In an exciting development that underscores our commitment to innovation and customer success, Striim has officially achieved Premier Tier status in Snowflake’s AI Data Cloud Products program. This major milestone not only deepens our strategic partnership with Snowflake but also unlocks a host of new benefits for our customers.
What Does Premier Tier Status Mean?
Striim has advanced from Select to Premier Tier in Snowflake’s AI Data Cloud Products program: a recognition of our deep integration, proven customer impact, and commitment to delivering real-time, AI-ready data solutions. As a Premier partner, we gain enhanced co-selling opportunities, technical collaboration, and greater alignment with Snowflake’s go-to-market initiatives, directly benefiting our customers.
This upgrade positions Striim at the forefront of the ecosystem, enabling us to leverage a range of new opportunities and resources to drive further innovation and customer engagement. With the fastest ingest into Snowflake using Snowpipe API, advanced data preparation for AI workloads, and AI-driven protection for data in transit, Striim empowers businesses to move, transform, and secure data with unmatched speed and intelligence.
Why This Milestone Matters
The Premier Tier upgrade is not just an internal achievement; it represents a major win for our customers as well. Today, the ability to integrate real-time streaming data with robust analytical platforms is critical. With Striim’s deeper integration into Snowflake, we’re making it easier than ever for data teams to stream, transform, and secure their data effectively.
Here’s what that looks like for our customers:
Fastest Ingest into Snowflake – Striim delivers sub-second data movement into Snowflake using Snowpipe Streaming API, eliminating batch delays and reducing compute costs. Whether you’re streaming event data, transactional logs, or IoT telemetry, Striim ensures that your data lands in Snowflake with minimal latency, ready for immediate querying. This means fresher insights, real-time decision-making, and a competitive edge.
Preparing Data for AI – AI models are only as good as the data they’re trained on. Striim cleans, enriches, and structures data in-flight before it even reaches Snowflake, ensuring high-quality inputs for AI/ML workloads. With built-in schema evolution and support for semi-structured data (JSON, Avro, Parquet), Striim ensures your AI pipeline is always running on the most accurate, complete, and up-to-date data. Now, your AI-driven analytics and automation will deliver real value, rather than being held back by stale or messy data.
AI-Driven Data Protection – Streaming data introduces new security challenges—especially when sensitive information is moving across environments. Striim applies real-time anomaly detection and masking to identify potential risks before they become breaches. By using AI-driven heuristics and pattern detection, we help protect hackable data without slowing performance. Enjoy stronger data governance and safer AI adoption without bottlenecks.
Ready to Experience the Future of Real-Time Data Streaming?
With the strength of our Snowflake partnership and the numerous benefits it brings, we are more committed than ever to delivering the tools and insights you need to thrive in a data-centric world. Ready to explore how Striim’s enhanced capabilities can transform your data strategy? See how Striim’s enhanced Snowflake integration can optimize your real-time analytics and AI workflows. Explore our Striim + Snowflake solutions or request a demo today.
How Striim Keeps Enterprise Grade Streaming Workloads Safe
The Streaming Data Security Challenge
At Striim our approach to security encompasses protecting data both in motion and at rest, utilizing advanced encryption techniques and integrating with powerful tools. In this blog, I’ll walk you through 2 small pieces of this architecture on how Striim secures sensitive data & metadata (a) in motion and (b) at rest.
The Striim Shield: Protecting Data In Motion
One of the standout features gaining traction in this landscape is field-level encryption within data pipelines. While some startups have made this their sole focus, Striim takes it a step further by offering this capability at no extra cost through our innovative practice known as encrypted streaming.
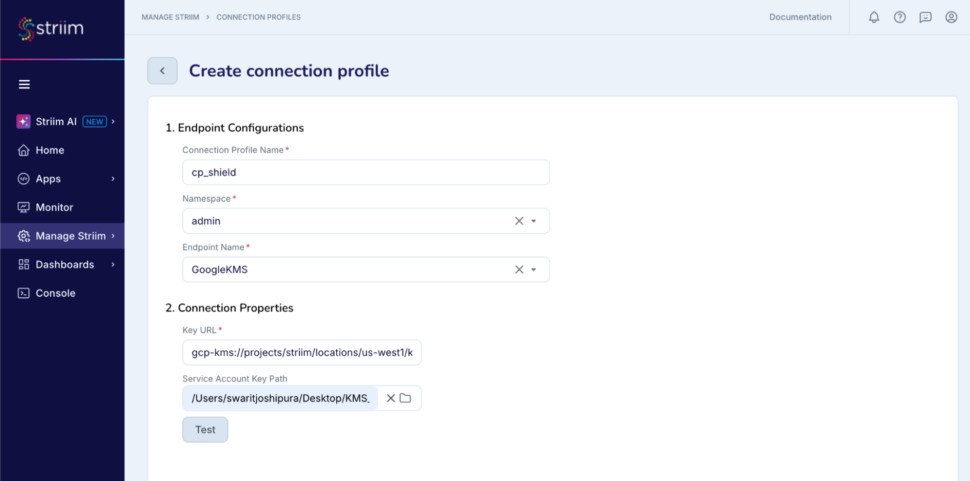
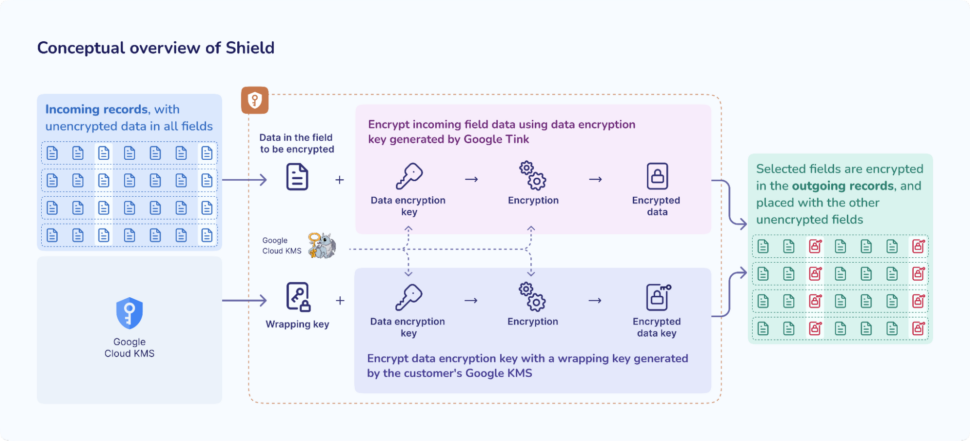
With Shield, you can easily encrypt one or more fields within a data stream with your own self-managed encryption key. This means that as your data flows downstream—eventually reaching its external target—those sensitive fields remain securely encrypted.
