As a unified data streaming and integration company, the Striim platform sits at the heart of our customers’ data architecture. It is crucial that our customers trust our software, and our company, to always do the right thing from a security perspective.
With that in mind, we are thrilled to announce that Striim is now officially SOC 2 Type 1 certified.
A SOC 2 assessment report provides detailed information and assurance about an organization’s security, confidentiality, availability, processing integrity, and/or privacy controls, based on their assurance of compliance with the American Institute of Certified Public Accountants (AICPA) Trust Services Principles and Criteria for Security. A SOC 2 report is often the primary document that the security departments of our customers will rely on to assess Striim’s ability to maintain adequate security.
SOC 2 compliance comes in two forms: the SOC 2 Type 1 report which describes the design of the controls we have in place to meet relevant trust criteria at specific point in time; and a SOC 2 Type 2 report which details the operational effectiveness of those controls over a specified period of time. These reports are the results of audits performed by independent third parties, in our case Grant Thornton LLP.
We have completed SOC 2 Type 1 and are in the process of the requisite assessments over time to complete SOC 2 Type 2.
To achieve this certification, we have undergone a year-long effort to ensure that our people, principles, and processes are fully aligned with the level of security our customers would expect from a SaaS company. This has involved investments in training and new technologies to help automate processes and protect infrastructure, and a lot of documentation, reporting, and continual internal reviews.
The scope of the report covers all people, systems, and processes involved in getting the Striim software into the hands of our customers, whether they are using Striim on-premise, in their own cloud environment, utilizing containers, or are one of the initial Striim Cloud private preview customers.
SOC 2 is not just a certification, it is a way of thinking, and a journey that requires a deep dive into everything you do. Completing this certification has given us the opportunity to solidify security as a number one operating principle within the company, and ensure that all actions involve security considerations. Now that we have all of the required controls in place, we are working diligently to show how we can maintain those controls throughout the year, as we work towards SOC 2 Type 2 certification. We’ll keep you posted.
Data warehouses allow businesses to find insights by storing and analyzing huge amounts of data. Over the last few years, Snowflake, a cloud-native relational datawarehouse, has gained significant adoption across organizations for real-time analytics.
In this post, we’ll share an overview of real-time analytics with Snowflake, some challenges with real-time data ingestion in Snowflake, and how Striim addresses these challenges and enables users to optimize their costs.
Continuous Pipelines and Real-Time Analytics With Snowflake: Architecture and Costs
Snowflake’s flexible and scalable architecture allows users to manage their costs by independently controlling three functions: storage, compute, and cloud services. Consumption of Snowflake resources (e.g. loading data into a virtual warehouse and executing queries) is billed in the form of credits. Datastorage is billed at a flat-rate based on TB used/month. Storage and credits can be purchased on demand or up front (capacity).
In 2017, Snowflake introduced the Snowpipedata loading service to allow Snowflake users to continuously ingest data. This feature, together with Snowflake Streams and Tasks, allows users to create continuous data pipelines. As shown below, Snowpipe loads data from an external stage (e.g., AmazonS3). When data enters the external staging area, an event is generated to request data ingestion by Snowpipe. Snowpipe then copies files into a queue before loading them into an internal staging table(s). Snowflake Streams continuously record subsequent changes to the ingested data (for example, INSERTS or UPDATES), and Tasks automate SQL queries that transform and prepare data for analysis.
Creating a continuous data pipeline in Snowflake using Snowpipe to ingest data, and Streams and Tasks to automate change detection and data transformation. Image source: Snowflake docs.
While Snowpipe is ideal for many uses cases, continuous ingestion of large volumes of data can present challenges including:
Latency: On average, once a file notification is sent, Snowpipe loads incoming data after a minute. But when it comes to larger files, loading takes more time. Similarly, if your project requires an excessive amount of compute resources for performing decompression, description, and transformation on the fresh data, data ingestion with Snowpipe will take longer.
Cost: The utilization costs of Snowpipe include an overhead for managing files in the internal load queue. With more files queued for loading, this overhead will continue to increase over time. For every 1,000 files queued, you have to pay for 0.06 credits. For example, if your application loads 100,000 files into Snowflake daily, Snowpipe will charge you six credits.
Real-time Analytics With Striim and Snowflake: An Overview
Striim is a real-time data integration platform that enables you to process and analyze your streaming data and control how your data is uploaded to Snowflake.
With growing workloads, you can reduce costs incurred during real-time analytics by integrating Striim with Snowflake. Striim is an end-to-end data integration platform that enables enterprises to derive quick insights from high-velocity and high-volume data. Striim combines real-time data integration, streaming analytics and live data visualization, in a single platform.
Some benefits of using Striim for real-time analytics include:
Support for all types of data, including structured, unstructured, and semi-structured data from on-premise and cloud sources. High-performance change data capture from databases
In-memory, high-speed streaming SQL queries for in-flight transformation, filtering, enrichment, correlation, aggregation, and analysis. Live dashboards and visualizations
A customizable Snowflake Writer that gives users granular control over how data is uploaded to Snowflake
Next, we’ll share two examples demonstrating how Striim can support real-time analytics use cases while helping you optimize your Snowflake costs.
Optimize Snowflake Costs With Striim: Examples
Earlier, we discussed the latency and cost considerations for continuous ingestion with Snowpipe. Striim lets you minimize these costs via an “Upload Policy” that allows you to set parameters that control the upload to Snowflake. These parameters allow the Snowflake Writer, which writes to one or more tables in Snowflake, to consolidate the multiple input events of individual tables and perform operations on these groups of events with greater efficiency. You can control the number of events and set interval and file sizes. Unlike other tools that limit you to these settings at the global level, Striim goes one step further by allowing these configurations at the table level.
These events are staged to AWS S3, Azure Storage, or local storage, after which they are written to Snowflake. You can configure the Snowflake Writer in Striim to collect all the incoming events, batch them locally as a temp file, upload them to a stage table, and finally merge them with your final Snowflake table. Here’s what an example workflow would look like:
Example 1: Choose how to batch your data to meet your SLAs
The Snowflake Writer’s “Upload Policy” allows you to batch data at varying frequencies based on your company’s data freshness service level agreement (SLA). Data freshness is the latency between data origination and its availability in the warehouse. For example, data freshness can measure the time it takes for data to move from your sales CRM into your Snowflake warehouse. A data freshness SLA is a commitment that guarantees moving data within a specific period.
Let’s take a look at the following diagram to review how Striim manages data freshness SLAs. If you have a large data warehouse, then you often need critical data views (e.g., customer data) and reports. With a 5-minute data freshness SLA, you can ensure that this data loads into your data warehouse five minutes after it’s generated in its data source (e.g., ERP system). However, for other use cases, such as reports, you don’t necessarily need data immediately. Hence, you can settle with a 30-minute data freshness SLA. Depending on how fast you need data, Striim uses fast or medium/low SLA tables to deliver data via its SnowflakeWriter.
While other tools have a sync frequency, Striim has come up with an innovative way of handling data freshness SLAs. For instance, if 50% of your tables can be reported with a one-hour data freshness SLA, 35% with a 30-minute SLA, and 15% with a five-minute SLA, you can split up these tables. This way, you can use Striim to optimize the cost of ingesting your data.
In addition to giving you granular control over the upload process, Striim enables you to perform in-flight, real-time analysis of your data before it’s uploaded to Snowflake. Striim is horizontally scalable, so there are no limitations if you need to analyze large volumes of data in real time. So, even if you choose to batch your data for Snowflake, you can still analyze it in real time in Striim.
Example 2: Reduce costs by triggering uploads based on a given time interval
As mentioned previously, the Snowflake Writer’s “Upload Policy” governs how and when the upload to Snowflake is triggered. Two of the parameters that control the upload are “EventCount”and “Interval”. So, which one of these two parameters yields lower latencies and costs? In most cases using the “Interval” parameter is a better option; here’s an example to show why.
Assume that a system is producing 100k events a minute. Setting an “UploadPolicy = EventCount:10000” would instruct Snowflake Writer to work on 10 upload, merge tasks (100,000/10,000). Assume that each upload, merge takes one minute to complete. So it will take at least 10 minutes to process all 100k events. At the end of the fifth minute, the source would have pumped another 500k events, and Snowflake Writer will be processing another 40 upload, merge tasks (400,000/10,000). In this configuration, you could see the lag increase over time.
If you go with the “Interval” approach, you would get better results. Assume the value of “UploadPolicy = Interval:5m” would instruct the Snowflake Writer to upload, merge tasks every five minutes. It means that every five minutes, Snowflake Writer would receive 500,000 events from the source and process upload, merge in two minutes (assumption). You could see a constant latency of seven minutes (five-minute interval + two-minute upload, merge time) across all the batches.
Cost is another advantage of the “Interval” based approach. In the “EventCount” based approach, you are keeping the Snowflake virtual warehouses always active. For the “EventCount” based approach, Snowflake Writer is active for the entire five minutes as opposed to two minutes for the “Interval” based approach. Therefore, this approach can help you optimize your Snowflake costs.
