Modern systems don’t break because data is wrong. They break because data is late.
When a transaction commits in PostgreSQL, something downstream depends on it. A fraud detection model. A real-time dashboard. A supply chain optimizer. An AI agent making autonomous decisions. If that change takes hours to propagate, the business operates on stale context.
For most enterprise companies, the answer is still “too long.” Batch pipelines run overnight. Analysts reconcile yesterday’s numbers against this morning’s reports. By the time the data lands, the moment it mattered most has already passed. When your fraud model runs on data that’s six hours old, you aren’t preventing fraud. You’re just documenting it.
Change Data Capture (CDC) changes the paradigm. Rather than waiting for a nightly batch job to catch up, CDC reads a database’s transaction log—the record of every insert, update, and delete—and streams those changes to downstream systems the instant they occur.
For PostgreSQL, one of the most widely adopted relational databases for mission-critical workloads, CDC is essential infrastructure.
This guide covers how CDC works in PostgreSQL, the implementation methods available, real-world enterprise use cases, and the technical challenges you should plan for.
Whether you’re evaluating logical decoding, trigger-based approaches, or a fully managed integration platform, you’ll find actionable guidance to help you move from batch to real-time.
Change Data Capture in PostgreSQL 101
Change Data Capture identifies row-level changes—insert, update, and delete operations—and delivers those changes to downstream systems in real time.
In PostgreSQL, CDC typically works by reading the Write-Ahead Log (WAL). The WAL is PostgreSQL’s transaction log. Every committed change is recorded there before being applied to the database tables. By reading the WAL, CDC tools can stream changes efficiently without re-querying entire tables or impacting application workloads. This approach:
- Minimizes load on production systems
- Eliminates full-table batch scans
- Delivers near real-time propagation
- Enables continuous synchronization across systems
For modern enterprises, especially those running PostgreSQL in hybrid or multi-cloud environments—or migrating to AlloyDB—this is essential.
In PostgreSQL environments, this matters for a specific reason: Postgres is increasingly the database of choice for mission-critical applications. Companies like Apple, Instagram, Spotify, and Twitch rely on PostgreSQL to power massive production workloads. When data in those systems changes, the rest of the enterprise needs to know immediately.
CDC in PostgreSQL breaks down data silos by enabling real-time integration across hybrid and multi-cloud environments. It keeps analytical systems, cloud data warehouses, and AI pipelines in perfect sync with live application data.
Without it, you’re making decisions on stale information, and in domains like dynamic pricing, supply chain logistics, or personalized marketing, stale data is costly.
Key Features and How CDC Is Used in PostgreSQL
PostgreSQL CDC captures row-level changes and propagates them with sub-second latency. Here’s what that enables in practice:
- Real-time data propagation. Changes are delivered as they occur, closing the gap between when data is written and when it becomes actionable for downstream consumers.
- Low-impact processing. By reading the database’s Write-Ahead Log (WAL) rather than querying production tables directly, CDC minimizes the performance impact on the source database.
- Broad integration support. A single PostgreSQL source can simultaneously feed cloud warehouses (Snowflake, BigQuery), lakehouses (Databricks), and streaming platforms (Apache Kafka).
When enterprises move from batch processing to PostgreSQL CDC, they typically apply it to three core areas:
- Modernizing ETL/ELT pipelines. CDC replaces the heavy “extract” phase of traditional ETL with a continuous, low-impact feed of changes, enabling real-time transformation and loading. Instead of waiting on nightly jobs, data moves as it’s created, reducing latency and infrastructure strain.
- Real-time analytics and warehousing. CDC keeps dashboards and reporting systems in sync without running resource-heavy full table scans or waiting for batch windows. Analytics environments stay current, which improves decision-making and operational visibility.
- Event-driven architectures. CDC turns database commits into actionable events. You can trigger downstream workflows like order fulfillment, inventory alerts, fraud checks, or customer notifications without building custom polling logic into your applications.
- AI adoption. With real-time data flowing through CDC, organizations can operationalize AI more effectively. Machine learning models, anomaly detection systems, fraud scoring engines, and predictive forecasting tools can operate on continuously updated data rather than stale snapshots. This enables faster decisions, higher model accuracy, and intelligent automation embedded directly into business processes.
