

Confluent has established itself as a prominent name in the world of real-time data. Built by the original creators of Apache Kafka, Confluent provides a data streaming platform designed to help businesses harness the continuous flow of information from their applications, websites, and systems.
The primary appeal of Confluent lies in its promise to tame the complexity of Apache Kafka. Raw Kafka is a powerful, open-source technology, but it demands deep technical expertise to deploy effectively.
While Confluent provides a path to adopting data streaming, it is not a one-size-fits-all solution. Many organizations find that the operational overhead, opaque pricing models, and a fragmented ecosystem of necessary add-ons create significant challenges down the line. As the need for real-time data becomes more critical, businesses are increasingly looking for more user-friendly and cost-effective alternatives for their enterprise.
Where Confluent Falls Short as a Data Streaming Solution
Despite its market position, Confluent’s platform presents several challenges that can hinder an organization’s ability to implement a truly seamless and cost-effective data streaming strategy. These shortcomings often lead businesses to seek out more integrated and transparent alternatives.
- Requires deep Kafka expertise and complex setup: Operating and scaling Confluent, particularly in on-premise or non-cloud-native environments, demands significant technical know-how of Kafka’s intricate architecture.
- Lacks native CDC and advanced transformation capabilities: Users must integrate separate tools like Debezium for Change Data Capture (CDC) and Apache Flink for complex transformations, which increases latency, cost, and operational overhead.
- Opaque, usage-based pricing can drive up costs: The resource-based pricing model often leads to unexpectedly high costs, especially for high-throughput workloads or use cases requiring long-term data retention.
- Limited out-of-the-box observability: Confluent’s built-in monitoring features are minimal. Achieving real-time, end-to-end visibility across data pipelines requires custom development or dedicated, third-party observability tools.
- Connector access may be restricted or costly: Many essential connectors for popular enterprise systems are gated behind premium tiers, making full integration more difficult and expensive to achieve.
Alternative Solutions to Confluent for Data Streaming

