Introducing Striim Cloud on Google Cloud: a fully managed and unified cloud solution offering real time data streaming and integration
Insights-driven organizations grow an average of 30% per year, but with ever-increasing data sources, formats, and volumes, it’s a huge undertaking to integrate and unify it all. While homegrown tools, scripts, and third party utilities may offer temporary relief, it can become unwieldy to manage them across multiple teams and environments. And then you add in the need for low latency — because who wants stale data? — and the struggles with scalability to keep up with company growth.
With the release of Striim Cloud on Google. Remove data silos: Connect your sources and targets and manage your data pipelines within one console. Cloud, we’re excited to offer a solution for data scientists, database admins, and businesses that rely on data.
Starting today, Striim Cloud can be purchased on the Google Cloud marketplace. Striim Cloud on Google Cloud delivers five key benefits:
- Get started quickly: Launch smart data pipelines within ten minutes of sign up.
- Remove data silos: Connect your sources and targets and manage your data pipelines within one console.
- Reduce total cost of ownership: Replace multiple tools with a single platform. Pay as you go based on consumption and quickly scale as needed.
- Ensure business continuity: Protect your business with daily backups, disaster recovery, uptime SLA of 99.5% and high availability.
- Rest easy with enterprise-grade features: Proven at enterprise scale with petabytes of data securely and reliably moved every day to the cloud.