Real-World Examples of CDC in PostgreSQL
CDC is not a conceptual architecture pattern reserved for whiteboard discussions. It is production infrastructure used by enterprises in high-risk, high-volume environments where data latency directly impacts revenue, compliance, and customer trust.
How Financial Services Use CDC for Fraud Detection
In financial services, latency is risk. The time between when a transaction is committed and when it is analyzed determines the potential financial and reputational impact. Batch processes that execute hourly or nightly create exposure windows that fraudsters can exploit.
With PostgreSQL-based CDC, transaction data is streamed immediately after commit into fraud detection systems. Instead of waiting for scheduled extracts, scoring models receive events in near real time, enabling institutions to detect anomalies as they occur and intervene before funds are transferred or losses escalate.
CDC also plays a critical role beyond fraud detection. Financial institutions operate under strict regulatory requirements that demand accurate, timely reporting and clear audit trails. Because CDC captures ordered, transaction-level changes directly from the database log, it provides a reliable record of data movement and system state over time. This strengthens internal controls and supports compliance with regulatory frameworks such as SOX and PCI DSS.
In environments where milliseconds matter and oversight is non-negotiable, PostgreSQL CDC becomes foundational, not optional.
Improving Manufacturing and Supply Chains with CDC
Manufacturing and logistics environments depend on precise coordination across systems, facilities, and partners. When inventory counts, production metrics, or shipment statuses fall out of sync—even briefly—the impact cascades quickly: missed deliveries, excess working capital tied up in stock, delayed production runs, and strained supplier relationships.
PostgreSQL CDC enables real-time operational visibility by streaming changes from production databases as soon as they are committed. Inventory updates propagate immediately to planning and ERP systems. Equipment readings and production metrics surface in monitoring dashboards without delay. Shipment status changes synchronize across distribution and customer-facing platforms in near real time.
This continuous flow of operational data reduces reconciliation cycles and shortens response times when disruptions occur. Instead of reacting at the end of a shift or after a nightly batch run, teams can intervene the moment anomalies appear.
As a result, teams can achieve fewer bottlenecks, more accurate inventory positioning, improved service levels, and stronger resilience across the supply chain. According to Deloitte’s 2025 Manufacturing Outlook, real-time data visibility is no longer a competitive differentiator—it is a baseline requirement for operational resilience in modern manufacturing environments.
Using CDC to Supercharge AI and ML
CDC and AI are tightly coupled at the systems level because machine learning pipelines are only as good as the freshness and integrity of the data they consume. A model can be well-architected and properly trained, but if inference runs against stale features, performance degrades. Feature drift accelerates, predictions lose calibration, recommendation relevance drops, and anomaly detection shifts from proactive to post-incident analysis.
When PostgreSQL is the system of record for transactional workloads, Change Data Capture provides a log-based, commit-ordered stream of row-level mutations directly from the WAL. Instead of relying on periodic snapshots or bulk extracts, every insert, update, and delete is propagated downstream in near real time. This allows feature stores, streaming processors, and model inference services to consume a continuously synchronized representation of operational state.
From an architectural perspective, CDC enables:
- Low-latency feature pipelines. Transactional updates are transformed into feature vectors as they occur, keeping online and offline feature stores aligned and reducing training-serving skew.
- Continuous inference. Models score events or entities immediately after state transitions, rather than waiting for batch windows.
- Incremental retraining workflows. Data drift detection and model retraining pipelines can trigger automatically based on streaming deltas instead of scheduled jobs.
This foundation unlocks several high-impact use cases:
- Predictive maintenance. Operational metrics, maintenance logs, and device telemetry updates flow into forecasting models as state changes occur. Risk scoring and failure probability calculations are recomputed continuously, enabling condition-based interventions instead of fixed maintenance intervals.
- Dynamic pricing. Pricing engines respond to live transaction streams, inventory adjustments, and demand fluctuations. Instead of recalculating prices from prior-day aggregates, models adapt in near real time, improving margin optimization and market responsiveness.
- Anomaly detection at scale. Fraud signals, transaction irregularities, healthcare metrics, or infrastructure deviations are evaluated against streaming baselines. Detection models operate on current behavioral patterns, reducing false positives and shrinking mean time to detection.
Beyond traditional ML, CDC is increasingly foundational for agent-driven architectures. Autonomous AI agents depend on accurate, synchronized context to execute decisions safely.
