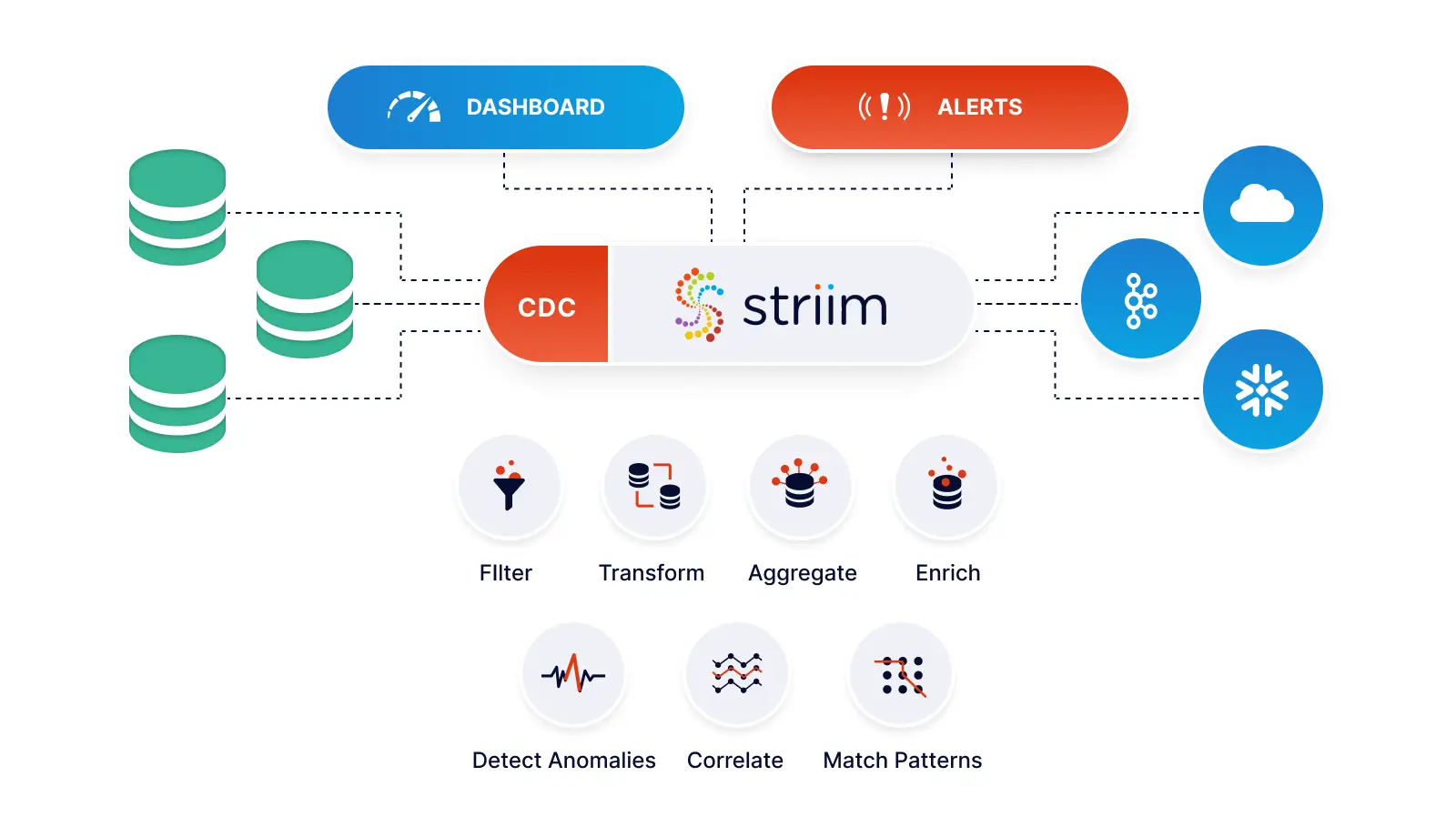
Migrate your database data and schemas to Databricks in minutes.
Stream operational data from Oracle to your data lake in real-time
Automatically keep schemas and models in sync with your operational database.
On this page
We will go over two ways on how to create smart pipelines to stream data from Oracle to Databricks. Striim also offers streaming integration from popular databases such as PostgreSQL, SQLServer, MongoDB, MySQL, and applications such as Salesforce to Databricks Delta Lake.
In the first half of the demo, we will be focusing on how to move historical data for migration use cases, which are becoming more and more common as many users start moving from traditional on-prem to cloud hosted services.
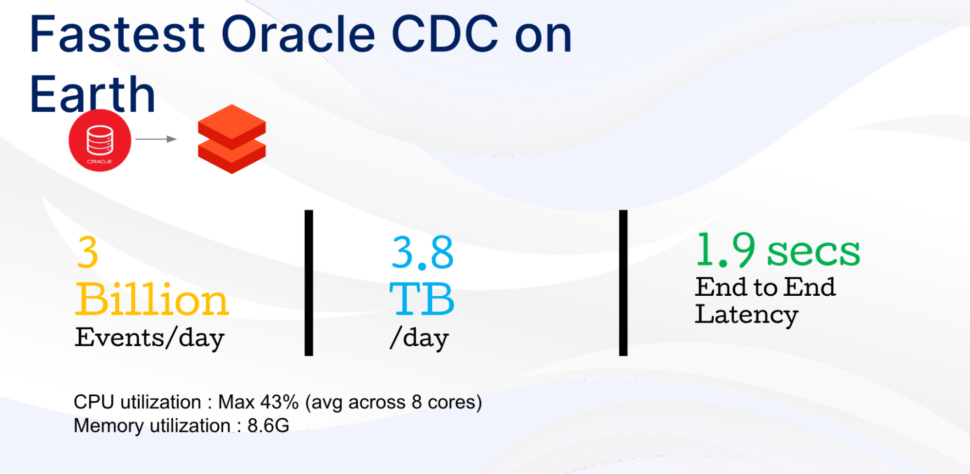
Striim is also proud to offer the industry’s fastest and most scalable Oracle change data capture to address the most critical use cases.
Striim makes initial load, schema conversion, and change data capture a seamless experience for data engineers.
In a traditional pipeline approach, there are times we would have to manually create the schema either through code or infer the schema from the csv file etc.
And next, configure the connectivity parameters for the source and target.
Striim offers the ability to reduce the amount of time and manual effort when it comes to setting up these connections and also creates the schema at the target with the help of a simple wizard.
Here we have a view of the databricks homepage with no schema or table created in the DBFS.
In the Striim UI, under the ‘Create app’ option, we can choose from templates offered for a wide array of data sources and targets.
With our most recent 4.1 release, we have also support the Delta Lake adapter as a Target datasink.
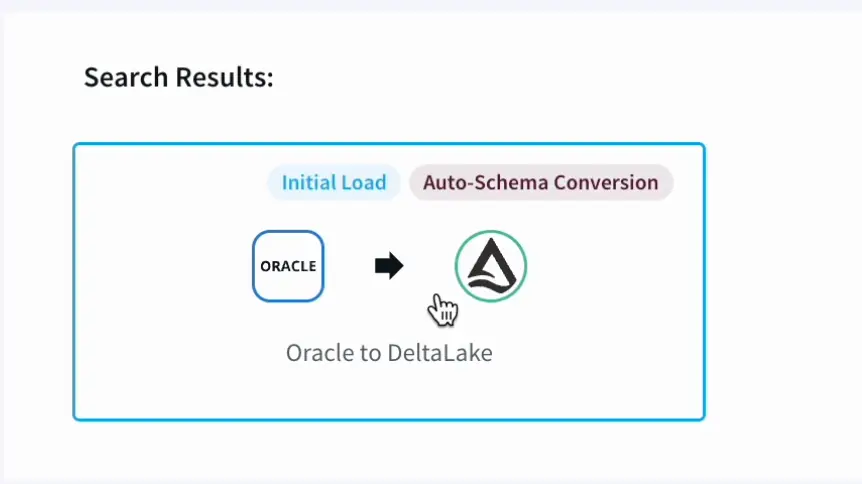
Part 1: Initial Load and Schema Creation
In this demo, we will be going over on how to move historical data from Oracle to Databrick’s Delta lake.
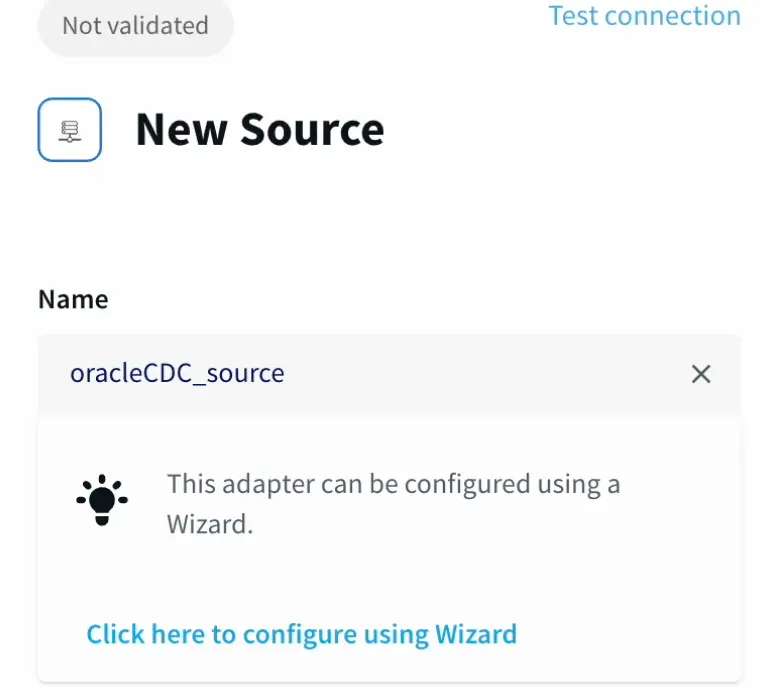
With the help of Striim’s Intuitive Wizard we name the application,
With the added option to create multiple namespaces depending on our pipelines needs and requirements
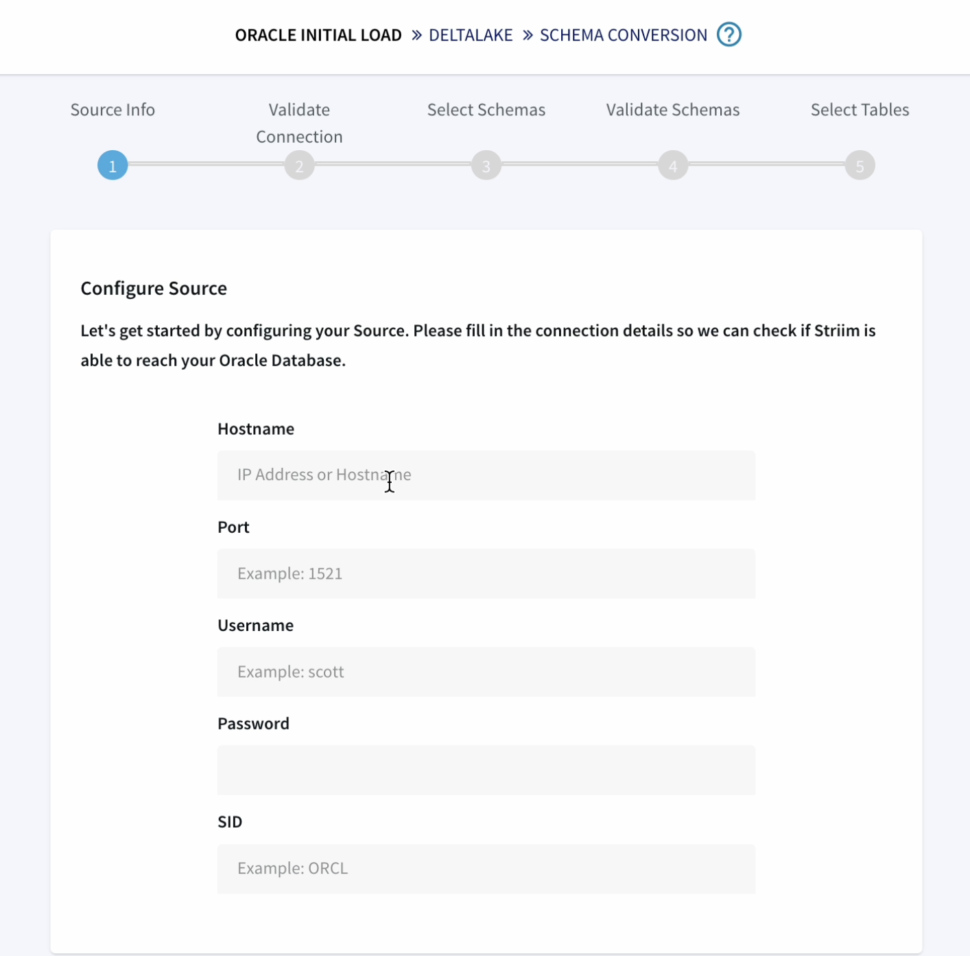
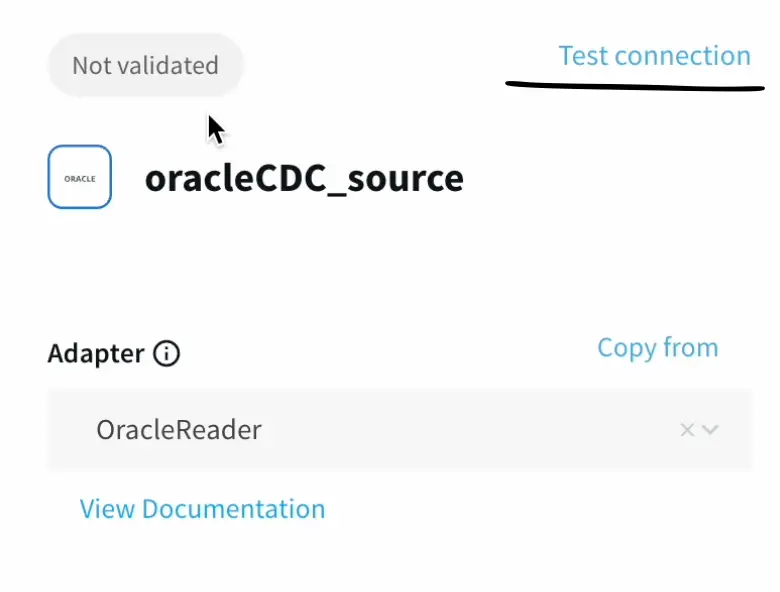
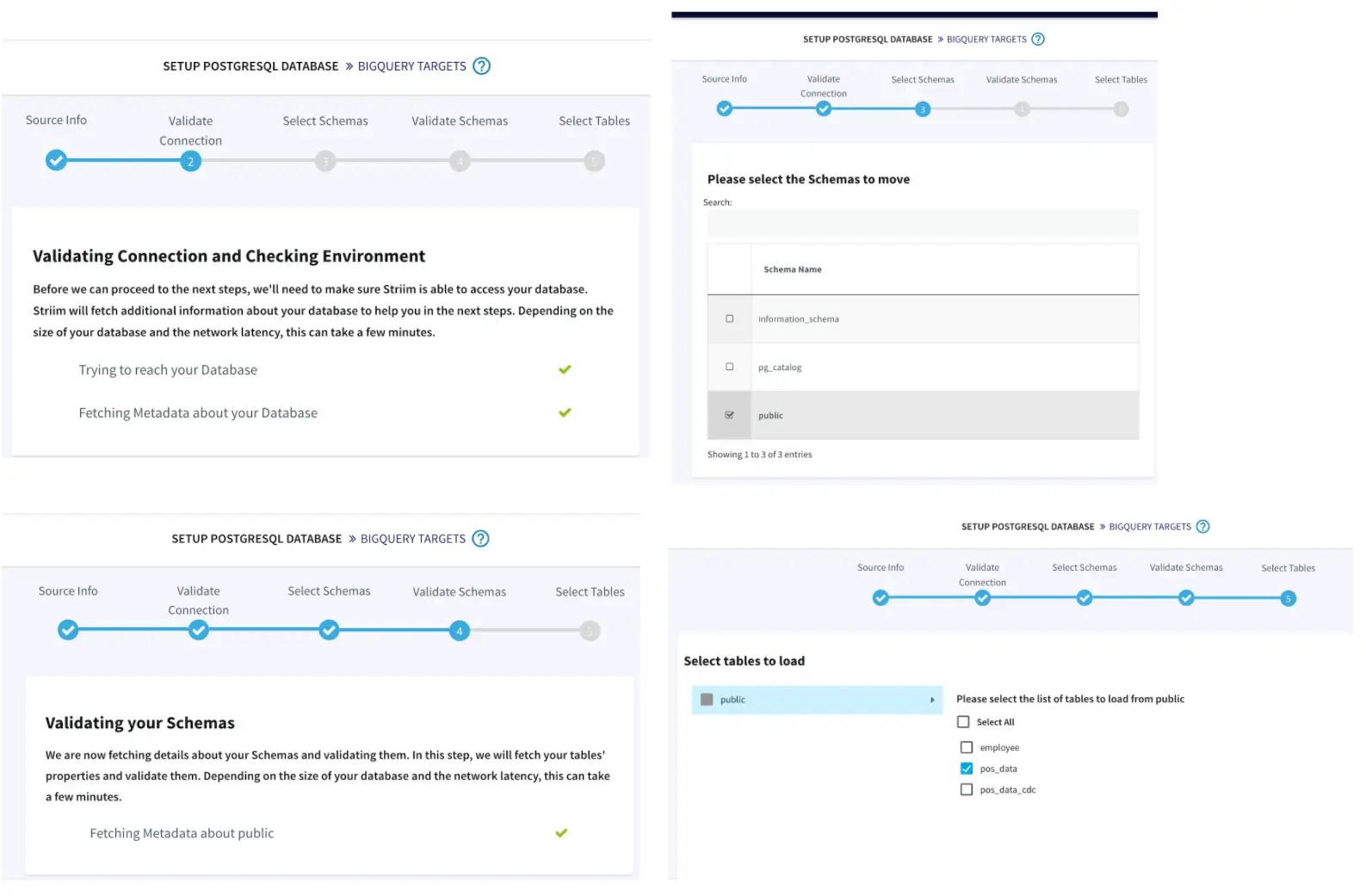
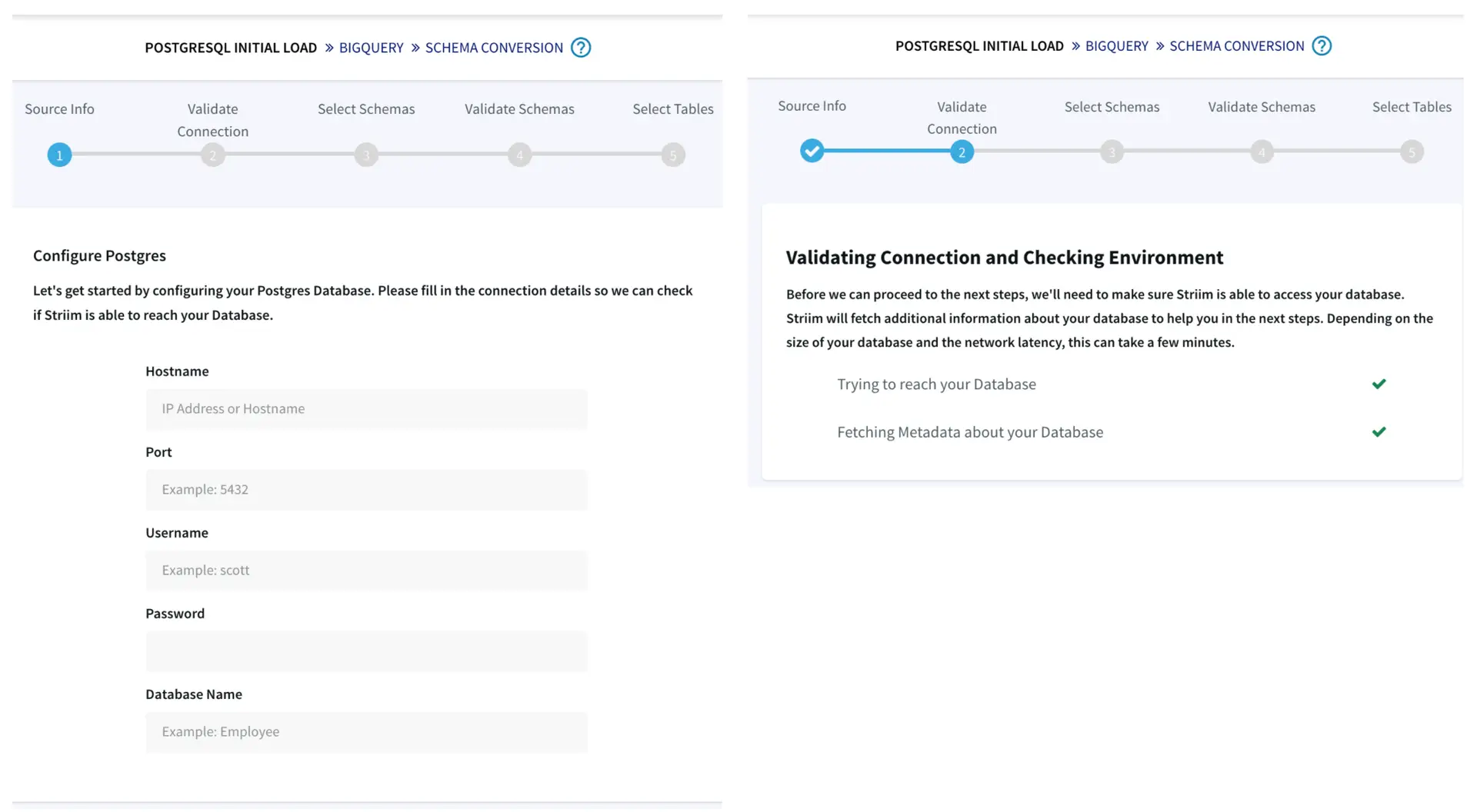
First we configure the source details for the Oracle Database.