Go Through Striim Documentation to Improve Your Data-Centric Operations
If you’d like to optimize your other data-related workloads, Striim’s documentation shows some of the things that you can do.
Go through theWeb UI Guide to learn about Striim’s browser-based user interface.
Go through theDashboard Guide to build and edit dashboards and visualizations.
Go through theProgrammer’s Guide to create and edit Striim applications.
Want a customized walkthrough of the Striim platform and its real-time integration and analytics capabilities? Request a demo with one of our platform experts, or alternatively, try Striim for free.
As more companies rely on data to drive critical business decisions, improve product offerings, and serve customers better, the amount of data companies capture is higher than ever. Thisstudy by Domo estimates 2.5 quintillion bytes of data were generated every day in 2017, with this figure set to increase to463 exabytes in 2025. But what good is all that data if companies can’t utilize it quickly? The topic of the most optimal data storage for data analytics needs has beenlong debated.
Data warehouses and data lakes have been the most widely used storage architectures for big data. But what about using a data lakehouse vs. a data warehouse? A data lakehouse is a new data storage architecture that combines the flexibility of data lakes and the data management of data warehouses.
Depending on your company’s needs, understanding the different big-data storage techniques is instrumental to developing a robust data storage pipeline for business intelligence (BI), data analytics, and machine learning (ML) workloads.
A data warehouse is a unified data repository for storing large amounts of information from multiple sources within an organization. A data warehouse represents a single source of “data truth” in an organization and serves as a core reporting and business analytics component.
Typically, data warehouses store historical data by combining relational data sets from multiple sources, including application, business, and transactional data. Data warehouses extract data from multiple sources and transform and clean the data before loading it into the warehousing system to serve as a single source of data truth. Organizations invest in data warehouses because of their ability to quickly deliver business insights from across the organization.
Data warehouses enable business analysts, data engineers, and decision-makers to access data via BI tools, SQL clients, and other less advanced (i.e., non-data science) analytics applications.
Data warehouses, when implemented, offer tremendous advantages to an organization. Some of the benefits include:
Improving data standardization, quality, and consistency: Organizations generate data from various sources, including sales, users, and transactional data. Data warehousing consolidates corporate data into a consistent, standardized format that can serve as a single source of data truth, giving the organization the confidence to rely on the data for business needs.
Delivering enhanced business intelligence: Data warehousing bridges the gap between voluminous raw data, often collected automatically as a matter of practice, and the curated data that offers insights. They serve as the data storage backbone for organizations, allowing them to answer complex questions about their data and use the answers to make informed business decisions.
Increasing the power and speed of data analytics and business intelligence workloads: Data warehouses speed up the time required to prepare and analyze data. Since the data warehouse’s data is consistent and accurate, they can effortlessly connect to data analytics and business intelligence tools. Data warehouses also cut down the time required to gather data and give teams the power to leverage data for reports, dashboards, and other analytics needs.
Improving the overall decision-making process: Data warehousing improves decision-making by providing a single repository of current and historical data. Decision-makers can evaluate risks, understand customers’ needs, and improve products and services by transforming data in data warehouses for accurate insights.
For example,Walgreens migrated its inventory management data into Azure Synapse to enable supply chain analysts to query data and create visualizations using tools such as Microsoft Power BI. The move to a cloud data warehouse also decreased time-to-insights: previous-day reports are now available at the start of the business day, instead of hours later.
The disadvantages of a data warehouse
Data warehouses empower businesses with highly performant and scalable analytics. However, they present specific challenges, some of which include:
Lack of data flexibility: Although data warehouses perform well with structured data, they can struggle with semi-structured and unstructured data formats such as log analytics, streaming, and social media data. This makes it hard to recommend data warehouses for machine learning and artificial intelligence use cases.
High implementation and maintenance costs: Data warehouses can be expensive to implement and maintain. This article by Cooladata estimates theannual cost of an in-house data warehouse with one terabyte of storage and 100,000 queries per month to be $468,000. Additionally, the data warehouse is typically not static; it becomes outdated and requires regular maintenance, which can be costly.
What Is a Data Lake?
A data lake is a centralized, highly flexible storage repository that stores large amounts of structured and unstructured data in its raw, original, and unformatted form. In contrast to data warehouses, which store already “cleaned” relational data, a data lake stores data using a flat architecture and object storage in its raw form. Data lakes are flexible, durable, and cost-effective and enable organizations to gain advanced insight from unstructured data, unlike data warehouses that struggle with data in this format.
In data lakes, the schema or data is not defined when data is captured; instead, data is extracted, loaded, and transformed (ELT) for analysis purposes. Data lakes allow for machine learning and predictive analytics using tools for various data types from IoT devices, social media, and streaming data.
Because data lakes can store both structured and unstructured data, they offer several benefits, such as:
Data consolidation: Data lakes can store both structured and unstructured data to eliminate the need to store both data formats in different environments. They provide a central repository to store all types of organizational data.
Data flexibility: A significant benefit of data lakes is their flexibility; you can store data in any format or medium without the need to have a predefined schema. Allowing the data to remain in its native format allows for more data for analysis and caters to future data use cases.
Cost savings: Data lakes are less expensive than traditional data warehouses; they are designed to be stored on low-cost commodity hardware, like object storage, usually optimized for a lower cost per GB stored. For example,Amazon S3 standard object storage offers an unbelievable low price of $0.023 per GB for the first 50 TB/month.
Support for a wide variety of data science and machine learning use cases: Data in data lakes is stored in an open, raw format, making it easier to apply various machine and deep learning algorithms to process the data to produce meaningful insights.
The disadvantages of a data lake
Although data lakes offer quite a few benefits, they also present challenges:
Poor performance for business intelligence and data analytics use cases: If not properly managed, data lakes can become disorganized, making it hard to connect them with business intelligence and analytics tools. Also, a lack of consistent data structure and ACID (atomicity, consistency, isolation, and durability) transactional support can result in sub-optimal query performance when required for reporting and analytics use cases.
Lack of data reliability and security: Data lakes’ lack of data consistency makes it difficult to enforce data reliability and security. Because data lakes can accommodate all data formats, it might be challenging to implement proper data security and governance policies to cater to sensitive data types.
What Is a Data Lakehouse? A Combined Approach
A data lakehouse is a new, big-data storage architecture that combines the best features of both data warehouses and data lakes. A data lakehouse enables a single repository for all your data (structured, semi-structured, and unstructured) while enabling best-in-class machine learning, business intelligence, and streaming capabilities.
Data lakehouses usually start as data lakes containing all data types; the data is then converted toDelta Lake format (an open-source storage layer that brings reliability to data lakes). Delta lakes enable ACID transactional processes from traditional data warehouses on data lakes.
The benefits of a data lakehouse
Data lakehouse architecture combines a data warehouse’s data structure and management features with a data lake’s low-cost storage and flexibility. The benefits of this implementation are enormous and include:
Reduced data redundancy: Data lakehouses reduce data duplication by providing a single all-purpose data storage platform to cater to all business data demands. Because of the advantages of the data warehouse and the data lake, most companies opt for a hybrid solution. However, this approach could lead to data duplication, which can be costly.
Cost-effectiveness: Data lakehouses implement the cost-effective storage features of data lakes by utilizing low-cost object storage options. Additionally, data lakehouses eliminate the costs and time of maintaining multiple data storage systems by providing a single solution.
Support for a wider variety of workloads: Data lakehouses provide direct access to some of the most widely used business intelligence tools (Tableau,PowerBI) to enable advanced analytics. Additionally, data lakehouses use open-data formats (such as Parquet) with APIs and machine learning libraries, including Python/R, making it straightforward for data scientists and machine learning engineers to utilize the data.
Ease of data versioning, governance, and security: Data lakehouse architecture enforces schema and data integrity making it easier to implement robust data security and governance mechanisms.
The disadvantages of a data lakehouse
The main disadvantage of a data lakehouse is it’s still a relatively new and immature technology. As such, it’s unclear whether it will live up to its promises. It may be years before data lakehouses can compete with mature big-data storage solutions. But with the current speed of modern innovation, it’s difficult to predict whether a new data storage solution could eventually usurp it.
Data Warehouse vs. Data Lake vs. Data Lakehouse: A Quick Overview
The data warehouse is the oldest big-data storage technology with a long history in business intelligence, reporting, and analytics applications. However, data warehouses are expensive and struggle with unstructured data such as streaming and data with variety.
Data lakes emerged to handle raw data in various formats on cheap storage for machine learning and data science workloads. Though data lakes work well with unstructured data, they lack data warehouses’ ACID transactional features, making it difficult to ensure data consistency and reliability.
The data lakehouse is the newest data storage architecture that combines the cost-efficiency and flexibility of data lakes with data warehouses’ reliability and consistency.
This table summarizes the differences between the data warehouse vs. data lake vs. data lakehouse.
