
We sit down with Bruno Aziza – Head of Analytics at Google Cloud – To discuss the latest trends in data such as data mesh, data governance, and the real-world value of real-time data.
We sit down with Bruno Aziza – Head of Analytics at Google Cloud – To discuss the latest trends in data such as data mesh, data governance, and the real-world value of real-time data.

Watch our on-demand webinar on data streaming patterns that enable enterprises to analyze and act on data in real time.
Alok Pareek and Sanjeev Mohan cover topics including:
Alok Pareek
Founder, EVP Products Striim, Former VP of Engineering at Oracle and GoldenGate
Sanjeev Mohan
Principal, SanjMo & Former Gartner Research VP, Big Data and Advanced Analytics
According to a Gartner prediction, only 20% of data analytics projects will deliver business outcomes. Indeed, given that the current data architectures are not well equipped to handle data’s ubiquitous and increasingly complex interconnected nature, this is not surprising. So, in a bid to address this issue, the question on every company’s lips remains — how can we properly build our data architecture to maximize data efficiency for the growing complexity of data and its use cases?
First defined in 2018 by Zhamak Dehghani, Head of Emerging Technologies at Thoughtworks, the data mesh concept is a new approach to enterprise data architecture that aims to address the pitfalls of the traditional data platforms. Organizations seeking a data architecture to meet their ever-changing data use cases should consider the data mesh architecture to power their analytics and business workloads.
A data mesh is an approach to designing modern distributed data architectures that embrace a decentralized data management approach. The data mesh is not a new paradigm but a new way of looking at how businesses can maximize their data architecture to ensure efficient data availability, access, and management.
Rather than viewing data as a centralized repository, a data mesh’s decentralized nature distributes data ownership to domain-specific teams that manage, control, and deliver data as a product, enabling easy accessibility and interconnectivity of data across the business.
Today most companies’ data use cases can be split into operational and analytical data. Operational data represents data from the company applications’ day-to-day operations. For example, using an e-commerce store, this will mean customer, inventory, and transaction data. This operational data type is usually stored in databases and used by developers to create various APIs and microservices to power business applications.

Operational vs. analytical data plane
On the other hand, analytical data represents historical organizational data used to enhance business decisions. In our e-commerce store example, analytical data answers questions such as “how many customers have ordered this product in the last 20 years?” or “what products are customers likely to buy in the winter season?” Analytical data is usually transported from multiple operational databases using ETL (Extract, Transform, and Load) techniques to centralized data stores like data lakes and warehouses. Data analysts and scientists use it to power their analytics workloads, and product and marketing teams can make effective decisions with the data.
A data mesh understands the difference between the two broad types of data and attempts to connect these two data types under a different structure — a decentralized approach to data management. A data mesh challenges the idea of the traditional centralization of data into a single big storage platform.
A data mesh is technology agnostic and underpins four main principles described in-depth in this blog post by Zhamak Dehghani. The four data mesh principles aim to solve major difficulties that have plagued data and analytics applications for a long time. As a result, learning about them and the problems they were created to tackle is important.
Domain-oriented decentralized data ownership and architecture
This principle means that each organizational data domain (i.e., customer, inventory, transaction domain) takes full control of its data end to end. Indeed, one of the structural weaknesses of centralized data stores is that the people who manage the data are functionally separate from those who use it. As a result, the notion of storing all data together within a centralized platform creates bottlenecks where everyone is mainly dependent on a centralized “data team” to manage, leading to a lack of data ownership. Additionally, moving data from multiple data domains to a central data store to power analytics workloads can be time consuming. Moreover, scaling a centralized data store can be complex and expensive as data volumes increase.
There is no centralized team managing one central data store in a data mesh architecture. Instead, a data mesh entrusts data ownership to the people (and domains) who create it. Organizations can have data product managers who control the data in their domain. They’re responsible for ensuring data quality and making data available to those in the business who might need it. Data consistency is ensured through uniform definitions and governance requirements across the organization, and a comprehensive communication layer allows other teams to discover the data they need. Additionally, the decentralized data storage model reduces the time to value for data consumers by eliminating the need to transport data to a central store to power analytics. Finally, decentralized systems provide more flexibility, are easier to work on in parallel, and scale horizontally, especially when dealing with large datasets spanning multiple clouds.
Data as a product
This principle can be summarized as applying product thinking to data. Product thinking advocates that organizations must treat data with the same care and attention as customers. However, because most organizations think of data as a by-product, there is little incentive to package and share it with others. For this reason, it is not surprising that 87% of data science projects never make it to production.
