In this video, learn why enterprises must stream data into Snowflake to take full advantage of this data warehouse built for the cloud.
To learn more about Striim for Snowflake Data Warehouse, visit our Snowflake solution page.
Video Transcription:
You chose Snowflake to provide rapid insights into your data on a massive scale, on AWS or Azure. However, most of your source data resides elsewhere – in a wide variety of on-premise or cloud sources. How do you continually move data to Snowflake in real-time, processing it along the way, so that your fast analytics and insights are reporting on timely data?
Snowflake was built for the cloud, and built for speed. By separating compute from storage you can easily scale up and down as needed. This gives you instant elasticity supporting any amount of data, and high speed queries for any number of users, coupled with the peace of mind provided by secure data sharing. The per-second pricing and support for multiple clouds allows you to choose your infrastructure and only pay when you are using the data warehouse.
However, residing in cloud means you have to determine how to most effectively move data to Snowflake. This could be migrating an existing Teradata or Exadata Data Warehouse, or continually populating Snowflake with newly generated on-premises data from operational databases, logs, or device information. In order for the warehouse to provide up-to-date information, there should be as little latency as possible between the original data creation and its delivery to Snowflake.
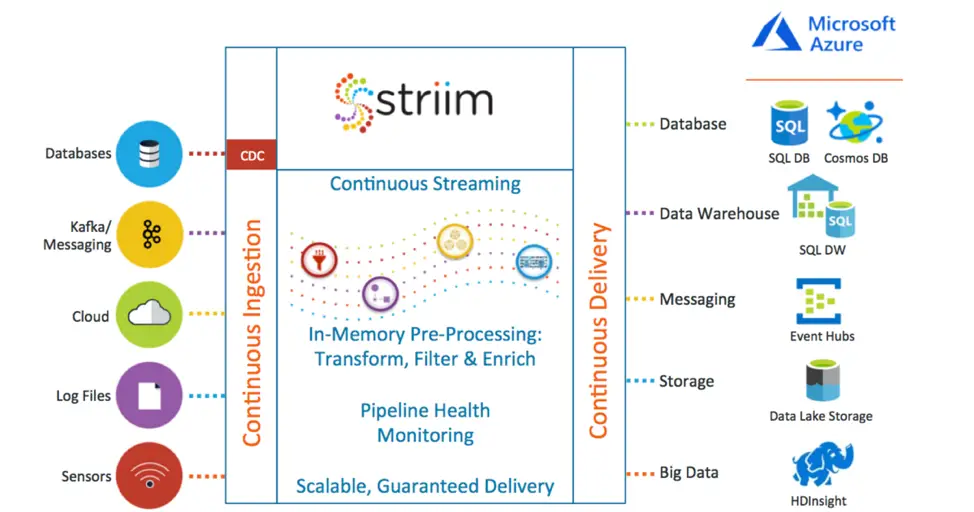
The Striim platform can help with all these requirements and more. Our database adapters support change data capture, or CDC, from enterprise or cloud databases. CDC directly intercepts database activity and collects all the inserts, updates, and deletes as they happen, ready to stream into Snowflake. Adapters for machine logs and other files read at the end of multiple files in parallel to stream out data as it is written, removing the inherent latency of batch. While data from devices and messaging systems can be collected easily, independent of their format, through a variety of high-speed adapters and parsers.
After being collected continuously, the streaming data can be delivered directly into Snowflake with very low latency, or pushed through a data pipeline where it can be pre-processed through filtering, transformation, enrichment, and correlation using SQL-based queries, before delivery into Snowflake. This enables such things as data denormalization, change detection, de-duplication, and quality checking before the data is ever stored.
In addition to this, because Striim is an enterprise-grade platform, it can scale with Snowflake and reliably guarantee delivery of source data while also providing built-in dashboards and verification of data pipelines for operational monitoring purposes.
The Striim wizard-based UI enables users to rapidly create a new data flow to move data to Snowflake. In this example, real-time change data from Oracle is being continually delivered to Snowflake. The wizard walks you through all the configuration steps, checking that everything is set up properly, and results in a data flow application. This data flow can be enhanced to filter, transform and enrich the data through SQL-based queries. In the video, we add a name and email address from a cache, based on an ID present in the original data.
When the application is started, data flows in real-time from Oracle to Snowflake. Making changes in Oracle results in the transformed data being written continually to Snowflake, visible through the Snowflake UI.
Striim and Snowflake can change the way you do analytics, with Snowflake providing rapid insight to the real-time data provided by Striim. The data warehouse that is built for the cloud needs data delivered to the cloud, and Striim can continuously move data to Snowflake to support your business operations and decision-making.
To learn more about how Striim makes it easy to continuously move data to Snowflake, visit our Striim for Snowflake product page, schedule a demo with a Striim technologist, or download the platform and try it for yourself.