In the above, you can clearly see that the SSN, or social security number, is being encrypted through the Shield component. So, how does this work?
The system architecture is centered around a Key Management Service (KMS) that maintains a master Key Encryption Key (KEK). This KEK is utilized to encrypt the Data Encryption Key (DEK), which is generated by the Striim server using the Tink cryptographic library.
The encryption process is optimized through a batching mechanism. A Tink client is batched to utilize a specific KEK for a predetermined number of events flowing through the data pipeline. This approach balances computational efficiency with security requirements.
The implementation serves two primary technical objectives:
Encryption of data prior to warehouse ingestion, ensuring protection during network transit.
Maintenance of data encryption within the warehouse, providing security for data at rest.
So, what about decryption? – to decrypt the data, customers must utilize Tink in conjunction with the same KMS. This ensures that decryption is only possible for authorized entities possessing the correct cryptographic keys.
Here’s how you can get your hands dirty with it in Striim
Create a connection profile which connects to the KMS
Create a shield component in the flow designer which uses this connection profile
Deploy & Run your application, and sit back and enjoy encrypted real-time data streaming!
It’s important to note that since we send the data encryption key over the network to be encrypted by the KMS, there are performance implications in terms of speed while using this feature.
For simpler encryption than Shield, Striim offers the WITH ENCRYPTION option during application creation. This secures data streams between Striim servers or from Forwarding Agents, especially useful when data sources are external to the cluster or private network. You can apply encryption at the application or flow level to balance security and performance, encrypting only sensitive data streams as needed.
The Striim Vault: Protecting Customer Metadata
Now that we’ve discussed how data in motion is safe in Striim at rest, we’ll dive into how data is kept safe at rest. Striim maintains customer metadata in our Metadata Repository (MDR). This includes all information such as pipeline source & target metadata, user information, pipeline deployment plans and more. While this repository is crucial for storing various configuration details, we understand that certain information—such as passwords and table names—requires an extra layer of security.
When users input passwords for database connections or secure JDBC connections, Striim doesn’t simply store this sensitive information in plain text. Instead, we’ve developed a sophisticated system to protect these credentials – Striim integrates seamlessly with external vaults, providing customers with a secure way to manage their sensitive data. This integration allows customers to avoid storing sensitive information directly in the MDR, even though we do encrypt that before persisting it as well.
Our vault integration includes several advanced security features:
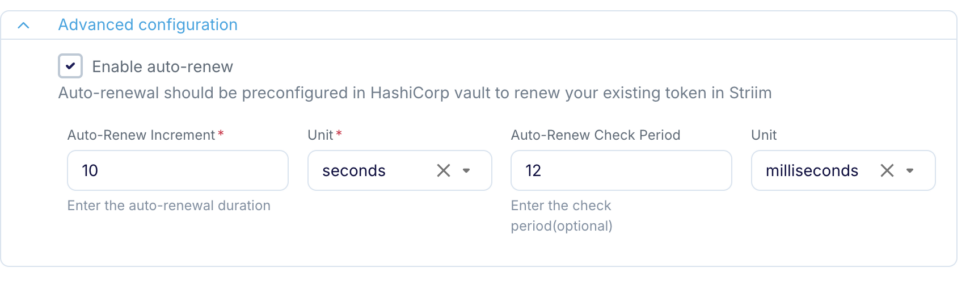
Token Auto-renewal: Customers can configure settings for Striim to automatically renew the vault token periodically. This ensures that even if a token is leaked, it becomes invalid after a certain time. The Striim server operates a timer thread within the JVM that regulates the frequency at which the HashiCorp Renew Endpoint is accessed.
Reference-based Storage: In Striim, we maintain a reference to the connection in the vault and the key that the customer wants to use as the password for their database or any other sensitive field.
Runtime Connection: Striim makes the connection to the vault at runtime. This means the sensitive value is only stored in memory and never persisted to the MDR.
