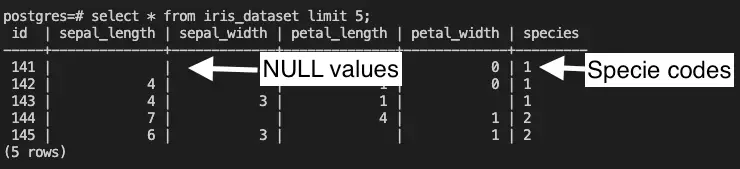
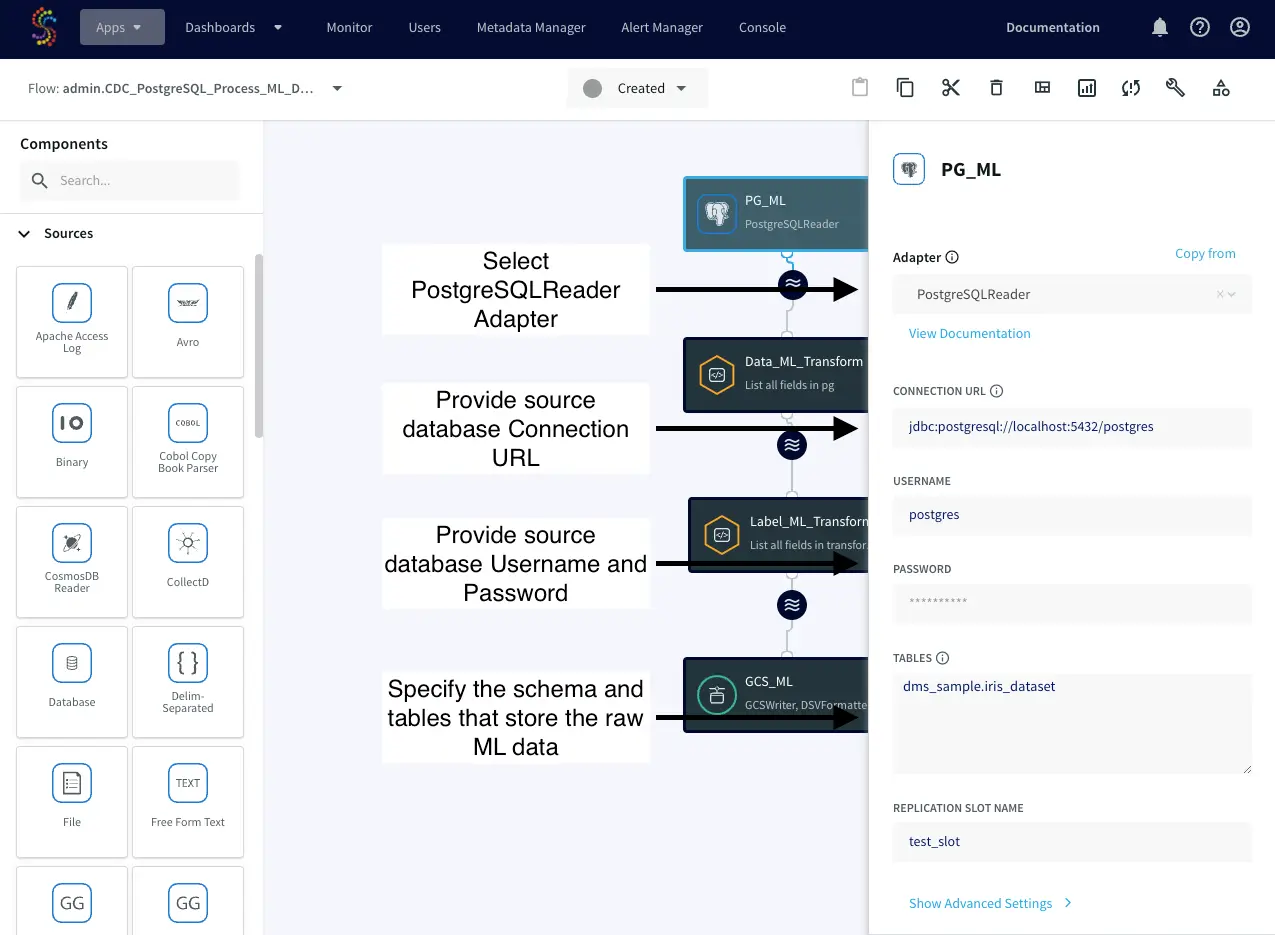
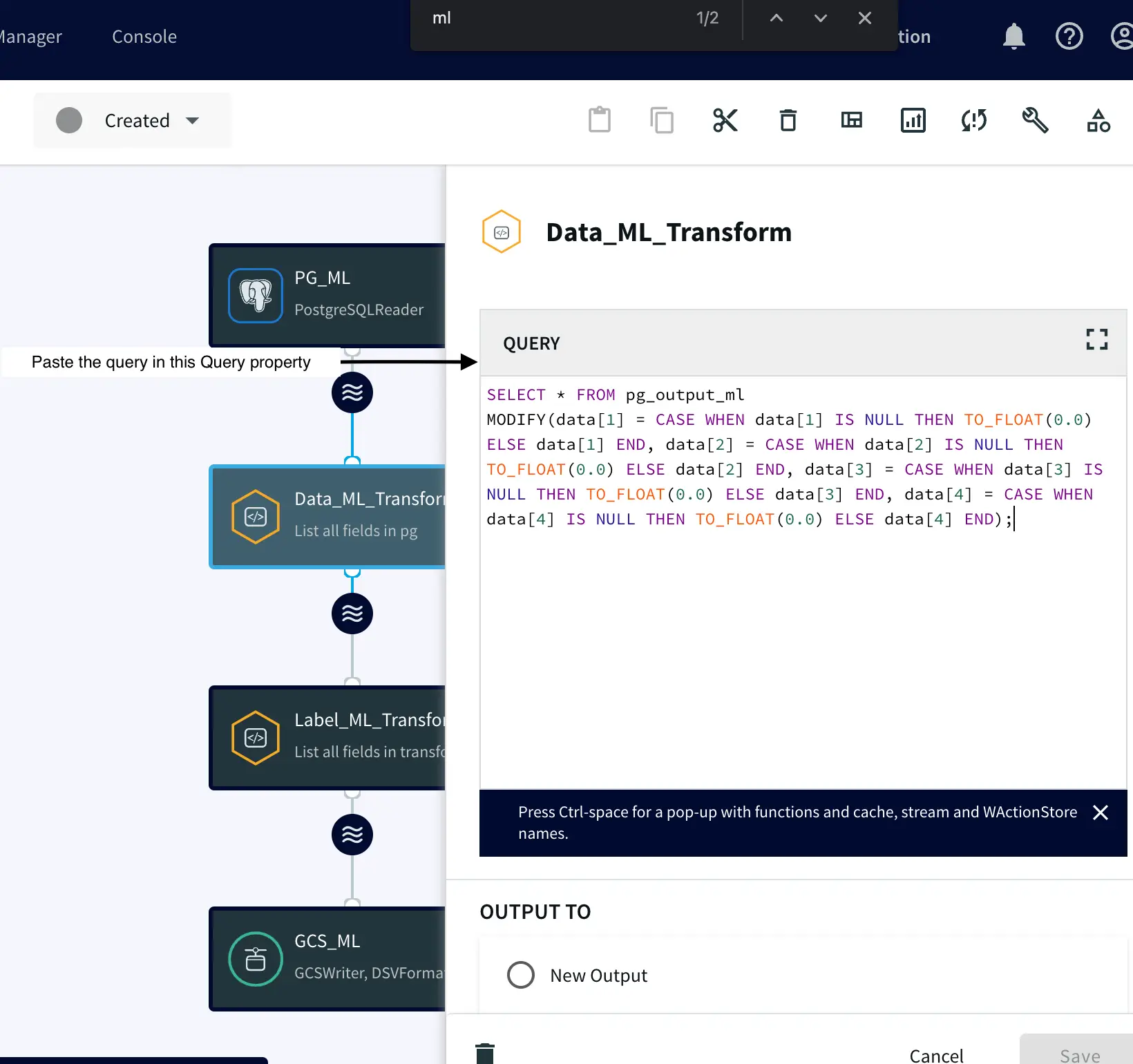
