To the data scientists pushing the boundaries of what’s possible, the AI experts and enthusiasts who see beyond the horizon, and the techies building tomorrow’s solutions today — this manifesto is for you. The key to unlocking AI’s full potential lies in real time data. Traditional methods no longer suffice in a world that demands instant insights and immediate action.
Real-Time AI as the New Competitive Battleground

AI and ML are more than just buzzwords; they are driving substantial economic growth, creating new job opportunities, and shaping the future. The AI market is projected to reach a staggering $1,339 billion by 2030. This exponential growth underscores the widespread adoption and integration of AI across various industries. Furthermore, AI is on track to boost the US GDP by 21% by 2030. This highlights the profound economic impact AI will have. By automating routine tasks, optimizing operations, and providing deep insights through data analysis, AI enables businesses to increase productivity while reducing costs. And contrary to common fears that AI will eliminate jobs, it is expected to create 20-50 million positions by 2030. These roles will span various sectors, including data science, AI ethics, machine learning engineering, and AI-related research and development.
Real-Time Data — The Missing Link
What is Real-Time Data?
In the realm of data processing, real-time data refers to information that is delivered and processed almost instantaneously as it is generated. Unlike batch processing, which involves collecting and processing data in bulk at scheduled intervals, real-time data ensures immediate availability and actionability. This immediacy allows for decisions and responses to be made in the moment, offering a dynamic edge over traditional methods.
The Death of Traditional Batch Processing
The shift from batch processing to real-time data marks a crucial technological evolution driven by the need for speed and efficiency. Batch processing resulted in significant delays between data generation and actionable insights. As the demand for faster decision-making grew, the limitations of traditional batch processing became glaringly apparent. Traditional methods introduced latency, making it impossible to act on data immediately, a critical issue in environments requiring timely decisions.
Furthermore, batch processing systems were rigid and inflexible, struggling to scale as data volumes grew and needing substantial reengineering to adapt to new data types or sources. The advent of real-time data processing revolutionized this paradigm, providing the means to analyze and act on data as it flows, thereby minimizing latency to sub-second and offering unparalleled scalability and adaptability to modern data streams. This transformation is responsible for enabling real-time decision-making and fostering innovation across industries, cementing real-time data as the cornerstone of AI algorithms and advancements.
Dispelling Misconceptions and Demonstrating Value
In the world of AI and ML, there are a few common objections to the adoption of real-time data processing. Let’s dive into these misconceptions and demonstrate the true value of real-time capabilities.
Misconception: Batch Processing Suffices
Objection: Many AI/ML tasks can be handled with batch processing. Models trained on historical data can make predictions without needing real-time updates. The necessity of real-time data is highly specific to certain use cases, and not all industries or applications benefit equally.
Reality Check: While batch processing works for some tasks, it falls short in dynamic environments requiring high responsiveness and timely decision-making. Real-time data integration allows models to process the most recent data points, reducing lag between data generation and actionable insights. This is crucial in fields like finance, where market conditions shift rapidly, or e-commerce, where user behavior and inventory status constantly change. For example, fraud detection models relying on batch data might miss real-time anomalies, whereas real-time data can detect and respond to fraud within milliseconds. In healthcare, real-time patient monitoring can provide immediate insights for timely interventions, improving patient outcomes. The notion that real-time data is only useful in specific cases is outdated as countless industries increasingly leverage real-time capabilities to stay competitive and responsive.
Misconception: Complexity and Cost
Objection: Implementing real-time data systems is complex and costly. The infrastructure required for real-time data ingestion, processing, and analysis can be significantly more expensive than batch processing systems.
Reality Check: While real-time systems require an investment, the ROI is substantial. Modern cloud-based architectures and scalable platforms like Striim and Apache Kafka have reduced the complexity and cost of real-time data processing. Real-time systems drive higher revenues and better customer experiences by enabling immediate responses to emerging trends and anomalies. For instance, real-time inventory management in retail can prevent stockouts and overstock, directly impacting sales and customer satisfaction. The initial investment in real-time capabilities is outweighed by the long-term gains in efficiency, responsiveness, and competitive advantage.