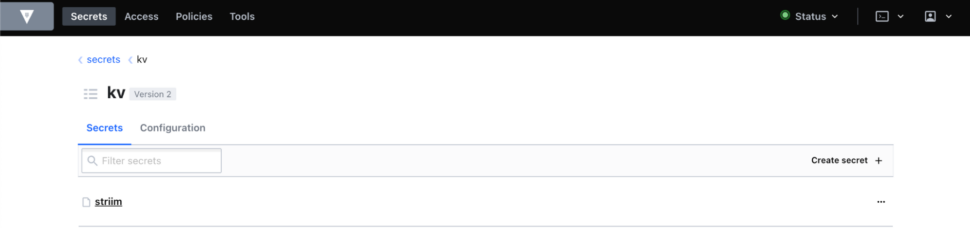
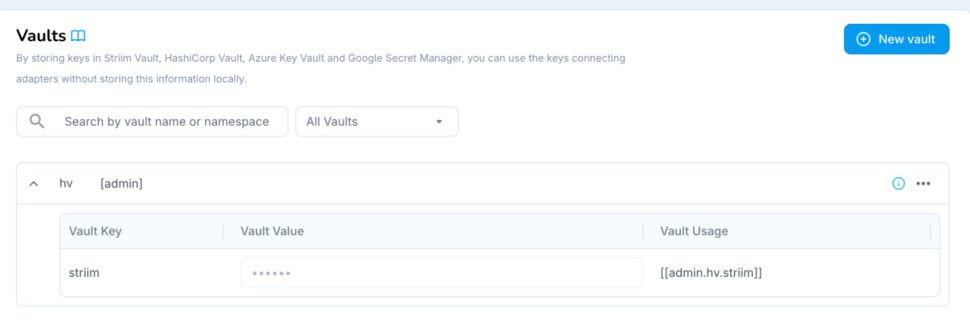
One of the many vaults we integrate with is the HashiCorp Vault. Here’s how it works:
Customers maintain their keys and values on their HashiCorp server.
In Striim, customers create a reference to their vault. You provide only an access token to connect to the HashiCorp Server, rather than the actual credentials.
Once the vault is created, customers can see their HashiCorp Vault keys, as well as the usage of the vault in Striim Application components such as Sources & Targets.
Striim users can use this vault key as the password in their source/target (e.g., Oracle Reader) – this ensures that the raw password is never stored in our MDR, and only maintained in-memory for this connection.
Deploy and Run Pipeline – This is the final step which allows you to run your data pipeline and drive mission critical business applications securely, and in real-time!
Benefits of Using Vaults in Striim
Enhanced Security: Sensitive data is never stored at rest in Striim’s MDR.
Flexibility: Customers can use their preferred vault solution. We integrate with Google’s Secret Manager, HashiCorp Vault, Azure Key Vault, and even provide our own homegrown Striim Vault.
Reduced Risk: Sensitive credentials existing in a completely segregated system designed for data protection allows for heightened security.
For this post we focused on protecting and data in motion with Shield, and data at rest with vaults. In an era where data breaches can cost companies millions and erode customer trust, Striim’s commitment to secure data processing provides peace of mind. By addressing security at every stage of the data lifecycle, from ingestion to processing to storage, we enable businesses to harness the power of their data without compromising on safety.
This article only scratches the surface in how we keep your data safe. There are so many more amazing features in our new release, including automated PII detection, OAuth connectivity, SSO/SAML support, and more to safely activate your siloed data in real-time.
In the fast-paced world of retail, the ability to harness data effectively is crucial for staying ahead. On September 18, 2024, at Big Data London, Morrisons shared its digital transformation journey through the presentation, “Learn How Morrisons is Accelerating the Availability of Actionable Data at Scale with Google and Striim.”
Peter Laflin, Chief Data Officer at Morrisons, outlined the supermarket chain’s strategic partnership with Striim, a global leader in real-time data integration and streaming, and Google Cloud. This collaboration is pivotal in optimizing Morrisons’ supply chain, improving stock management, and enhancing customer satisfaction through the power of real-time data analytics.
By harnessing Striim’s advanced data platform alongside Google Cloud’s robust infrastructure, Morrisons has effectively integrated and streamlined data from its vast network of over 2,700 farmers and growers supplying raw materials to its manufacturing plants across the UK. This initiative has enabled seamless information flow and real-time visibility across its operations, allowing the supermarket to make quicker, data-driven decisions that directly impact customer experience. Tata Consultancy Services (TCS), Morrisons’ long-standing systems integration partner, has been instrumental in the success of this transformation. TCS worked closely with Morrisons’ teams to ensure the seamless implementation of Striim’s platform, facilitating smooth integration and alignment across operations.
The keynote featured insights from industry experts, including John Kutay, Head of Products at Striim, and Mike Reed, Retail Account Executive at Google, who underscored the transformative impact of innovative data strategies in the retail sector.
As Morrisons continues to embrace this data-driven approach, it sets a new standard for enhancing customer satisfaction and operational efficiency in the competitive retail environment.
At Striim, we’re excited to partner with GigaOm to present an exclusive webinar that promises to shed light on a game-changing topic in the world of data: “The Rise of Streaming Data Platforms: Embrace the Future Now.” This event took place on September 12, 2024 at 12:00 PM EDT. You can watch it on-demand here.
Real-time data processing has evolved from a competitive advantage to a necessity. Advanced streaming data platforms are now essential for businesses aiming to enhance agility and responsiveness. These platforms enable quicker, more informed decision-making, a critical capability in today’s complex business environment.