Data Warehouse
Data Lake
Data Lakehouse
Storage Data Type
Works well with structured data
Works well with semi-structured and unstructured data
Can handle structured, semi-structured, and unstructured data
Purpose
Optimal for data analytics and business intelligence (BI) use-cases
Suitable for machine learning (ML) and artificial intelligence (AI) workloads
Suitable for both data analytics and machine learning workloads
Cost
Storage is costly and time-consuming
Storage is cost-effective, fast, and flexible
Storage is cost-effective, fast, and flexible
ACID Compliance
Records data in an ACID-compliant manner to ensure the highest levels of integrity
Non-ACID compliance: updates and deletes are complex operations
ACID-compliant to ensure consistency as multiple parties concurrently read or write data
The “data lakehouse vs. data warehouse vs. data lake” is still an ongoing conversation. The choice of which big-data storage architecture to choose will ultimately depend on the type of data you’re dealing with, the data source, and how the stakeholders will use the data. Although a data lakehouse combines all the benefits of data warehouses and data lakes, we don’t advise you to throw your existing data storage technology out the window for a data lakehouse.
Data Lakehouse vs. Data Warehouse vs. Data Lake: Which One Is Right for Your Needs?
Data lakehouses can be complex to build from scratch. And you’ll most likely use a platform built to support open data lakehouse architecture. So, ensure you research each platform’s different capabilities and implementations before making a purchase.
A data warehouse is a good choice for companies seeking a mature, structured data solution that focuses on business intelligence and data analytics use cases. However, data lakes are suitable for organizations seeking a flexible, low-cost, big-data solution to drive machine learning and data science workloads on unstructured data.
Suppose the data warehouse and data lake approaches aren’t meeting your company’s data demands, or you’re looking for ways to implement both advanced analytics and machine learning workloads on your data. In that case, a data lakehouse is a reasonable choice.
Whichever solution you choose,Striimcan help. Striim makes it simple to continuously and non-intrusively ingest all your enterprise data from various sources in real-time for data warehousing. Striim can also be used to preprocess your data in real-time as it is being delivered into the data lake stores to speed up downstream activities.
The demand for data engineers and data architects is higher than ever. A report by Opinium, in collaboration with the UK’s Department for Digital, Culture, Media and Sport, shows UK companies alone are currently recruiting for 178,000 to 234,000 roles that require hard data skills. And as we continue to generate and use data to enhance critical business decisions, the demand for data professionals will continue to increase.
The data architect and data engineer roles are sometimes used interchangeably. Although there is some overlap, and they share some specific duties, understanding how both roles operate in the organization can benefit engineering managers looking to build an engineering team and students and professionals looking to develop a career in either field.
What Is a Data Architect? The Role and Its Responsibilities
A data architect is responsible for formulating the organizational data strategy and defining the data management standards and principles on which the organization operates. Data architects design the “data blueprint” that other data consumers follow and implement.
They create the organization’s logical and physical data assets and set data policies based on company requirements. Data architects are often veterans in the industry who have had experience in many data roles and have gained experience navigating complex business scenarios and designing solutions that data teams can implement.
Data architect responsibilities
The data architect’s primary responsibility revolves around providing deep technical expertise for designing, creating, managing, and deploying large-scale data systems in the organization.
A data architect’s responsibilities include:
Designing, developing, implementing, and translating business requirements and the overall organizational data strategy, including standards, principles, data sources, storage, pipelines, data flow, and data security policies
Collaborating with data engineers, data scientists, and other stakeholders to execute the data strategy
Communicating and defining data architecture patterns in the organization that guide the data framework
Leading data teams to develop secure, scalable, high-performance, and reliable big data and analytics software and services
What skills do data architects have?
Data architects need a combination of technical and soft skills to thrive. Typically, data architects start in other data roles, such as data scientist, data analyst, or data engineer, and work their way up to becoming data architects after years of experience with data modeling, data design, and data management. Some of the skills data architects have include:
Data modeling, integration, design, and data management: Data architects understand the concepts, principles, and implementation of data modeling, design, and data management. They can produce relevant data models and design the organization’s data flow.
Databases and operating systems: Data architects are experienced in the various SQL and NoSQL databases. They understand the advantages and drawbacks of each and how they can be set up effectively and securely across different operating systems (Linux, Windows) and environments (development and production).
Data architecture: Data architects know the best practices on data architecture for enterprise data warehouse development. They have a solid understanding of the organization’s data infrastructure and how different systems interact.
Data security and governance: Data architects understand the processes, roles, policies, standards, and metrics that ensure the effective and efficient use of data/information. Data architects are skilled in data governance strategies with a good understanding of the risks and mitigations of each. They ensure data governance is in line with the overall organizational strategy.
Communication and leadership: Data architects are usually leaders of the data management team; as such, they must communicate clear technical solutions to complex data problems to both technical and non-technical audiences.
Although every organization has slightly different requirements, you’ll notice similar skills and common themes (like the ones outlined above) throughout job descriptions for this role. For example, this data solutions architect role with Lightspeed asks that candidates have experience with data management for software as a service (SaaS) tools and build data solutions and models for this team.
What Is a Data Engineer? The Role and Its Responsibilities
A data engineer is responsible for designing, maintaining, and optimizing data infrastructure for data collection, management, transformation, and access. Data engineers create pipelines that convert raw data into usable formats for data scientists and other data consumers to utilize.
The data engineer role evolved to handle the core data aspects of software engineering and data science; they use software engineering principles to develop algorithms that automate the data flow process. They also collaborate with data scientists to build machine learning and analytics infrastructure, from testing to deployment.
Data engineer responsibilities
The primary responsibility of a data engineer is ensuring that data is readily available, secure, and accessible to stakeholders when they need it.
A data engineer’s responsibilities typically include:
Building and maintaining data infrastructure for the optimal extraction, transformation, and loading of data from a wide variety of sources such as Amazon Web Services (AWS) and Google Cloud big data platforms
Ensuring data accessibility at all times and implementing company data policies with respect to data privacy and confidentiality
Cleaning and wrangling data from primary and secondary sources into formats that can be efficiently utilized by data scientists and other data consumers
Collaborating with engineering teams, data scientists, and other stakeholders to understand how data can be leveraged to meet business needs
What skills do data engineers have?
Data engineering is a synthesis of software engineering and data science, so knowledge of both fields is advantageous. Because data engineering is heavily reliant on programming, most data engineers begin their careers as software engineers and then pivot to data engineering.
Some of the skills required of data engineers include:
Database systems (SQL and NoSQL): Data engineers have a good knowledge of SQL and NoSQL databases and are skilled in writing queries to manipulate and retrieve data.
Data migration and integration: Data engineers are often tasked with aggregating data from multiple sources and migrating data from one platform to another based on business needs. Data engineers understand data migration and integration techniques (Big-Bang, trickle, lift and shift )and the tools required to perform them. Striim is a popular tool used by data engineers for data integration and migration; it provides modern, reliable data integration and migration across the public and private cloud.
Data wrangling: Data wrangling is the process of gathering, cleaning, enriching, and transforming data into the desired format to incorporate better decision-making in less time. A data engineer is skilled in various data wrangling techniques and tools, such as extraction, transformation, and loading (ETL).
Data processing techniques and tools: Data engineers are experienced in various data processing techniques, such as real-time processing and batch processing; they are comfortable working with data processing tools such as Apache Kafka and Apache Spark.
Programming languages (Python): Data engineering relies heavily on programming; data engineers are typically fluent in at least one programming language, with Python being regarded as the most popular and widely used programming language in the data engineering community.
Cloud computing and distributed systems: With more companies relying on cloud providers for data infrastructure needs, companies rely on data engineers to create data solutions using popular cloud providers, such as Amazon Web Services, Google Cloud, and Azure. Data engineers have experience working with tools such as Hadoop for the distributed processing of large datasets.
Although each organization’s requirements are slightly different, you’ll notice similar skills and common themes (such as the ones outlined above) throughout the job descriptions for data engineer roles. For example, the candidate for this data engineer, infrastructure engineering role at TikTok will be responsible for collaborating with software engineers and data scientists to build big data solutions.
Data Architect vs. Data Engineer: What Are the Differences?
The data architect and data engineer titles are closely related and, as such, frequently confused. The difference in both roles lies in their primary responsibilities.
Data architects design the vision and blueprint of the organization’s data framework, while the data engineer is responsible for creating that vision.
Data architects provide technical expertise and guide data teams on bringing business requirements to life; data engineers ensure data is readily available, secure, and accessible to stakeholders (data scientists, data analysts) when they need it.
Data architects have substantial experience in data modeling, data integration, and data design and are often experienced in other data roles; data engineers have a strong foundation in programming with software engineering experience.
The data architect and the data engineer work together to build the organization’s data system.
Here’s a table to briefly summarize the key differences and help you visualize the contrast in responsibilities:
Data Architect
Data Engineer
Visualizes the blueprint for the organizational data framework, defining how the data will be stored, consumed, integrated, and managed by different data entities and IT systems
Builds and maintains the data systems and information specified by data architects in the data framework
Deep expertise in databases, data modeling, data architecture, and operating systems
Strong background in software engineering, algorithms, and application development
Focused on leadership and high-level data strategy
Focused on the day-to-day tasks of cleaning, wrangling, and preparing data for other data consumers, such as data scientists
Data Architect vs. Data Engineer: Which Is Right for You?
