Scaling The Adoption of our Enterprise Data Platform

I am very excited to officially announce that Striim has just received $50 million in Series C financing. I’m particularly pleased that it was led by Goldman Sachs, and also includes our existing investors including Summit Partners, Atlantic Bridge Ventures, Dell Ventures, and Bosch Ventures. Goldman has the most sophisticated technology radar of anyone in the finance industry, and what they saw in Striim was a next generation technology that could enable the cloud wave that’s breaking all over the world and disrupting essentially every enterprise in every industry vertical. All the credit goes to our team members, our customers and our partners for this recognition.
While many companies may use cloud for services like IaaS, backup storage, or web operations, only a small share of enterprises have moved their core workloads to the cloud. We expect that many more will be doing so over the next several years, with Striim as the engine driving and accelerating that digital transformation. Striim provides the ability to make real time data driven decisions by collecting, moving and processing data from multiple sources and delivering it to various cloud targets with low latency. Crucially, Striim can do this in an automated, scalable, secure, and reliable way, with very little configuration effort and no coding.
What this new infusion of financing will do is to allow Striim to strengthen its go-to-market capabilities to meet the exploding global demand for transitioning data to the cloud. That means significantly expanding the teams and building an expanded presence in EMEA, APAC, ANZ, and South America, as well as collaborating even more closely with our strategic partners, including Google and Microsoft.
This new financing will also help with an important new expansion of Striim’s product portfolio . Right now, the Striim platform is provided with OOTB features to build data pipelines – deployed on-premise, through cloud marketplaces, or as a containerized cloud solution. However, later this year we will be launching multiple products that provide fully managed cloud services, to comprehensively handle cloud data flows with zero administration, and in a highly available, and managed fashion for companies ranging from small businesses to large enterprises.
In addition to new funds, we are delighted to have a new board member, Bob Kelly, an operating partner for Goldman Sachs. Before he joined Goldman, Bob was an executive at Microsoft where he worked on the development of Microsoft’s cloud, Azure. He brings a great deal of experience to this area and he absolutely understands the potential significance of Striim’s technology in transforming the world’s economy into a fully digital one. Goldman’s participation in moving Striim forward is a huge vote of confidence in our people and what we are doing.
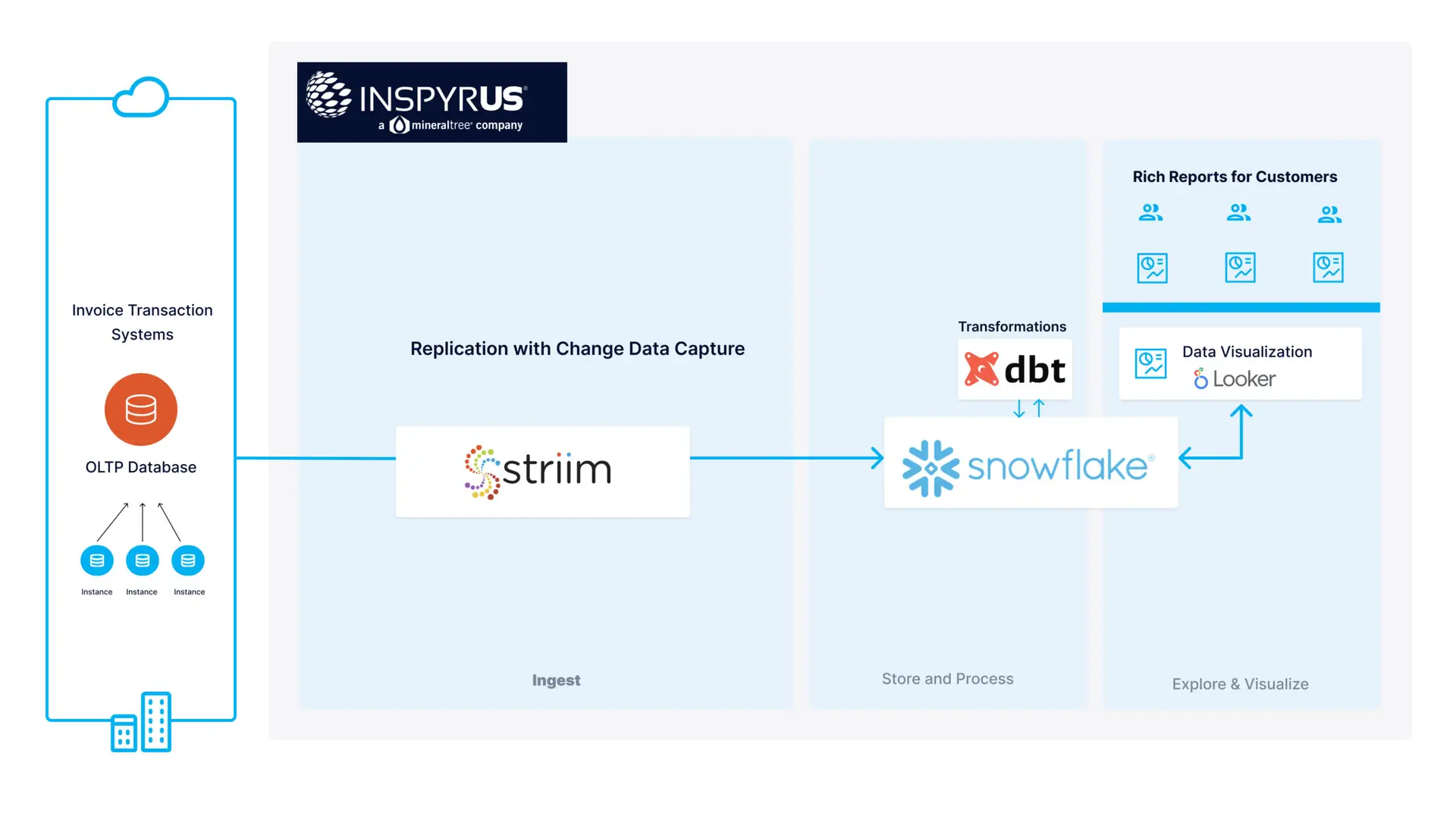
In this economy, the only constant is change. We are in a very dynamic market, serving a spectrum of similarly dynamic industries. It is crucial for these businesses to have accurate and timely information in order to make critical business decisions. One of the key aspects of our real-time data integration is a technology called Change Data Capture. Providing reliable change data capture that supports sustained high volumes across multiple databases is not an easy task, and typically was only supported by database replication technologies. However, we have coupled this with real-time ETL and streaming capabilities providing a unique combination that has been instrumental in our customers’ success as well as driving our partnerships with Google Cloud and Microsoft Azure to provide on-premise migrations to those cloud technologies.
We believe that Striim’s platform with our real-time data integration technology, and upcoming cloud services will provide the rarely-seen infrastructure enabling digital transformation of businesses in essentially every sector worldwide. And we are tremendously gratified by the vote of confidence that Goldman Sachs, Summit Partners, Atlantic Bridge Ventures, Dell Ventures and Bosch Ventures have shown in the work we are doing. Let’s go!