Data becomes a first-class citizen in a data mesh architecture with its development and operations teams behind it. Building on the principle of domain-oriented data ownership, data product managers release data in their domains to other teams in the form of a “product.” Product thinking recognizes the existence of both a “problem space” (what people require) and a “solution space” (what can be done to meet those needs). Applying product thinking to data will ensure the team is more conscious of data and its use cases. It entails putting the data’s consumers at the center, recognizing them as customers, understanding their wants, and providing the data with capabilities that seamlessly meet their demands. It also answers questions like “what is the best way to release this data to other teams?” “what do data consumers want to use the data for?” and “what is the best way to structure the data?”
Self-serve data infrastructure as a platform
The principle of creating a self-serve data infrastructure is to provide tools and user-friendly interfaces so that generalist developers (and non-technical people) can quickly get access to data or develop analytical data products speedily and seamlessly. In a recent McKinsey survey, organizations reported spending up to 80% of their data analytics project time on repetitive data pipeline setup, which ultimately slowed down the productivity of their data teams.
The idea of the self-serve data infrastructure as a platform is that there should be an underlying infrastructure for data products that the various business domains can leverage in an organization to get to the work of creating the data products rapidly. For example, data teams should not have to worry about the underlying complexity of servers, operating systems, and networking. Marketing teams should have easy access to the analytical data they need for campaigns. Furthermore, the self-serve data infrastructure should include encryption, data product versioning, data schema, and automation. A self-service data infrastructure is critical to minimizing the time from ideation to a working data-driven application.
Federated computational governance
This principle advocates that data is governed where it is stored. The problem with centralized data platforms is that they do not account for the dynamic nature of data, its products, and its locations. In addition, large datasets can span multiple regions, each having its own data laws, privacy restrictions, and governing institutions. As a result, implementing data governance in this centralized system can be burdensome.
The data mesh more readily acknowledges the dynamic nature of data and allows for domains to designate the governing structures that are most suitable for their data products. Each business domain is responsible for its data governance and security, and the organization can set up general guiding principles to help keep each domain in check.
While it is prescriptive in many ways about how organizations should leverage technology to implement data mesh principles, perhaps the more significant implementation challenge is how that data flows between business domains.
Event streams are a continuous flow of “events” known as data points that flow from systems that generate data to systems that consume that data for different workloads. In our online store example, when a customer places an order, that “order event” is propagated to the various consumers who listen to that event. The consumer could be a checkout service to process the order, an email service that sends out confirmation emails, or an analytics service carrying out real-time customer order behaviors.
Event streams offer the best option for building a data mesh, mainly when the data involved is used by multiple teams with unique needs across an organization. Because event streams are published in real time, streams enable immediate data propagation across the data mesh. Additionally, event streams are persisted and replayable, so they let you capture both real-time and historical data with one infrastructure. Finally, because the stored events don’t change, they make for a great source of record, which is helpful for data governance.
In our work with Striim customers, we tend to see three common streaming patterns in a data mesh.
In the first pattern, data is streamed from legacy systems to create new data products on a self-service infrastructure (commonly on a public cloud). For example, medical records data can be streamed from on-premise EHR (electronic health records) systems to a real-time analytics system like GoogleBigQuery, to feed cloud applications used by doctors. In the meantime, operational monitoring applications on the data pipeline help to ensure that pipelines are operating as expected.

In the second pattern, data is also consumed as it moves along the pipeline. Data is processed (e.g. by continuous queries or window-based views) to create “data as a product applications”. For example, a financial institution may build a fraud detection application that analyzes streaming data to identify potential fraud in real time.

Once you have a data product (e.g. freshly analyzed data), you can share it with another data product (e.g. the original data source or day-to-day business applications like Salesforce). This pattern, also known as reverse ETL, enables companies to have actionable information at their points of engagement, allowing for more intelligent interactions.

To build a data mesh, you need to understand the different components (and patterns) that make up the enterprise data mesh architecture. In this article, Eric Broda gives a detailed overview of data mesh architectural patterns, bringing much-needed clarity to the “how” of a data mesh.

Still building on our e-commerce example, let’s walk through how these components could operate in a real-world data mesh scenario. For example, say our retail company has both a brick-and-mortar and online presence, but they lack a single source of truth regarding inventory levels. Disjointed systems in their on-premises data center can result in disappointing customer experiences. For example, customers shopping online may be frustrated to discover out-of-stock items that are actually available in their local store.
The retailer’s goal is to move towards an omnichannel, real-time customer experience, where customers can get a seamless experience no matter where (or when) they place their order. In addition, the retailer needs real-time visibility into inventory, to maintain optimal inventory levels at any point in time (including peak shopping seasons like Black Friday/Cyber Monday).
A data mesh suits this use case perfectly, and allows them to keep their on-premises data center running without disruption. Here’s how they can build a data mesh with Striim’s unified streaming and integration platform.

A data mesh unlocks endless possibilities for organizations for various workloads, including analytics and building data-intensive applications. Event streams offer the best communication medium for implementing a data mesh. They provide efficient data access to all data consumers and bridge the operational/analytical divide, giving batch and streaming users a real-time, fast, and consistent view of data.
