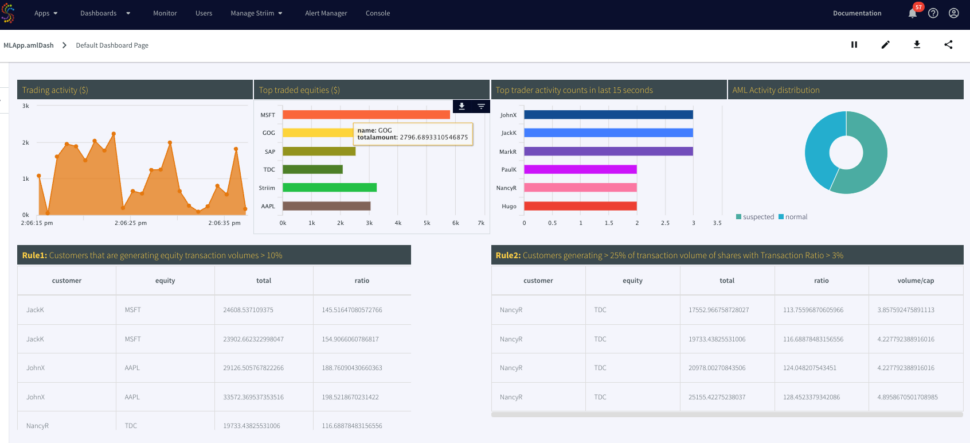
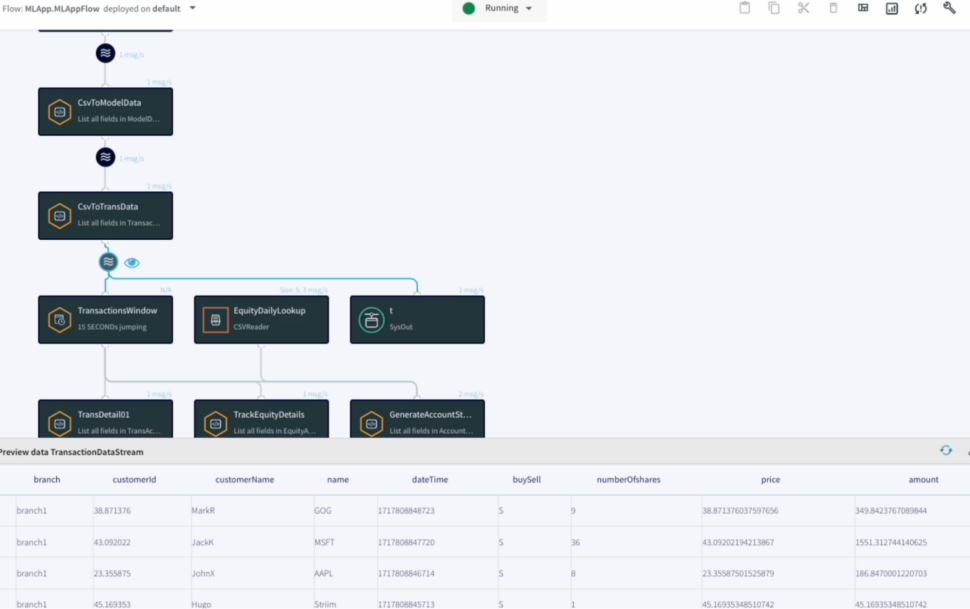
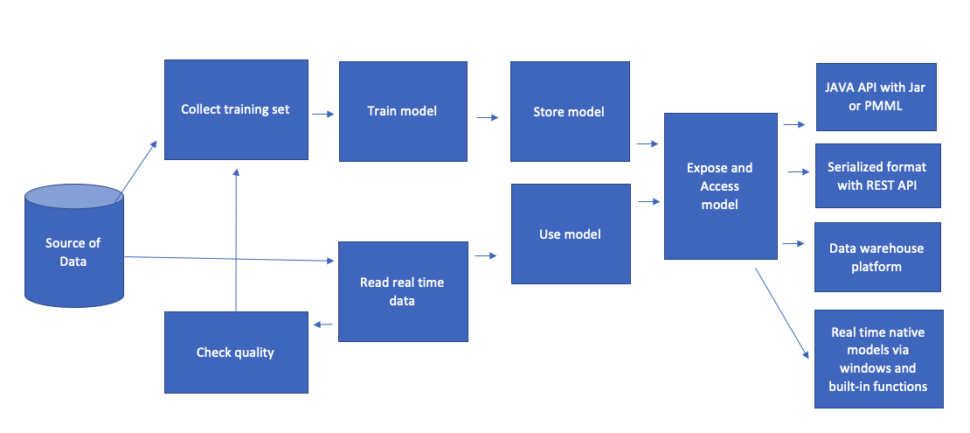
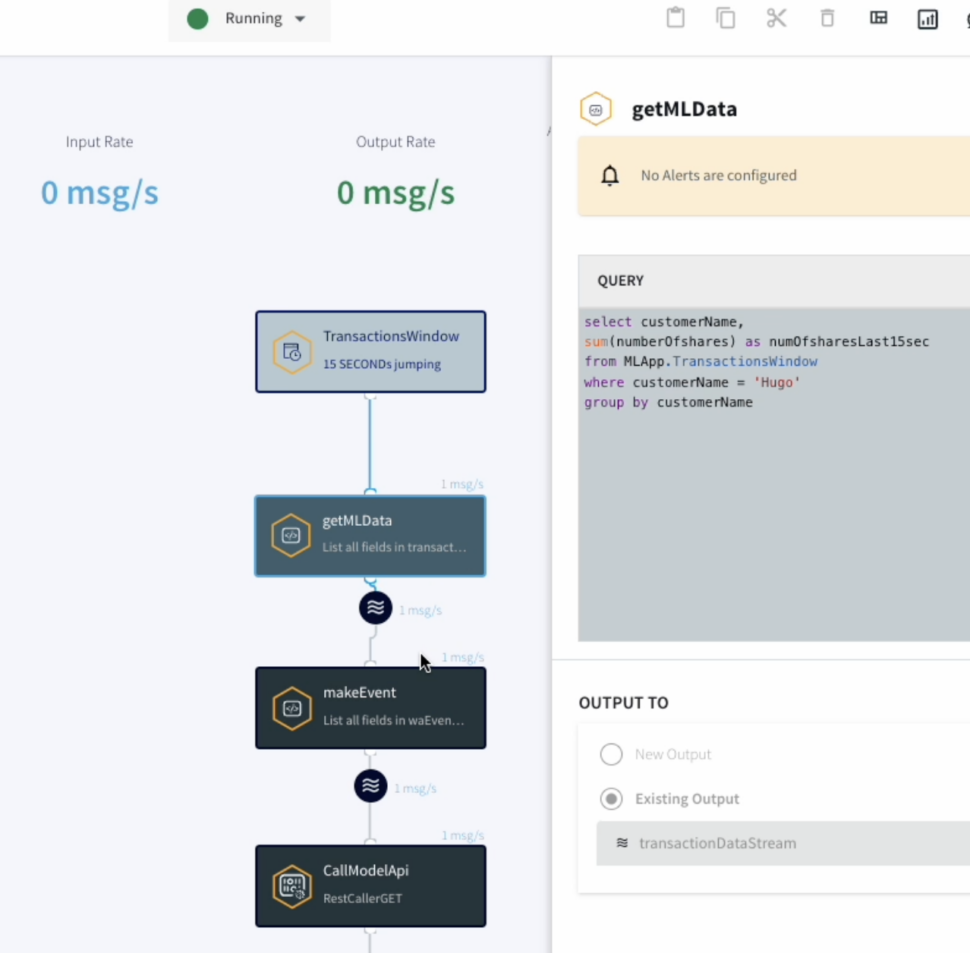
Is your business running in “real-time”? Many think they do, but if you look under the hood, you might find that your “live” data is already a few minutes or even hours old.
In fact, many teams are still wrestling with batch processes or have plastered a “speed layer” onto an old system. You’re likely collecting massive amounts of data from logs, sensors, and customer interactions, but unless you’re delivering data in real time, you can’t act on it fast enough to make a difference.
Streaming analytics brings data into the “now.” It’s a fundamental shift that helps you move from just reporting on what happened yesterday to responding to what’s happening in the moment. In a world driven by intelligent systems and real-time customer expectations, “good enough” real-time just doesn’t cut it anymore. Done right, streaming analytics becomes a strategic enabler that can give your organization a competitive advantage.
