
In this week’s episode, John Kutay sits down with Eric Broda, a 30-year veteran in the financial industry, to discuss the foundations for a Data Mesh.
Tag: Real-time Data
The Future of Analytics with Bruno Aziza (Head of Analytics at Google Cloud)
We sit down with Bruno Aziza – Head of Analytics at Google Cloud – To discuss the latest trends in data such as data mesh, data governance, and the real-world value of real-time data.
Enterprise Data Streaming Patterns: Integration, Governance and Data Mesh


Watch our on-demand webinar on data streaming patterns that enable enterprises to analyze and act on data in real time.
Alok Pareek and Sanjeev Mohan cover topics including:
- How to deliver real-time data and insights in complex enterprise environments
- The latest opinions and best practices for enterprise streaming data patterns, including data mesh
- A real-world example of a mesh architecture in retail
Speakers
Alok Pareek
Founder, EVP Products Striim, Former VP of Engineering at Oracle and GoldenGate
Sanjeev Mohan
Principal, SanjMo & Former Gartner Research VP, Big Data and Advanced Analytics
Rethink Your Data Architecture With Data Mesh and Event Streams

According to a Gartner prediction, only 20% of data analytics projects will deliver business outcomes. Indeed, given that the current data architectures are not well equipped to handle data’s ubiquitous and increasingly complex interconnected nature, this is not surprising. So, in a bid to address this issue, the question on every company’s lips remains — how can we properly build our data architecture to maximize data efficiency for the growing complexity of data and its use cases?
First defined in 2018 by Zhamak Dehghani, Head of Emerging Technologies at Thoughtworks, the data mesh concept is a new approach to enterprise data architecture that aims to address the pitfalls of the traditional data platforms. Organizations seeking a data architecture to meet their ever-changing data use cases should consider the data mesh architecture to power their analytics and business workloads.
What Is a Data Mesh?
A data mesh is an approach to designing modern distributed data architectures that embrace a decentralized data management approach. The data mesh is not a new paradigm but a new way of looking at how businesses can maximize their data architecture to ensure efficient data availability, access, and management.
How does a data mesh differ from traditional data architectures?
Rather than viewing data as a centralized repository, a data mesh’s decentralized nature distributes data ownership to domain-specific teams that manage, control, and deliver data as a product, enabling easy accessibility and interconnectivity of data across the business.
Today most companies’ data use cases can be split into operational and analytical data. Operational data represents data from the company applications’ day-to-day operations. For example, using an e-commerce store, this will mean customer, inventory, and transaction data. This operational data type is usually stored in databases and used by developers to create various APIs and microservices to power business applications.

Operational vs. analytical data plane
On the other hand, analytical data represents historical organizational data used to enhance business decisions. In our e-commerce store example, analytical data answers questions such as “how many customers have ordered this product in the last 20 years?” or “what products are customers likely to buy in the winter season?” Analytical data is usually transported from multiple operational databases using ETL (Extract, Transform, and Load) techniques to centralized data stores like data lakes and warehouses. Data analysts and scientists use it to power their analytics workloads, and product and marketing teams can make effective decisions with the data.
A data mesh understands the difference between the two broad types of data and attempts to connect these two data types under a different structure — a decentralized approach to data management. A data mesh challenges the idea of the traditional centralization of data into a single big storage platform.
What are the four principles of a data mesh, and what problems do they solve?
A data mesh is technology agnostic and underpins four main principles described in-depth in this blog post by Zhamak Dehghani. The four data mesh principles aim to solve major difficulties that have plagued data and analytics applications for a long time. As a result, learning about them and the problems they were created to tackle is important.
Domain-oriented decentralized data ownership and architecture
This principle means that each organizational data domain (i.e., customer, inventory, transaction domain) takes full control of its data end to end. Indeed, one of the structural weaknesses of centralized data stores is that the people who manage the data are functionally separate from those who use it. As a result, the notion of storing all data together within a centralized platform creates bottlenecks where everyone is mainly dependent on a centralized “data team” to manage, leading to a lack of data ownership. Additionally, moving data from multiple data domains to a central data store to power analytics workloads can be time consuming. Moreover, scaling a centralized data store can be complex and expensive as data volumes increase.
There is no centralized team managing one central data store in a data mesh architecture. Instead, a data mesh entrusts data ownership to the people (and domains) who create it. Organizations can have data product managers who control the data in their domain. They’re responsible for ensuring data quality and making data available to those in the business who might need it. Data consistency is ensured through uniform definitions and governance requirements across the organization, and a comprehensive communication layer allows other teams to discover the data they need. Additionally, the decentralized data storage model reduces the time to value for data consumers by eliminating the need to transport data to a central store to power analytics. Finally, decentralized systems provide more flexibility, are easier to work on in parallel, and scale horizontally, especially when dealing with large datasets spanning multiple clouds.
Data as a product
This principle can be summarized as applying product thinking to data. Product thinking advocates that organizations must treat data with the same care and attention as customers. However, because most organizations think of data as a by-product, there is little incentive to package and share it with others. For this reason, it is not surprising that 87% of data science projects never make it to production.
Data becomes a first-class citizen in a data mesh architecture with its development and operations teams behind it. Building on the principle of domain-oriented data ownership, data product managers release data in their domains to other teams in the form of a “product.” Product thinking recognizes the existence of both a “problem space” (what people require) and a “solution space” (what can be done to meet those needs). Applying product thinking to data will ensure the team is more conscious of data and its use cases. It entails putting the data’s consumers at the center, recognizing them as customers, understanding their wants, and providing the data with capabilities that seamlessly meet their demands. It also answers questions like “what is the best way to release this data to other teams?” “what do data consumers want to use the data for?” and “what is the best way to structure the data?”
Self-serve data infrastructure as a platform
The principle of creating a self-serve data infrastructure is to provide tools and user-friendly interfaces so that generalist developers (and non-technical people) can quickly get access to data or develop analytical data products speedily and seamlessly. In a recent McKinsey survey, organizations reported spending up to 80% of their data analytics project time on repetitive data pipeline setup, which ultimately slowed down the productivity of their data teams.
The idea of the self-serve data infrastructure as a platform is that there should be an underlying infrastructure for data products that the various business domains can leverage in an organization to get to the work of creating the data products rapidly. For example, data teams should not have to worry about the underlying complexity of servers, operating systems, and networking. Marketing teams should have easy access to the analytical data they need for campaigns. Furthermore, the self-serve data infrastructure should include encryption, data product versioning, data schema, and automation. A self-service data infrastructure is critical to minimizing the time from ideation to a working data-driven application.
Federated computational governance
This principle advocates that data is governed where it is stored. The problem with centralized data platforms is that they do not account for the dynamic nature of data, its products, and its locations. In addition, large datasets can span multiple regions, each having its own data laws, privacy restrictions, and governing institutions. As a result, implementing data governance in this centralized system can be burdensome.
The data mesh more readily acknowledges the dynamic nature of data and allows for domains to designate the governing structures that are most suitable for their data products. Each business domain is responsible for its data governance and security, and the organization can set up general guiding principles to help keep each domain in check.
While it is prescriptive in many ways about how organizations should leverage technology to implement data mesh principles, perhaps the more significant implementation challenge is how that data flows between business domains.
Why Are Event Streams a Good Fit for Building a Data Mesh?
Event streams are a continuous flow of “events” known as data points that flow from systems that generate data to systems that consume that data for different workloads. In our online store example, when a customer places an order, that “order event” is propagated to the various consumers who listen to that event. The consumer could be a checkout service to process the order, an email service that sends out confirmation emails, or an analytics service carrying out real-time customer order behaviors.
Event streams offer the best option for building a data mesh, mainly when the data involved is used by multiple teams with unique needs across an organization. Because event streams are published in real time, streams enable immediate data propagation across the data mesh. Additionally, event streams are persisted and replayable, so they let you capture both real-time and historical data with one infrastructure. Finally, because the stored events don’t change, they make for a great source of record, which is helpful for data governance.
Three common streaming patterns in a data mesh
In our work with Striim customers, we tend to see three common streaming patterns in a data mesh.
In the first pattern, data is streamed from legacy systems to create new data products on a self-service infrastructure (commonly on a public cloud). For example, medical records data can be streamed from on-premise EHR (electronic health records) systems to a real-time analytics system like GoogleBigQuery, to feed cloud applications used by doctors. In the meantime, operational monitoring applications on the data pipeline help to ensure that pipelines are operating as expected.