Striim has all the capabilities to build a data mesh using event streams, as shown above. Striim makes it easy to create new streams for data product owners with a simple streaming SQL query language and role-based access to streams. Additionally, Striim provides real-time data integration, connecting over 150 sources and targets across hybrid and multi-cloud environments.
Tutorial
Operational Analytics
Visualize real time data with Striim’s powerful Analytic Dashboard
Capture Data Updates in real time
Use Striim’s postgrescdc reader for real time data updates
Build Real-Time Analytical ModelsUse dbt to build Real-Time analytical and ML models
On this page
In part 1 of PostgreSQL to Bigquery streaming, we have shown how data can be securely replicated between Postgres database and Bigquery. In this
recipe we will walk you through a Striim application capturing change data from postgres database and replicating to bigquery for real time visualization.
In addition to CDC connectors, Striim has hundreds of automated adapters for file-based data (logs, xml, csv), IoT data (OPCUA, MQTT), and applications such as Salesforce and SAP. Our SQL-based stream processing engine makes it easy to
enrich and normalize data before it’s written to Snowflake.
Traditionally Data warehouses that required data to be transferred use batch processing but with Striim’s streaming platform data can be replicated in real-time efficiently with added cost.
Data loses its value over time and businesses need to be updated with most recent data in order to make the right decisions that are vital to overall growth.
In this tutorial, we’ll walk you through how to create a replica slot to stream change data from postgres tables to bigquery and use the in-flght data to generate analytical dashboards.
PostgreSQL CDC: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
Continuous Query : Striim Continuous queries are are continually running SQL queries that act on real-time data and may be used to filter, aggregate, join, enrich, and transform events.
Window: A window bounds real-time data by time, event count or both. A window is required for an application to aggregate or perform calculations on data, populate the dashboard, or send alerts when conditions deviate from normal parameters.
BigQueryWriter: Striim’s BigQueryWriter writes the data from various supported sources into Google’s BigQuery data warehouse to support real time data warehousing and reporting.
For this recipe, we will host our app in Striim Cloud but there is always a free trial to visualize the power of Striim’s Change Data Capture.
For CDC application on a postgres database, make sure the following flags are enabled for the postgres instance:
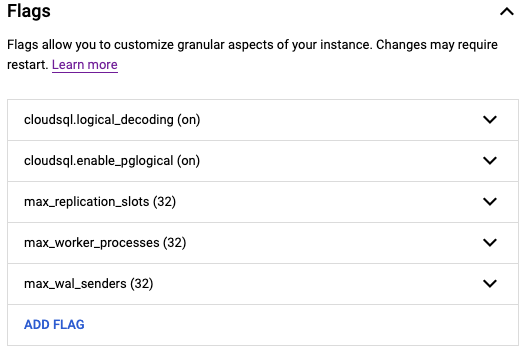
Create a user with replication attribute by running the following command on google cloud console:
CREATE USER replication_user WITH REPLICATION IN ROLE cloudsqlsuperuser LOGIN PASSWORD ‘yourpassword’;
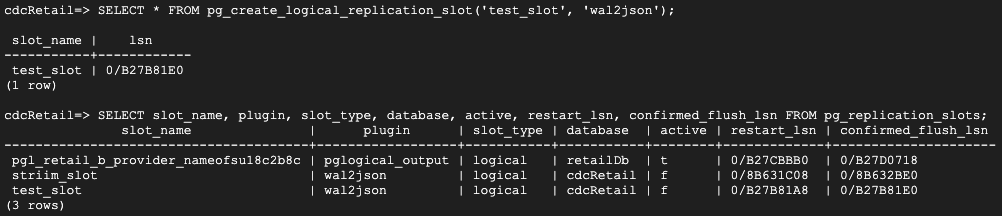
Follow the steps below to set up your replication slot for change data capture:
Create a logical slot with wal2json plugin.