When choosing a career or hiring, note that the data architecture role requires years of experience in a previous data-related role; both roles require a deep understanding of database systems, data processing tools, and experience working with big data. To put together an effective data management team, you must first understand the differences between the roles.
When interviewing for data engineers, consider whether the candidate has experience building software and APIs, as well as a solid understanding of various databases, data wrangling, and data processing techniques.
For data architects, on the other hand, be sure to ask what data projects they’ve led in the past and get a sense of their “data philosophy.” Remember that a data architect will be the leader of your data management team to whom you should feel confident delegating authority.
Today, organizations are developing data architectures and infrastructures that use real-time streaming data, making data governance more crucial than ever. When a large amount of data has to be rapidly processed in near real-time, data in motion in the form of streaming data is an excellent option.
Governing data at rest (i.e., data stored in databases) wasn’t easy in the first place; now, organizations have to deal with a tougher challenge following the rise of data in motion (i.e., data that is moved between different sources and environments). As more and more data is streamed in real-time, managing streams spread across multiple sources and apps (e.g., databases and CRMs) takes the matter to a whole new level.
There is a gap in the data governance space. Organizations use data governance tools that are more suited for managing data at rest. However, the growing adoption of big data analytics means that managing data in motion is more crucial than ever.Striim has prioritized addressing this vacuum by introducing solutions to some of the most common data governance challenges.
Data security is one of the major data governance challenges. But, you can only secure data that you’re aware of. That’s why a data governance team always sets a certain objective: Identify and classify the data that exists within the enterprise.
It’s common for businesses to have complex data environments that are often all over the place. Developing a framework to find data sources on a continuous basis is a tough nut to crack, and keeping data categorized is equally challenging.
Solution: Striim enables data discovery
To discover and classify your data, you have to answer a few questions, such as:
Where is the data located?
Who can access the data?
How long will you keep the data?
Striim can help you resolve your data issues by bringing your streaming data into a centralized location (e.g. a data warehouse) where a data catalog solution can provide a bird’s-eye view of all the data within your organization. Furthermore, Striim allows you to enrich your data with reference data to make your data more meaningful. For example, a B2B company may use a relational database to store order information. With a normalized schema, many of the data fields are in the form of IDs, e.g. the “Orders” table may have a column for “Sales Rep ID”. Striim can add valuable context to the “Orders” data by adding sales rep names and emails (from the “SalesRep” table) to the streaming data en route to a data warehouse.
Striim enriches the “Orders” stream with cached data from the “SalesRep” table (name, email)
Once the data is centralized, a data catalog arranges data into an easy-to-understand format, allowing data users to use it readily. It also addresses multiple data governance issues. For example, your data catalog can connect siloed data, which can help to fix data inconsistencies and improve data quality. Or, you can use it to control data for compliance.
You can use these catalogs to store metadata and integrate it with data collaboration, management, and search tools (e.g., Tableau, Elasticsearch). This way, your users can locate and utilize relevant data instantly. It provides context to your data roles. For instance, your data scientists can use a data catalog to find and understand a dataset, which can uncover crucial insights. These can be market trends, correlations, hidden patterns, and customer preferences to help your business make informed business decisions.
And if you’re using Confluent’s streaming platform, Striim offers a seamless integration with Confluent’s schema registry and serialization layer. This enables you to stream data (from databases and other sources) into Confluent and leverage their recently-released Stream Governance features.
Challenge #2: Loose permissions for data access
Often, organizations grant extremely broad permissions to their data teams for data access. As a result, the lines between the responsibilities of data governance roles like chief data officer, data custodian, data steward, data trustee, data owner, and data user are blurred. This lack of access control can also make it difficult to minimize data privacy risks and maximize accountability.
Some organizations manage their data governance by tracking data access through access logs, but this presents its own set of challenges. That’s because each data technology comes with its own log system that stores varying information. You also need context to understand these logs, such as who accessed the data and what they did with it. This context is often stored in various tools that are incompatible with access logs. There’s a clear need for a better solution.
Solution: Striim offers role-based access control to enforce better control over data
Roles and responsibilities form the cornerstone of an effective data governance strategy. Data governance holds people accountable for performing the right set of actions at the right time. To do this, Striim can help with the definition and deployment of roles that are suited to the organizational structure and culture. This is done through role-based access control (RBAC), allowing you to control what your business users can do at both granular and broad levels.
For example, you can designate whether the user is a data custodian, data trustee, or data user and assign roles and data access permissions based on employees’ positions in your organization.
The main objective of RBAC is to provide a framework that lets organizations set and enforce access control policies for their data, which helps to streamline data governance. It grants permissions to ensure that employees receive adequate access — good enough to help them do their jobs.
With Striim, you can set roles and privileges to access all objects. An object in Striim can be many things, including sources, targets, streams, flow, and so on.
Your admins can define roles with different access levels and controls on objects, such as:
A group of users who can create and edit any type of object.
A group of users who can copy and read data from objects but aren’t allowed to edit them.
For example, you may have a connector that reads data with PII (‘Personal Identifiable Information’). You can create a specific permission to read the objects that contain PII and assign permission only to users with that degree of authorization.
In Striim, user permissions control which actions given users can take on different object types (for example, streams or sources).
Challenge #3: Teams share the same data implementation
A common data governance challenge is when different departments use the same application for their data-related tasks. The data team configures a data infrastructure or system that several other departments use for the collection of accurate data. However, a lack of communication can lead to an employee breaking the system.
For instance, suppose multiple teams share the same website and data analytics infrastructure. The goal of the IT team will be to use the data from analytics to fix the website’s functionality and security. On the other hand, a marketing team will be crunching the numbers to find ways to improve customer experience. Unfortunately, the difference in these team goals can lead to ongoing blunders, such as double-tagging or interrupted customer journeys.
Solution: Striim uses apps and app groups to divide workloads
You can use apps and app groups in Striim to divide workloads between teams. Striim supports data orchestration — essentially, you can use Striim’s user interface and REST APIs to automate the data in flight between your event tracking, data loader, modeling, and data integration tools.
Organizations can create a dedicated app for each business group to build a domain-specific view or transformation for analysis. That means that both your marketing and IT teams can have their own data workflows, empowering them to work more freely without one department affecting another.
For example, you can dedicate a group of Striim apps to collect streaming data from streaming databases and transfer it to a data warehouse for data analysis. Similarly, you can have a Striim app for data transformation that uses Python scripts to convert data from your sources to a standardized format.
A Striim app to stream data to collect streaming data from MySQL(via Change Data Capture) to Kafka
Challenge #4: Lack of security for data in motion
Data in motion is exposed to a wide range of risks. Unlike data at rest, it travels both inside and outside the organization. These days, it’s important to protect data in motion because modern regulatory guidelines likeHIPAA,GDPR, andPCI DSS enforce the protection of data in motion.
Solution: Striim offers advanced security features to protect data in motion
Striim protects data in motion with a number of security initiatives. Some of these include:
Striim helps you to set an encryption policy to encrypt your data with encryption algorithms, such as RSA (Rivest–Shamir–Adleman), PGP (Pretty Good Privacy), and AES (Advanced Encryption Standard). This can especially come in handy in compliance-based industries (e.g., healthcare) and help protect data like PHI (protected health information) and PII (personally identifiable information).
Striim has multi-layered application security for exporting and importing data pipeline applications. For instance, during the import of these applications, you can set a passphrase for applications that contain passwords and other encrypted values. This way, you can incorporate an additional security layer into your application security.
Striim has a secure, centralized repository, Striim Vault, which can serve as a go-tool for storing passwords and encryption keys. Striim’s vault also integrates seamlessly with 3rd party vaults such as HashiCorp
A reliable data governance program is key to addressing your data governance challenges
The value of data governance is understated.A reliable data governance program increases the trust of people in your data analytics, business processes, and systems that power your data-driven decision-making. It offers secure access, enabling IT to successfully oversee the management of data sources and analytical content and meet policy, risk, and compliance requirements. Line-of-business employees can instantly locate the data they need and perform their jobs better.
Streamline your enterprise data governance framework with Striim. Learn more about how Striim can enhance your data governance initiatives by getting atechnical demo.
Data engineer roles have gained significant popularity in recent years.This study by Dice shows that the number of data engineering job listings has increased by 15% between Q1 2021 to Q2 2021,up 50% from 2019.
In addition to being an in-demand role, working as a data engineer can allow you to solve problems, experiment with large datasets, and understand patterns in our world. Students and professionals looking for a switch to a technology role should consider a career in data engineering.
To help you understand the requirements of a data engineer, we’ve compiled the roles and responsibilities of data engineers, the tools they use, and what you need to get started as a data engineer.
What is a Data Engineer: An Overview of the Responsibilities
Data engineers are responsible for designing, maintaining, and optimizing data infrastructure for data collection, management, transformation, and access. They are in charge of creating pipelines that convert raw data into usable formats for data scientists and other data consumers to utilize. The data engineer role evolved to handle the core data aspects of software engineering and data science; they use software engineering principles to develop algorithms that automate the data flow process. They also collaborate with data scientists to build machine learning and analytics infrastructure from testing to deployment.
