
Not all data pipelines are created equal. Brittle, rigid, and too slow for the pace of modern business—too many legacy data pipelines are holding organizations back from delivering true business impact.
Yet, data pipelines are the backbone of the modern enterprise. It’s time to move beyond ad-hoc batch processes and consider the best ways to design and build data pipelines optimized for low-latency, mission-critical reliability, and scalable operations.
This article provides a clear, practical guide to modern data pipelines. We’ll explore what they are, why they matter, and how they function in the real world—from powering real-time analytics and enabling seamless cloud migrations to feeding continuous, decision-ready data to enterprise AI applications.
Most importantly, you’ll leave with a clear build sequence, the key design decisions you need to make, and an understanding of what “good” looks like at each stage of the journey. Next, we’ll walk through a repeatable build process, including source identification, ingestion method selection (CDC vs APIs vs batch), your transformation approach (streaming ETL vs ELT), and continuous monitoring.
What are Data Pipelines?
Data pipelines are essentially automated processes that extract data from various sources, transform it into a usable format, and load it into a destination like a cloud data warehouse or data lake. You can think of them as the circulatory system for your enterprise data.
However, it’s critical to distinguish between simple data movement and robust data pipeline design. Simple data movement might involve a custom script copying a table from a database to a CSV file every night. It moves the data, but it lacks the robustness required for enterprise operations.
Modern data pipeline design encompasses much more than just moving bits and bytes. It involves ensuring reliability (handling network failures or schema changes automatically), observability (alerting when a pipeline breaks and exactly why), transformations (cleaning, joining, and enriching data in-flight), and governance (ensuring data security and compliance).
For example, a modern, real-time pipeline might keep a target like Snowflake or Google BigQuery continuously updated from a legacy transactional system like Oracle or SQL Server using Change Data Capture (CDC). This ensures that your analytics and downstream apps always see fresh operational changes the instant they happen.
Real-World Use Cases for Data Pipelines
The architectural benefits of robust data pipelines are clear, but how do they translate into tangible business value? Different outcomes require different pipeline architectures: namely, batch processing, stream processing, or CDC-based replication. Let’s look at a few concrete examples:
- Cloud Migration and Replication: Enterprises moving off legacy infrastructure use pipelines to continuously sync on-premises databases to cloud targets with minimal disruption. By using log-based CDC, you can achieve zero-downtime migrations and keep hybrid environments perfectly in sync. (Requires: CDC-based replication)
- Customer 360 and Personalization: A retailer can ingest data from their e-commerce platform, point-of-sale systems, and CRM. By transforming and joining this data in-flight, they create a unified customer profile, enabling hyper-personalized marketing delivered the moment a customer interacts with the brand. (Requires: Streaming pipelines)
- Fraud and Security Monitoring: Financial institutions rely on sub-second data pipelines to analyze transaction streams in real time. By continuously monitoring for anomalous patterns, they can flag and block fraudulent transactions before they settle. (Requires: Streaming pipelines)
- Operational Alerting and Real-Time Analytics: Manufacturing companies collect sensor telemetry from the factory floor. By analyzing this data as it flows, they can detect equipment anomalies and trigger predictive maintenance alerts, minimizing costly downtime. (Requires: Streaming pipelines)
To support these outcomes, enterprise pipelines typically fall into one of three categories:
- Batch pipelines: Best for high-volume, historical analysis where latency is not a primary concern (e.g., end-of-month financial reporting).
- Streaming pipelines: Essential when data must be processed, enriched, and acted upon immediately (e.g., real-time fraud detection or personalization).
- CDC-based replication: The ideal approach for operational replication, keeping analytical systems seamlessly synchronized with transactional databases so dashboards always reflect the current state of the business.
How to Build a Data Pipeline
Building a data pipeline shouldn’t be a purely theoretical exercise. Whether you are building a simple batch export or a complex, real-time streaming architecture, taking a strategic, methodical approach is the best way to ensure reliability and scale for the long term.
Here’s a step-by-step guide to designing and constructing an enterprise-grade data pipeline.
1. Define Goals & Success Metrics
Before writing any code or selecting tools, define the business outcome and the required Service Level Agreement (SLA). “What good looks like” depends entirely on the use case.
Best Practice: Force the pipeline design decision early based on latency requirements. For example, if the goal is real-time fraud detection, the pipeline requires sub-second latency and continuous ingestion—pointing you immediately toward a streaming architecture. Conversely, if the goal is end-of-day financial reporting, the pipeline can tolerate batch processing, allowing you to optimize for throughput and compute costs rather than speed.