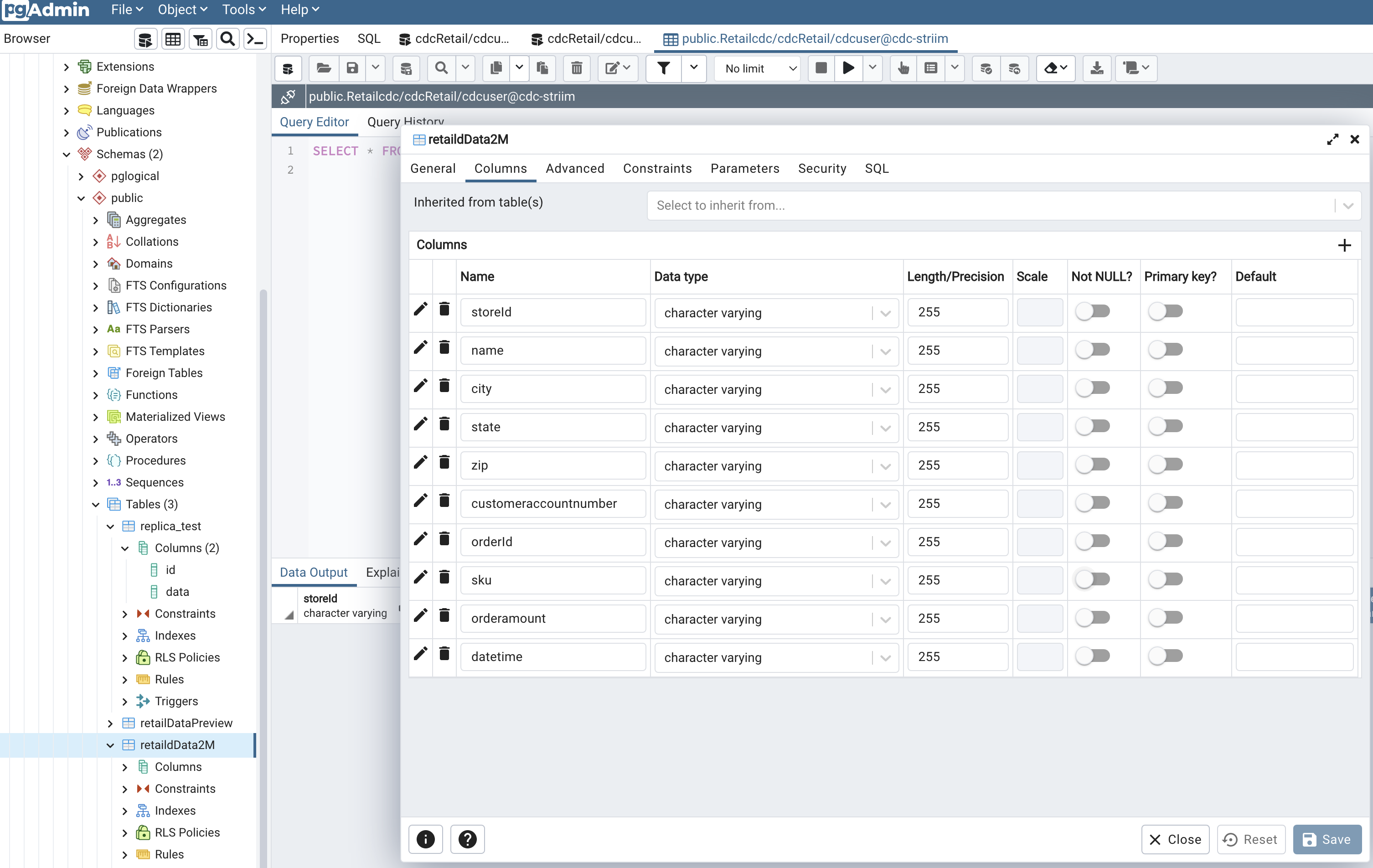
Create table that needs to be replicated for capturing changes in data. I have used PgAdmin, which is a UI for postgres database management system to create my table and insert data into it.
