Overview
We’d like to demonstrate how you can migrate Oracle data to Microsoft Azure SQL Server running in the cloud, in real time, using Striim and change data capture (CDC).
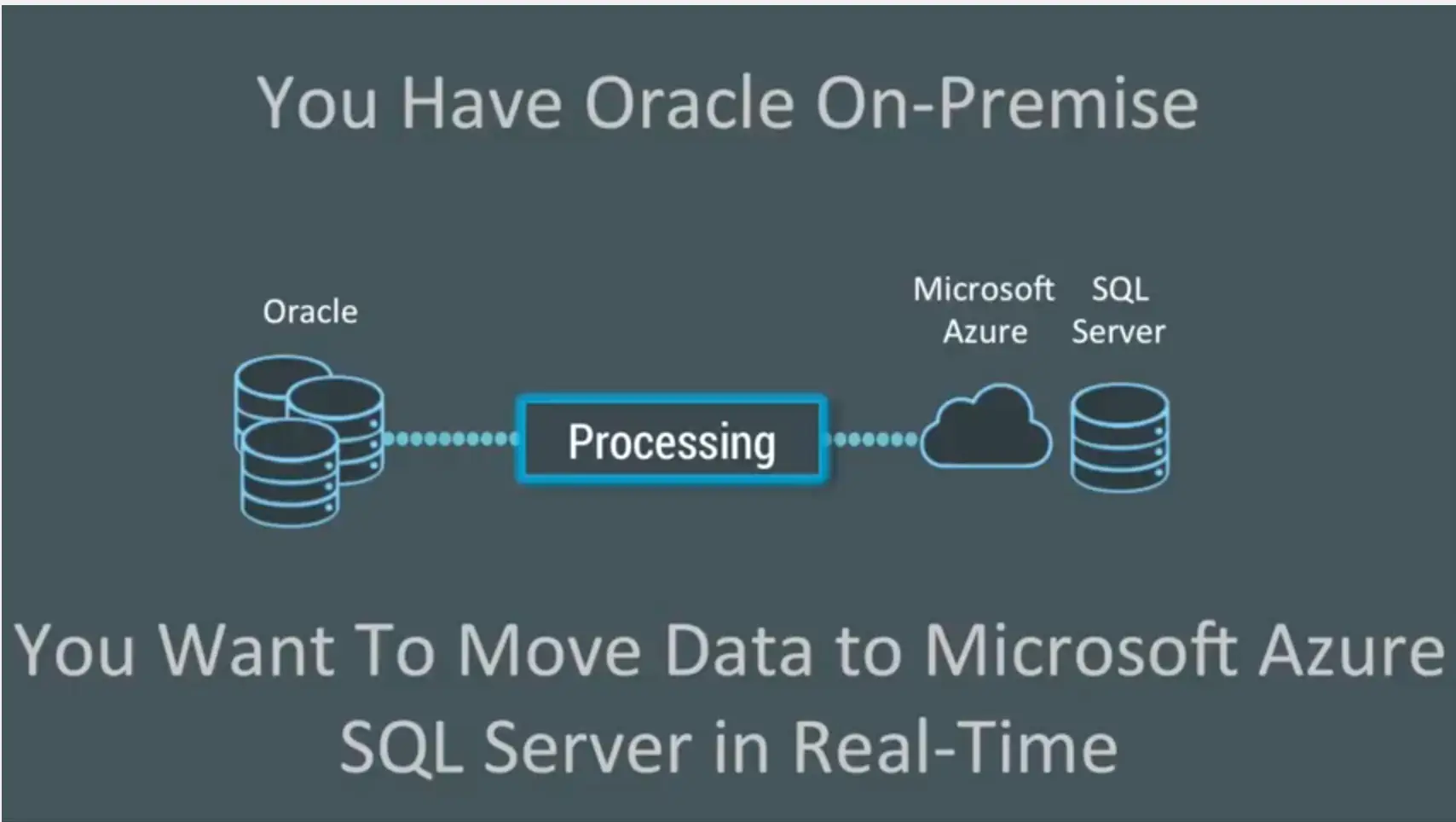
People often have data in lots of Oracle tables, on-premise. They want to migrate Oracle data into Microsoft Azure SQL Server, in real-time. How do you go about moving data from Oracle to Azure without affecting your production databases?
https://www.youtube.com/watch?v=iglW9aJCUlE
You can’t use SQL queries because typically these would be queries against a timestamp – like table scans that you do over and over again – and that puts a load on the Oracle Database. You might also skip important transactions. You need change data capture (CDC) which enables non-intrusive collection of streaming database change.