In the second pattern, data is also consumed as it moves along the pipeline. Data is processed (e.g. by continuous queries or window-based views) to create “data as a product applications”. For example, a financial institution may build a fraud detection application that analyzes streaming data to identify potential fraud in real time.

Once you have a data product (e.g. freshly analyzed data), you can share it with another data product (e.g. the original data source or day-to-day business applications like Salesforce). This pattern, also known as reverse ETL, enables companies to have actionable information at their points of engagement, allowing for more intelligent interactions.

How to build a data mesh with event streams
To build a data mesh, you need to understand the different components (and patterns) that make up the enterprise data mesh architecture. In this article, Eric Broda gives a detailed overview of data mesh architectural patterns, bringing much-needed clarity to the “how” of a data mesh.

- Data Product APIs: This is the communication layer that makes data within a data product accessible via a contract that is consistent, uniform, and compliant to industry-standard specifications (REST API, GraphQL, MQTT, gRPC).
- Change Data Capture: This is used by an enterprise data mesh to track when data changes in a database. These database transaction changes are captured as “events.”
- Event Streaming Backbone: This concept is used to communicate CDC (Change Data Capture) events and other notable events (for example, an API call to the Data Mesh) to interested consumers (within and between Data Products) in an enterprise data mesh.
- Enterprise Data Product Catalog: This repository allows developers and users to view metadata about data products in the enterprise data mesh.
- Immutable Change/Audit Log: This retains data changes within the enterprise data mesh for future audit and governance purposes.
Still building on our e-commerce example, let’s walk through how these components could operate in a real-world data mesh scenario. For example, say our retail company has both a brick-and-mortar and online presence, but they lack a single source of truth regarding inventory levels. Disjointed systems in their on-premises data center can result in disappointing customer experiences. For example, customers shopping online may be frustrated to discover out-of-stock items that are actually available in their local store.
The retailer’s goal is to move towards an omnichannel, real-time customer experience, where customers can get a seamless experience no matter where (or when) they place their order. In addition, the retailer needs real-time visibility into inventory, to maintain optimal inventory levels at any point in time (including peak shopping seasons like Black Friday/Cyber Monday).
A data mesh suits this use case perfectly, and allows them to keep their on-premises data center running without disruption. Here’s how they can build a data mesh with Striim’s unified streaming and integration platform.
A data mesh in practice, using Striim

- Operational applications update data in the on-premises inventory, pricing, and catalog databases (e.g. when an online order is placed, the appropriate database is updated)
- Striim’s change data capture (CDC) reader continuously reads the operational database transaction logs, creating database change streams that can be persisted and replayed via a native integration with Kafka
- Striim performs in-memory processing of the event streams, allowing for detection and transformation of mismatched data (e.g. mismatched timestamp fields). Data is continuously synced and validated. Furthermore, Striim automatically detects schema changes in the source databases, either propagating them or alerting users of an issue. All this happens with sub-second latency to ensure that any consumer of data in the mesh has fresh and accurate data.
- Events are streamed to a unified data layer in the cloud, to both lake storage and an inventory database, with the flexibility to add any number of self-service systems (streaming data consumers) to provide an optimal customer experience and support real-time decision-making. So an online customer who wants to pick up an item at their local store can do so without a hitch. A returning customer can be offered a personalized coupon to encourage them to add more items to their order.
- The retail company can integrate Striim with a solution like Confluent’s schema catalog, making it easier to classify, organize, and find event streams
Use Striim as the Event Ingestion and Streaming Backbone of Your Data Mesh
A data mesh unlocks endless possibilities for organizations for various workloads, including analytics and building data-intensive applications. Event streams offer the best communication medium for implementing a data mesh. They provide efficient data access to all data consumers and bridge the operational/analytical divide, giving batch and streaming users a real-time, fast, and consistent view of data.
Striim has all the capabilities to build a data mesh using event streams, as shown above. Striim makes it easy to create new streams for data product owners with a simple streaming SQL query language and role-based access to streams. Additionally, Striim provides real-time data integration, connecting over 150 sources and targets across hybrid and multi-cloud environments.
Stream Data from PostgreSQL to Google BigQuery with Striim Cloud – Part 2