This webinar delves into why streaming data platforms represent the next significant advancement in Big Data solutions. Tune in and discover how these technologies can transform your approach to data and drive your business forward.
What You Can Expect:
In this dynamic session, we’ll dive into:
Next-Generation Big Data: Learn about the cutting-edge advancements in streaming data platforms and why they are at the forefront of the Big Data revolution.
Expert Insights: Hear from GigaOm analysts as they evaluate various platforms, focusing on edge deployment, data quality, temporal features, machine learning (ML), and SQL utility.
Real-World Applications: Discover real-world success stories and practical use cases that highlight the transformative potential of real-time data.
Join Us for to Dive Deeper into the Rise of Streaming Data Platforms
Have you heard the news? We’re thrilled to share that Striim has been recognized as a Leader and Fast Mover in the GigaOm Radar Report for Streaming Data Platforms. This accolade highlights our commitment to providing cutting-edge, high-performing solutions that meet the evolving needs of our customers.
In its 2024 report, GigaOm evaluated the rapidly changing streaming data landscape and outlined the key capabilities (table stakes, key features, and emerging features) and nonfunctional requirements (business criteria) that set leading streaming data platforms apart. Striim’s recognition is a testament to our comprehensive feature set and innovative approach to delivering value to our customers.
Why Striim Stands Out
As detailed in the GigaOm Radar Report, Striim’s unified data integration and streaming service platform excels due to its distributed, in-memory architecture that extensively utilizes SQL for essential operations such as transforming, filtering, enriching, and aggregating data. Additionally, the platform’s support for the Tungsten query language (TQL) extends SQL functionality with advanced windowing capabilities and integration options through Java.
One of our platform’s key strengths is its versatile windowing functions, which include batch-based, time-based, session-based, and hybrid windows. This flexibility enables organizations to tailor data processing to their specific needs. Furthermore, our support for pattern matching and ad hoc queries further enhances the platform’s adaptability.
More Than a Data Streaming Platform
Beyond streaming data, Striim delivers on data ingestion through Change Data Capture (CDC), ELT, ETL, and snapshots. Our distributed messaging and queuing capabilities, which can be persisted in Kafka, facilitate seamless data flow between publishers and subscribers. This is crucial for real-time data delivery and notifications, supported by integration with services like Azure Event Hubs and Google Pub/Sub.
Striim’s robust AI features, including built-in classification, regression functions, and ML-based anomaly detection, are particularly noteworthy. Our ability to generate vector embeddings and deploy lightweight agents on edge devices showcases our dedication to advanced data processing and security, with options for data masking and encryption.
Constantly Innovating
Our machine learning capabilities and support for emerging features have positioned Striim in the Innovation half of the GigaOm Radar, underscoring our role as a dedicated solution for streaming data. This recognition reaffirms our status as a Leader and Fast Mover, committed to driving the streaming data platform market forward.
The GigaOm Radar report provides a comprehensive overview of key players in the streaming data platform market, helping decision-makers evaluate solutions and make informed investment decisions. We’re honored by GigaOm’s recognition and look forward to continuing our journey of innovation and excellence in the streaming data space.
Ready to dive deeper into why Striim was given this recognition? Check out the complete GigaOm Radar Report now for a detailed analysis and insights into the streaming data platform market, and dive deeper into how Striim stands out.
Exciting news for data-driven organizations: Striim is thrilled to announce a Technology Partnership with Yellowbrick Data. This strategic alliance opens up a world of possibilities for businesses looking to leverage the power and speed of Striim’s real-time data streaming and integration capabilities to seamlessly move data into the Yellowbrick Data Warehouse and drive lightning-fast analytics.
Striim, the frontrunner in real-time data integration and streaming analytics, has joined forces with Yellowbrick Data, renowned for its high-performance data warehousing solution. Together, we are delivering a synergy that is set to transform how companies handle data, offering a wealth of benefits to customers eager to unlock new opportunities and optimize their operations.
Here are some of the key values that this Striim and Yellowbrick Data partnership brings to customers:
Lightning-Fast Analytics: With Striim’s real-time data streaming and integration, coupled with Yellowbrick Data Warehouse’s exceptional performance, businesses can now achieve lightning-fast analytics. This enables organizations to gain instant insights from their data, enhancing decision-making and responsiveness.
Seamless Data Movement: The partnership streamlines the process of moving data into the Yellowbrick Data Warehouse. Striim’s capabilities make it easy for organizations to replicate, transform, and load data in real time, ensuring that data is always up-to-date and readily available for analytics.
Scalability and Flexibility: Yellowbrick Data Warehouse offers scalability and flexibility, allowing businesses to expand their data warehousing capabilities as needed. This ensures organizations can meet the demands of a growing data landscape without compromising on performance.
Cost-Efficiency: The combined solution provides an affordable alternative to traditional data warehousing systems. It allows businesses to achieve high-performance analytics without breaking the bank, making efficient use of their IT budgets.
Data Agility: Striim’s real-time data streaming and integration capabilities, when integrated with Yellowbrick Data Warehouse, offer data agility. Businesses can work with a wide range of data sources, formats, and types, ensuring they can effectively manage diverse data workloads.
Accelerated Insights: The partnership accelerates the data-to-insights journey. With faster data movement and analytics, organizations can capitalize on data-driven opportunities, stay competitive, and drive innovation.