Data engineers help organizations structure and access their data with the speed and scalability they need and provide the infrastructure to enable teams to deliver great insights and analytics from that data.Kevin Wylie, a data engineer with Netflix,says his work is about making the lives of data consumers easier and enabling these consumers to be more impactful.
Most times, the format/structure optimal to store data for an application is rarely optimal for data science/reporting/analytics. For example, your application may need to be able to serve one million concurrent requests for individual records. But your data science team might need to access billions of records per time. Both scenarios will require different approaches to solve their problems, and this is where data engineers can help.
The primary responsibility of a data engineer is ensuring that data is readily available, secure, and accessible to stakeholders when they need it. Data engineering responsibilities can be grouped into two main categories:
Data structure and management
Data engineers are responsible for implementing and maintaining the underlying infrastructure and architecture for data generation, storage, and processing. Their responsibilities include:
Building and maintaining data infrastructure for optimal extraction, transformation, and loading of data from a wide variety of sources such as Amazon Web Services (AWS) and Google Cloud big data platforms.
Ensuring data accessibility at all times and implementing company data policies with respect to data privacy and confidentiality.
Improving data systems reliability, speed, and performance.
Creating optimal data warehouses, pipelines, and reporting systems to solve business problems.
Data analysis and insight
Data engineers play an important role in building platforms that enable data consumers to analyze and gain insights from data. They are responsible for:
Cleaning and wrangling data from primary and secondary sources into formats that can be easily utilized by data scientists and other data consumers.
Developing data tools and APIs for data analysis.
Deploying and monitoring machine learning algorithms and statistical methods in production environments.
Collaborating with engineering teams, data scientists, and other stakeholders to understand how data can be leveraged to meet business needs.
Although every organization has slightly different requirements, data engineering job listings from top tech company’s career sites likeNetflix andGoogleand articles from job sites such asIndeed can provide more information on what data engineers are commonly responsible for in an organization.
Data Engineers vs. Data Scientists vs. Data Architects: What are the Differences?
From a thankful data scientist to data engineers. Original post here.
These roles vary significantly from company to company and often overlap since their work usually revolves around the same key component: data. Larger companies tend to have separate departments for these roles, and in smaller companies, it’s not uncommon to have one person acting as all three.
This table gives a brief overview of the differences between the three roles.
Data Architect
Data Engineer
Data Scientist
Data architects plan and design the framework the data engineers build. They create the organization’s logical and physical data assets, as well as the data management resources, and they set data policies based on company requirements.
Data engineers are responsible for gathering, collecting, and processing data. They also build systems, algorithms, and APIs to expose datasets to data consumers.
Data scientists are responsible for performing statistical analysis using machine learning and artificial intelligence on collated data in order to gain insight and form new hypotheses.
Unless a company has a large data/engineering team, it’s unlikely to have all three of these roles and will likely employ some combination of the above based on engineering, data, and business needs. Read more: For a deeper dive into how data architects and data engineers differ in responsibilities, skill sets, and career paths, see our comparison: Data Architect vs. Data Engineer.
What Tools Do Data Engineers Use?
There are no one-size-fits-all tools data engineers use. Instead, each organization leverages tools based on business needs. However, below are some of the popular tools data engineers use. You don’t necessarily have to gain mastery of all the tools here, but we recommend you learn the fundamentals of each core tool.
Databases
In our fast-paced world where tools and technologies are constantly evolving, SQL remains central to it all and is a foundational tool for data engineers. SQL is the standard programming language for creating and managing relational database systems (a collection of tables that consist of rows and columns).
NoSQL databases are non-tabular and can take the form of a graph or a document, depending on their data model. Popular SQL databases include MYSQL, PostgreSQL, and Oracle. MongoDB, Cassandra, and Redis are examples of popular NoSQL databases.
Data processing
Today’s businesses recognize the importance of processing data in real-time to enhance business decisions. As a result, data engineers are in charge of building real-time data streaming and data processing pipelines.Apache Spark is an analytics engine used for real-time stream processing;Apache Kafka is a popular tool for building streaming pipelines and is used by more than80% of fortune 500 companies.
Data engineers are typically fluent in at least one programming language to create software solutions to data challenges.Python is regarded as the most popular and widely used programming language in the data engineering community. It’s easy to learn and features a simple syntax and an abundance of third-party libraries geared toward data needs.
Data migration and integration
As more companies leverage cloud-based computing to meet business demands, migrating mission-critical applications can introduce several challenges of which migrating the underlying database is often the most difficult. Data migration and integration refer to the processes involved in moving data from one system or systems to another without compromising its integrity. Data integration specifically is the process of consolidating data from various sources and combining it in a meaningful and valuable way.
Striim is a popular real-time data integration platform used by data engineers for both data integration and migration; it provides modern, reliable data integration and migration across the public and private cloud.
Distributed systems
Because of the massive amount of data in circulation today, a single machine/system cannot meet data processing and storage requirements. Distributed systems are systems that work together to achieve a common goal but appear to the end-user as a single system.
Hadoop is a popular data engineering framework for storing and computing large amounts of data using a network of computers.
Data science and machine learning
Data engineers need a basic understanding of popular data science tools because it enables them better to understand data scientists and other data consumers’ needs.PyTorch is an open-source machine learning library used for deep learning applications using GPUs and CPUs.TensorFlow is a free, open-source machine learning platform that provides tools for teams to create and deploy machine learning-powered applications.
What Skills Do I Need to Learn to be a Data Engineer?
Data engineering is a developing field that bisects software engineering and data science. While there are no defined steps to becoming a data engineer, that doesn’t mean you can’t do it.
Here are some of the necessary skills and knowledge you need to become a successful data engineer.
Understand databases (SQL and NoSQL): An essential skill for data engineers is learning how databases work and how to write queries to manipulate and retrieve data. Thisfree database systems course by freeCodeCamp and Cornell University is an excellent resource to learn how database systems work.
Understand data processing techniques and tools:LinkedIn Learningprovides fantastic resources to learn Apache Kafka – a popular tool for data processing.
Know a programming language: Knowing how to program is a must-have skill for data engineers. Programming languages such as Python and Scala are popular with data engineers.The complete Python Bootcamp on Udemy is a popular resource for getting started with Python.
Understand how distributed systems work:Designing Data-Intensive Applications is a great resource to understand the fundamental challenges companies face when designing large data applications.
Learn about cloud computing: With more companies relying on cloud providers for data infrastructure needs, learning how to design and engineer data solutions using popular cloud providers such as Amazon Web Services, Google Cloud, and Azure will help you stand out as a data engineer.Online courses, official tutorials, and certifications from cloud providers (like this one fromGoogle Cloud) are excellent ways to learn cloud computing.
Research from Domo estimates that humans generate about2.5 quintillion bytes of data per day through social media, video sharing, and other means of communication. Furthermore, the World Economic Forum predicts that by 2025,the world will generate 463 exabytes of data per day, the equivalent of 212,765,957 DVDs per day. With the copious amount of data generated, there will be an increase in the demand for data engineers to manage it.
If you love experimenting with data, using it to discover patterns in technology or enjoy building systems that organize and process data to help companies make data-driven decisions, you might consider a career in data engineering. Further, data engineering is a lucrative field, with amedian base salary of $102,472. While data engineering can be difficult and complex, and you may need to learn new skills and technology, it is also a rewarding career in a growing field.
Insight-driven businesses have the edge over others; they grow at an average of more than 30% annually. Noting this pattern, modern enterprises are trying to become data-driven organizations and get more business value out of their data. But the rise of cloud, the emergence of the Internet of Things (IoT), and other factors mean that data is not limited to on-premises environments.
In addition, there are voluminous amounts of data, many data types, and multiple storage locations. As a consequence, managing data is getting more difficult than ever.
One of the ways organizations are addressing these data management challenges is by implementing a data fabric. Using a data fabric is a viable strategy to help companies overcome the barriers that previously made it hard to access data and process it in a distributed data environment. It empowers organizations to manage mounting amounts of data with more efficiency. Data fabric is one of the more recent additions to the lexicon of data analytics. Gartner listed data fabric as one of the top 10 data and analytics trends for 2021.
A data fabric is an architecture that runs technologies and services to help an organization manage its data. This data can be stored in relational databases, tagged files, flat files, graph databases, and document stores.
A data fabric architecture facilitates data-centric tools and applications to access data while working with various services. These can include Apache Kafka (for real-time streaming), ODBC (open database connectivity), HDFS (Hadoop distributed file system), REST (representational state transfer) APIs, POSIX (portable operating system interface), NFS (network file system), and others. It’s also crucial for a data fabric architecture to support emerging standards.
A data fabric is agnostic to architectural approach, geographical locations, data use case, data process, and deployment platforms. With data fabric, organizations can work toward meeting one of their most desired goals: having access to the right data in real-time, with end-to-end governance-and all at a low cost.
Data fabric vs. data lake
Often it happens that organizations lack clarity on what makes a data lake different from a data fabric. A data lake is a central location that stores large amounts of data in its raw and native format.
However, there’s an increase in the trend of data decentralization. Some data engineers believe that it’s not practical to build a central data repository, which you can govern, clean, and update effectively.