This guide breaks down what streaming analytics is, why it matters, and how it impacts your business. We’ll cover the common challenges, the key features to look for in a platform, and how solutions like Striim make it all possible.
Streaming Analytics vs. Data Analytics
Streaming analytics and data analytics are both powerful tools for extracting insights from data, but they differ in how they process and analyze information.
Streaming analytics refers to the real-time processing and analysis of data as it is generated. It focuses on analyzing continuous streams of data from sources like IoT devices, social media feeds, sensors, or transaction logs. The goal is to derive actionable insights or trigger immediate actions while the data is still in motion. Use streaming analytics when you need to act on data immediately, such as for fraud detection, monitoring IoT devices, or providing real-time recommendations.
Data analytics is the broader field of analyzing data to uncover patterns, trends, and insights. It typically involves working with static or historical datasets that are stored in databases or data warehouses. The analysis can be descriptive, diagnostic, predictive, or prescriptive, depending on the goal. Use data analytics when you need to analyze trends, make strategic decisions, or work with large historical datasets.
What Is Streaming Analytics?
Streaming analytics is the process of continuously capturing, processing, and analyzing data while it’s still moving. There’s no waiting for it to be stored in a database or for a batch job to run. It’s built for situations where every second counts and latency directly impacts your bottom line.
This stands apart from traditional BI dashboards that show snapshots of data, or event streaming platforms that just move data from point A to point B without transforming or analyzing it. Streaming analytics works with data from IoT sensors, application logs, financial transactions, and website activity. It can even handle unstructured data like chat logs, giving you a complete view of your business.
Streaming Analytics vs. Event Streaming
Event streaming focuses on the continuous movement of data from one system to another, acting as a pipeline to transport raw events without analyzing them. In contrast, streaming analytics goes a step further by also processing, analyzing, and deriving actionable insights from the data in real time, enabling immediate decision-making and responses.
Harness IoT and Data Analytics for Strategic Business Growth
How can IoT and data analytics help drive innovation? Explore real-world use cases like:
• Predictive maintenance, real-time monitoring, and efficient supply chain management in manufacturing
• Smart city initiatives that optimize resource management, track employee productivity, and enhance public safety
• Remote patient monitoring, predictive diagnostics, and personalized treatment plan
Investigate more possibilities for strategic business growth in this article.
Why Streaming Analytics Matters Today
The speed of business today demands faster decisions and immediate actions. Streaming analytics allows you to act in the moment, turning it from a nice-to-have feature into a competitive necessity. It solves some of the biggest headaches that slow organizations down.
Latency Is the New Bottleneck in AI
Your AI and intelligent systems are only as good as the data they receive. When you feed them stale information from batch jobs, their performance suffers. Streaming analytics gives your models a constant flow of fresh data, helping you generate insights and make predictions that are relevant right now, not based on what happened yesterday.
Micro-Batch Is Not Real-Time
In situations like fraud detection or supply chain management, waiting for the next batch cycle means you’ve already missed your chance to act. If a fraudulent purchase gets approved because your system was waiting for its next five-minute update, that’s real money lost. The opportunity cost of these small delays adds up quickly.
Fragmented Data Kills Operational Agility
When your data is trapped in different silos across on-premise and cloud systems, it’s nearly impossible to get a clear picture of your operations. Streaming analytics breaks down these walls. It lets you analyze data from multiple systems in real time without having to move it all to one central location first. This gives your teams the agility to respond to changes as they happen.
Discover how streaming analytics transforms raw, real-time data into actionable insights, enabling faster decisions and competitive agility. Read an In-Depth Guide to Real-Time Analytics.
How Streaming Analytics Works

Streaming analytics might sound complicated, but it follows a simple flow: ingest, process, enrich, and act. A unified platform simplifies this process, unlike fragmented approaches that require you to piece together multiple tools.
Ingest Data Continuously from Live Sources
First, you need to capture data the moment it’s created. This includes changes from databases (using Change Data Capture (CDC)), sensor readings, application logs, and more. This process needs to be fast and reliable, without slowing down your source systems. Using a platform with a wide range of connectors and strong CDC capabilities is key.
Process and Transform Data in Motion
As data flows into your pipeline, it’s filtered, transformed, or joined with other streams. This is where raw data starts to become useful. For example, you can take a customer’s website click and instantly enrich it with their purchase history from another database—all while the data is still moving.
