In this post, we’ll walk through how to build a real-time AI-powered sentiment analysis pipeline using Striim, OpenAI, and LangChain with a simple, high performance pipeline.
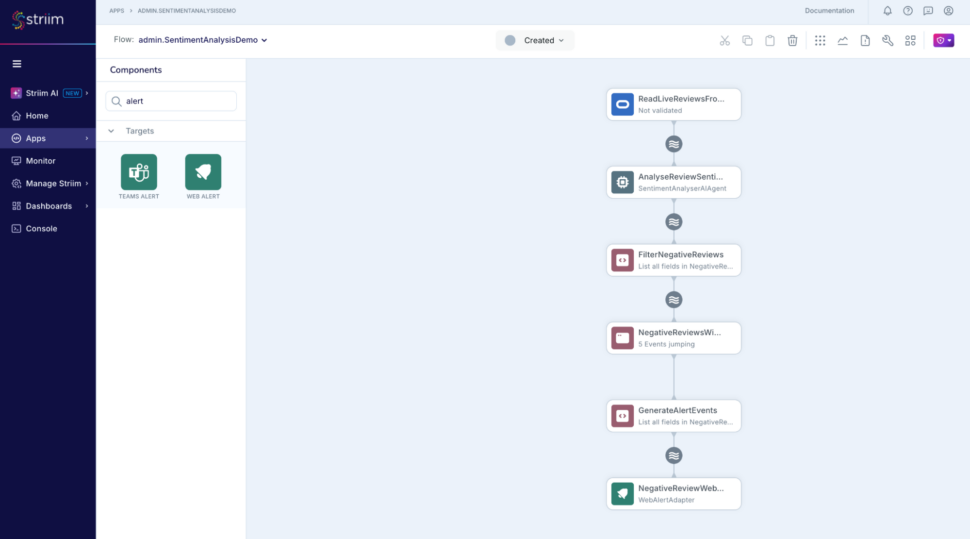
Real-time sentiment analysis is essential for applications such as monitoring and responding to customer feedback, detecting market sentiment shifts, and automating responses in conversational AI. However, implementing it often requires setting up Kafka and Spark clusters, infrastructure, message brokers, third-party data integration tools, and complex event processing frameworks, which add significant overhead, operational costs, and engineering complexity. Similarly, traditional machine learning approaches require large labeled datasets, manual feature engineering, and frequent model retraining, making them difficult to implement in real-time environments.
Striim eliminates these challenges by providing a fully integrated streaming, transformation, and AI processing platform that ingests, processes, and analyzes sentiment in real-time with minimal setup.
We’ll walk you through the design covering the following,
- Building the AI Agent using Striim’s open processor
- Using Change Data Capture (CDC) technology to capture the review contents in real time using Striim Oracle CDC Reader.
- Group the negative reviews in Striim partitioned windows
- Generate real time notifications using Striim Alert manager if the number of negative reviews exceeds the threshold values and transform them into actions for the business.
Why Sentiment Analysis using Foundation Models? How is it different from traditional Machine Learning Based Approaches?
Sentiment analysis has traditionally relied on supervised machine learning models trained on labeled datasets, where each text sample is explicitly categorized as positive, negative, or neutral. These models typically require significant pre-processing, feature engineering, and domain-specific training to perform effectively. However, foundation models, such as large language models (LLMs), simplify sentiment analysis by leveraging their vast pretraining on diverse text corpora.
One of the key differentiators of foundation models is their unsupervised learning approach. Unlike traditional models that require labeled sentiment datasets, foundation models learn patterns, relationships, and contextual meanings from large-scale, unstructured text data without explicit supervision. This enables them to generalize sentiment understanding across multiple domains without additional training.
Why Real-Time Streaming Instead of Batch Jobs?
Real-time sentiment analysis enables businesses to make swift, data-driven decisions by transforming customer feedback, social media discussions, and other textual data into actionable insights as they occur. Unlike batch-based analysis, which processes data in scheduled intervals, real-time analysis ensures that organizations can respond immediately when sentiment changes.
- Instant Decision-Making – Businesses can act on customer feedback, social media trends, and emerging issues in the moment, rather than waiting for delayed batch processing. This allows proactive engagement rather than reactive damage control.
- Crisis Management – In cases of negative publicity, brand reputation issues, or product complaints, real-time sentiment analysis enables companies to intervene quickly, mitigating risks before they escalate.
- Enhanced Customer Experience – Organizations can integrate real-time sentiment analysis with tools like Slack, Salesforce, and Microsoft Dynamics, allowing automated alerts and instant responses to customer feedback. This improves customer satisfaction and fosters stronger relationships.
- Competitive Advantage – Companies that react faster to market sentiment gain a strategic edge over competitors who rely on delayed batch analysis, enabling them to pivot business strategies and marketing efforts in real time.
- Dynamic Trend Monitoring – Social media sentiment and public opinion shift rapidly. Real-time analysis ensures businesses stay updated on trending topics, emerging concerns, and viral events, helping them adjust messaging and engagement strategies on the fly.
- Fraud and Risk Detection – In industries like finance and cybersecurity, real-time sentiment analysis can detect anomalies and suspicious activities (e.g., sudden spikes in negative sentiment around a stock or service) and trigger automated responses to mitigate risks proactively.
By integrating real-time sentiment analysis into business communication and CRM platforms like Slack, Salesforce, and Microsoft Dynamics, organizations can automate workflows, trigger alerts, and enable teams to respond instantly to sentiment shifts—leading to smarter decision-making, better customer experiences, and greater operational efficiency.