Tutorial
Stream Data from PostgreSQL to Google BigQuery with Striim Cloud – Part 2
Use Striim Cloud to stream CDC data securely from PostgreSQL database into Google BigQuery
Benefits
Operational Analytics
Visualize real time data with Striim’s powerful Analytic Dashboard
Capture Data Updates in real time
Use Striim’s postgrescdc reader for real time data updates
Build Real-Time Analytical ModelsUse dbt to build Real-Time analytical and ML models
On this page
Overview
In part 1 of PostgreSQL to Bigquery streaming, we have shown how data can be securely replicated between Postgres database and Bigquery. In this
recipe we will walk you through a Striim application capturing change data from postgres database and replicating to bigquery for real time visualization.
In addition to CDC connectors, Striim has hundreds of automated adapters for file-based data (logs, xml, csv), IoT data (OPCUA, MQTT), and applications such as Salesforce and SAP. Our SQL-based stream processing engine makes it easy to
enrich and normalize data before it’s written to Snowflake.
Traditionally Data warehouses that required data to be transferred use batch processing but with Striim’s streaming platform data can be replicated in real-time efficiently with added cost.
Data loses its value over time and businesses need to be updated with most recent data in order to make the right decisions that are vital to overall growth.
In this tutorial, we’ll walk you through how to create a replica slot to stream change data from postgres tables to bigquery and use the in-flght data to generate analytical dashboards.
Core Striim Components
PostgreSQL CDC: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
Continuous Query : Striim Continuous queries are are continually running SQL queries that act on real-time data and may be used to filter, aggregate, join, enrich, and transform events.