2. Identify Sources and Destinations
Map out exactly where the data lives and where it needs to go. Modern enterprises rarely have just one source. You might be pulling from relational databases (Oracle, PostgreSQL), NoSQL stores (MongoDB), SaaS applications (Salesforce), or flat files.
Best Practice: “Good” source identification includes auditing the source system’s limitations. Can the legacy database handle the load of frequent API polling? If not, you must consider low-impact methods like log-based CDC. Define your destination (e.g., Snowflake, BigQuery, Kafka) based on how downstream consumers (analysts or AI applications) need to access the data.
3. Choose a Replication Method and Handle Schema Changes
Arguably the most critical technical decision in your pipeline build: decide how data will move. It could be via API polling, batch extracts, or Change Data Capture (CDC).
Best Practice: For operational databases, log-based CDC is the gold standard. Instead of querying the database and degrading performance, CDC reads the transaction logs, capturing inserts, updates, and deletes with sub-second latency and minimal overhead. Crucially, consider how the pipeline handles schema changes (e.g., a column is added to the source database). A brittle pipeline will break; a robust pipeline uses automated schema evolution to detect the change and seamlessly propagate it to the target without downtime.
4. Determine Your Transformation Strategy (ETL vs. ELT)
Raw data is rarely ready for analytics or AI. It needs to be filtered, masked, joined, and aggregated. You must decide where this happens. In traditional ETL (Extract, Transform, Load), transformation happens in a middle tier before reaching the destination. In modern ELT (Extract, Load, Transform), raw data is loaded into the cloud data warehouse, and transformations are handled there using cloud compute.
Best Practice: For real-time use cases, streaming ETL is often the superior approach. By transforming data in-flight (e.g., masking PII or filtering out irrelevant events before it hits the warehouse), you reduce cloud storage and compute costs while ensuring the data landing in your destination is immediately decision-ready.
5. Monitor, Govern, and Iterate
In an enterprise context, data infrastructure is usually a mid to long term project. Day-two operations are what separate successful data teams from those drowning in technical debt.
Best Practice: Implement continuous monitoring for latency, throughput, and error rates. “Good” governance looks like this:
- Continuously: Monitor data flow and set up automated alerts for pipeline failures or latency spikes.
- Weekly: Review alert logs to identify transient errors or performance bottlenecks.
- Monthly: Run a reliability review. Assess how the pipeline handled any schema changes, evaluate mean time to recovery (MTTR) for any failures, and review cloud compute costs.
- Iteratively: Revisit the pipeline design whenever source systems upgrade, SLAs tighten, or downstream consumers change their requirements.
Common Challenges in Data Pipelines
Even the best-designed pipelines can encounter difficulties. Understanding the common pitfalls can help you build more resilient systems and choose the right tools to overcome them.
Latency and Data Freshness
Modern businesses demand real-time insights, but batch pipelines deliver stale data. This is one of the most common challenges, where the delay between an event happening and the data being available for analysis is too long. Striim solves this with log-based CDC, enabling continuous, sub-second data synchronization that keeps downstream analytics and applications perfectly current.
Poor Data Quality and Schema Drift
Poor data quality can corrupt analytics, break applications, and erode trust. A related challenge is schema drift, where changes in the source data structure (like a new column) cause downstream processes to fail. Striim addresses this head-on with in-pipeline data validation and schema evolution capabilities, which automatically detect and propagate source schema changes to the target, ensuring pipeline resilience.
Pipeline Complexity and Tool Sprawl
Many data teams are forced to stitch together a complex web of single-purpose tools for ingestion, transformation, and monitoring. This “tool sprawl” increases complexity, raises costs, and makes pipelines brittle and hard to manage. Striim unifies the entire pipeline into a single, integrated platform, reducing operational burden and simplifying the data stack.
Monitoring, Observability, and Alerting
When a pipeline fails, how quickly will you know? Without real-time visibility, troubleshooting becomes a painful, reactive exercise. Modern pipelines require built-in observability. Striim provides comprehensive health dashboards, detailed logs, and proactive alerting, giving teams the tools they need to monitor performance and recover from errors quickly.
Governance and Compliance
Meeting regulations like GDPR and HIPAA requires strict control over who can access data and how it’s handled. This is challenging in complex pipelines where data moves across multiple systems. Striim helps enforce governance with features to mask sensitive data in-flight, create detailed audit trails, and manage access controls, ensuring compliance is built into your data operations.