Whether the agent is approving a transaction, escalating a fraud alert, adjusting supply chain workflows, or personalizing a customer interaction, it must reason over the current state of the system. Streaming PostgreSQL changes into vector pipelines, retrieval layers, and orchestration frameworks ensures that agents act on authoritative data rather than lagging replicas.
By propagating committed database changes directly into feature engineering layers, inference services, and agent runtimes, CDC aligns operational systems with AI systems at the data plane. The result is tighter feedback loops, reduced model drift, and intelligent systems that operate on real-time truth rather than delayed approximations.
CDC Implementation Methods for PostgreSQL
PostgreSQL provides multiple ways to implement Change Data Capture (CDC). The right approach depends on performance requirements, operational tolerance, architectural complexity, and how much engineering ownership teams are prepared to assume.
Broadly, CDC in PostgreSQL is implemented using:
- Logical decoding (native WAL-based capture)
- Trigger-based CDC
- Third-party platforms that leverage logical decoding
Each option comes with trade-offs in scalability, maintainability, and operational overhead.
Logical Decoding: The Native Approach
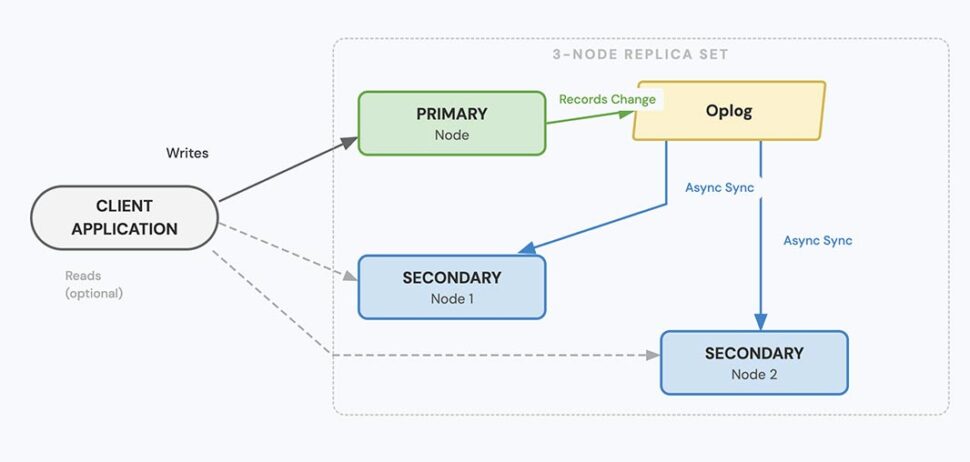
Logical decoding is PostgreSQL’s built-in mechanism for streaming row-level changes. It works by reading from the Write-Ahead Log (WAL) — the transaction log that records every committed INSERT, UPDATE, and DELETE before those changes are written to the actual data files.
Instead of polling tables or adding write-time triggers, logical decoding converts WAL entries into structured change events that downstream systems can consume.
To enable logical decoding, PostgreSQL requires:
- wal_level = logical
- Configured replication slots
- A logical replication output plugin
How It Works Under the Hood
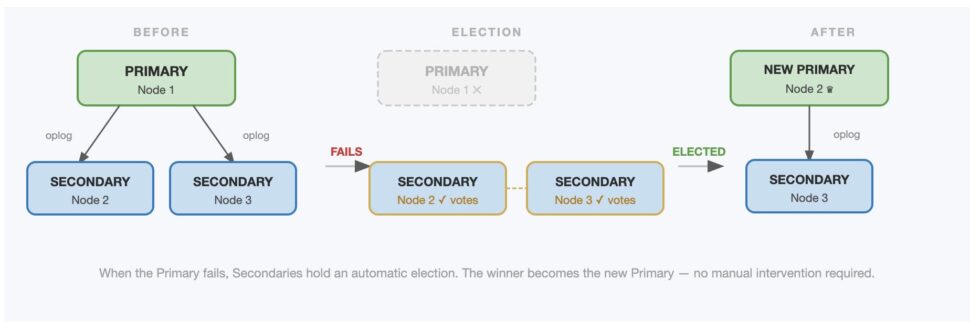
Replication slots
Replication slots track how far a consumer has progressed through the WAL stream. PostgreSQL retains WAL segments needed by each slot until the consumer confirms they’ve been processed. This ensures changes are not lost — even if the downstream system disconnects temporarily.
