
Introduction

The world is drowning in data. More than 80% of respondents in an IBM study said that the sources, the volume, and the velocity of data they work with had increased. So it comes as no surprise that companies are eager to take advantage of these trends; the World Economic Forum’s report lists data analysts and scientists as the most in-demand job role across industries in 2020. And although companies are ramping up efforts in this field, there are major obstacles on the road ahead.
Not only are most analysts forced to work with unreliable and outdated data, but many also lack tools to quickly integrate data from different sources into a unified view. Traditional batch data integration is hardly up to this challenge.
That’s why a growing number of companies are looking for more effective and faster types of data integration. One solution is real-time data integration, a technology superior to batch methods because it enables rapid decision-making, breaks down data silos, future-proofs your business, and offers many other benefits.
Different types of data integration

Depending on their business needs and IT infrastructures, companies opt for different types of data integration. Some choose to ingest, process, and deliver data in real time, while others might use batch integration. Let’s quickly dive into each one of those.
Batch data integration
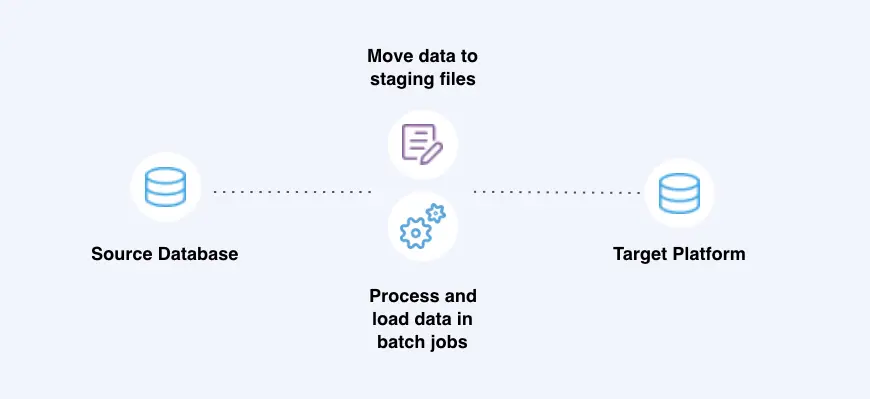
Batch data integration involves storing all the data in a single batch and moving it at scheduled periods of time or only once a certain amount is collected. This approach is useful if you can wait to receive and analyze data.
Batch data integration, for instance, can be used for maintaining an index of company files. You don’t necessarily need an index to be refreshed each time a document is added or modified; once or twice a day should be sufficient.
Electric bills are another relevant example. Your electric consumption is collected during a month and then processed and billed at the end of that period. Banks also use batch processing, which is why some card transactions might take time to be reflected in your online banking dashboard.
Real-time data integration with change data capture
Real-time data integration involves processing and transferring data as soon as it’s collected. The process isn’t literally instantaneous, though. It takes a fraction of a second to transfer, transform, and analyze data using change data capture (CDC), transform-in-flight, and other technologies.
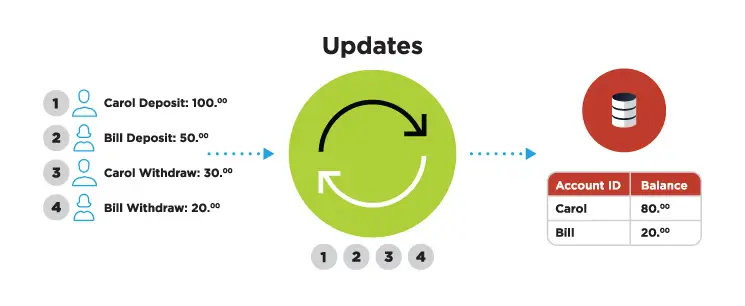
CDC involves tracking the database’s change logs and then turning inserts, updates, and other events into a stream of data applied to a target database. In many situations, however, data needs to be delivered in a specific format. That’s where the transform-in-flight feature comes into play as it turns data that’s in motion into a required format and enriches it with inputs from other sources. Data is delivered to the master file in a consumable form and is ready for processing.
Real-time data integration can be deployed in a range of time-sensitive use cases. Take, for example, reservation systems: When you book a vacation at your favorite hotel, its master database is automatically updated to prevent others from booking the same room. Point-of-sale terminals rely on the same data-processing tech. As you type your PIN and then take money from a terminal, your account is automatically updated to reflect this action.
ETL VS ELT
ETL (extract, transform, load) is another approach to data integration and has been standard for decades. It consists of three parts:
- The first component of this method involves extracting data from the source systems using database queries (JDBC, SQL) or change data capture in the case of real-time data integration.
- Transform, a second component of ETL, includes processing the data so it can be consumed properly in the target system. Examples of transformation include data type mapping, re-formatting data (e.g. removing special characters), or deriving aggregated values from raw data.
- And load is the third component of ETL. It relates to the writing of the data to the target platform. This can be as simple as writing to a delimited file. Or, it can be as complex as creating schemas in a database or performing merge operations in a data warehouse.
ELT (Extract, load, transform) re-orders the equation by allowing the target data platform to handle transformation while the integration platform simply collects and delivers the data.
There are a few factors that have led to the recent popularity of ELT:
- The cost of compute has been optimized over time with open source tools (Spark, Hadoop) and cloud infrastructure such as AWS, Microsoft Azure, and Google Cloud.
- Modern cloud data platforms like Snowflake and Databricks provide analysts and cloud architects with a simple user experience to analyze disparate data sources in one platform. ELT tools load raw and unstructured data into these types if data platforms so analysts can join and correlate the data.
- ETL has increasingly become synonymous with legacy, batch data integration workloads that poorly integrate with the modern data stack
Andreesen Horowitz’s recent paper on modern data infrastructure highlighted ELT as being a core component of next-generation data stacks while referring to ETL as ‘brittle’. It’s unclear why they are categorizing all ETL tools as brittle, but it’s clear there’s a perception that ETL has become synonymous with legacy, outdated data management practices.
However, real-time data integration modernizes ETL by using the latest paradigms to transform and correlate streaming data in-flight so it’s ready for analysis the moment it’s written to the target platform. This allows analysts to avoid data transformation headaches, reduce their cloud resource usage, and simply start analyzing their data in their platform of choice.
And real-time data processing is evolving and growing in popularity because it helps solve many difficult challenges and offers a range of benefits.
Real-time data flows allow rapid decision-making

