Data Integration Tools: A Buyer’s Guide to the Landscape
In a modern enterprise, data is all over the place. Today, your data ecosystem is more likely a sprawling network of SaaS applications, cloud data warehouses, legacy systems, and edge devices than a neatly centralized hub. While each of these platforms solves a specific problem, together they create a new one: a fragmented, disconnected data mess.
For most enterprise leaders, the challenge isn’t just storing data, it’s moving it. You need to get customer interactions from your CRM into your warehouse for analytics, sync inventory logs with your ERP, and feed real-time context into your AI models. And increasingly, you need this to happen now, not during a batch window at 2:00 AM.
This is where data integration tools come in. They are the plumbing that connects your disparate systems, ensuring that insight flows freely across the organization.
But if you’ve started researching the market, you’ve likely noticed that “data integration” is a deceptively broad term. It covers everything from traditional batch ETL (Extract, Transform, Load) platforms and simple SaaS connectors to modern, real-time streaming solutions. Finding the right tool means cutting through the noise of acronyms and vendor promises to find the architecture that actually fits your use case.
This guide is designed to do exactly that. We’ll unpack what data integration tools really do, the different types available (including why the industry is shifting toward real-time), and the key features you need to look for to future-proof your stack.
What Are Data Integration Tools?
Data integration tools connect your data sources (like databases, SaaS apps, or file systems) to a destination (like a data warehouse, data lake, or another application). Its job is to extract data, transform it into a usable format, and load it where it needs to go.
But that simple definition hides a lot of complexity. “Integration” isn’t a single specific task. It covers a massive range of use cases. You might use one tool to dump yesterday’s sales data into Snowflake for a morning report and a completely different tool to sync live inventory levels between your ERP and your e-commerce platform.
Because the use cases vary so much, the tools do too. You will find:
- Batch tools that move data in large chunks at scheduled intervals.
- Real-time streaming tools that move data the instant it is created.
- Cloud-native platforms designed for modern stacks versus legacy on-premise solutions.
- No-code/Low-code builders for business users versus complex frameworks for data engineers.
Here is the reality we see at Striim. While batch processing has been the standard for decades, modern business is moving too fast for “yesterday’s data.” We believe data integration should be real-time by default. It should be cloud-ready and built to handle the scale of a streaming-first world, not just occasional updates.
Types of Data Integration Tools
If the marketplace feels crowded, it’s because “integration” is a massive umbrella. A tool designed to sync your marketing emails is not the same tool designed to migrate a mainframe database to the cloud.