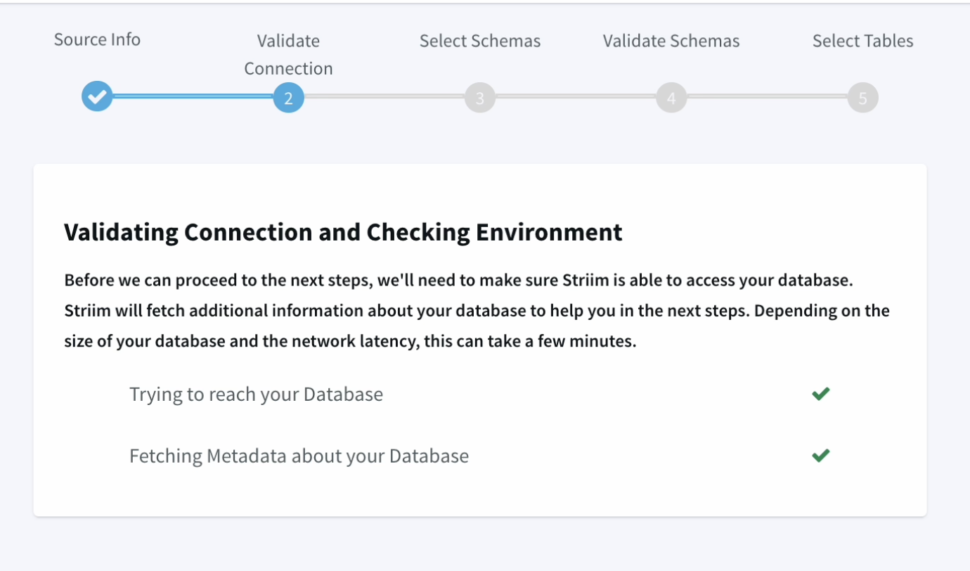
We can validate our connection details
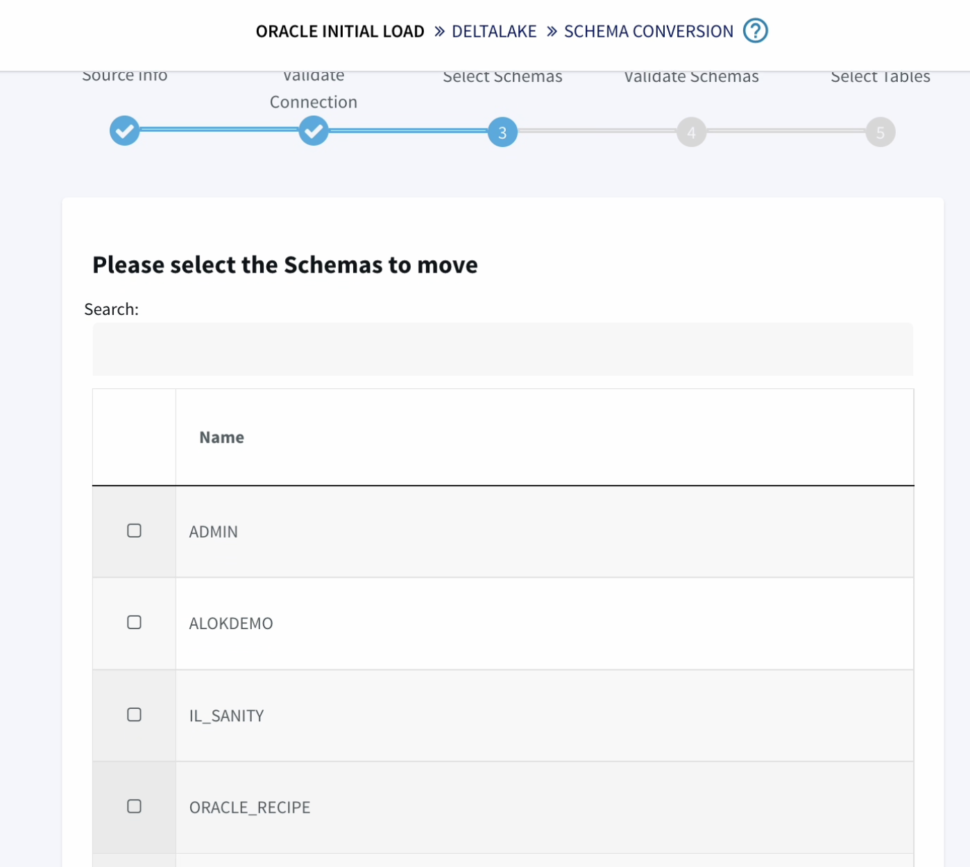
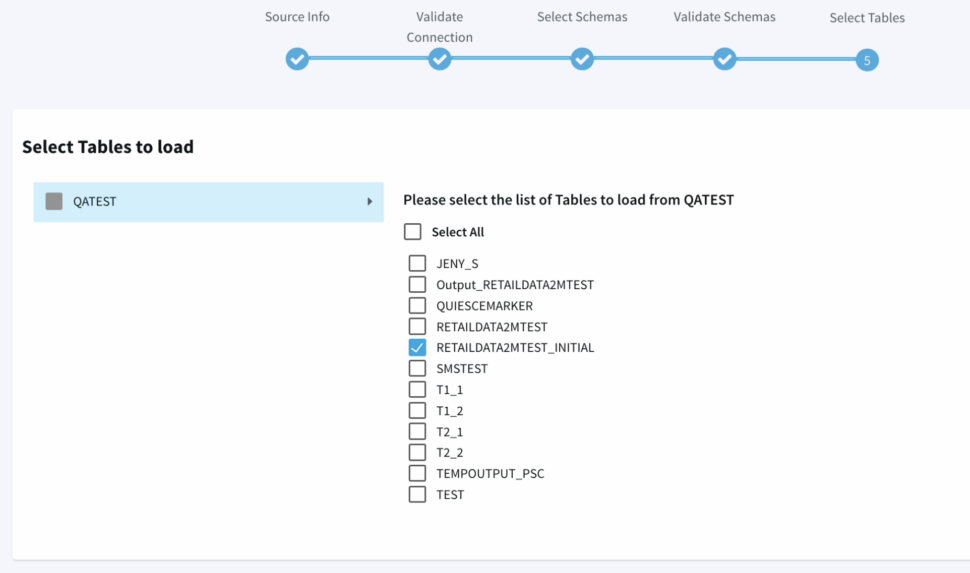
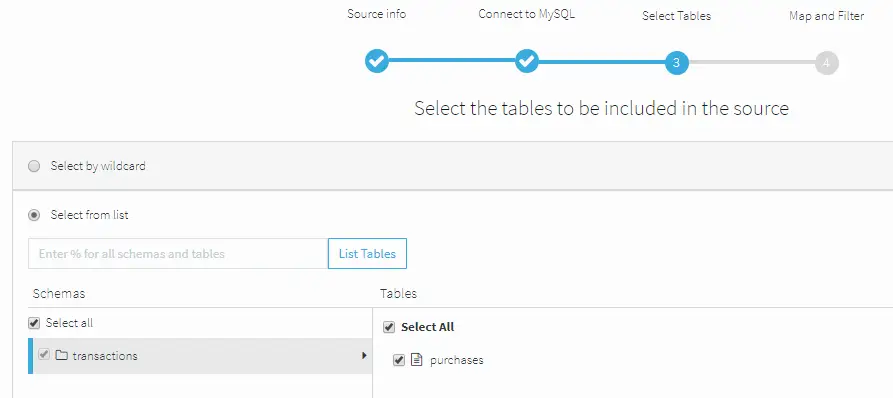
Next we have to option to choose the schemas and tables that we specifically want to move, providing us with more flexibility instead of replicating the entire database or schema.
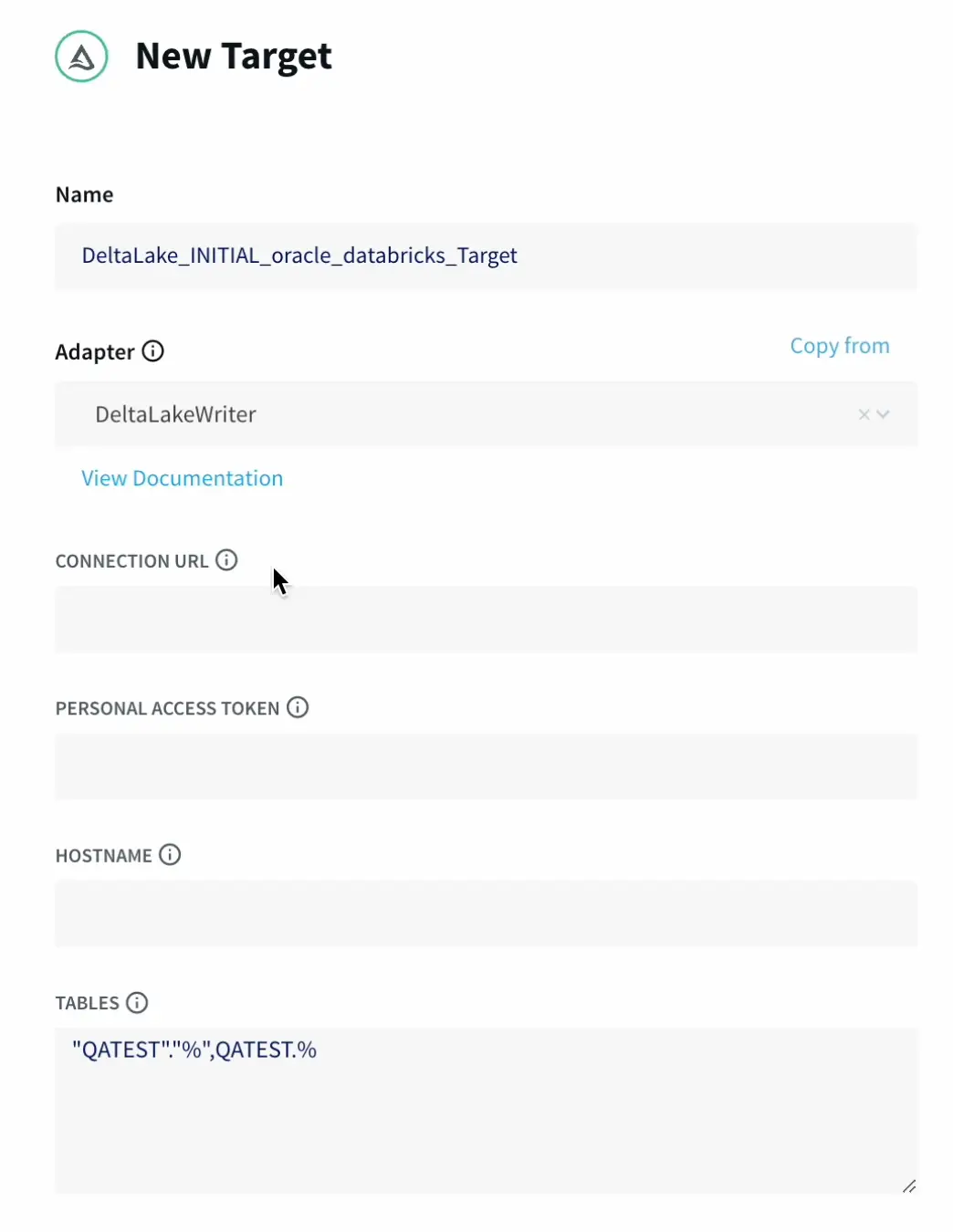
Now we can start to configure our target Delta Lake.
Which supports ACID transactions, scalable metadata handling, and unifies streaming and batch data processing.