Striim Cloud is built on our popular Striim Enterprise platform – proven at enterprise scale. Even though Striim Cloud is designed with simplicity in mind, it is also secure, reliable, and comprehensive.
Striim Cloud gives you extensive options to control and customize your data pipelines. Services come with daily backups, built-in disaster recovery and an uptime SLA of 99.5%. This blog will take you through a sample use case, but Striim Cloud is capable of much more than this specific use case.
Striim Cloud offers great return-on-investment and delivers immediate value to cloud customers as shown below:

Striim Cloud Example Use Case: Build a Ticketing Application on Google BigQuery
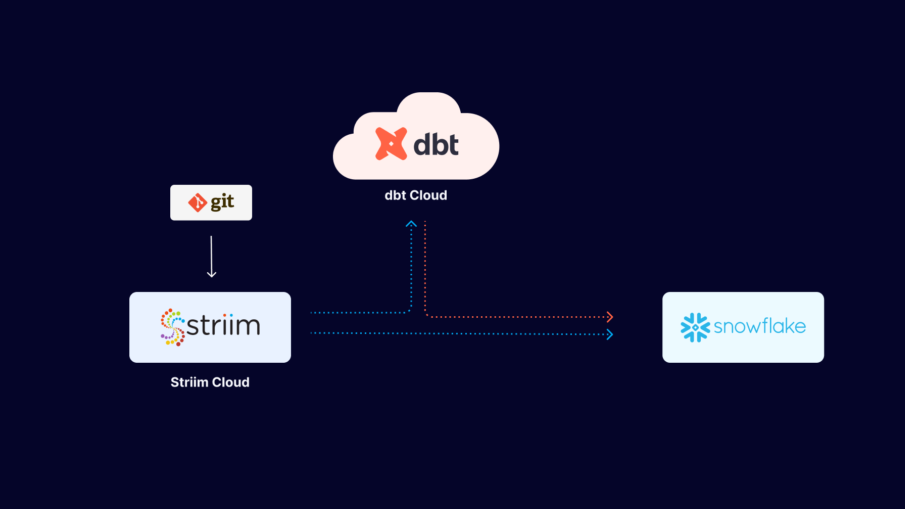
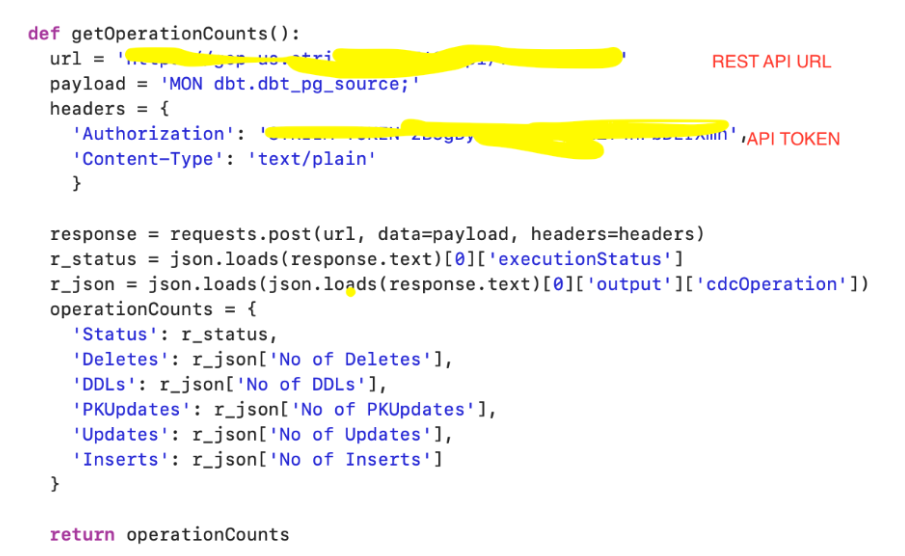
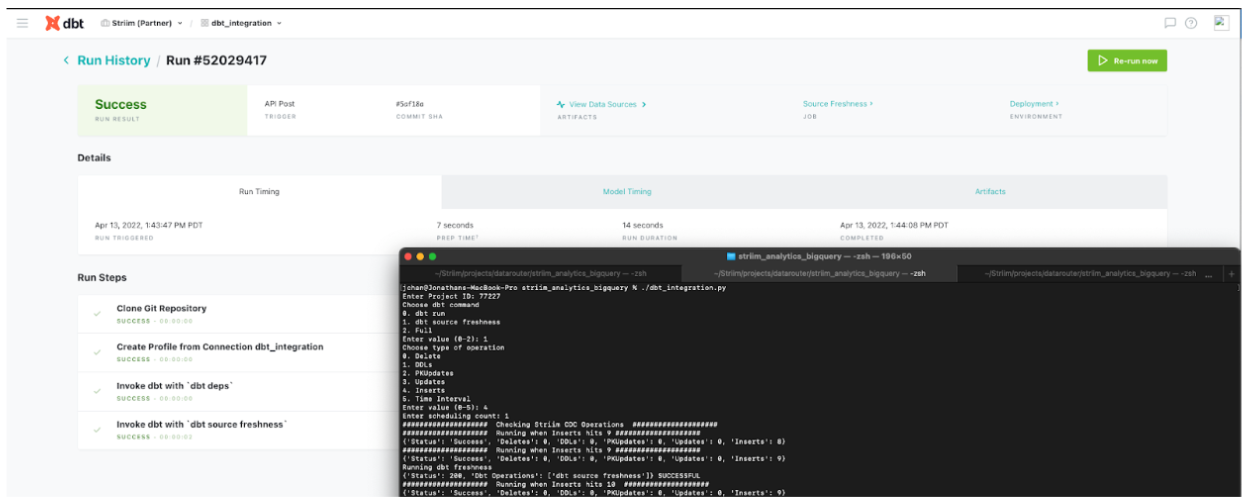
To give you a quick tour of Striim Cloud, we’re going to walk through a use case for a ticketing application used to sell tickets for football and baseball games. The app is running an on-premise Oracle database. Our objective is to move data to BigQuery with millisecond latency so we can analyze the data and glean insights — like the number of tickets sold by game, by state, or by stadium — to facilitate real-time business decisions. The same flow is shown in the architecture diagram below, along with other capabilities of Striim Cloud on Google Cloud.

Start by going to the Striim Cloud Enterprise solution on the Google Cloud Marketplace. Go through the standard marketplace SaaS solution purchase flow and sign up with Striim Cloud as shown in the image below. Alternatively, you can also sign up for the trial from Striim.com.