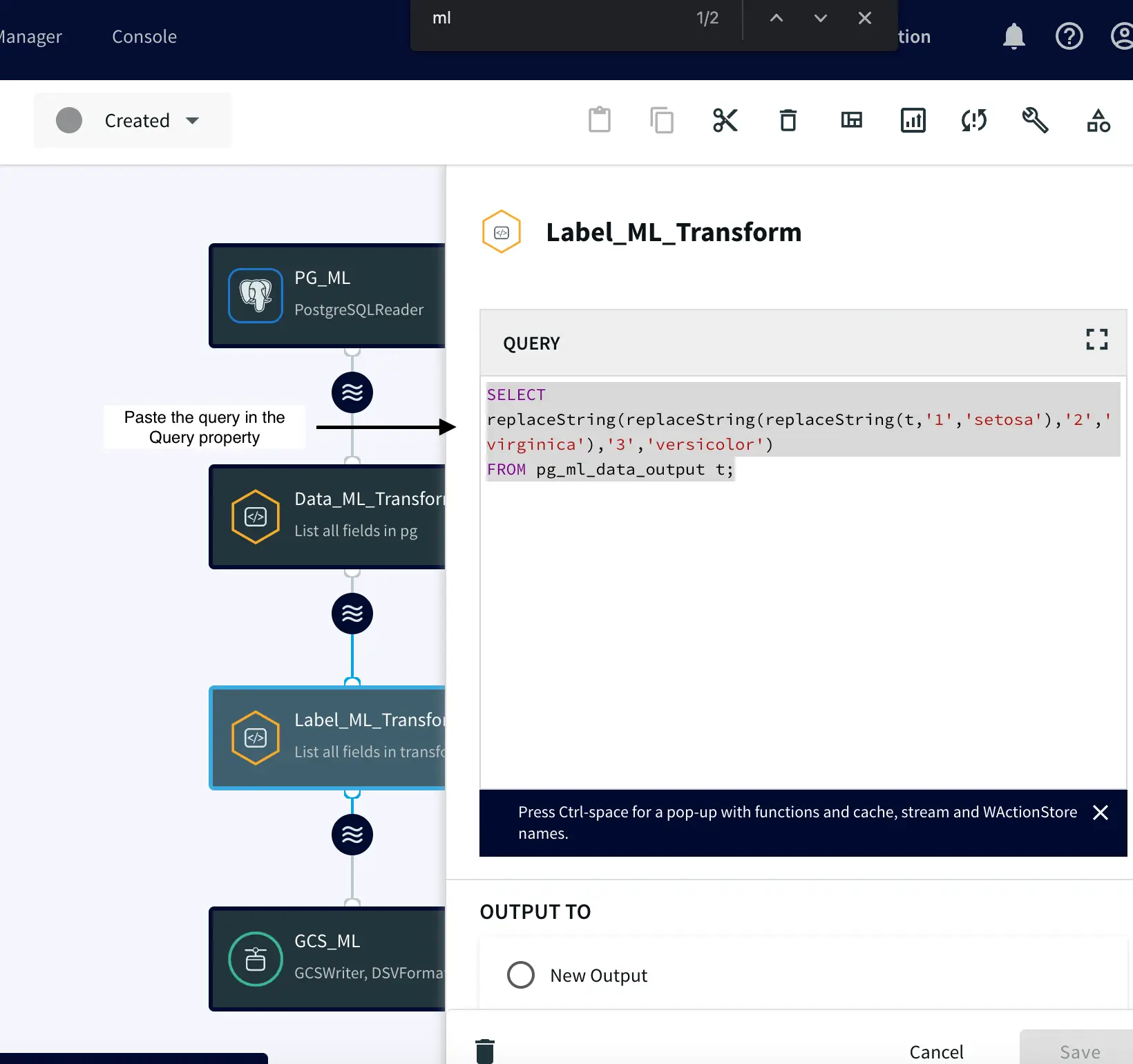
Kappa Architectures are becoming a popular way of unifying real-time (streaming) and historical (batch) analytics giving you a faster path to realizing business value with your pipelines.