Follow the steps described in part 1 for creating an app from scratch. You can find the TQL file for this app in our git repository.
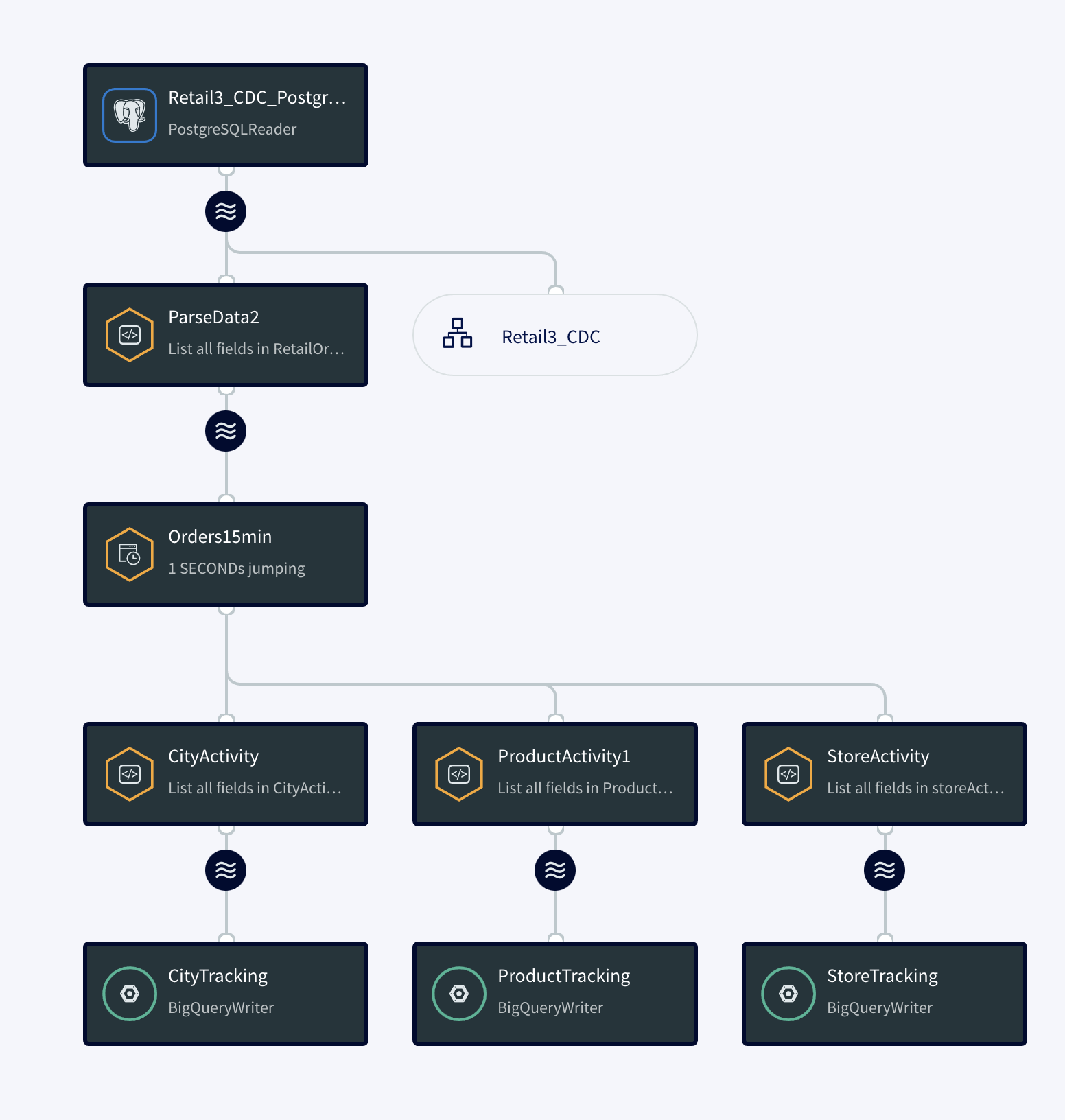
The diagram below simplifies each component of the app.
