Tutorial
Recover your CDC pipeline on Striim after planned downtime or cluster failure with no loss of data
Use Striim to recover or autoresume your data stream after server failure
Benefits
Restart your data pipeline after planned or unplanned failure from where it left off.
Resume data streaming automatically by assigning retry interval for planned outages
Avoid duplicate data from source to target table after recovery from CDC pipeline failure
On this page
Overview
Striim is a next generation unified data streaming product that offers change data capture (CDC) from popular databases such as Oracle, SQLServer, PostgreSQL and many others. Server downtime is defined as the amount of time organizations are offline. This is an unavoidable event for most companies and can be either planned due to maintenance or IT-related tasks or unplanned due to system crashes or connectivity issues.
Data Pipelines are majorly affected by server failovers. In 2009, PayPal’s network infrastructure faced a technical issue, causing it to go offline for one hour. This downtime led to a loss of transactions worth $7.2 million. In these circumstances real-time streaming with a strong recovery feature is one of the most efficient solutions.
With few limitations, Striim applications can be recovered after planned downtime or most cluster failures with no loss of data. In the following recipe, we have shown how to enable ‘RECOVERY’ and ‘AUTO RESUME’ features in Striim that can be utilized to handle failovers along with real-time streaming. Striim allows data pipelines to pick up from where it left during the failover, thus avoiding loss of data or duplicates in the target table. Please find the github link for this application here.
Core Striim Components
PostgreSQL CDC: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
Snowflake Writer: Striim’s Snowflake Writer writes to one or more existing tables in Snowflake. Events are staged to local storage, Azure Storage, or AWS S3, then written to Snowflake as per the Upload Policy setting.
Enabling Recovery from System Failures
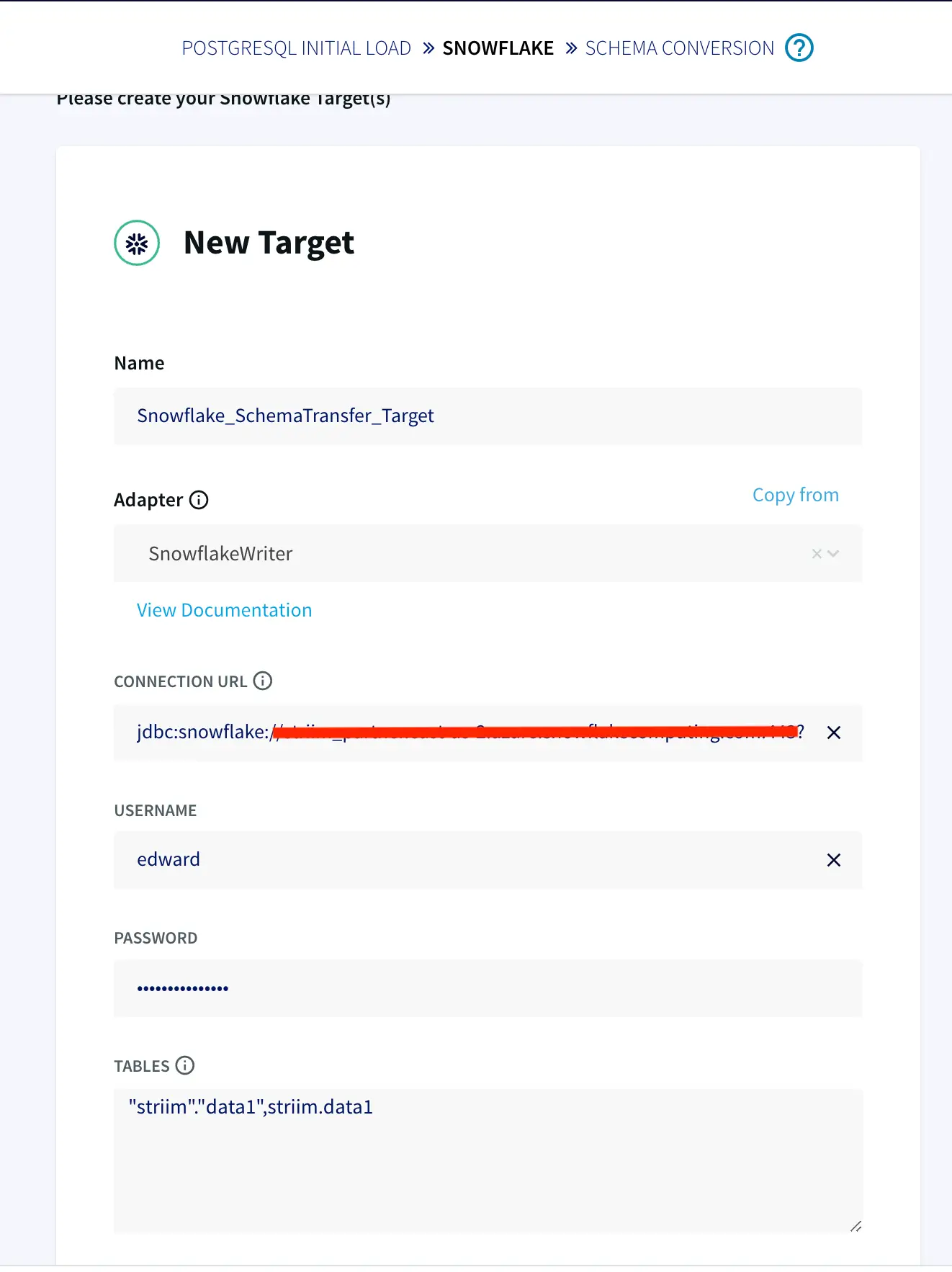
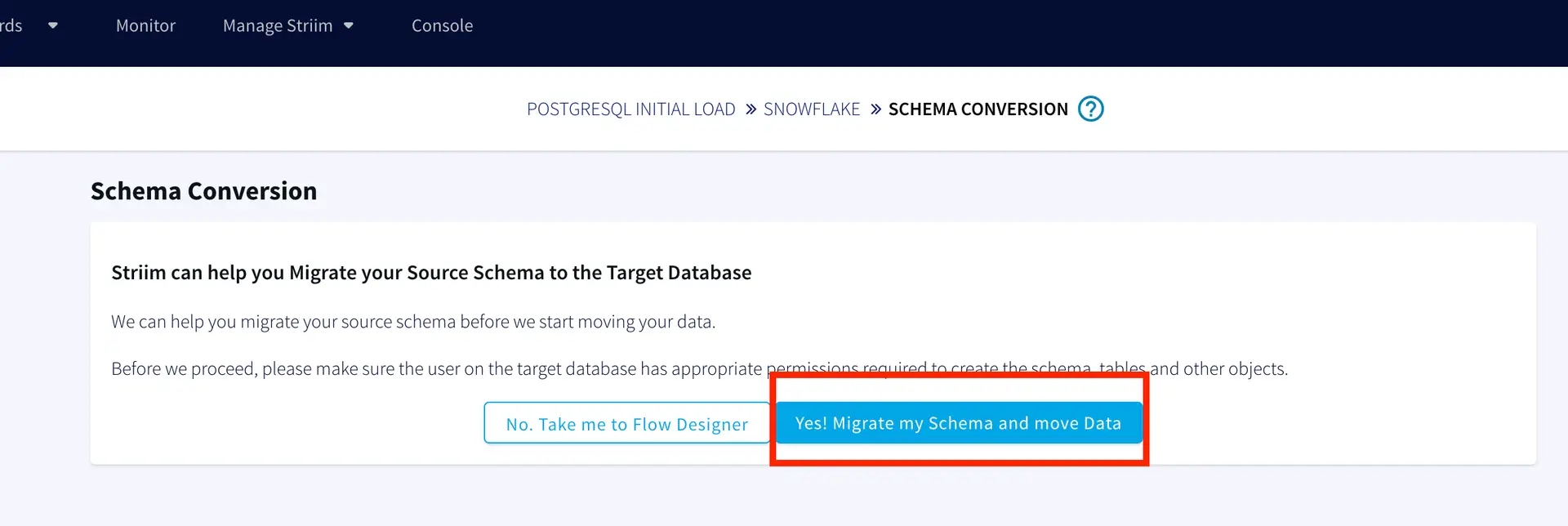
Striim supports recovery from system failures through Recovery and Autoresume features. For recovery of WAction stores, persistence streams must be enabled on every WAction store within the