Treating batch and streaming as separate pipelines for separate use cases drives up complexity, cost, and ultimately deters data teams from solving business problems that truly require data streaming architectures.
Kappa Architecture combines streaming and batch while simultaneously turning data warehouses and data lakes into near real-time sources of truth.

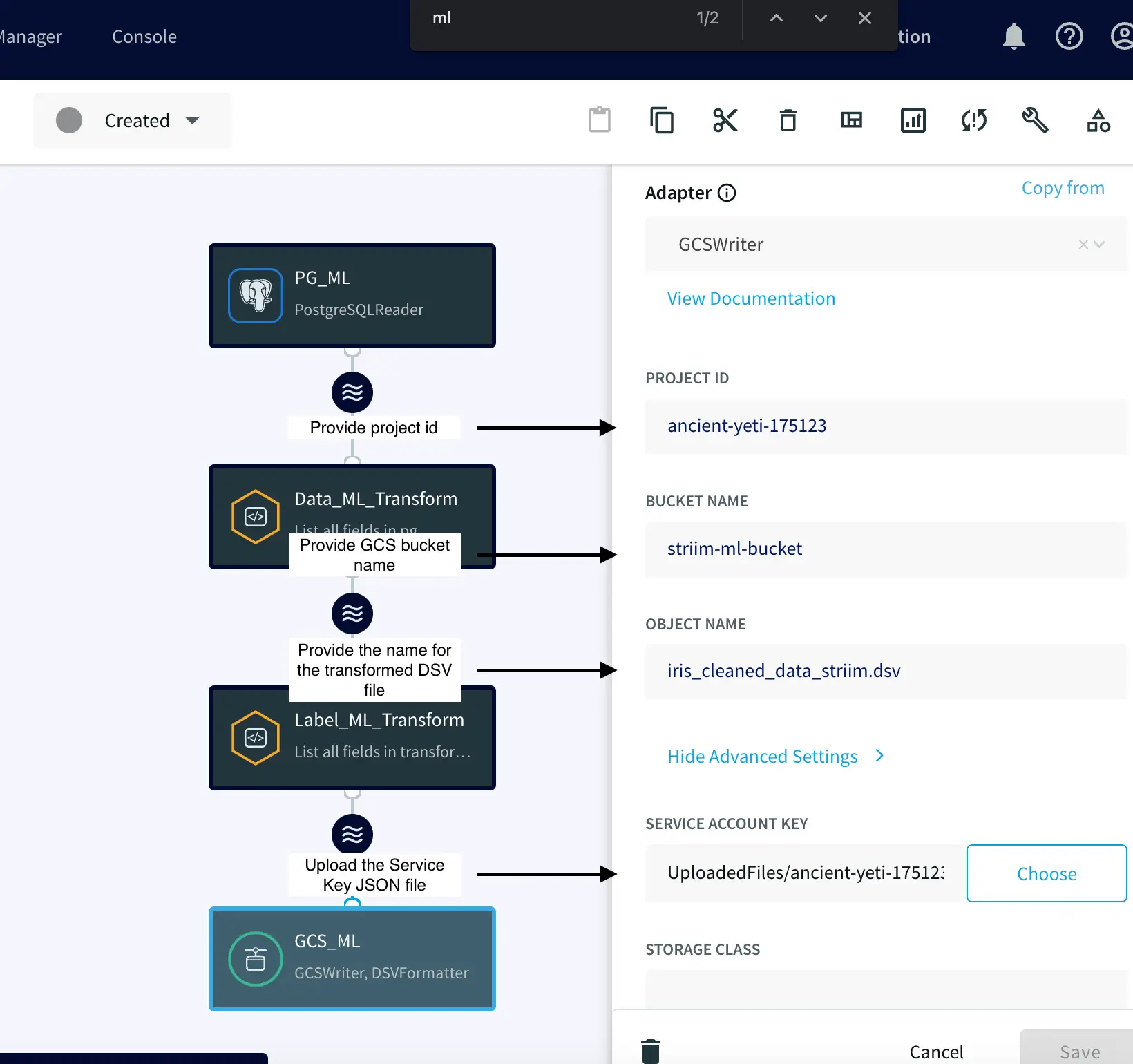
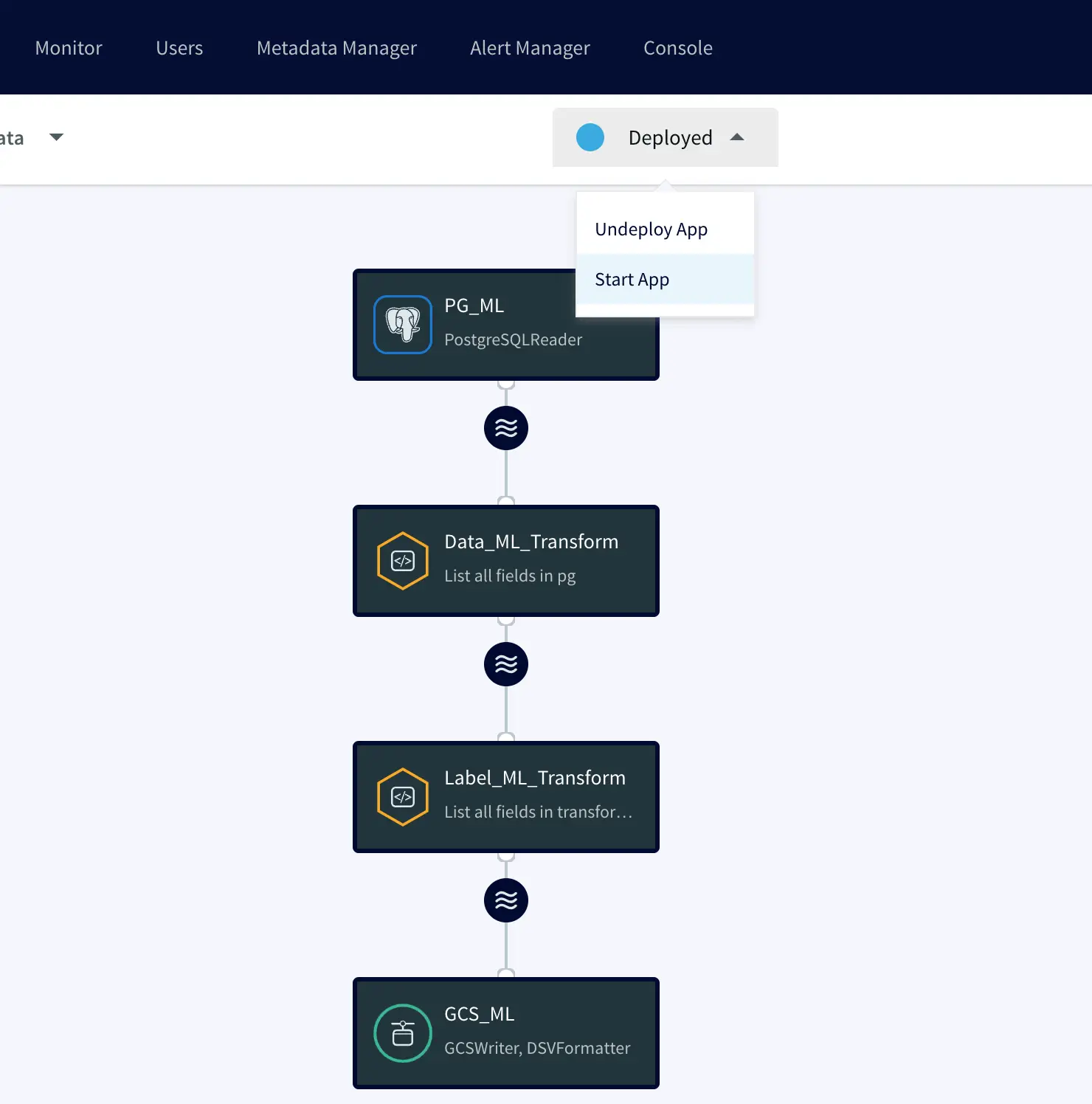
The development of Kappa architecture has revolutionized data processing by allowing users to quickly and cost-effectively reduce data integration costs. Kappa architecture is a powerful data processing architecture that enables near-real-time data processing, making it ideal for companies needing to quickly process large amounts of data. Striim offers an easy-to-use platform with drag-and-drop functionality and pre-built components that make it simple to build a kappa architecture. In this article, we will take a look at the benefits and drawbacks of kappa architecture, how Striim makes it easier to use, what infrastructure you need for your kappa architecture, and how you can start designing your own kappa architecture with a free version of Striim’s unified data integration and streaming platform.