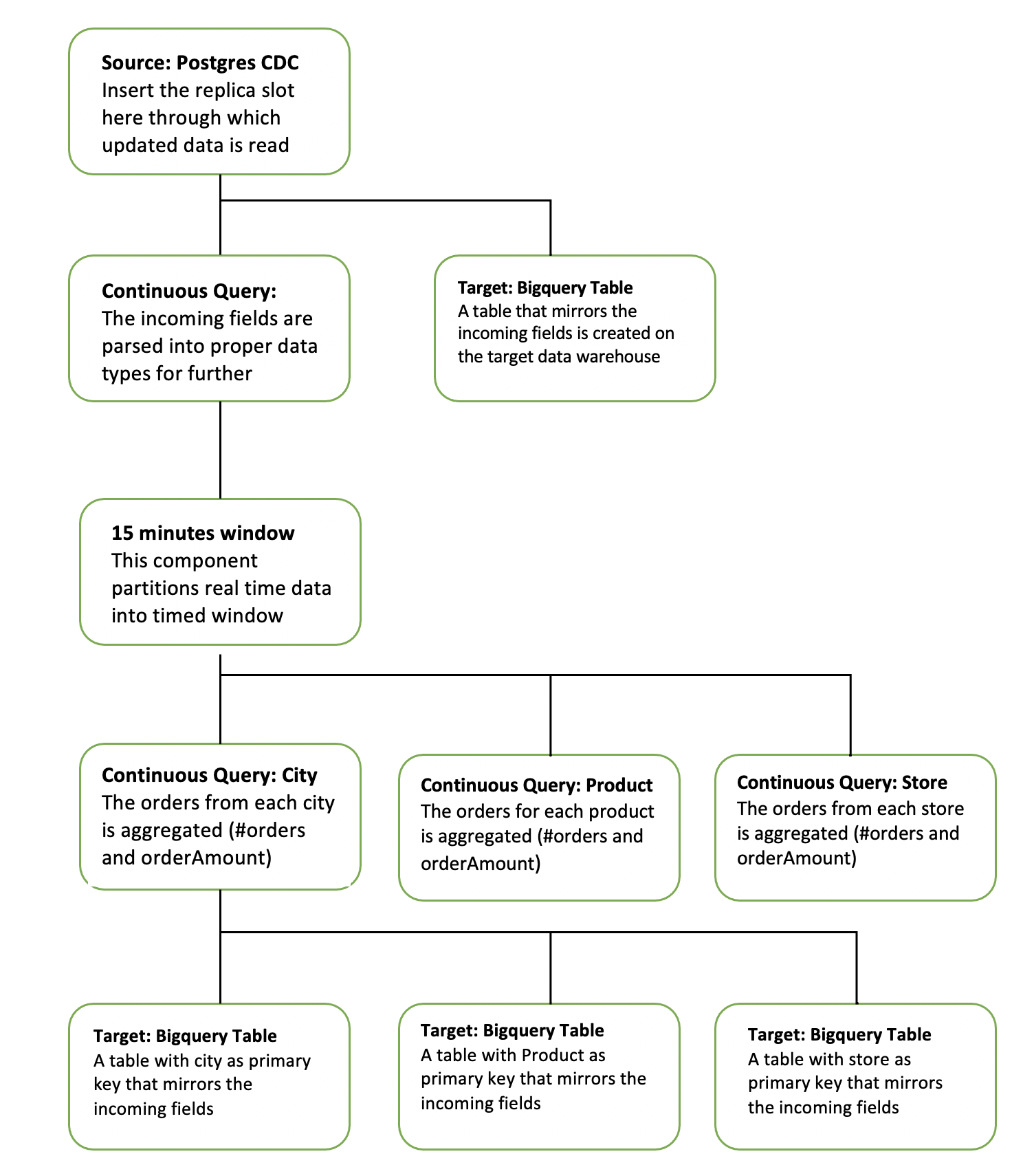
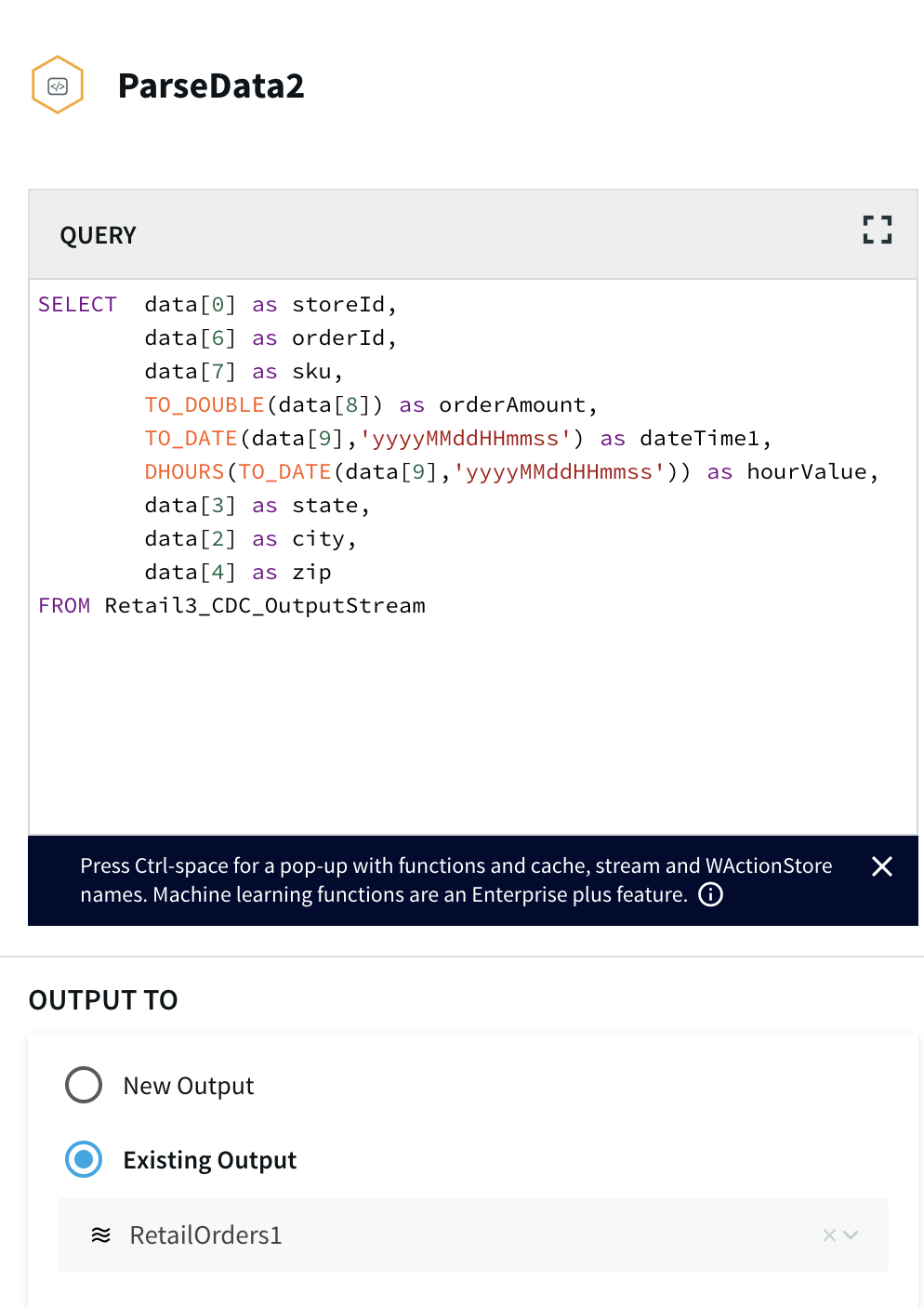
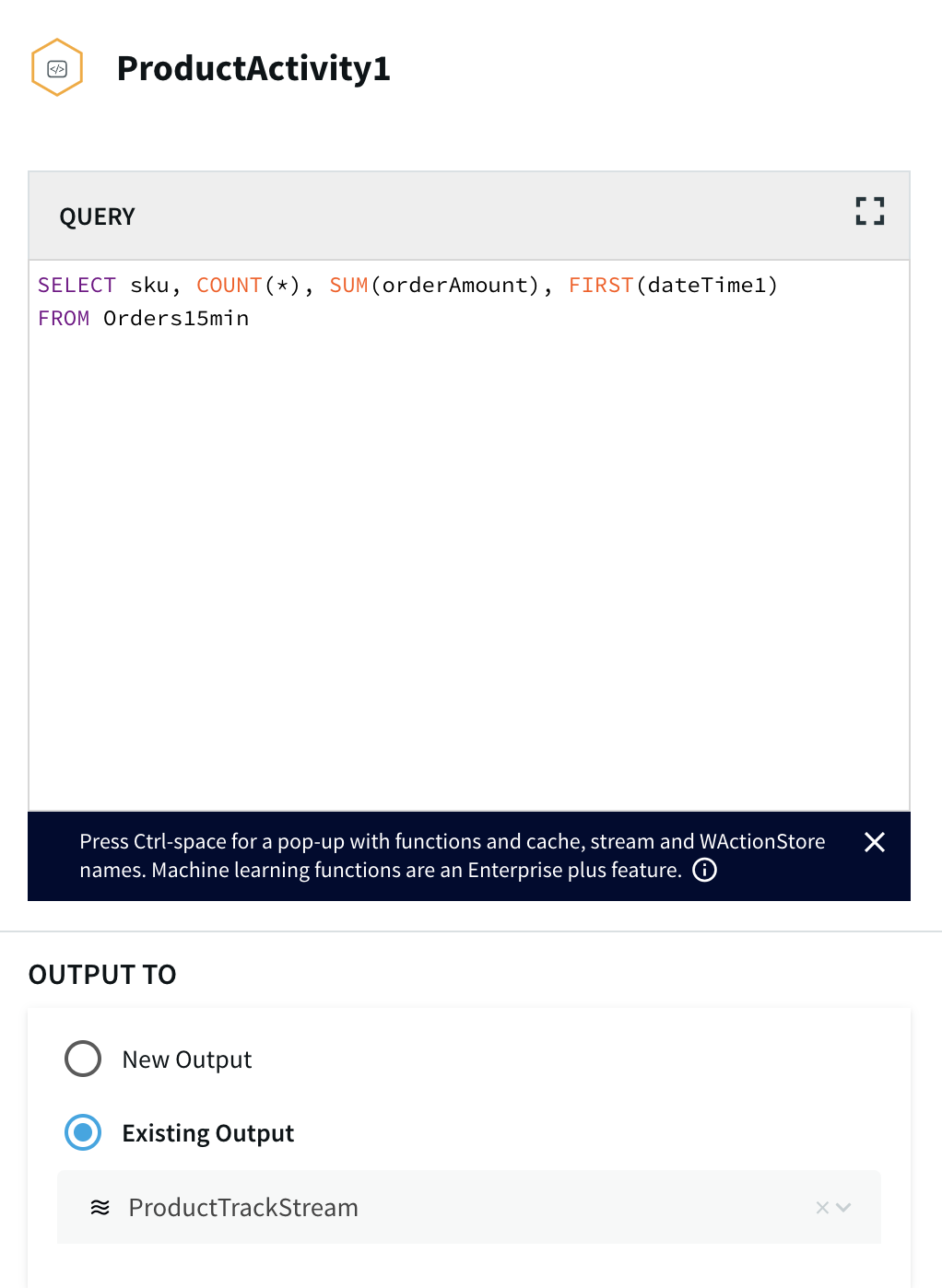
The continuous query is a sql-based query that is used to query the database.The following queries are for ParseData2 where data is transformed into proper data type for further processing and ProductActivity1 where product data is aggregated to derive useful insights about each product.
