The supply chain industry is the backbone on which many industries rely, such as manufacturing and retail. It produces large amounts of valuable business data daily, but according to a McKinsey study, only 2% of companies have visibility into their supply base beyond the second tier (e.g. chip fabrication in the semiconductor supply chain).
The supply chain industry is the backbone on which many industries rely, such as manufacturing and retail. It produces large amounts of valuable business data daily, but according to a McKinsey study, only 2% of companies have visibility into their supply base beyond the second tier (e.g. chip fabrication in the semiconductor supply chain).
66% of supply chain companies believe using data analytics is of critical importance for their future operations, but extracting value from supply chain data isn’t easy. Since the industry is split into various areas — such as procurement, logistics, and warehouses — data silos are common, with data scattered across legacy systems and spreadsheets. This makes it challenging to collect and analyze supply chain data.
Smart data pipelines unify data from multiple sources and enable real-time analytics of supply chain data. This gives managers the ability to make decisions based on a summary of accurate and timely data in the form of charts, graphs, and dashboards — or respond to real-time alerts generated automatically. Real-time analytics in the supply chain helps to avoid stockouts, protect drivers, tackle supply and demand issues, and increase the overall efficiency and profitability.
Boosts Decision-Making for Procurement
Real-time analytics can help you collect and analyze procurement data for better decision-making. Procurement managers can pull and analyze different sets of data, including supplier and buyer information, benchmark price, price variance and fulfillment, and invoice unit. This data can be collected from an operational system like an enterprise resource planning (ERP) system.
Spend analysis
You can use descriptive analytics to consolidate purchasing-related data and get insights to minimize costs without compromising efficiency. For example, you can use descriptive analytics to collect historical data for creating visualizations (e.g., reports) on spend analysis to work on budgeting. This can help to answer questions, such as:
- What is the organization buying?
- From where and for whom is the organization buying?
- Which categories have the largest spend?
Supplier negotiation
One way real-time analytics can save money is by monitoring the organization’s purchasing history and providing real-time insights via prescriptive analytics to compare supplier pricing. When this information is presented in real time in the form of detailed reports, sourcing teams can use it to negotiate with suppliers on pricing if it’s higher than competitors. This also benefits your relationship with the supplier; they can identify missed opportunities in sales that were lost to lower-priced alternatives.
Introduces Better Visibility in Warehouses
According to a survey, around 70% of supply chain leaders said that they want better visibility into their warehouse. Real-time analytics can help manage warehouse operations and give visibility into inventory, fulfillment, labor, and production.
Automation
You can identify functions that take a lot of time, or where manual errors are recurrent (e.g., clerical errors), and incorporate automation to improve efficiency and save costs.
Take picking products for order in warehouse operations, which can take a lot of time when done manually. Real-time analytics can use artificial intelligence for automated picking systems to streamline the process. These systems can use machine learning to analyze routes for picking and find the most efficient route for each item by reducing walking and sorting time.
Inventory management
Real-time analytics can help you to view, manage, and optimize inventory levels in real time. You can view top-selling, on-hand, and out-of-stock items on a dashboard. With a single view, you can adjust inventory in all warehouses.
Your dashboard can show that your warehouse has plenty of products that aren’t in demand at the moment, whereas there’s not enough stock for in-demand products. This is done by analyzing data, such as seasonal influence (e.g., Black Friday), trend forecasts, and historical sales.
Before you are out of stock, predictive analytics can be used for demand forecasting. It can balance your purchasing to get sufficient stock for the right products on time. These products can then be placed in pick-up and staging areas in the warehouse to improve the delivery time and enhance the customer experience.
On a similar note, your dashboard can show dead stock — items stuck on the shelf for too long — and recommend ways to deal with it. For instance, you can get rid of dead stock by putting up a clearance sale on your e-commerce website or bundling it with other products at a discount price.
Tracks Logistics Operations
You can use real-time analytics to improve your operational efficiency and reduce accidents.
On-time and reliable delivery of goods
Real-time insights can make predictions on estimated transit times and improve planning for shipments. This is done by feeding real-time data to route planning algorithms that can map out the best possible route, helping your drivers avoid disruptions such as traffic jams and weather issues.
