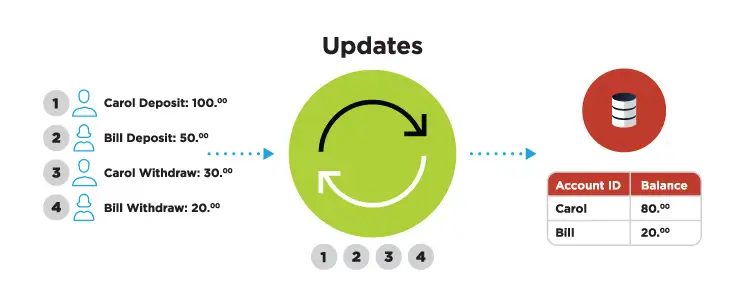
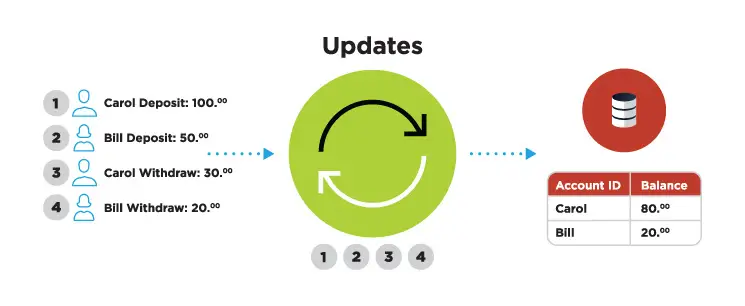
Data is the new oil, but it’s only useful if you can move, analyze, and act on it quickly. A Nucleus Research study shows that tactical data loses half its value 30 minutes after it’s generated, while operational data loses half its value after eight hours.
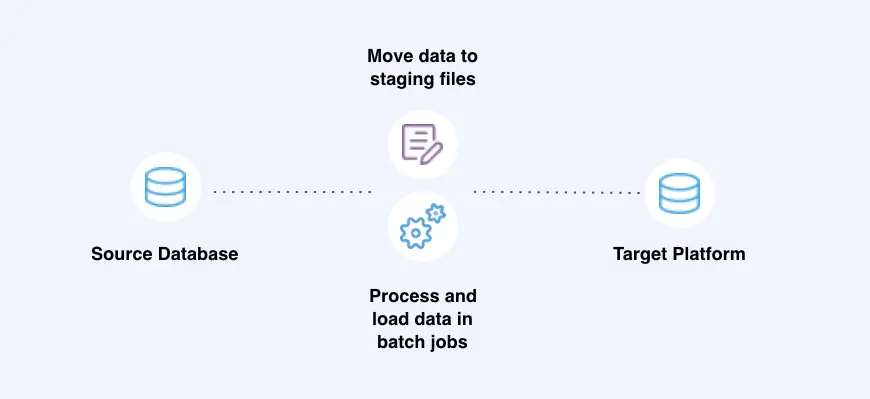
Change data capture (CDC) plays a vital role in the efforts to ensure that data in IT systems is quickly ingested, transformed, and used by analytics and other types of platforms. Change data capture is a software process that identifies changes to data in source systems and replicates those changes to target systems. And this process can be achieved using various change data capture methods, such as table deltas and database log mining.
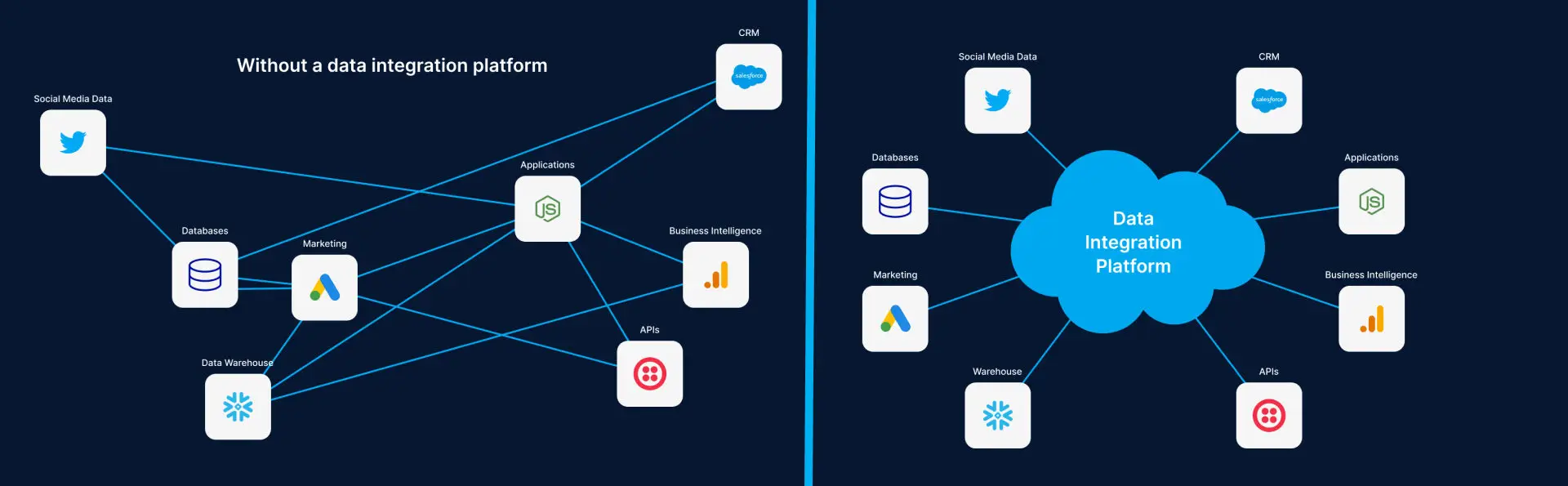
Failure to handle data effectively prevents companies from taking advantage of their data assets. To help teams modernize their data environment, we explore reasons why you need to change data capture solutions and different tactics you can use.