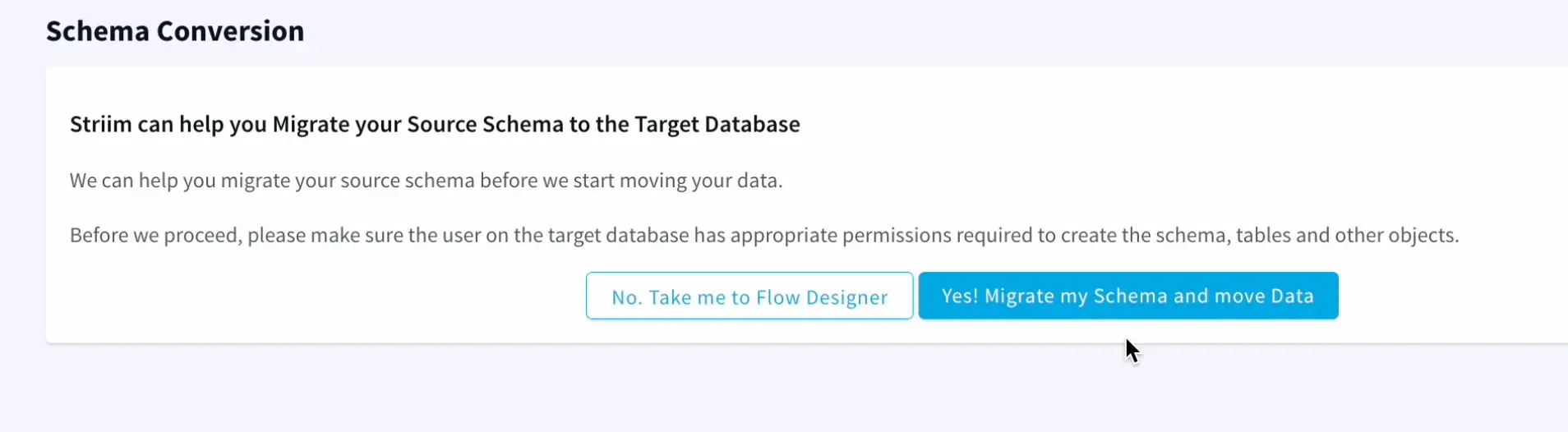
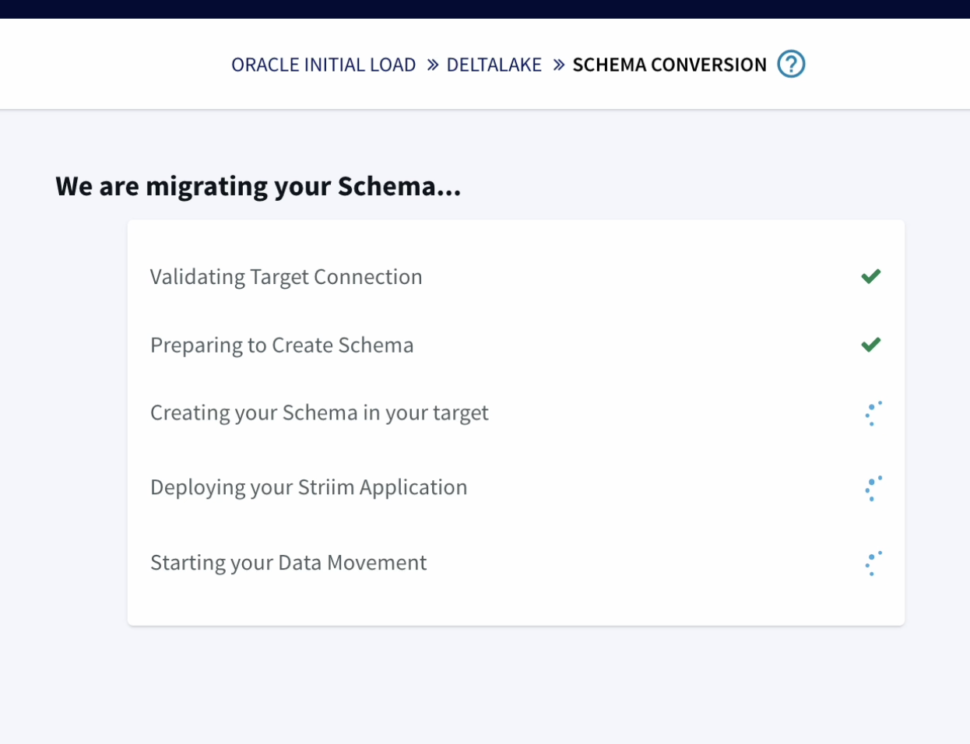
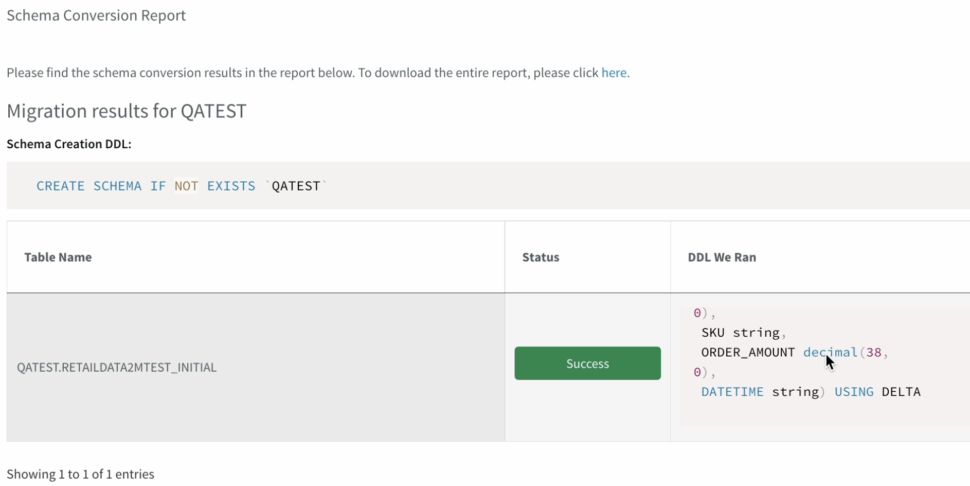
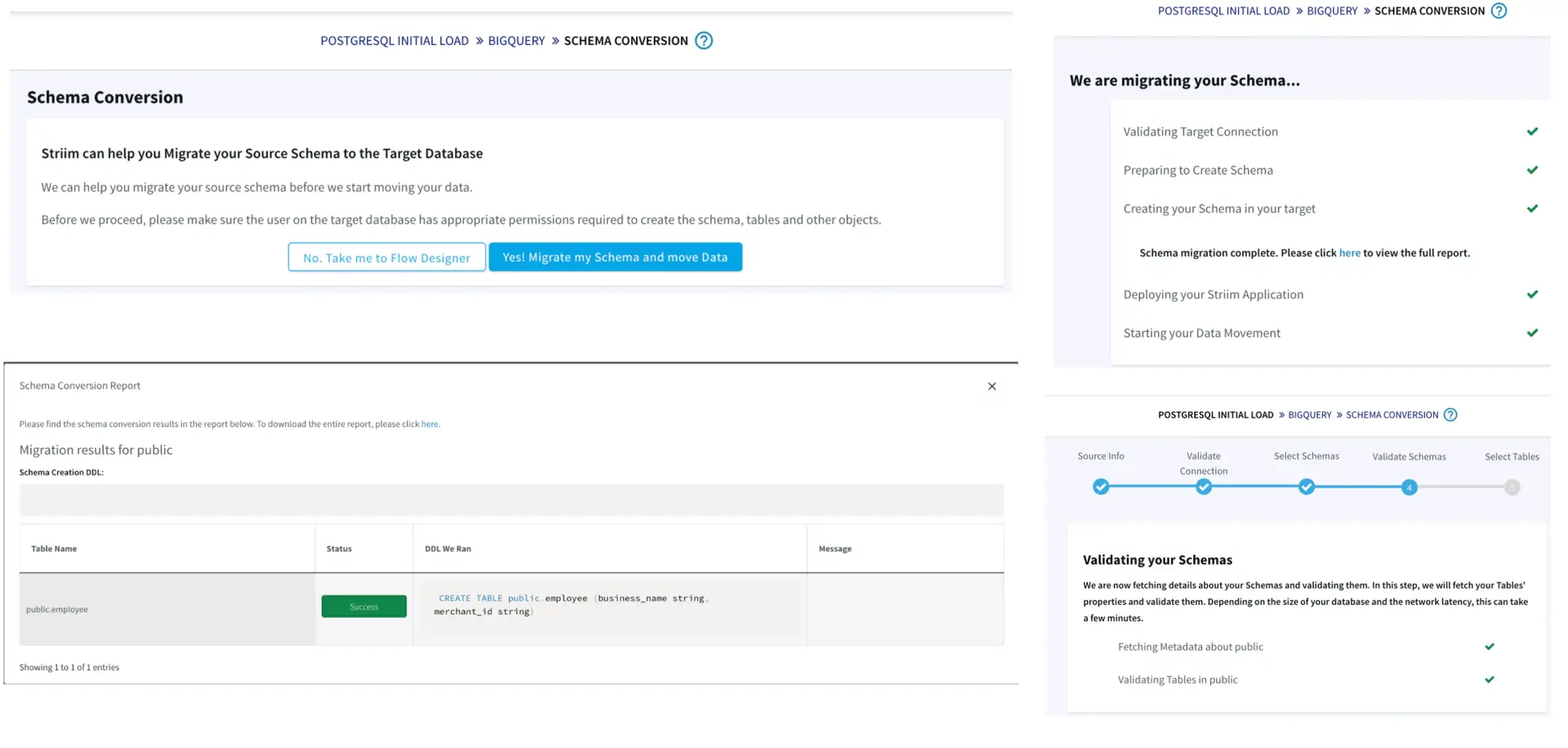
Striim has the capability to migrate schemas too as part of the wizard which makes it very seamless and easy.
The wizard takes care of validating the target connections, using the oracle metadata to create schema in the target and initiate the historical data push to delta lake as well.
Making the whole end to end operation finish in less then a fraction of the time it would take with traditional pipelines.
Once the schema is created, we can also verify it before we go ahead with the migration to Delta lake
Striim’s unified data integration provides unprecedented speed and simplicity which we have just observed on how simple it was to connect a source and target.
In case, we want to make additional changes to the Fetch size, provide a custom Query. The second half of the demo highlights , how we can apply those changes without the wizard.
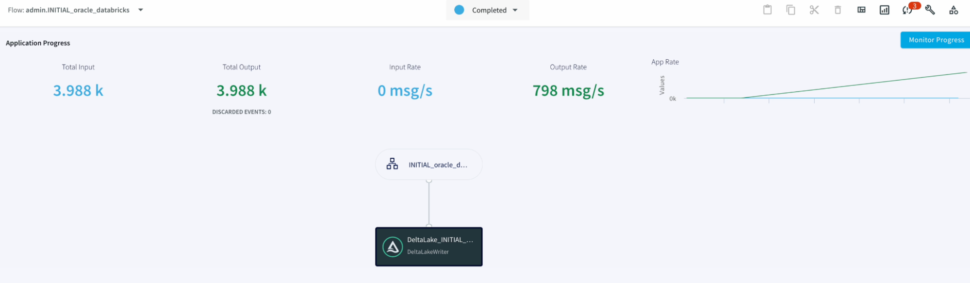
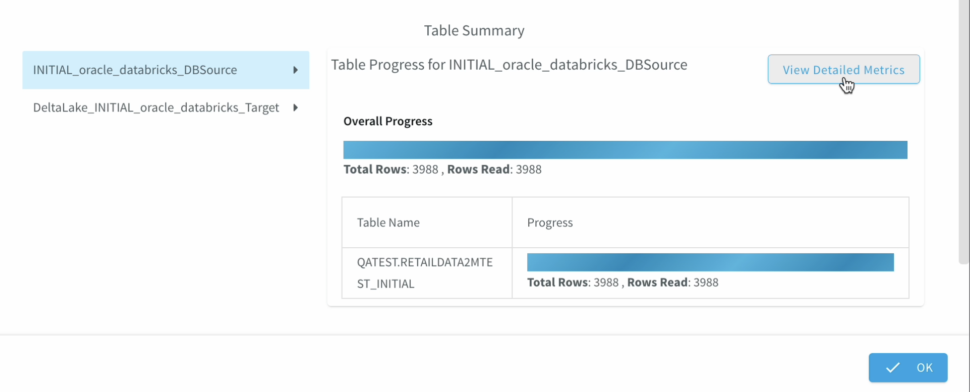
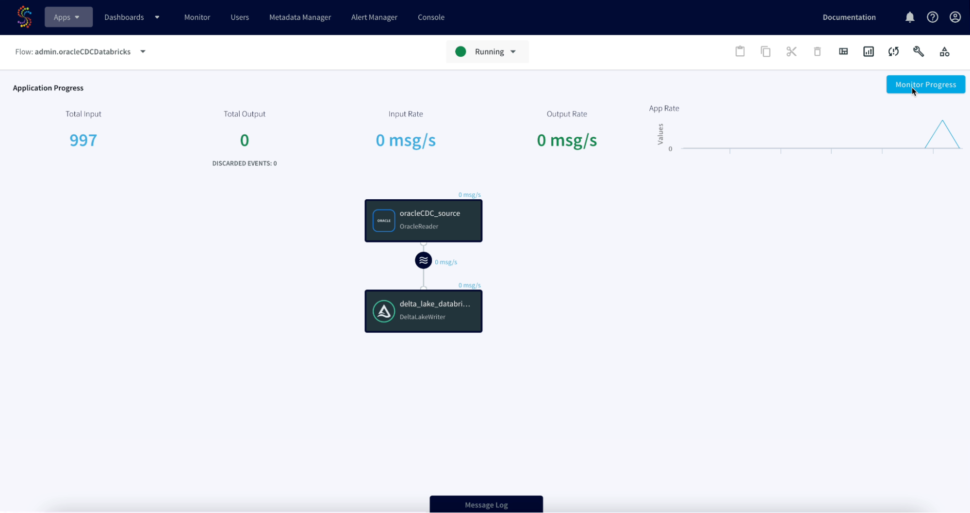
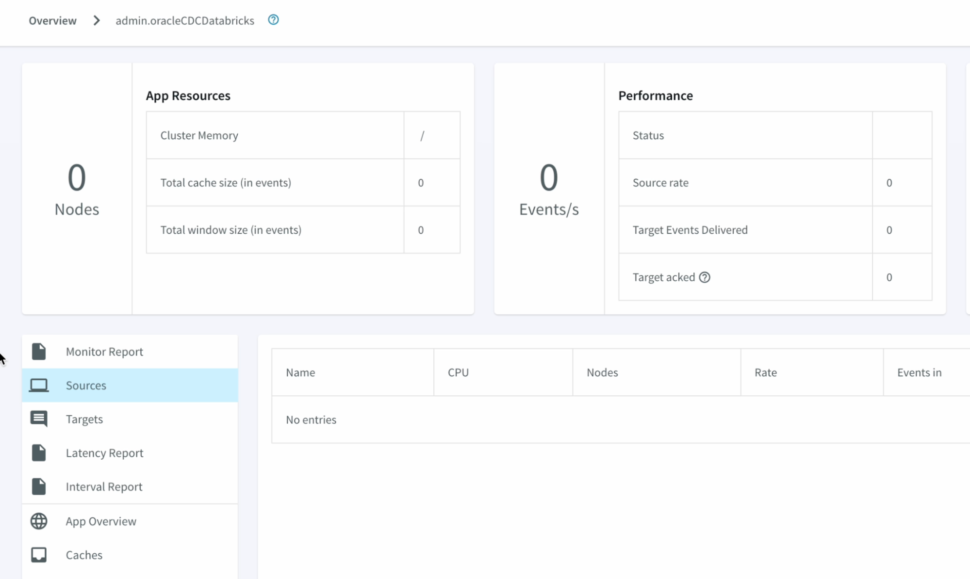
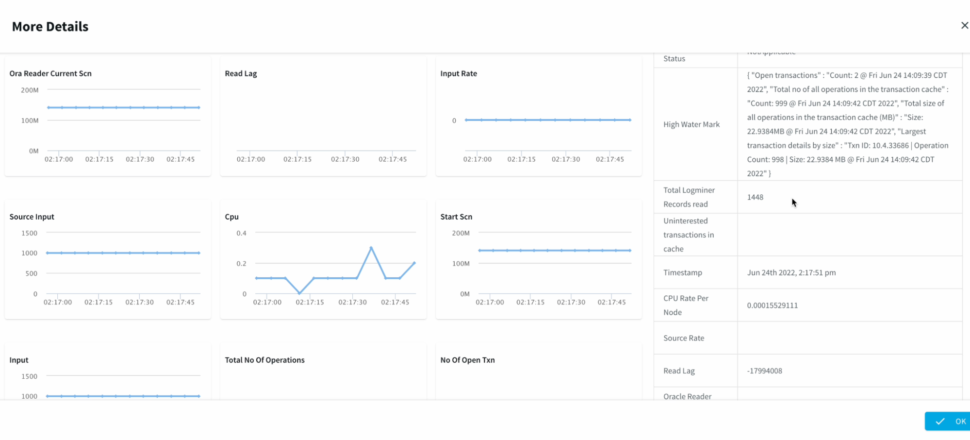
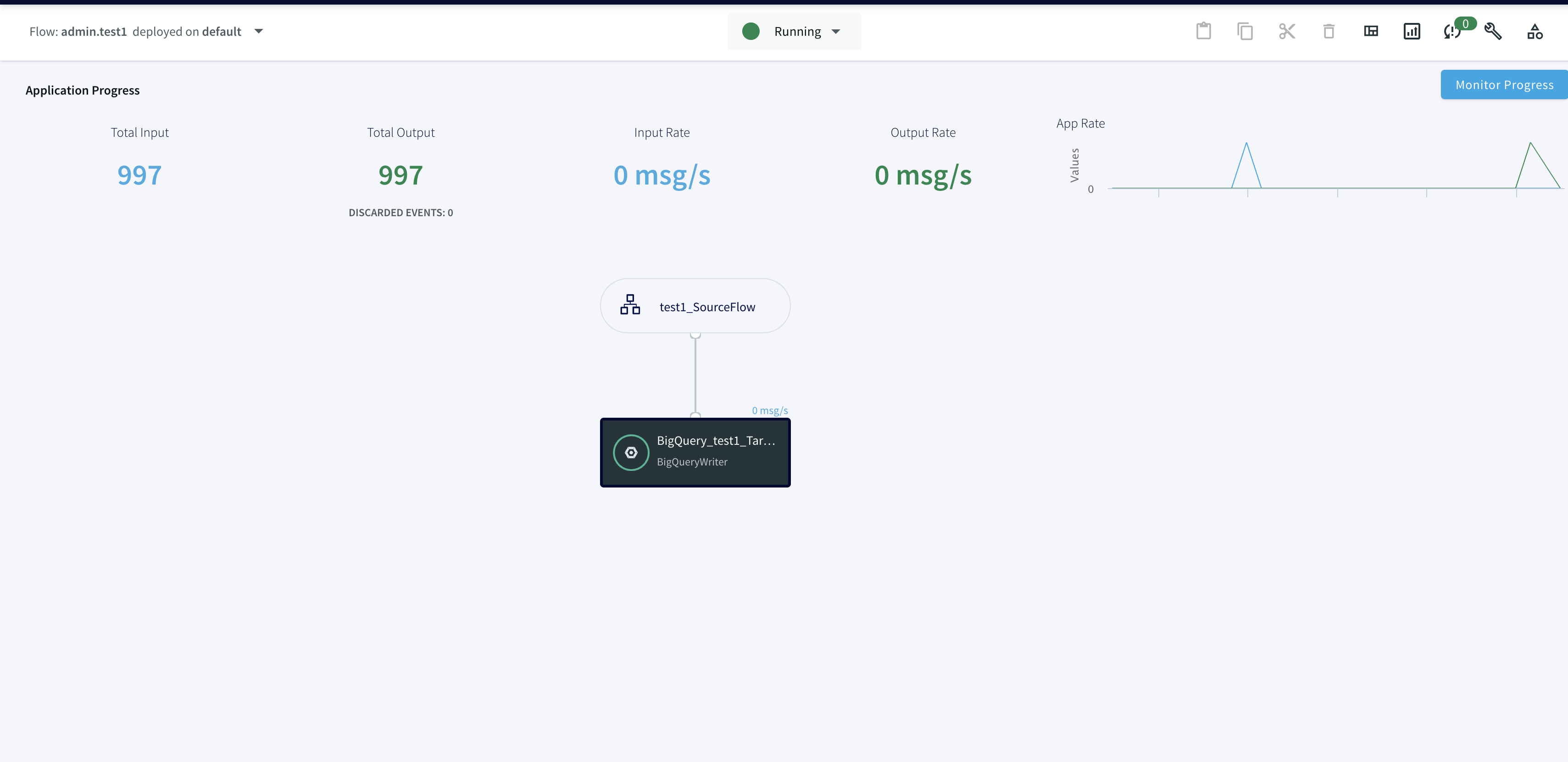
We can Monitor the progress of the job with detailed metrics which would help with the data governance to ensure data has been replicated appropriately.