“Striim is truly thrilled to embark on this transformative journey through our Technology Partnership with Yellowbrick Data,” said Phillip Cockrell, Senior Vice President of Business Development at Striim. “This collaboration empowers organizations to unleash the full potential of their data, seamlessly integrating our real-time data streaming and integration with Yellowbrick’s high-performance Data Warehouse. The speed and agility this brings to analytics is nothing short of revolutionary, and we are excited to be at the forefront of enabling businesses to drive lightning-fast insights and innovations.”
“We are excited to partner with Striim, a true frontrunner in real-time data integration and streaming analytics,” said Allen Holmes, VP of Business Development, Cloud & Global Partners at Yellowbrick Data. Striim’s expertise and technology in real-time data streaming and integration perfectly complement Yellowbrick Data’s high-performance data warehousing solution. Together, we are providing organizations with a powerful combination that enables lightning-fast analytics, seamless data movement, scalability, cost-efficiency, and data agility.“
Striim’s Technology Partnership with Yellowbrick Data is a game-changer for organizations seeking to supercharge their data analytics. By combining Striim’s real-time data streaming and integration with Yellowbrick’s high-performance data warehousing solution, businesses gain the power and speed required to make data-driven decisions in real time. In a data-centric world, this partnership empowers organizations with the tools they need to thrive and succeed in an ever-evolving landscape.
Striim, a key partner for Microsoft Fabric today announced its new, low-latency, open-format data integration and streaming service for Microsoft Fabric. This service seamlessly integrates data from disparate sources, mission-critical enterprise applications, and databases into Microsoft Fabric. Through Striim’s AI-ready data streaming, we’re ushering in a new era of analytics and AI, all harmonized under a single data platform on Microsoft Azure.
What is Microsoft Fabric?
Microsoft Fabric is an end-to-end data analytics solution with full-service capabilities, including data movement, data lake, data warehouse, analytics, and business intelligence. All of these services are served by Microsoft OneLake, a unified intelligent storage layer that solves the complex problem of decentralized data teams working in silos. Striim uniquely streams low-latency data to Microsoft Fabric to power analytics and AI with fresh, real-time data with its fully managed service natively built on Microsoft Azure.
Let’s take a scenario of a large retail business that has stores across multiple cities. The business wants to gain critical real-time insights across its stores, purchases, inventory, costs incurred per store and identify patterns like seasonal sales, perform predictive analysis for inventory, sales etc. Typically to achieve this goal various teams including data engineers, sql developers, data scientists and business analysts work independently with their own datasets and data pipelines, tools & scripts causing not only duplicate efforts but also silos of storage footprint. The management of these siloed efforts quickly becomes complex including data governance, privacy, user access control and infrastructure management etc. that can result in an increased TCO for the business.
Microsoft Fabric was introduced to address this exact challenge through a unified storage layer with access control and dedicated workgroups for individual teams to work independently on the same data set. However, the data needed in Fabric Warehouse or Lakehouse resides in enterprise silos and still needs to be unified through a real-time streaming service that lets users ingest, process, enrich and load the data to the warehouse, lakehouse or Microsoft Power BI datamarts services; otherwise this integration effort has to be done independently by each data team. Striim’s service Striim for Microsoft Fabric does exactly that, offering a real-time, low latency and highly scalable data streaming service that matches the Fabric scale and serves as a single tool for all data teams in the organization with various Analytics and AI use cases.
Real time Insights in Power BI Dashboards
Let’s overview how this is accomplished in Striim.
In our above example, the retail customer who is interested in critical business insights will simply sign up for Striim Cloud and follow three simple steps to get the data into Fabric data warehouse and lakehouse targets in less than 5 minutes to have access to real time insights in Power BI dashboards.
Step 1: Create the Striim Cloud service on Azure, this process uses Azure Kubernetes Service, deploys Striim and configures a cluster.
Step 2: Create a data pipeline with source connection details and optionally use Azure private link to securely route data completely off of the public internet.
Step 3: Configure Fabric target to Fabric warehouse
Now simply monitor data being streamed from source to target/targets in real-time. Data will be directly written directly to the data warehouse in delta-parquet format so the Power BI can be configured to receive the real-time data from data warehouse tables.
Retail customer’s requirements are consolidated and simplified across groups to get the business insights in less than 5 minutes using Microsoft Fabric Power BI. Shown below are data insights such as sales by store, traffic to the stores by dates and cost of running stores etc.
About Striim
Striim’s Cloud based service offers a lot of inbuilt smart defaults, automation and intelligence that helps users focus on their actual business needs instead of spending their time on managing pipelines. It saves time and effort for the data engineering team, offers a no-code experience for citizen developers and real-time querying directly from pipelines for engineers and SQL developers and enables businesses with real-time data to make decisions. This unified data streaming nicely compliments the open vision of Microsoft Fabric platform.
Lisa Martin 0:06
Good morning, everyone and welcome to the cubes j one coverage of Google Cloud Next live at Moscone south in San Francisco. I’m Lisa Martin. Dustin Kirkland is my cube analyst. co host. We’re here with about 20,000 people, you can hear the din of the bus behind us. There was a tremendous amount of announcements this morning. Lot of great Google Cloud execs, customers, partners, we’re here with Striim joining us next, John Kutay, the head of product joins us, John, great to have you. Thank you so much for joining us on The Cube.
John Kutay 0:36
Thanks so much for having me. Super excited for this discussion.
Lisa Martin 0:39
Yeah, I would love to share with the audience more about Striim . What do you guys do mission vision help us understand that?
