
Modern computing demands have forced businesses to ensure high availability and data accessibility while tackling various networks simultaneously. That’s why it’s crucial to get 24/7 and real-time access to key business data from your database—and for many businesses, that database is Oracle. Whether a business is looking to process millions of transactions or build a data warehouse, Oracle is the go-to option for handling critical enterprise workloads.
In today’s digital age, organizations must scale up their systems and build an ecosystem that helps them seamlessly access data from their Oracle database to improve the efficiency of their operations. To achieve this, they can use database replication — a technique that enables data access to a wide range of sources (e.g., servers and sites). Since it allows real-time data access, database replication maintains high-data availability and addresses a major concern for enterprises.
Why Replicate an Oracle Database?
Replicating an Oracle database makes it easy to distribute, share, and consolidate data. With replication, businesses can synchronize data across different locations, share data with vendors and partners, and aggregate data from their branches — both international and local.
Companies use Oracle database replication to create multiple copies of an organization’s database. These synchronized copies pave the way for distributed data processing, backups for disaster recovery, testing, and business reporting.
Some benefits of Oracle database replication include the following:
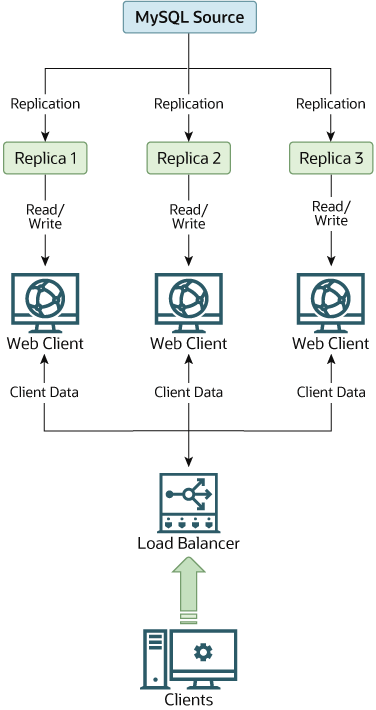
- Enhance application availability. Since database replication copies data to several machines, it’s easier to maintain access to your application’s data. Even if one of your machines is compromised due to a malware attack, faulty hardware, or another issue, your application data will remain available 24/7.
- Enhance server performance. It’s a common practice in database replication to direct data read operations to a replica. This allows system administrators to minimize processing cycles on the primary server and prioritize it for write operations.
- Enhance network performance. Maintaining multiple copies of the same data is convenient for minimizing data access latency. That’s because you can fetch the relevant data from the location where the transaction is being executed.
For instance, users from Europe might face latency problems while trying to access Australian-based data centers. You can address this challenge via Oracle database replication, so a replica of your data is placed closer to the user.
A common example of Oracle database replication can be found in money transfers and ATM withdrawals. For example, if you withdraw $150 from an ATM, the transaction will be immediately copied to each of your bank’s servers. As a result, your information will be updated instantaneously in all branches to display $150 less in your account.
Similarly, an e-commerce website that uses an Oracle database has to ensure visitors from different countries can view the same product information at each site. Database replication helps them to achieve this goal by copying their product details for each site.
4 Ways to Replicate An Oracle Database
Choosing the right approach to replicate your Oracle depends on several factors, including the goal of your replication, the size of the database, how the performance of the source systems is affected, and whether you need synchronous replication or asynchronous replication.
Here are some of the common ways to replicate an Oracle database.
1. Full Dump and Load
In this approach, you start by choosing a table you want to replicate. Next, you define a replication interval (could be 4, 8, or 12 hours) as per your requirements. For each interval, your replicated table is queried, and a snapshot is generated. This snapshot (also known as a dump) is used as the substitute for the previous snapshot.
This approach is effective for small tables (usually less than 100 million rows). However, once the table grows in size, you will have to rely on a more reliable replication strategy. That’s because it takes a considerable amount of time to perform the dump.
2. Incremental Approach (Table Differencing)
Table differencing is an approach in which a copy of the source table is periodically compared to an older version of the table and the differences are extracted.