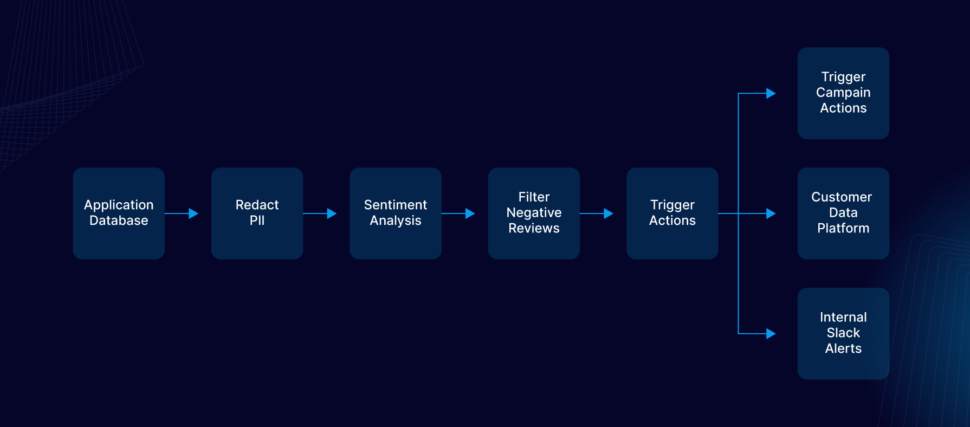
Problem statements
A centralized Oracle database is used by the feedback systems.
The business analytics team has been collecting the feedback in batches, manually process and coming up with insights to improve the customer experience at the stores with negative feedback.
- Real-time data synchronization : The submitted feedback must be captured in real-time without impacting the performance of the centralised Oracle database
- Real-time analysis of the feedback : The captured feedback must be immediately analysed to figure out the sentiment.
- Real-time windowing and notification : The negative feedback should be grouped by stores, notifications should be generated upon hitting threshold and sent to the external system for converting the data to action.
Solution
Striim has all the necessary features for the use case and the problem statements described.
- Reader : Capture real-time changes from Oracle database.
- Open processor : Extended program used to analyse the real time events carrying the content of the feedback using AI.
- Continuous query : Filter the negative review and send downstream
- Partitioned window : Group the negative reviews for each store and send downstream upon hitting threshold.
- Alert subscription : Send web alert notification to the user whenever the partitioned window sends down an event.
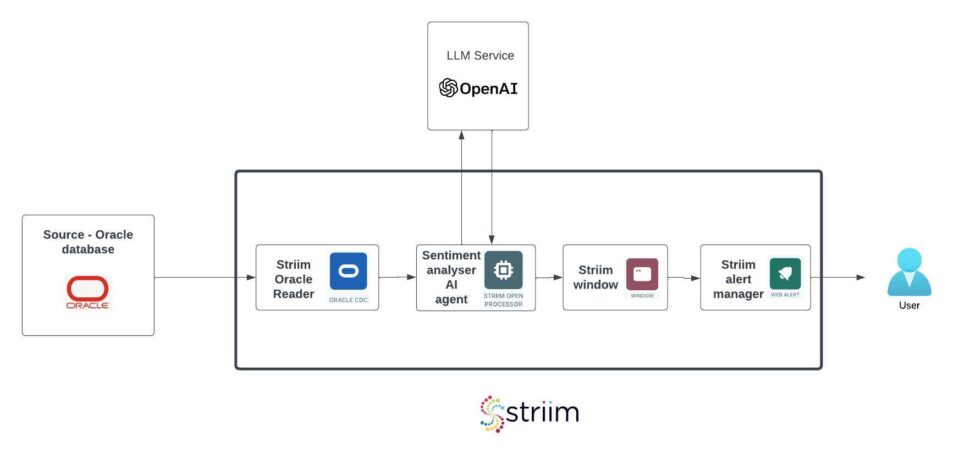
Step by step instructions
Set up Striim Developer 5.0
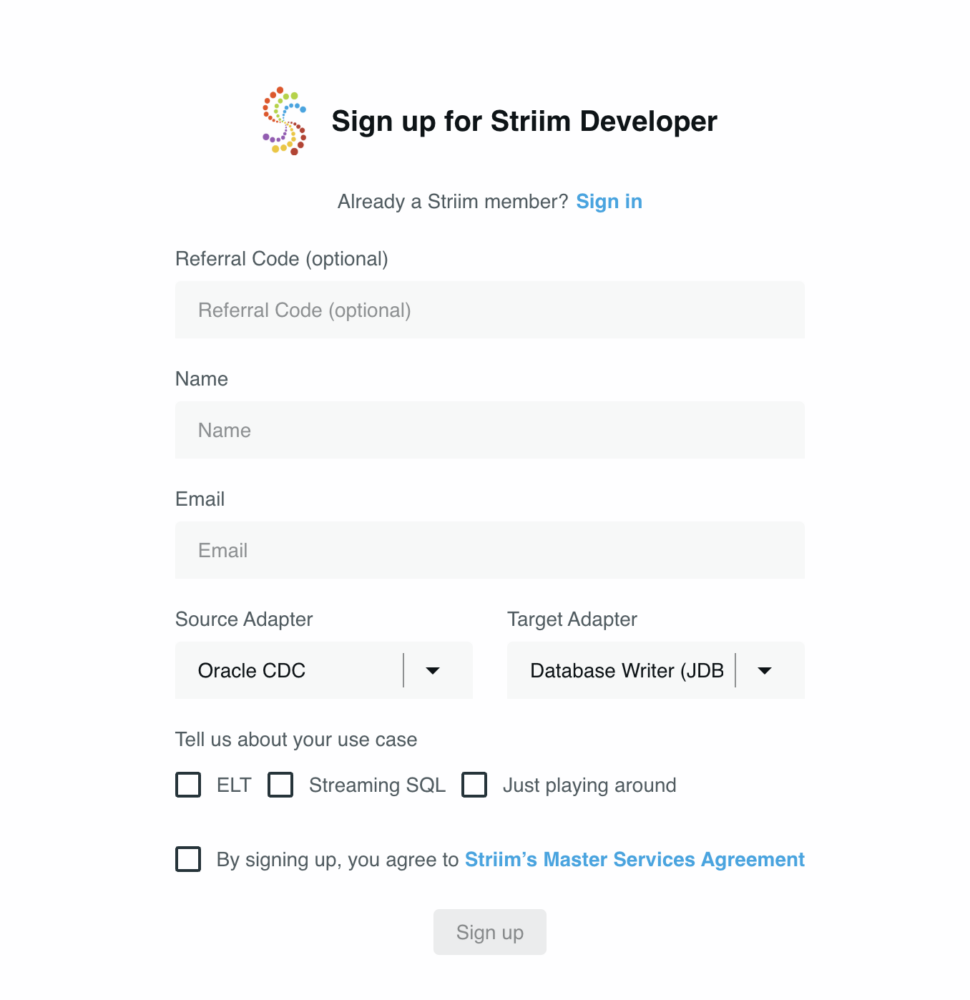
- Sign up for Striim developer edition for free at https://signup-developer.striim.com/.