Overview of kappa architecture
Kappa architecture is a powerful data processing architecture that enables near-real-time data processing. By combining batch and stream processing techniques, companies are able to process large volumes of data quickly and efficiently, even with frequent changes in the data structure. Two different systems are required for creating a kappa architecture: one for streaming data and another for batch processing. Stream processors, storage layers, message brokers, and databases make up the basic components of this architecture.
The goal of kappa architecture is to reduce the cost of data integration by providing an efficient and real-time way of managing large datasets. By eliminating manual processes such as ETL (extract-transform-load) systems, companies can save time and money while still leveraging advanced technologies like machine learning and artificial intelligence (AI). Striim offers an intuitive UI with drag-and-drop functionality as well as prebuilt components to help users design their own custom kappa architectures. With its free version also available, businesses can start building their own system right away without needing expensive consultants or weeks spent configuring complex systems.
In conclusion, kappa architectures have revolutionized the way businesses approach big data solutions – allowing them to take advantage of cutting edge technologies while reducing costs associated with manual processes like ETL systems. With Striim’s unified platform making it easier than ever before to build a custom kappa architecture tailored exactly towards your business needs – you can get started designing your own system today!
Benefits of kappa architecture for data integration
Kappa architecture is quickly gaining popularity due to its ability to enable near-real-time data processing and reduce the complexity associated with data integration. By utilizing a single codebase for both streaming and batch processing, businesses can reap multiple benefits from this solution. This simplification drastically cuts down on development resources needed as well as infrastructure setup and maintenance costs. Additionally, it allows for efficient processing of both real-time and historical data which eliminates the need for multiple versions of the same dataset or manually managed systems.
The versatility offered by kappa architectures makes them suitable for many industries such as healthcare, finance, retail, telecoms energy and more. Companies can leverage this technology to create analytics solutions that are tailored to their individual needs that are capable of handling substantial amounts of streaming data in real-time without any latency issues. Moreover, users can design their own system with Striim’s unified platform which features an intuitive UI with drag-and-drop functionality – plus they offer a free version so businesses can get started straight away!
In summation, kappa architectures offer immense advantages for those looking to reduce their data integration costs while using cutting edge technologies. With Striim’s unified platform businesses have access to a range of features that make designing their own system easy and straightforward – all at an affordable cost or even free!
Drawbacks of kappa architecture
Kappa architecture has revolutionized the way businesses process and store data, allowing them to take advantage of cutting edge technologies while reducing costs associated with manual processes. However, this technology is not without its drawbacks.
The complexity of setting up and maintaining a kappa architecture can be very high, requiring specialized engineers to ensure that all components are properly configured and functioning correctly. Additionally, without a centralized system for managing data, it can be difficult for businesses to maintain data governance across their organization. This lack of centralization also means that each component must be independently managed, leading to higher costs in terms of additional computing resources.
Another limitation of kappa architecture is scalability. As more data is processed through the system, it will require more computing resources in order to remain efficient and effective. This makes scaling the architecture complex and costly, as businesses will need to invest in additional hardware or cloud computing services in order to handle larger volumes of data processing.
Finally, kappa architectures are not suitable for all types of data processing tasks. While they are well suited for near-real-time analytics applications, they may not be the best choice for batch processing jobs or those that require intensive computation or machine learning algorithms. It’s important for businesses to assess their individual needs before deciding if kappa architectures are the right choice for reducing their data integration costs.
How Striim overcomes these drawbacks to make Kappa simple and affordable
Kappa architecture is an incredibly powerful tool for businesses looking to quickly and cost-effectively reduce data integration costs, but it does have some drawbacks that can make it difficult to use. Striim’s platform overcomes these drawbacks by making it easy and affordable to build a Kappa architecture.