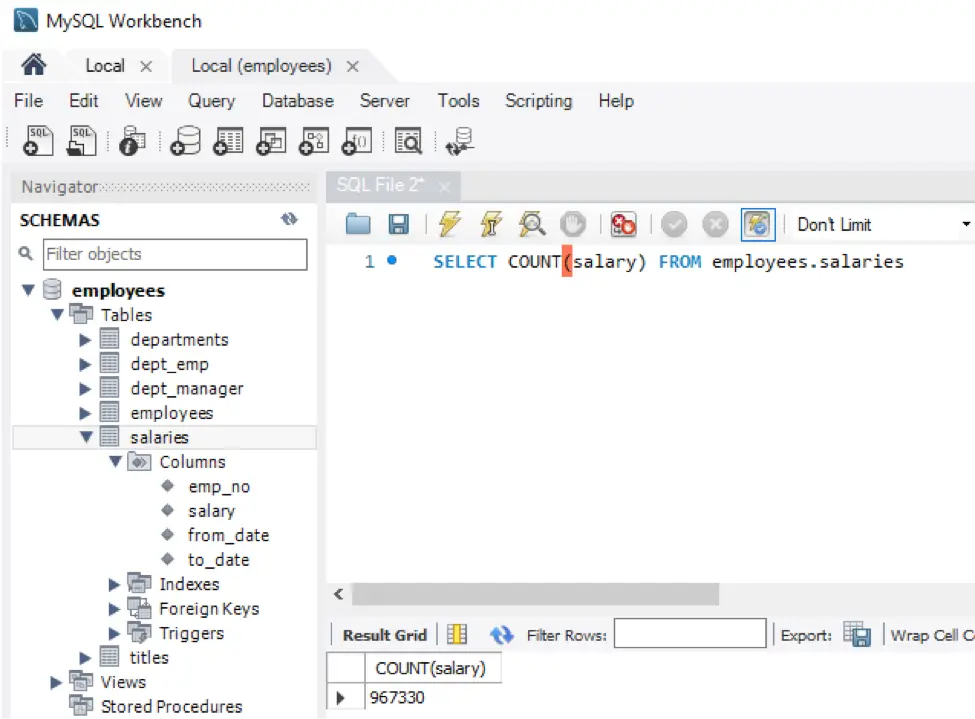
For example, use the following command to get the difference between the two tables, named new_version and old_version.
SELECT * FROM new_version MINUS SELECT * FROM old_version;
This command gives you the inserts and updates that are present in the new_version of the table. However, when the time comes to load data into the target database, you have to make sure to replace the table’s old version with the new version (so you can compare it to a future new version of the table).
The incremental approach provides an accurate view of changed data while only using native SQL scripts. However, this method can lead to high computation and transport costs. In addition, it isn’t ideal for restoring data. For instance, if you want to go through the files that were backed up incrementally on Wednesday, you’ll first have to restore the full backup from Tuesday.
3. Trigger-Based Approach
This approach depends on triggers — a function you can set up to execute automatically whenever a data change occurs in your database system.
For example, you can set a trigger that inserts a record into another table (the “change table”) whenever the source table changes. You can then replicate your data from the Oracle database to another database.
Oracle comes with a stored procedure to set any trigger and monitor the source table for updates. Triggers help to achieve synchronous replication. However, this approach can affect the performance of the source database because triggers cause transactions to be delayed.
4. Change Data Capture

Change data capture (CDC) is a managed software process that determines the rows in source tables that have been modified after the last replication. This makes it more efficient and faster than other methods, especially the ones that copy entire tables at every replication cycle and replicate even the rows that weren’t changed.
CDC replicates create-update-delete (CUD) operations, written in SQL via the following commands: INSERT, UPDATE, and DELETE.
Here’s why Oracle CDC is a better approach for replicating your Oracle database:
- Since CDC only works with the rows that have changed, it sends less data from the source to the replication, putting a minimal load on the network.
- Proper CDC implementation ensures that replication operations don’t affect your production database. In this way, you can free up resources for transactions.
- With CDC, you can achieve real-time data integration, helping you build streaming analytics.
For example, consider HomeServe, a leading home assistance provider. HomeServe wanted to send detailed reports to its insurer partners that could give an in-depth overview of water leaks. To do this, they needed a technology that could help them move the operational data to Google BigQuery without impacting their database.
Ultimately, they went with Striim’s enterprise-grade CDC to go through binary logs, JSON columns, and other sources. This allowed them to move all the changes from the transactional database. More importantly, CDC ensured no overhead was caused on the source system and performance remained unaffected. Learn more about it here.
Oracle GoldenGate is another tool that can replicate data from one Oracle database to another by using CDC. GoldenGate can be useful for a broad array of use cases. These include multi-cloud ingestion, data lake ingestion, high availability (peer-to-peer, unidirectional, bi-directional, etc.), and online transactional processing (OLTP) data replication.
Although Oracle GoldenGate is more convenient than the above methods, configuring it requires assistance from an Oracle administrator.
Simplify Oracle Database Replication with Striim

CDC is the best approach for replicating Oracle databases in many scenarios, but which tool should you choose to implement it? Consider taking a look at Striim.