Window: A window bounds real-time data by time, event count or both. A window is required for an application to aggregate or perform calculations on data, populate the dashboard, or send alerts when conditions deviate from normal parameters.
BigQueryWriter: Striim’s BigQueryWriter writes the data from various supported sources into Google’s BigQuery data warehouse to support real time data warehousing and reporting.
Step 1: Create a Replication Slot
For this recipe, we will host our app in Striim Cloud but there is always a free trial to visualize the power of Striim’s Change Data Capture.
For CDC application on a postgres database, make sure the following flags are enabled for the postgres instance:
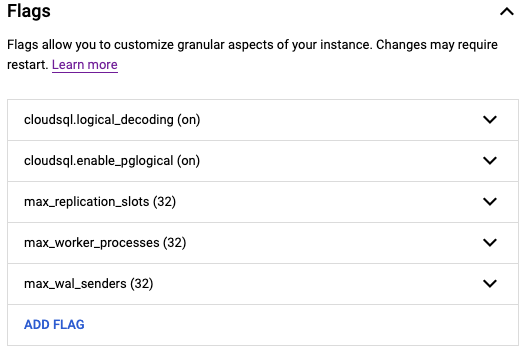
Create a user with replication attribute by running the following command on google cloud console:
CREATE USER replication_user WITH REPLICATION IN ROLE cloudsqlsuperuser LOGIN PASSWORD ‘yourpassword’;
Follow the steps below to set up your replication slot for change data capture:
Create a logical slot with wal2json plugin.
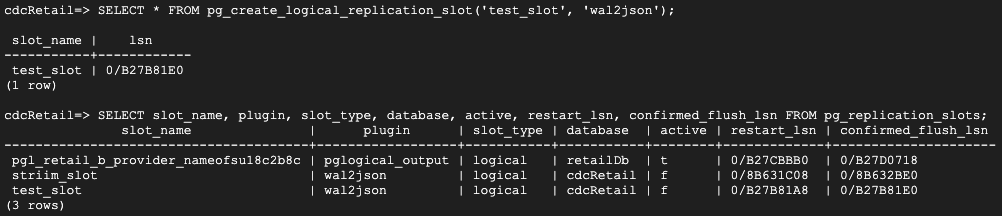
Create table that needs to be replicated for capturing changes in data. I have used PgAdmin, which is a UI for postgres database management system to create my table and insert data into it.
Step 2: Configure CDC app on Striim Server
Follow the steps described in part 1 for creating an app from scratch. You can find the TQL file for this app in our git repository.
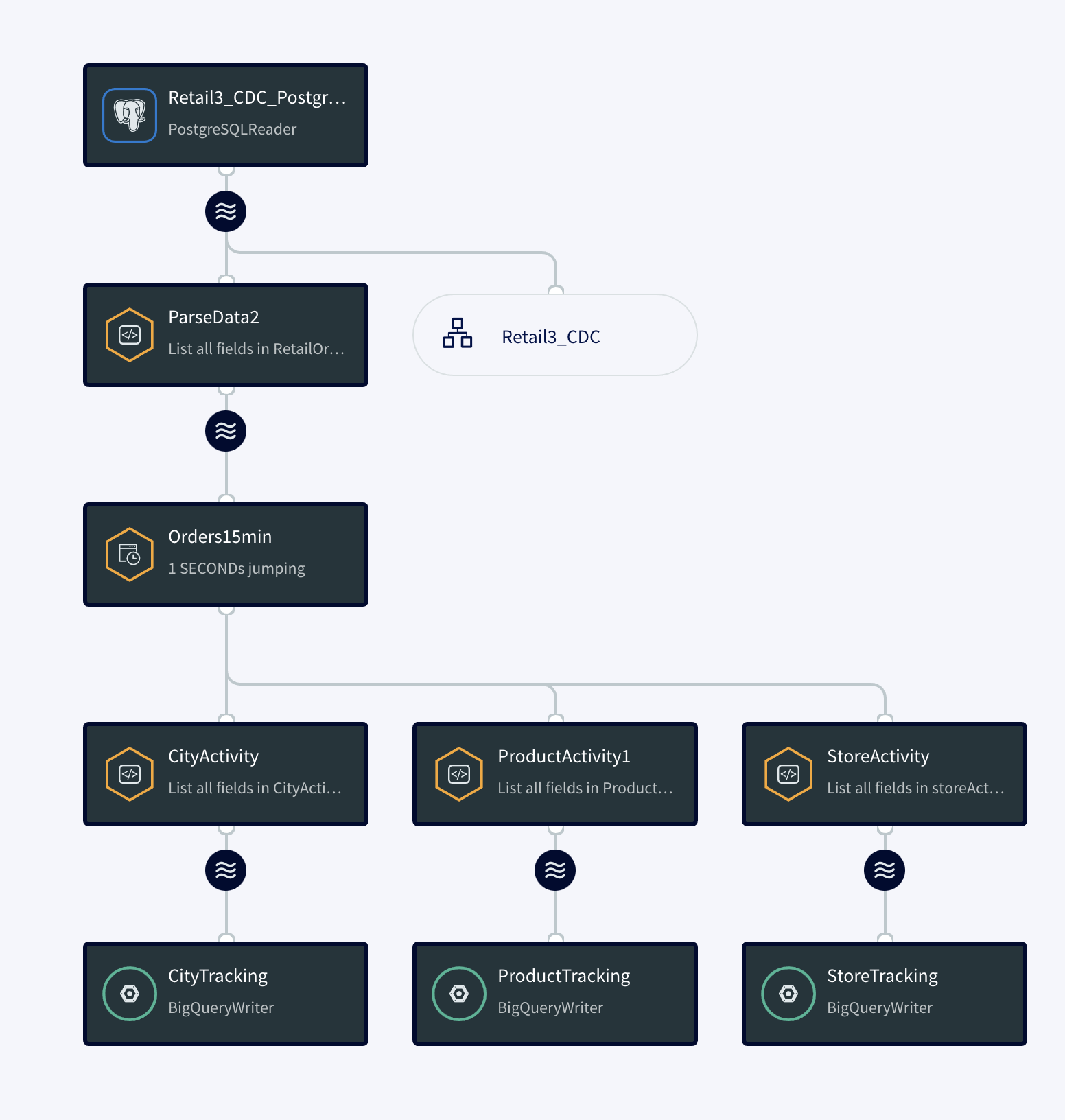
The diagram below simplifies each component of the app.
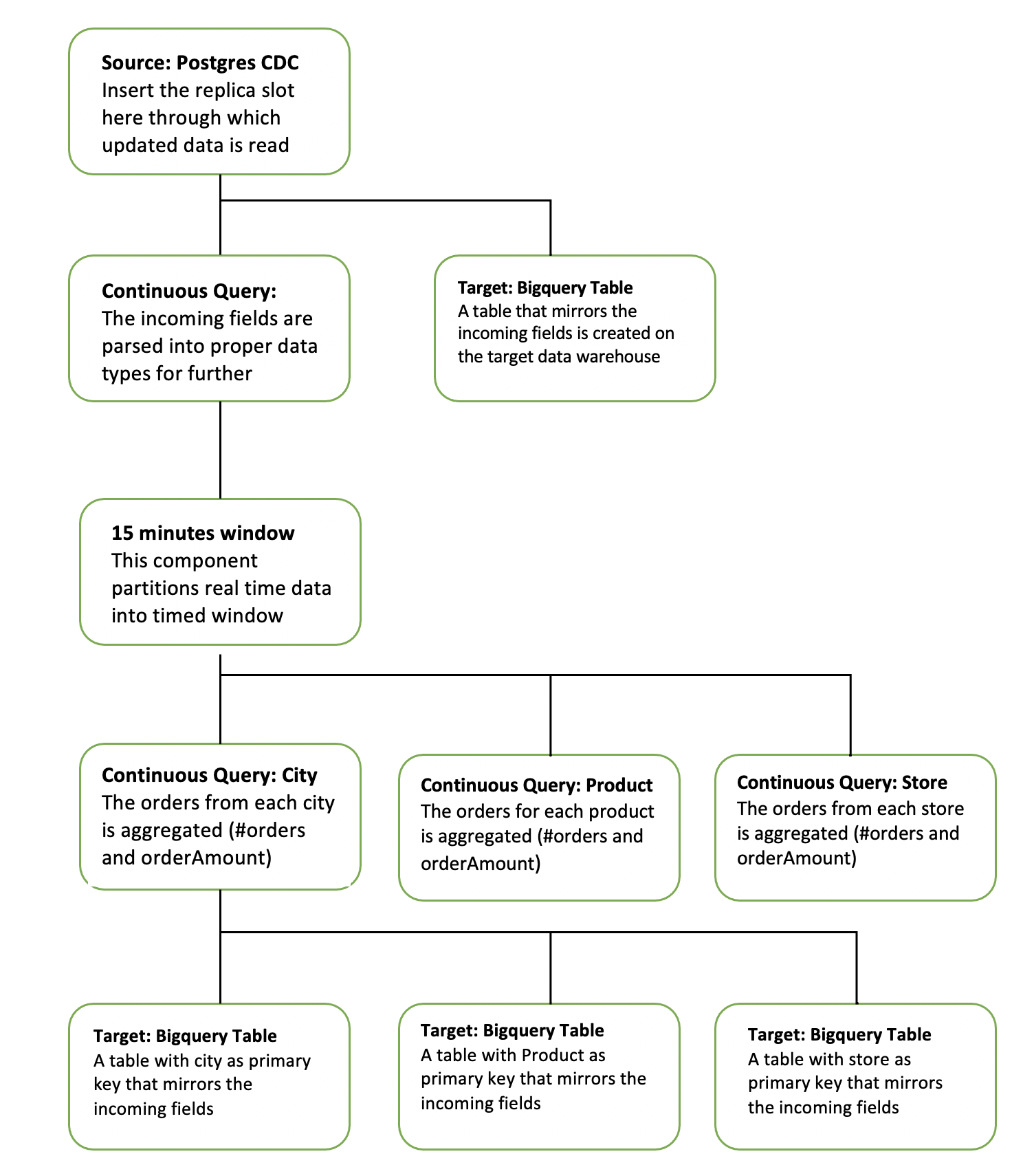
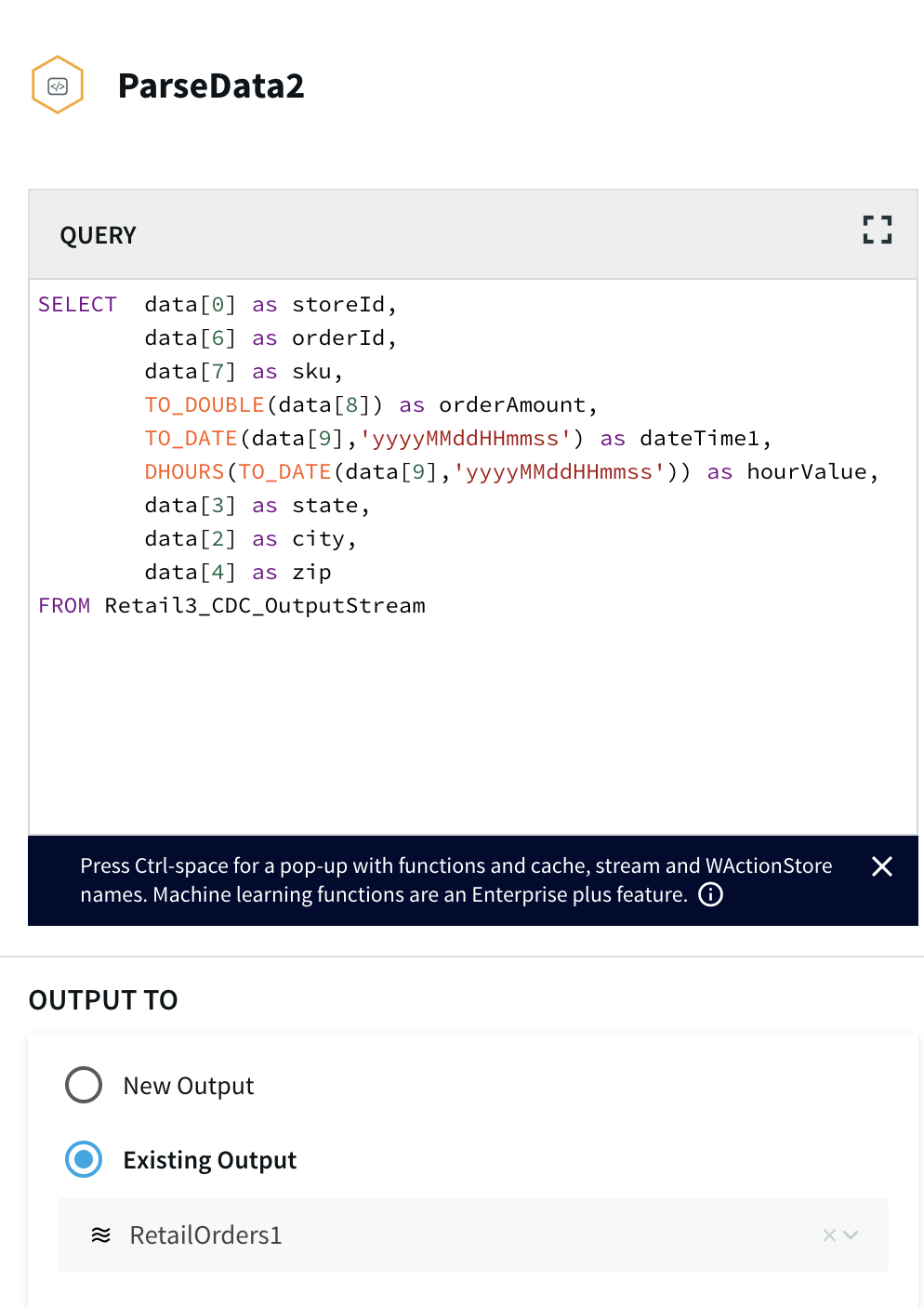
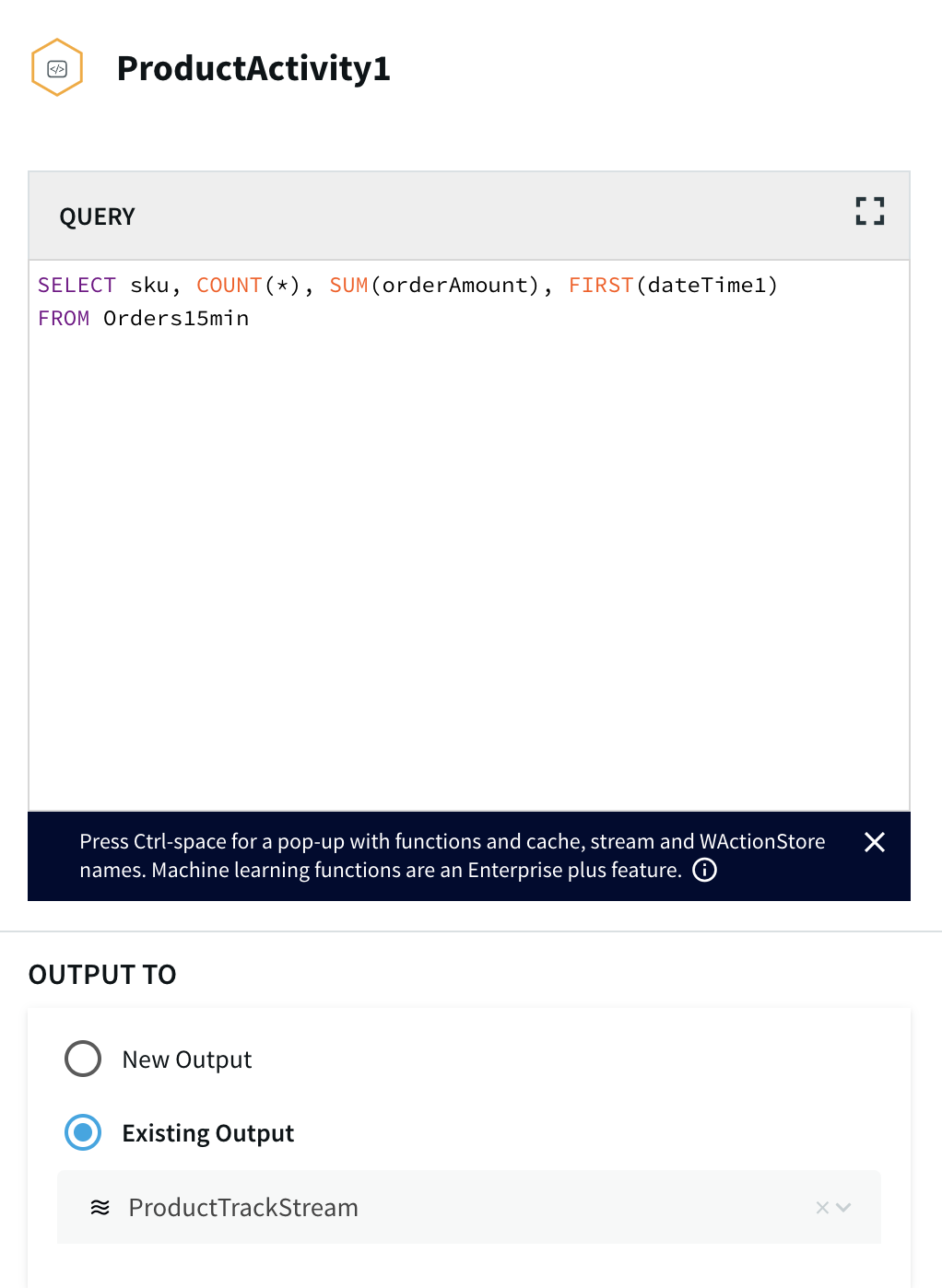