Once you sign up for Striim Cloud, it takes less than ten minutes to get your first data pipeline up and running through a simple and intuitive user flow. It’s a three step process:
- Create a cloud service
- Create a Striim app for your data pipeline
- Set up content and speed
Create a cloud service:
In this step you only need to provide the cluster name — Striim Cloud applies smart defaults for everything else. However, if desired you can change the default cluster size, modify security options, sign-in options, user roles, and more.

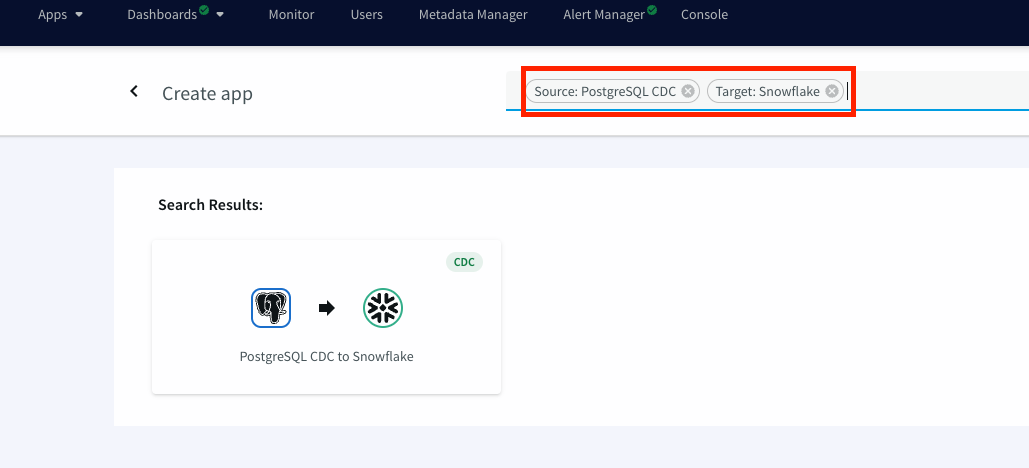
Create an app for your smart data pipeline:
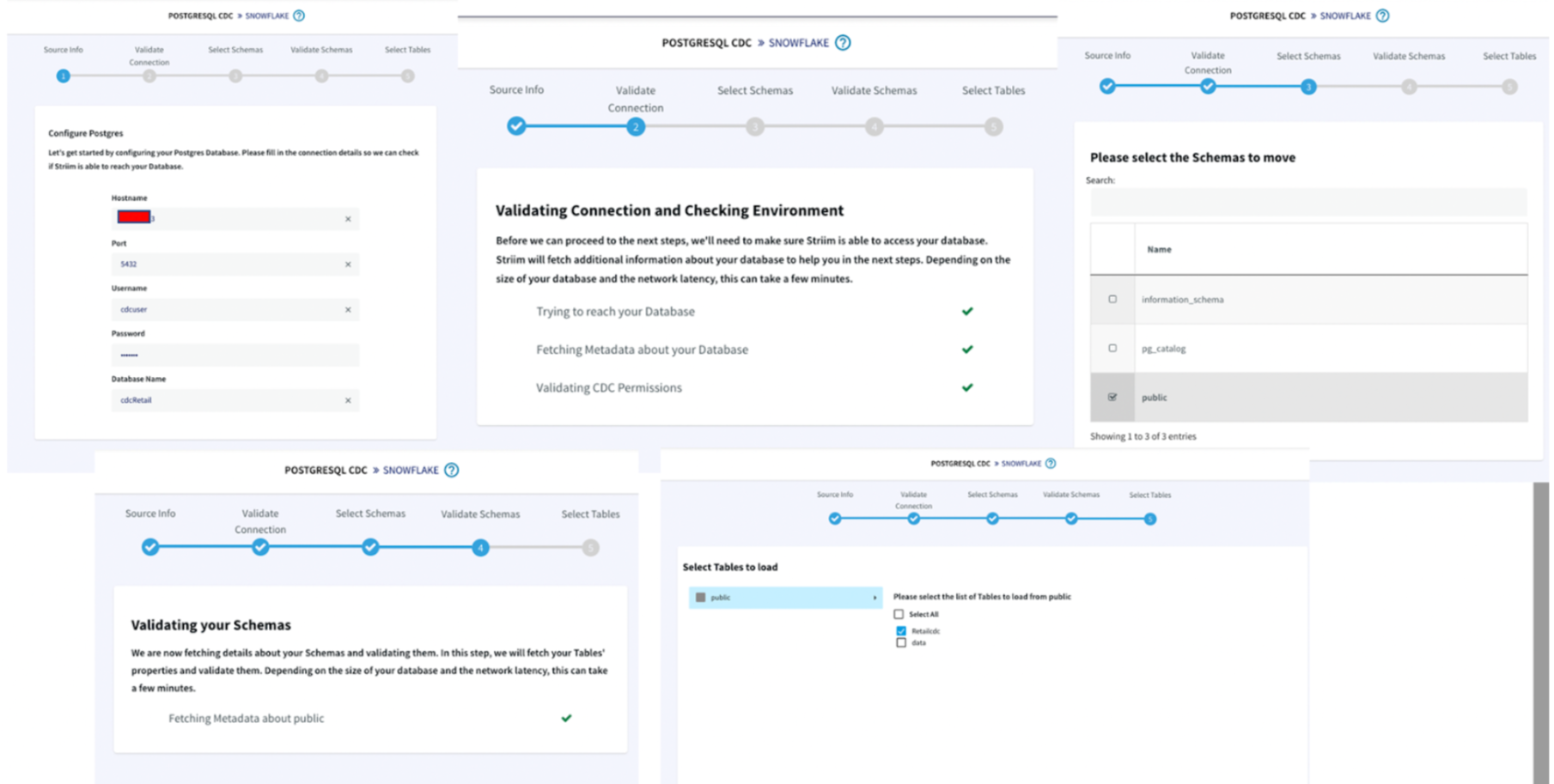
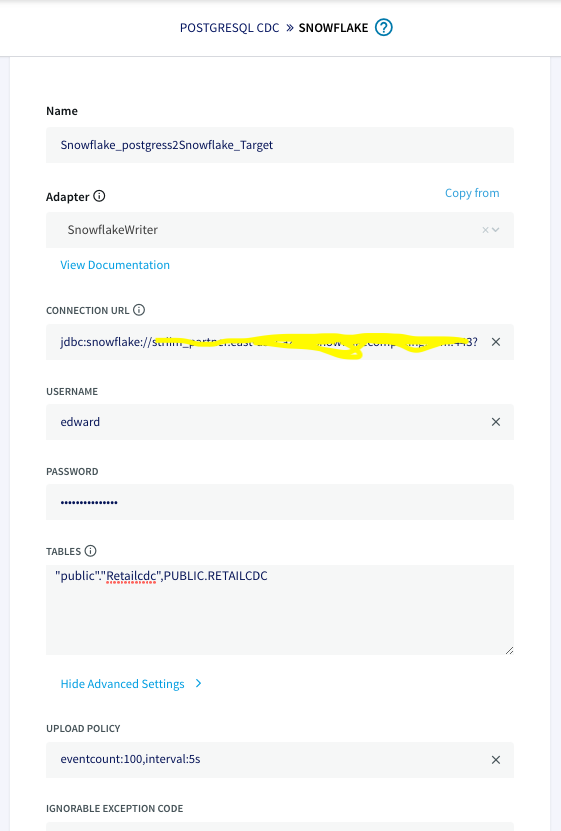
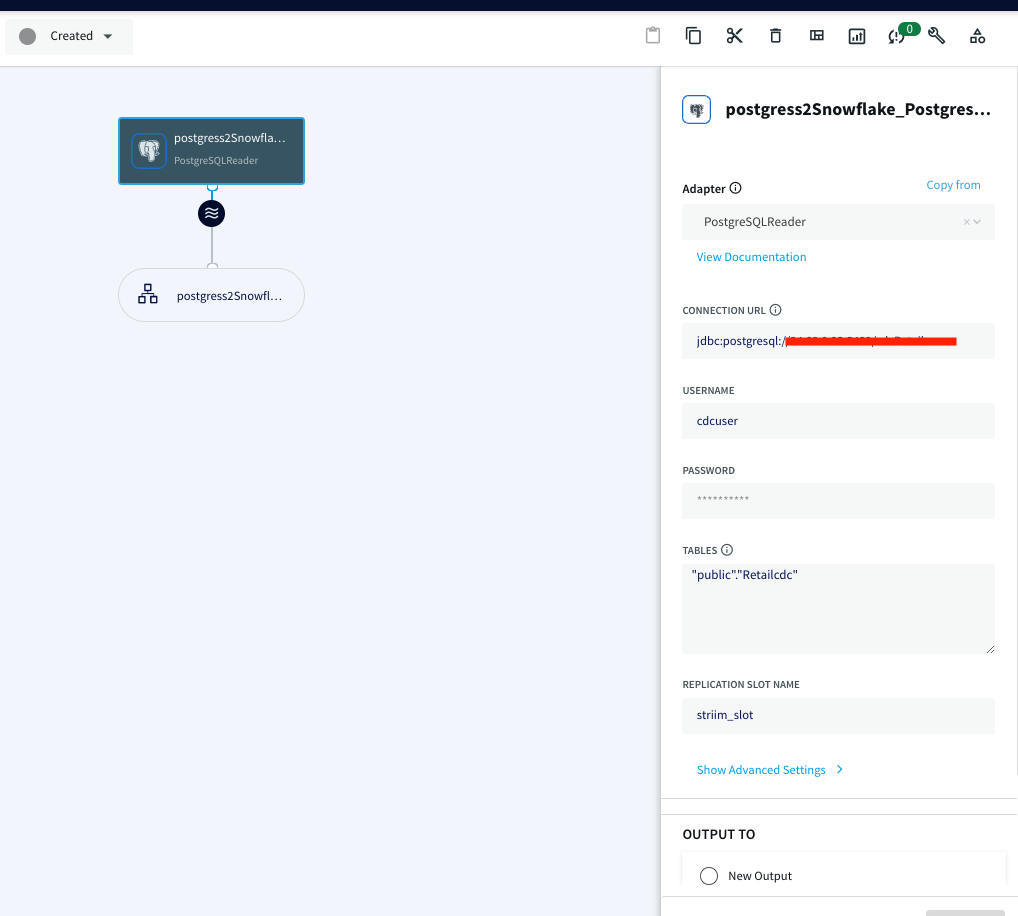
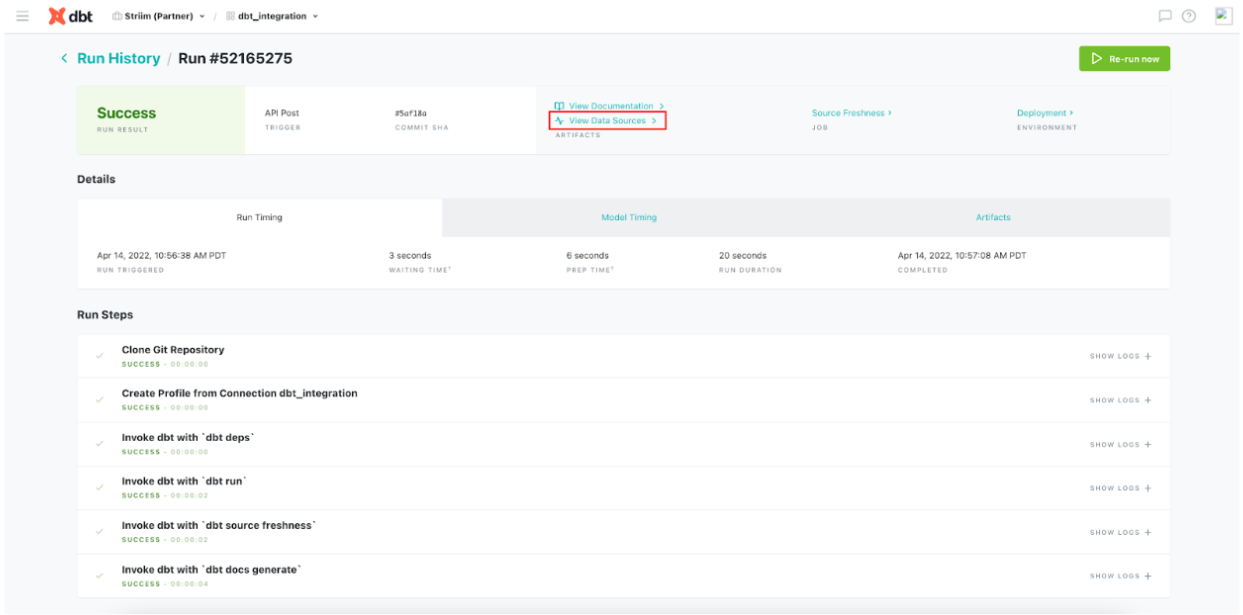
Next, you create a Striim app — essentially a data pipeline — using drag-and-drop elements or a wizard-based flow. Once again, Striim Cloud automatically applies smart defaults in the app. In our example, we’re creating an Oracle to BigQuery pipeline with source and