John Kutay 0:46
Striim is unified data streaming. For generative AI analytics and operations. We love helping our customers infuse real time data into their decisions into their operations. And now generative AI, which is becoming a top priority for many of the enterprise data teams that we’re working with.
Lisa Martin 1:04
It is Gen AI is probably the hottest topic on the planet, or one of you talked about real time. And I think one of the things we’ve learned in the last few years is that access to real time data is no longer nice to have for companies. It’s an imperative. It’s really, for every industry, it’s really hard to do that. But I’m curious what some of the gaps in the market were, when Striim was launched that you guys saw the thought we can solve this?
John Kutay 1:27
So the company’s CEO and CTO came from Golden Gate software, which at the time of its acquisition by Oracle was the number one database replication product in the market. But it was very pigeonholed into just copying data between databases. And there was this obvious demand in the market to not only move data in real time, but to analyze it. And now with this big wave of generative AI, it’s not about data going into some warehouse and you wait for someone to pull up a report. Now you want data automatically making decisions for you. You want your customers to talk to a smart, AI driven bot that knows everything about them, and can answer questions for them. And this all requires real time data.
Lisa Martin 2:07
Absolutely. And every company whether I always think of whether it’s the grocery store, or the gas station, or Starbucks has my data, and I expect that they not only use it responsibly and securely, but also use it to give me that real time relevant, personalized experience that I want every company has to be really I’ve heard people say data driven. And I heard someone last week say no, not data driven, Insight driven. Difference. Yeah, there’s a difference there. Talk to us about how Striim is working with enterprise data teams to really help them extract the value of data, and especially working with Gen AI,
John Kutay 2:40
Macys.com, who we presented with previously at Google Cloud, next session, you know, they power remember, they’re not in the business of doing data, right. They’re trying to sell clothes, and they had a digital first initiative with Striim , help them go from their existing investments in their on premise, you can call legacy infrastructure, and help make sure that that data is in Google Cloud within seconds. Because if they’re building new digital applications, that data has to be there. So we’re really proud to have customers like that. And then we have other examples of airlines, for example, they want to run their operations on time, they need good customer experiences, they need to make sure the aircraft’s are safe. We help American airlines do exactly that. We were presenting with them at a data and AI Summit. And with Striim, Databricks MongoDB. They were able to again, take their aircraft telemetry, action it for their operational teams that are there to maintain the aircraft, make sure that everything’s safe, everything’s ready to go. And best of all, everything’s on time.
Lisa Martin 3:45
Yeah, that’s what it’s all about, right? Being on time these days. Yeah. And
Dustin Kirkland 3:48
along those lines, talk to me a little bit about the velocity in terms of, you know, how teams integrate this, how fast how long does it take how long till we see results from integrating Striim ?
John Kutay 3:55
Absolutely, we’re really proud of being able to get our customers into production in a matter of weeks. Even when it’s complex. It’s breaking down long standing data silos within the enterprise, a lot of technical complexity. For instance, at our presentation with American Airlines at data in AI Summit, they were really proud of the fact that they went to production at global scale, within 12 weeks of Striim and it’s because Striim’s a unified data streaming platform, meaning connectors, the data movement, the modeling, the processing, streaming into your target systems, meaning whether it’s Google Cloud, infrastructure, data, bricks, snowflake, all that data has to be there with quality and uptime SLA is that are that the business can trust?
Lisa Martin 4:39
Where are your customer conversations these days? Are you talking with Chief Data Officers, CIOs, is all of the above does it I’ve mentioned it can vary depending on the organization. But every company is so data rich, but they have to be able to figure out how do we get access to this now,
John Kutay 4:53
it’s really important to be a catalyst for internal collaboration, meaning you have to work with the CIOs the Chief Data officers all the way down to the people who are in the trenches, building the pipelines and build alignment there. And that’s something that we’re also really proud of. And, you know, because at the end of the day, yeah, you’re solving technical problems, but you’re delivering on business use cases and initiatives. And that’s the most critical thing.
Lisa Martin 5:16
What are some of the key use cases that you see that maybe have more horizontal play across industries that Striim is involved in?
John Kutay 5:24
Yeah, that’s an amazing question. So right now, data teams, you know, they already had a year’s worth of initiatives on their play. And now a generative AI, all the innovation that’s happening here at Google Cloud Next, and across the various platforms, there is a very high priority mandate for data teams to adopt generative AI, and really bring their data into generative AI and then do the reverse, which is bring generative AI to where their data is today. So those are some some of the use cases that they’re looking at in terms of making sure that data is making decision on its own. Yeah.
Lisa Martin 5:59
Can you share a little bit about the partnership with Google what you guys are doing together? How you’re helping customers really unlock the value of AI and Gennai?
John Kutay 6:06
Absolutely, we’re really proud of our partnership with Google. If you’re a big query user, you go into the Add Data button Striim’s right there, you can launch it from your console stream as a Google Cloud native products, our CTO alo Pareek, presented up here at Google Cloud Next, since the beginning, when they were doing these shows, and you know, we’re really proud of helping enterprises quickly realize the value of Google Cloud by complementing their existing enterprise investments, getting that data into Google Cloud and making sure that it’s reliable and the business can build on top of that, using the the modern infrastructure that Google is providing.
Lisa Martin 6:44
Yeah, that modern infrastructure, they talked a lot about that this morning. And providers, it’s was probably like, music to their ears.
