According to Gartner, “SDI (stream data integration) implements a data pipeline to ingest, filter, transform, enrich and then store the data in a target database or file to be analyzed later.” 1 Further, “For SDI systems, the input event streams are a continuous, unbounded sequence of event records rather than a static snapshot of data at rest in a file or database. The streams are data ‘in motion.’” 1
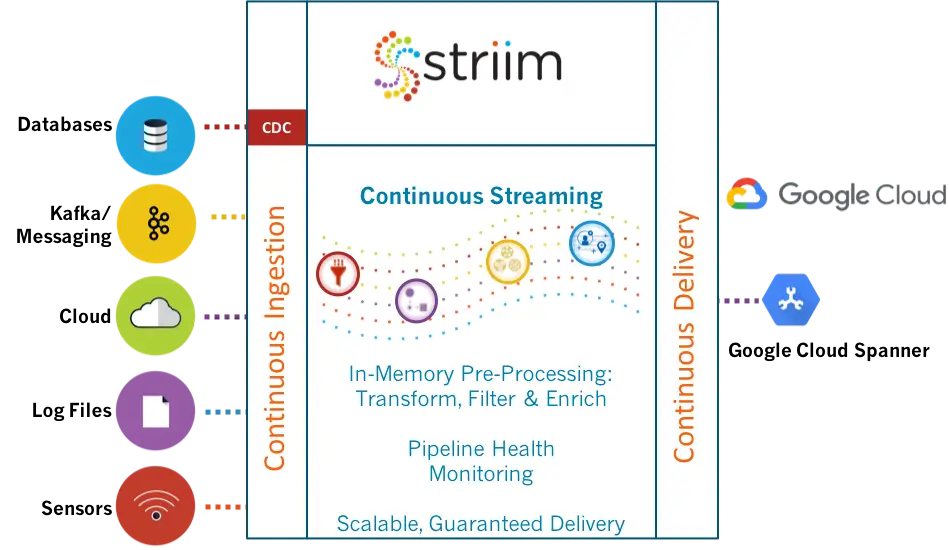
Stream data integration ingests event data from across the organization and makes it available in real time to support data-driven decisions to improve customer experience, minimize fraud, and optimize operations and resource utilization. As event streams make up a substantial portion of the data used by the real-time applications and analytics programs that drive business decisions, the value of stream data integration is immense.
According to Gartner, “in our annual survey for the data integration tools market, 47% of organizations reported that they need streaming data to build a digital business platform, yet only 12% of those organizations reported that they currently integrate streaming data for their data and analytics requirements.” 1
At Striim, it is our belief that stream data integration is essential for you to successfully leverage next-generation infrastructures such as Cloud, advanced analytics/ML, real-time applications, and IoT analytics that make it possible to harness the value of event streams in their decision making. Failure to move away from traditional data integration practices to those technologies that support stream data integration can result in valuable opportunities being missed. Batch processing technologies such as ETL simply cannot meet the high volume and low latency requirements of real-time data streams.
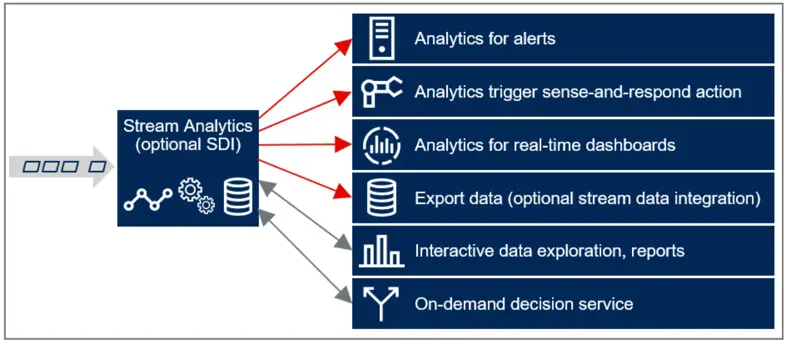
As stream data integration becomes a higher priority, you may wish to reconsider how your data management architecture can support your requirements. Research published by Gartner in March 2019 stated that, “By 2023, over 70% of organizations will use more than one data delivery style to support their data integration use cases, resulting in preference for tools than can support the combination of multiple data delivery styles (such as ETL and stream data integration).” 1
We designed the Striim platform specifically for stream data integration, to enable businesses to move to Cloud, easily build real-time applications that use real-time events, and get more operational value from their data. By providing up-to-date data in the format it is needed – on-prem or in the Cloud – Striim supports operational intelligence and other high-value operational workloads.
Striim captures real-time data from a wide variety of sources including databases (using low-impact change data capture), cloud applications, log files, IoT devices, and message queues. With the data is in motion, Striim applies filtering, transformations, aggregations, masking, and enrichment using static or streaming reference data. Users can perform SQL-based streaming analytics and visualize the data flow and the content of data in real time and receive verification of delivery.
The real-time data is then delivered in the required format to the targets including Cloud environments, Kafka and other messaging systems, Hadoop, relational and NoSQL databases, and flat files.
Cloud Adoption and Hybrid Cloud Architecture
As businesses adopt cloud services to modernize their IT environments and transform their business operations, continuous data flow between on-premises systems and cloud solutions becomes imperative. Without having up-to-date data in their cloud solutions, businesses cannot offload high-value, operational workloads, and consequently, restrict the scope of their business transformation. Striim enables streaming data pipelines to major cloud platforms to help seamlessly extend enterprise data centers to the cloud.
The solution also offers cloud-to-cloud integration as more and more businesses adopt multiple cloud vendors for different services. Also, as the initial and crucial step into the cloud journey, the same stream data integration technology enables data migration to cloud without interrupting business systems,. It minimizes risks by allowing thorough testing of the new system without time limitations.
Data Integration for Real-Time Applications
Striim enables users to develop stream data integration pipelines that support their real-time applications quickly and easily with a wizard-based UI and SQL-based language. Should it be required, and before the data is even delivered to the target, Striim can provide a visualization of the data and perform analytics on the data while it is in motion using SQL-based streaming analytics.
Real-Time Integration and Pre-Processing for Advanced Analytics and Machine Learning
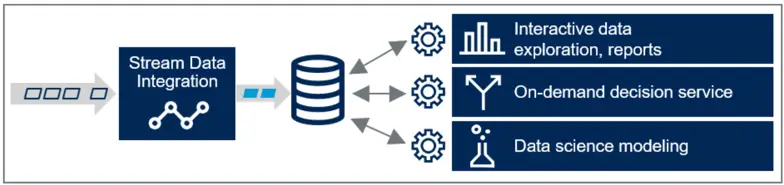
Stream data integration from Striim enables users to leverage real-time data from a wide range of sources for operational intelligence solutions. Because the data is pre-processed in-flight to a consumable format, it speeds downstream applications and accelerates insight into operations. Stream data integration enables smart data architecture where only the necessary data is stored in the form that serves the end users.
Striim supports machine learning solutions by pre-processing and extracting suitable features before continuously delivering training files to your analytics environment. After you create ML models, you can bring them to Striim using the open processor component. By applying your ML logic to streaming events, you can gain real-time insights that guide daily operational decision making and truly transform your business. Striim can also monitor model fitness and trigger retraining of models for full automation.
To learn more about our stream data integration capabilities, please visit our Real-time Data Integration solution page, schedule a demo with a Striim expert, or download the Striim platform to get started.
1 Gartner: Adopt Stream Data Integration to Meet Your Real-Time Data Integration and Analytics Requirements, 15 March 2019, Ehtisham Zaidi, W. Roy Schulte, Eric Thoo