Part 2: Change Data Capture
As part of our second demo, we will be highlighting Striim’s Change data Capture that helps drive Digital transformation and leverage true real time analytics.
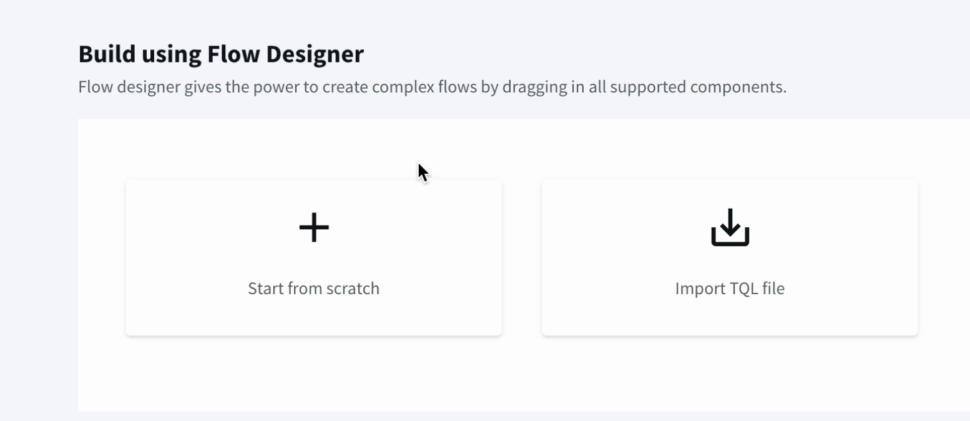
Earlier we have gone through how to create a pipeline through the wizard, and Now we will have a look at how we can tune our pipeline without the wizard and use the intuitive drag and drop flow design
From the Striim dashboard , we can navigate the same way as earlier to create An Application from scratch or also import a TQL file if we already have a pipeline created.
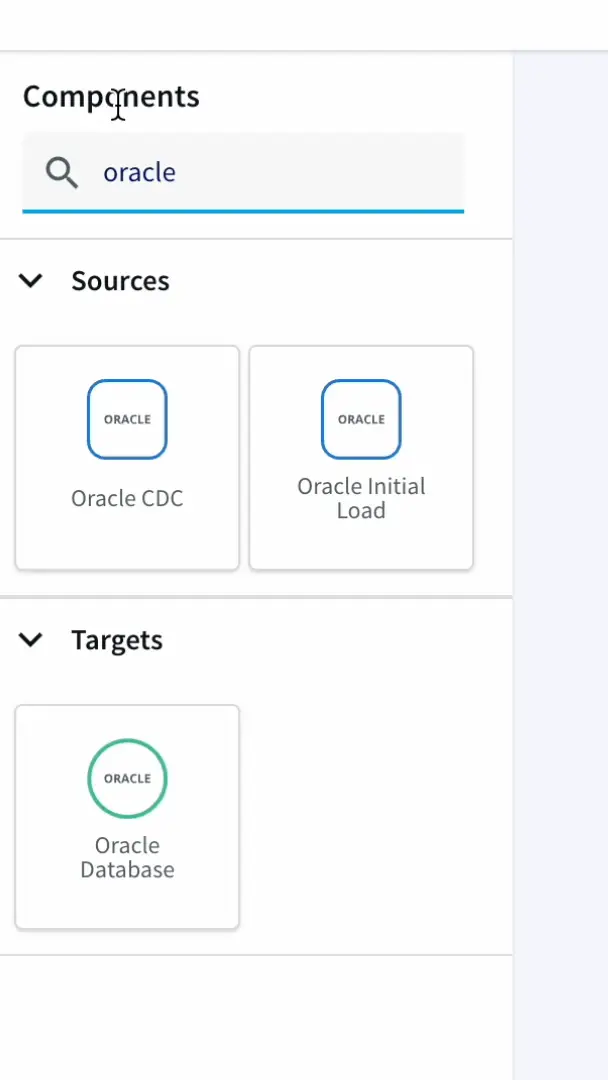
From the search bar, we can search for the oracle CDC adapter. The UI is super friendly with an easy drag and drop approach.
We can skip the wizard if we want and go ahead and enter the connection parameters like earlier.
In the additional parameters, we have the flexibility to make any changes to the data we pull from the source.
Lastly, we can create an output stream that will connect to the data sink
We can test connections and validate our connections even without deploying the app or pipeline.
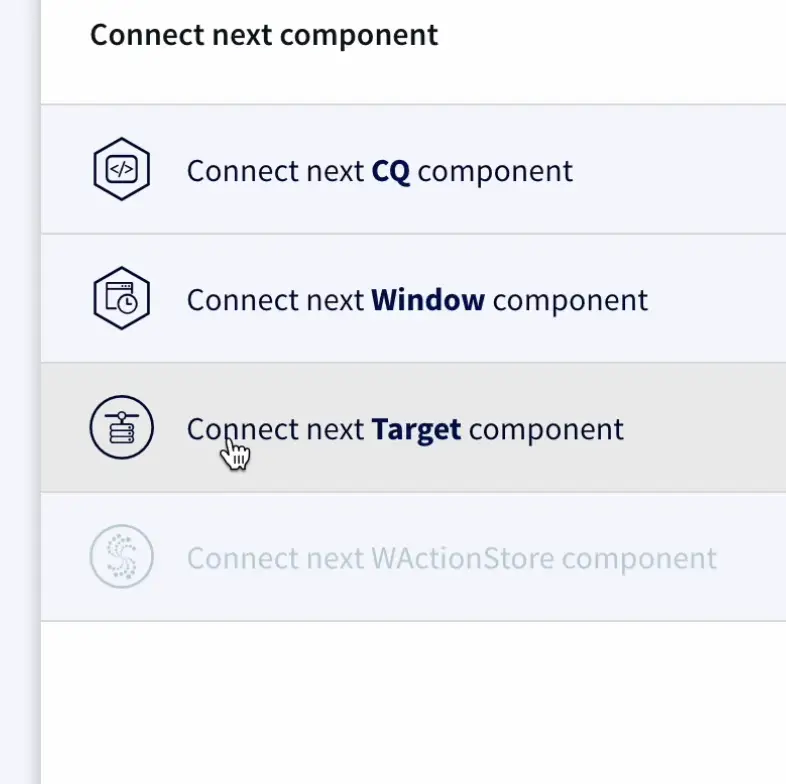
Once the source connection is established , we can connect to a target component, and select the delta Lake adapter from the drop down.
Databricks has a unified approach to its design that allows us to bridge the gap between different types of users ranging from Analysts, Data Scientists, and Machine Learning Engineers.
From the Databricks dashboard, we can navigate to the Compute section to access the cluster’s connection parameters.
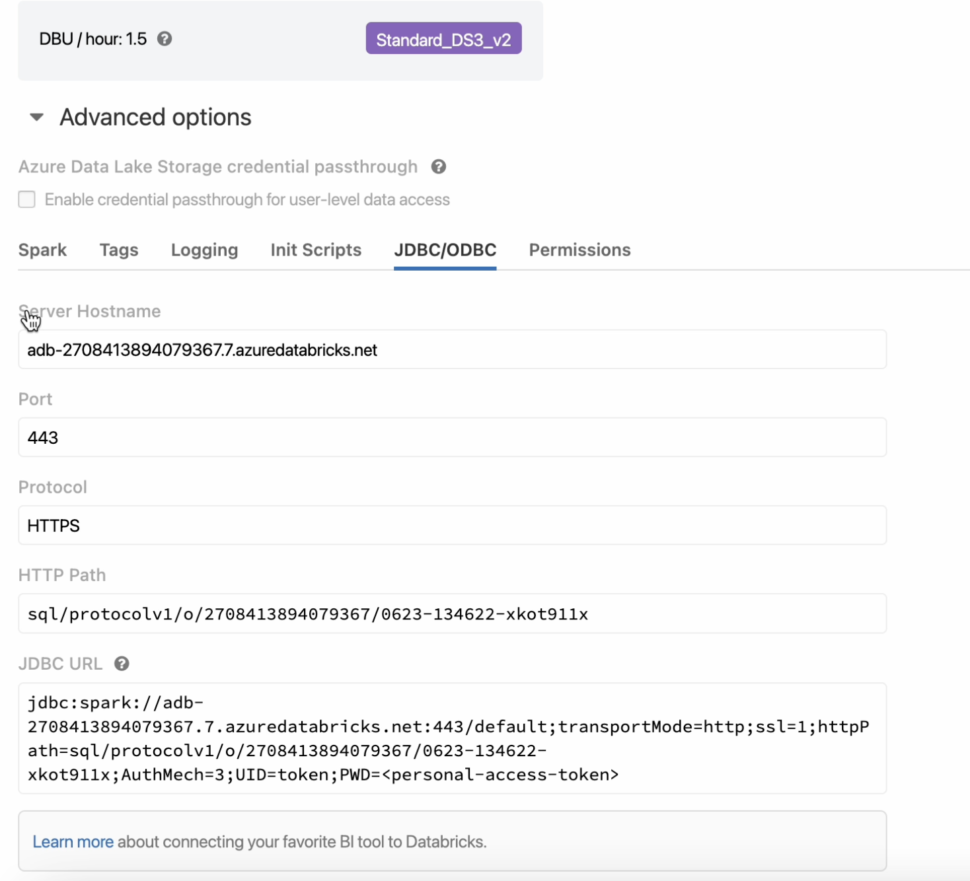
Under the advanced settings, select the JDBC/ODBC settings to view the cluster’s Hostname and JDBC URL.
Next, we can go ahead and generate a Personal access token that will be used to authenticate the user’s access to DatabricksFrom the settings, we can navigate to the user’s settings and click on Generate a new token.
After adding the required parameters, we can go ahead and create the directory in DBFS through the following commands in a notebook
Next, we can go ahead and deploy the app and start the flow to initiate the CDC.
We can refresh Databricks to view the CDC data, Striim allows us to view the detailed metrics of a pipeline in real-time.
Tools you need
Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
Databricks
Databricks combines data warehouse and Data lake into a Lakehouse architecture
Oracle
Oracle is a multi-model relational database management system.
Delta Lake
Delta Lake is an open-source storage framework that supports building a lakehouse architecture
Conclusion
Managing large-scale data is a challenge for every enterprise. Real-time, integrated data is a requirement to stay competitive, but modernizing your data architecture can be an overwhelming task.
Striim can handle the volume, complexity, and velocity of enterprise data by connecting legacy systems to modern cloud applications on a scalable platform. Our customers don’t have to pause operations to migrate data or juggle different tools for every data source—they simply connect legacy systems to newer cloud applications and get data streaming in a few clicks.
Seamless integrations. Near-perfect performance. Data up to the moment. That’s what embracing complexity without sacrificing performance looks like to an enterprise with a modern data stack.
Use cases
Integrating Striim’s CDC capabilities with Databricks makes it very easy to rapidly expand the capabilities of a Lakehouse with just a few clicks.
Striim’s additional components allow not only to capture real-time data, but also apply transformations on the fly before it even lands in the staging zone, thereby reducing the amount of data cleansing that is required.
The wide array of Striim’s event transformers makes it as seamless as possible with handling any type of sensitive data allowing users to maintain compliance norms on various levels.
Allow high-quality data into Databricks which can then be transformed via Spark code and loaded into Databrick’s new services such as Delta Live tables.
Migrating from MySQL to BigQuery for Real-Time Data Analytics
How to replicate and synchronize your data from on-premises MySQL to BigQuery using change data capture CDC)
Benefits
Operational AnalyticsAnalyze your data in real-time without impacting the performance of your operational database.Act in Real TimePredict, automate, and react to business events as they happen, not minutes or hours later.Empower Your TeamsGive teams across your organization a real-time view into operational data
On this page
Overview
In this post, we will walk through an example of how to replicate and synchronize your data from on-premises MySQL to BigQuery using change data capture (CDC).
Data warehouses have traditionally been on-premises services that required data to be transferred using batch load methods. Ingesting, storing, and manipulating data with cloud data services like Google BigQuery makes the whole process easier and more cost effective, provided that you can get your data in efficiently.
Striim real-time data integration platform allows you to move data in real-time as changes are being recorded using a technology called change data capture. This allows you to build real-time analytics and machine learning capabilities from your on-premises datasets with minimal impact.
Step 1: Source MySQL Database
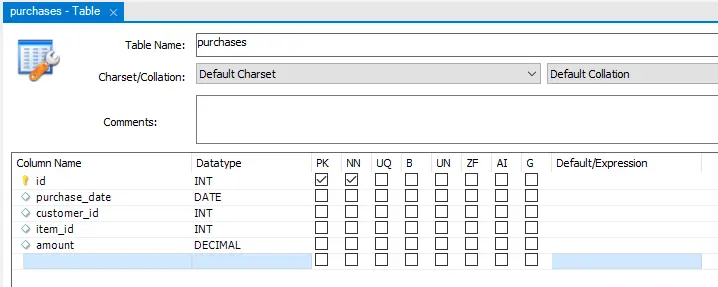
Before you set up the Striim platform to synchronize your data from MySQL to BigQuery, let’s take a look at the source database and prepare the corresponding database structure in BigQuery. For this example, I am using a local MySQL database with a simple purchases table to simulate a financial datastore that we want to ingest from MySQL to BigQuery for analytics and reporting.
I’ve loaded a number of initial records into this table and have a script to apply additional records once Striim has been configured to show how it picks up the changes automatically in real time.
Step 2: Targeting Google BigQuery
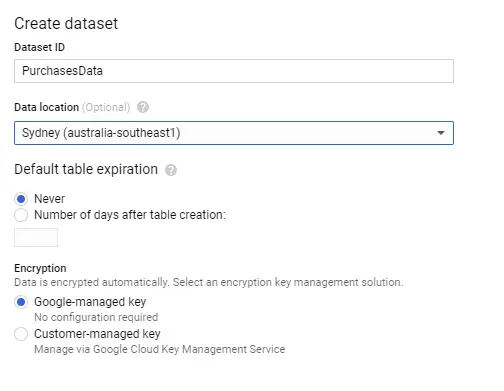
You also need to make sure your instance of BigQuery has been set up to mirror the source or the on-premises data structure. There are a few ways to do this, but because you are using a small table structure, you are going to set this up using the Google Cloud Console interface. Open the Google Cloud Console, and select a project, or create a new one. You can now select BigQuery from the available cloud services. Create a new dataset to hold the incoming data from the MySQL database.
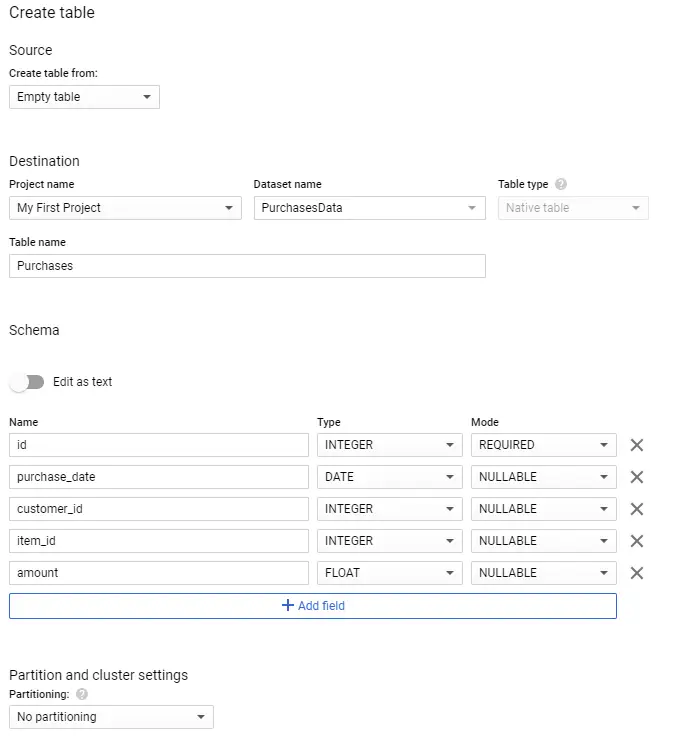
Once the dataset has been created, you also need to create a table structure. Striim can perform the transformations while the data flies through the synchronization process. However, to make things a little easier here, I have replicated the same structure as the on-premises data source.