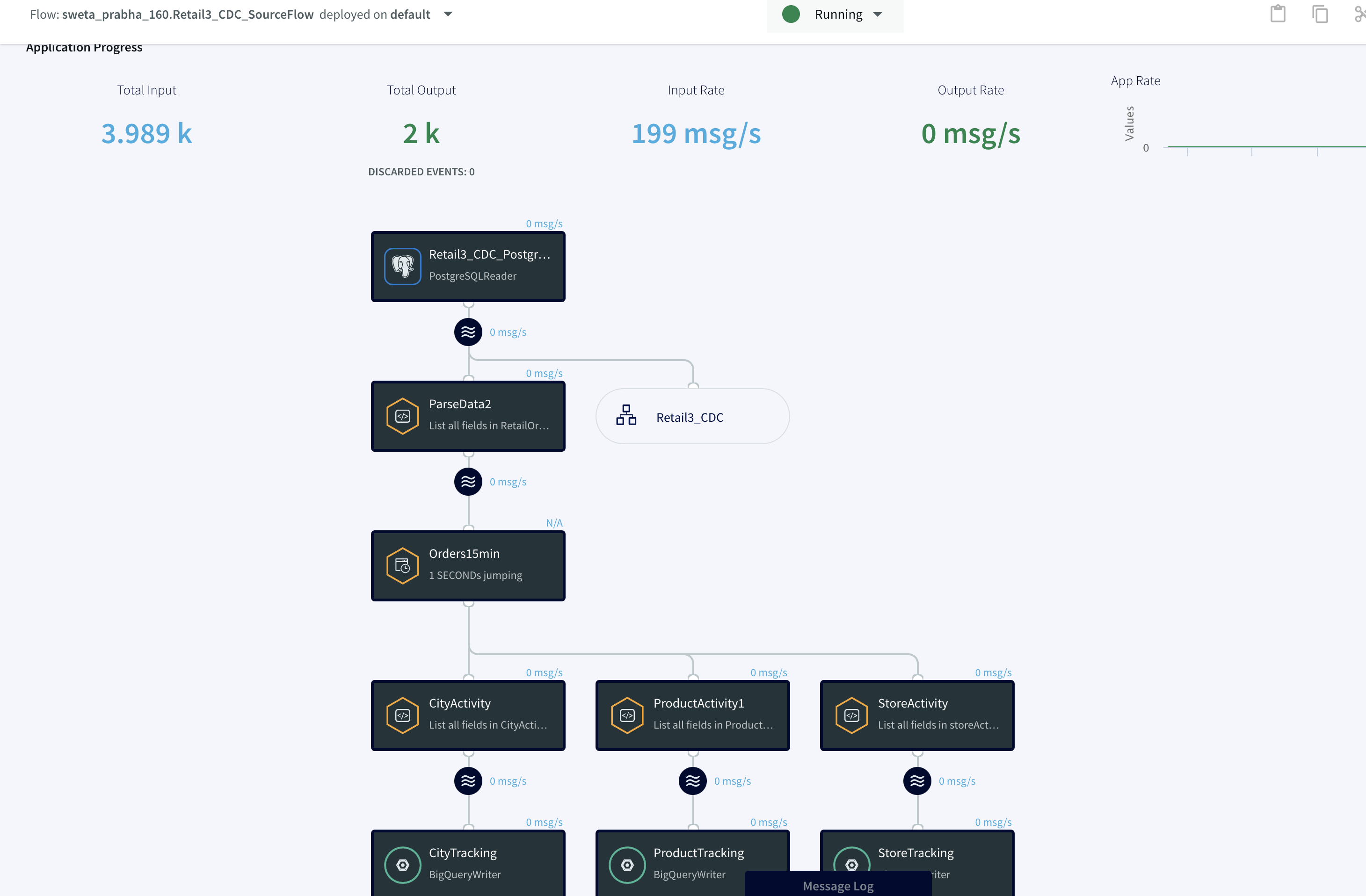
In this step you will deploy and run the final app to visualize the power of Change Data Capture in Striim’s next generation technology.
Step 1: Follow this recipe to create a Replication Slot and user for Change Data Capture
The replication user reads change data from your source database and replicates it to the target in real-time.
Step 2: Download the dataset and TQL file from our github repo and set up your Postgres Source and BigQuery Target.
You can find the csv dataset in our github repo. Set up your BigQuery dataset and table that will act as a target for the streaming application
Step 3: Configure source and target components in the app
Configure the source and target components in the striim app. Please follow the detailed steps from our recipe.
Step 4: Run the streaming app
Deploy and run real-time data streaming app
Our tutorial showed you how easy it is to capture change data from PostgreSQL to Google BigQuery, a leading cloud data warehouse. By constantly moving your data into BigQuery, you could now start building analytics or machine learning models on top, all
with minimal impact to your current systems. You could also start ingesting and normalizing more datasets with Striim to fully take advantage of your data when combined with the power of BigQuery..
As always, feel free to reach out to our integration experts to schedule a demo, or try Striim for free here.

Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL is an open-source relational database management system.

BigQuery is a serverless, highly scalable multicloud data warehouse.



