Most enterprise data is stale before anyone acts on it. Batch pipelines run overnight, dump the information into a warehouse, and teams analyze it the next day. That approach was perfectly fine when business moved at the speed of weekly reports. Today, it’s no longer enough.
When your customer profile updates after the buyer has left your site, you’ve missed the window for personalization. When your fraud detection runs on data that’s six hours old, you aren’t preventing fraud. You’re just documenting it. Legacy batch workflows and siloed systems trap your most valuable assets in the past, leaving you to react to history rather than shape the present.
Real-time data is no longer a luxury. It’s a foundational requirement for scaling AI, meeting modern customer expectations, and driving agile operations. With cloud adoption accelerating, IoT networks expanding, and AI systems demanding massive volumes of fresh context to function properly, the pressure to modernize is intense.
The market has already recognized this reality. According to McKinsey, 92% of business leaders plan to increase investment in real-time data analytics in the near future. The mandate is clear: enterprises must move from historical reporting to instant intelligence.
To help you navigate this transition, we’ll break down exactly what real-time data is, how modern streaming architectures work, and what you need to look for when evaluating a platform to power it.
What Is Real-Time Data?
At its core, real-time data is information that is captured, processed, and made available for action within milliseconds or seconds of being generated.
But “fast” is only half the equation. The true definition of real-time data hinges on its actionability. It’s the difference between reading a report about a spike in fraudulent transactions from yesterday, and automatically blocking a fraudulent transaction the moment a credit card is swiped. Real-time data is the foundational fuel for live decision-making, automated operations, and in-the-moment personalization at enterprise scale.
To understand how this data flows through an organization, it can be helpful to distinguish between two common types:
- Event data: These are discrete, specific actions or state changes. Examples include a customer placing an order, a database record being updated, or a user clicking “Add to Cart.”
- Stream data: This is a continuous, unending flow of information. Examples include IoT sensor readings from a jet engine, ongoing server log outputs, or live financial market tickers.
Capitalizing on both event and stream data requires a shift away from traditional request-response setups toward an event-driven architecture. Instead of downstream systems (like analytics dashboards, machine learning models, or operational applications) constantly asking your database, “anything new here?”, event-driven architectures automatically push the data forward the instant an event occurs.
Common Misconceptions About Real-Time Data
Because “real-time” is a highly sought-after capability, the term has been heavily diluted in the market. Many legacy architectures have been rebranded as real-time, but under the hood, they fail to deliver true immediacy.
Let’s clear up a few common misconceptions:
- Scheduled batch jobs running every 5–15 minutes: Shrinking your batch window is not the same as streaming. Micro-batching might feel faster for daily reporting, but 15 minutes is still a lifetime when you are trying to power dynamic pricing, live customer support agents, or fraud detection.
- Polling-based updates labeled as “event-driven”: If your architecture relies on constantly querying a source database to check for new records, it’s inherently delayed. Worse still, polling puts a massive, unnecessary compute strain on your source systems.
- CDC-only pipelines with no transformation guarantees: Change Data Capture (CDC) is a powerful way to ingest data, but simply moving raw database logs from Point A to Point B isn’t enough. If your pipeline lacks the ability to filter, enrich, and transform that data in motion, you’re not delivering decision-ready context, you’re just shifting the processing bottleneck to your target data warehouse.
If your data is delayed, duplicated, or depends on polling, your system isn’t real-time. It’s just fast batch.
Why Real-Time Data Matters
Today, enterprises are moving beyond batch processing because the window to act on data has vanished. Users, customers, and automated systems don’t wait for nightly ETL jobs to finish. They demand immediacy.
Real-time data powers much more than a faster BI dashboard. It is the connective tissue for smarter AI, frictionless customer experiences, and instant operational decisions.
For executive leadership, this is no longer just a data engineering concern—it is a strategic capability. Real-time data accelerates time-to-decision, slashes operational risk, and serves as the non-negotiable foundation for AI and automation at scale.
Here is how real-time data translates into tangible business benefits:
Use Case |
Business Benefit |
| Fraud detection in financial apps | Stop threats before they cause financial damage, rather than tracking losses post-incident. |
| Live personalization in retail | Improve conversion rates and Customer Lifetime Value (CLTV) by recommending products while the buyer is actively browsing. |
| Real-time supply chain tracking | Optimize logistics, dynamically reroute shipments, and reduce costly downtime. |
| AI model feedback loops | Improve model accuracy and reduce drift instantly by feeding AI fresh, context-rich data streams. |
| Predictive maintenance for IoT | Minimize equipment failures by detecting anomalies in sensor data before a breakdown occurs. |
How Modern Real-Time Data Architectures Work
Understanding the value of real-time data is one thing; but architecting a system to deliver it is no mean feat. At its best, real-time architectures function a bit like an intelligent nervous system, capturing changes instantly, processing them in motion, and routing the exact right context to the systems that need it.