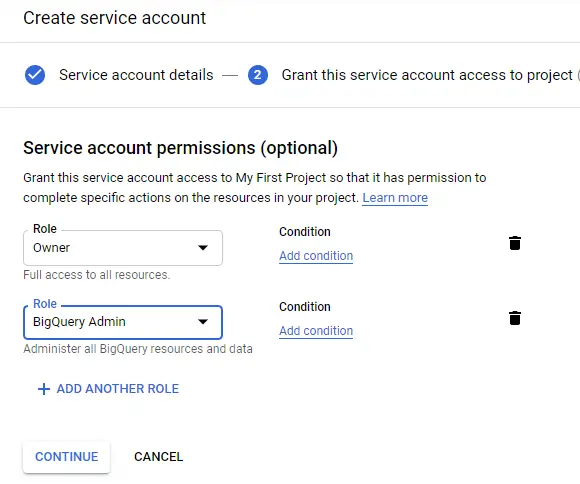
You will also need a service account to allow your Striim application to access BigQuery. Open the service account option through the IAM window in the Google Cloud Console and create a new service account. Give the necessary permissions for the service account by assigning BigQuery Owner and Admin roles and download the service account key to a JSON file.
Step 3: Set Up the Striim Application
Now you have your data in a table in the on-premises MySQL database and have a corresponding empty table with the same fields in BigQuery. Let’s now set up a Striim application on Google Cloud Platform for the migration service.
Open your Google Cloud Console and open or start a new project. Go to the marketplace and search for Striim. A number of options should return, but the option you are after is the first item that allows integration of real-time data to Google Cloud services.
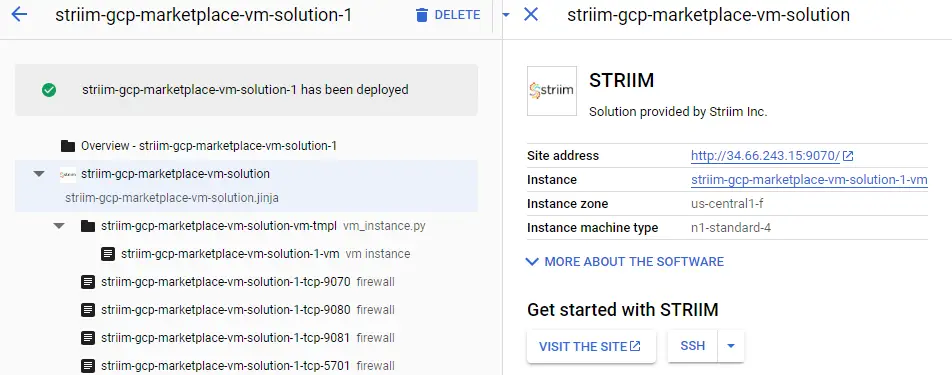
Select this option and start the deployment process. For this tutorial, you are just using the defaults for the Striim server. In production, you would need to size appropriately depending on your load.
Click the deploy button at the bottom of this screen and start the deployment process.
Once this deployment has finished, the details of the server and the Striim application will be generated.
Before you open the admin site, you will need to add a few files to the Striim Virtual Machine. Open the SSH console to the machine and copy the JSON file with the service account key to a location Striim can access. I used /opt/striim/conf/servicekey.json.
You also need to restart the Striim services for these setting and changes to take effect. The easiest way to do this is to restart the VM.
Give these files the right permissions by running the following commands:
chown striim:striim
chmod 770
You also need to restart the Striim services for this to take effect. The easiest way to do this is to restart the VM.
Once this is done, close the shell and click on the Visit The Site button to open the Striim admin portal.
Before you can use Striim, you will need to configure some basic details. Register your details and enter in the Cluster name (I used “DemoCluster”) and password, as well as an admin password. Leave the license field blank to get a trial license if you don’t have a license, then wait for the installation to finish.
When you get to the home screen for Striim, you will see three options. Let’s start by creating an app to connect your on-premises database with BigQuery to perform the initial load of data. To create this application, you will need to start from scratch from the applications area. Give your application a name and you will be presented with a blank canvas.
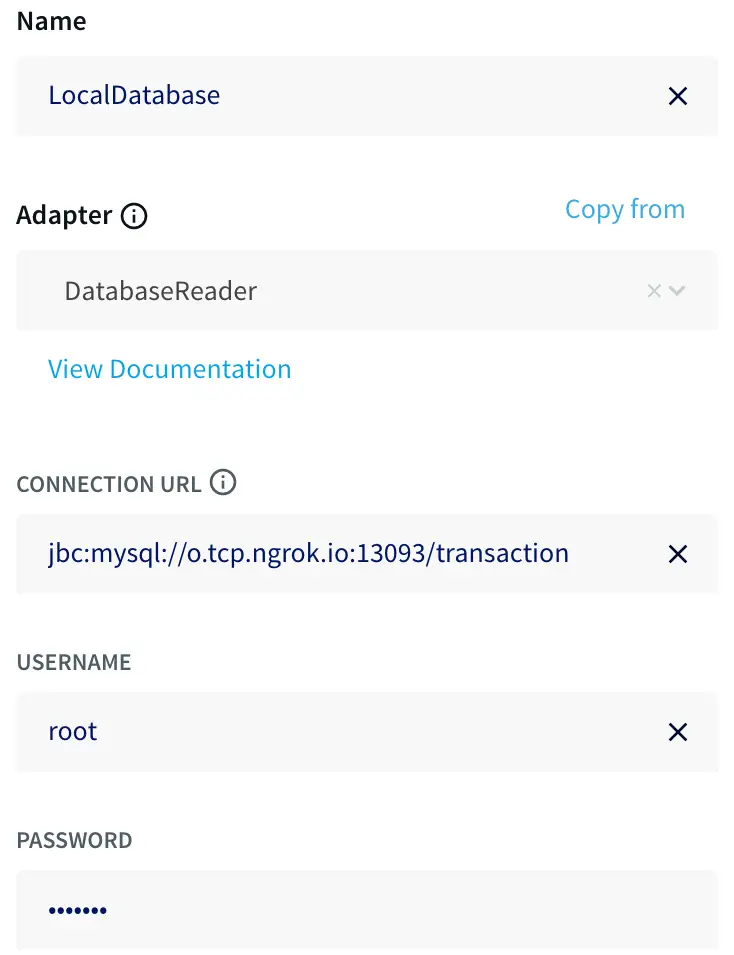
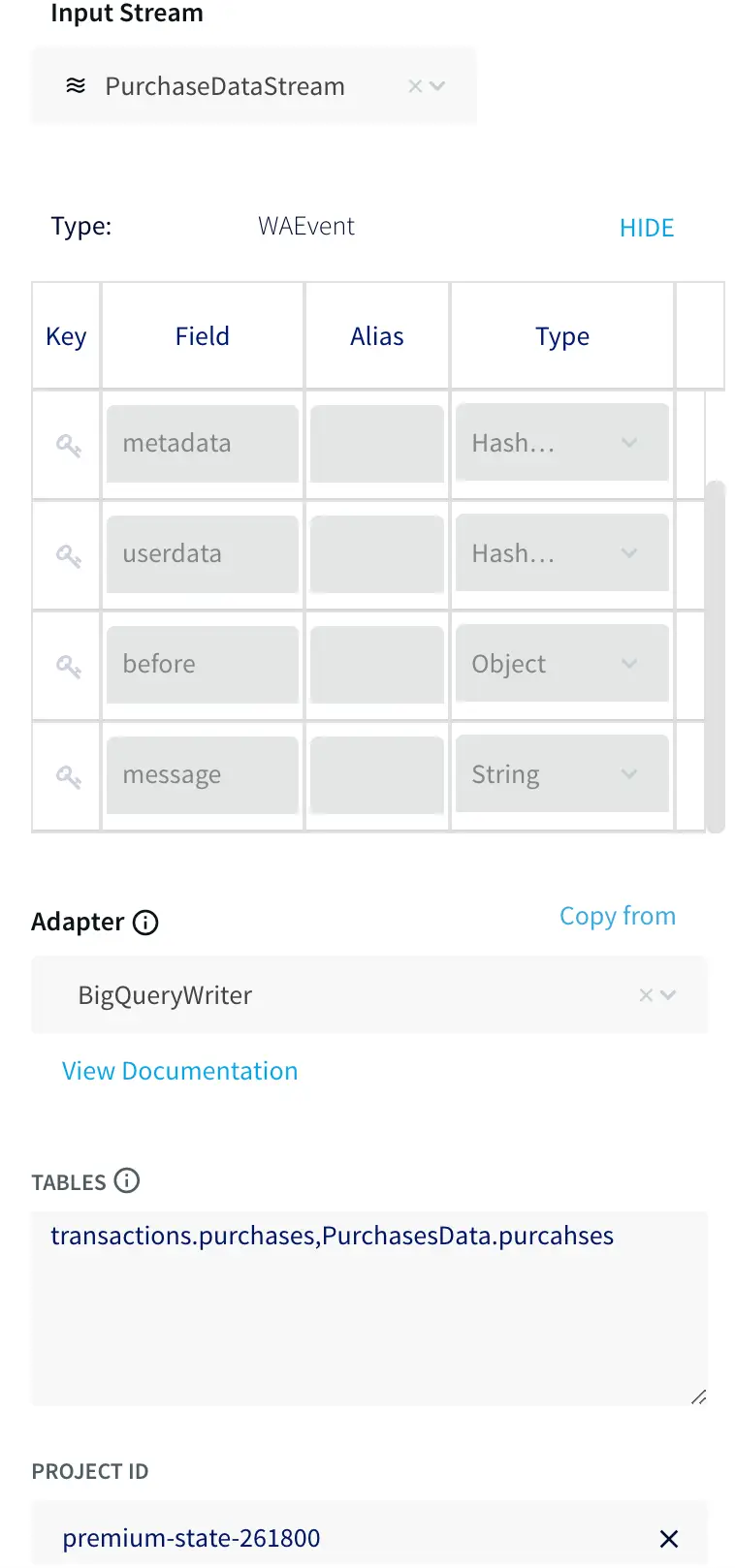
The first step is to read data from MySQL, so drag a database reader from the sources tab on the left. Double-click on the database reader to set the connection string with a JDBC-style URL using the template:
jdbc:mysql://:/
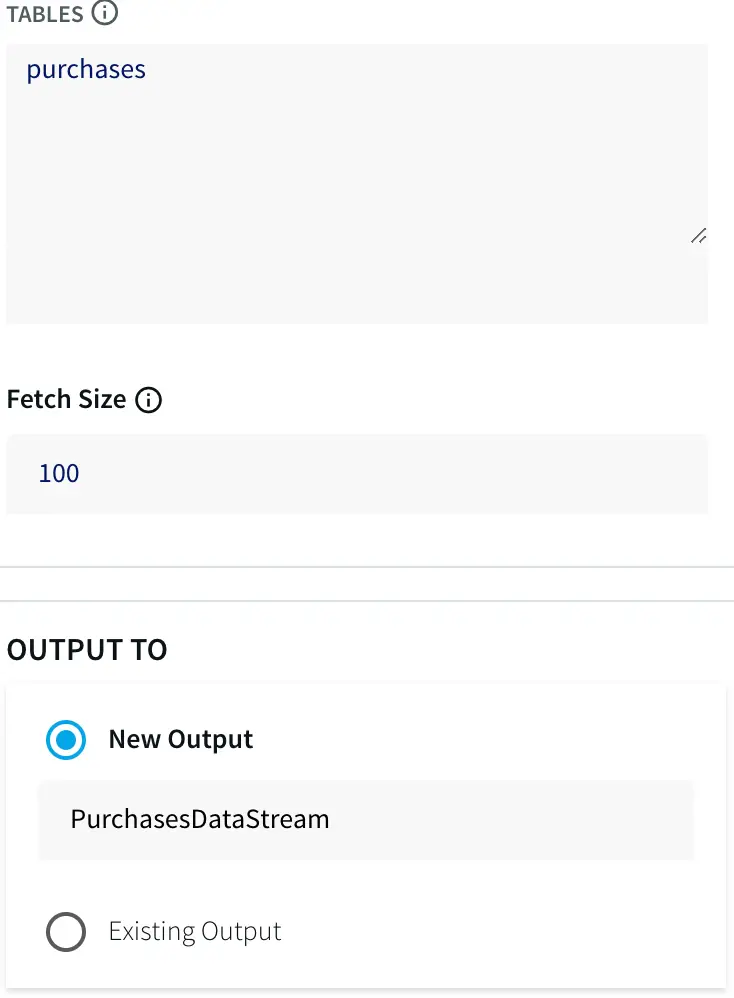
You must also specify the tables to synchronize — for this example, purchases — as this allows you to restrict what is synchronized.
Finally, create a new output. I called mine PurchasesDataStream.
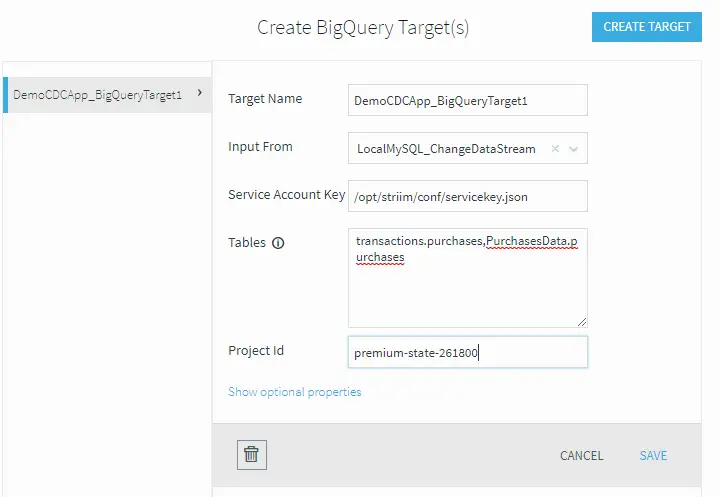
You also need to connect your BigQuery instance to your source. Drag a BigQuery writer from the targets tab on the left. Double-click on the writer and select the input stream from the previous step and specify the location of the service account key. Finally, map the source and target tables together using the form:
.,.
For this use case this is just a single table on each side.
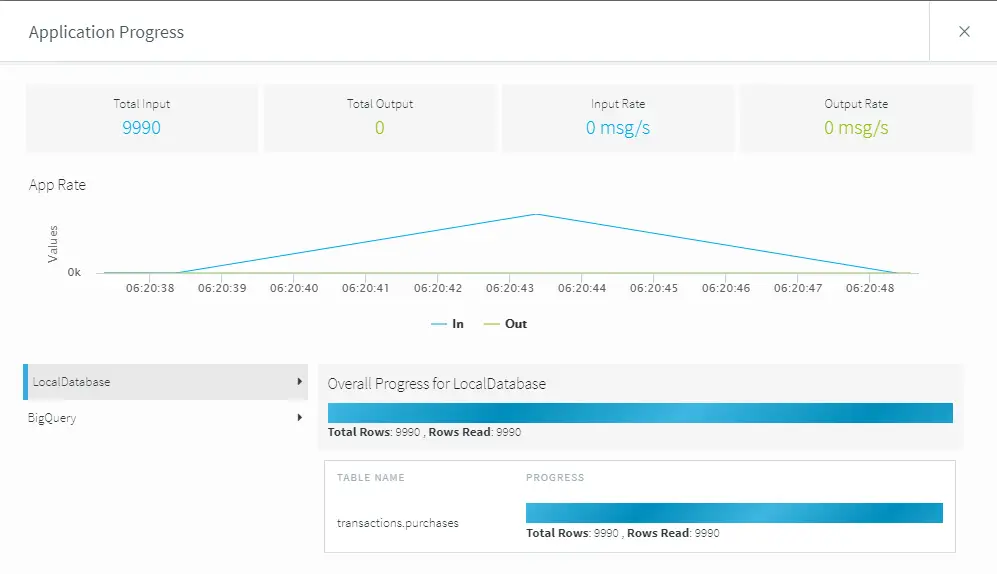
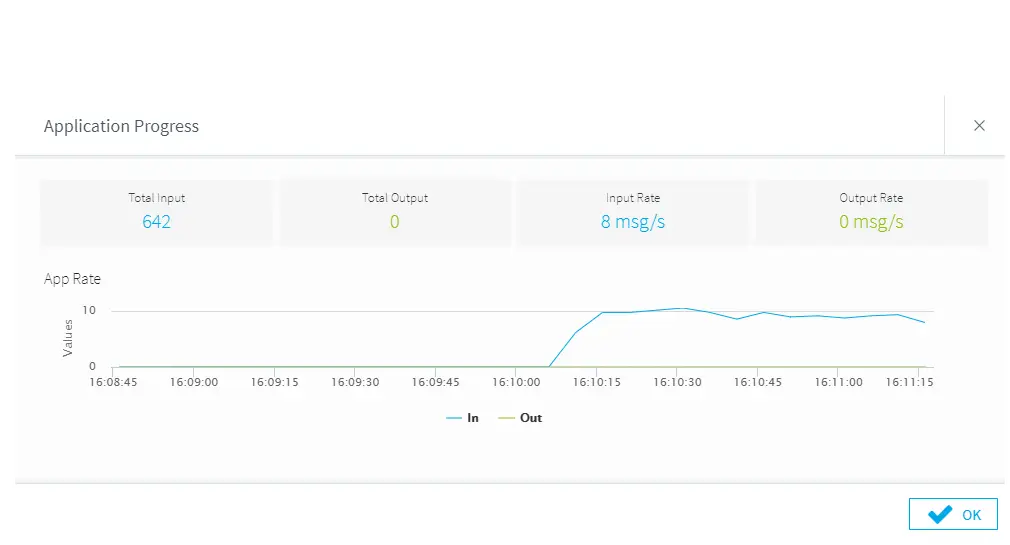
Once both the source and target connectors have been configured, deploy and start the application to begin the initial load process. Once the application is deployed and running, you can use the monitor menu option on the top left of the screen to watch the progress.