To choose the right solution, you need to understand the four main categories.
ETL/ELT Platforms
These are the traditional workhorses of data warehousing.
- ETL (Extract, Transform, Load) is the classic method: data is pulled from a source, cleaned and formatted on a separate server, and then loaded into a warehouse.
- ELT (Extract, Load, Transform) is the modern cloud-native variation. It dumps raw data directly into a cloud warehouse (like Snowflake or BigQuery) and uses the warehouse’s own power to transform it later.
Best for: Historical analysis, regulatory reporting, and “rearview mirror” business intelligence where a 24-hour delay is acceptable.
Streaming/CDC Platforms
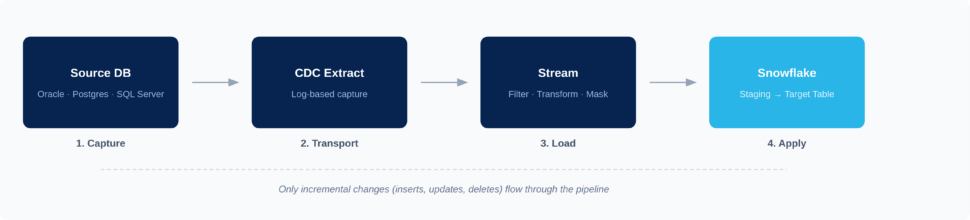
This is where the industry is heading. Instead of moving data in large batches once a day, these tools move data continuously as it is generated. This is often powered by Change Data Capture (CDC), technology that reads transaction logs from databases to capture inserts, updates, and deletes in real-time.
Best for: Real-time analytics, AI/ML pipelines, fraud detection, live operational dashboards, and any scenario where “right now” matters more than “yesterday.”
Data Replication & Migration Tools
These tools are built for one specific purpose: to create an exact copy of a database in another location. They are often used for disaster recovery, high availability, or a one-time “lift and shift” migration to the cloud. They typically don’t offer much in the way of data transformation; their job is fidelity, not flexibility.
Best for: Moving a legacy on-premise database to the cloud or creating a backup for disaster recovery.
iPaaS and SaaS Integration Tools
If you’ve ever used a tool to automatically add a row to a spreadsheet when you get a new email, you’ve used an iPaaS (Integration Platform as a Service). These are typically low-code platforms designed to trigger workflows between SaaS applications (like Salesforce, Slack, or HubSpot).
Best for: Simple workflow automation and connecting SaaS apps. They generally struggle with high-volume, enterprise-grade data loads.
Where Does Striim Fit?
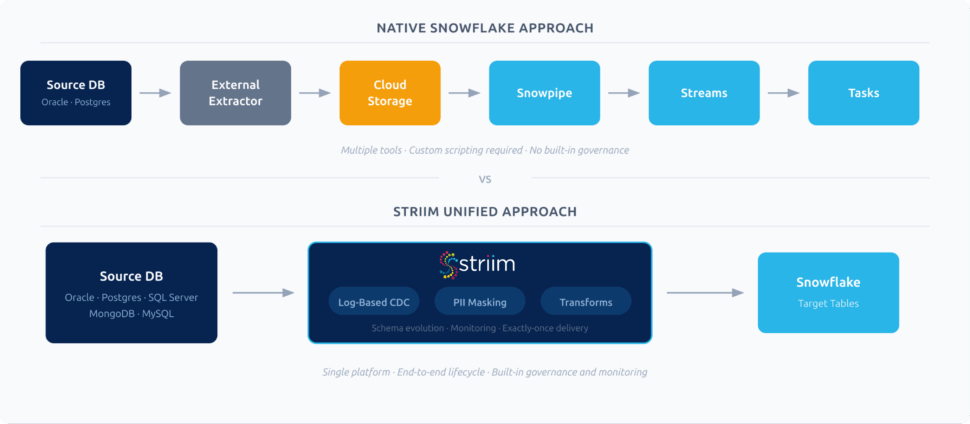
You will also encounter a divide between Open Source Frameworks (like Kafka or Debezium) and Enterprise Platforms. Open source gives you raw power and flexibility but requires a massive engineering effort to build, secure, and maintain.
Striim sits at the intersection of these worlds. We provide the real-time speed and power of a streaming platform but packaged with the usability, security, and connectivity of an enterprise solution. We are built to handle the high-volume complexity of CDC and streaming, but we make it accessible enough that you don’t need a team of Java engineers to run it.
Benefits of Using Data Integration Tools
As your business scales, your data complexity grows with it. What starts as a manageable set of spreadsheets and a CRM quickly becomes a chaotic mess of disparate apps and databases.
Without a strategy to unify them, you end up with data silos where critical information is trapped in different departments.