To see how this works in practice, let’s walk through the lifecycle of a real-time data pipeline, from the moment an event occurs to the moment it drives a business outcome.

Data Ingestion and Change Data Capture (CDC)
The first step is capturing the data the instant it is created. In legacy batch systems, this usually meant running heavy queries against operational databases, which drained compute resources and slowed down applications.
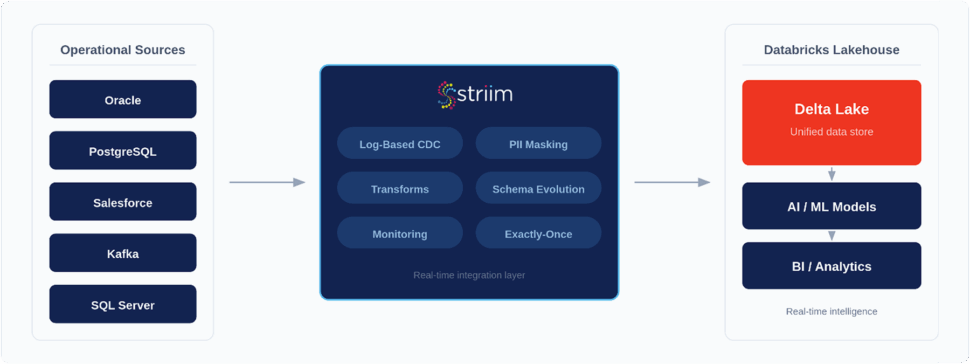
Ideally this is avoided through the use of Change Data Capture (CDC). CDC is a non-intrusive method that reads a database’s transaction logs silently in the background. Whether a customer updates their address or a new order is placed, CDC captures that exact change in milliseconds without impacting the performance of your source systems (like Oracle, PostgreSQL, or SQL Server).
Beyond databases, a robust ingestion layer also continuously streams event data from APIs, application logs, and IoT sensors across complex hybrid and multi-cloud environments.
In-Stream Processing, Transformation, and Enrichment
Ingesting data in real time is useless if data is simply dumped, raw and unformatted into a data warehouse. To make data decision-ready, it must be processed in motion.
Instead of waiting for data to land before cleaning it, modern stream processing engines allow you to filter, aggregate, and enrich the data while it is still in the pipeline. For example, a streaming pipeline can instantly join a live transaction event with historical customer data to provide full context to a fraud detection model.
This layer is also critical for enterprise security and governance. With in-stream processing, you can detect and mask sensitive Personally Identifiable Information (PII) before it ever reaches a downstream analytics tool, ensuring strict compliance with regulations like GDPR or HIPAA without slowing down the pipeline.
Delivery to Analytics, AI/ML, and Operational Systems
Once the data is captured, cleaned, and enriched, it must be delivered to its final destination, often simultaneously to multiple targets.
A modern architecture routes this continuous flow of high-quality data into cloud data warehouses and data lakes (such as Snowflake, Databricks, or Google BigQuery) for immediate analytics. Simultaneously, it can feed directly into live operational applications, BI dashboards, or machine learning models, creating the real-time feedback loops required for agentic AI and automated decision-making.
Key Components of a Real-Time Data Architecture
Real-time data systems rely on multiple interconnected layers to function reliably. Because these architectures demand constant uptime, high throughput, and fault tolerance, they can be incredibly complex to build and maintain from scratch. Attempting to stitch together open-source tools for each layer often results in a fragile “Franken-stack” that requires a dedicated team just to keep it running.
Effective architecture streamlines these layers into an integrated approach. Here are some of the foundational components that make it work:
Source Systems and Connectors
Your architecture is only as good as its ability to integrate with where your data lives. This requires robust, pre-built connectors that can ingest data continuously from a wide variety of sources, including:
- Operational databases (Oracle, PostgreSQL, SQL Server, MySQL)
- Message queues (Apache Kafka, RabbitMQ)
- Cloud services and enterprise applications (Salesforce, SAP)
- IoT devices and edge sensors
Crucially, these connectors must support hybrid and multi-cloud ingestion. A modern pipeline needs to be able to seamlessly read a transaction from an on-prem Oracle database, process it, and securely deliver it to Snowflake in AWS, without missing a beat.
Stream Processing Engines and Frameworks
This is the brain of the operation, where raw streams are transformed into valuable insights. Advanced stream processing relies on core concepts like:
- Event time vs. processing time: Understanding whether an event is processed based on when it actually occurred in the real world versus when it hit the system.
- Windowing: Grouping continuous streams of data into logical time buckets (e.g., aggregating all clicks in a 5-minute window).