Striim application. Before enabling Recovery, create your app using flow designer. In the following use-case, our source is postgres CDC and target is Snowflake. You can refer to our recipes and tutorials for detailed steps on creating striim app from flow designer, both using wizard or from scratch.You can configure the Recovery and Autoresume setting from flow designer as follows:
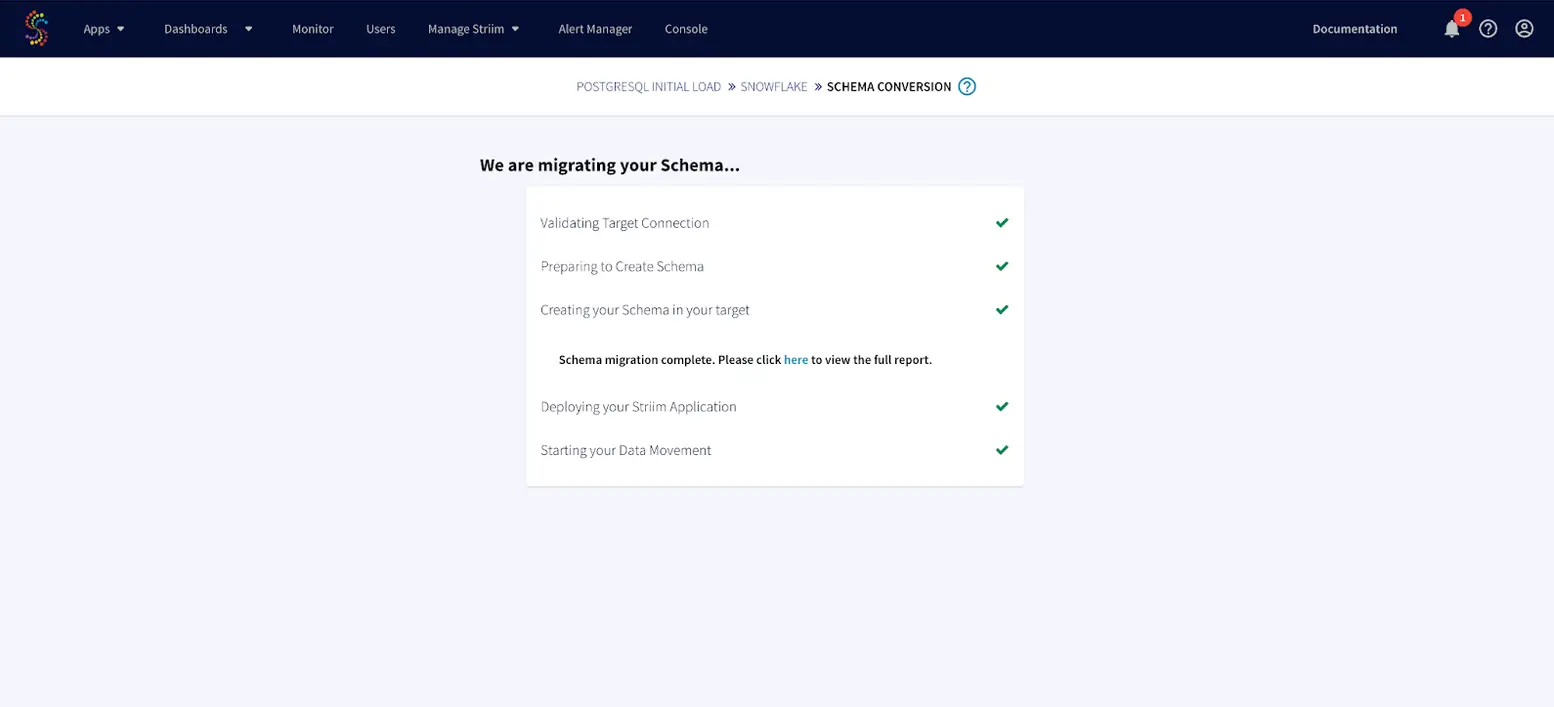
On the upper right corner under app configuration -> App settings, specify the time interval for ‘RECOVERY’.With this setting, Striim will record a recovery checkpoint every ten seconds (or time specified by the user), provided it has completed recording the previous checkpoint. When recording a checkpoint takes more than ten seconds, Striim will start recording the next checkpoint immediately. When the Striim application is restarted after a system failure, it will resume exactly where it left off.
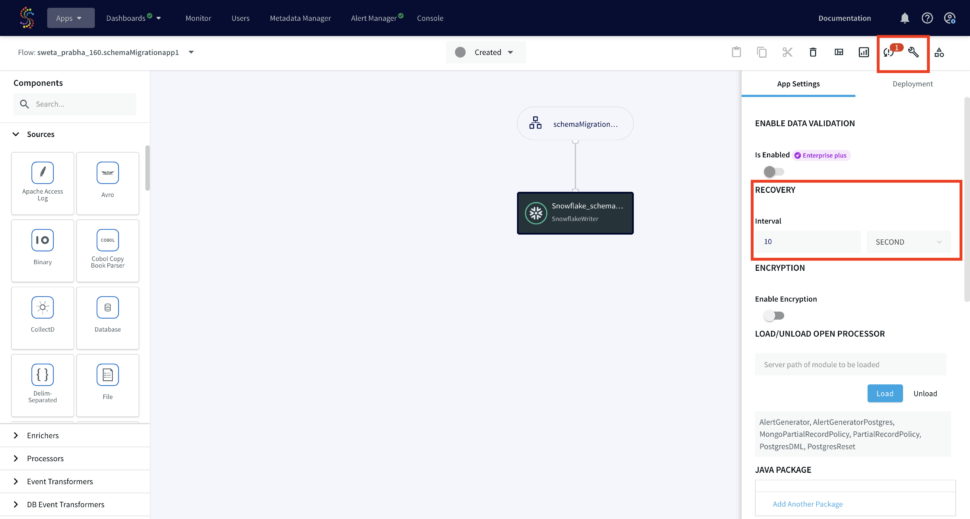
Running the Streaming App before Failover
The postgres CDC to Snowflake streaming application is deployed and run. When one row is inserted to the source table, it is replicated into the target table.