target credentials for Striim Cloud to connect securely. Striim Cloud connects and validates the connection in this step for a better user experience.


Set up content and speed:
In the third and final configuration steps, select content like schemas, collections, and tables on the source and map to the corresponding schemas, collections, and tables on the target. Striim Cloud automatically does most of the heavy lifting including auto-schema conversions and data-type conversions.
Striim Cloud offers many advanced features such as data transform, enrich, mask, encrypt, and correlate in the pipeline.
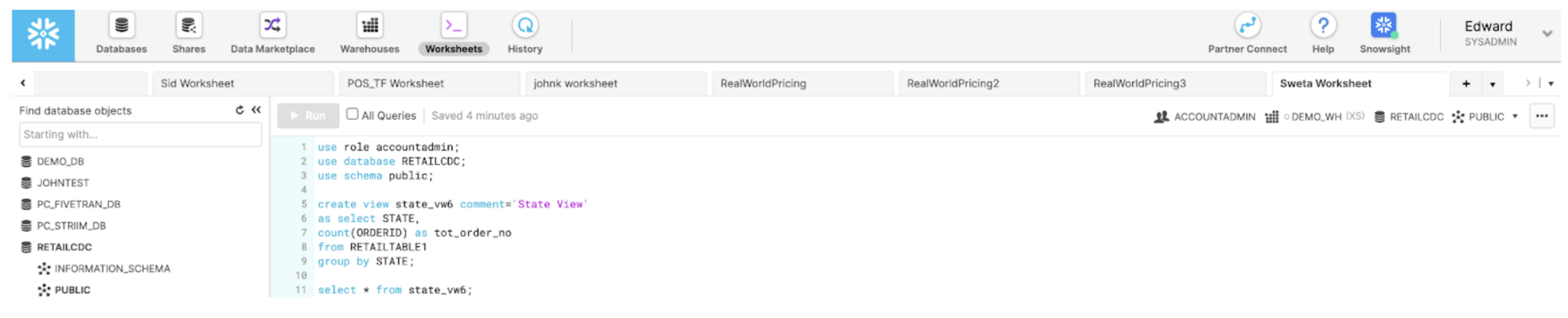
As your data is ingested and delivered, you can monitor its progress and watch real-time ticket data landing in BigQuery. With Striim Cloud, you can easily create actionable data insights and a dashboard for a real-time view of ticket sales data.

Striim Cloud offers many more features and capabilities for real-time data streaming and analytics. Learn more about Striim Cloud here and contact us for a trial or demo.