- Exactly-once semantics (E1P): Guaranteeing that no matter what happens (e.g., a network failure), every single event is processed once and only once—preventing data duplication or loss.
While frameworks like Apache Flink or Kafka Streams are powerful, they often require writing complex custom code in Java or Scala. Striim takes a more approachable, developer-friendly route: offering integrated processing with a familiar streaming SQL interface. This allows data engineers to build and deploy complex transformations in minutes, completely bypassing the need for highly specialized, custom-coded pipelines.
Targets: Data Warehouses, Data Lakes, and Applications
Once processed, data needs to land where it can drive value. High-performance connectors must instantly route data to popular analytical destinations like Snowflake, Databricks, and Google BigQuery.
But real-time architecture isn’t just about feeding analytics. It’s also about reverse-engineering that value back into operations. By streaming enriched data into operational databases (like PostgreSQL) or directly into applications, you enable real-time alerts, instant UX updates, and the continuous feedback loops necessary to keep AI models accurate and relevant.
Supporting Tools: Monitoring, Governance, and Compliance
In a real-time environment, you cannot afford to find out about a broken pipeline tomorrow. You need comprehensive supporting tools to track data flow health, pipeline performance, and schema evolution (e.g., what happens if a column name changes in the source database?).
Governance is essential, especially for ML and AI pipelines consuming sensitive customer data.
This is why patching together separate tools is risky. Striim mitigates this by offering a unified platform with native connectors, in-flight transformation logic, and enterprise-grade observability built directly into the system. You get continuous visibility, access control, and audit logging out of the box, ensuring your pipelines remain performant, secure, and compliant.
Challenges of Working with Real-Time Data
Real-time data promises unparalleled speed and agility, but executing it well requires careful planning and the right tooling. Moving data in milliseconds across distributed systems introduces a host of engineering hurdles that batch processing simply doesn’t face.
Let’s look at the most common challenges teams encounter, and what it takes to overcome them.
Latency, Consistency, and Fault Tolerance
When building streaming pipelines, terms like “speed” aren’t specific enough. Teams must manage three distinct metrics:
- Processing latency: How fast the engine executes transformations.
- End-to-end latency: The total time it takes a record to travel from the source database to the target application.
- Throughput: The volume of data the system can handle over a given time period.
Ensuring high throughput with low end-to-end latency is difficult, especially when you factor in the need for consistency. When networks partition or target systems experience downtime, how do you prevent data loss or duplication? Striim addresses this through a fault-tolerant architecture that relies on automated checkpointing and robust retry mechanisms, ensuring exactly-once processing (E1P) even during system failures.
Data Quality, Governance, and Observability
A broken pipeline will trigger an alert, but a functioning pipeline that silently delivers bad data has the potential to quietly destroy your analytics applications and AI models.
Real-time data is highly susceptible to issues like schema drift (e.g., an upstream developer drops a column from an Oracle database), duplicate events, and missing context. Ensuring data contracts are upheld in motion is critical. Striim’s comprehensive observability features, including inline validation and rich data lineage, act as an active governance layer. They help you troubleshoot bottlenecks, validate payloads, and prevent bad data from propagating downstream.
Integration Complexity and Operational Overhead
The biggest hidden cost of a real-time initiative is the DIY “Franken-stack.” Piecing together standalone open-source tools for CDC, message brokering, stream processing, and data delivery (e.g., Debezium + Kafka + Flink + Airflow) creates massive operational overhead.
These fragmented architectures demand highly specialized engineering talent just to keep the lights on. Striim drastically reduces this integration burden through an all-in-one platform approach. By providing pre-built templates, an intuitive UI-based configuration, and automated recovery, Striim ensures your engineers spend their time building high-value business use cases, rather than babysitting infrastructure.
Best Practice Tips to Maximize the Value of Real-Time Data
Transitioning from batch to streaming is a significant architectural shift. Unfortunately, many data teams struggle to scale their real-time efforts due to poor upfront planning, tool sprawl, and a lack of clear business goals.
Drawing from our experience deploying Striim across Fortune 500 companies, here are three proven best practices to ensure your real-time initiatives deliver maximum value without overwhelming your engineering teams.
Start with High-Impact Use Cases
When adopting real-time data, it’s tempting to try and migrate every historical batch job at once. Don’t boil the ocean. Instead, identify workflows that genuinely require and benefit from sub-second updates—such as fraud alerts, live customer journeys, or continuous AI pipelines.
Start by implementing one critical, high-visibility pipeline. For example, leading retailers like Macy’s rely on Striim to process high-volume transaction data in real time, dramatically optimizing inventory management and customer experiences. By proving value quickly on a targeted use case, you build organizational trust and momentum for broader adoption.

Design for Scale and Resilience Early
A pipeline that works perfectly for 1,000 events per second might completely collapse at 100,000. When architecting your system, plan for high event volume, failover, and schema evolution from day one.