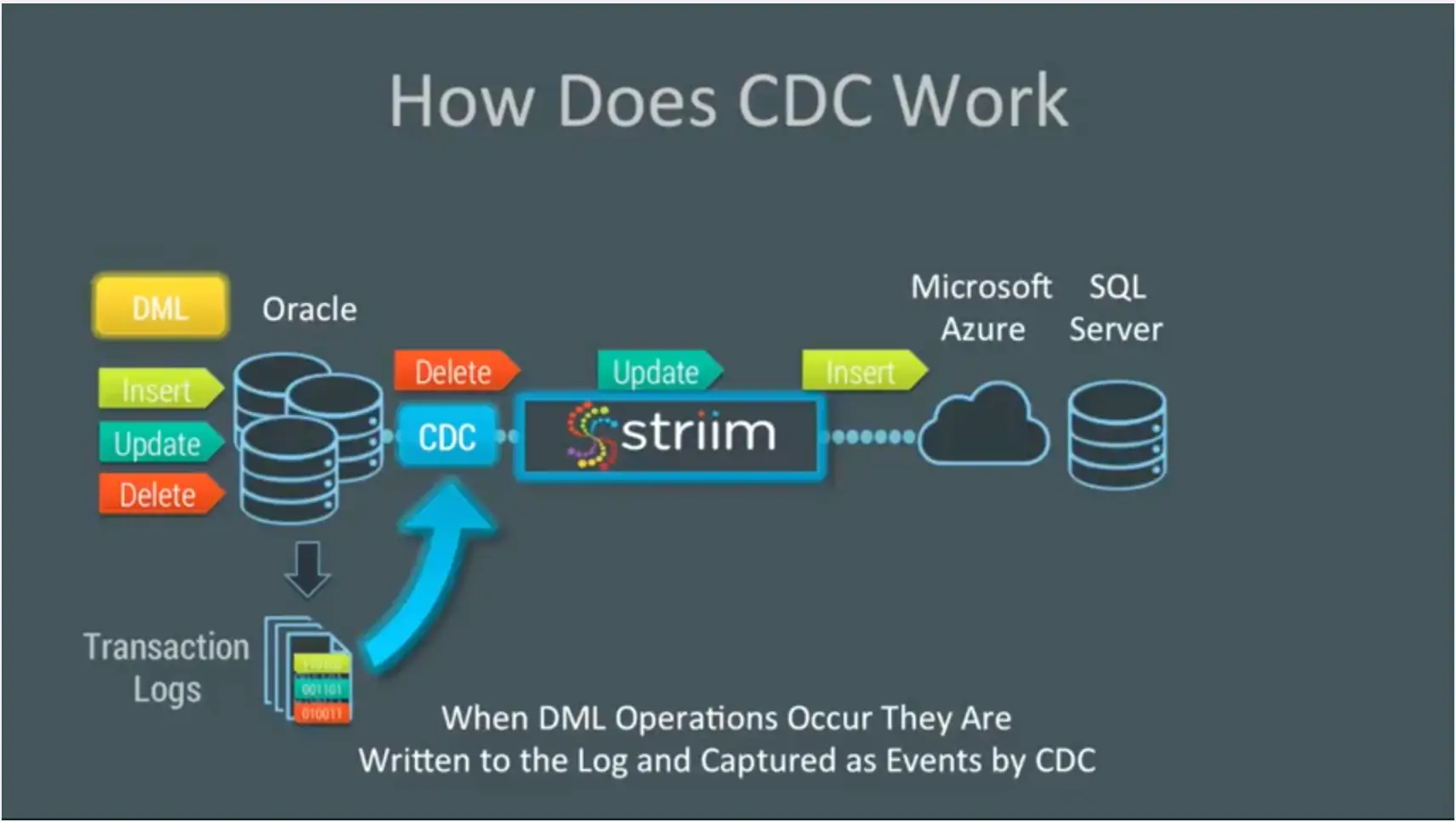
Striim provides change data capture as a collector out of the box. This enables real-time collection of change data from Oracle SQL Server and MySQL. CDC works because databases write all the operations that occur into transaction logs. Change data capture listens to those transaction marks, instead of using triggers or timestamps, and directly reads these logs to collect operations. This means that every DML operation – every insert, update, and delete – is written to the logs captured by change data capture and turned into events by our platform.
In this demo, you will see how you can utilize Striim to do real-time collection of change data capture from Oracle Database and deliver that data, in real-time, into Microsoft Azure SQL Server. We also build a custom monitoring solution of the whole end-to-end data flow. The demo starts at the 1:43 mark.
Connect to Microsoft Azure SQL Server
First, we connect to Microsoft Azure SQL Server. In this instance, we have two tables: TCUSTOMER and TCUSTORD, that we can show are currently completely empty. We use a data flow that we’ve built in Striim to capture data from an on-premise Oracle database using change data capture. You can see the configuration properties, and deliver the data (after doing some processing) into Microsoft Azure SQL Server.
To show this, we run some SQL against Oracle. This SQL does a combination of inserts, updates, and deletes against our two Oracle tables. When we run this, you can see the data immediately in the initial stream. That data stream is then split into multiple processing steps and then delivered into a Azure SQL Server. If we redo the query against our Azure tables, you can see that the previously empty tables now have data in them. That data was delivered live and will continue to be delivered in a streaming fashion as long as changes are happening in the Oracle database.