With smart sensors and the internet of things (IoT), you can notify key personnel about the status and condition of in-transit goods throughout the supply chain. For this purpose, sensors are used to monitor factors such as shock, humidity, light, temperature, and location. This can be especially useful to identify the likelihood of a food item going bad or a fragile product getting broken in real time, where the system generates an alert and sends it to the supply chain management.
Accident prevention
According to a study, every year, more than 20% of all fleet vehicles get into accidents. Most of these issues are traced to bad driver behaviors, which cause employers in the US a lot of direct and indirect damage. Poor driver behavior includes the following:
- Driving when drowsy
- Risky driving
- Speeding
- Harsh braking
You can use real-time analytics with smart cams and electronic logging devices to assess driving behavior. For instance, you can capture data, such as when a driver accelerates quickly without keeping a safe distance between themselves and other vehicles or when a driver is often involved in harsh braking while changing lanes. With real-time analytics, you can get a single daily view that can detect drivers with recurrent driving patterns and enroll them in a driver safety awareness program.
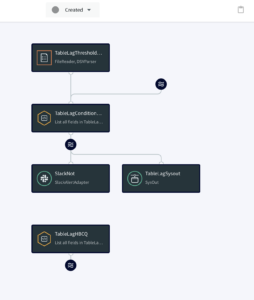
Adopt Real-time Supply Chain Analytics With Striim