Enrich and Apply Real-Time Logic
Next, you can apply business rules or run the data through machine learning models directly in stream. This lets you do things like score a transaction for fraud risk or spot unusual patterns in sensor data. You could even have a single stream that checks a purchase for fraud while also seeing if the customer qualifies for a special offer, all in a fraction of a second.
Deliver to Targets and Visualize Insights
Finally, the processed insights are sent where they need to go. This might be a cloud data warehouse like Snowflake, a BI tool, or a real-time dashboard. The key is to deliver the information with sub-second latency so your teams and automated systems can take immediate action.
Real-Time Data Movement and Stream Processing: 6 Best Practices
Gain essential strategies for building reliable, scalable real-time data pipelines, emphasizing streaming-first integration, low-latency processing, and continuous data validation to enable actionable insights and operational efficiency. Read the full blog post to learn more.
Challenges in Implementing Streaming Analytics (and How to Solve Them)
While the value of streaming analytics is clear, getting it right can be challenging. Many teams struggle with the steep learning curve of open-source tools or get locked into a single cloud ecosystem. A unified platform like Striim is designed to help you sidestep these common pitfalls.
Open-source streaming stacks (Kafka/Flink/etc.): Steep learning curve, no native CDC, requires multiple tools for ingestion, processing, and monitoring.
Cloud-native tools: Strong within a single cloud but poor hybrid/multi-cloud support; risk of vendor lock-in.
Point solutions: Handle ingestion only; no in-flight transformation or decisioning.
Data Drift, Schema Evolution, and Quality Issues
Data formats and schemas can change without warning, breaking your pipelines and corrupting your analytics. With open-source tools, this often requires manual code fixes and redeployments. Striim, on the other hand, automatically detects these changes, adjusts the pipeline on the fly, and provides dashboards to help you monitor data quality.
Out-of-Order Events and Latency Spikes
Events don’t always arrive in the right order, which can throw off your analytics and trigger false alerts. Building custom logic to handle this is complicated and can break easily. Striim’s processing engine automatically handles event ordering and timing, ensuring your insights are accurate and delivered with consistent, sub-second latency.
Operational Complexity and Skill Gaps
Many streaming analytics projects fail because they require a team of experts specializing in complex systems like Kafka or Flink. Striim’s all-in-one platform makes it easier for everyone. Its low-code, SQL-based interface allows both developers and analysts to build powerful streaming pipelines without needing a PhD in distributed systems.
The Cost of False Real-Time
“Almost real-time” isn’t enough when every second matters. In some industries, a small delay in detecting fraud can result in a big financial loss. The hidden lags in micro-batch systems can have serious consequences. Striim processes data in memory to deliver true, sub-second performance across all your environments, so you can act instantly.
Striim Real-Time Analytics Quick Start
This tutorial provides a step-by-step guide to using Striim’s platform for creating real-time analytics applications. Learn how to process streaming data, build dashboards, and gain actionable insights with ease.
Must-Have Features in a Streaming Analytics Platform
Not all streaming platforms are created equal. To get the most out of your real-time data, you need a solution that does more than just move it from one place to another. Here are the features to look for.
Native Support for Real-Time Data Ingestion (including CDC)
Your platform should be able to pull in high volumes of data from all your sources—from databases and applications to IoT. It needs to offer log-based CDC to integrate with your operational databases in real time and low-impact integration with operational databases. Striim excels here with its CDC engine and support for hybrid environments.
In-Flight Data Processing and Transformation
Look for the ability to filter, join, and enrich data streams as they flow. A platform with powerful, SQL-based tools for transforming data in motion will help you turn raw information into valuable insights much faster. Look for SQL support, stateful processing, and real-time business logic. Striim’s real-time SQL (TQL) and CEP engine stands out here.
Real-Time Analytics and Decisioning Capabilities
The platform should be able to trigger alerts, update dashboards, or call other applications based on patterns it detects in the data. This includes handling everything from anomaly detection to complex fraud rules without any delay, as with Striim’s real-time alerting and monitoring workflows.
Enterprise-Grade Scale, Reliability, and Observability
You need a platform that can grow with your data volumes, support mission-critical workloads without fail, and deliver consistent sub-second latency. Strong observability tools are also essential for debugging and monitoring pipelines. With Striim, you get a distributed architecture with built-in pipeline monitoring.