John Kutay 6:50
Yes. Frames, clearly a important piece of that for sure. How do your customers think about the return on investment, you know, the Striim, Google Cloud, all that making their investment in in you and seeing a return? Look, when I work with the data team, and I tried to work with them on their goals and OKRs and things along those lines, if their goal is to move data from A to B, that’s not good enough, we have to talk about what your actual business initiatives are and how this data project or you know tactic is going to help you there. So the example like I brought up with Macy’s, right, they can tie that to customer experiences having more fresh, reliable data is critical American Airlines, their their aircrafts, you know, moving, making sure that those are operating with the as fast as possible. aircrafts are taking off on time well maintained. And that’s really where you see the ROI is like, how is data helping your business meet their mission statements?
Lisa Martin 7:51
When you’re in customer or prospect conversations, John? And they say, why Striim? What do you say? What are those key differentiators that really shine a light on value prop?
John Kutay 8:02
Yeah, absolutely. The fact that it’s simply a unified platform, but just in a couple of clicks, we’re spinning up a lot of complex infrastructure that you don’t have to know about as an end user, making sure that it’s very reliable, it’s very fast. You know, instead of Striim vendors were you know, I mean, sorry, companies are pulling in six, seven vendors do the same thing. Now you get the whole thing in one single pane of glass, you get your connectors, you get your data processing your data delivery, monitoring data quality and freshness, so that the data stakeholders know that there’s ultimately trust in that data.
Lisa Martin 8:37
And that trust is currency these days, right? It’s absolutely has to be there. But sounds like what Striim is doing to me as you’re really, are you helping companies to like kick out six to seven other vendors so that from what I’m hearing workforce productivity cost efficiencies are why as Dustin was talking about, it seems like those are some of the big outcomes in general that organizations can achieve with Striim.
John Kutay 8:59
I always think about is very purpose driven. You know, you have a specific business problem you’re trying to solve, rather than it taking years of development and expensive investments, you can get your initiatives off the ground and into production very quickly. And you know, that’s just with the power of the platform and the way that we can partner with data teams as well to make sure that they’re tying it to their business initiatives and getting that value out of it.
Lisa Martin 9:22
Yeah, it’s all about getting trusting making sure the data is trustworthy responsible, secure and extracting that value. Last question, John, for us before we wrap here anything new exciting coming up, first thing that we should be looking for any events, any webinars, things that you want to plug?
John Kutay 9:35
Yeah, in fact, tonight, we’re doing a what’s new and data live. This is a thought leader ship session that I run, really excited to have Bruno Aziza was formerly Yeah, head of data analytics. Now he’s at capital G alphabets, capital G. And we have Sanji Mohan, who was previously at Gartner. And we have Ridhima Khan, VP of dapper Labs is going to talk about modern digital consumer experiences. So that’s Tonight at Salesforce sour, we’re going to record it. So it’ll be made available to everyone. And we’re going on score with what’s new and data and bringing all the data practitioners, data leaders to really talk about how they’re innovating with data and meeting all these business goals that they’re trying to deliver.
Lisa Martin 10:16
Awesome. Lots of stuff going on. Yeah. Best of luck tonight. Sanjeev is a is a cube analyst from time to time. We know Bruno. He’s been on the show. So lots of great folks that’s that we were talking about before we went live like tech, it’s just like two degrees of separation. John, it’s great to have you You’re now officially a CUBE alumni, I probably can get you a sticker. So appreciate you sharing with us what’s going on at Striim with Google and how you’re really enabling those data teams to maximize value and use Gen AI. Thank you so much.
John Kutay 10:41
Thank you for having me.
Lisa Martin 10:42
Our pleasure for John Kutay and Dustin Kirkland. I’m Lisa Martin, and you’re watching The Cube live day one of our three days of coverage of Google Cloud Next. Dustin and I are going to be right back with our next guest. So don’t go anywhere.
In this article, I’ll share how to create a custom Striim CentOS image with Packer, deploy it, and incorporate it into your infrastructure and DevOps stack. Before we set up our environment and start building and deploying the image, let’s go through the definitions of both tools.
What is HashiCorp Packer?
Hashicorp Packer is an open-source Infrastructure-as-Code (IaC) tool that enables you to quickly build and deploy custom images for cloud and on-premises environments. With Packer, you can create custom image builds for a variety of platforms, such as Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure, and more. You can use Packer to automate the process of building images from scratch, including creating, configuring, and optimizing them. Additionally, Packer can be used to efficiently deploy those images in multiple cloud locations or on-premises.
Packer is great for automating the creation of machine images so that they can be deployed quickly and easily. The tool supports a variety of image formats and has built-in support for various configuration management tools, such as Chef and Puppet. By using Packer, you can ensure that your images are always up-to-date and properly configured. This makes it easier to manage and maintain your infrastructure in the cloud or on-premises.
What is Striim?
Striim is an end-to-end streaming platform for real-time data integration, complex event processing, and analytics. It is designed to ingest, analyze, and deliver massive volumes of data from multiple sources including databases, files, messaging systems, and IOT devices.
By integrating Packer into the Striim deployment process, we can quickly create an automated environment that enables your analytics team to immediately replicate real-time data to data warehouses and/or RDBMS databases.
Pre-requisites:
An available Linux (CentOS, Ubuntu, or Suse) machine.