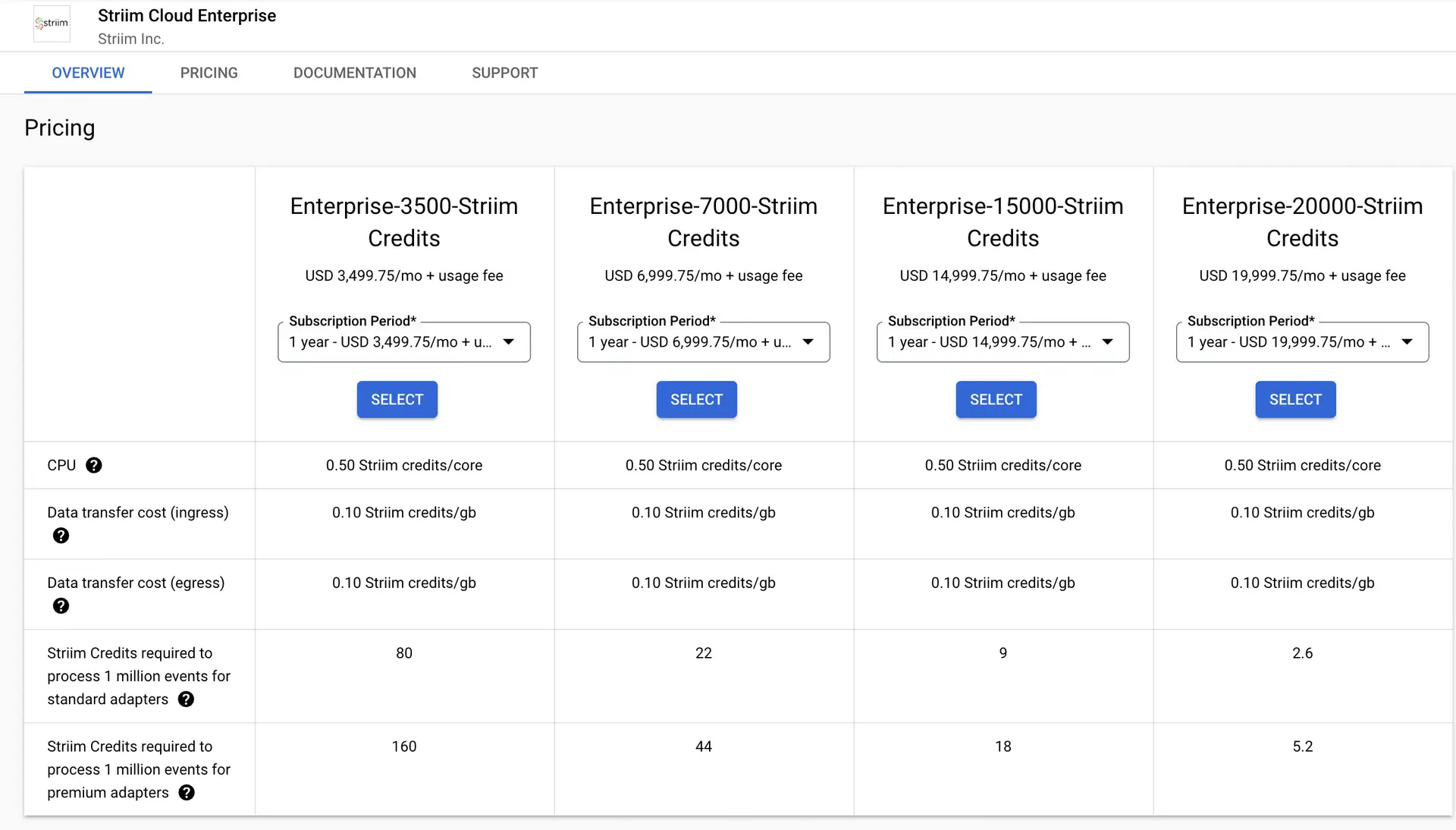
Now that you know about the different ways in which real-time analytics can improve supply chain performance, you need to look for a reliable tool that can help you to implement it on an enterprise level. For this purpose, consider looking into Striim for advanced analytics capabilities.
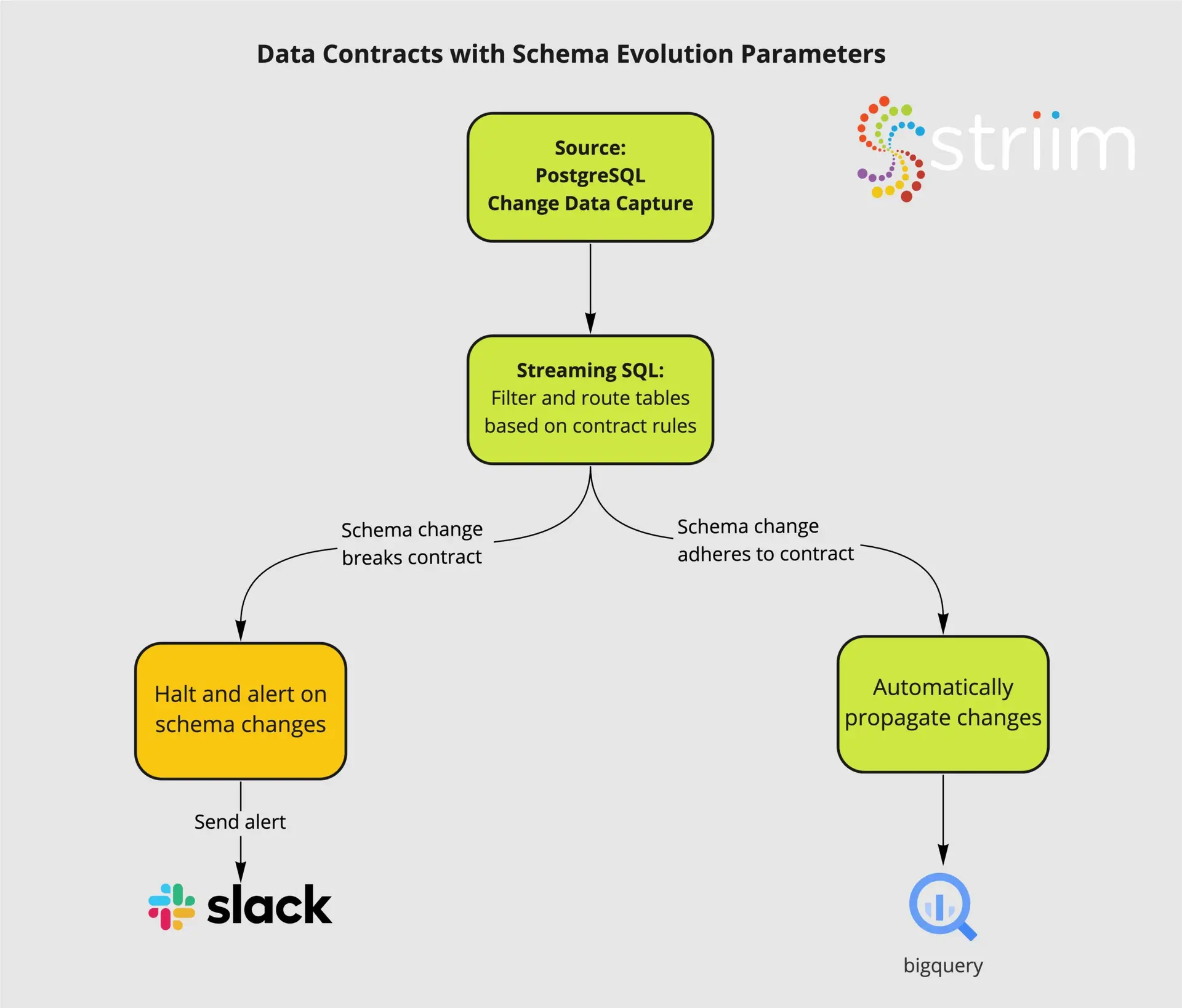
Striim is a real-time data integration and streaming platform that supports streaming analytics and