Seamless Integration with Modern Data Infrastructure
A future-proof platform needs to connect easily with your existing data warehouses, like Snowflake and BigQuery, as well as messaging systems like Kafka. It must also support hybrid and multi-cloud environments, giving you the freedom to deploy your data wherever you want. Striim’s pre-built connectors and flexible deployment model stand out here.
Integrate both real-time and historical data in your ecosystem
While fresh, real-time data is crucial, ideally your platform of choice can also utilize historic data, especially for training AI and ML models. While many tools can handle either real-time updates or ingest historic data alone, the best solutions will be able to handle (and integrate) both for a rich, unified data set.
Why Choose Striim for Streaming Analytics
Trying to build a streaming analytics solution often leads to a messy collection of tools, frustrating latency issues, and complex integrations. Striim simplifies everything by combining ingestion, transformation, decisioning, and delivery into a single platform built for today’s hybrid-cloud world. The result is faster AI-driven insights, lower engineering overhead, and reliable real-time streaming at scale.
| Capability | Striim | Open-Source Stack | Cloud-Native ELT | Legacy CDC |
|---|---|---|---|---|
| Real-Time | True in-memory streaming, <1s latency | Multi-tool, latency varies | Often micro-batch | CDC only, no transformation |
| CDC | Native, hybrid/on-prem/cloud | Requires add-on (Debezium) | Limited, reloads common | Yes, no enrichment |
| Transformation | In-flight SQL + CEP | Requires Flink/Spark | Post-load only | Not supported |
| Schema Evolution | Auto-detect & adapt mid-stream | Manual fix & redeploy | Delayed handling | Manual |
| Hybrid/Multi-Cloud | Built-in, consistent SLAs | Complex setup | Single-cloud focus | On-prem only |
| Ease of Use | Low-code, intuitive interface | High technical barrier | Simple for cloud DBs | DBA-focused |
| AI/ML | AI-ready feature streams | Custom to build | Limited | Not supported |
| Security | Compliant with SOC 2, GDPR, HIPAA, and other major security benchmarks. | Liable to security breaches and vulnerabilities. | Limited | Vulnerable |
While there are many options out there, Striim is the leading platform that provides a complete, unified solution for streaming analytics, while other approaches only solve part of the puzzle.
Ready to stop reporting on the past and start acting in the present? Start a free trial of Striim or book a demo to see streaming analytics in action.
FAQs About Streaming Analytics
How does streaming analytics architecture change when deploying across hybrid or multi-cloud environments?
Deploying streaming analytics in hybrid or multi-cloud environments requires distributed data ingestion tools like change data capture (CDC) to collect real-time data from diverse sources without impacting performance. Regional processing nodes and edge computing reduce latency by pre-processing data closer to its source, while containerized microservices and auto-scaling ensure scalability for fluctuating workloads.
Security and compliance demand end-to-end encryption, role-based access control (RBAC), and local processing of sensitive data to meet regulations. Unified monitoring tools provide real-time observability for seamless management.
To avoid vendor lock-in, cloud-agnostic tools and open APIs ensure interoperability, while redundant nodes, multi-region replication, and self-healing pipelines enhance resilience. These adjustments enable real-time insights, scalability, and compliance across distributed systems.
What strategies prevent performance degradation when scaling streaming analytics to billions of events per day?
Scaling streaming analytics requires in-memory processing to avoid disk I/O delays, ensuring faster throughput and lower latency. Horizontal scaling adds nodes to distribute workloads, while data partitioning and dynamic load balancing evenly distribute streams and prevent bottlenecks.
To reduce strain, stream compression minimizes bandwidth usage, and pre-aggregation at the source limits data volume. Backpressure management techniques, like buffering, maintain stability during spikes. Optimized query execution and auto-scaling dynamically adjust resources, while fault tolerance mechanisms like checkpointing ensure quick recovery from failures. These strategies enable high performance and reliability at massive scale.
How can streaming analytics integrate with AI/ML pipelines for real-time model scoring and retraining?
Scaling streaming analytics for massive data volumes requires in-memory processing to eliminate disk I/O delays and ensure low-latency performance. Horizontal scaling adds nodes to handle growing workloads, while data partitioning and dynamic load balancing evenly distribute streams to prevent bottlenecks.
