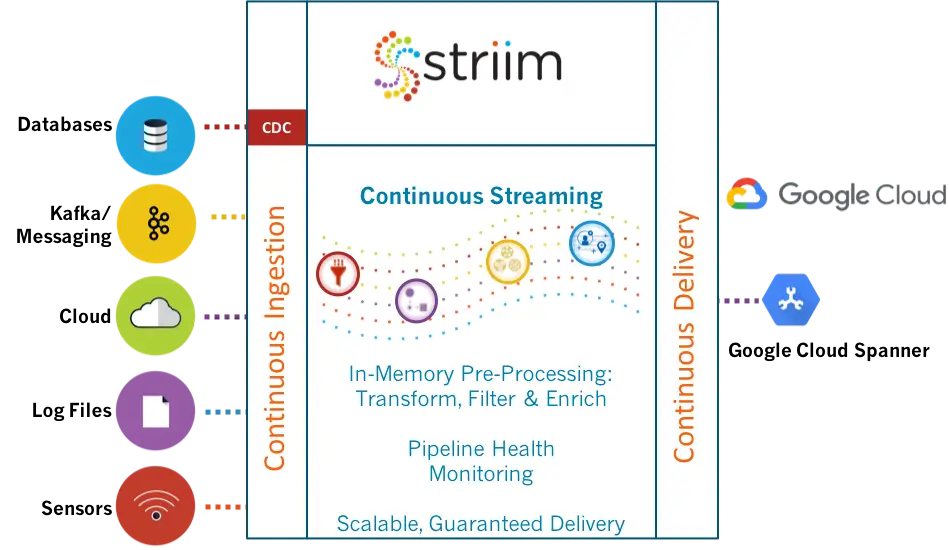
Now that you have a high-level overview of the Striim platform, let’s discuss how you can build data iPaaS applications with Striim.
You can deploy the entire platform in the cloud either by bringing your own license or as a metered iPaaS service. This gives you everything – it gives you all the sources, all the targets, and all the capabilities of the platform. There are also specific versions that you can deploy for particular solutions. So, for example, if you have on-premises Oracle databases and you want to push that data, as it’s changing, say to Azure SQL Data Warehouse, you can use that specific solution. You can still work with all of the sources, but you’re limited to delivering the data into Azure SQL Data Warehouse. There are dozens of specific cloud service solutions. They also are metered; they run as iPaaS in the cloud.
There are also a lot of different flavors of iPaaS. People usually bring up the multi-tenant type of iPaaS where the vendor hosts the service for you, allowing you to login and have access within an environment to be able to build data flows, etc. Striim chose not to go that route because customers are not typically that happy with the notion of being in a joint, multi-tenant environment where they are worried about data security and being guaranteed use of resources so that their applications will run at the right speed, etc.
Instead, Striim went with the ability to purchase the platform on Azure, Google Cloud, or Amazon as a metered service. With this approach, it’s running in your cloud environments, so you control the security, data, and everything else. Customers are more comfortable with this than the notion of a multi-tenant solution for iPaaS. As you can see in this video, we have metered iPaaS solutions for data in the marketplace for all three major cloud environments – Azure, AWS, and Google Cloud.
When you are working with the platform, on-premises or in the cloud, you interact with it through our intuitive web-based UI. This provides access to existing applications, as well as being able to import and create new applications.
You can start by building or importing applications, so, for example, if you’ve already built something in development, you can import it into production. If you are starting from scratch, you begin with an empty application and drag and drop components into the flow designer. But the easier way to get going is through the wizards which provide a large number of application templates. A lot of users start with a template because it enables you to rapidly build simple data flows, and check everything is correct as you go along.
For example, if you wanted to read from a MySQL database on-premises and deliver into Azure Cosmos DB, you could name the application, “MySQLtoCosmos,” and put it in a namespace. Namespaces keep things separate, and the way our security works, you can lock things down so that only certain people have access to certain namespaces. You can do much finer-grain things than that. You can give users access to the data that’s produced as the end result of the data pipeline, but not the raw data because that may have personally identifiable information in it. In our example, we will filter all that out before we push it into the cloud.
So you create a new namespace and save it. And then you can actually build data iPaaS applications, letting the wizards walk you through setting up the connection. Once all properties are configured, it will test everything to make sure that the connection is correct. This is an important step. One of the reasons Striim introduced its many wizards and templates was to make the development process as easy, intuitive, and fast as possible.
So in these steps, we check to make sure that not only does the connection to the database work, but also that connection has the right privileges, and that change data capture (CDC) is turned on. CDC collects all the inserts, updates, and deletes as they happen in a database (this is enabled at the database level). It also checks that you can get to the database metadata so you can actually see what tables and columns there are. If any of these steps don’t work, then the wizards will tell you what to do. Basically the instructions in the manual are mirrored by steps in the wizards so people know exactly what to do. In certain cases, the wizards can even do it for you. Once the connection is verified, you get to choose your data and go on to the next step. And then finally you’ll configure your target.
To learn more about how to build data iPaaS applications with Striim, read our Striim Platform Overview data sheet, set up a quick demo with a Striim technologist, or provision the Striim platform as an iPaaS solution on Microsoft Azure, Google Cloud Platform, or Amazon Web Services.
If you missed it or would like to catch up on this iPaaS blog series, please read part 1, “The Striim Platform as a Data Integration Platform as a Service.”