Integration tools do more than just move bytes from A to B. They provide the connective tissue that allows your organization to function as a single, cohesive unit.
Real-Time Access to Consistent Data
The biggest cost of a disconnected stack is uncertainty. When your marketing platform says one thing and your ERP says another, you lose trust in the numbers. Modern integration tools create a reliable “single source of truth” by ensuring data is consistent across all systems.
Faster, More Accurate Decision Making
Old-school batch processing meant looking at your business through a rearview mirror. You were always analyzing what happened yesterday. Real-time integration tools flip this dynamic. They deliver live data to your analytics dashboards, allowing you to spot trends, react to supply chain issues, or personalize customer offers in the moment.
Streamlined Engineering Workflows
Building custom connections between systems is a massive drain on your engineering talent. It requires writing brittle scripts that break whenever an API changes. Dedicated integration tools abstract this complexity away. They provide pre-built connectors and automated monitoring, freeing your data team to focus on building value rather than fixing broken pipelines.
16 Best Data Integration Tools
The following list covers the major players across all categories: from modern streaming platforms to legacy ETL giants. We’ve grouped them by their primary strengths to help you navigate the landscape.
 1. Striim
1. Striim
Striim is the only unified data streaming and integration platform that offers real-time Change Data Capture (CDC) with built-in streaming intelligence. While most tools force you to choose between speed (streaming) and complexity (writing custom code), Striim delivers enterprise-grade real-time data movement in a low-code, fully managed platform. Key Features:
- Real-Time CDC: Captures data instantly from transactional databases (Oracle, SQL Server, PostgreSQL, etc.) without slowing down the source system.
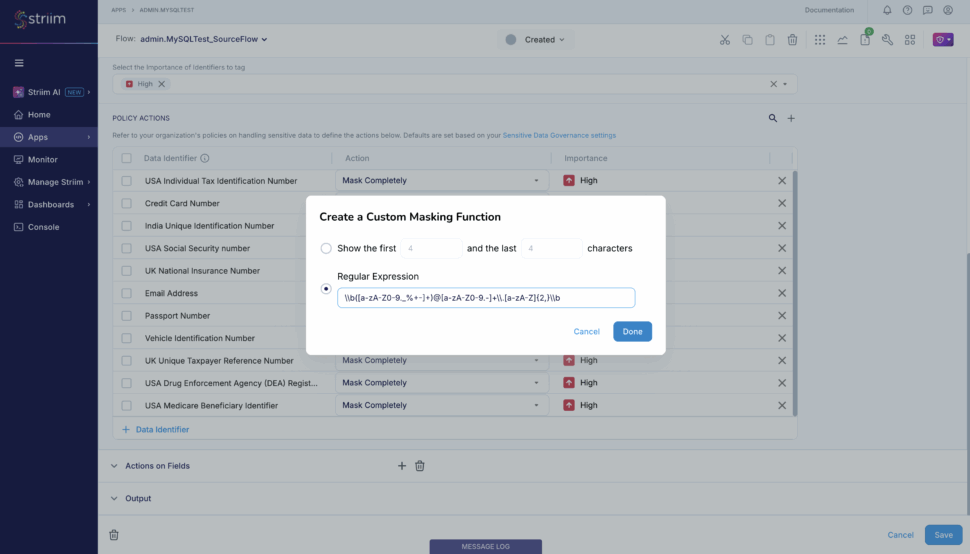
- In-Flight Transformation: Filter, mask, aggregate, and enrich data using SQL before it ever lands in the destination.
- 150+ Built-in Adapters: Connects legacy on-prem systems (like Mainframes and HP NonStop) directly to modern clouds (Snowflake, Databricks, BigQuery) in real-time.
- Zero-Downtime Migration: Keeps old and new systems in sync during cloud migrations to eliminate cutover risk.
What kind of companies use Striim? Enterprises with mission-critical data needs—like financial services, retail, and healthcare—that require sub-second latency for fraud detection, customer personalization, or operational analytics. Pros:
- True real-time performance (milliseconds, not minutes).
- Handles complex enterprise sources that newer tools often miss.
- Combines integration and streaming analytics in one platform.
Cons:
- Striim may be overkill for certain use cases, such as simple, low-volume nightly batch jobs.
Pricing: Consumption-based model (pay for what you move) via Striim Cloud, or enterprise licensing for self-hosted deployments.