Striim
Striim is a unified, real-time data integration and streaming platform that offers an all-in-one alternative to the fragmented Confluent ecosystem. Recognized on platforms like Gartner Peer Insights, businesses choose Striim to simplify the creation of smart data pipelines. It enables them to stream, process, and deliver data from enterprise databases, cloud applications, and log files to virtually any target in real time. This allows for rapid development of real-time analytics, AI and ML applications, and cloud integration initiatives without the steep learning curve of raw Kafka.
Striim’s Pros and Cons
Pros:
- All-in-One Platform: Combines data integration, streaming, and processing in a single solution.
- Native, Low-Impact CDC: Built-in Change Data Capture from enterprise databases without requiring third-party tools.
- Powerful In-Flight Processing: Enables complex transformations and enrichments on data in motion—before it lands in its destination.
- Performance and Scale: Engineered for high-throughput, low-latency workloads.
- Broad Connectivity: Offers hundreds of pre-built connectors for a wide range of data sources and targets.
- Enterprise-Ready: Includes built-in high availability, security, and governance features.
- Hybrid/Multi-Cloud Native: Deploys consistently across on-premises, cloud, and edge environments.
Cons:
- Advanced Feature Learning Curve: While the platform is overwhelmingly user-friendly, mastering its most advanced transformation and deployment capabilities requires some learning. To help, Striim offers an expansive academy where users can get to grips with the platform and its core capabilities, with videos, quizzes, and interactive learning modules.
- Not a pure message broker: While Striims powers real-time streaming to and from Kafka, its primary focus is on end-to-end integration and processing data, not just queuing like raw Kafka.
Top Features of Striim
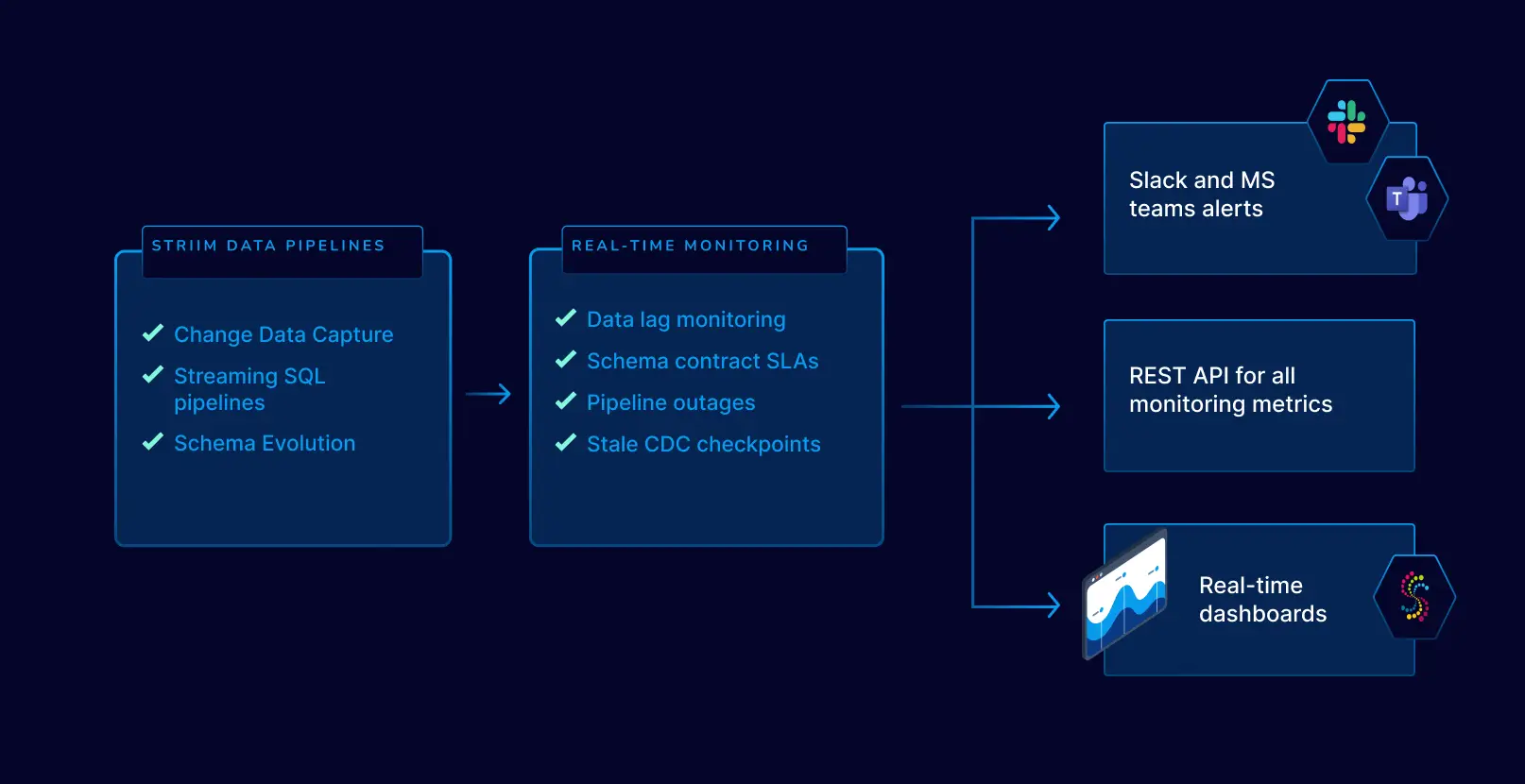
- Built-in Change Data Capture (CDC): Enables real-time data replication from enterprise databases without third-party tools—unlike Confluent’s reliance on Debezium.
- Prebuilt connectors for enterprise and cloud systems: Simplifies integration with databases, warehouses, cloud storage, and messaging platforms—reducing setup time and complexity.
- Hybrid and multi-cloud support: Deploys easily across on-prem, cloud, or edge environments, making it ideal for organizations with complex infrastructure.
- Intuitive UI and visual pipeline designer: Lowers the barrier to entry for data teams by eliminating the need to manage Kafka internals directly.
- Sub-second latency with built-in monitoring: Ensures fast, reliable data delivery with end-to-end visibility—no need to stitch together external monitoring tools.
Striim: A Unified Platform for Real-Time Data Integration
- Confluent relies on third-party tools like Debezium for CDC, adding setup time and operational overhead. Striim includes native CDC connectors as part of an all-in-one platform, making it faster and easier to stream data from enterprise databases.
- Kafka-based pipelines often require custom code or external systems for transformation and filtering. Striim handles in-flight transformations natively, enabling real-time processing without added complexity.
- Achieving reliable, lossless delivery in Confluent often demands deep tuning and custom monitoring. Striim offers built-in delivery guarantees, observability, and alerting, giving teams end-to-end visibility and control from a single interface.
How Striim Simplifies Deployment Across Multi-Cloud Environments
- Deploying and managing Confluent outside of Confluent Cloud can be resource-intensive and complex. Striim is designed for multi-cloud environments, offering a consistent, low-overhead experience everywhere.
- Confluent often demands deep Kafka expertise to manage topics, brokers, and schema registries. Striim offers a visual UI, integrated monitoring, and fewer moving parts, so data teams can move faster without needing deep knowledge of Kafka.
- Many key Confluent connectors are gated behind premium tiers or require manual setup. Striim includes a wide range of prebuilt, production-ready connectors, accelerating integration with critical systems.