Running the Streaming App after Failover
When a failover occurs, the app stops and the last checkpoint is recorded. When recovery is enabled, DatabaseWriter uses the table specified by the Checkpoint Table property to store information used to ensure that there are no missing or duplicate events after recovery.
The failover occurred after the first row was replicated to target table:

When the app is restarted, it takes some time to start from where the application left off:

During failover, two more rows were added to the source table which was picked up by the striim app and once the server was up, two more rows were replicated to the target table.

The following snapshots show the source (Postgres) and target (Snowflake) tables and we can see there is no repetition on the target table even though the app started after a failover.

You can also monitor the checkpoint with console commands. To see detailed recovery status, enter MON . in the console (see Using the MON command). If the status includes “late” checkpoints, we recommend you Contact Striim support, as this may indicate a bug or other problem (though it will not interfere with recovery).

To see the checkpoint history, enter SHOW . CHECKPOINT HISTORY in the console.

Automatically Restarting an Application after a Crash
If known transient conditions such as network outages cause an application to crash, you may configure it to restart automatically after a set period of time. You can enable auto resume feature with desired retry interval and maximum retries under App Setting in the flow design as follows:
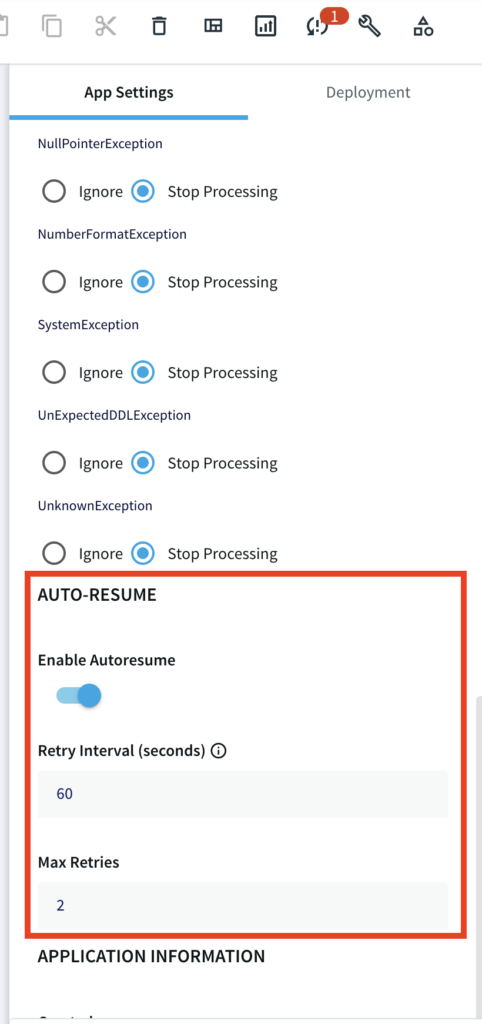
Setting Up Striim app for CDC pipeline recovery
Step 1: Download the data and Sample TQL file from our github repo
You can download the TQL files for streaming app our github repository. Deploy the Striim app on your Striim server. It should have failure recovery enabled. If you are creating your app from wizard please follow the steps shown in the recipe
Step 2: Configure your source and target
Configure your source and Target in the striim components.
Step 3:Run app before failover
Deploy your streaming app and run it for real-time data replication
Step 4: Run app after failover
Run the Striim app after Failover. Check the source and target for the recovered data
Wrapping Up: Start your Free Trial Today
The above tutorial showed you how to enable recovery for any planned or unplanned server outages or failovers. With Striim’s powerful CDC technology and recovery feature, you can rely on your real-time data pipeline for any analytical purposes even when there is a failover. Striim supports a multitude of sources and targets . This can be utilized to build reliable streaming applications with desired databases and data warehouses.
As always, feel free to reach out to our integration experts to schedule a demo, or try Striim for free here.
Tools you need

Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.

Snowflake
Snowflake is a cloud-native relational data warehouse that offers flexible and scalable architecture for storage, compute and cloud services.



 Enable ‘SCHEMA EVOLUTION-CDDL CAPTURE’ and enter the name of the CDDL TRACKING TABLE that we created in Step 2. The CDDL ACTION property is ‘Process’.
Enable ‘SCHEMA EVOLUTION-CDDL CAPTURE’ and enter the name of the CDDL TRACKING TABLE that we created in Step 2. The CDDL ACTION property is ‘Process’.