However, replication slots must be monitored. If a consumer becomes unavailable or falls too far behind, WAL files continue accumulating. Without safeguards, this can consume disk space and eventually affect database availability. PostgreSQL 13 introduced max_slot_wal_keep_size to help limit retained WAL per slot, but monitoring replication lag remains essential.
Output plugins
Output plugins define how decoded changes are formatted. Common options include:
- pgoutput — PostgreSQL’s native logical replication plugin
- wal2json — a widely used plugin that formats changes as JSON
Logical decoding captures row-level DML operations (INSERT, UPDATE, DELETE). It does not automatically provide a standardized stream of DDL events (such as ALTER TABLE), so schema changes must be managed carefully.
Why Logical Decoding Scales
Because logical decoding reads directly from the WAL instead of executing SELECT queries:
- It avoids full-table scans
- It does not introduce table locks
- It minimizes interference with transactional workloads
For high-volume production systems, this makes it significantly more efficient than polling or trigger-based alternatives.
That said, logical decoding introduces operational responsibility. Replication slot monitoring, WAL retention management, failover planning, and schema evolution handling all become part of your production posture.
Trigger-Based CDC: Custom but Costly
Trigger-based CDC uses PostgreSQL triggers to capture changes at write time. When a row is inserted, updated, or deleted, a trigger fires and typically writes the change into a separate audit or changelog table. Downstream systems then read from that table.
This approach offers flexibility but comes with trade-offs.
Benefits
- Fine-grained control over what gets captured
- Works on older PostgreSQL versions that predate logical replication
- Allows embedded transformation logic during the write operation
Drawbacks
- Performance overhead. Triggers execute synchronously inside transactions, adding latency to every write.
- Scalability limits. High-throughput systems can experience measurable degradation.
- Maintenance burden. Changelog tables must be pruned, indexed, and monitored to prevent growth and bloat.
- Operational complexity. Managing triggers across large schemas becomes difficult and error-prone.
Trigger-based CDC is typically reserved for low-volume systems or legacy environments where logical decoding is not an option.
Third-Party Platforms: Moving from Build to Buy
Logical decoding provides the raw change stream. Running it reliably at scale is a separate challenge. Production-grade CDC requires:
- Monitoring replication slot lag
- Managing WAL retention
- Handling schema changes
- Coordinating consumer failover
- Delivering to multiple downstream systems
- Centralized visibility and alerting
Open-source tools such as Debezium build on logical decoding and publish changes into Kafka. They are powerful and widely used, but they require Kafka infrastructure, configuration management, and operational ownership.
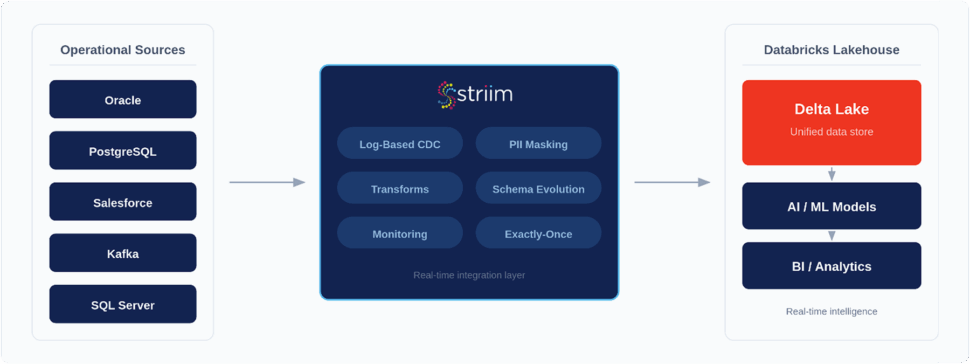
Striim for PostgreSQL CDC: Enterprise-Grade Change Data Capture with Schema Evolution
Capturing changes from PostgreSQL is only half the battle. Running CDC reliably at scale — across cloud-managed services, hybrid deployments, and evolving schemas — requires more than basic replication. Striim’s PostgreSQL change capture capabilities are built to handle these challenges for production environments.
Striim reads change data from PostgreSQL using logical decoding, providing real-time, WAL-based capture without polling or heavy load on production systems. In Striim’s architecture, CDC pipelines typically consist of an initial load (snapshot) followed by continuous change capture using CDC readers.