The continuous query is a sql-based query that is used to query the database.The following queries are for ParseData2 where data is transformed into proper data type for further processing and ProductActivity1 where product data is aggregated to derive useful insights about each product.
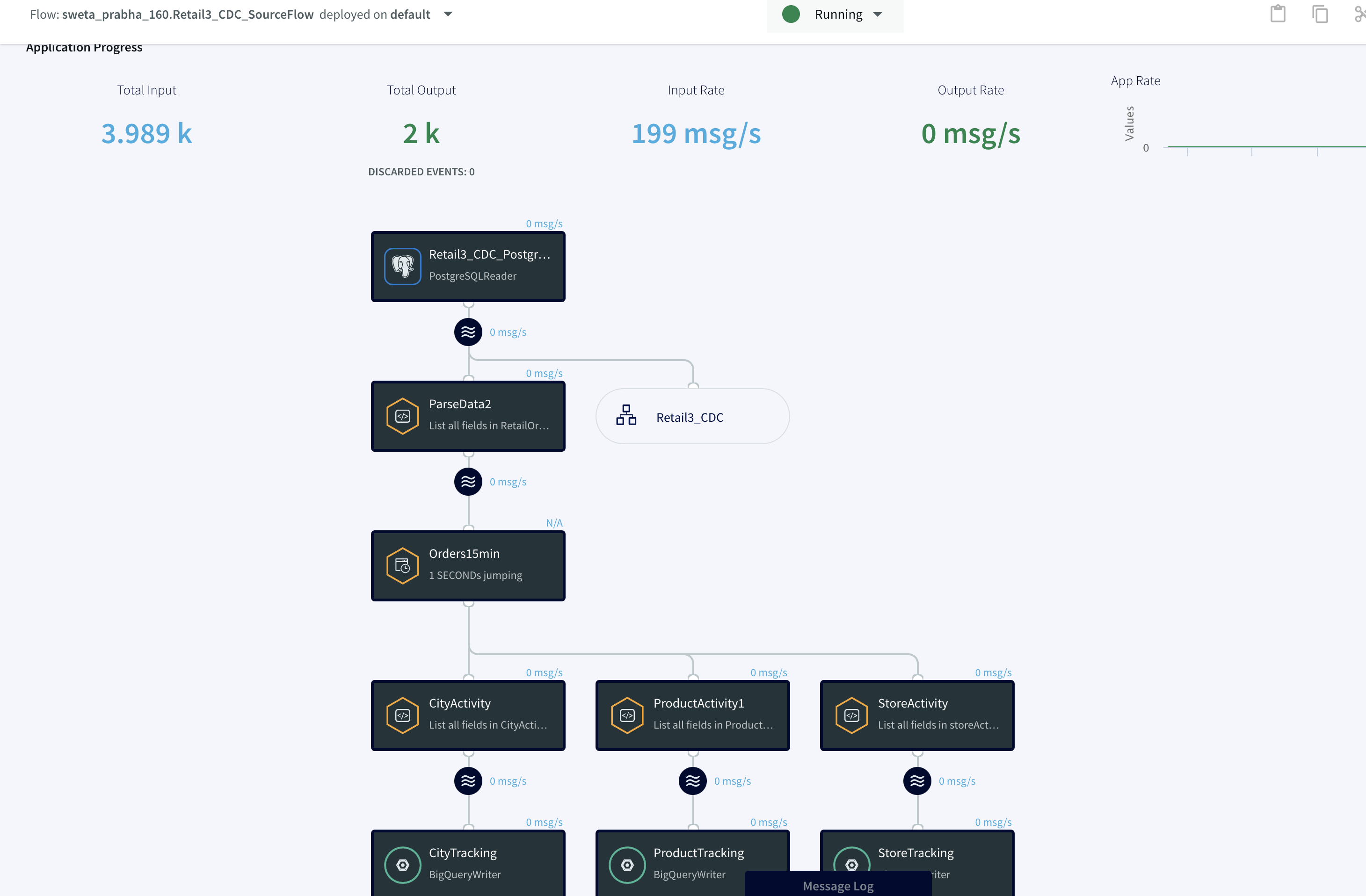
Step 3: Deploy and Run the Striim app for Fast Data Streaming
In this step you will deploy and run the final app to visualize the power of Change Data Capture in Striim’s next generation technology.
Setting Up the Postgres to BigQuery Streaming Application
Step 1: Follow this recipe to create a Replication Slot and user for Change Data Capture
The replication user reads change data from your source database and replicates it to the target in real-time.
Step 2: Download the dataset and TQL file from our github repo and set up your Postgres Source and BigQuery Target.
You can find the csv dataset in our github repo. Set up your BigQuery dataset and table that will act as a target for the streaming application
Step 3: Configure source and target components in the app
Configure the source and target components in the striim app. Please follow the detailed steps from our recipe.
Step 4: Run the streaming app
Deploy and run real-time data streaming app
Wrapping Up: Start Your Free Trial
Our tutorial showed you how easy it is to capture change data from PostgreSQL to Google BigQuery, a leading cloud data warehouse. By constantly moving your data into BigQuery, you could now start building analytics or machine learning models on top, all
with minimal impact to your current systems. You could also start ingesting and normalizing more datasets with Striim to fully take advantage of your data when combined with the power of BigQuery..
As always, feel free to reach out to our integration experts to schedule a demo, or try Striim for free here.
Tools you need

Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.

Google BigQuery
BigQuery is a serverless, highly scalable multicloud data warehouse.
Striim Cloud

The 7 Data Replication Strategies You Need to Know

What is
Data replication involves creating copies of data and storing them on different servers or sites. This results in multiple, identical copies of data being stored in different locations.
makes available on multiple sites, and in doing so, offers various benefits.
First of all, it enables better . If a system at one site goes down because of hardware issues or other problems, users can access stored at other nodes. Furthermore, allows for improved . Since is replicated to multiple sites, IT teams can easily restore deleted or corrupted .
also allows faster access to . Since is stored in various locations, users can retrieve from the closest servers and benefit from reduced latency. Also, there’s a much lower chance that any one server will become overwhelmed with user queries since can be retrieved from multiple servers. also supports improved , by allowing to be continuously replicated from a production database to a used by business intelligence teams.
Replicating to the
Replicating to the offers additional benefits. is kept safely off-site and won’t be damaged if a major disaster, such as a flood or fire, damages on-site infrastructure. is also cheaper than deploying on-site centers. Users won’t have to pay for hardware or maintenance.

Replicating to the is a safer option for smaller businesses that may not be able to afford full-time cybersecurity staff. providers are constantly improving their network and physical security. Furthermore, sites provide users with on-demand scalability and flexibility. can be replicated to servers in different geographical locations, including in the nearby region.
R Challenges
technologies offer many benefits, but IT teams should also keep in mind several challenges.
First of all, keeping at leads to rising and processing costs. In addition, setting up and maintaining a system often requires assigning a dedicated internal team.
Replicating across multiple copies requires deploying new processes and adding more traffic to the network. Finally, managing multiple updates in a distributed environment may cause to be out of sync on occasion. Database administrators need to ensure consistency in processes.
Data Replication Methods
The data replication strategy you choose is crucial as it impacts how and when your data is loaded from source to replica and how long it takes. An application whose database updates frequently wouldn’t want a data replication strategy that could take too long to reproduce the data in the replicas. Similarly, an application with less frequent updates wouldn’t require a data replication strategy that reproduces data in the replicas several times a day.
Log-Based Incremental Replication
Some databases allow you to store transaction logs for a variety of reasons, one of which is for easy recovery in case of a disaster. However, in log-based incremental replication, your replication tool can also look at these logs, identify changes to the data source, and then reproduce the changes in the replica data destination (e.g., database). These changes could be INSERT, UPDATE, or DELETE operations on the source database.
The benefits of this data replication strategy are:
- Because log-based incremental replication only captures row-based changes to the source and updates regularly (say, once every hour), there is low latency when replicating these changes in the destination database.
- There is also reduced load on the source because it streams only changes to the tables.
- Since the source consistently stores changes, we can trust that it doesn’t miss vital business transactions.
- With this data replication strategy, you can scale up without worrying about the additional cost of processing bulkier data queries.
Unfortunately, a log-based incremental replication strategy is not without its challenges:
- It’s only applicable to databases, such as MongoDB, MySQL, and PostgreSQL, that support binary log replication.
- Since each of these databases has its own log formats, it’s difficult to build a generic solution that covers all supported databases.
- In the case where the destination server is down, you have to keep the logs up to date until you restore the server. If not, you lose crucial data.
Despite its challenges, log-based incremental replication is still a valuable data replication strategy because it offers fast, secure, and reliable replication for data storage and analytics.
Key-Based Incremental Replication
As the name implies, key-based replication involves replicating data through the use of a replication key. The replication key is one of the columns in your database table, and it could be an integer, timestamp, float, or ID.
Key-based incremental replication only updates the replica with the changes in the source since the last replication job. During data replication, your replication tool gets the maximum value of your replication key column and stores it. During the next replication, your tool compares this stored maximum value with the maximum value of your replication key column in your source. If the stored maximum value is less than or equal to the source’s maximum value, your replication tool replicates the changes. Finally, the source’s maximum value becomes the stored value.
This process is repeated for every replication job that is key-based, continually using the replication key to spot changes in the source. This data replication strategy offers similar benefits as log-based data replication but comes with its own limitations:
- It doesn’t identify delete operations in the source. When you delete a data entry in your table, you also delete the replication key from the source. So the replication tool is unable to capture changes to that entry.
- There could be duplicate rows if the records have the same replication key values. This occurs because key-based incremental replication also compares values equal to the stored maximum value. So it duplicates the record until it finds another record of greater replication key.
In cases where log-based replication is not feasible or supported, key-based replication would be a close alternative. And knowing these limitations would help you better tackle data discrepancies where they occur.
Full Table Replication
Unlike the incremental data replication strategies that update based on changes to logs and the replication key maximum value, full table replication replicates the entire database. It copies everything: every new, existing, and updated row, from source to destination. It’s not concerned with any change in the source; whether or not some data changes, it replicates it.
The full table data replication strategy is useful in the following ways:
- You’re assured that your replica is a mirror image of the source and no data is missing.
- Full table replication is especially useful when you need to create a replica in another location so that your application’s content loads regardless of where your users are situated.
- Unlike key-based replication, this data replication strategy detects hard deletes to the source.
However, replicating an entire database has notable downsides:
- Because of the high volume of data replicated, full-table replication could take longer, depending on the strength of your network.
- It also requires higher processing power and can cause latency duplicating that amount of data at every replication job.
- The more you use full table replication to replicate to the same database, the more rows you use and the higher the cost to store all that data.
- Low latency and high processing power while replicating data may lead to errors during the replication process.
Although full table replication isn’t an efficient way to replicate data, it’s still a viable option when you need to recover deleted data or there aren’t any logs or suitable replication keys.
Snapshot Replication
Snapshot replication is the most common data replication strategy; it’s also the simplest to use. Snapshot replication involves taking a snapshot of the source and replicating the data at the time of the snapshot in the replicas.
Because it’s only a snapshot of the source, it doesn’t track changes to the source database. This also affects deletes to the source. At the time of the snapshot, the deleted data is no longer in the source. So it captures the source as is, without the deleted record.
For snapshot replication, we need two agents:
- Snapshot Agent: It collects the files containing the database schema and objects, stores them, and records every sync with the distribution database on the Distribution Agent.
- Distribution Agent: It delivers the files to the destination databases.
Snapshot replication is commonly used to sync the source and destination databases for most data replication strategies. However, you may use it on its own, scheduling it according to your custom time.
Just like the full table data replication strategy, snapshot replication may require high processing power if the source has a considerably large dataset. But it is useful if:
- The data you want to replicate is small.
- The source database doesn’t update frequently.
- There are a lot of changes in a short period, such that transactional or merge replication wouldn’t be an efficient option.
- You don’t mind having your replicas being out of sync with your source for a while.
Transactional Replication
In transactional replication, you first duplicate all existing data from the publisher (source) into the subscriber (replica). Subsequently, any changes to the publisher replicate in the subscriber almost immediately and in the same order.
It is important to have a snapshot of the publisher because the subscribers need to have the same data and database schema as the publisher for them to receive consistent updates. Then the Distribution Agent determines the regularity of the scheduled updates to the subscriber.
To perform transactional replication, you need the Distribution Agent, Log Reader Agent, and Snapshot Agent.
- Snapshot Agent: It works the same as the Snapshot Agent for snapshot replication. It generates all relevant snapshot files.
- Log Reader Agent: It observes the publisher’s transaction logs and duplicates the transactions in the distribution database.
- Distribution Agent: It copies the snapshot files and transaction logs from the distribution database to the subscribers.
- Distribution database: It aids the flow of files and transactions from the publisher to the subscribers. It stores the files and transactions until they’re ready to move to the subscribers.
Transactional replication is appropriate to use when:
- Your business can’t afford downtime of more than a few minutes.
- Your database changes frequently.
- You want incremental changes in your subscribers in real time.
- You need up-to-date data to perform analytics.
In transactional replication, subscribers are mostly used for read purposes, and so this data replication strategy is commonly used when servers only need to talk to other servers.
Merge Replication
Merge replication combines (merges) two or more databases into one so that updates to one (primary) database are reflected in the other (secondary) databases. This is one key trait of merge replication that differentiates it from the other data replication strategies. A secondary database may retrieve changes from the primary database, receive updates offline, and then sync with the primary and other secondary databases once back online.
In merge replication, every database, whether it’s primary or secondary, can make changes to your data. This can be useful when one database goes offline and you need the other to operate in production, then get the offline database up to date once it’s back online.
To avoid data conflicts that may arise from allowing modifications from secondary databases, merge replication allows you to configure a set of rules to resolve such conflicts.
Like most data replication strategies, merge replication starts with taking a snapshot of the primary database and then replicating the data in the destination databases. This means that we also begin the merge replication process with the Snapshot Agent.
Merge replication also uses the Merge Agent, which commits or applies the snapshot files in the secondary databases. The Merge Agent then reproduces any incremental updates in the other databases. It also identifies and resolves all data conflicts during the replication job.
You may opt for merge replication if:
- You’re less concerned with how many times a data object changes but more interested in its latest value.
- You need replicas to update and reproduce the updates in the source and other replicas.
- Your replica requires a separate segment of your data.
- You want to avoid data conflicts in your database.
Merge replication remains one of the most complex data replication strategies to set up, but it can be valuable in client-server environments, like mobile apps or applications where you need to incorporate data from multiple sites.
Bidirectional Replication
Bidirectional replication is one of the less common data replication strategies. It is a subset of transactional replication that allows two databases to swap their updates. So both databases permit modifications, like merge replication. However, for a transaction to be successful, both databases have to be active.

Here, there is no definite source database. Each database may be from the same platform (e.g., Oracle to Oracle) or from separate platforms (e.g., Oracle to MySQL). You may choose which rows or columns each database can modify. You may also decide which database is a higher priority in case of record conflicts, i.e., decide which database updates are reflected first.
Bidirectional replication is a good choice if you want to use your databases to their full capacity and also provide disaster recovery.
Your Data Replication Strategy Shouldn’t Slow You Down: Try Striim
Regardless of your type of application, there’s a data replication strategy that best suits your business needs. Combine any data replication strategies you want. Just ensure that the combination offers a more efficient way to replicate your databases according to your business objectives.
Every data replication strategy has one cost in common: the time it takes. Few businesses today can afford to have their systems slowed down by data management, so the faster your data replicates, the less negative impact it will have on your business.
Replicating your database may be time-consuming, and finding the right data replication tool to help speed up and simplify this process, while keeping your data safe, can be beneficial to your business.

For fast, simple, and reliable data replication, Striim is your best bet. Striim provides real-time data replication by extracting data from databases using log-based change data capture and replicating it to targets in real time. Regardless of where your data is, Striim gets your data safely to where you need it to be and shows you the entire process, from source to destination.
Schedule a demo and we’ll give you a personalized walkthrough or try Striim at production-scale for free! Small data volumes or hoping to get hands on quickly? At Striim we also offer a free developer version.
Introducing Striim Cloud – Data Streaming and Integration as a Service

Since announcing our Series C fundraising led by Goldman Sachs we doubled down on our mission to enable companies to power their decisions in real-time, and after a year in private preview, collecting feedback from customers, testing workloads and tweaking and adjusting, we’re thrilled to announce the public launch of Striim Cloud: the industry’s first and only unified data streaming and integration fully managed service. Striim Cloud was uniquely designed to address the challenges of enterprise data streaming with an emphasis on our best-in-market change data capture, fully dedicated infrastructure (no shared data for sensitive environments), and seamless interoperability with on-premise and self-managed versions of Striim.