Because this example contains a small data load, the initial load application finishes pretty quickly. You can now stop this initial load application and move on to the synchronization.
Step 4: Updating BigQuery with Change Data Capture
Striim has pushed your current database up into BigQuery, but ideally you want to update this every time the on-premises database changes. This is where the change data capture application comes into play.
Go back to the applications screen in Striim and create a new application from a template. Find and select the MySQL CDC to BigQuery option.
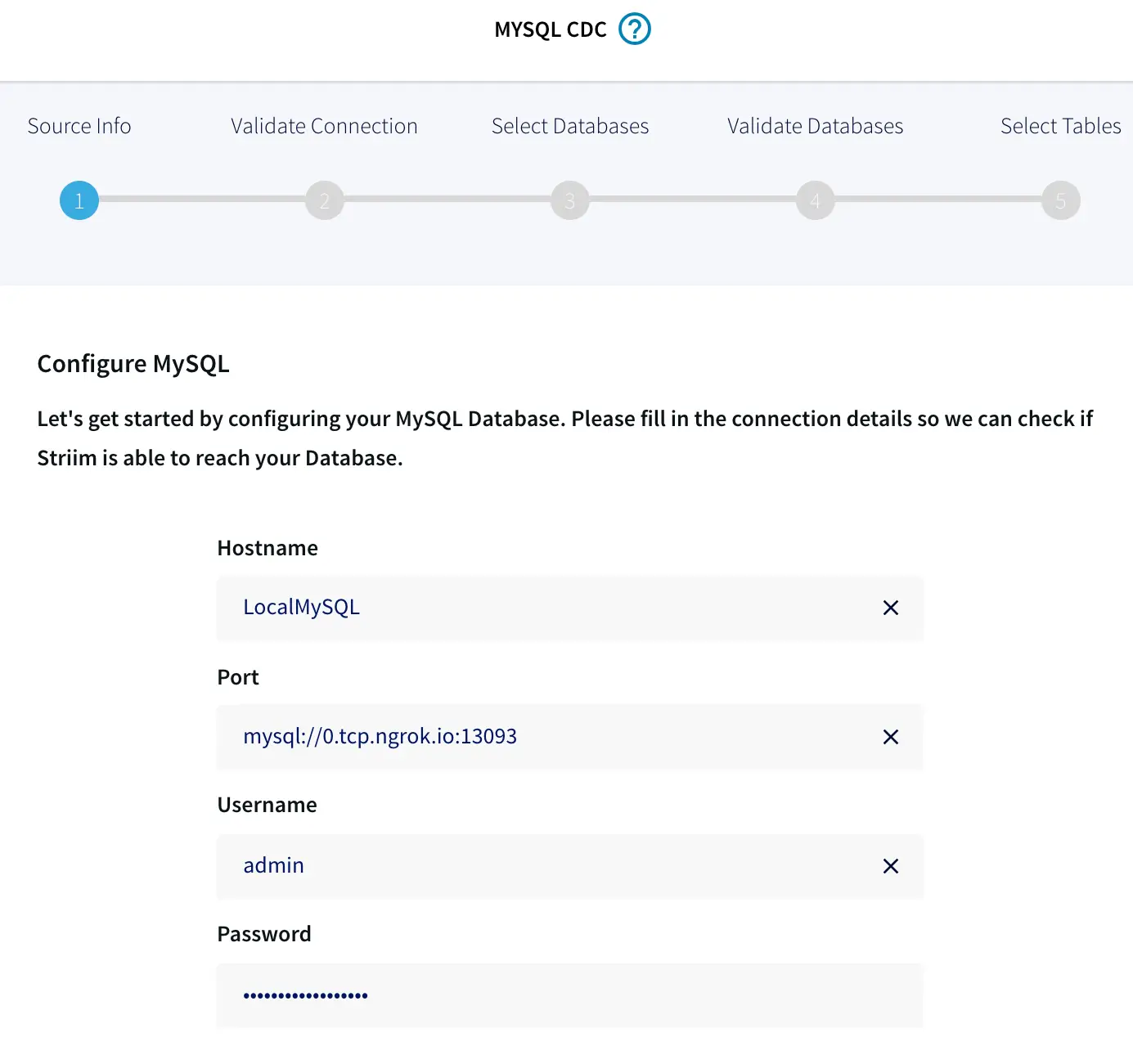
Like the first application, you need to configure the details for your on-premises MySQL source. Use the same basic settings as before. However, this time the wizard adds the JDBC component to the connection URL.
When you click Next, Striim will ensure that it can connect to the local source. Striim will retrieve all the tables from the source. Select the tables you want to sync. For this example, it’s just the purchases table.
Once the local tables are mapped, you need to connect to the BigQuery target. Again, you can use the same settings as before by specifying the same service key JSON file, table mapping, and GCP Project ID.
Once the setup of the application is complete, you can deploy and turn on the synchronization application. This will monitor the on-premises database for any changes, then synchronize them into BigQuery.
Let’s see this in action by clicking on the monitor button again and loading some data into your on-premises database. As the data loads, you will see the transactions being processed by Striim.
Next Step
As you can see, Striim makes it easy for you to synchronize your on-premises data from existing databases, such as MySQL, to BigQuery. By constantly moving your data into BigQuery, you could now start building analytics or machine learning models on top, all with minimal impact to your current systems. You could also start ingesting and normalizing more datasets with Striim to fully take advantage of your data when combined with the power of BigQuery.
Deliver Real-Time Insights and Fresh Data with dbt and Striim on Snowflake Partner Connect
Use Striim to stream data from PostgreSQL to Snowflake and coordinate transform jobs in dbt
Benefits
Manage Scalable Applications Integrate Striim with dbt to transform and monitor real time data SLAs
Capture Data Updates in real time Use Striim’s postgrescdc reader for real time data updates
Build Real-Time Analytical ModelsUse dbt to build Real-Time analytical and ML models
On this page
Overview
Striim is a unified data streaming and integration product that offers change capture (CDC) enabling continuous replication from popular databases such as Oracle, SQLServer, PostgreSQL and many others to target data warehouses like BigQuery and Snowflake.
dbt Cloud is a hosted service that helps data analysts and engineers productionize dbt deployments. It is a popular technique among analysts and engineers to transform data into usable formats and also ensuring if source data freshness is meeting the SLAs defined for the project. Striim collaborates with dbt for effective monitoring and transformation of the in-flight data. For example, if the expectation is that data should be flowing every minute based on timestamps, then dbt will check that property and make sure the time between last check and latest check is only 1 minute apart.
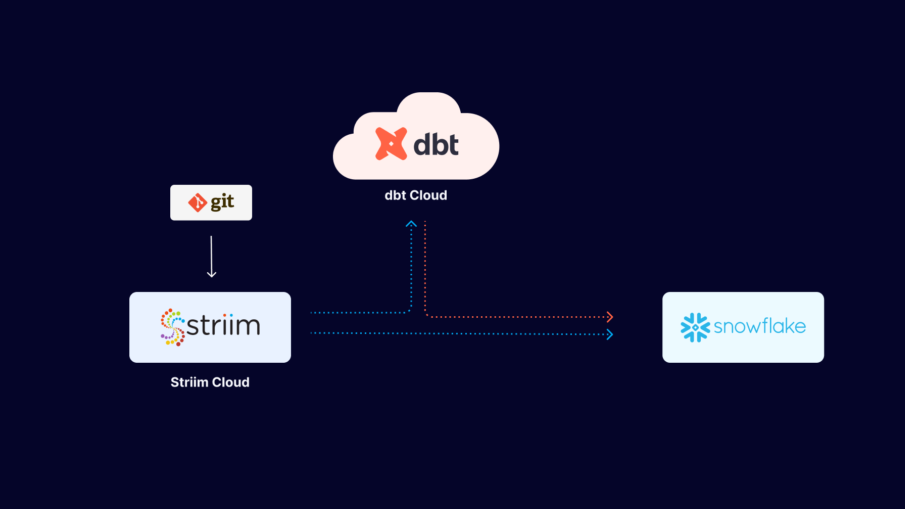
In this recipe, we have shown how Striim and dbt cloud can be launched from Snowflake’s Partner Connect to perform transformation jobs and ensure data freshness with Snowflake data warehouse as the target.
Core Striim Components
PostgreSQL CDC: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
Snowflake Writer: Striim’s Snowflake Writer writes to one or more existing tables in Snowflake. Events are staged to local storage, Azure Storage, or AWS S3, then written to Snowflake as per the Upload Policy setting.
Benefits of DBT Integration with Striim for Snowflake
Striim and dbt work like magic with Snowflake to provide a simple, near real-time cloud data integration and modeling service for Snowflake. Using Striim, dbt, and Snowflake a powerful integrated data streaming system for real-time analytics that ensures fresh data SLAs across your company.
Striim is unified data streaming and integration product that can ingest data from various sources including change data from databases (Oracle, PostgreSQL, SQLServer, MySQL and others), and rapidly deliver it to your cloud systems such as Snowflake. Data loses it’s much of its value over time and to make the most out of it, real-time analytics is the modern solution. With dbt, datasets can be transformed and monitored within the data warehouse. Striim streams real-time data into the target warehouse where analysts can leverage dbt to build models and transformations. Coordinating data freshness validation between Striim and dbt is a resilient method to ensure service level agreements. Companies can leverage Striim integration with dbt in production to make real-time data transformation fast and reliable.
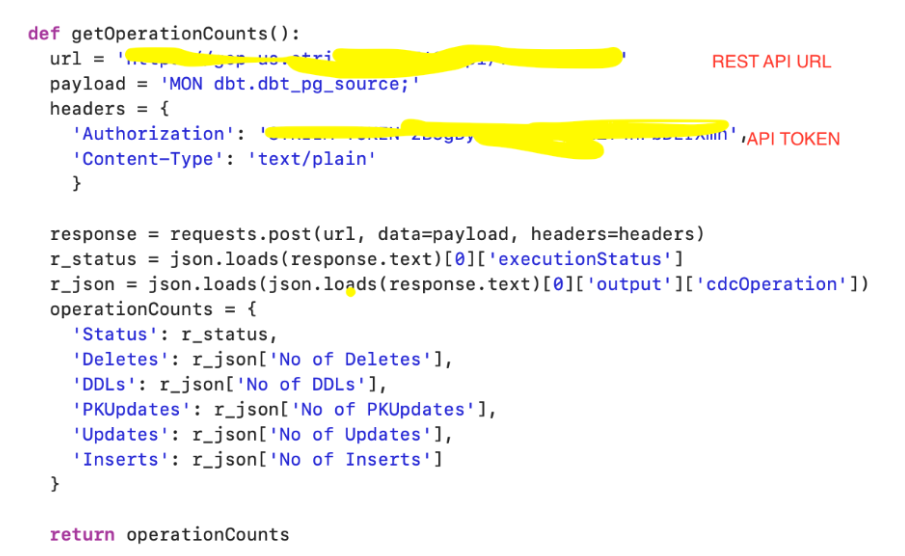
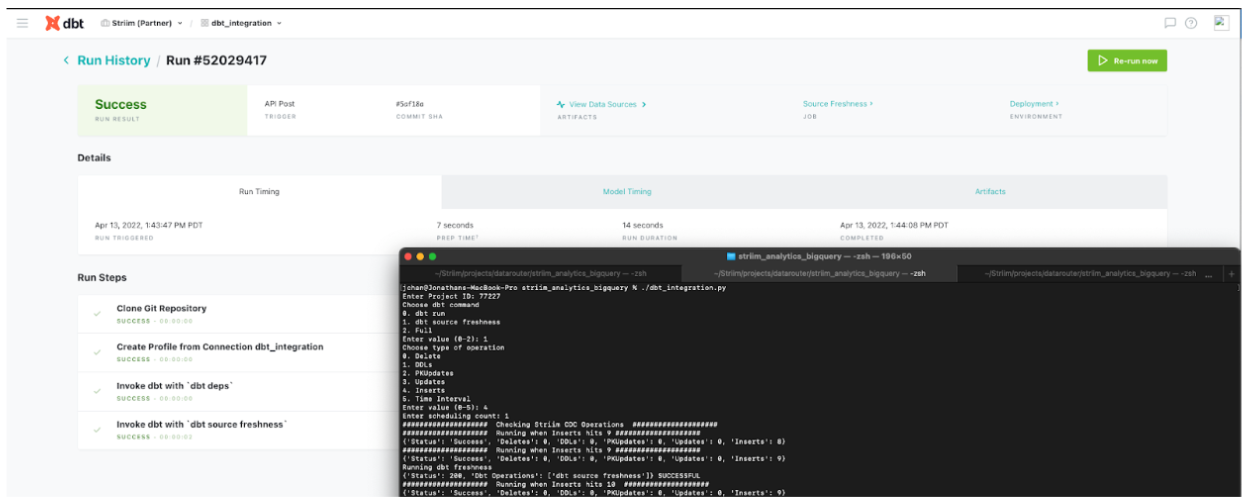
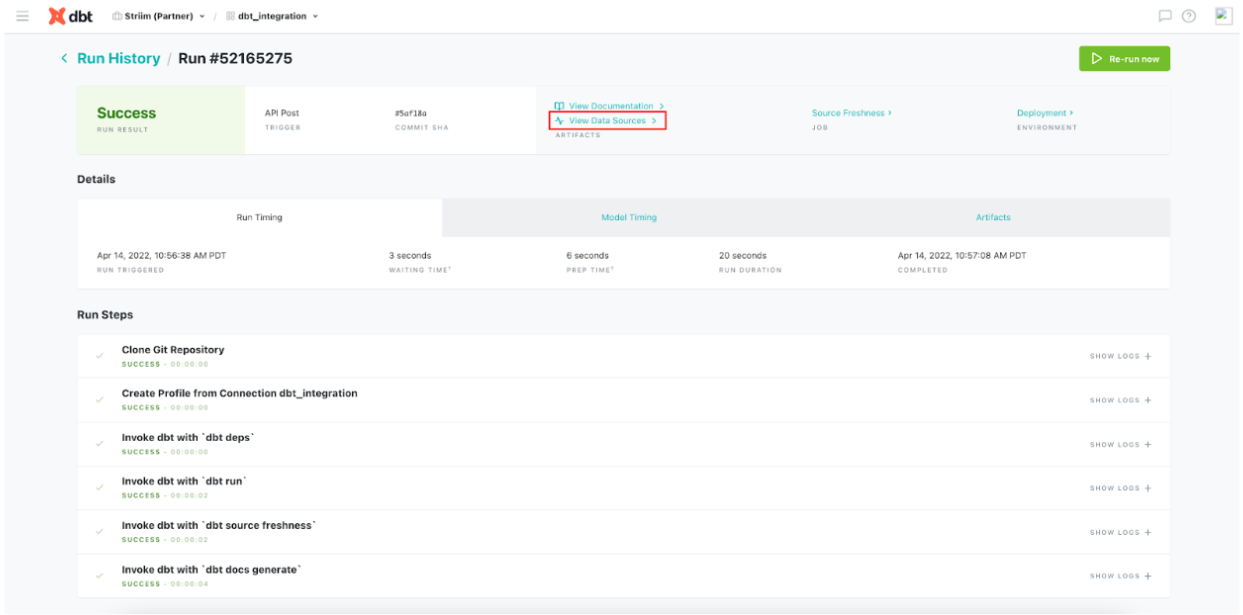
We have demonstrated how to build a simple python script that pings the Striim API to fetch metadata from the Striim source (getOperationCounts()) that records the number of DDLs, deletes, inserts and updates. This data can be used by dbt to monitor freshness, schedule or pause dbt jobs. For example, run dbt when n inserts occur on the source table or Striim CDC is in-sync. The schematic below shows the workflow of dbt cloud integration with striim server. Users can configure DBT scheduling within Striim via dbt cloud API calls. dbt integration with Striim enhances the user’s analytics pipeline after Striim has moved data in real-time.
Step 1: Launch Striim Cloud from Snowflake Partner Connect
Follow the steps below to connect Striim server to postgres instance containing the source database:
Launch Striim in Snowflake Partner Connect by clicking on “Partner Connect” in the top right corner of the navigation bar.
In the next window, you can launch Striim and sign up for a free trial.
Create your first Striim Service to move data to Snowflake.