delivery of fresh data to analytics systems. It acts as a real-time connector between your data sources (e.g. a warehouse management system) and destinations, like a cloud data warehouse that feeds into a business intelligence (BI) reporting tool like Tableau. No matter where your data resides, Striim can connect it — in real time — and provide actionable insights throughout your supply chain.
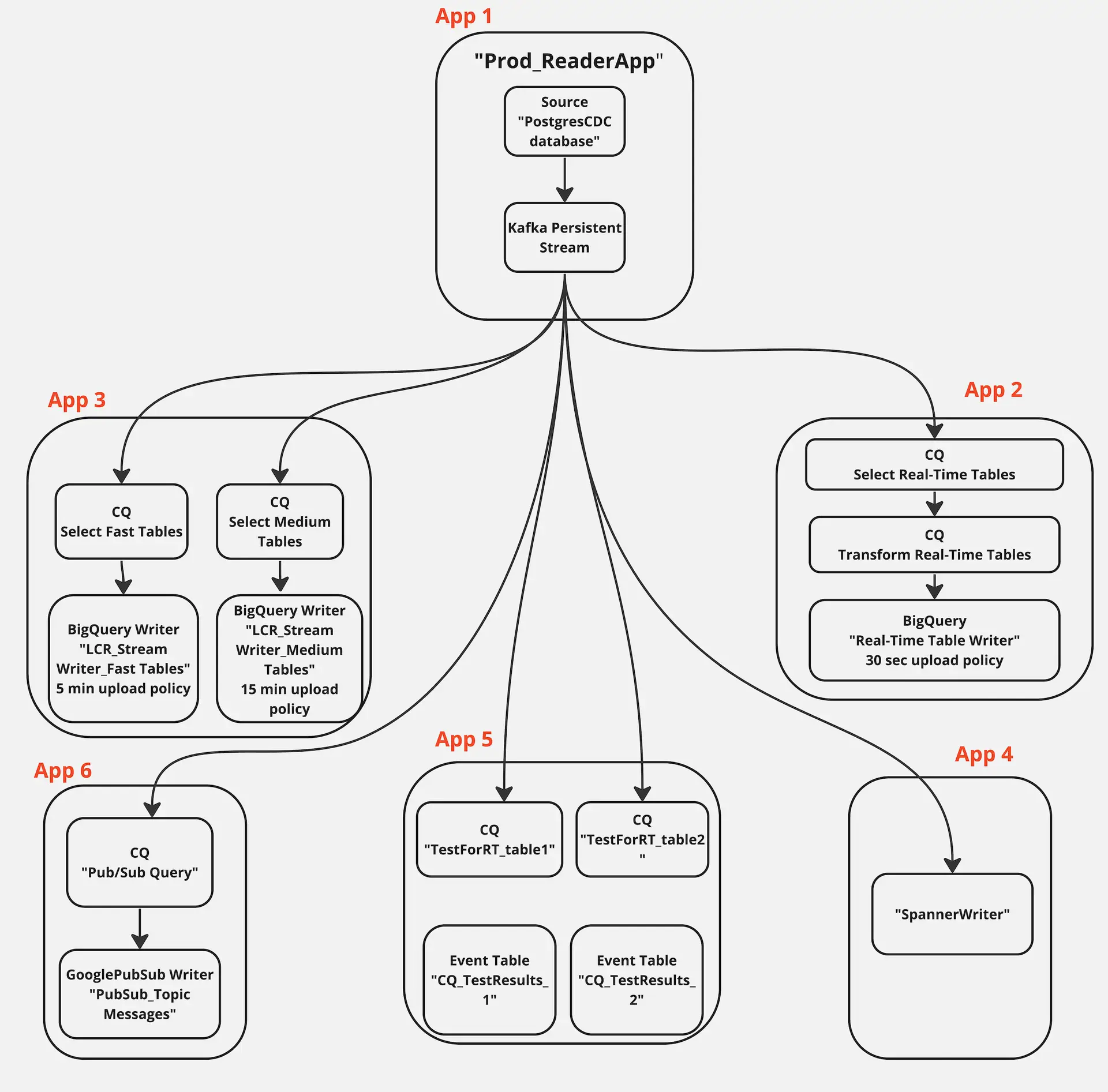
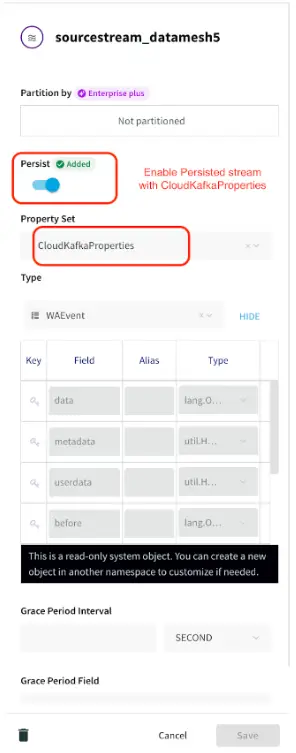
