puts heavy, periodic strain on your MongoDB operational database.
It’s worth noting that Databricks Auto Loader can partially ease the pain of file-based ingestion by automatically detecting new files and handling schema evolution as the files arrive. However, Auto Loader can only process files after they are exported; your data freshness remains entirely bound by your batch schedule.
Native Spark/MongoDB Connectors
For teams already heavily invested in the Databricks ecosystem, a common approach is to use the official MongoDB Spark Connector. This allows a Databricks cluster to connect directly to your MongoDB instance and read collections straight into Spark DataFrames.
- The Pros: It provides direct access to the source data and natively handles MongoDB’s semi-structured BSON/JSON formats.
- The Cons: This method is not optimized for continuous, real-time updates. Polling a live database for changes requires running frequent, heavy Spark jobs. Worse, aggressive polling can directly degrade the performance of your production MongoDB cluster, leading to slow application response times for your end users.
- The Verdict: It requires careful cluster tuning and significant maintenance overhead to manage incremental loads effectively at scale.
Streaming Approaches and Change Data Capture (CDC)
If your goal is to power real-time AI, ML, or operational analytics, Change Data Capture (CDC) is the gold standard. Instead of querying the database for data, CDC methods passively tap into MongoDB’s oplog (operations log) or change streams. They capture every insert, update, and delete exactly as it happens and stream those events continuously into Databricks.
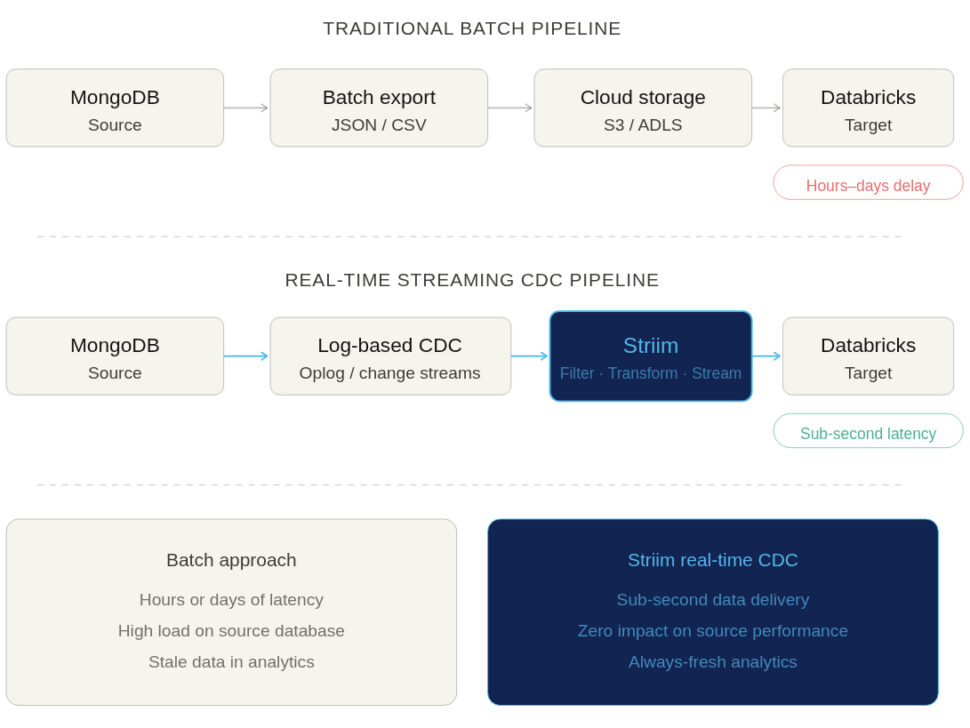
- Why it matters for AI/ML: Predictive models and real-time dashboards degrade rapidly if their underlying data isn’t fresh. Streaming CDC ensures that Databricks always reflects the exact, current state of your operational applications.
- The Complexity Warning: While the architectural concept is elegant, building a CDC pipeline yourself is incredibly complex. Not all CDC tools or open-source frameworks gracefully handle MongoDB’s schema drift, maintain strict event ordering, or execute the necessary retries if a network failure occurs. Doing this reliably requires enterprise-grade stream processing.
Challenges of Integrating MongoDB with Databricks
Connecting an operational NoSQL database to an analytical Lakehouse represents a paradigm shift in how data is structured and processed. While pulling a small, one-off snapshot might seem trivial, the underlying challenges are severely magnified when you scale up to millions of daily events.
Before building your pipeline, your data engineering team must be prepared to tackle the following hurdles.
Latency and Stale Data in Batch Pipelines
The most immediate challenge is the inherent delay in traditional ETL. Delays between a MongoDB update and its visibility in Databricks actively undermine the effectiveness of your downstream analytics and ML workloads. If an e-commerce platform relies on a nightly batch load to update its recommendation engine, the model will suggest products based on yesterday’s browsing session—completely missing the user’s current intent. For high-stakes use cases like fraud detection, a multi-hour delay renders the data practically useless.