Data Lakes vs. Data Warehouses for Data Pipelines
Choosing where you store data is just as important as deciding how it gets there. The storage destination—typically a data lake or a data warehouse—will shape your pipeline’s design, cost, and capabilities. Understanding the differences is key to building an effective data architecture. Caption: Data lakes and data warehouses serve different purposes; lakes store raw data for exploration, while warehouses store structured data for analysis.
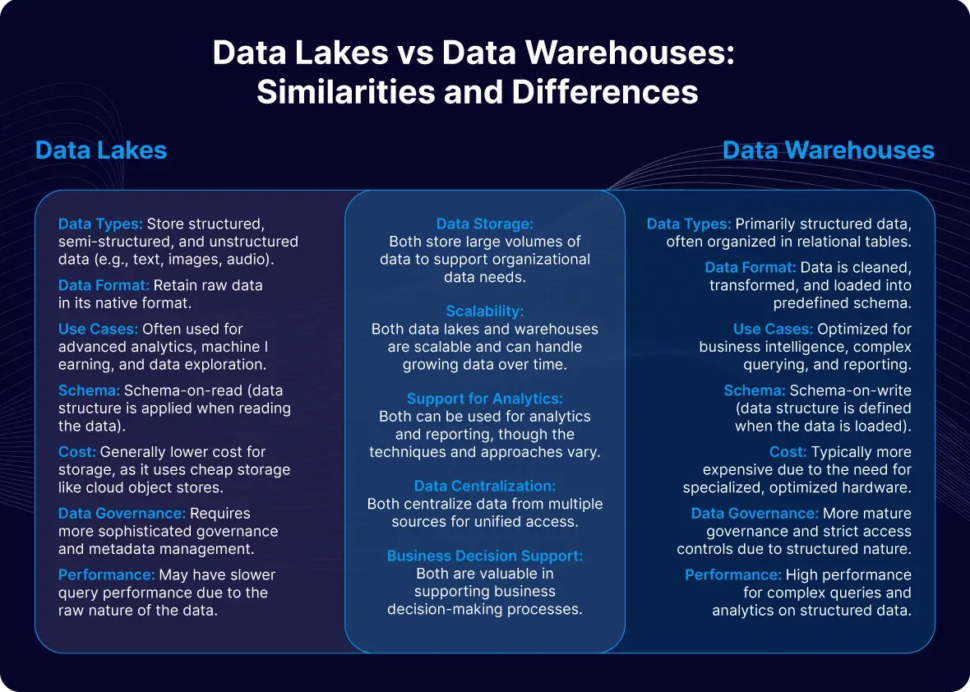
Differences in Storage Format and Schema
The fundamental difference lies in how they handle data structure. A data warehouse stores data in a highly structured, predefined format (schema-on-write). Data is cleaned and modeled before being loaded, making it optimized for fast, reliable business intelligence and reporting.
A data lake, by contrast, is a vast repository that stores raw data in its native format, structured or unstructured (schema-on-read). The structure is applied when the data is pulled for analysis, offering immense flexibility for data science, machine learning, and exploratory analytics where the questions aren’t yet known.
Choosing the Right Architecture for Your Pipeline
It’s not necessarily a binary choice between one or the other; many modern architectures use both.
- Use a data warehouse when your pipeline’s primary goal is to power standardized BI dashboards and reports with consistent, high-quality data.
- Use a data lake when you need to store massive volumes of diverse data for future, undefined use cases, or to train machine learning models that require access to raw, unprocessed information.
A unified platform like Striim supports this hybrid reality. You can build a single data pipeline that delivers raw, real-time data to a data lake for archival and exploration, while simultaneously delivering structured, transformed data to a data warehouse to power critical business analytics.
Choosing Tools and Tech to Power Your Data Pipelines
The data ecosystem is crowded. Every tool claims to be “real-time” or “modern,” but few offer true end-to-end data management capabilities. Navigating this landscape requires understanding the different categories of tools and where they fit.
Popular Open-Source and Cloud-Native Tools
The modern data stack is filled with powerful, specialized tools. Apache Kafka is the de facto standard for streaming data pipelines, but it requires significant expertise to manage. Airflow is a popular choice for orchestrating complex batch workflows. Fivetran excels at simple, batch-based data ingestion (ELT), and dbt has become the go-to for performing transformations inside the data warehouse. While each is strong in its niche, they often need to be stitched together, creating the tool sprawl and complexity discussed earlier.