On the other hand, a data fabric supports heterogeneous data locations. It simplifies managing data stored in disparate data repositories, which can be a data lake or a data warehouse. Therefore, a data fabric doesn’t replace a data lake. Instead, it helps it to operate better.
Why do you need data fabric in today’s digital world?
Data fabrics empower businesses to use their existing data architectures more efficiently without structurally rebuilding every application or data store. But why is a data fabric relevant today?
Organizations are handling challenges of bigger scalability and complexity. Today, their IT systems are advanced and work with disparate environments while managing existing applications and modern applications powered by microservices.
Previously, software development teams went with their own implementation for data storage and retrieval. A typical enterprise data center stores data in relational databases (e.g., Microsoft SQL Server), non-relational databases (e.g., MongoDB), data repositories (e.g., a data warehouse), flat files, and other platforms. As a result, data is spread across rigid and isolated data silos, which creates issues for modern businesses.
Unifying this data isn’t trivial. Apps store data in a wide range of formats, even if they are using the same data. Besides, organizations store data in various siloed applications. Consolidating this data includes going through data deduplication — a process that removes duplicate copies of repeating data. Taking data to the right application at the right time is desirable, but it’s a tough nut to crack. That’s where a data fabric architecture can resolve your problem.
A data fabric helps to:
Handle multiple environments simultaneously, including on-premises, cloud, and hybrid.
Use pre-packaged modules to establish connections to any data source.
Bolster data preparation, data quality, and data governance capabilities.
Improve data integration between applications and sources.
A data fabric architecture allows you to map data from different apps, making business analysis easier. Your team can draw decisions and insights from existing and new data points with connected data. For instance, suppose an authorized user in the sales department wants to look at data from marketing. A data fabric lets them access marketing data seamlessly, in the same way they access sales data.
With a data fabric, you can build a global and agile data environment that can track and govern data across applications, environments, and users. For instance, if objects move from one environment to another, the data fabric notifies each component about this change and oversees the required processes, such as what process to run, how to run, and what’s the object’s state.
Data fabric examples to consider for improving your organization’s processes
The flexibility of a data fabric architecture helps in more ways than one. Some of the data fabric examples include the following:
Enhancing machine learning (ML) models
When the right data is fed to machine learning (ML) models in a timely manner, their learning capabilities improve. ML algorithms can be used to monitor data pipelines and recommend suitable relationships and integrations. These algorithms can obtain information from data while being connected to the data fabric, go through all the business data, examine that data, and identify appropriate connections and relationships.
One of the most time-consuming elements of training ML models is getting the data ready. A data fabric architecture helps to use ML models more efficiently by reducing data preparation time. It also aids in increasing the usability of the prepared data across applications and models. When an organization distributes data across on-premises, cloud, and IoT, it’s the data fabric that provides controlled access to secure data, enhancing ML processes.
Building a holistic customer view
Businesses can employ a data fabric to harness data from customer activities and understand how interacting with customers can offer more value. This could include consolidating real-time data of different sales activities, the time it takes to onboard a customer, and customer satisfaction KPIs.
For instance, an IT consulting firm can consolidate data from customer support requests and rework their sales activities accordingly. The firm receives concerns from its clients regarding the lack of a tool that can help them to migrate their on-premises databases to multi-cloud environments without downtime. The firm can then recognize the need to resolve this issue, find a reliable tool like Striim to address it, and have its sales representatives recommend the tool to customers.
Security is key to a successful data fabric implementation
Over the past few years, cyberattacks, especially ransomware attacks, have grown at a rapid rate. So, it’s no surprise organizations are concerned about the risk these attacks pose to their data security while data is being moved from one point to another in the data fabric.
Organizations can improve data protection by incorporating security protocols to protect their data from cyber threats. These protocols include firewalls, IPSec (IP Security), and SFTP (Secure File Transfer Protocol). Another thing to consider is a dynamic and fluid access control policy, which can be adapted dynamically to tackle evolving cyber threats.
With so many cyberattacks causing damages worth millions, securing your data across all points is integral for successfully implementing your data fabric architecture.
This can be addressed in multiple ways:
Ensuring data at-rest and in-flight are encrypted
Protecting your networking traffic from the public internet by using PrivateLink on services like Azure and AWS
Managing secrets and keys securely across clouds
Building your data fabric with Striim
Now that you know the benefits and some use cases of a data fabric, how can you start the transition towards a data fabric architecture in your organization?
According to Gartner, a data fabric should have the following components:
A data integration backbone that is compatible with a range of data delivery methods (including ETL, streaming, and replication)
The ability to collect and curate all forms of metadata (the “data about the data”)
The ability to analyze and make predictions from data and metadata using ML/AI models
A knowledge graph representing relationships between data
While there are various ways to build a data fabric, the ideal solution simplifies the transition by complementing your existing technology stack. Striim serves as the foundation for a data fabric by connecting with legacy and modern solutions alike. Its flexible and scalable data integration backbone supports real-time data delivery via intelligent pipelines that span hybrid cloud and multi-cloud environments.
Striim enables a multi-cloud/hybrid cloud data fabric architecture with automated, intelligent pipelines that continuously deliver data to consumers including data warehouses and data lakes.
Striim continuously ingests transaction data and metadata from on-premise and cloud sources and is designed ground-up for real-time streaming with:
An in-memory streaming SQL engine that transforms, enriches, and correlates transaction event streams
Machine learning analysis of event streams to uncover patterns, identify anomalies, and enable predictions
Real-time dashboards that bring streaming data to life, from live transaction metrics to business-specific metrics (e.g. suspected fraud incidents for a financial institution or live traffic patterns for an airport)
Hybrid and multi-cloud vault to store passwords, secrets, and keys. Striim’s vault also integrates seamlessly with 3rd party vaults such as HashiCorp
Continuous movement of data (without data loss or duplication) is essential to mission-critical business processes. Whether a database schema changes, a node fails, or a transaction is larger than expected — Striim’s self-healing pipelines resolve the issue via automated corrective actions. For example, Striim detects schema changes in source databases (e.g. create table, drop table, alter column/add column events), and users can set up intelligent workflows to perform desired actions in response to DDL changes.
As shown below, in the case of an “Alter Table” DDL event, Striim is configured to automatically propagate the change to downstream databases, data warehouses and data lakehouses. In contrast, in the case of a “Drop Table” event, Striim is set up to alert the Ops Team.
How intelligent workflows can be set up to automatically respond to different types of DDL/schema changes.
With Striim at its core, a data fabric functions as a comprehensive source of truth — whether you choose to maintain a current snapshot or a historical ledger of your customers and operations. The example below shows how Striim can replicate exact DML statements to the target system, creating an exact replica of the source:
DML propagation to replicate database changes from source to target. This will actually perform updates and deletes on your target system to match it to the source exactly.
And the following example shows how Striim can be used to maintain a historical record of all the changes in the source system:
History-mode for a record of all changes. This will show the logical change event and the optype including what has changed in the row.
Taken together, Striim makes it possible to build an intelligent and secure real-time data fabric across multi-cloud and hybrid cloud environments. Once data is unified in a central destination (e.g. a data warehouse), a data catalog solution can be used to organize and manage data assets.
Learn More: On-Demand Data Fabric Webinar
Looking for more examples and use cases of enterprise data patterns including data fabric, data mesh, and more? Watch our on-demand webinar with James Serra (Data Platform Architecture Lead at EY) on “Building a Multi-Cloud Data Fabric for Analytics”. Topics covered include:
Pros and cons of multi-cloud vs doubling down on a single cloud
Enterprise data patterns such as Data Fabric, Data Mesh, and The Modern Data Stack
Data ingestionand data transformation in a multi-cloud/hybrid cloud environment
Comparison of data warehouses (Snowflake, Synapse, Redshift, BigQuery) for real-time workloads
Database migration refers to transferring your data from one platform to another. An organization can opt for database migration for a multitude of reasons. For example, an organization might feel that a specific database (e.g., Oracle) has features that can offer more benefits than their existing database (e.g., MySQL). Or, they might want to cut costs by moving their on-premises legacy system to the cloud (e.g., Amazon RDS).
Having said that, moving data from one place to another isn’t a simple endeavor – a narrative supported by stats. According to Gartner, 50% of all data migration projects go above their predetermined budgetsand affect the overall business negatively. The lack of an adequate database migration strategy and flawed execution are most often the culprits. That’s because database migration projects:
Involve a greater degree of complexity than other IT projects
Often involve databases that host mission-critical applications (which requires careful coordination of downtime, as well as data loss prevention measures)
Tend to take a great deal of time and effort (from manual schema changes to post-migration database validations)
Involve several systems, technologies, and IT teams to work properly
Simply put, an effective database migration strategy can prevent companies from blowing budgets and deadlines.
Why a Database Migration Strategy Is Key to Your Organization’s Success
A database migration strategy is a plan that facilitates your data transfer from one platform to another. There is a wide range of complexities that go into the data migration process. It’s much more than simply copying and pasting data. Such a plan takes certain factors into account, such as a data audit, data cleanup, data maintenance, protection, and governance.