- Select Oracle CDC as the source and Database Writer as the target in the sign-up form.
Prepare the table in Oracle
A simple table is created in the Oracle database and is used for the demo :
CREATE TABLE STORE_REVIEWS(
REVIEW_ID VARCHAR(1024),
STORE_ID VARCHAR(1024),
REVIEW_CONTENT varchar(1024))
Create the Striim application
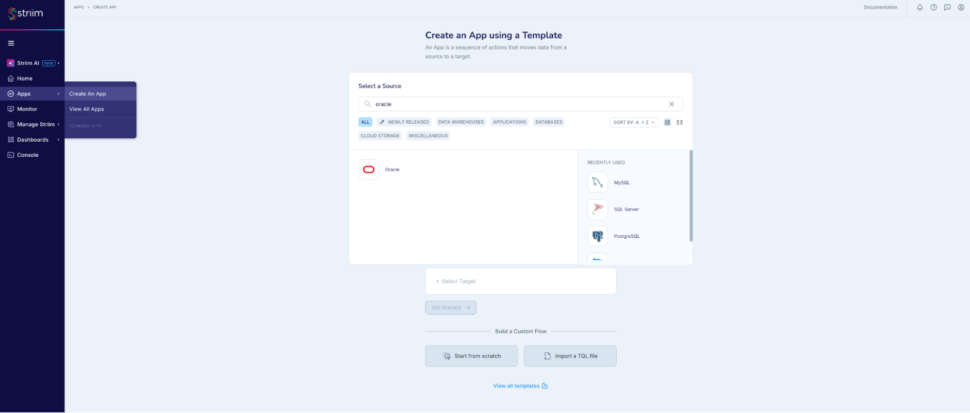
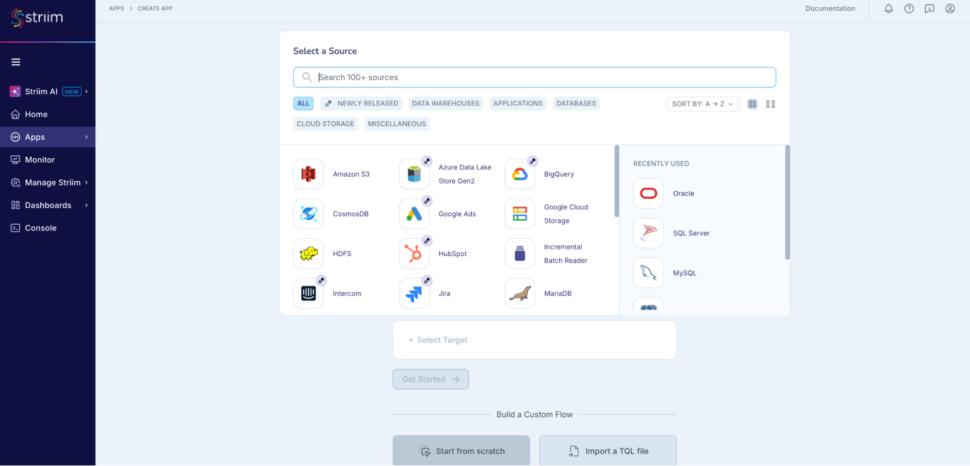
Step 1: Go to Apps -> Create An App -> Start from scratch -> name the app