In addition to the data movement, we’ve also built a monitoring application complete with dashboard that shows data flowing through the various tables, the types of operations occurring, and the entire end-to-end transaction lag. This shows the difference between when a transaction was committed on the source system, and when it was captured and applied to the target. You can also see some of the most recent transactions.
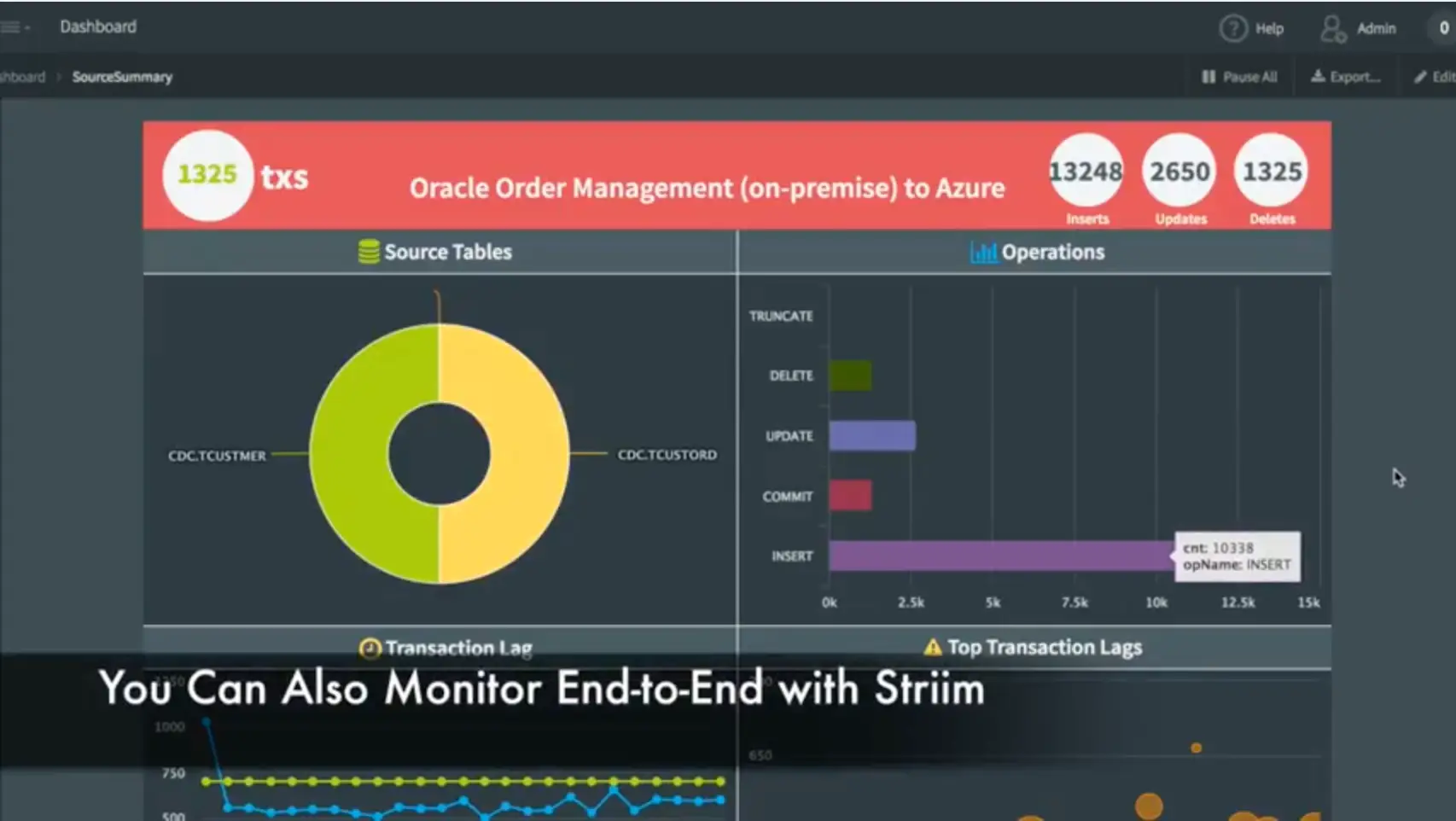
This monitoring application was built, again, using a data flow within the Striim platform. This data flow uses the original streaming change data from the Oracle Database and then applies some processing in the form of SQL queries to generate statistics. In addition to generating data for the dashboard, you can also use this as rules to generate alerts for thresholds, etc. The dashboard itself is not hard-coded. It’s generated using a dashboard builder which utilizes queries to connect to the back-end. Each visualization is powered by a query against the back-end data. There are lots of visualizations to choose from.
We hope you have enjoyed seeing how to migrate Oracle data into the cloud using Striim via the Oracle to Azure demo. If you would like a more in-depth look at this application, please request a demo with one of our lead technologists.