Real-Time CDC and Stream Processing
This is where Striim occupies a unique position. It is not just another workflow tool or a simple data mover; it is a unified, real-time integration platform. By combining enterprise-grade, log-based Change Data Capture (CDC) for ingestion, a powerful SQL-based stream processing engine for in-flight transformation, and seamless delivery to dozens of targets, Striim replaces the need for multiple disparate tools. It provides a single, cohesive solution for building, managing, and monitoring real-time data pipelines from end to end.
Why Choose Striim for Your Data Pipelines?
Striim delivers real-time data through Change Data Capture (CDC), ensuring sub-second latency from source to target. But it’s about more than just speed. It’s a complete, unified platform designed to solve the most complex data integration challenges without requiring you to stitch together a fragmented web of point solutions.
From a tactical perspective, Striim maps perfectly to the modern pipeline build sequence. It handles non-intrusive ingestion via log-based CDC, executes in-flight transformations using a robust SQL-based streaming ETL engine, and provides continuous monitoring and automated schema evolution before delivering data to major cloud targets. Instead of juggling separate tools for extraction, processing, and loading, Striim unifies the entire lifecycle. Global enterprises trust Striim to power their mission-critical data pipelines because of its:
- Built-in, SQL-based Stream Processing: Filter, transform, and enrich data in-flight using a familiar SQL-based language.
- Low-Code/No-Code Flow Designer: Accelerate development with a drag-and-drop UI and automated data pipelines, while still offering extensibility for complex scenarios.
- Multi-Cloud Delivery: Seamlessly move data between on-premises systems and any major cloud platform.
- Enterprise-Grade Reliability: Ensure data integrity with built-in failover, recovery, and exactly-once processing guarantees.
Ready to stop wrestling with brittle pipelines and start building real-time data solutions? Book a demo with one of our experts or start your free trial today to discover Striim for yourself.
FAQs
Why are data pipelines important for cloud migration?
Cloud migrations often stall or fail due to extensive downtime and data inconsistencies between legacy and new systems. Real-time data pipelines solve this by continuously replicating data from on-premises systems to the cloud without interrupting operational workloads. By using log-based Change Data Capture (CDC), a pipeline can sync a legacy database to a modern target like Snowflake, achieving a zero-downtime migration while keeping hybrid environments in perfect sync.
When should you use change data capture (CDC) instead of API polling or scheduled extracts?
You should use CDC whenever you need sub-second latency and cannot afford to impact the performance of your source databases. API polling and batch extracts place a heavy query load on operational systems and only capture data at scheduled intervals. CDC, conversely, reads database transaction logs invisibly, capturing inserts, updates, and deletes exactly as they happen, making it the only reliable choice for real-time analytics and operational alerting.
How do you handle schema changes without breaking downstream dashboards or apps?
Brittle pipelines break whenever a source database adds or drops a column, leading to missing data, failed loads, and corrupted downstream dashboards. To handle this gracefully, modern pipelines must employ automated schema evolution. This capability detects DDL (Data Definition Language) changes at the source in real-time and automatically propagates those changes to the target data warehouse, eliminating hours of manual pipeline repairs.
What are the main 3 stages in a data pipeline?
The three foundational stages of a data pipeline are ingestion (Extract), processing (Transform), and delivery (Load). Ingestion securely captures data from source systems, ideally through real-time methods like CDC. Processing cleanses, filters, joins, and enriches the data—often in-flight via streaming ETL—so it is formatted for business use. Finally, delivery routes the decision-ready data into a target destination, such as a cloud data warehouse, a data lake, or directly into an AI application.
What should you validate in-flight to prevent bad data from reaching your warehouse?
Validating data in-flight is critical to maintaining a single source of truth and preventing costly downstream errors. You should check for schema conformity, null values in primary keys, and formatting anomalies (like an incorrectly formatted email address). Additionally, AI-native pipelines should govern sensitive data on the fly, instantly masking Personally Identifiable Information (PII) before it lands in the warehouse to ensure analytics and AI models are built on safe, trusted data.
What are some key barriers to building a data pipeline?
The most common barriers are legacy system constraints, deeply ingrained data silos, and a lack of specialized engineering talent. Legacy databases often lack modern APIs and crash under the weight of heavy batch extraction queries. Furthermore, orchestrating different point tools for ingestion, transformation, and monitoring creates a fragmented architecture that is difficult to scale—requiring unified platforms to simplify the process and guarantee reliable data delivery.