Misconception: Data Quality and Stability
Objection: Real-time data can be noisy and unstable, leading to potential inaccuracies in model predictions. Batch processing allows for more thorough data cleaning and preprocessing.
Reality Check: Real-time data does not mean compromising on quality. Advanced real-time analytics platforms incorporate robust data cleaning and anomaly detection, ensuring models receive high-quality, stable inputs. Tools like Apache Beam and Spark Streaming provide mechanisms for real-time data validation and cleansing. Real-time data pipelines can also integrate seamlessly with existing ETL processes to maintain data integrity. By leveraging these technologies, organizations can ensure that their real-time data is as reliable and accurate as batch-processed data, while gaining the added advantage of immediacy.
Misconception: Model Retraining Frequency
Objection: Many models do not need to be retrained frequently. The insights gained from real-time data might not justify the cost and effort of constant retraining.
Reality Check: The pace of change in today’s world demands models that can adapt quickly. Real-time data enables continuous learning and incremental updates, ensuring models remain relevant and accurate. Techniques like online learning and incremental model updates allow models to evolve without the need for complete retraining. For example, recommendation systems can benefit from real-time user behavior data, continuously refining their suggestions to enhance user engagement. By integrating real-time data, organizations can maintain high model performance and accuracy, adapting swiftly to new patterns and trends.
Industry Disruption through Real-Time AI
Real-time AI is redefining how businesses operate by providing up-to-the-second information that enhances predictive accuracy, supports continuous learning, and automates complex decision-making processes. This integration allows AI to adapt instantly to new data, which is essential for applications where split-second decision-making is critical, including fraud detection, autonomous vehicles, and financial trading. It also powers real-time anomaly detection in cybersecurity and manufacturing, identifying threats and malfunctions as they occur. Additionally, real-time data empowers personalized customer experiences by analyzing interactions on the fly, delivering tailored recommendations and services. The scalability and adaptability of real-time data platforms ensure AI systems are always equipped with the most current information, driving innovation and efficiency across industries.
Real-Time AI & ML in the Real World
Predictive Maintenance in Manufacturing
ML algorithms, often powered by sensors and IoT devices, continuously monitor equipment health. Anticipating failures, predictive maintenance minimizes downtime and optimizes productivity by analyzing historical data and real-time sensor readings, enabling proactive scheduling and preventing disruptions in production.
Customer Churn Prediction in Telecom
ML models may consider factors such as customer demographics, usage patterns, customer service interactions, and billing history. By identifying customers at risk of churn, telecom companies can implement targeted retention strategies, such as personalized offers or improved customer support.
Fraud Detection in Finance
ML algorithms learn from historical data to identify patterns associated with fraudulent transactions. Real-time monitoring allows financial institutions to detect anomalies and trigger immediate alerts or interventions. This proactive approach helps prevent financial losses due to fraudulent activities.
Personalized Marketing in E-commerce
ML algorithms analyze not only purchase history but also browsing behavior and preferences. This enables e-commerce platforms to deliver personalized product recommendations through targeted advertisements, email campaigns, and website interfaces, enhancing the overall shopping experience.
Healthcare Diagnostics and Predictions
ML models, particularly in medical imaging, can assist healthcare providers by identifying subtle patterns indicative of diseases. Predictive analytics also help healthcare providers anticipate patient health deterioration, enabling early interventions and personalized treatment plans.
Dynamic Pricing in Retail
ML algorithms consider a multitude of factors, including competitor pricing, inventory levels, historical sales data, and customer behavior. By dynamically adjusting prices in real time, retailers can optimize revenue, respond to market changes, and maximize profitability.
Supply Chain Optimization
ML-driven demand forecasting considers historical data, seasonality, and external factors like economic trends and geopolitical events. This enables accurate inventory management, reduces excess stock, and ensures timely deliveries, ultimately improving the overall efficiency of the supply chain.