Handling Schema Drift and Complex JSON Structures
MongoDB’s greatest strength for developers—its flexible, schema-less document model—is often a data engineer’s biggest headache. Applications can add new fields, change data types, or deeply nest JSON arrays at will, without ever running a database migration. However, when landing this data into Databricks, you are moving it into structured Delta tables. If your integration pipeline cannot automatically adapt to evolving document structures (schema drift), your downstream pipelines will break, requiring manual intervention and causing significant downtime.
Ensuring Data Consistency and Integrity at Scale
Moving data from Point A to Point B is easy. Moving it exactly once, in the correct order, while processing thousands of transactions per second, is incredibly difficult. Network partitions, brief database outages, or cluster restarts are inevitable in distributed systems. If your pipeline cannot guarantee exactly-once processing (E1P), you risk creating duplicate events or missing critical updates entirely. In financial reporting or inventory management, a single dropped or duplicated event can break the integrity of the entire dataset.
Managing Infrastructure and Operational Overhead
Many teams attempt to solve the streaming challenge by stitching together open-source tools, for example, deploying Debezium for CDC, Apache Kafka for the message broker, and Spark Structured Streaming to land the data. The operational overhead of this DIY approach is massive. Data engineers end up spending their cycles maintaining connectors, scaling clusters, and troubleshooting complex failures rather than building valuable data products.
Challenge Area |
The Operational Reality |
| Connector Maintenance | Open-source connectors frequently break when MongoDB or Databricks release version updates. |
| Cluster Scaling | Managing Kafka and Spark clusters requires dedicated DevOps resources to monitor memory, CPU, and partition rebalancing. |
| Observability | Tracking exactly where an event failed (was it in the CDC layer, the broker, or the writer?) requires building custom monitoring dashboards. |
| Error Recovery | Restarting a failed streaming job without duplicating data requires complex checkpointing mechanisms that are notoriously hard to configure. |
Best Practices for Powering Databricks with Live MongoDB Data
Building a resilient, real-time pipeline between MongoDB and Databricks is entirely achievable. However, the most successful enterprise teams don’t reinvent the wheel; they rely on architectural lessons from the trenches.
While you can technically build these best practices into a custom pipeline, doing so requires significant engineering effort. That is why leading organizations turn to enterprise-grade platforms like Striim to bake these capabilities directly into their infrastructure.
Here are some best practices to ensure a production-ready integration.
Start With An Initial Snapshot, Then Stream Changes
To build an accurate analytical model in Databricks, you cannot just start streaming today’s changes; you need the historical baseline. The best practice is to perform an initial full load (a snapshot) of your MongoDB collections, and then seamlessly transition into capturing continuous changes (CDC).
Coordinating this manually is difficult. If you start CDC too early, you create duplicates; if you start it too late, you miss events. Platforms like Striim automate this end-to-end. Striim handles the initial snapshot and automatically switches to CDC exactly where the snapshot left off, ensuring your Databricks environment has a complete, gap-free, and duplicate-free history.
Transform And Enrich Data In Motion For Databricks Readiness
MongoDB stores data in flexible BSON/JSON documents, but Databricks performs best when querying highly structured, columnar formats like Parquet via Delta tables. Pre-formatting this data before it lands in Databricks reduces your cloud compute costs and drastically simplifies the work for your downstream analytics engineers.
While you can achieve this with custom Spark code running in Databricks, performing transformations mid-flight is much more efficient. Striim offers built-in stream processing (using Streaming SQL), allowing you to filter out PII, flatten nested JSON arrays, and enrich records in real time, so the data lands in Databricks perfectly structured and ready for immediate querying.
Monitor Pipelines For Latency, Lag, And Data Quality
Observability is non-negotiable. When you are feeding live data to an AI agent or a fraud detection model, you must know immediately if the pipeline lags or if data quality drops. Data teams need comprehensive dashboards and alerting to ensure their pipelines are keeping up with business SLAs.
Building this level of monitoring from scratch across multiple open-source tools is a heavy lift. Striim provides end-to-end visibility out of the box. Data teams can monitor throughput, quickly detect lag, identify schema drift, and catch pipeline failures before they impact downstream analytics.
Optimize Delta Table Writes To Avoid Small-File Issues
One of the biggest pitfalls of streaming data into a lakehouse is the “small file problem.” If you write every single MongoDB change to Databricks as an individual file, it will severely degrade query performance and bloat your storage metadata.
To ensure optimal performance, take a strategic approach to batching and partitioning your writes into Databricks. These optimizations are incredibly complex to tune manually in DIY pipelines. Striim handles write optimization automatically, smartly batching micro-transactions into efficiently sized Parquet files for Delta Lake, helping your team avoid costly performance bottlenecks without lifting a finger.
Simplify MongoDB to Databricks Integration with Striim
Striim is the critical bridge between MongoDB’s rich operational data and the Databricks Lakehouse. It ensures that your analytics and AI/ML workloads run on live, trusted, and production-ready data, rather than stale batch exports.