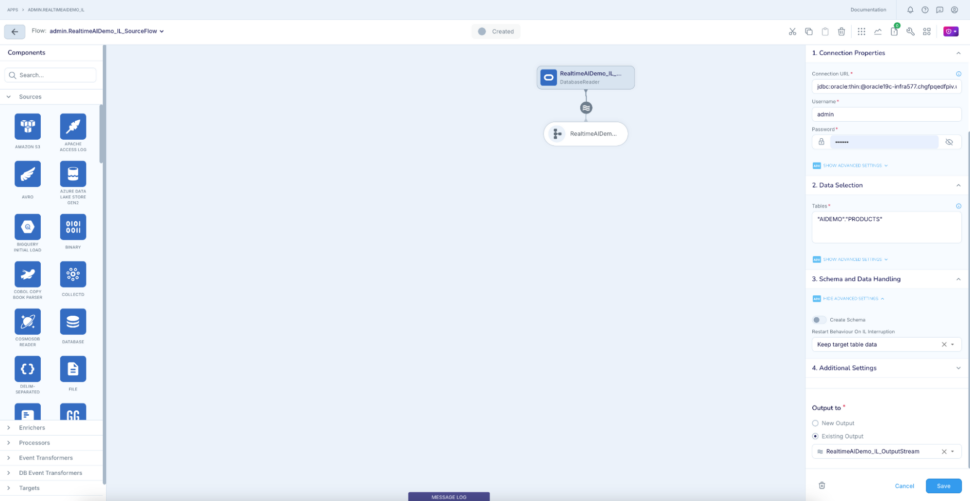
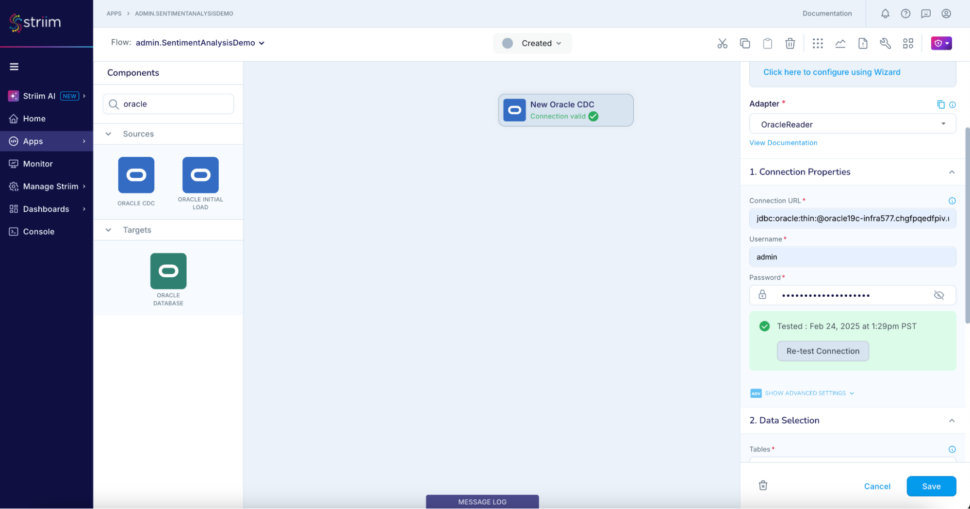
Step 2: Add an Oracle CDC reader to read the live reviews from the oracle database
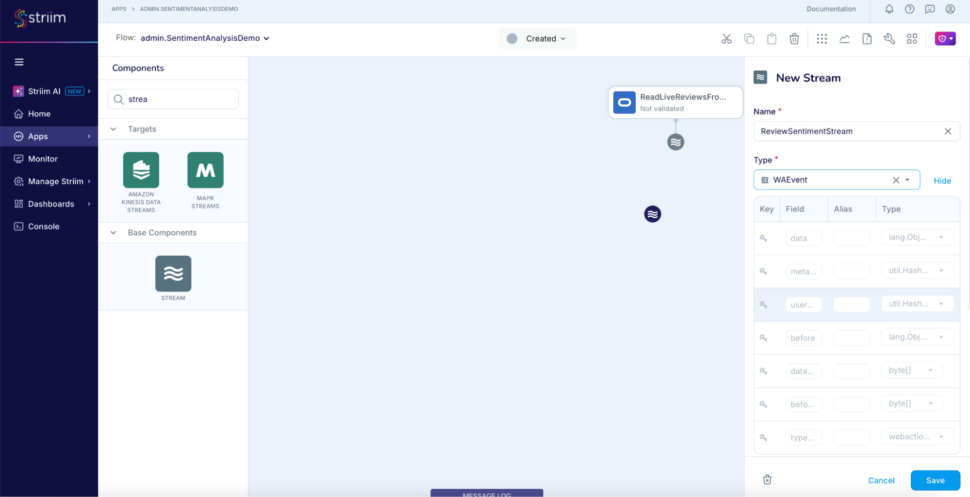
Step 3: Add another stream to use as output for the analyser AI agent
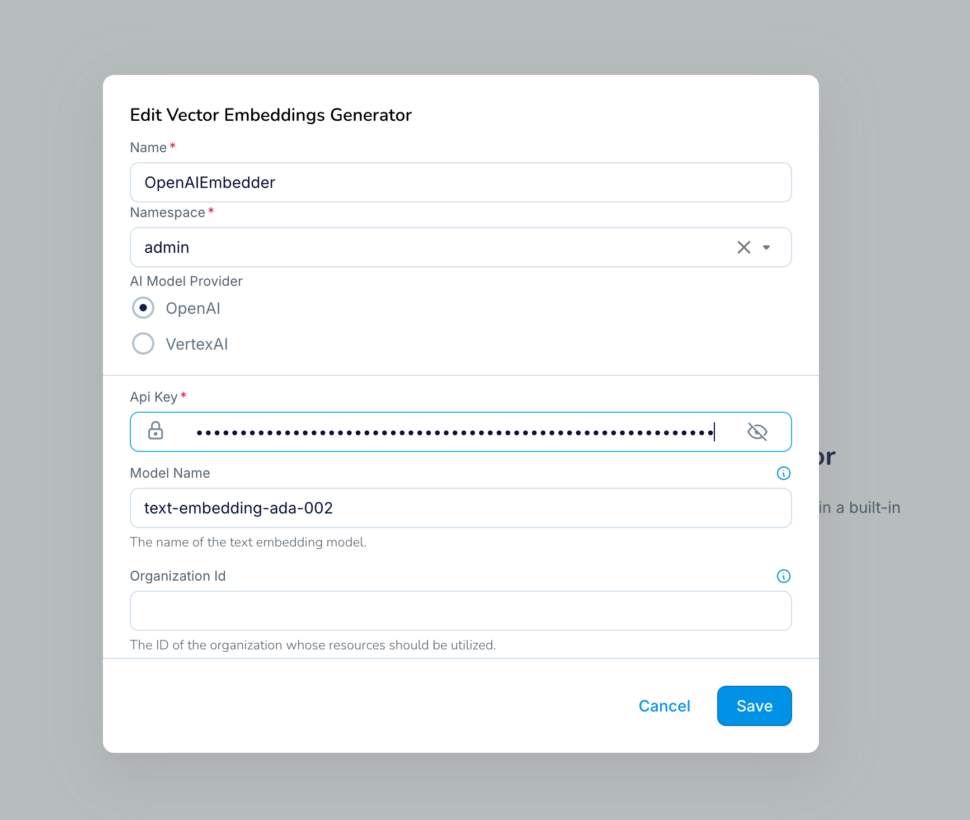
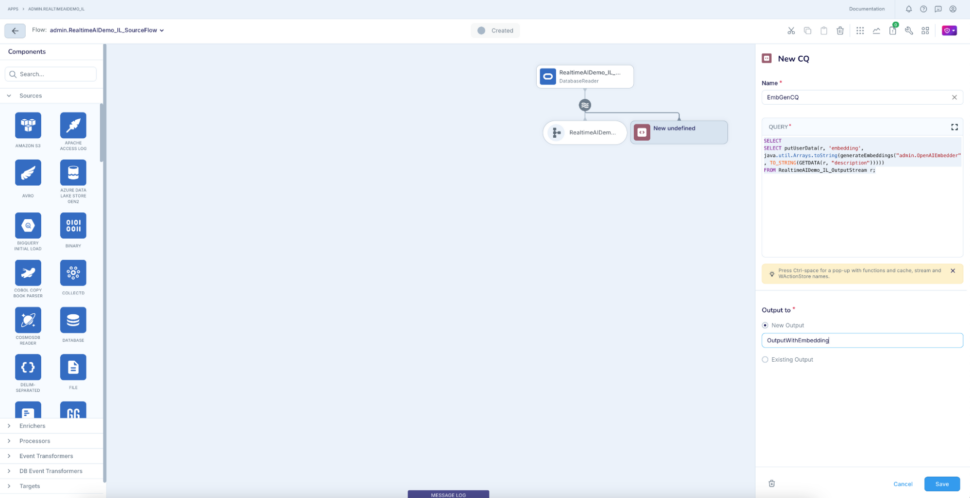
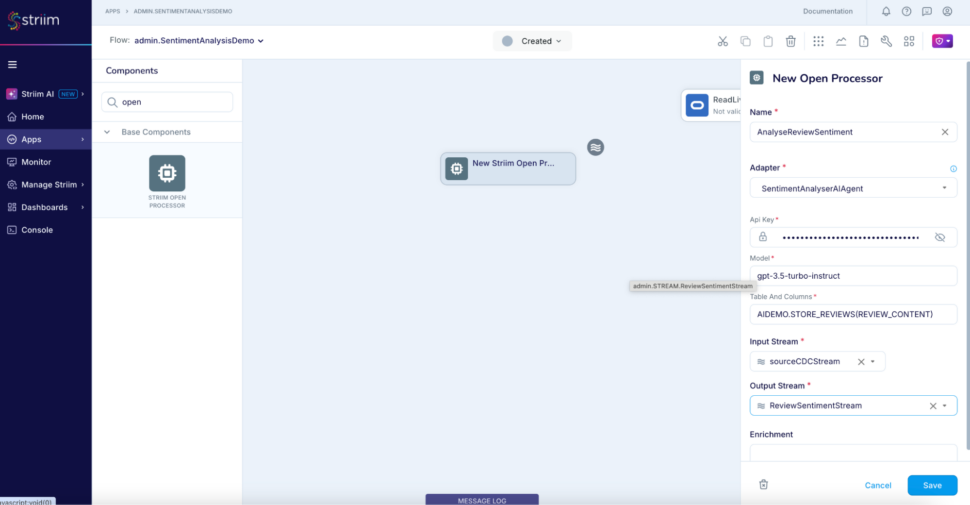
Step 4: Add an open processor using SentimentAnalyser AIAgent to analyse the sentiment of the value of column REVIEW_CONTENT