Human Resources and Talent Management
ML tools assist in resume screening by identifying relevant skills and qualifications. Predictive analytics can assess employee satisfaction, helping organizations identify areas for improvement and implement strategies to enhance employee retention and engagement.
UPS Success Story: Where Real-Time Data Supercharged Real-Time AI

Safeguarding shipments with AI and real-time data
UPS Capital® is leveraging Google’s Data Cloud and AI technologies to safeguard packages from porch piracy. With more than 300 million American consumers turning to online shopping, UPS Capital has witnessed the significant challenges customers face in securing their package delivery ecosystem. Now, the company is leveraging its digital capabilities and access to data to help customers rethink traditional approaches to combat shipping loss and deliver better customer experiences.
https://youtu.be/shreurvc28U?si=2rVZTIO0YWnMR2W-
DeliveryDefense™ Address Confidence utilizes real-time data and machine learning algorithms to safeguard packages. By assigning a confidence score to potential delivery locations, it enhances the assessment of successful delivery probabilities while mitigating loss or theft risks. Every address is allocated a confidence score on a scale from 100 to 1000, with 1000 indicating the highest probability of delivery success. These scores are based on customer reports of package theft. Shippers can integrate this score into their shipping workflow through an API to take proactive, preventative actions on low-confidence addresses. For instance, if a package is destined for an address with a low confidence score, the merchant can proactively reroute the shipment to a secure UPS Access Point location. These locations typically have a confidence score of around 950 due to their high chain of custody security precautions.
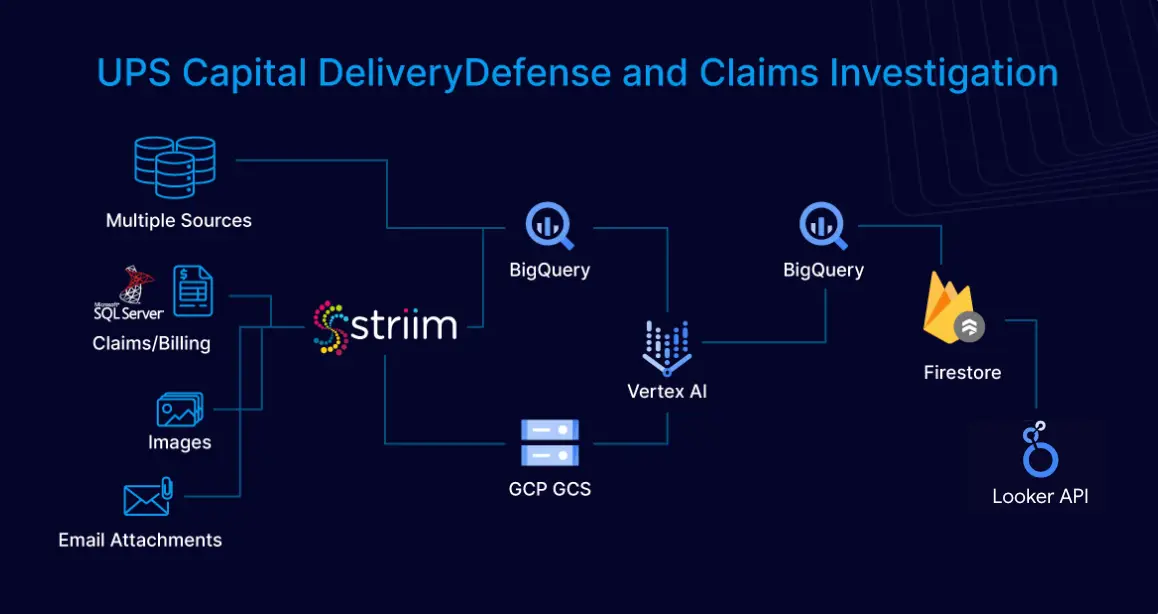
Striim’s real-time data integration platform works in tandem with Google Cloud’s modern architecture by dynamically embedding vectors into streaming information, enhancing data representation, processing efficiency, and analytical accuracy. Striim also integrates structured and unstructured data pulled from diverse sources and applies a variety of AI models from OpenAI and Vertex AI to generate embeddings that establish similarity scores between data points to reveal possible relationships.