Relying on manual load balancing or bespoke scripts for recovery will inevitably lead to downtime. Instead, lean on a platform with built-in scalability and automated retry logic. Striim is designed to handle bursty, unpredictable workloads dynamically, automatically managing load distribution and micro-batching where appropriate so your system remains resilient even under massive traffic spikes.
Use a Unified Real-Time Data Platform
The instinct for many engineering teams is to build their own streaming stack using a collection of specialized open-source tools—for instance, combining Debezium for CDC, Kafka for message brokering, Flink for transformation, and Airflow for orchestration.
While these are powerful tools individually, stitching them together creates a fragile infrastructure with massive maintenance overhead and painstakingly slow time to value. A unified real-time data platform like Striim eliminates this complexity. By consolidating ingestion, transformation, and delivery into a single, cohesive environment, you drastically reduce your integration burden, ensure consistent governance, and benefit from built-in monitoring—allowing your team to focus on building high-value products, not maintaining data plumbing.
How to Evaluate a Real-Time Data Platform
To evaluate a real-time data platform, you must rigorously assess its ability to provide true sub-second latency, native CDC, in-stream transformation capabilities, multi-cloud flexibility, and built-in enterprise governance.
The data tooling landscape is crowded, and many vendors have simply rebranded legacy or micro-batch workflows as “real-time.” Selecting the wrong architecture introduces massive hidden risks: delayed insights, operational outages, eroded data quality, and mounting integration overhead.
To separate the platforms built for true streaming from optimized batch in disguise, use these buyer questions to guide your evaluation:
Performance, Scalability, and Latency Guarantees
Can your existing platform maintain consistent sub-second latency and high throughput under unpredictable, bursty workloads?
Many retrofitted systems degrade under heavy load or force your teams to batch data to stabilize performance, breaking the real-time promise entirely. Your platform must handle high volumes gracefully. For example, Striim’s architecture consistently delivers predictable latency, achieving sub-2-second end-to-end delivery even at massive enterprise scales of 160 GB per hour.
Stream-First Architecture and CDC Support
Is the system truly event-driven, or does it rely on polling or micro-batching under the hood?
A true real-time architecture begins with native CDC ingestion, not staged pipelines or scheduled extraction jobs. You need a platform that reads transaction logs directly. Look for a solution that can capture changes from mission-critical systems like Oracle, SQL Server, and PostgreSQL while they are in motion, with absolutely zero disruption or compute strain on the source databases.
Built-In Transformation and SQL-Based Analytics
Can your team enrich and transform data as it flows, or are you forced to stitch together standalone tools like Flink, dbt, and Airflow?
Batch-based post-processing is too late for modern use cases like live personalization or fraud detection. In-stream transformation is a strict requirement. To avoid heavy engineering overhead, prioritize platforms like Striim that leverage a familiar, SQL-based interface. This allows teams to filter, mask, and enrich data in motion without writing bespoke, complex Java or Scala code.
Cloud-Native, Hybrid, and Multi-Cloud Support
Does the platform adapt to your existing architecture, or does it force a rip-and-replace migration?
A modern real-time data platform should provide seamless data movement across cloud and on-prem systems. This is especially critical for enterprise teams operating across global regions or undergoing gradual cloud modernizations. Striim deployments natively span AWS, Azure, GCP, and hybrid environments, ensuring data flows without any tradeoffs in latency or system resilience.
Monitoring, Security, and Compliance Readiness
Does your stack provide continuous visibility and control?
Without comprehensive observability, silent failures, undetected data loss, and compliance gaps are inevitable. DIY data stacks rarely include built-in governance features, which introduces massive audit risks and model drift for AI applications. Effective real-time platforms must provide real-time observability, granular role-based access control (RBAC), in-flight encryption, and audit logging—features that are non-negotiable for industries like financial services and healthcare.
Why Leading Companies Choose Striim
Real-time data is the baseline for the next generation of enterprise AI and operational agility. However, achieving it shouldn’t require your engineering teams to manage fragile, disjointed infrastructure.
Striim is the only unified Integration and Intelligence platform that offers real-time ingestion, processing, transformation, and delivery in a single, cohesive environment. Built as a streaming-first architecture, Striim eliminates the complexity of DIY data pipelines by providing sub-second CDC, intuitive SQL-based transformation logic, cloud-native scale, and enterprise-grade observability straight out of the box.
Leading enterprises rely on Striim to turn their data from a historical record into a live, competitive advantage. Companies like American Airlines and UPS Capital use Striim to power their most critical operations, reducing latency from hours to milliseconds, optimizing logistics, and unlocking entirely new revenue streams.
Ready to see the difference a unified real-time data platform can make for your architecture?
Get started for free or book a demo today to explore Striim with one of our streaming data experts.