Broad Support for PostgreSQL and PostgreSQL-Compatible Services
Striim supports real-time CDC from an extensive set of PostgreSQL environments, including:
- Self-managed PostgreSQL (9.4 and later)
- Amazon Aurora with PostgreSQL compatibility
- Amazon RDS for PostgreSQL
- Azure Database for PostgreSQL
- Azure Database for PostgreSQL – Flexible Server
- Google Cloud SQL for PostgreSQL
- Google AlloyDB for PostgreSQL
This means you can standardize CDC across on-premises and cloud platforms without changing tools, processes, or integration logic.
For detailed setup and prerequisites for reading from PostgreSQL, see the official Striim PostgreSQL Reader documentation.
WAL-Based Logical Decoding for Real-Time Capture
Striim leverages PostgreSQL’s native logical replication framework. Change events are extracted directly from the Write-Ahead Log (WAL) — the same transaction log PostgreSQL uses for replication — and streamed into Striim CDC pipelines. This ensures:
- Capture of row-level DML operations (INSERT, UPDATE, DELETE)
- Ordered, commit-consistent change events
- Minimal impact on production workloads (no table scans or polling)
- Near real-time delivery for downstream systems
Because Striim uses replication slots, change data is retained until it has been successfully consumed, protecting against temporary downstream outages and ensuring no data is lost.
Initial Load + Continuous CDC
Many CDC use cases require building an initial consistent snapshot before streaming new changes. Striim supports this pattern by combining:
- Database Reader for an initial point-in-time load
- PostgreSQL CDC Reader for continuous WAL-based change capture
This dual-phase approach avoids downtime and ensures a consistent starting state before real-time replication begins.
Built-In Schema Evolution (DDL) Support
One of the most common causes of pipeline failures in CDC is schema change. Native PostgreSQL logical decoding captures DML, but schema changes like adding or dropping columns don’t appear in the WAL stream in a simple “event” format.
Striim addresses this with automated schema evolution. When source schemas change, Striim detects those changes and adapts the CDC pipeline accordingly. This reduces the need for manual updates and prevents silent errors or pipeline breakage due to schema drift. Automatic schema evolution is especially valuable in agile environments with frequent development cycles or ongoing database enhancements.
In-Motion Processing with Streaming SQL
Striim’s CDC capabilities are more than just change capture. Its Streaming SQL engine lets you apply logic in real time while data flows through the pipeline, including:
This in-flight processing ensures downstream systems receive data that is not only fresh, but also clean, compliant, and ready for analytics or operational use.
Production Observability and Control
Running CDC at scale requires visibility and control. Striim provides:
- Visualization dashboards for pipeline health and status
- Replication lag and throughput monitoring
- Alerts for failures or lag spikes
- Centralized management across all CDC streams
This turns PostgreSQL CDC from a low-level technical task into a manageable, observable data service suitable for enterprise environments.
Powering Agentic AI with Striim and Postgres
Agentic AI systems don’t just analyze data, they act on it. But autonomous agents are only as effective as the data they act on. If they operate on stale or inconsistent inputs, decisions degrade quickly. Striim connects real-time PostgreSQL CDC directly to AI-driven pipelines, ensuring agents operate on live, commit-consistent data streamed from the WAL. Every insert, update, and delete becomes part of a continuously synchronized context layer for inference and decision-making. Striim also embeds AI capabilities directly into streaming pipelines through built-in agents:
- Sherlock AI for sensitive data discovery
- Sentinel AI for real-time protection and masking
- Euclid for vector embeddings and semantic enrichment
- Foreseer for anomaly detection and forecasting
This allows enterprises to classify, enrich, secure, and score data in motion — before it reaches downstream systems or AI services. By combining real-time CDC, in-flight processing, schema evolution handling, and AI agents within a single platform, Striim enables organizations to move from passive analytics to production-ready, agentic AI systems that operate on trusted, real-time data.
Frequently Asked Questions
What is Change Data Capture (CDC) in PostgreSQL?
Change Data Capture (CDC) in PostgreSQL is the process of capturing row-level changes — INSERT, UPDATE, and DELETE operations — and streaming those changes to downstream systems in near real time.
In modern PostgreSQL environments, CDC is typically implemented using logical decoding, which reads changes directly from the Write-Ahead Log (WAL). This allows systems to process incremental updates without scanning entire tables or relying on batch jobs.
How does PostgreSQL logical decoding work?