code here;
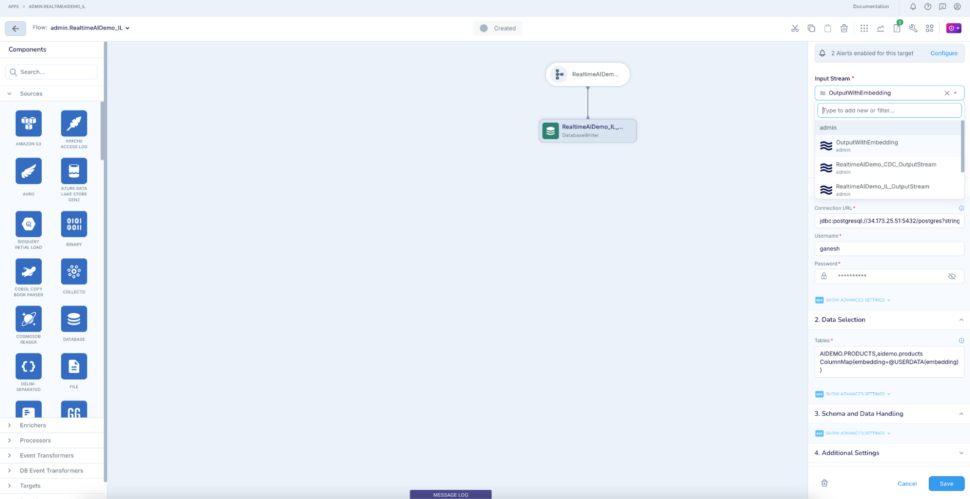
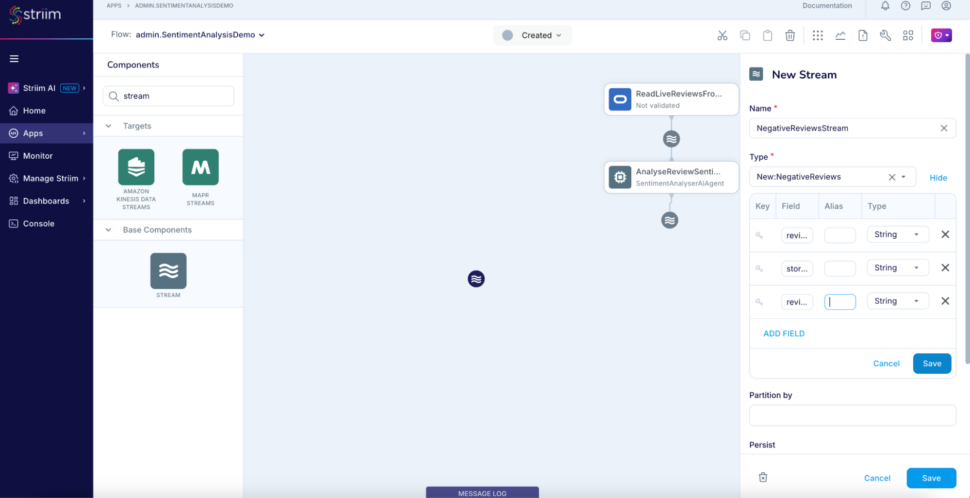
Step 5: Add another stream named NegativeReviewsStream to use a typed stream as output for the Continuous Query component which filters the negative reviews. Add a new type while defining the stream with three fields review_id. store_id, review_sentiment.
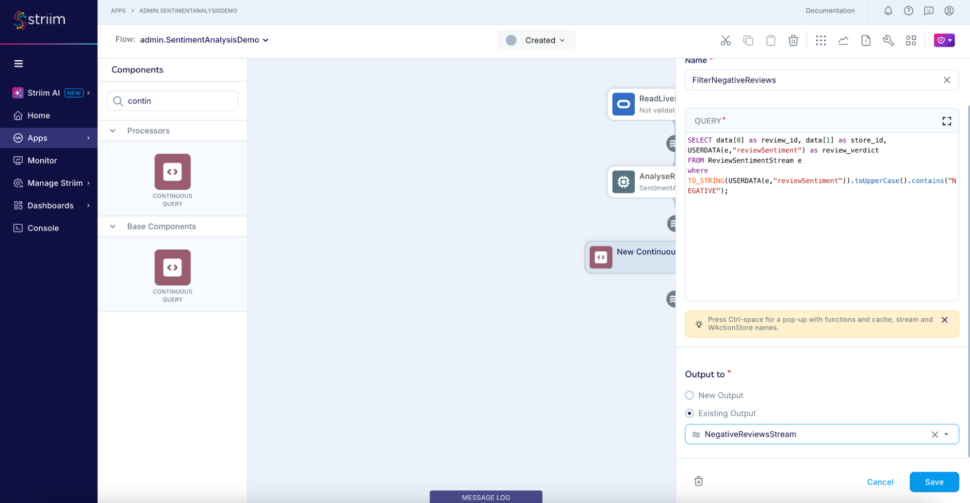
Step 6: Add a CQ that takes input from the ReviewSentimentStream, filters