2. Qlik (formerly Attunity)
Qlik Replicate (formerly Attunity) is a well-established player in the CDC space. It is known for its strong replication capabilities, particularly for SAP and mainframe environments. Key Features:
- Automated bulk loads and real-time CDC.
- Agentless architecture that minimizes footprint on source systems.
- Strong SAP integration.
Pros:
- Reliable for simple 1:1 database replication.
- Broad support for legacy platforms.
Cons:
- Limited transformation capabilities (often requires Qlik Compose).
- Can become expensive and complex to manage at scale.
Pricing: Enterprise pricing (contact sales).

3. Confluent
Built by the creators of Apache Kafka, Confluent is a streaming platform designed for event-driven architectures. It is less of a “tool” and more of a foundational infrastructure for building streaming applications. Key Features:
- Managed Apache Kafka service.
- Stream processing via ksqlDB.
- Broad ecosystem of connectors.
Pros:
- The gold standard for high-throughput event streaming.
- Extremely scalable.
Cons:
- High technical barrier to entry; requires engineering expertise.
- Can be overkill for simple point-to-point integration needs.
Pricing: Pay-as-you-go based on throughput and storage.

4. Oracle GoldenGate
The legacy heavyweight of the CDC world. GoldenGate has been the standard for Oracle-to-Oracle replication for decades and is deeply embedded in many Fortune 500 tech stacks. Key Features:
- Deep integration with Oracle Database internals.
- Bi-directional replication for active-active high availability.
Pros:
- Unmatched reliability for Oracle ecosystems.
- Proven in the most demanding enterprise environments.
Cons:
- Extremely expensive and complex to license.
- Rigid and difficult to use for non-Oracle targets or modern cloud use cases.
Pricing: Processor-based licensing.

5. Informatica PowerCenter
Informatica is the quintessential traditional ETL platform. It is a powerful, comprehensive suite for data management, quality, and governance, primarily designed for on-premise data warehousing. Key Features:
- Extensive library of pre-built transformations.
- robust metadata management and data lineage.
Pros:
- Can handle virtually any batch integration scenario.
- Strong governance features for regulated industries.
Cons:
- Complexity effectively requires certified developers to manage.
- Struggles with modern cloud-native and real-time agility.
Pricing: Expensive enterprise licensing.

6. Talend
Talend (now part of Qlik) offers a suite of data integration tools ranging from an open-source “Open Studio” to a paid enterprise platform. It generates Java code to execute data pipelines. Key Features:
- Visual design canvas that generates native code.
- Strong data quality features embedded in the flow.
Pros:
- Flexible and developer-friendly.
- Open Source version allows for free testing/learning.
Cons:
- Managing generated Java code can become messy at scale.
- Performance can lag compared to purpose-built engines.
Pricing: Free open-source version; tiered subscription for enterprise.

7. Fivetran
Fivetran is the leader in the modern “ELT” movement. It is a SaaS tool designed to be dead simple: you plug in a source, plug in a warehouse, and it just works. Key Features:
- Zero-maintenance, fully managed pipelines.
- Automatic schema drift handling (adapts when source columns change).
Pros:
- Incredibly easy to set up (minutes, not months).
- Great for marketing and sales data integration.
Cons:
- Volume-based pricing becomes very expensive at scale.
- “Black box” nature means you have little control over how/when data moves.
Pricing: Consumption-based (Monthly Active Rows).

8. Stitch (part of Talend)
Similar to Fivetran, Stitch is a cloud-first ELT tool focused on simplicity. It is developer-focused and offers a lower entry price point for smaller teams. Key Features:
- Open-source “Singer” tap/target framework.
- Simple replication to cloud warehouses.
Pros:
- Transparent pricing and easy setup.
- Extensible via open-source community connectors.
Cons:
- Less enterprise-grade functionality than Fivetran.
- Limited transformation capabilities.
Pricing: Tiered volume-based subscription.

9. Hevo Data
Hevo is a no-code data pipeline platform that combines ELT simplicity with some real-time capabilities. It positions itself as a user-friendly alternative to Fivetran with faster data movement. Key Features:
- Automated schema mapping.
- Supports both ETL and ELT workflows.
Pros:
- User-friendly interface.
- Supports some transformation capability (Python code).
Cons:
- Not a true enterprise-grade streaming platform like Striim or Confluent.
Pricing: Event-based subscription.

10. Airbyte
Airbyte is the open-source challenger to Fivetran. It has gained massive popularity by offering a “build your own connector” model and transparent pricing. Key Features:
- Large library of community-maintained connectors.
- Run it yourself (Open Source) or use their Cloud service.
Pros:
- No vendor lock-in; you own the infrastructure.
- Access to long-tail connectors that other vendors ignore.
Cons:
- Community connectors vary widely in quality and reliability.
- Self-hosting requires engineering maintenance.
Pricing: Free (Open Source); Credit-based (Cloud).

11. AWS Glue
AWS Glue is a serverless data integration service native to Amazon Web Services. It is primarily code-based (Python/Scala) and targets developers building data lakes on S3. Key Features:
- Serverless architecture (no infrastructure to manage).
- Data Catalog to discover and search metadata.
Pros:
- Seamless if you are already 100% on AWS.
- Cost-effective for sporadic batch workloads.
Cons:
- Steep learning curve; requires coding skills.
- Slow startup times (“cold starts”) make it poor for real-time needs.
Pricing: Pay-as-you-go based on DPU-hours.