Apache Kafka
Apache Kafka is the open-source distributed event streaming platform that Confluent is built upon. It is a mature, highly scalable, and durable publish-subscribe messaging system. Businesses choose raw Apache Kafka when they have deep engineering expertise and require maximum control over their infrastructure. You can find community and professional reviews on sites like G2.
Pros and Cons
- Pros: Highly scalable and fault-tolerant, massive open-source community, unparalleled performance for high-throughput scenarios, and complete vendor neutrality.
- Cons: Extremely complex to set up, manage, and scale without a dedicated team; lacks built-in tools for management, monitoring, and security; requires integrating other systems for schema management and connectors.
Top Features
- High-throughput, low-latency message delivery.
- Durable and replicated storage of event streams.
- A rich ecosystem of client libraries for various programming languages.
- Scalable, distributed architecture that can handle trillions of events per day.
- The Kafka Connect framework for building and running reusable connectors.

Redpanda
Redpanda is a modern streaming data platform that is API-compatible with Kafka. It positions itself as a simpler, more performant, and more cost-effective alternative by being written in C++ and engineered to be self-sufficient without requiring Zookeeper. Small and medium-sized businesses opt for Redpanda to get Kafka-like capabilities with lower operational overhead, reduced latency, and a smaller resource footprint. This makes it suitable for both performance-critical applications and resource-constrained environments. See user reviews on TrustRadius.
Pros and Cons
- Pros: Kafka API compatibility, no Zookeeper dependency simplifies architecture, lower tail latencies, and improved resource efficiency.
- Cons: Redpanda’s ecosystem is young compared to Kafka, some advanced Kafka features may not be fully mature, and being a commercial open-source product, some features are enterprise-only.
Top Features
- A single-binary deployment model for simplicity.
- Built-in schema registry and HTTP proxy.
- Data-oriented architecture optimized for modern hardware (NVMe, multi-core CPUs).
- Tiered storage for cost-effective, long-term data retention.
- High performance with a thread-per-core model.

Amazon MSK (Managed Streaming for Apache Kafka)
Amazon MSK is a fully managed AWS service that makes it easy to build and run applications that use Apache Kafka to process streaming data. It manages the provisioning, configuration, and maintenance of Kafka clusters, including handling tasks like patching and failure recovery. Businesses choose MSK to offload the operational burden of managing Kafka to AWS, allowing them to focus on application development while leveraging deep integration with other AWS services.
Pros and Cons
- Pros: Fully managed by AWS, simplified cluster provisioning and scaling, seamless integration with the AWS ecosystem (S3, Lambda, Kinesis), and enterprise-grade security features.
- Cons: Can lead to cloud vendor lock-in with AWS, pricing can be complex to predict and potentially high, and offers less control over the underlying Kafka configuration compared to a self-managed setup.
Top Features
- Automated provisioning and management of Apache Kafka clusters.
- Multi-AZ replication for high availability.
- Integration with AWS Identity and Access Management (IAM) for security.
- Built-in monitoring via Amazon CloudWatch.
- Serverless tier (MSK Serverless) that automatically provisions and scales resources.

Google Cloud Pub/Sub
Google Cloud Pub/Sub is a serverless, global messaging service. It allows for simple and reliable communication between independent applications. Pub/Sub is known for asynchronous workflows and event-driven architectures within the Google Cloud ecosystem. It excels at decoupling services and ingesting event data at scale.
Pros and Cons
- Pros: Fully serverless architecture, scales automatically, provides global message delivery, and integrates deeply with Google Cloud services.
- Cons: It is not Kafka-compatible, which can be a hurdle for teams with existing Kafka tools. It also locks into Google Cloud’s ecosystem.
Top Features
- Push and pull message delivery.
- At-least-once delivery guarantee.
- Filtering messages based on attributes.
- Global availability with low latency.
- Integration with IAM and other Google Cloud security services.