Log in to your VM and verify Packer is installed by running this command:
$ packer --version
1.8.6 Once verified, copy the JSON key from the GCP service account to the home directory:
$ ls
account_key.json
Export the following environment variables for later configuration use:
# Values from the Striim license
export company_name=<company_name_from_striim_license>
export cluster_name=<cluster_name_from_striim_license>
export license_key=<license_key_from_striim_license>
export product_key=<product_key_from_striim_license >
# Setting up the passwords for Keystore, admin, and sys users
export keystore_pass=<keystore_pass_for_striim_config>
export admin_pass=<admin_pass_for_striim_config>
export sys_pass=<sys_pass_for_striim_config>
export mdr_type=<mdr_type_for_striim_config>
Creating Your Striim Image
Create a shell script named striim_install.sh and add the following code to it:
Striim (V4.1.2) and Java JDK (V1.8.0) will be installed using this shell script, and Striim will be configured using the environment variables that we specified in the previous section. Note: This shell script installs Striim and Java JDK only in CentOS, RedHat, Amazon Linux 2, and SUSE Linux machines.
Create a JSON file named packer_striim_image.json and copy the following code:
The provisioners section uses built-in and third-party software to install and configure the image after booting. In our case, we are copying our striim_install.sh to the machine’s /tmp/ directory and executing the script to install Striim and its dependencies. More info: https://developer.hashicorp.com/packer/docs/provisioners
Once these files are created, we should see a file structure like the one below in our home directory:
Let’s run the following commands to validate our Packer JSON file:
$ packer validate packer_striim_image.json
The configuration is valid.
Once we verified that it is valid, we can deploy our image:
$ packer build packer_striim_image.json
...
==> Wait completed after 3 minutes 36 seconds
==> Builds finished. The artifacts of successful builds are:
--> googlecompute: A disk image was created: gcp-custom-striim-image-167888819
We can copy the image name gcp-custom-striim-image-167888819 and use it to build a VM in GCP to check that Striim is correctly installed on this image:
We can access the Striim UI by navigating to <public_or_private_ip>:9080 in the browser once the VM is in the “Running” state:
In conclusion, Packer is a powerful tool that can be used to create a more efficient infrastructure-as-code approach. With Packer, image builds and deployments can be automated in a secure and consistent manner. This automation allows you to quickly build and deploy Striim images without worrying about manual configuration errors. In addition to this, using Striim Cloud can fully automate this entire process. Visit theStriim Cloud page for a fully managed SaaS service/solution and Pay As You Go option to reduce total cost of ownership.
Deploying a server can be a time-consuming process, but with the help of Terraform, it’s easier than ever. Terraform is an open-source tool that automates the deployment and management of infrastructure, making it an ideal choice for quickly and efficiently setting up a Striim server in the cloud or on-premise. With the help of Striim‘s streaming Extract, Transform, and Load (ETL) data platform, data can be replicated and transformed in real-time, with zero downtime, from a source database to one or more target database systems. Striim enables your analytics team to work more efficiently and migrate critical database systems.
In this blog post, we’ll walk through the steps of how to use Terraform to automate the deployment of a Striim server in AWS.
Pre-requisites
Access to an AWS account including the Access Key ID and Secret Access Key.
We’ll be using Terraform version 1.3.6 in this tutorial. Please verify the version by running this command:
terraform -version
Terraform v1.3.6 on linux_amd64If
Once the installation is successful, we can authenticate to our AWS account by exporting the AWS_ACCESS_KEY_ID , AWS_SECRET_ACCESS_KEY and AWS_REGION environment variables:
After the installation process, we can create a directory named striim_server_tf and add the following files inside:
main.tf — will include the primary set of configuration for your module. Additionally, you can create additional configuration files and arrange them in a way that makes sense for your project:
variables.tf — will contain the variable definitions for your module:
As was mentioned above in the “Striim Credentials and License Information” section from the variables.tf file, we will need to set Striim’s license information and user passwords as environment variables since they are confidential values:
Once we have these files created, we should see a directory and file structure like this:
striim_server_tf
|
|-- main.tf
|
|-- variables.tf
Run Terraform
At this point, we have configured our Terraform environment to deploy a Striim server to our AWS account and written Terraform code to define the server. To deploy it, we can now execute the two Terraform commands, terraform plan and terraform apply, inside of the striim_server_tf directory.
Theterraform plan command lets the user preview the changes (create, destroy, and modify) that Terraform plans to make to your overall infrastructure.
Theterraform apply command executes the actions proposed in a Terraform plan.
If these commands executions are successful, you should see a message at the end of your terminal with the following message:
To verify the Striim server deployment, navigate to the AWS EC2 console and search for striim-server:
Make sure it’s in a Running state and Status check is 2/2 checks passed.
Next, enter the public IP address of the server with :9080 at the end of the url in a web browser and check to see if Striim is up and running:
Enter your credentials and verify you can log in to Striim console:
By leveraging Terraform and its Infrastructure-as-Code approach, deploying a Striim server can be automated with ease. It allows organizations to save time and money by quickly spinning up Striim servers, which can be used for data migration or zero downtime replication. This blog post provided an overview of how to use Terraform to set up and deploy a Striim server, as well as how to verify that the deployment was successful. With Terraform, it is possible to automate the entire process, making it easier than ever to deploy and manage cloud infrastructure. In addition to this, using Striim Cloud can fully automate this entire process. Visit the Striim Cloud page for a fully managed SaaS service/solution and Pay As You Go option to reduce total cost of ownership.