12. Azure Data Factory (ADF)
Microsoft’s cloud-native ETL service. ADF is a visual, drag-and-drop tool that orchestrates data movement across the Azure ecosystem. Key Features:
- SSIS integration (easier migration for SQL Server shops).
- Visual “data flow” designer.
Pros:
- Excellent integration with the Microsoft stack (Azure SQL, Synapse).
- Powerful orchestration capabilities.
Cons:
- Can be complex to configure properly.
- Debugging errors can be frustratingly opaque.
Pricing: Pay-as-you-go based on activity runs and data movement.

13. Google Cloud Dataflow
Dataflow is Google’s fully managed service for stream and batch processing. It is built on the open-source Apache Beam model. Key Features:
- Unified batch and streaming model.
- Horizontal autoscaling.
Pros:
- Incredibly powerful for massive scale data processing.
- Serverless and low-maintenance.
Cons:
- High complexity; requires writing Java or Python code.
- Tied heavily to the Google Cloud ecosystem.
Pricing: Pay-as-you-go based on vCPU and memory usage.

14. IBM DataStage
A legacy enterprise player similar to Informatica. DataStage is known for its parallel processing engine and ability to handle massive throughput in on-premise environments. Key Features:
- Parallel processing architecture.
- Deep mainframe connectivity.
Pros:
- Proven stability for massive, complex enterprise jobs.
Cons:
- Interface feels dated compared to modern tools.
- High cost and heavy infrastructure footprint.
Pricing: Enterprise licensing.

15. Oracle Data Integrator (ODI)
Unlike GoldenGate, ODI is an ELT tool designed for bulk data movement. It is optimized for pushing processing down to the database level rather than using a separate engine. Key Features:
- ELT architecture (uses target DB power).
- Declarative design approach.
Pros:
- High performance for Oracle-centric warehouses.
- Lower infrastructure cost than traditional ETL servers.
Cons:
- Niche appeal mostly limited to Oracle shops.
- Steep learning curve.
Pricing: Processor-based licensing.