UPS Capital brings significant operational rewards, evidenced by over 280,000 claims paid annually. With $236 billion in declared value and 690k shippers protected, its solutions offer robust protection for shippers, ensuring peace of mind and financial security in every shipment.
The Future of AI is Now — And It’s Real-Time
Real-time data and AI are significantly improving existing processes and impacting the bottom line across industries. From retail and finance to healthcare and beyond, the integration of real-time data is driving greater efficiency, more personalized customer experiences, and continuous innovation. This shift is creating new opportunities and setting higher standards.
Businesses are encouraged to embrace real-time data and AI to stay competitive in the future. By adopting these technologies, companies can fully leverage AI, stay ahead of the competition, and navigate the evolving technological landscape. The future of AI is real-time, and the time to act is now.






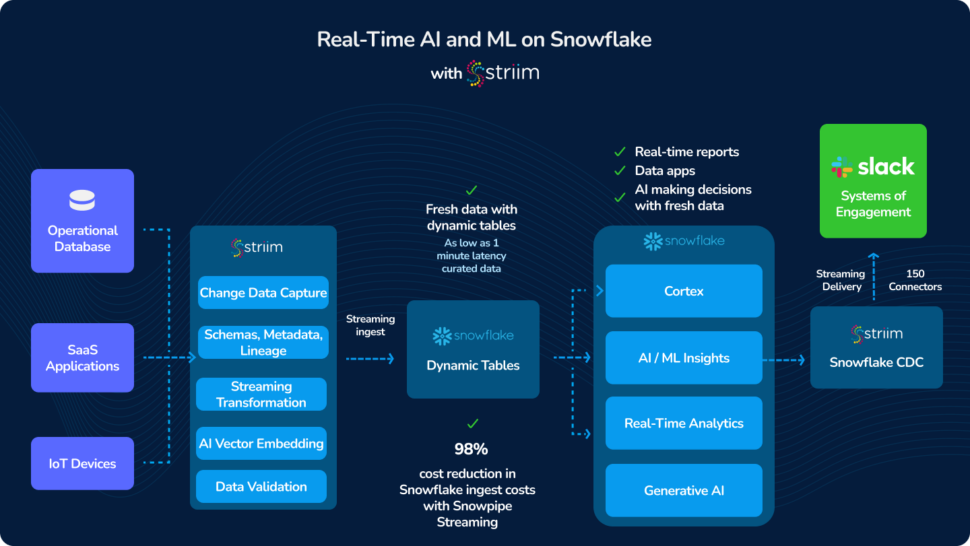
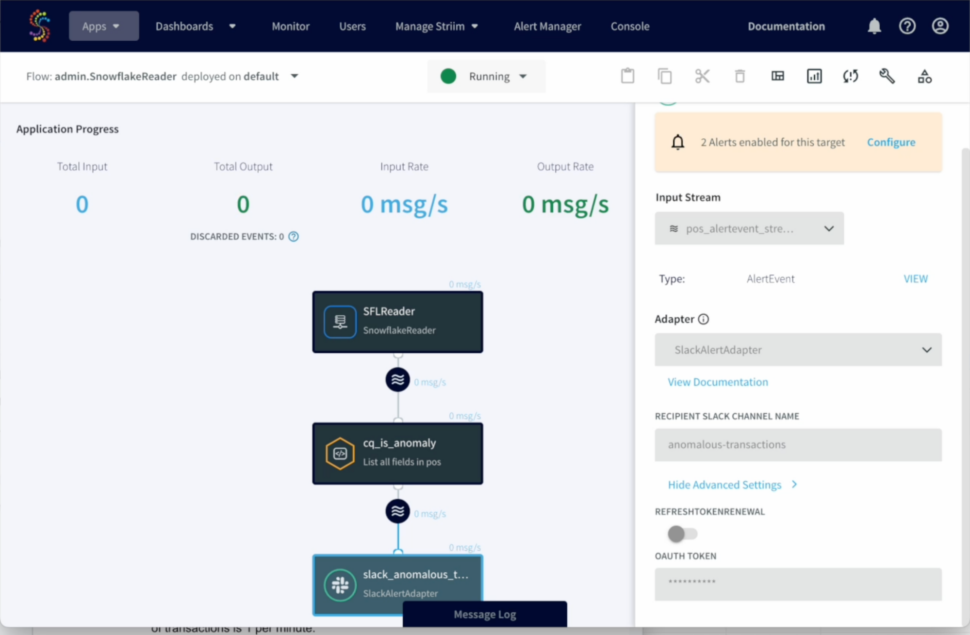
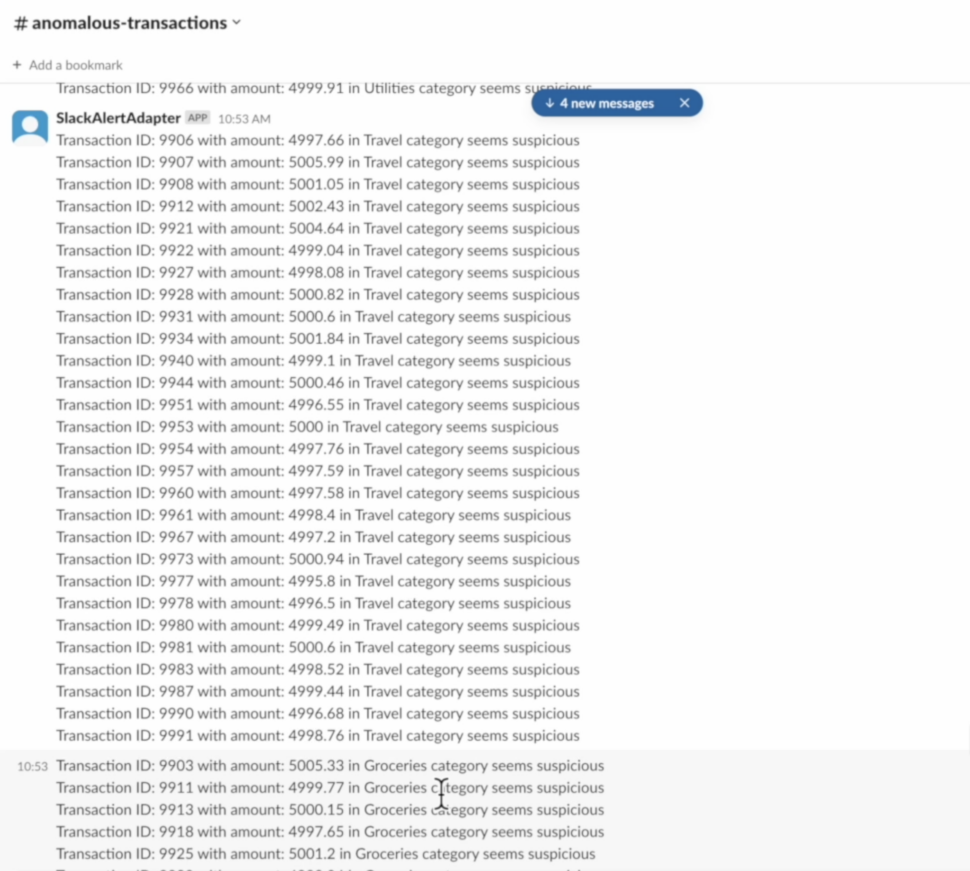
 By utilizing Striim, Inspyrus ingested real-time data from an OLTP database, loaded it into Snowflake, and transformed it there. It then used an intelligence tool to visualize this data and create rich reports for users. As a result, Inspyrus users are able to view reports in real time and utilize insights immediately to fuel better decisions.
By utilizing Striim, Inspyrus ingested real-time data from an OLTP database, loaded it into Snowflake, and transformed it there. It then used an intelligence tool to visualize this data and create rich reports for users. As a result, Inspyrus users are able to view reports in real time and utilize insights immediately to fuel better decisions.