A well-defined database migration strategy can reduce the business impact of database migration. A strategy helps the data migration team to avoid creating a poor experience that often generates more issues than it solves. A subpar strategy can cause your team to miss deadlines, exceed budgets, and cause the entire project to fail. According to a study, database migration can lead to more than $250,000 in cost overruns.
Legacy data doesn’t always align with the new system. Bringing unnecessary data to a new system wastes resources. But a database migration strategy can address these issues by identifying the core data requirements and guide you to make the right decisions.
3 Types of Database Migration Strategies
There are three main approaches to database migration: big bang data migration, trickle data migration, and zero downtime migration.
1. Big Bang Database Migration
A big bang migration transfers all data from one source system to a target database in a single operation at a single point in time. Often it’s performed during a weekend or a scheduled downtime period.
The benefit of this strategy is its simplicity, as everything occurs in a time-boxed event. The tradeoff is downtime. This can be undesirable for organizations that run their systems 24/7.
2. Trickle Database Migration
A trickle migration follows an agile-type approach to database migration. It breaks down the migration into small sub-migrations, each having its own scope, deadlines, and goals. This way, it’s easier for the database migration team to confirm the success of each phase. If any sub-processes falter, it’s common to only re-work the failed process. As a result, the lessons from the failure can be utilized to improve subsequence runs. That’s one of the reasons why it’s less prone to unexpected failures.
The drawback is that trickle database migration takes more time. Since you have to run two systems simultaneously, it consumes more resources and effort.
3. Zero-Downtime Database Migration
A zero-downtime migration replicates data from the source database to the target database. It allows the client to access and operate on the source database while the migration is in process.
Benefits include less business disruption, faster migration, and minimal cost, especially when considering business impact and all-hands migration efforts.
Database Migration Best Practices
Sticking to the best practices can increase the likelihood of successful database migration. Some of the practices followed by a well-planned database migration strategy include:
Set Up the Database Migration Project Scope
First, set the parameters (e.g., object types, source objects in scope, connection parameters) of your database migration project. Like other IT initiatives, this process is prone to scope creep.
According to a published study, specifications change in 90% of data migration projects. In addition, 25% of such projects tackle more than one specification change. Therefore, it’s better to start small. For instance, if you have multiple databases, then move data from only one of them. Once you succeed with this single migration, you can extend the project scope.
Analyze Your Current Data
Database migration projects deal with plenty of factors, such as:
The type of the data
The size of the data
The operating systems
The source and target systems
The database platform
Before you initiate the migration process, you have to determine how much data you need to move. For example, you might have records that are no longer required and better left behind. Or you might think about compatibility issues, such as when moving data from a relational database (e.g., Oracle) to a non-relational database (e.g., MongoDB).
Communicate the Process
Multiple teams need to give their input to the data migration process. Communicating the entire data migration process to them is vital. They should know what they’re expected to do. For that, you have to assign responsibilities and tasks.
Set a list of deliverables and tasks and assign roles to activities. Some of the questions you need to answer include:
Who is the chief decision-maker of the migration process?
Who has the authority to determine whether the migration was successful?
After database migration, who will validate data?
Lack of a proper division of tasks and responsibilities can cause organizational chaos and your project to fail.
Strengthen Your Database Migration Strategy with StreamShift
Part of building a database migration strategy will include making sure your team has the right tools in place. Using a tool like StreamShift helps to ensure a successful data migration.
StreamShift is a fully managed SaaS database migration tool that can simplify database migration from on-premise or cloud databases to your desired target databases.
With StreamShift, you can fulfill the core requirements needed for zero downtime database migration. All you need to do is choose source and target connections and provide the credentials. After that, StreamShift will handle everything, including creating initial schemas, bulk loading historical data, and performing continuous synchronization between the source and target.
StreamShift is run by a team that has years of deep data management and migration experience working with global enterprise customers. That’s why it comes with a user-friendly user interface that addresses various common and complex database migration pain points.
Modern computing demands have forced businesses to ensure high availability and data accessibility while tackling various networks simultaneously. That’s why it’s crucial to get 24/7 and real-time access to key business data from your database—and for many businesses, that database is Oracle. Whether a business is looking to process millions of transactions or build a data warehouse, Oracle is the go-to option for handling critical enterprise workloads.
In today’s digital age, organizations must scale up their systems and build an ecosystem that helps them seamlessly access data from their Oracle database to improve the efficiency of their operations. To achieve this, they can use database replication — a technique that enables data access to a wide range of sources (e.g., servers and sites). Since it allows real-time data access, database replication maintains high-data availability and addresses a major concern for enterprises.
Why Replicate an Oracle Database?
Replicating an Oracle database makes it easy to distribute, share, and consolidate data. With replication, businesses can synchronize data across different locations, share data with vendors and partners, and aggregate data from their branches — both international and local.
Companies use Oracle database replication to create multiple copies of an organization’s database. These synchronized copies pave the way for distributed data processing, backups for disaster recovery, testing, and business reporting.
Some benefits of Oracle database replication include the following:
Enhance application availability. Since database replication copies data to several machines, it’s easier to maintain access to your application’s data. Even if one of your machines is compromised due to a malware attack, faulty hardware, or another issue, your application data will remain available 24/7.
Enhance server performance. It’s a common practice in database replication to direct data read operations to a replica. This allows system administrators to minimize processing cycles on the primary server and prioritize it for write operations.
Enhance network performance. Maintaining multiple copies of the same data is convenient for minimizing data access latency. That’s because you can fetch the relevant data from the location where the transaction is being executed.
For instance, users from Europe might face latency problems while trying to access Australian-based data centers. You can address this challenge via Oracle database replication, so a replica of your data is placed closer to the user.
A common example of Oracle database replication can be found in money transfers and ATM withdrawals. For example, if you withdraw $150 from an ATM, the transaction will be immediately copied to each of your bank’s servers. As a result, your information will be updated instantaneously in all branches to display $150 less in your account.
Similarly, an e-commerce website that uses an Oracle database has to ensure visitors from different countries can view the same product information at each site. Database replication helps them to achieve this goal by copying their product details for each site.
4 Ways to Replicate An Oracle Database
Choosing the right approach to replicate your Oracle depends on several factors, including the goal of your replication, the size of the database, how the performance of the source systems is affected, and whether you need synchronous replication or asynchronous replication.
Here are some of the common ways to replicate an Oracle database.
1. Full Dump and Load
In this approach, you start by choosing a table you want to replicate. Next, you define a replication interval (could be 4, 8, or 12 hours) as per your requirements. For each interval, your replicated table is queried, and a snapshot is generated. This snapshot (also known as a dump) is used as the substitute for the previous snapshot.
This approach is effective for small tables (usually less than 100 million rows). However, once the table grows in size, you will have to rely on a more reliable replication strategy. That’s because it takes a considerable amount of time to perform the dump.
2. Incremental Approach (Table Differencing)
Table differencing is an approach in which a copy of the source table is periodically compared to an older version of the table and the differences are extracted.
For example, use the following command to get the difference between the two tables, named new_version and old_version.
SELECT * FROM new_versionMINUS SELECT * FROM old_version;
This command gives you the inserts and updates that are present in the new_version of the table. However, when the time comes to load data into the target database, you have to make sure to replace the table’s old version with the new version (so you can compare it to a future new version of the table).
The incremental approach provides an accurate view of changed data while only using native SQL scripts. However, this method can lead to high computation and transport costs. In addition, it isn’t ideal for restoring data. For instance, if you want to go through the files that were backed up incrementally on Wednesday, you’ll first have to restore the full backup from Tuesday.
3. Trigger-Based Approach
This approach depends on triggers — a function you can set up to execute automatically whenever a data change occurs in your database system.
For example, you can set a trigger that inserts a record into another table (the “change table”) whenever the source table changes. You can then replicate your data from the Oracle database to another database.
Oracle comes with a stored procedure to set any trigger and monitor the source table for updates. Triggers help to achieve synchronous replication. However, this approach can affect the performance of the source database because triggers cause transactions to be delayed.
4. Change Data Capture
Change data capture (CDC) is a managedsoftware process that determines the rows in source tables that have been modified after the last replication. This makes it more efficient and faster than other methods, especially the ones that copy entire tables at every replication cycle and replicate even the rows that weren’t changed.
CDC replicates create-update-delete (CUD) operations, written in SQL via the following commands: INSERT, UPDATE, and DELETE.
Here’s why Oracle CDC is a better approach for replicating your Oracle database:
Since CDC only works with the rows that have changed, it sends less data from the source to the replication, putting a minimal load on the network.
Proper CDC implementation ensures that replication operations don’t affect your production database. In this way, you can free up resources for transactions.
With CDC, you can achieve real-time data integration, helping you build streaming analytics.
For example, consider HomeServe, a leading home assistance provider. HomeServe wanted to send detailed reports to its insurer partners that could give an in-depth overview of water leaks. To do this, they needed a technology that could help them move the operational data to Google BigQuery without impacting their database.
Ultimately, they went with Striim’s enterprise-grade CDC to go through binary logs, JSON columns, and other sources. This allowed them to move all the changes from the transactional database. More importantly, CDC ensured no overhead was caused on the source system and performance remained unaffected.Learn more about it here.