Azure Event Hubs
Azure Event Hubs is a big data streaming platform and event ingestion service. Managed by Microsoft Azure, it can stream millions of events per second. Companies invested in the Azure ecosystem leverage Event Hubs to build real-time analytics pipelines, especially for application telemetry and device data from IoT.
Pros and Cons
- Pros: Massively scalable, integrates with the Azure stack, and offers a Kafka-compatible API endpoint.
- Cons: Primarily designed for ingestion; complex processing often requires other Azure services. It also results in Azure vendor lock-in.
Top Features
- A premium tier offering a Kafka-compatible endpoint.
- Dynamic scaling with Auto-inflate.
- Capture events directly to Azure Blob Storage or Data Lake Storage.
- Geo-disaster recovery.
- Secure access through Azure Active Directory and Managed Service Identity.
Other Popular Confluent Alternatives

Aiven
Aiven provides managed services for popular open-source data technologies, including a robust Apache Kafka offering. Businesses use Aiven to deploy production-grade fully-managed Kafka clusters on their preferred cloud provider (AWS, GCP, Azure) without handling the operational overhead. It’s ideal for teams who want a reliable, hosted Kafka solution with strong support.
Pros and Cons
- Pros: Multi-cloud portability, fully managed service, and bundles other tools like PostgreSQL and OpenSearch.
- Cons: Can be more costly than self-management and offers less granular control over Kafka configurations.

Tibco Messaging
TIBCO Messaging offers a suite of high-performance messaging products for enterprise-level data distribution. It’s chosen by large organizations, often with existing TIBCO investments, for its mission-critical reliability and performance in complex systems. It is not a pure Kafka solution but can integrate with it.
Pros and Cons
- Pros: Enterprise-grade security and reliability, part of a broad integration ecosystem, and includes strong commercial support.
- Cons: Complex, can be expensive, and represents a more traditional approach to messaging compared to cloud-native platforms.

Strimzi
Strimzi is an open-source project that simplifies running Apache Kafka on Kubernetes. It uses Kubernetes Operators to automate the deployment, management, and configuration of a Kafka cluster. Strimzi is for organizations committed to a cloud-native, Kubernetes-first strategy that want to manage Kafka declaratively.
Pros and Cons
- Pros: Kubernetes-native automation, strong community support, and simplifies Kafka operations on K8s.
- Cons: Requires significant Kubernetes expertise and is a self-managed solution, meaning you are responsible for the underlying infrastructure.
Choosing the Right Streaming Platform
The data streaming landscape is diverse with a host of powerful alternatives to Confluent. The right choice will depend on your organization’s goals, existing infrastructure, and technical expertise. Cloud-native platforms like Pub/Sub and Event Hubs offer simplicity at the cost of vendor lock-in. While managed Kafka providers like Aiven and Amazon MSK reduce operational burden, but can limit control. Modern challengers like Redpanda and WarpStream promise a more efficient Kafka experience.
For organizations seeking to move beyond simply managing a message broker, a unified platform is often the most direct path to value. Instead of stitching together separate tools for ingestion, transformation, and monitoring, an all-in-one solution like Striim accelerates the delivery of real-time, actionable insights, so you can act on your data the instant it’s born.
Ready to see how a unified approach can simplify your data architecture? Book a personalized demo of Striim today.







 By utilizing Striim, Inspyrus ingested real-time data from an OLTP database, loaded it into Snowflake, and transformed it there. It then used an intelligence tool to visualize this data and create rich reports for users. As a result, Inspyrus users are able to view reports in real time and utilize insights immediately to fuel better decisions.
By utilizing Striim, Inspyrus ingested real-time data from an OLTP database, loaded it into Snowflake, and transformed it there. It then used an intelligence tool to visualize this data and create rich reports for users. As a result, Inspyrus users are able to view reports in real time and utilize insights immediately to fuel better decisions. 























 With its real-time streaming capabilities, cloud integration options, pricing plans that fit various budgets, intuitive UI with drag-and drop functionality and pre-built components – as well as its free version – Striim makes building a Kappa architecture simple and affordable. This makes it the ideal tool for businesses looking to reduce their data integration costs while taking advantage of cutting edge technologies.
With its real-time streaming capabilities, cloud integration options, pricing plans that fit various budgets, intuitive UI with drag-and drop functionality and pre-built components – as well as its free version – Striim makes building a Kappa architecture simple and affordable. This makes it the ideal tool for businesses looking to reduce their data integration costs while taking advantage of cutting edge technologies.