and outputs only the negative reviews to the stream we just created – NegativeReviewsStream.
SELECT data[0] as review_id, data[1] as store_id, USERDATA(e,"reviewSentiment") as review_verdict
FROM ReviewSentimentStream e
where TO_STRING(USERDATA(e,"reviewSentiment")).toUpperCase().contains("NEGATIVE")
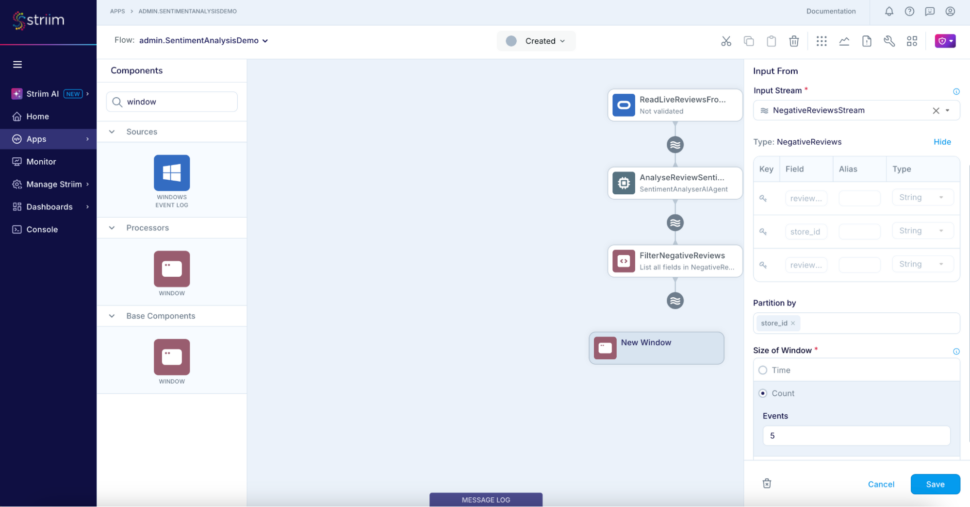
Step 7: Add a jumping window to partition the negative reviews based on the store_id which will be consumed downstream for generating the alert below.