1. Change Data Capture accelerates reporting and business intelligence
CDC enables companies to quickly move data from different systems, like customer relationship management (CRM) or enterprise resource planning (ERP), into a single dashboard. Faster data collection then leads to timely reporting and improved business intelligence capabilities.
Improved reporting and business intelligence benefit businesses in different ways. One way is that companies may use CDC to report on customer purchases more quickly. Access to timely purchase data would then enable sales teams to offer qualifying customers special offers sooner and close the deal.
Another way manufacturers can use CDC to their benefit is to ensure that data generated by production machines is moved instantaneously to reporting or intelligence dashboards. Analysts can then discover that, for example, specific manufacturing lines are slower than usual. These findings can be used not only to fix the inefficient machines but also to better manage supply chain operations.
2. Change Data Capture connects different database systems
CDC helps teams with incompatible database systems share data in near real-time. One way to do that is by using CDC to populate a staging database with data from different systems. Users can then access the staging database without negatively affecting the performance of primary databases.
CDC especially benefits mid- to large-sized companies that often use a number of different database systems. Support agents in mid- to large-sized companies often need to access data on products purchased by customers, a piece of information typically managed by sales teams. In this case, CDC can be used to move relevant data to a data mart and have support agents access it to get the information they need.
CDC also helps companies better integrate their IT infrastructure following an acquisition or merger. Corporate systems often tend to be different or even incompatible. This challenge can be solved by merging disparate data sets into a single repository, which allows teams to access data and carry out their reporting and analysis work. The repository can also feed data to new systems. And the original databases can continue running for as long as necessary.
3. Change Data Capture pushes data to multiple lines of business
Companies can use CDC to continuously update a data mart with sales or customer data and have different lines of business access that data through web apps. Providing data through data marts reduces the user traffic previously directed to remote databases, including CRM or ERP.
Manufacturers can also use change data capture to ensure customer data, such as canceled or changed orders, is promptly forwarded to various business units, such as production and finance teams. Employees can then take appropriate measures to change a manufacturing deadline or update a sales forecast.
4. Change Data Capture handles two-way data flows
CDC helps companies instantaneously collect and share business data. Such two-way data flows provide departments with the information needed to make new decisions and policies.
Take, for instance, an insurance business. When working on new pricing models or business strategies, corporate teams need to collect and access multiple data points. They need to review data on client responses to past pricing models. Changes in consumer behavior, such as unusual buying patterns in specific regions, are of interest as well. CDC solutions can be used to feed all of these data points into the systems used by the corporate teams. Armed with these insights, teams can then develop better rates and policies. But if these pieces of information aren’t refreshed continuously, insurers may create policies using outdated data.
And information on new policies and rates needs to be quickly pushed to customer-facing apps and systems used by sales agents. Failure to do so may cause agents to prepare inaccurate offers to potential clients, for example. Once again, CDC solutions can be used to push data to specific apps or systems.
5. Change Data Capture improves a master data management system
IT teams can use CDC to draw data from multiple databases and continuously update the master data management (MDM) system, a master record of critical data. CDC, in combination with data integration tech, can transform or adjust data so it reaches MDM in the desired format. Various departments and systems can then pull data from the MDM system or use it for reporting, analysis, and operational purposes.
6. Change Data Capture integrates apps with otherwise incompatible databases
Businesses can use data integration platforms with CDC capabilities to integrate certain software tools into otherwise incompatible in-house database systems. Doing so provides teams with more flexibility when it comes to choosing and deploying business apps. Employees can now focus on working with apps that help the company reach its business goals instead of worrying about database compatibility.
7. Change Data Capture reduces pressure on operational databases
Companies can use CDC to create a copy of operational databases that users can then access. This reduces the stress on vital production systems by diverting heavy user traffic to a secondary database that’s constantly refreshed. The primary operational databases are then less likely to suffer issues, such as unanticipated downtime or poor performance.
Analytics queries, in particular, can consume a lot of processing power. Diverting them to secondary databases removes a major source of stress to the production system.