Unlike other solutions in the market, Striim Cloud leverages over 5 years of experience gained from delivering our self-managed, massively scalable streaming platform to over 100 enterprise customers and 2500 deployments in 6 continents. Striim is also led by the executive team behind GoldenGate Software.
The power of Striim Cloud is also a result of collaborating closely with incredible partners like Microsoft. “Microsoft is committed to making migration to Azure as smooth as possible, while paving the way for continuous innovation for our customers. Our goal is to build technology that empowers today’s innovators to unleash the power of their data and explore possibilities that will improve their businesses and our world,” said Rohan Kumar, Corporate Vice President, Azure Data at Microsoft. “We are pleased to work with Striim to provide our customers with a fast way to replicate their data to the Azure platform and gain mission-critical insights into data from across the organization.”
With that collaboration, we’ve made Striim Cloud available with consumption-based pricing on the Azure marketplace. Microsoft Azure customers can leverage existing investments in the Azure ecosystem to power digital transformation initiatives with real-time data.
With Striim Cloud we’re offering unprecedented speed and simplicity with the following value-adds:
- Fast setup with schema conversion and initial load into your analytics platforms
- Low impact change data capture built by the team from GoldenGate
- Meet fast data SLAs (sub-second delivery) with fast data streaming and end-to-end lag monitoring
- Low cost of ownership with fully managed, fully dedicated cloud infrastructure by Striim
- Enterprise-level security with encrypted data at-rest and in-flight
- Consumption-based pricing; pay only for the data you successfully move from source to target and the compute you need in that moment
But don’t take my word for it, sign up for a free trial and start powering your decisions with real-time data.
Building a Multi-Cloud Data Fabric for Real-Time Analytics


Data is increasingly siloed, making it harder for companies to extract the most value from their data. This is compounded by the fact that over 90% of companies plan on having hybrid cloud and or multi-cloud operations by 2022.
Watch this on-demand webinar with James Serra (Data Platform Architecture Lead at EY) where we demystify building a multi-cloud data environment for operations and real-time analytics. We cover the following topics:
- Pros and cons of multi-cloud vs doubling down on a single cloud
- Enterprise data patterns such as Data Fabric, Data Mesh, and The Modern Data Stack
- Data ingestion and data transformation in a multi-cloud/hybrid cloud environment
- Comparison of data warehouses (Snowflake, Synapse, Redshift, BigQuery) for real-time workloads
Oracle Change Data Capture – An Event-Driven Architecture for Cloud Adoption

Tutorial
Oracle Change Data Capture – An Event-Driven Architecture for Cloud Adoption
How to replace batch ETL by event-driven distributed stream processing
Benefits
Operational Analytics
Use non-intrusive CDC to Kafka to create persistent streams that can be accessed by multiple consumers and automatically reflect upstream schema changes
Empower Your TeamsGive teams across your organization a real-time view of your Oracle database transactions.Get Analytics-Ready DataGet your data ready for analytics before it lands in the cloud. Process and analyze in-flight data with scalable streaming SQL.
On this page
Overview
All businesses rely on data. Historically, this data resided in monolithic databases, and batch ETL processes were used to move that data to warehouses and other data stores for reporting and analytics purposes. As businesses modernize, looking to the cloud for analytics, and striving for real-time data insights, they often find that these databases are difficult to completely replace, yet the data and transactions happening within them are essential for analytics. With over 80% of businesses noting that the volume & velocity of their data is rapidly increasing, scalable cloud adoption and change data capture from databases like Oracle, SQLServer, MySQL and others is more critical than ever before. Oracle change data capture is specifically one area where companies are seeing an influx of modern data integration use cases.
To resolve this, more and more companies are moving to event-driven architectures, because of the dynamic distributed scalability which makes sharing large volumes of data across systems possible.
In this post we will look at an example which replaces batch ETL by event-driven distributed stream processing: Oracle change data capture events are extracted as they are created; enriched with in-memory, SQL-based denormalization; then delivered to the Mongodb to provide scalable, real-time, low-cost analytics, without affecting the source database. We will also look at using the enriched events, optionally backed by Kafka, to incrementally add other event-driven applications or services.

Continuous Data Collection, Processing, Delivery, and Analytics with the Striim Platform
Event-Driven Architecture Patterns
Most business data is produced as a sequence of events, or an event stream: for example, web or mobile app interactions, devices, sensors, bank transactions, all continuously generate events. Even the current state of a database is the outcome of a sequence of events.
Treating state as the result of a sequence of events forms the core of several event-driven patterns.
Event Sourcing is an architectural pattern in which the state of the application is determined by a sequence of events. As an example, imagine that each “event” is an incremental update to an entry in a database. In this case, the state of a particular entry is simply the accumulation of events pertaining to that entry. In the example below the stream contains the queue of all deposit and withdrawal events, and the database table persists the current account balances.

Imagine Each Event as a Change to an Entry in a Database
The events in the stream can be used to reconstruct the current account balances in the database, but not the other way around. Databases can be replicated with a technology called Change Data Capture (CDC), which collects the changes being applied to a source database, as soon as they occur by monitoring its change log, turns them into a stream of events, then applies those changes to a target database. Source code version control is another well known example of this, where the current state of a file is some base version, plus the accumulation of all changes that have been made to it.

The Change Log can be used to Replicate a Database
What if you need to have the same set of data for different databases, for different types of use? With a stream, the same message can be processed by different consumers for different purposes. As shown below, the stream can act as a distribution point, where, following the polygot persistence pattern, events can be delivered to a variety of data stores, each using the most suited technology for a particular use case or materialized view.

Streaming Events Delivered to a Variety of Data Stores
Event-Driven Streaming ETL Use Case Example
Below is a diagram of the Event-Driven Streaming ETL use case example:

Event-Driven Streaming ETL Use Case Diagram
-
Striim’s low-impact, real-time Oracle change data capture (CDC) feature is used to stream database changes (inserts, updates and deletes) from an Operational Oracle database into Striim
-
CDC Events are enriched and denormalized with Streaming SQL and Cached data, in order to make relevant data available together
-
Enriched, denormalized events are streamed to CosmosDB for real-time analytics
-
Enriched streaming events can be monitored in real time with the Striim Web UI, and are available for further Streaming SQL analysis, wizard-based dashboards, and other applications in the cloud. You can use Striim by signing up for free Striim Developer or Striim Cloud trial.
Striim can simultaneously ingest data from other sources like Kafka and log files so all data is streamed with equal consistency. Please follow the instructions below to learn how to build a Oracle CDC to NoSQL MongoDB real-time streaming application:
Step1: Generate Schemas in your Oracle Database
You can find the csv data file in our github repository. Use the following schema to create two empty tables in your source database:
The HOSPITAL_DATA table, containing details about each hospital would be used as a cache to enrich our real-time data stream.
Schema:
CREATE TABLE “<database name>”.“HOSPITAL_DATA”
(“PROVIDER_ID” VARCHAR2(10),
“HOSPITAL_NAME” VARCHAR2(50),
“ADDRESS” VARCHAR2(50),
“CITY” VARCHAR2(50),
“STATE” VARCHAR2(40),
“ZIP_CODE” VARCHAR2(10),
“COUNTY” VARCHAR2(40),
“PHONE_NUMBER” VARCHAR2(15), PRIMARY KEY (“PROVIDER_ID”));
Insert the data from this csv file to the above table.
The HOSPITAL_COMPLICATIONS_DATA contains details of complications in various hospitals. Ideally the data is streamed in real-time but for our tutorial, we will import csv data for CDC.
Schema:
CREATE TABLE <database name>.HOSPITAL_COMPLICATIONS_DATA (
COMPLICATION_ID NUMBER(10,0) NOT NULL,
PROVIDER_ID VARCHAR2(10) NULL,
MEASURE_NAME VARCHAR2(100) NULL,
MEASURE_ID VARCHAR2(40) NULL,
COMPARED_TO_NATIONAL VARCHAR2(50) NULL,
DENOMINATOR VARCHAR2(20) NULL,
SCORE VARCHAR2(20) NULL,
LOWER_ESTIMATE VARCHAR2(40) NULL,
HIGHER_ESTIMATE VARCHAR2(20) NULL,
FOOTNOTE VARCHAR2(400) NULL,
MEASURE_START_DT DATE NULL,
MEASURE_END_DT DATE NULL,
);
Step 2: Replacing Batch Extract with Real Time Streaming of CDC Order Events
Striim’s easy-to-use CDC wizards automate the creation of applications that leverage change data capture, to stream events as they are created, from various source systems to various targets. In this example, shown below, we use Striim’s OracleReader (Oracle Change Data Capture) to read the hospital incident data in real-time and stream these insert, update, delete operations, as soon as the transactions commit, into Striim, without impacting the performance of the source database. Configure your source database by entering the hostname, username, password and table names.