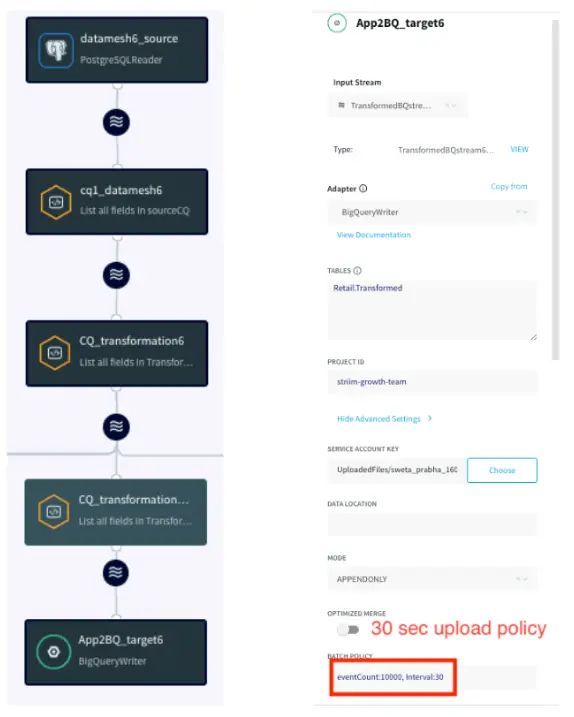
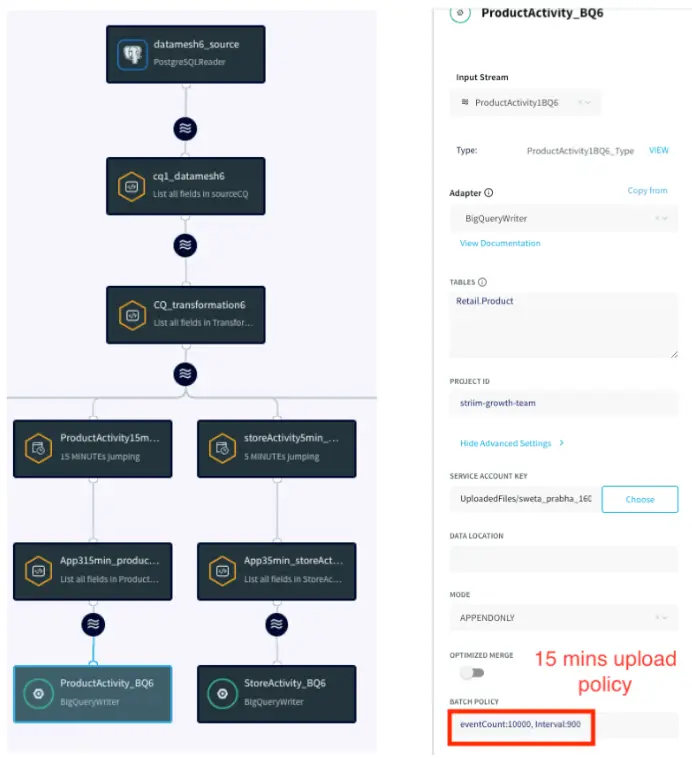
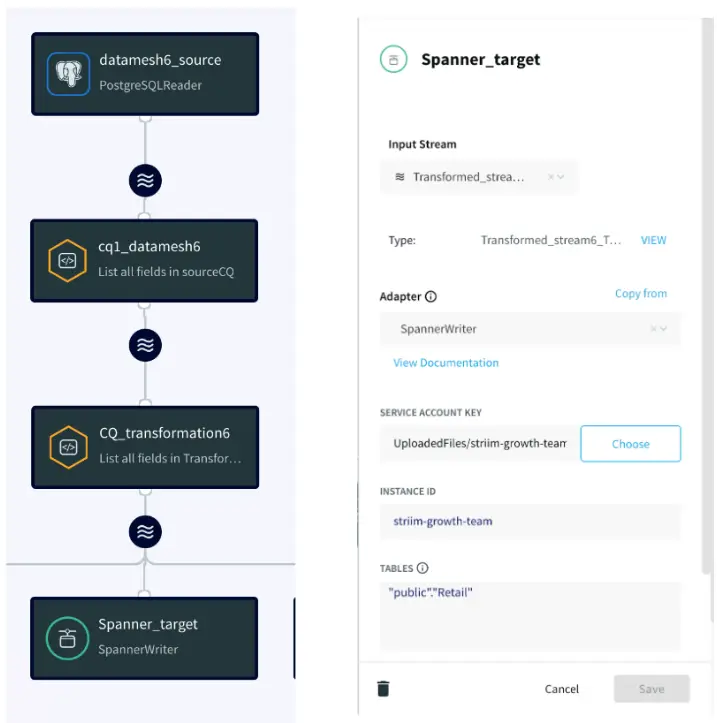
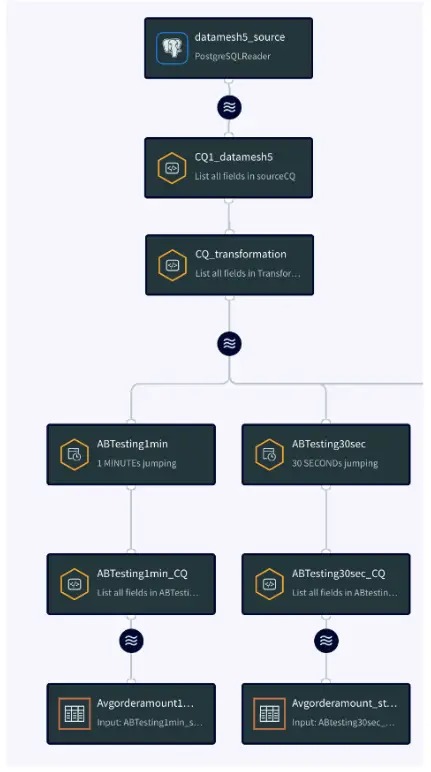
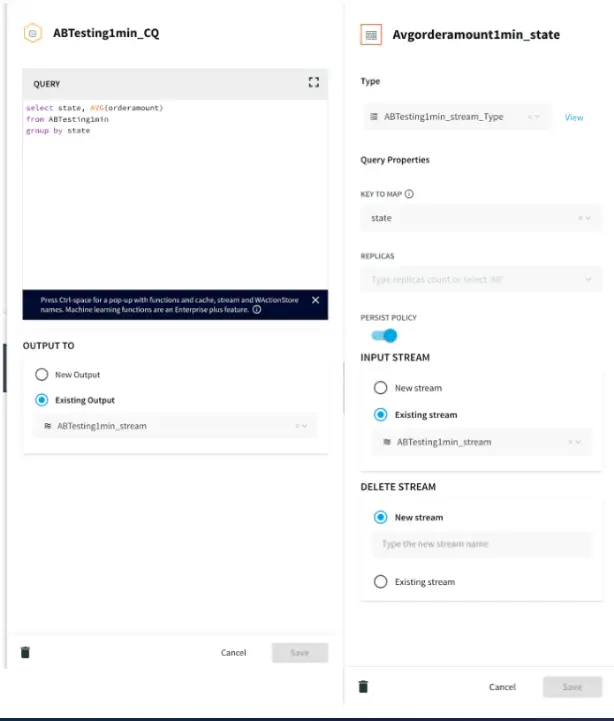
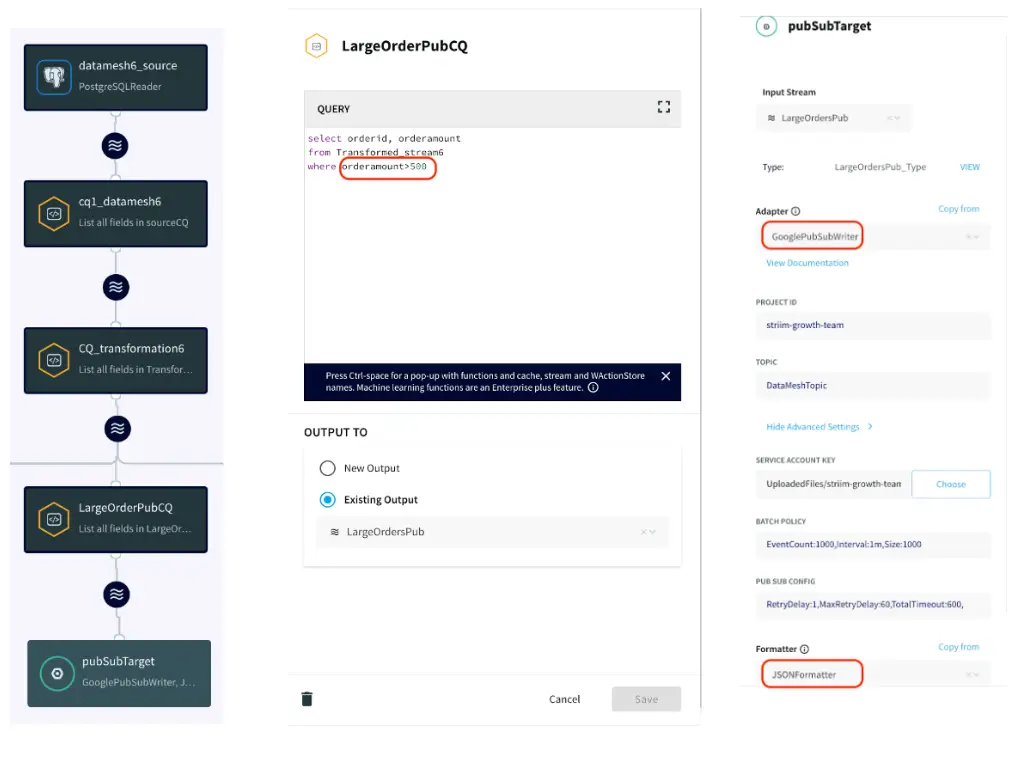
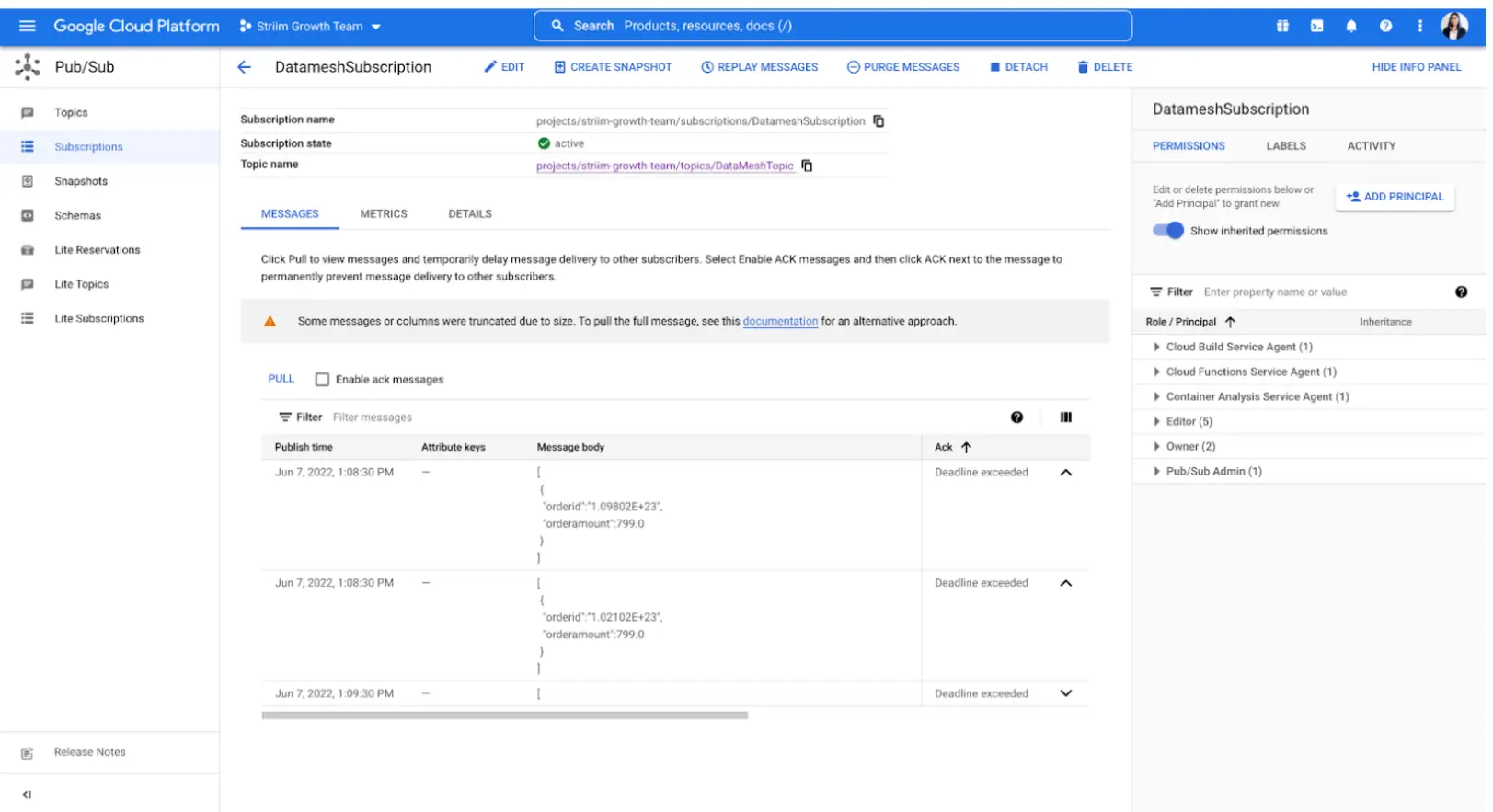
Striim has supported several organizations with their supply chain operations. For example, Striim has helped Macy’s, a leading retail chain, to adopt real-time inventory visibility. Below is a diagram that shows how Macy’s uses Striim to send real-time order and inventory data from its on-premise mainframe systems to business applications and dashboards in Google Cloud. This way, Macy’s has streamlined its inventory and has been able to adjust stock levels easily.

If you’re looking to modernize your supply chain to get a competitive advantage, learn more about Striim’s real-time analytics solution and request a free trial or sign up for a demo today.