Stream compression reduces bandwidth usage, and pre-aggregation at the source minimizes the data entering the pipeline. Backpressure management, like buffering, maintains stability during spikes, while optimized query execution ensures efficient processing. Continuous monitoring and auto-scaling dynamically adjust resources, and fault tolerance mechanisms like checkpointing ensure quick recovery from failures. These strategies enable reliable, high-performance streaming at scale.
What are the best practices for ensuring data quality and consistency across distributed streaming pipelines?
Maintaining data quality in distributed pipelines starts with real-time validation, including schema checks, anomaly detection, and automated quality controls to ensure data integrity. Data lineage tracking provides transparency, helping teams trace and resolve issues quickly, while schema evolution tools adapt to structural changes without breaking pipelines.
For consistency, event ordering and deduplication are managed using watermarking and time-windowing techniques. Fault-tolerant architectures with checkpointing and replay capabilities ensure recovery without data loss. Global data catalogs and metadata tools unify data views across environments, while real-time observability frameworks monitor performance and flag issues early. These practices ensure reliable, high-quality data for real-time decisions.
How does streaming analytics support compliance in regulated industries without sacrificing latency?
Streaming analytics supports compliance in regulated industries by embedding security, governance, and monitoring directly into the data pipeline, ensuring adherence to regulations without compromising speed. End-to-end encryption protects data both in transit and at rest, safeguarding sensitive information while maintaining low-latency processing.
Role-based access control (RBAC) and multi-factor authentication (MFA) ensure that only authorized users can access data, meeting strict access control requirements. Additionally, real-time data lineage tracking provides full visibility into how data is collected, processed, and used, which simplifies audits and ensures compliance with regulations like GDPR or HIPAA.
To address data residency requirements, streaming platforms can process sensitive data locally within specific regions while still integrating with global systems. Automated policy enforcement ensures that compliance rules, such as data retention limits or anonymization, are applied consistently across the pipeline.
Finally, real-time monitoring and alerting detect and address potential compliance violations immediately, preventing issues before they escalate. By integrating these compliance measures into the streaming architecture, organizations can meet regulatory requirements while maintaining the sub-second latency needed for real-time decision-making.
What is the cost trade-off between unified streaming platforms and stitched-together open-source stacks?
Unified streaming platforms have higher upfront costs due to licensing but offer an all-in-one solution with built-in ingestion, processing, monitoring, and visualization. This simplifies deployment, reduces maintenance, and lowers total cost of ownership (TCO) over time.
Open-source stacks like Kafka and Flink are free upfront but require significant engineering resources to integrate, configure, and maintain. Teams must manually handle challenges like schema evolution and fault tolerance, increasing complexity and operational overhead. Scaling to enterprise-grade performance often demands costly infrastructure and expertise.
Unified platforms are ideal for faster time-to-value and simplified management, while open-source stacks suit organizations with deep technical expertise and tight budgets. The choice depends on prioritizing upfront savings versus long-term efficiency.
How do you monitor and troubleshoot event ordering issues in a large-scale streaming system?
Managing event ordering in large-scale streaming systems requires watermarking to track stream progress and time-windowing to handle late-arriving events without losing accuracy. Real-time observability tools are critical for detecting anomalies like out-of-sequence events or latency spikes, with metrics such as event lag and throughput offering early warnings.
To resolve issues, replay mechanisms can reprocess streams, while deduplication logic eliminates duplicates caused by retries. Distributed tracing provides visibility into event flow, helping pinpoint problem areas. Fault-tolerant architectures with checkpointing ensure recovery without disrupting event order. These practices ensure accurate, reliable processing at scale.
What role does CDC play in enabling streaming analytics for operational databases?
Change Data Capture (CDC) is a cornerstone of streaming analytics for operational databases, as it enables real-time data ingestion by capturing and streaming changes—such as inserts, updates, and deletes—directly from the database. This allows organizations to process and analyze data as it is generated, without waiting for batch jobs or manual exports.
CDC minimizes the impact on source systems by using log-based methods to track changes, ensuring that operational databases remain performant while still providing fresh data for analytics. It also supports low-latency pipelines, enabling real-time use cases like fraud detection, personalized recommendations, and operational monitoring.
Additionally, CDC ensures data consistency by maintaining the order of changes and handling schema evolution automatically, which is critical for accurate analytics. By integrating seamlessly with streaming platforms, CDC allows organizations to unify data from multiple operational systems into a single pipeline, breaking down silos and enabling cross-system insights.