By 2023, there will be over 5 billion internet users and 29.3 billion networked devices, each producing ever-larger amounts of different types of data. Real-time integration allows companies to act quickly on this information.
Data from on-premises and cloud-based sources can easily be fed, in real-time, into cloud-based analytics built on, for instance, Kafka (including cloud-hosted versions such as Google PubSub, AWS Kinesis, Azure EventHub), Snowflake, or BigQuery, providing timely insights and allowing fast decision making.
And speed is becoming a critical resource. Detecting and blocking fraudulent credit card usage requires matching payment details with a set of predefined parameters in real time. If, in this case, data processing took hours or even minutes, fraudsters could get away with stolen funds. But real-time data integration allows banks to collect and analyze information rapidly and cancel suspicious transactions.
Companies that ship their products also need to make decisions quickly. They require up-to-date information on inventory levels so that customers don’t order out-of-stock products. Real-time data integration prevents this problem because all departments have access to continuously updated information, and customers are notified about sold-out goods.
Real-time data integration breaks down data silos
When deciding which types of data integration to use, data silos are another obstacle companies have to account for. When data sets are scattered across ERP, CRM, and other systems, they’re isolated from each other. Engineers then find it hard to connect the dots, uncover insights, and make better decisions. Fortunately, real-time data integration helps businesses break down data silos.
From relational databases and data warehouses to IoT sensors and log files, real-time data integration delivers data with sub-second latency from various sources to a new environment. Organizations then have better visibility into their processes. Hospitals, for example, can integrate their radiology units with other departments and ensure that patient imaging data is shared with all stakeholders instead of being siloed.
Real-time data integration future-proofs your business
Speed is essential in a world that produces more and more data. Annual mobile traffic alone will reach almost a zettabyte by 2022, changing the existing technologies and giving rise to new ones. Thriving in this digital revolution requires handling an array of challenges and opportunities. It also requires navigating between different types of data integration options, with real-time tech capable of future-proofing your business in many different ways.
Avoid vendor lock-in with a multi-cloud strategy
According to IBM, 81% of all enterprises have a multi-cloud strategy already laid out or in the works.
Real-time data integration allows your team to get more value from the cloud by making it possible to experiment with or adopt different technologies. You’d be able to use a broader range of cloud services and, by extension, build better applications and improve machine-learning models. And these capabilities are critical to a resilient and flexible IT architecture that underpins innovation efforts across on-premises and cloud environments.
Improving customer service ops
Your support reps can better serve customers by having data from various sources readily available. Agents with real-time access to purchase history, inventory levels, or account balances will delight customers with an up-to-the-minute understanding of their problems. Rapid data flows also allow companies to be creative with customer engagement. They can program their order management system to inform a CRM system to immediately engage customers who purchased products or services.
Better customer experiences then translate into increased revenue, profits, and brand loyalty. Almost 75% of consumers say a good experience is critical for brand loyalties, while most businesses consider customer experience as a competitive differentiator vital for their survival and growth.
Optimizing business productivity
Spotting inefficiencies and taking corrective actions is another important goal for today’s companies. Manufacturers, for instance, achieve this goal by deploying various improvement methodologies, such as Lean production, Six Sigma, or Kaizen.
Whichever of those or other productivity tactics they choose, companies need access to real-time data and continuously updated dashboards. Relying on periodically refreshed data can slow down progress. Instead of tackling problems in real time, managers take a lot of time to spot problems, causing unnecessary costs and increased waste.
Therefore, the key to optimizing business productivity is collecting, transferring, and analyzing data in real time. And many companies agree with this argument. According to an IBM study, businesses expect that fast data will allow them to “make better informed decisions using insights from analytics (44%), improved data quality and consistency (39%), increased revenue (39%), and reduced operational costs (39%).”
Harnessing the power of digital transformation

Among different types of data integration, real-time tech is the one that allows companies to truly take their data game to the next level. No longer constrained by batch processing, businesses can innovate more, build better products, and drive profits. Harnessing the power of data will provide them with a much-needed competitive edge. And that can make all the difference between growth and stagnation as the digital revolution reshapes the world.
Definitions
Batch data integration involves storing all the data in a single batch and moving it only once a certain amount is collected or at scheduled periods of time.
Real-time data integration involves processing and transferring data as soon as it’s collected using change data capture (CDC), transform-in-flight, and other technologies.
Benefits of real-time data integration
- Enables rapid decision-making
- Accelerates ELT with faster loads
- Modernizes ETL with high throughput transformations
- Breaks down data silos
- Prepares teams for a multi-cloud, anti-vendor lock-in strategy
- Improves customer experiences