Oracle GoldenGate is another tool that can replicate data from one Oracle database to another by using CDC. GoldenGate can be useful for a broad array of use cases. These include multi-cloud ingestion, data lake ingestion, high availability (peer-to-peer, unidirectional, bi-directional, etc.), and online transactional processing (OLTP) data replication.
Although Oracle GoldenGate is more convenient than the above methods, configuring it requires assistance from an Oracle administrator.
Simplify Oracle Database Replication with Striim
CDC is the best approach for replicating Oracle databases in many scenarios, but which tool should you choose to implement it? Consider taking a look at Striim.
UsingStriim’s Oracle CDC reader, you can turn your Oracle database into a streaming source and migrate your critical transactional data to cloud environments or real-time applications.
Thelog-based CDC method in Striim fetches the insert, update, and delete operations in the Oracle redo logs. Even better, Striim’s CDC reader can buffer large transactions to disk with minimal performance overhead. Throughout this process, the source systems remain unaffected.
Another thing that makes Striim stand out is, unlike other tools, it can work without the LogMiner continuous mining feature, which was deprecated in 19c. Additionally, Striim can read from GoldenGate trail files.
Here’s the thing: Getting a 500: Server error is never good news to a business, regardless of its source. Granted, the error could stem from a number of issues, but what happens when a problem with your database is the cause of the error? Are you going to start panicking because you don’t have a backup, or would you be calm, assured that yourreplicais up and running?
This is just one of the uses of MySQL replication. Replication is the process of copying data from one database (source) to another (replica). The data copied can be part or all of the information stored in the source database. MySQL database replication is carried out according to the business needs — and if you’re considering having a replica, here’s what you need to know.
Why Replication?
Replication may seem expensive from afar — and it usually is if you consider time and effort expended. On a closer look and in the long run, you’ll see it delivers great value to your business. It saves you time, and more money, in the future.
Most of the benefits of replication revolve around the availability of the database. However, it also ensures the durability and integrity of the data stored.
Replication Improves the Server’s Performance
HTTP requests to the server are either read (SELECT) or write(CREATE, UPDATE, DELETE) queries. An application may require a large chunk of these queries per minute, and these may, in turn, slow down the server. With replicas, you can distribute the load in the database.
For example, if the bulk of your requests are read queries, you can have the source server handle all write operations on the server, and then the replicas can be read-only. As a result, your server becomes more efficient as this load is spread across the databases. Doing this also helps avoid server overload.
Replication Allows for Easier Scalability
As a business grows, there is often a heavier load on the server. You can tackle this extra load by either scaling vertically by getting a bigger database or scaling horizontally by distributing your database’s workload among its replicas. However, scaling vertically is often a lengthy process because it takes a while — from several hours to a few months — to fully migrate your data from one database to another.
When scaling horizontally, you spread the load without worrying about reaching the load limit of any one database — at least for a while. You also do not need to pause or restart your server to accommodate more load as you would have done when moving your data to another database.
Without replicas, you might have to do backups on tape, and in the event of a failover, it could take hours before the system is restored. And when it’s fully restored, it’ll only contain data from the last backup; the latest data snapshot is often lost. Having replicas means you can easily switch between databases when one fails without shutting down the server.
You can automate the switch so that once a source stops responding, queries are redirected to a replica in the shortest time possible. Then, when the source is back online, it can quickly receive updates to the replica.
Replication Provides an Easy Way to Pull Analytics
Pulling analytics on data stored in the database is a common procedure, and replication provides a hassle-free way to do this. You can draw insights for analytics from replicas, so you avoid overloading the source. Doing this also helps preserve the data integrity of the source — the information remains untouched, preventing any tampering with the data (whether by accident or otherwise).
Otherwise, the source can always sync up with the replica to get the latest data snapshot as needed.
Whatever the size of your database, MySQL replication is beneficial — especially if you intend to grow your business. First, figure out if and how replication affects your business and go from there to decide how many replicas to have and which replication method to use.
Use Cases For MySQL Replication
MySQL replication allows you to make exact copies of your database and update them in near real-time, as soon as updates to your source database are made. There are several cases where MySQL replication is helpful, and a few of them include:
Backups
Data backups are usually performed on a replica so as not to affect the up-time and performance of the source. These backups can be done in three forms: using mysqldump, raw data files, and backing up a source while it’s read-only. For small- to medium-sized databases, mysqldump is more suitable.
Using mysqldump involves three steps:
Stop the replica from processing queries using mysqladmin stop-replica
Dump selected or all databases by running mysqldump
Restart the replication process once the dump is completed. mysqladmin start-replica does that for you.
Since information backed up using mysqldump is in the form of SQL statements, it would be illogical to use this method for larger databases. Instead, raw data files are backed up for databases with large data sets.
Scaling Out
Using replication to scale out is best for servers with more reads and fewer writes. An example is a server for e-commerce where more users look through your product catalog than users adding to your catalog. You’re then able to distribute the read load from the source to the replicas.
Have an integrated platform for read and write connections to the server and the action of those requests on the server. That platform could be a library that helps carry out these functions. Here’s anexample layout of replication for scale-out solutions.
Switching Sources
MySQL allows you to switch your source database when need be (e.g., failover) using theCHANGE REPLICATION SOURCE TO statement. For example, say you have a source and three replicas, and that source fails for some reason. You can direct all read/write requests to one of the replicas and have the other two replicate from your new source. Remember toSTOP REPLICA andRESET MASTER on the new source.
Once the initial source is back, it can replicate from the active source using the sameCHANGE REPLICATION SOURCE TO statement. To revert the initial source to source, follow the same procedure used to switch sources above.
Whatever your reason for adopting MySQL replication, there’s extensivedocumentation on MySQL statements that can help you achieve your replication goal.
The Common Types of MySQL Replication
You can set up MySQL replication in a number of ways, depending on many factors. These factors include the type of data, the quantity of the data, the location, and the type of machines involved in the replication.
To help you determine the right type of MySQL replication for your needs, let’s review the most common MySQL replication types:
Snapshot Replication
As the name implies, snapshot replication involves taking a picture-like replica of a database. It makes an exact replication of the database at the time of the data snapshot. Because it’s a snapshot, the replica database does not track updates to the source. Instead, you take snapshots of the source at intervals with the updates included.
Snapshot replication is simple to set up and easy to maintain and is most useful for data backup and recovery. And the good news is that it’s included by default in a lot of database services.
Merge Replication
The word “merge” means to combine or unite to form a single entity. That’s the basis for merge replication — it unites data from the source database with the replica. Merge replication is bidirectional: changes to the source are synchronized with the replicas and vice versa.
You can use merge replication when there are multiple replicas working autonomously, and the data on each database needs to be synchronized at certain operational levels of the server. It is mostly used in server-client environments.
An example of a merge replication use case would be a retail company that maintains a warehouse and tracks the stock levels in a central (source) database. Stores in different locations have access to replica databases, where they can make changes based on products sold (or returned). These changes can be synchronized with the source database. In turn, changes to the source database are synchronized with the replicas, so that everyone has up-to-date inventory information.
Transactional Replication
Transactional replication begins with a snapshot of the source database. Subsequent changes to the source are replicated in the replica as they occur in near real-time and in the same order as the source. Thus, updates to the replica usually happen as a response to a change in the source.
Replicas in transactional replication are typically read-only, although they can also be updated. Therefore, transactional replication is mainly found in server-server environments, for instance, multi-region/zone databases.
There are a few other MySQL replication types, but one feature is common to all, including those discussed above. Each replication typically starts with an initial sync with the source database. After that, they branch out to their respective processes and use cases.
The Power of Leveraging Your MySQL Replicas
We’ve established the importance and advantages of replicating your databases, but keeping up with changes or corruption to the database can be a struggle for a lot of production teams. To top that, you need to know how your data is ingested and delivered and, more importantly, ensure this process of ingestion and delivery is continuous.
WithStriim, you can easily see and understand the state of your data workflow at any given time. Whether your server is on-premise, cloud-based or hybrid, you can still create data flows and have control over how your data is gathered, processed, and delivered. We’reready when you are.

































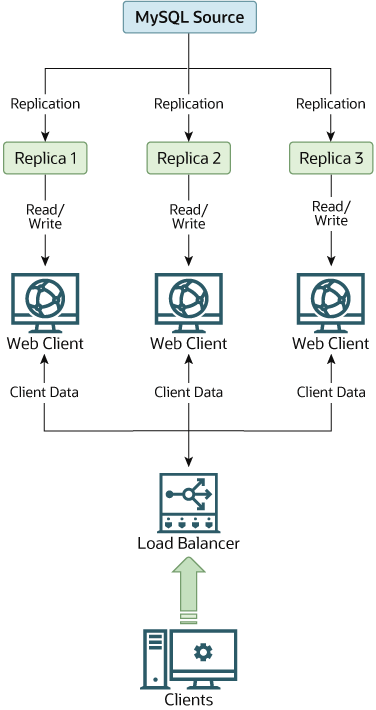{kind=link}