Logical decoding reads committed changes from the WAL and converts them into structured change events. It uses:
- Replication slots to track consumer progress and prevent data loss
- Output plugins (such as pgoutput or wal2json) to format change events
This approach avoids table polling and minimizes impact on transactional workloads, making it suitable for high-throughput production systems when properly monitored.
What are the main ways to implement CDC in PostgreSQL?
There are three common approaches:
- Logical decoding (native WAL-based capture)
- Trigger-based CDC, where database triggers write changes to audit tables
- CDC platforms that build on logical decoding and provide additional monitoring, transformation, and management capabilities
Logical decoding is the modern standard for scalable CDC implementations.
Does CDC affect PostgreSQL performance?
Yes, CDC introduces overhead — but the impact depends on how it’s implemented.
Logical decoding consumes CPU and I/O resources to read and decode WAL entries, but it does not add locks to tables or require full-table scans. Trigger-based approaches, by contrast, add overhead directly to write transactions.
Proper configuration, infrastructure sizing, and replication lag monitoring are essential to maintaining performance stability.
Can CDC handle schema changes in PostgreSQL?
Schema changes — such as adding columns or modifying data types — are a common operational challenge.
PostgreSQL logical decoding captures row-level DML events but does not automatically standardize DDL changes for downstream systems. As a result, native CDC implementations often require manual updates when schemas evolve.
Enterprise platforms such as Striim provide automated schema evolution handling, allowing pipelines to adapt to source changes without breaking or requiring downtime.
How does Striim capture CDC from PostgreSQL?
Striim captures PostgreSQL changes using native logical decoding. It reads directly from the WAL via replication slots and streams ordered, commit-consistent change events in real time.
Striim supports CDC from:
- Self-managed PostgreSQL
- Amazon RDS and Aurora PostgreSQL
- Azure Database for PostgreSQL
- Google Cloud SQL for PostgreSQL
- Google AlloyDB for PostgreSQL
This enables consistent CDC across hybrid and multi-cloud environments.
Can Striim write to PostgreSQL and AlloyDB?
Yes. Striim can write to both PostgreSQL and PostgreSQL-compatible systems, including Google AlloyDB.
This supports use cases such as:
- PostgreSQL-to-PostgreSQL replication
- Migration from PostgreSQL to AlloyDB
- Continuous synchronization across environments
- Hybrid and multi-cloud architectures
Striim supports DML replication and handles schema evolution during streaming, making it suitable for production-grade database modernization.
Can Striim perform an initial load and continuous CDC?
Yes. Striim supports a two-phase approach:
- An initial bulk snapshot of source tables
- Seamless transition into continuous WAL-based change streaming
This allows organizations to migrate or synchronize databases without downtime while maintaining transactional consistency.
Why would a company choose Striim instead of managing logical decoding directly?
Native logical decoding is powerful, but running it reliably at scale requires:
- Monitoring replication slot lag
- Managing WAL retention
- Handling schema drift
- Building monitoring and alerting systems
- Coordinating failover and recovery
Striim builds on PostgreSQL’s native capabilities while abstracting operational complexity. It provides centralized monitoring, in-stream transformations, automated schema handling, and enterprise-grade reliability — reducing operational risk and accelerating time to production.
Unlock the Full Potential of CDC in PostgreSQL with Striim
PostgreSQL CDC is the foundational infrastructure for any enterprise that needs its analytical, operational, and AI systems to reflect reality—not yesterday’s static snapshot. From native logical decoding to fully managed platforms, the implementation path you choose determines how much value you extract and how much engineering effort you waste.
The core takeaway: CDC isn’t just about data replication. It’s about making PostgreSQL data instantly useful across every system that depends on it.
Striim makes this straightforward. With real-time CDC from PostgreSQL, in-stream transformations via Streaming SQL, automated schema evolution, and built-in continuous data validation, Striim delivers enterprise-grade intelligence without the burden of a DIY approach. Our Active-Active architecture ensures zero downtime, guaranteeing that your data flows reliably at scale.
Whether you’re streaming PostgreSQL changes to Snowflake, feeding real-time context into Databricks, or powering autonomous AI agents with Model Context Protocol (MCP), Striim provides the processing engine and operational reliability to do it flawlessly.
Ready to see it in action? Book a demo to explore how Striim handles PostgreSQL CDC in production, or start a free trial and build your first real-time pipeline today.