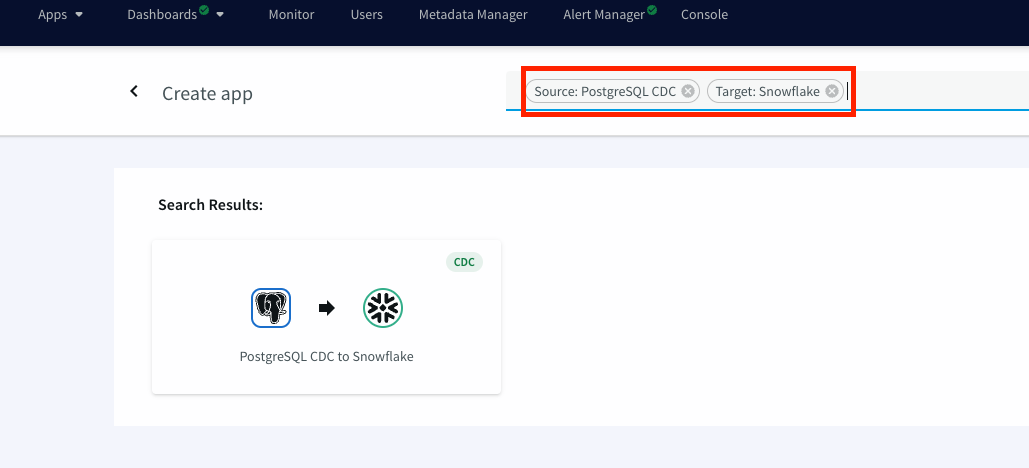
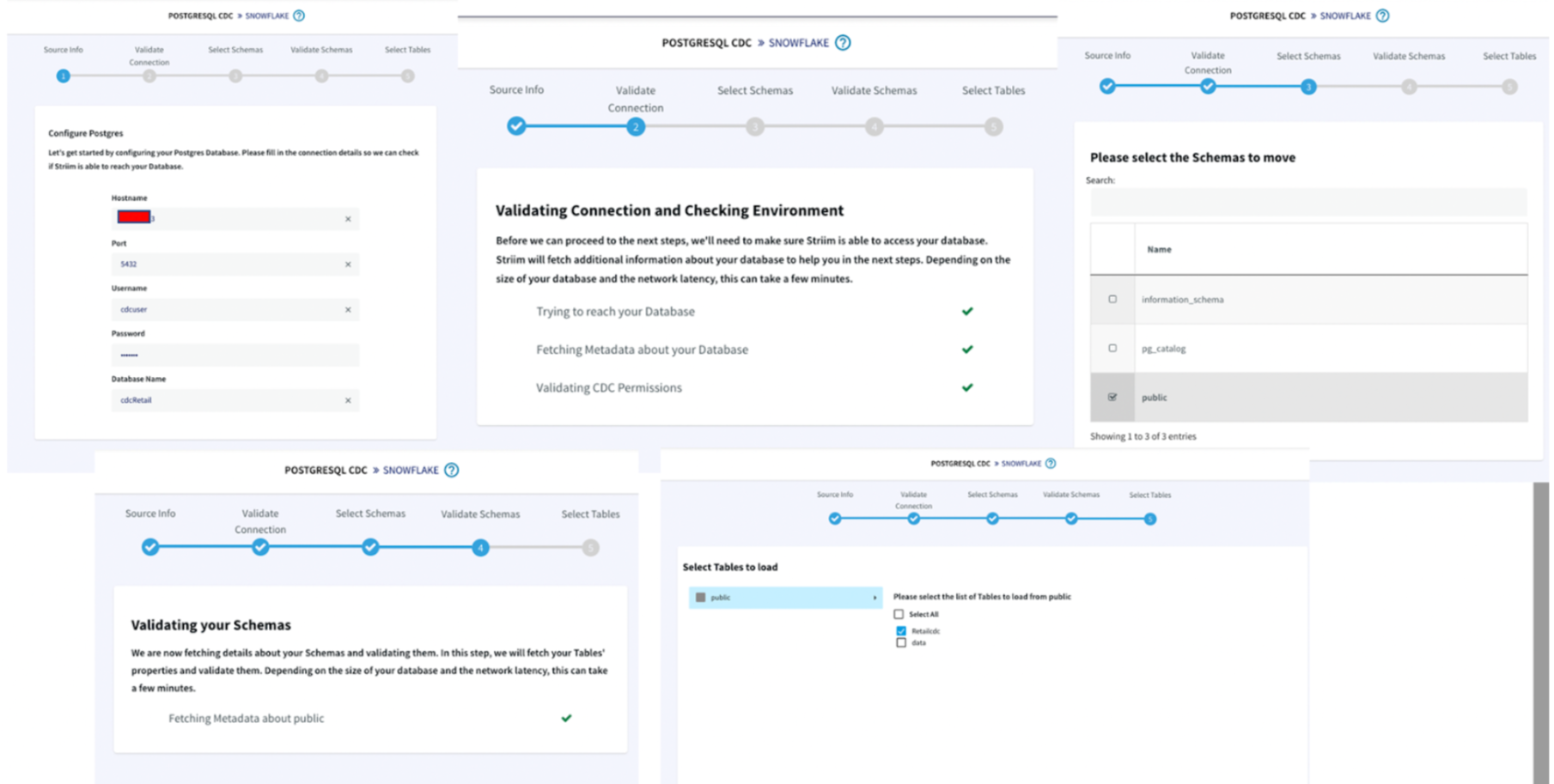
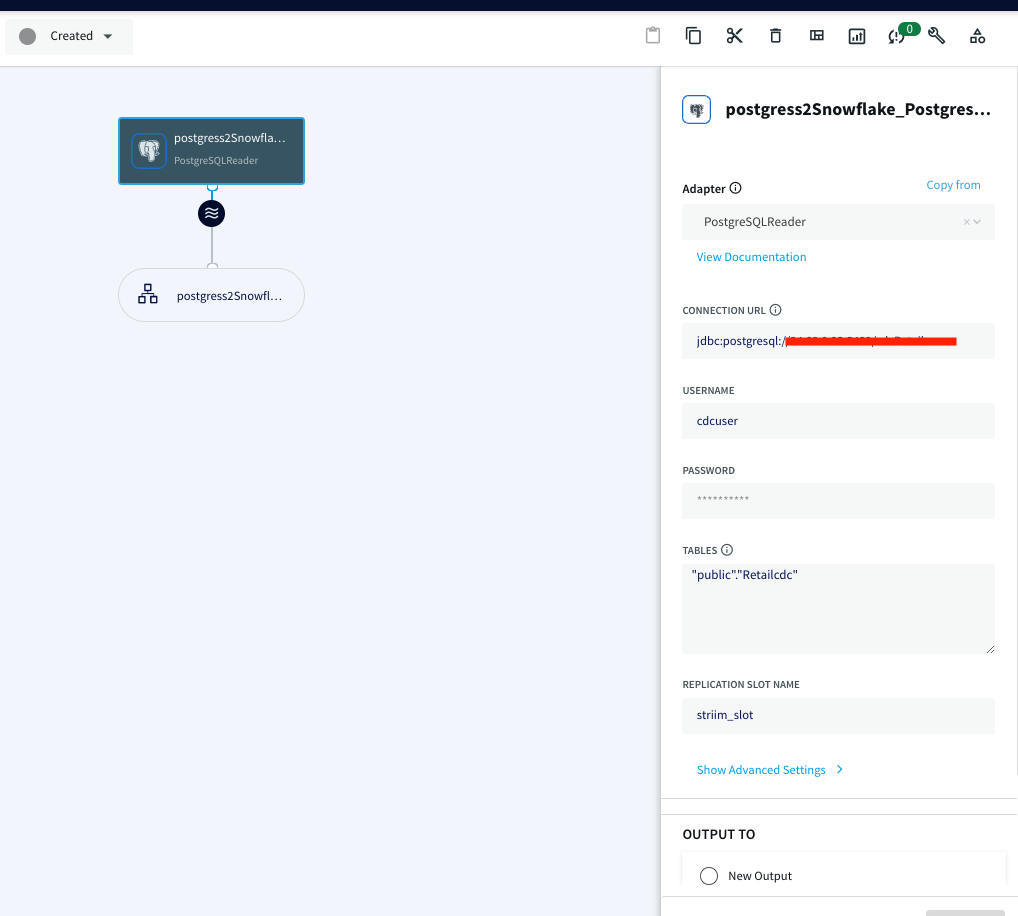
Launch the new service and use app wizard to stream data from PostgresCDC to Snowflake and Select Source and Target under create app from wizard:
Give a name to your app and establish the connection between striim server and postgres instance.
Step 1 :
Hostname: IP address of postgres instance
Port : For postgres, port is 5432
Username & Password: User with replication attribute that has access to source database
Database Name: Source Database
Step 2 :The wizard will check and validate the connection between source to striim server
Step 3 :Select the schema that will be replicated
Step 4 :The selected schema is validated
Step 5 :Select the tables to be streamed
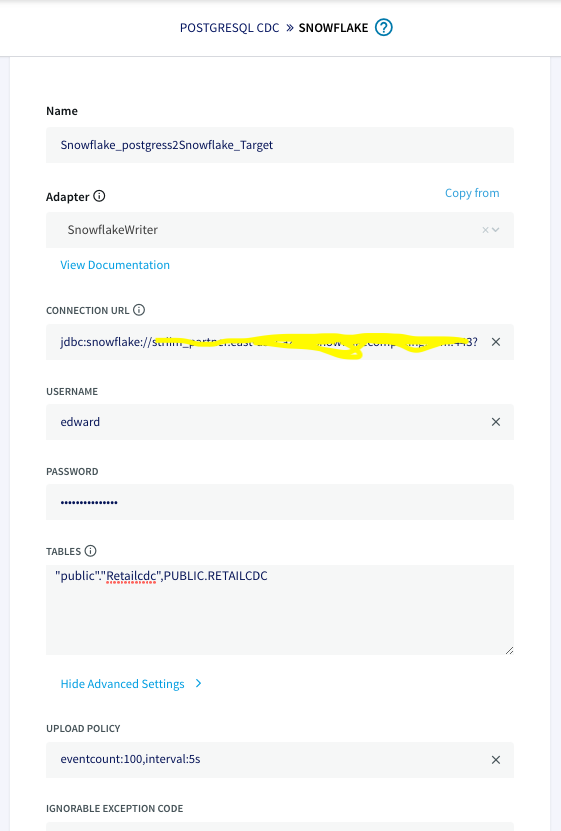
Once the connection with the source database and tables is established, we will configure the target where the data is replicated to.
The connection url has the following format: jdbc:snowflake://YOUR_HOST-2.azure.snowflakecomputing.com:***?warehouse=warehouse_name &db=RETAILCDC&schema=public
After the source and targets are configured and connection is established successfully, the app is ready to stream change data capture on the source table and replicate it onto the target snowflake table. When there is an update on the source table, the updated data is streamed through striim app to the target table on snowflake.
Step 2: Launch dbt cloud from Snowflake Partner Connect
Snowflake also provides dbt launches through Partner Connect. You can set up your dbt cloud account and project using this method. For more information on how to set up a fully fledged dbt account with your snowflake connection, managed repository and environments please follow the steps in Snowflake’s dbt configuration page.
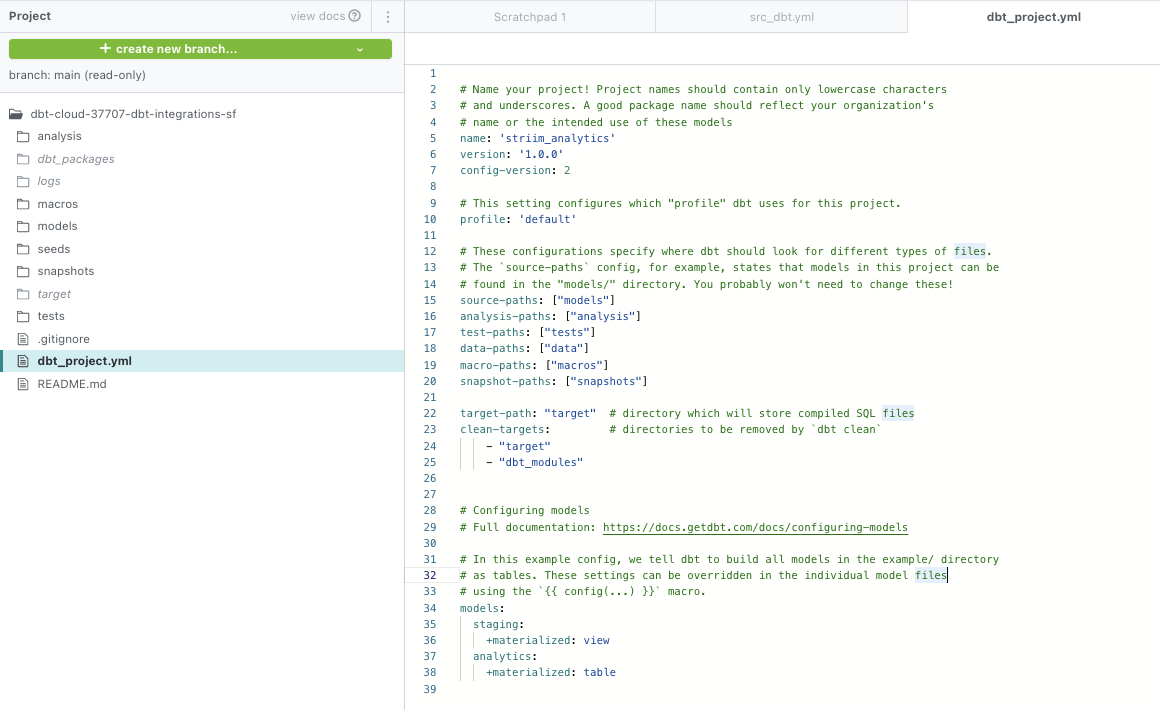
Step 3: Configure your project on cloud managed repository in dbt cloud
For information on how to set up the cloud managed repository, please refer to this documentation.
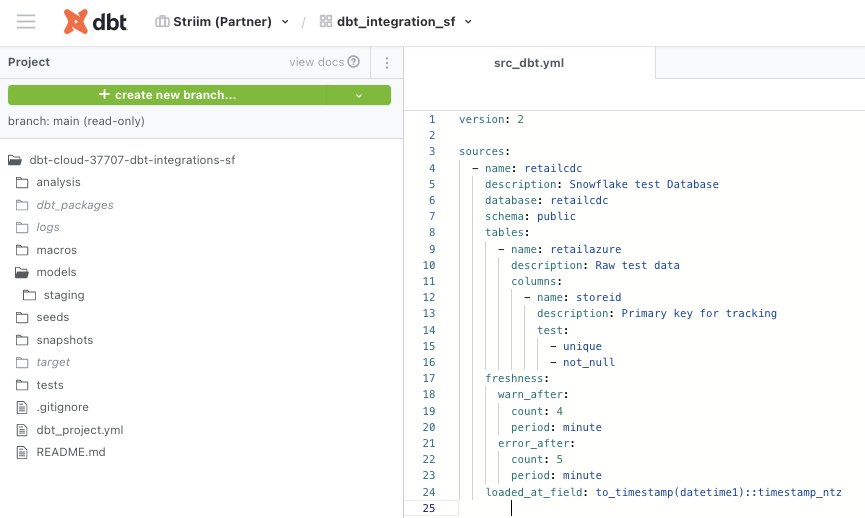
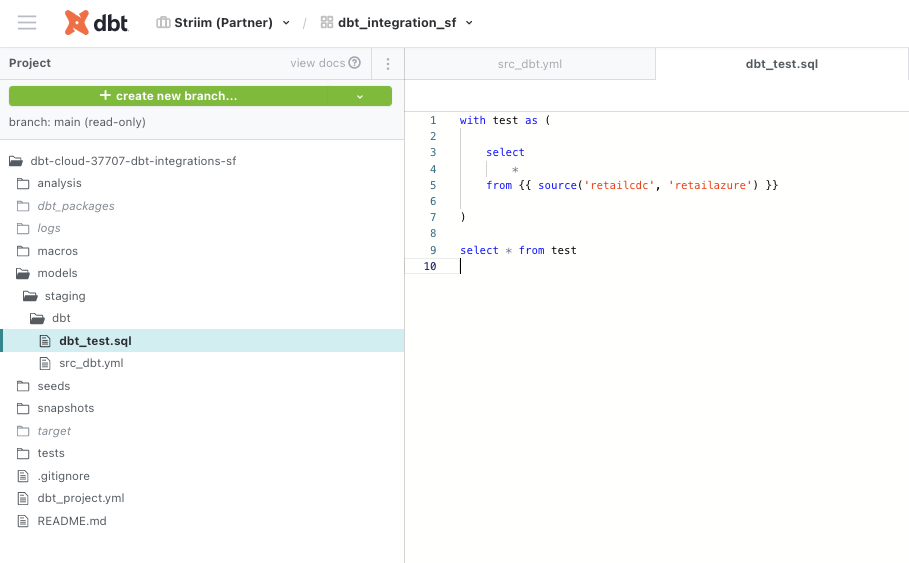
The dbt_project.yml, model yaml files and sql staging files for this project were configured as follows. Please follow this github repo to download the code.
Step 4: Add Striim’s service API in the Python Script to fetch Striim app’s metadata
We will use python script to ping Striim’s service API to gather metadata from the Striim app. The metadata is compared against benchmarks to determine the SLAs defined for the project. The python script for this project can be downloaded from here.