In short, CDC bridges the gap between operational databases and real-time analytics, providing the foundation for actionable insights and faster decision-making.
How can you future-proof a streaming analytics implementation against schema changes and new data sources?
To future-proof a streaming analytics system, use schema evolution tools that automatically adapt to changes like added or removed fields, ensuring pipelines remain functional. Schema registries help manage versions and maintain compatibility across components, while data abstraction layers decouple schemas from processing logic, reducing the impact of changes.
For new data sources, adopt modular architectures with pre-built connectors and APIs to simplify integration. At the ingestion stage, apply data validation and transformation to ensure new sources align with expected formats. Real-time monitoring tools can flag issues early, allowing teams to address problems quickly. These strategies create a flexible, resilient system that evolves with your data needs.
When is micro-batch processing still the right choice over true streaming analytics?
Micro-batch processing is a good choice when real-time insights are not critical, and slight delays in data processing are acceptable. It works well for use cases like periodic reporting, refreshing dashboards every few minutes, or syncing data between systems where sub-second latency isn’t required.
It’s also suitable for organizations with limited infrastructure or technical expertise, as micro-batch systems are often simpler to implement and maintain compared to true streaming analytics. Additionally, for workloads with predictable, low-frequency data updates, micro-batching can be more cost-effective by reducing the need for always-on processing.
However, it’s important to evaluate the trade-offs, as micro-batch processing may miss opportunities in scenarios like fraud detection or real-time personalization, where immediate action is essential.
Deploying streaming analytics in hybrid or multi-cloud environments requires distributed data ingestion tools like change data capture (CDC) to collect real-time data from diverse sources without impacting performance. Regional processing nodes and edge computing reduce latency by pre-processing data closer to its source, while containerized microservices and auto-scaling ensure scalability for fluctuating workloads.
Security and compliance demand end-to-end encryption, role-based access control (RBAC), and local processing of sensitive data to meet regulations. Unified monitoring tools provide real-time observability for seamless management.
To avoid vendor lock-in, cloud-agnostic tools and open APIs ensure interoperability, while redundant nodes, multi-region replication, and self-healing pipelines enhance resilience. These adjustments enable real-time insights, scalability, and compliance across distributed systems.
Scaling streaming analytics requires in-memory processing to avoid disk I/O delays, ensuring faster throughput and lower latency. Horizontal scaling adds nodes to distribute workloads, while data partitioning and dynamic load balancing evenly distribute streams and prevent bottlenecks.
To reduce strain, stream compression minimizes bandwidth usage, and pre-aggregation at the source limits data volume. Backpressure management techniques, like buffering, maintain stability during spikes. Optimized query execution and auto-scaling dynamically adjust resources, while fault tolerance mechanisms like checkpointing ensure quick recovery from failures. These strategies enable high performance and reliability at massive scale.
Scaling streaming analytics for massive data volumes requires in-memory processing to eliminate disk I/O delays and ensure low-latency performance. Horizontal scaling adds nodes to handle growing workloads, while data partitioning and dynamic load balancing evenly distribute streams to prevent bottlenecks.
Stream compression reduces bandwidth usage, and pre-aggregation at the source minimizes the data entering the pipeline. Backpressure management, like buffering, maintains stability during spikes, while optimized query execution ensures efficient processing. Continuous monitoring and auto-scaling dynamically adjust resources, and fault tolerance mechanisms like checkpointing ensure quick recovery from failures. These strategies enable reliable, high-performance streaming at scale.
Maintaining data quality in distributed pipelines starts with real-time validation, including schema checks, anomaly detection, and automated quality controls to ensure data integrity. Data lineage tracking provides transparency, helping teams trace and resolve issues quickly, while schema evolution tools adapt to structural changes without breaking pipelines.
For consistency, event ordering and deduplication are managed using watermarking and time-windowing techniques. Fault-tolerant architectures with checkpointing and replay capabilities ensure recovery without data loss. Global data catalogs and metadata tools unify data views across environments, while real-time observability frameworks monitor performance and flag issues early. These practices ensure reliable, high-quality data for real-time decisions.