While DIY methods and native connectors exist, they often force you to choose between data freshness, cluster performance, and engineering overhead. Striim uniquely combines real-time Change Data Capture (CDC), in-flight transformation, and enterprise reliability into a single, unified platform. Built to handle massive scale—processing over 100 billion events daily for leading enterprises—Striim turns complex streaming architecture into a seamless, managed experience.
With Striim, data teams can leverage:
- Real-time Change Data Capture (CDC): Passively read from MongoDB oplogs or change streams with zero impact on source database performance.
- Built-in Stream Processing: Use SQL to filter, enrich, and format data (e.g., flattening complex JSON to Parquet) before it ever lands in Databricks.
- Exactly-Once Processing (E1P): Guarantee data consistency in Databricks without duplicates or dropped records.
- Automated Snapshot + CDC: Execute a seamless full historical load that instantly transitions into continuous replication.
- End-to-End Observability: Out-of-the-box dashboards to monitor throughput, latency, and pipeline health.
- Fault Tolerance: Automated checkpointing allows your pipelines to recover seamlessly from network failures.
- Secure Connectivity: Safely integrate both MongoDB Atlas and self-hosted/on-prem deployments.
- Optimized Delta Lake Writes: Automatically batch and partition writes to Databricks to ensure maximum query performance and scalable storage.
Ready to stop managing pipelines and start building AI? Try Striim for free or book a demo with our engineering team today.
FAQs
What is the best way to keep MongoDB data in sync with Databricks in real time?
The most effective method is log-based Change Data Capture (CDC). Instead of running heavy batch queries that degrade database performance, CDC passively reads MongoDB’s oplog or change streams. This allows platforms like Striim to capture inserts, updates, and deletes continuously, syncing them to Databricks with sub-second latency.
How do you handle schema drift when moving data from MongoDB to Databricks?
MongoDB’s flexible document model means fields can change without warning, which often breaks structured Databricks Delta tables. To handle this, your pipeline must detect changes in motion. Enterprise streaming platforms automatically identify schema drift mid-flight and elegantly evolve the target Delta table schema without requiring pipeline downtime or manual engineering intervention.
Why is streaming integration better than batch exports for AI and machine learning use cases?
AI and ML models rely on fresh context to make accurate predictions. If an e-commerce dynamic pricing model is fed via a nightly batch export, it will price items based on yesterday’s demand, losing revenue. Streaming integration ensures that Databricks Feature Stores are updated in milliseconds, allowing models to infer intent and execute decisions based on what a user is doing right now.
How do I choose between native connectors and third-party platforms for MongoDB to Databricks integration?
Native Spark connectors are useful for occasional, developer-led ad-hoc queries or small batch loads. However, if you poll them frequently for real-time updates, you risk severely straining your MongoDB cluster. Third-party CDC platforms like Striim are purpose-built for continuous, low-impact streaming at enterprise scale, offering built-in observability and automated recovery that native connectors lack.
Can Striim integrate both MongoDB Atlas and on-prem MongoDB with Databricks?
Yes. Striim provides secure, native connectivity for both fully managed MongoDB Atlas environments and self-hosted or on-premises MongoDB deployments. This ensures that no matter where your operational data lives, it can be securely unified into your Databricks Lakehouse without creating infrastructure silos.
What are the costs and ROI benefits of using a platform like Striim for MongoDB to Databricks pipelines?
Striim dramatically reduces compute overhead by eliminating heavy batch polling on MongoDB and optimizing writes to avoid Databricks SQL warehouse spikes. The true ROI, however, comes from engineering velocity. By eliminating the need to build, maintain, and troubleshoot complex Kafka/Spark streaming architectures, data engineers can refocus their time on building revenue-generating AI products.
How do you ensure data quality when streaming from MongoDB to Databricks?
Data quality must be enforced before the data lands in your lakehouse. Using in-flight transformations, you can validate data types, filter out malformed events, and mask PII in real time. Furthermore, utilizing a platform that guarantees exactly-once processing (E1P) ensures that network hiccups don’t result in duplicated or dropped records in Databricks.
Can MongoDB to Databricks pipelines support both historical and real-time data?
Yes, a production-grade pipeline should handle both seamlessly. The best practice is to execute an automated snapshot (a full load of historical MongoDB data) and then immediately transition into continuous CDC. Striim automates this hand-off, ensuring Databricks starts with a complete baseline and stays perfectly synchronized moving forward.
What security considerations are important when integrating MongoDB and Databricks?
When moving operational data, protecting Personally Identifiable Information (PII) is paramount. Data should never be exposed in transit. Using stream processing, teams can detect and redact sensitive customer fields (like credit card numbers or SSNs) mid-flight, ensuring that your Databricks environment remains compliant with HIPAA, PCI, and GDPR regulations.
How does Striim compare to DIY pipelines built with Spark or Kafka for MongoDB to Databricks integration?
Building a DIY pipeline requires stitching together and maintaining multiple distributed systems (e.g., Debezium, Kafka, ZooKeeper, and Spark). This creates a fragile architecture that is difficult to monitor and scale. Striim replaces this complexity with a single, fully managed platform that offers sub-second latency, drag-and-drop transformations, and out-of-the-box observability—drastically lowering total cost of ownership.