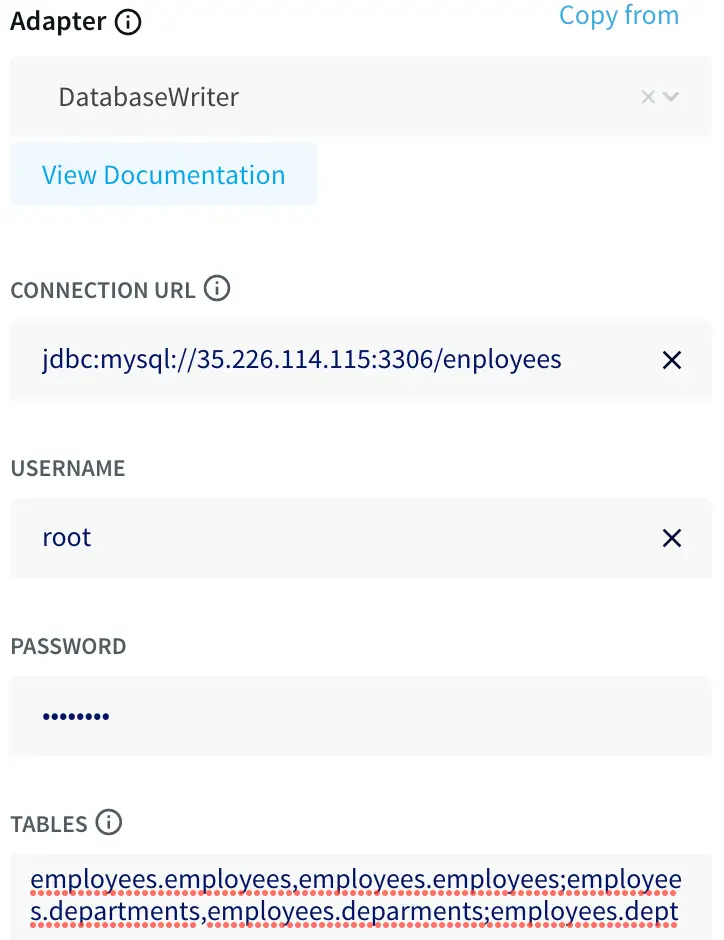
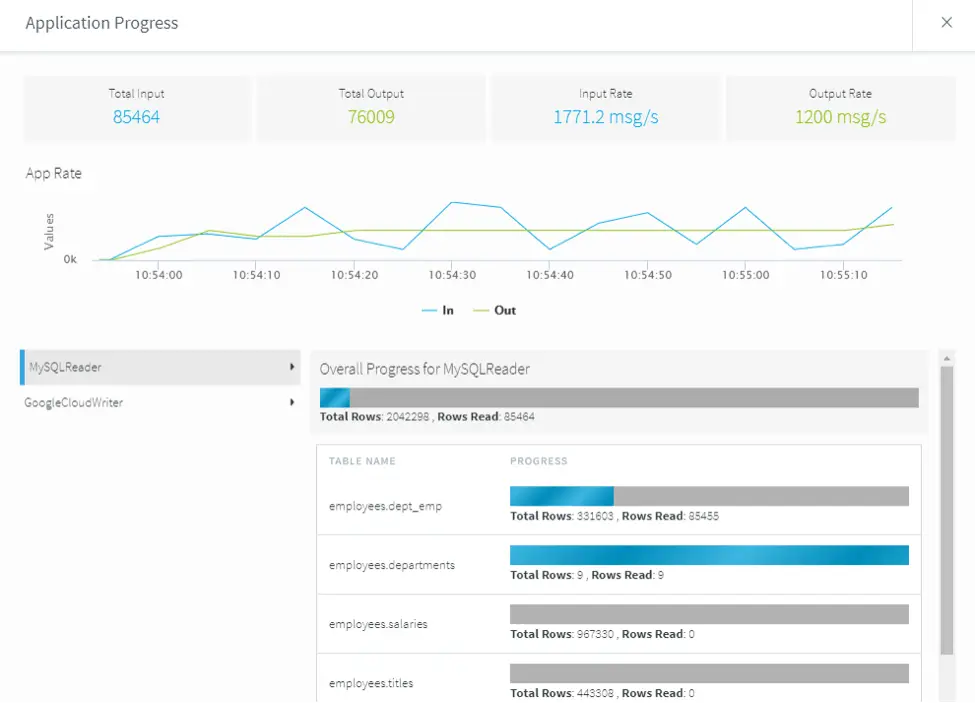
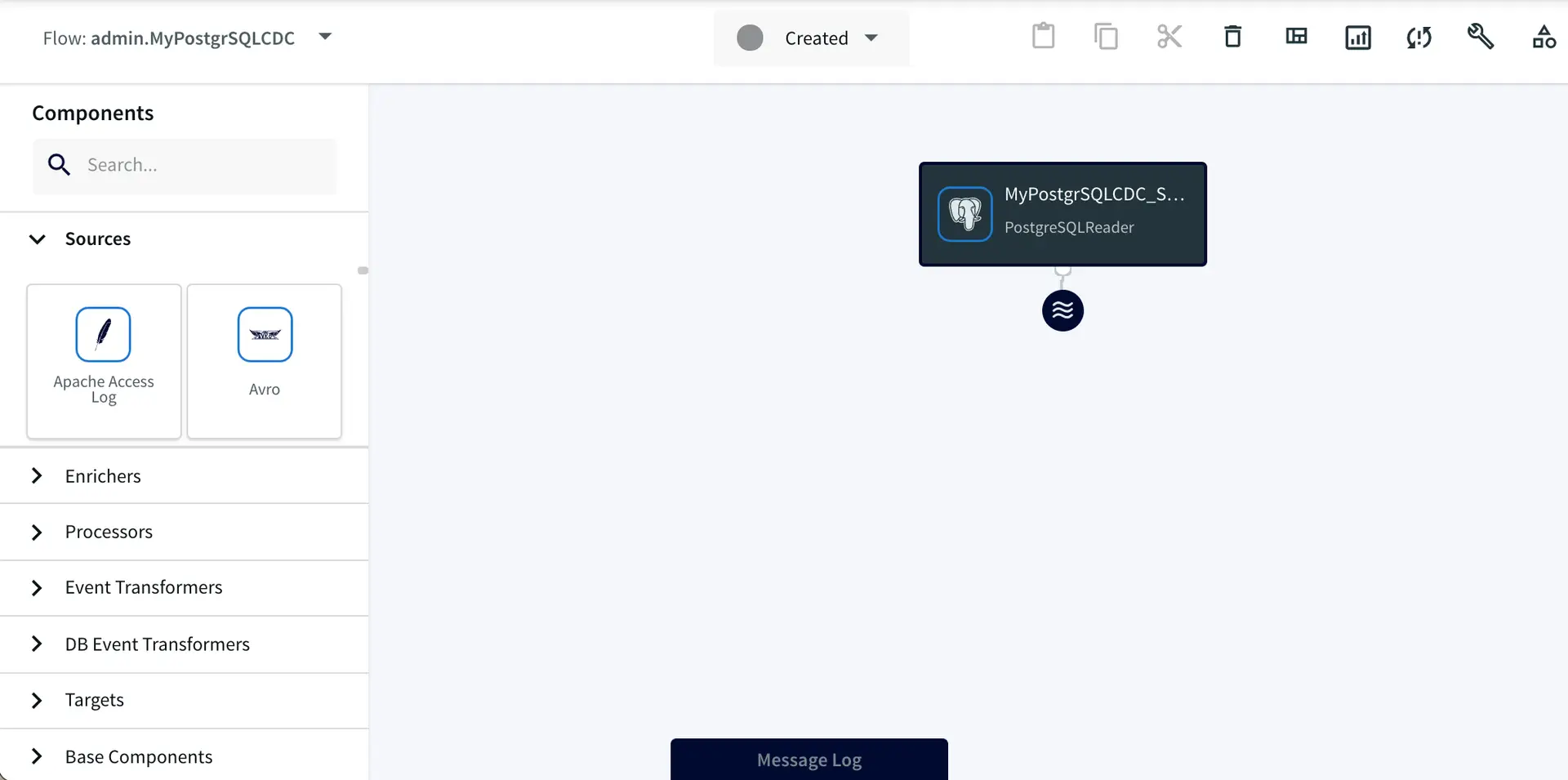
Using Striim’s Oracle CDC reader, you can turn your Oracle database into a streaming source and migrate your critical transactional data to cloud environments or real-time applications.
The log-based CDC method in Striim fetches the insert, update, and delete operations in the Oracle redo logs. Even better, Striim’s CDC reader can buffer large transactions to disk with minimal performance overhead. Throughout this process, the source systems remain unaffected.
Another thing that makes Striim stand out is, unlike other tools, it can work without the LogMiner continuous mining feature, which was deprecated in 19c. Additionally, Striim can read from GoldenGate trail files.
Schedule a demo and we’ll give you a personalized walkthrough or try Striim at production-scale for free! Small data volumes or hoping to get hands on quickly? At Striim we also offer a free developer version.


























































{kind=link}