16. SnapLogic
SnapLogic is an iPaaS (Integration Platform as a Service) that focuses on ease of use. It uses a visual “Snaps” interface to connect apps and data. Key Features:
- AI-powered integration assistant (“Iris”).
- Self-service UI for business users.
Pros:
- Very easy to use; great for connecting SaaS apps (Salesforce, Workday).
- Unified platform for app and data integration.
Cons:
- Struggles with high-volume, complex data replication scenarios.
- Can get expensive as you scale connector usage.
Pricing: Subscription-based.
Key Features to Look for in Data Integration Tools
The capabilities of each integration tool vary significantly depending on whether they were built for batch ETL, simple SaaS syncing, or high-speed streaming. Choosing the right tool isn’t a simple box-ticking exercise: it involves narrowing down the features that best align with your technical considerations, latency requirements, team skills, and infrastructure. Here are the critical capabilities you should be evaluating.
Connectivity
While almost every vendor claims “hundreds of connectors,” look closer. Do they support your specific legacy systems (like Mainframes or Oracle on-prem)? Do they have native, optimized connectors for your modern cloud targets (Snowflake, Databricks, BigQuery)? The best tools offer a mix of both, ensuring you aren’t forced to build custom workarounds for your most critical data sources.
Real-Time Ingestion and CDC
In the age of AI, batch can no longer keep up. Look for tools that offer true Change Data Capture (CDC). This allows you to capture data updates the instant they happen in the source database without impacting performance. Be wary of tools that claim “real-time” but actually use frequent micro-batch polling, which can strain your production systems.
Data Transformation and Enrichment
Moving raw data is rarely good enough for modern use cases. You usually need to filter, mask, or aggregate it before it lands in your warehouse. Tools that offer in-flight transformation allow you to clean and shape data while it is moving. This reduces the processing load on your destination warehouse and ensures that your analytics teams get clean, usable data instantly.
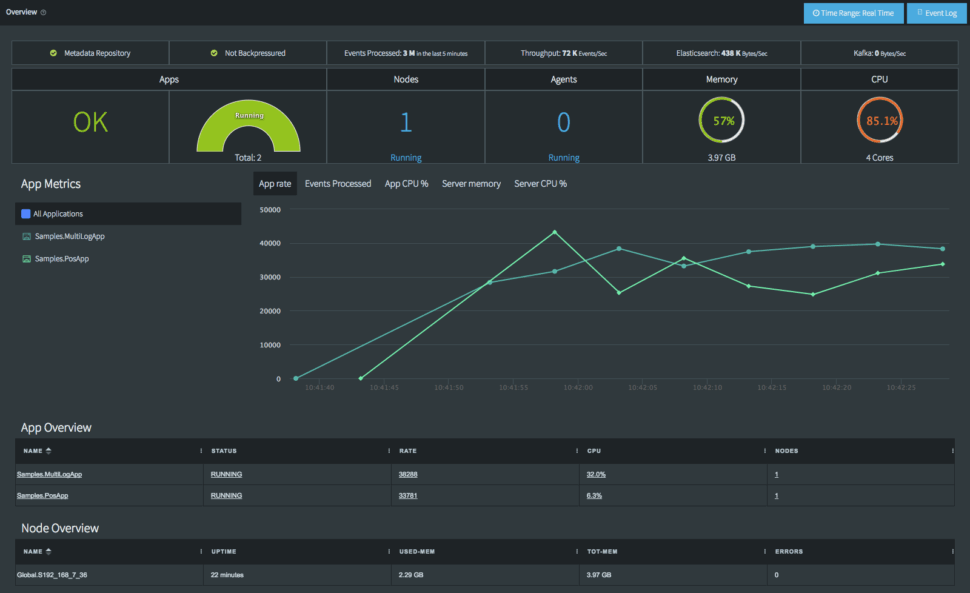
Monitoring and Observability
When a pipeline breaks, you need to know immediately. Enterprise-grade tools provide detailed dashboards, alerts, and lineage tracking. You should be able to see exactly where data is flowing, catch errors in real-time, and understand the health of your entire integration landscape at a glance.
Security and Compliance
If you are in a regulated industry like finance or healthcare, security is non-negotiable. Look for features like end-to-end encryption, role-based access control (RBAC), and compliance certifications (SOC 2, HIPAA, GDPR). Your integration tool will be handling your most sensitive data, so it must be as secure as the vault it lives in.
Scalability
Will the tool handle your data volume next year? Cloud-native platforms that can scale horizontally are essential for growing enterprises. Avoid legacy tools that require expensive hardware upgrades to handle increased loads.
Extensibility
Sometimes you need to do something unique. Can you inject custom code (like SQL or Java) into the pipeline? Can you build your own connector if needed? The best platforms offer a low-code interface for speed but allow you to drop down into code when complex logic is required.
How to Choose the Right Data Integration Tool
There is no single “best” tool. The right choice depends entirely on your specific business goals. To narrow down your shortlist, ask yourself these five questions:
- What is your latency tolerance? Do you need data to be actionable in sub-seconds (for fraud detection or AI), minutes (for operational reporting), or is a 24-hour delay acceptable? If you need sub-second speed, focus on streaming/CDC platforms. If yesterday’s data is fine, a cheaper batch ETL tool might suffice.
- What data are you moving, and how often? Are you moving massive transaction volumes from an Oracle database, or just syncing a few leads from Salesforce? High-volume, high-velocity data requires a robust, distributed architecture like Striim or Kafka.
- What is your tech stack? Are you 100% cloud, 100% on-prem, or hybrid? If you have a complex hybrid environment (e.g., mainframe on-prem to Snowflake in the cloud), you need a platform built to bridge that specific gap securely.
- Who will be building the pipelines? Do you have a team of Java engineers, or do you need a tool that business analysts can use? No-code/low-code tools speed up adoption, but ensure they don’t sacrifice the power and control your engineers might eventually need.
- What is your budget and expected scale? Consider total cost of ownership (TCO), not just the license fee. Open source might look free but carries a high engineering maintenance cost. Usage-based SaaS pricing can be cheap to start but expensive at scale. Look for a transparent pricing model that aligns with your growth.
Modern Data Integration Starts with Striim
The market is shifting. We are moving away from the era of “batch windows” and “nightly dumps” into a future where data is a continuous, living stream.
Choosing the right data integration tool is about more than just solving today’s problem. It’s about positioning your enterprise for that real-time future. It means selecting a platform that can handle your legacy heavyweights while seamlessly powering your modern AI and cloud initiatives.
Striim offers the enterprise-grade power of a streaming platform with the usability of a modern SaaS tool. We help you break free from legacy batch paradigms and give you the real-time visibility you need to compete. Ready to stop waiting for your data?
- Book a demo: See how Striim can modernize your data architecture in minutes.
- Sign up now: Start building your first real-time pipeline for free.