Streaming analytics supports compliance in regulated industries by embedding security, governance, and monitoring directly into the data pipeline, ensuring adherence to regulations without compromising speed. End-to-end encryption protects data both in transit and at rest, safeguarding sensitive information while maintaining low-latency processing.
Role-based access control (RBAC) and multi-factor authentication (MFA) ensure that only authorized users can access data, meeting strict access control requirements. Additionally, real-time data lineage tracking provides full visibility into how data is collected, processed, and used, which simplifies audits and ensures compliance with regulations like GDPR or HIPAA.
To address data residency requirements, streaming platforms can process sensitive data locally within specific regions while still integrating with global systems. Automated policy enforcement ensures that compliance rules, such as data retention limits or anonymization, are applied consistently across the pipeline.
Finally, real-time monitoring and alerting detect and address potential compliance violations immediately, preventing issues before they escalate. By integrating these compliance measures into the streaming architecture, organizations can meet regulatory requirements while maintaining the sub-second latency needed for real-time decision-making.
Unified streaming platforms have higher upfront costs due to licensing but offer an all-in-one solution with built-in ingestion, processing, monitoring, and visualization. This simplifies deployment, reduces maintenance, and lowers total cost of ownership (TCO) over time.
Open-source stacks like Kafka and Flink are free upfront but require significant engineering resources to integrate, configure, and maintain. Teams must manually handle challenges like schema evolution and fault tolerance, increasing complexity and operational overhead. Scaling to enterprise-grade performance often demands costly infrastructure and expertise.
Unified platforms are ideal for faster time-to-value and simplified management, while open-source stacks suit organizations with deep technical expertise and tight budgets. The choice depends on prioritizing upfront savings versus long-term efficiency.
Managing event ordering in large-scale streaming systems requires watermarking to track stream progress and time-windowing to handle late-arriving events without losing accuracy. Real-time observability tools are critical for detecting anomalies like out-of-sequence events or latency spikes, with metrics such as event lag and throughput offering early warnings.
To resolve issues, replay mechanisms can reprocess streams, while deduplication logic eliminates duplicates caused by retries. Distributed tracing provides visibility into event flow, helping pinpoint problem areas. Fault-tolerant architectures with checkpointing ensure recovery without disrupting event order. These practices ensure accurate, reliable processing at scale.
Change Data Capture (CDC) is a cornerstone of streaming analytics for operational databases, as it enables real-time data ingestion by capturing and streaming changes—such as inserts, updates, and deletes—directly from the database. This allows organizations to process and analyze data as it is generated, without waiting for batch jobs or manual exports.
CDC minimizes the impact on source systems by using log-based methods to track changes, ensuring that operational databases remain performant while still providing fresh data for analytics. It also supports low-latency pipelines, enabling real-time use cases like fraud detection, personalized recommendations, and operational monitoring.
Additionally, CDC ensures data consistency by maintaining the order of changes and handling schema evolution automatically, which is critical for accurate analytics. By integrating seamlessly with streaming platforms, CDC allows organizations to unify data from multiple operational systems into a single pipeline, breaking down silos and enabling cross-system insights.
In short, CDC bridges the gap between operational databases and real-time analytics, providing the foundation for actionable insights and faster decision-making.
To future-proof a streaming analytics system, use schema evolution tools that automatically adapt to changes like added or removed fields, ensuring pipelines remain functional. Schema registries help manage versions and maintain compatibility across components, while data abstraction layers decouple schemas from processing logic, reducing the impact of changes.
For new data sources, adopt modular architectures with pre-built connectors and APIs to simplify integration. At the ingestion stage, apply data validation and transformation to ensure new sources align with expected formats. Real-time monitoring tools can flag issues early, allowing teams to address problems quickly. These strategies create a flexible, resilient system that evolves with your data needs.
Micro-batch processing is a good choice when real-time insights are not critical, and slight delays in data processing are acceptable. It works well for use cases like periodic reporting, refreshing dashboards every few minutes, or syncing data between systems where sub-second latency isn’t required.
It’s also suitable for organizations with limited infrastructure or technical expertise, as micro-batch systems are often simpler to implement and maintain compared to true streaming analytics. Additionally, for workloads with predictable, low-frequency data updates, micro-batching can be more cost-effective by reducing the need for always-on processing.
However, it’s important to evaluate the trade-offs, as micro-batch processing may miss opportunities in scenarios like fraud detection or real-time personalization, where immediate action is essential.