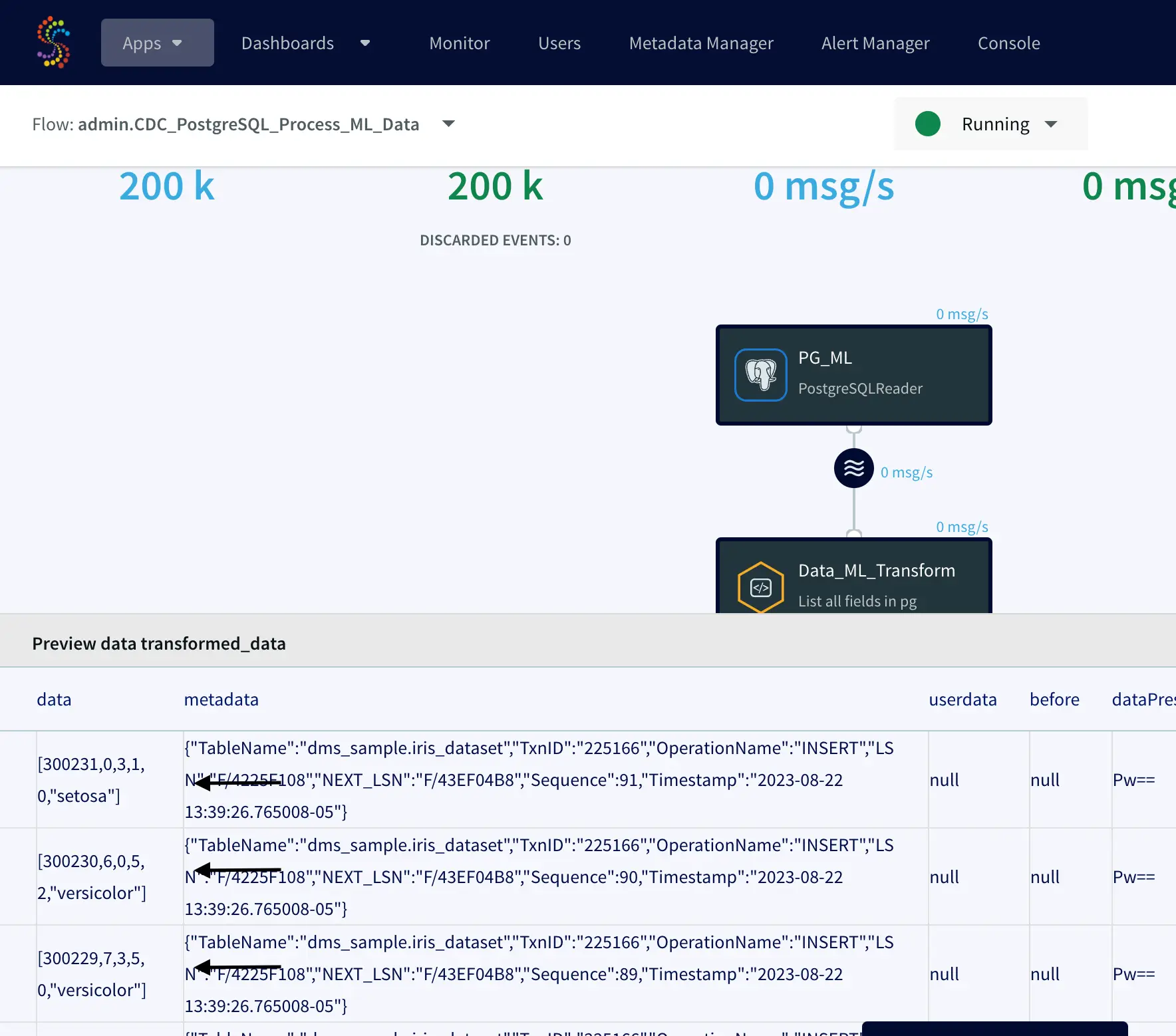
Striim’s real-time streaming capabilities allow users to capture data from over 150 sources in near-real time, which eliminates the need for manual processes. Striim users can also see cost reduction of over 90% when using its smart data pipelines.