8. Change Data Capture acts as an integral part of your disaster recovery or backup plan
Businesses can use CDC to maintain the standby copy of their data that can be accessed in the event of a disaster. And disaster recovery solutions are mandatory in some industries where failures can lead to catastrophic consequences for users and businesses. CDC-powered disaster recovery plans can thus prevent major disruptions.
How to select Change Data Capture tools
Companies evaluate potential CDC solutions based on various factors. And while some companies may have industry-specific requirements, there are certain features that any platform with change data capture capabilities should have, including:
-
- Support for log reading
- Transaction integrity
- In-flight change data processing
- Distributed processing in a clustered environment
- Continuous monitoring of change data streams
- Real-time delivery to a wide range of targets
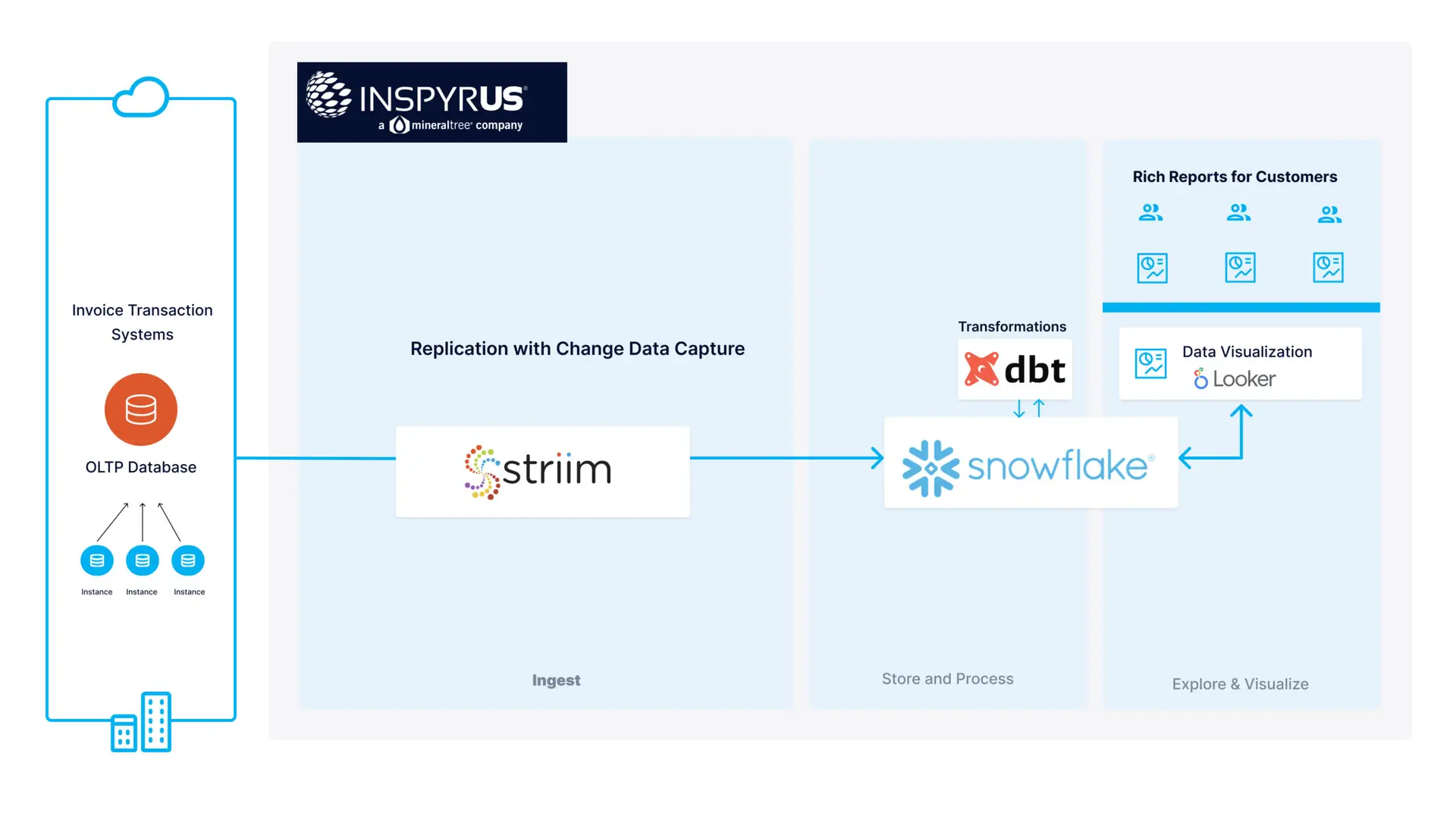
The fintech startup Inspyrus, for instance, is using Striim’s CDC capabilities to feed real-time operational data from its databases to Snowflake. As a result, customers can now access visualized real-time invoicing data and enjoy improved business intelligence reports.
Supercharging business growth
From improving data flows to strengthening data recovery solutions, change data capture can be of use in many ways. Getting the most value out of this technology is of vital importance. CDC enables teams to move and act on data quickly, producing new insights and business opportunities. And only then are companies able to use data as a fuel that supercharges their growth.