Step 8: Add another stream NegativeReviewAlertStream of type AlertEvent to use for the alert subscription.
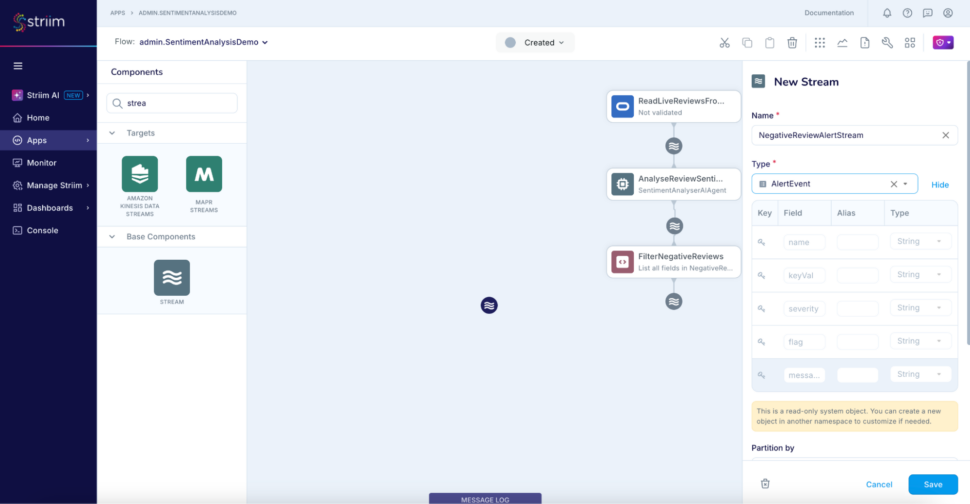
Step 9: Add the final CQ to construct the alerts whenever the window releases an event
SELECT 'Negative Review for storeID ' + store_id, store_id + '_' + DNOW(), 'warning', 'raise',
'Five negative Review received for store with ID : ' + store_id
FROM NegativeReviewsWindow
GROUP BY store_id
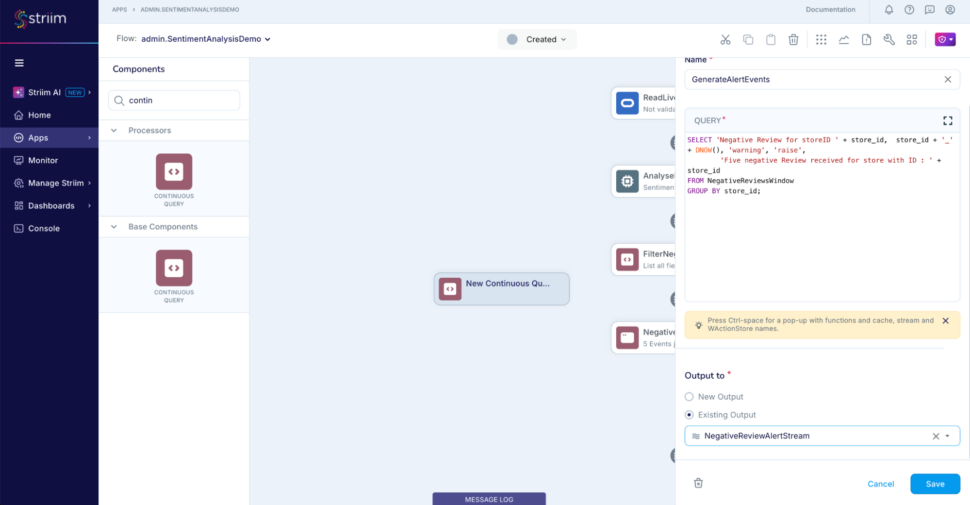
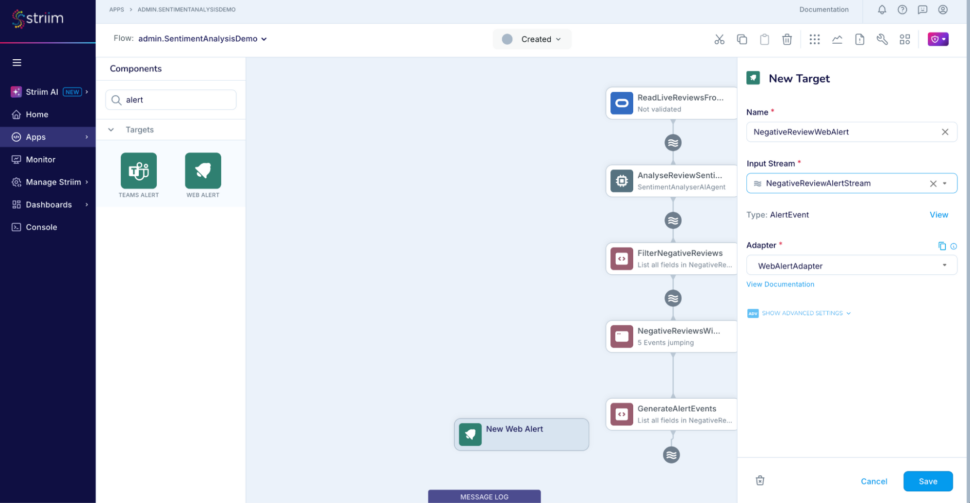
Step 10: Add a web alert subscription and use the stream NegativeReviewAlertStream as input
Finally the application should look like this :
(please note that you can alternatively import this TQL and modify the connection details and credentials as necessary as well : RealtimeSentimentAnalysisDemo.tql
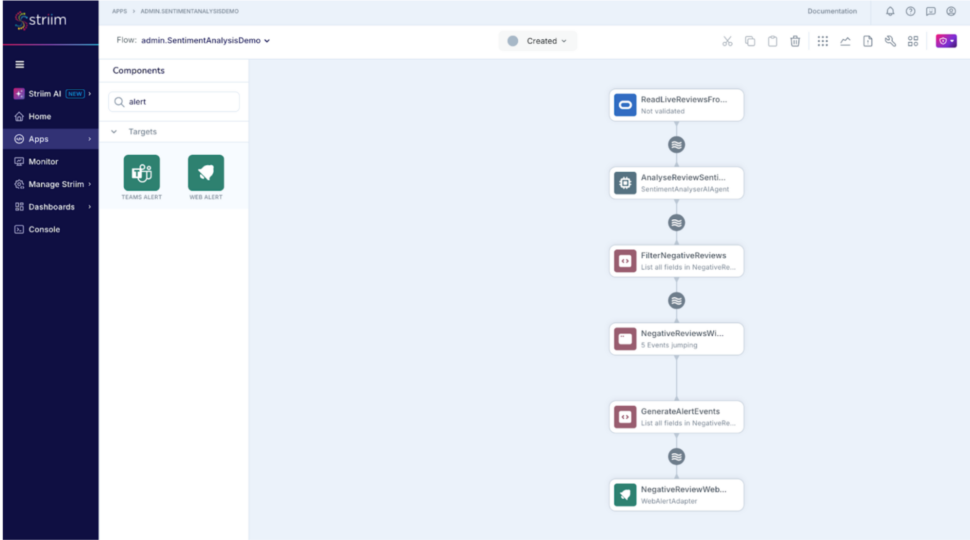
Run the Streaming application with AI Agent
Following DMLs are used for demonstration purposes :
-- A positive review for store 1
INSERT INTO STORE_REVIEWS values(1001,'0e26a9e92e4036bfaa68eb2040a8ec97','Great in-store customer service and helpful staff. Found exactly what I was looking for!');
-- A neutral review for store 1
INSERT INTO STORE_REVIEWS values(1002,'0e26a9e92e4036bfaa68eb2040a8ec97','The store was fine, but nothing stood out. Average shopping experience.');
-- A negative reviews for store 2
INSERT INTO STORE_REVIEWS values(1003, 'ed85bf829a36c67042503ffd9b6ab475', 'The store is understaffed. The products are not organised well.')
-- 5 negative reviews for store 1
INSERT INTO STORE_REVIEWS values(1004,'0e26a9e92e4036bfaa68eb2040a8ec97','The store was messy and disorganized. Hard to find what I needed.');