In addition, Striim has a range of pricing plans available, so businesses can find the plan that best suits their needs from its free Striim Developer tier to the Mission Critical offering which is the industry’s only horizontally scalable, unified data streaming platform as a managed service for maximum uptime SLAs and performance.
The intuitive UI, drag-and-drop functionality, and pre-built components make building a Kappa architecture quick and easy. This reduces the complexity associated with configuration and maintenance, allowing users to get up and running in no time. Plus, Striim’s free version allows users to start designing their kappa architecture without any upfront cost – making it perfect for businesses of all sizes. It also provides granular control for data contracts for data delivery and schema SLAs. With its real-time streaming capabilities, cloud integration options, pricing plans that fit various budgets, intuitive UI with drag-and drop functionality and pre-built components – as well as its free version – Striim makes building a Kappa architecture simple and affordable. This makes it the ideal tool for businesses looking to reduce their data integration costs while taking advantage of cutting edge technologies.
With its real-time streaming capabilities, cloud integration options, pricing plans that fit various budgets, intuitive UI with drag-and drop functionality and pre-built components – as well as its free version – Striim makes building a Kappa architecture simple and affordable. This makes it the ideal tool for businesses looking to reduce their data integration costs while taking advantage of cutting edge technologies.
Choosing the right infrastructure for kappa architecture
When setting up a kappa architecture, businesses have to choose between cloud and on-premise solutions. Cloud-based architectures are more cost-effective but lack the control of an on-premise setup. On the other hand, an on-premise architecture provides more control but can be more expensive and difficult to manage. Each option has its own advantages and disadvantages, so companies should carefully weigh their needs before deciding which type of infrastructure is right for them.
The components needed to create a successful kappa architecture vary depending on the setup chosen, but generally include storage, compute, networking resources, and some form of data integration software. Companies should ensure they have enough resources available in order to avoid any performance issues as data volumes increase over time. Additionally, businesses should plan for scalability and high availability in order to ensure that their system can handle large amounts of data without disruption or loss of service.
Cost optimization is also an important consideration when building a kappa architecture. Companies need to balance performance requirements with financial constraints in order to get the most out of their investment while still ensuring reliability and stability. Additionally, they should follow industry best practices such as using containerized workloads for portability and leveraging managed services such as databases and message brokers whenever possible. Finally, companies should keep abreast of emerging trends in kappa architectures such as serverless computing or streaming automation tools that could help them further reduce costs while improving efficiency and scalability.
Ultimately, choosing the right infrastructure for a kappa architecture requires careful consideration of individual needs while keeping cost optimization in mind. Businesses should assess their performance requirements alongside financial constraints in order to build a reliable system that meets both goals while taking advantage of industry best practices and emerging trends wherever possible.
Leveraging Striim’s unified data integration and streaming platform to build your kappa architecture
Building a kappa architecture with Striim’s unified data integration and streaming platform is an easy and cost-effective solution that can help businesses reduce their data integration costs. With its intuitive UI, drag-and-drop functionality and pre-built components, Striim’s platform makes it simple to construct the architecture quickly.
The platform is optimized to support a wide range of data sources, including both structured and unstructured data. This allows users to easily manage all their data in one place, while also allowing them to scale up or down as needed for peak performance. Additionally, Striim’s platform provides cloud integration options for popular cloud platforms like Amazon Web Services and Microsoft Azure.
Striim’s platform is designed with scalability in mind, making it easy for businesses to handle large volumes of real-time streaming data without any latency issues or downtime. Additionally, the platform provides automated monitoring capabilities that enable companies to ensure their architecture remains reliable and stable. Furthermore, the platform also offers several other features that make it easier for businesses to manage their kappa architectures such as advanced analytics tools, machine learning algorithms, security features and more.
In addition to its powerful features, Striim’s unified data integration and streaming platform comes with a free version that allows users to get started quickly and cost-effectively – without having to pay any upfront costs. This makes it an ideal choice for businesses looking for ways to reduce their data integration costs while taking advantage of cutting edge technologies like kappa architectures.
Start architecting your Kappa Architecture today by talking to one of our specialists or trying Striim for free.