Step 3: NULL Value handling
The data contains “Not Available” strings in some of the rows. Striim can manipulate the data in real-time to convert it into Null values using a Continuous Query component. Use the following query to change “Not Available” strings to Null:
SELECT
t
FROM complication_data_stream t
MODIFY
(
data[5] = CASE WHEN TO_STRING(data[5]) == "Not Available" THEN NULL else TO_STRING(data[5]) END,
data[6] = CASE WHEN TO_STRING(data[6]) == "Not Available" THEN NULL else TO_STRING(data[6]) END,
data[7] = CASE WHEN TO_STRING(data[7]) == "Not Available" THEN NULL else TO_STRING(data[7]) END,
data[8] = CASE WHEN TO_STRING(data[8]) == "Not Available" THEN NULL else TO_STRING(data[8]) END
);
Step 4: Using Continuous Query for Data Processing
The hospital_complications_data has a column COMPARED_TO_NATIONAL that indicates how the particular complication compares to national average. We will process this data to generate a column called ‘SCORE_COMPARISON’ that is in the scale of GOOD, BAD, OUTLIER or NULL and is easier to read. If “Number of Cases too small”, then the SCORE_COMPARISON is “Outlier” and if “worse than national average”, then the SCORE_COMPARISON is BAD otherwise GOOD.
SELECT
CASE WHEN TO_STRING(data[4]) =="Not Available" or TO_STRING(data[4]) =="Number of Cases Too Small"
THEN putUserData(t, 'SCORE_COMPARISON', "OUTLIER")
WHEN TO_STRING(data[4]) =="Worse than the National Rate"
THEN putUserData(t, 'SCORE_COMPARISON', "BAD")
WHEN TO_STRING(data[4]) =="Better than the National Rate" OR TO_STRING(data[4]) =="No Different than the National Rate"
THEN putUserData(t, 'SCORE_COMPARISON', "GOOD")
ELSE putUserData(t, 'SCORE_COMPARISON', NULL)
END
FROM nullified_stream2 t;

Step 5: Utilizing Caches For Enrichment
Relational Databases typically have a normalized schema which makes storage efficient, but causes joins for queries, and does not scale well horizontally. NoSQL databases typically have a denormalized schema which scales across a cluster because data that is read together is stored together.

With a normalized schema, a lot of the data fields will be in the form of IDs. This is very efficient for the database, but not very useful for downstream queries or analytics without any meaning or context. In this example we want to enrich the raw Orders data with reference data from the SalesRep table, correlated by the Order Sales_Rep_ID, to produce a denormalized record including the Sales Rep Name and Email information in order to make analysis easier by making this data available together.
Since the Striim platform is a high-speed, low latency, SQL-based stream processing platform, reference data also needs to be loaded into memory so that it can be joined with the streaming data without slowing things down. This is achieved through the use of the Cache component. Within the Striim platform, caches are backed by a distributed in-memory data grid that can contain millions of reference items distributed around a Striim cluster. Caches can be loaded from database queries, Hadoop, or files, and maintain data in-memory so that joining with them can be very fast. In this example, shown below, the cache is loaded with a query on the SalesRep table using the Striim DatabaseReader.
First we will define a cache type from the console. Run the following query from your console.
CREATE TYPE HospitalDataType(
PROVIDER_ID String KEY,
HOSPITAL_NAME String,
ADDRESS String,
CITY String,
STATE String,
ZIP_CODE String,
COUNTY String,
PHONE_NUMBER String
);

Now, drag a DB Cache component from the list of Striim Components on the left and enter your database details. The table will be queried to join with the streaming data.


Query:
SELECT PROVIDER_ID,HOSPITAL_NAME,ADDRESS,CITY,STATE,ZIP_CODE,COUNTY,PHONE_NUMBER FROM QATEST2.HOSPITAL_DATA;
Step 6: Joining Streaming and Cache Data For Real Time Transforming and Enrichment With SQL
We can process and enrich data-in-motion using continuous queries written in Striim’s SQL-based stream processing language. Using a SQL-based language is intuitive for data processing tasks, and most common SQL constructs can be utilized in a streaming environment. The main differences between using SQL for stream processing, and its more traditional use as a database query language, are that all processing is in-memory, and data is processed continuously, such that every event on an input data stream to a query can result in an output.
This is the query we will use to process and enrich the incoming data stream:
SELECT data[1] as provider_id, data[2] as Measure_Name, data[3] as Measure_id,
t.HOSPITAL_NAME as hosp_name,
t.state as cache_state,
t.phone_number as cache_phone
FROM score_comparison_stream n, hospital_data_cache t where t.provider_id=TO_STRING(n.data[1]);

In this query, we enriched our streaming data using cache data about hospital details. The result of this query is to continuously output enriched (denormalized) events, shown below, for every CDC event that occurs for the HOSPITAL_COMPLICATIONS_DATA table. So with this approach we can join streams from an Oracle Change Data Capture reader with cached data for enrichment.
Step 7: Loading the Enriched Data to the Cloud for Real Time Analytics
Now the Oracle CDC (Oracle change data capture) data, streamed and enriched through Striim, can be stored simultaneously in NoSQL Mongodb using Mongodb writer. Enter the connection url for your mongodb Nosql database in the following format and enter your username, password and collections name.
mongodb+srv://<username>:<password><hostname>/

Step 8: Running the Oracle CDC to Mongodb streaming application
Now that the striim app is configured, you will deploy and run the CDC application. You can also download the TQL file (passphrase: striimrecipes) from our github repository and configure your own source and targets. Import the csv file to HOSPITAL_COMPLICATIONS_DATA table on your source database after the striim app has started running. The Change data capture is streamed through the various components for enrichment and processing. You can click on the ‘eye’ next to each stream component to see the data in real-time.


Using Kafka for Streaming Replay and Application Decoupling
The enriched stream of order events can be backed by or published to Kafka for stream persistence, laying the foundation for streaming replay and application decoupling. Striim’s native integration with Apache Kafka makes it quick and easy to leverage Kafka to make every data source re-playable, enabling recovery even for streaming sources that cannot be rewound. This also acts to decouple applications, enabling multiple applications to be powered by the same data source, and for new applications, caches or views to be added later.
Streaming SQL for Aggregates
We can further use Striim’s Streaming SQL on the denormalized data to make a real time stream of summary metrics about the events being processed available to Striim Real-Time Dashboards and other applications. For example, to create a running count of each measure_id in the last hour, from the stream of enriched orders, you would use a window, and the familiar group by clause.
CREATE WINDOW IncidentWindow
OVER EnrichCQ
KEEP WITHIN 1 HOUR
PARTITION BY Measure_id;he familiar group by clause.
SELECT Measure_id,
COUNT(*) as MeasureCount,
FROM IncidentWindow
GROUP BY Measure_id;
Monitoring
With the Striim Monitoring Web UI we can now monitor our data pipeline with real-time information for the cluster, application components, servers, and agents. The Main monitor page allows to visualize summary statistics for Events
Processed, App CPU%, Server Memory, or Server CPU%. Below the Monitor App page displays our App Resources, Performance and Components.


Summary
In this blog post, we discussed how we can use Striim to:
-
Perform Oracle Change Data Capture to stream data base changes in real-time
-
Use streaming SQL and caches to easily denormalize data in order to make relevant data available together
-
Load streaming enriched data to Mongodb for real-time analytics
-
Use Kafka for persistent streams
-
Create rolling aggregates with streaming SQL
-
Continuously monitor data pipelines
Wrapping Up
Striim’s power is in its ability to ingest data from various sources and stream it to the same (or different) destinations. This means data going through Striim is held to the same standard of replication, monitoring, and reliability.
In conclusion, this recipe showcased a shift from batch ETL to event-driven distributed stream processing. By capturing Oracle change data events in real-time, enriching them through in-memory, SQL-based denormalization, and seamlessly delivering to the Azure Cloud, we achieved scalable, cost-effective analytics without disrupting the source database. Moreover, the enriched events, optionally supported by Kafka, offer the flexibility to incrementally integrate additional event-driven applications or services.
To give anything you’ve seen in this recipe a try, sign up for our developer edition or sign up for Striim Cloud free trial.