INSERT INTO STORE_REVIEWS values(1005,'0e26a9e92e4036bfaa68eb2040a8ec97','Terrible experience, long lines, and the staff was rude. Wont be coming back.');
INSERT INTO STORE_REVIEWS values(1006,'0e26a9e92e4036bfaa68eb2040a8ec97',' waited too long to check out, and the cashier was unhelpful.');
INSERT INTO STORE_REVIEWS values(1007,'0e26a9e92e4036bfaa68eb2040a8ec97','The store was out of stock for many items. Very frustrating.');
INSERT INTO STORE_REVIEWS values(1008,'0e26a9e92e4036bfaa68eb2040a8ec97','The return policy is terrible, and I had to wait forever to get help.');
A combination of 5 reviews are generated for one store in this example, this would mean that the AI agent would categorise these and the jumping window will release an event downstream for the store and the web alert adapter would publish a web alert.

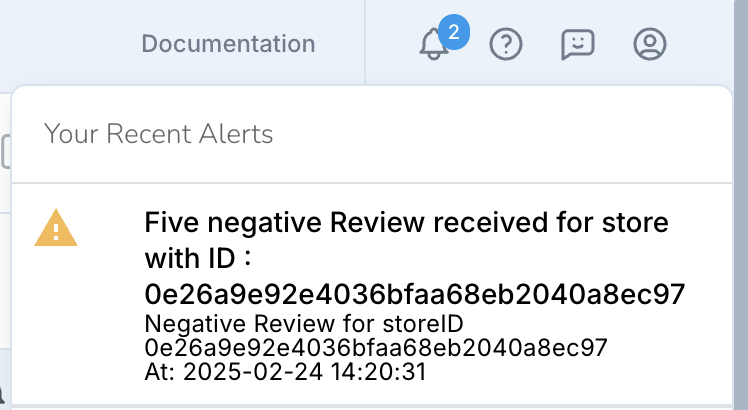
The can also be configured as a slack or a teams alert using Striim’s other alert subscription components. More here – https://www.striim.com/docs/platform/en/configuring-alerts.html
There we go! Data to decisions and AI in real-time.
SentimentAnalyser AI Agent Implementation
Please follow the instructions in Striim docs to build and load the open processor – https://www.striim.com/docs/platform/en/using-striim-open-processors.html
Download the java class SentimentAnalyserAIAgent from this location and the modified pom.xml file from this location.
Conclusion
Experience the power of real-time sentiment analysis with Striim. Get a demo or start your free trial today to see how you can convert real time data to decision coupled with AI techniques to deliver better, faster, and more responsive customer experiences.