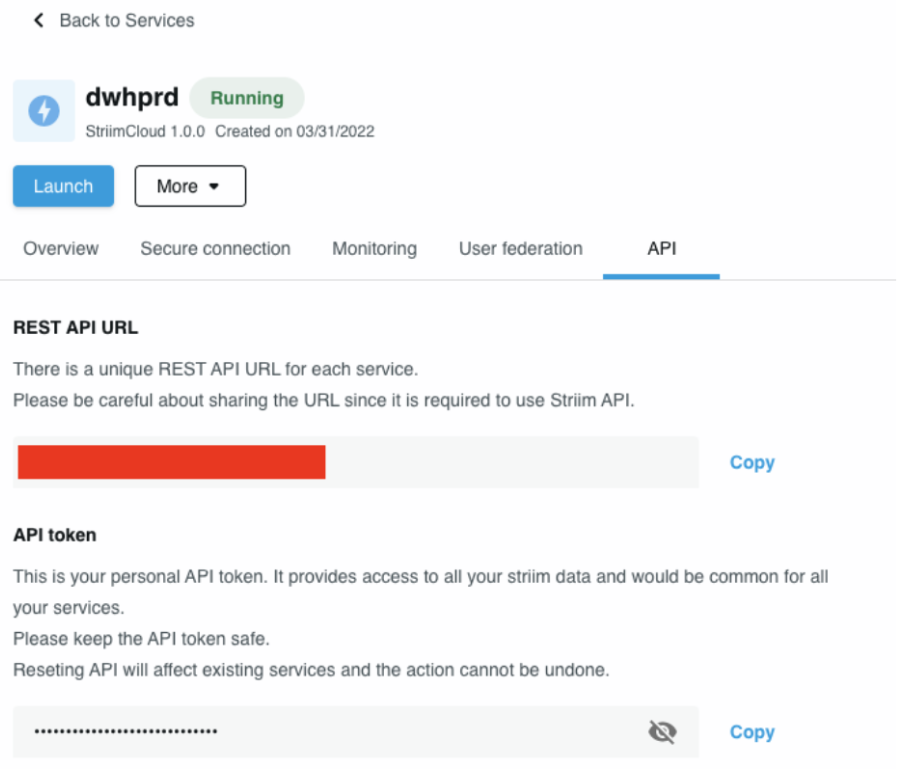
In the python script, enter the REST API URL as connection url and source name in payload.
Step 5: Run the Python Script
Once the dbt project is set up, the python script that hits the Striim Cloud Service url to get the metadata from striim server acts as a trigger to run dbt transformation and monitoring. To hit the dbt cloud API, the following commands are used. The account id and job id can be retrieved from dbt cloud url. The authorization token can be found under API access on the left navigation bar.
The following snapshots are from the dbt run that shows the inserts and source data freshness.
Follow this document to enable source freshness of the real time data flowing from PostgreSQL through Striim to BigQuery. The source freshness snapshots can be checked under view data source.
Video Walkthrough
Here is the video showing all the dbt run for the above tutorial.
https://www.youtube.com/watch?v=udzlepBexTM
Setting Up dbt and Striim
Step 1: Configure your dbt project
Configure your project on cloud managed repository in dbt cloud as shown in the recipe
Step 2: Edit the Python Script
Download the Python Script from our github repository and configure the endpoints
Step 3: Download TQL file
Download the TQL file and dataset from github repo and configure your source and target
Step 4: Run the Striim app
Deploy and run the Striim app for data replication
Step 5: Run the Python script
Run the Python Script and enable source freshness on dbt to monitor data SLAs
Wrapping Up: Start Your Free Trial
Our tutorial showed you how a striim app can run with dbt, an open source data transformation and monitoring tool. With this feature you can monitor your data without interrupting the real-time streaming through Striim. dbt can be used with popular adapter plugins like PostgreSQL, Redshift, Snowflake and BigQuery, all of which are supported by Striim. With Striim’s integration with major databases and data warehouses and powerful CDC capabilities, data streaming and analytics becomes very fast and efficient.
As always, feel free to reach out to our integration experts to schedule a demo, or try Striim for free here.
Tools you need
Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
Snowflake
Snowflake is a cloud-native relational data warehouse that offers flexible and scalable architecture for storage, compute and cloud services.
PostgreSQL
PostgreSQL is an open-source relational database management system.
dbt cloud
dbt™ is a transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation.
Integrate Striim for data streaming in your containerized application
Benefits
Manage Scalable Applications
Integrate Striim with your application inside Kubernetes Engine
Capture Data Updates in real time
Use Striim’s postgrescdc reader for real time data updates
Build Real-Time Analytical ModelsUse the power of Real Time Data Streaming to build Real-Time analytical and ML models
On this page
Overview
Kubernetes is a popular tool for creating scalable applications due to its flexibility and delivery speed. When you are developing a data-driven application that requires fast real-time data streaming, it is important to utilize a tool that does the job efficiently. This is when
Striim patches into your system. Striim is a unified data streaming and integration product that offers change capture (CDC) enabling continuous replication from popular databases such as Oracle, SQLServer, PostgreSQL and many others to target data warehouses like BigQuery and Snowflake.
In this tutorial we have shown how to run a Striim application in Kubernetes cluster that streams data from Postgres to Bigquery in real time. We have also discussed how to monitor and access Striim’s logs and poll Striim’s Rest API to regulate the data stream.
Core Striim Components
PostgreSQL CDC: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
BigQueryWriter: Striim’s BigQueryWriter writes the data from various supported sources into Google’s BigQuery data warehouse to support real time data warehousing and reporting.
Step 1: Deploy Striim on Google Kubernetes Engine
Follow the steps below to configure your Kubernetes cluster and start the required pods:
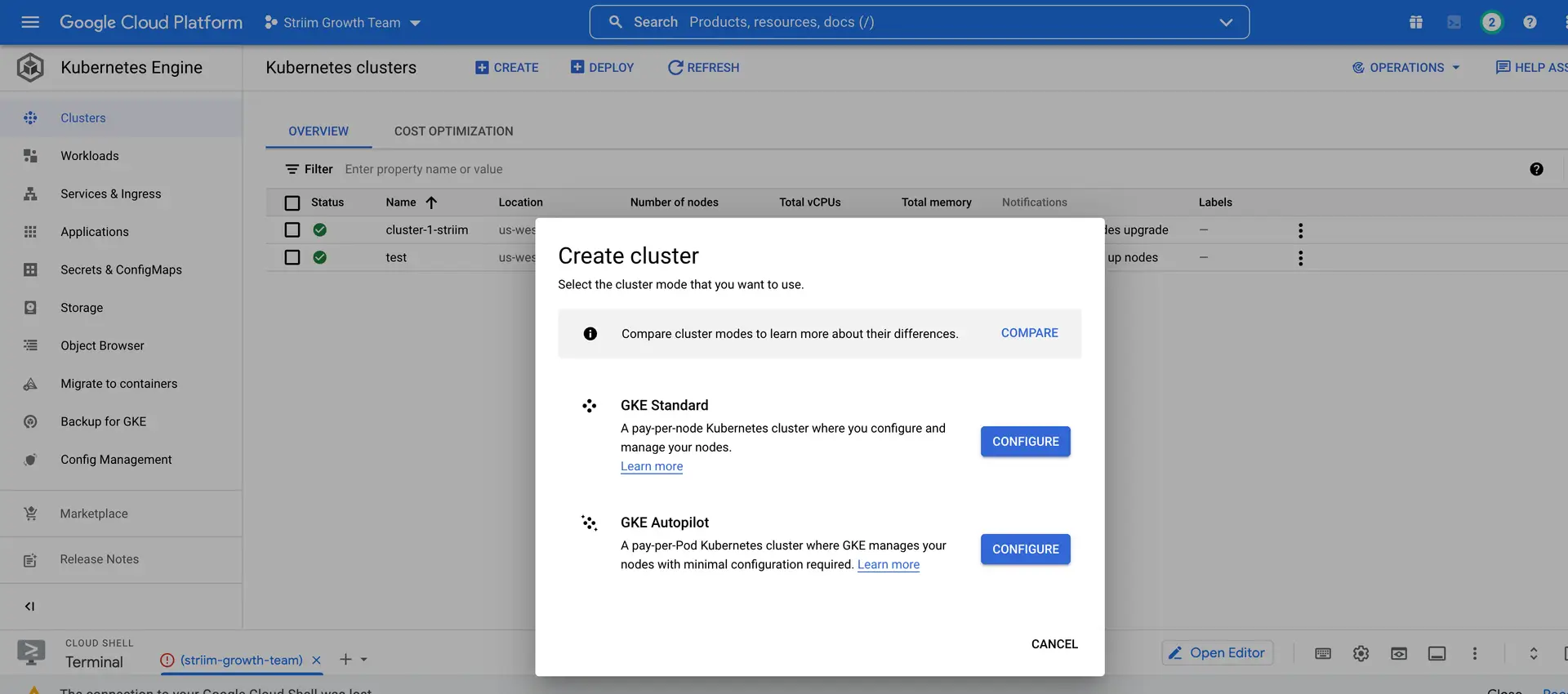
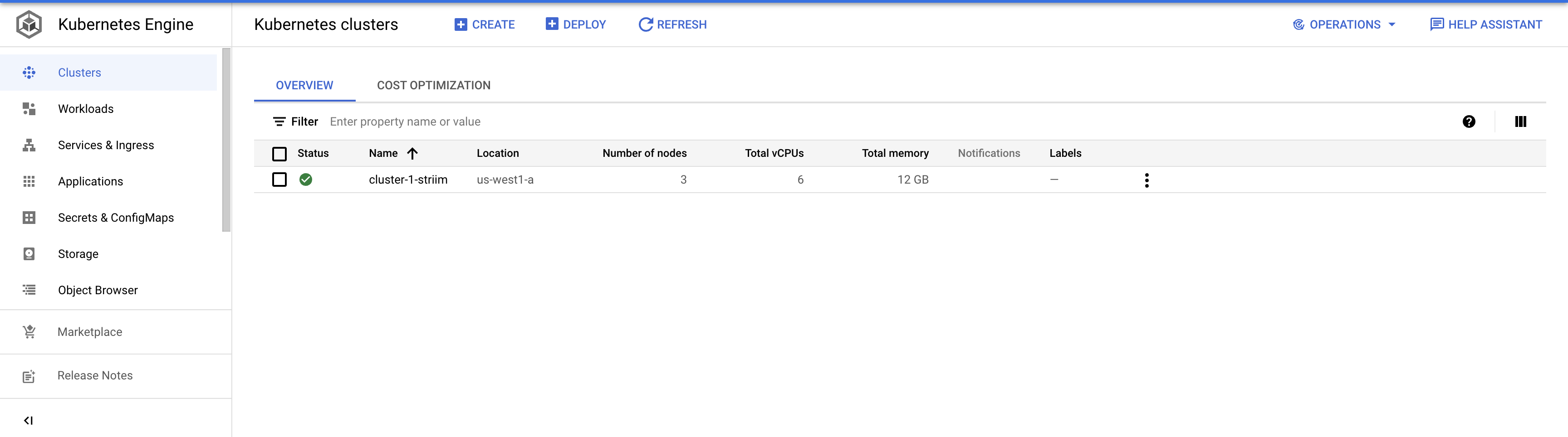
Create a cluster on GKE that will run the Striim-node and striim-metadata pods.
On your GKE, click clusters and configure a cluster with the desired number of nodes. Once the cluster is created, run the following command to connect the cluster.
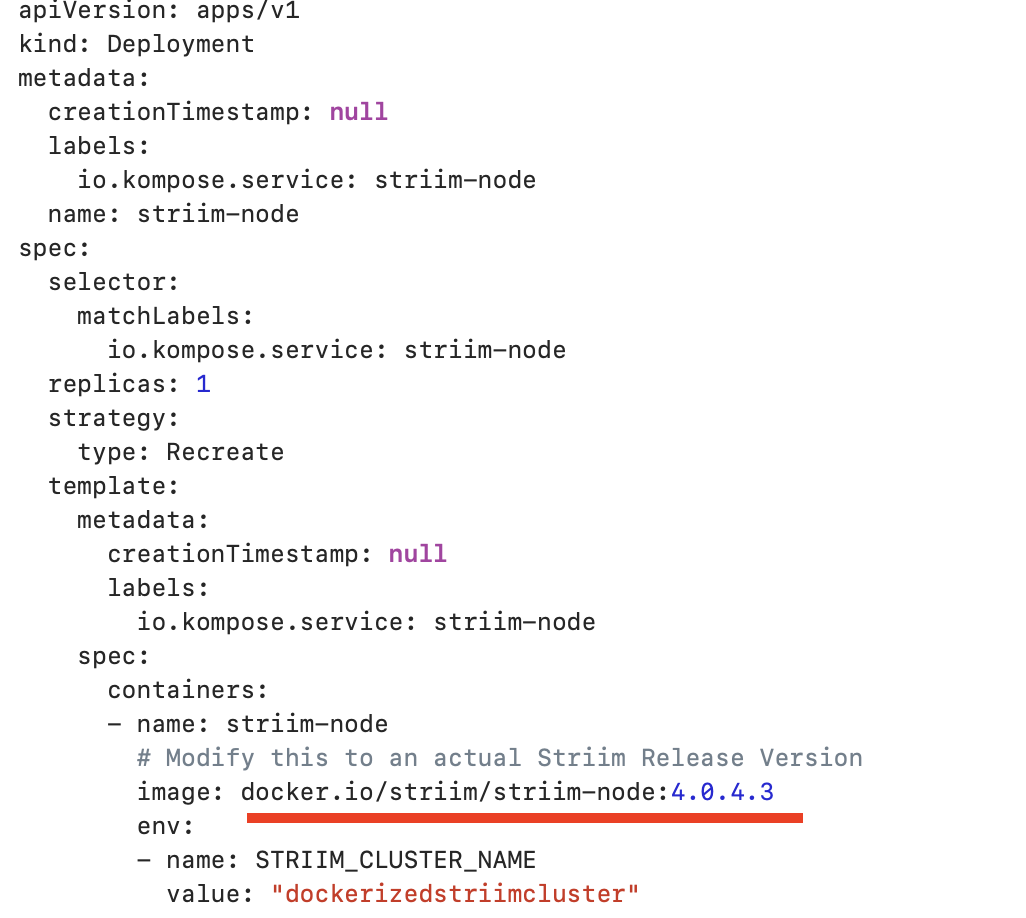
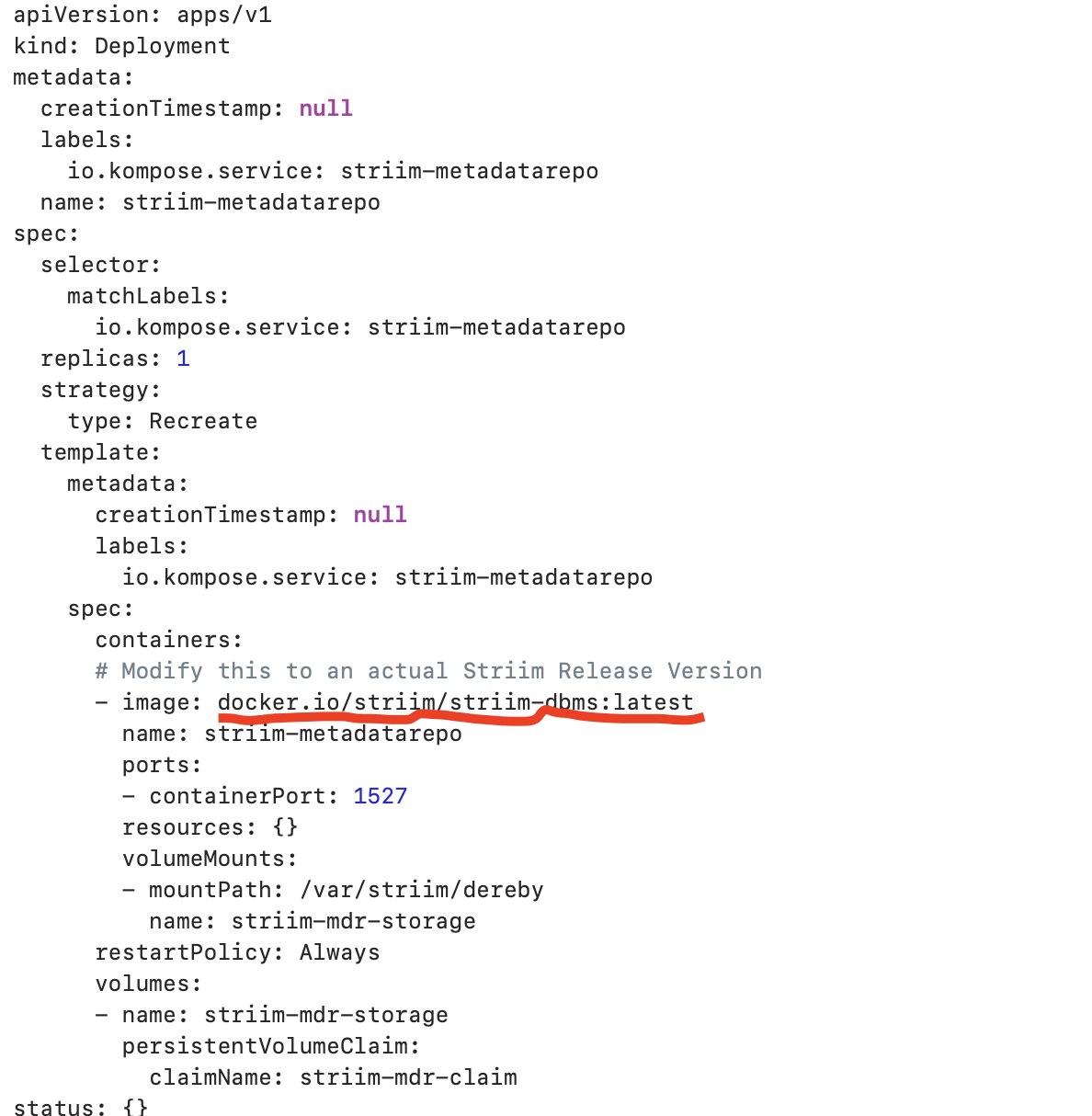
Configure the yaml file to run docker container inside K8 cluster.You can find a sample yaml file here that deploys striim-node and metadata containers. Modify the tags of striim-dbms and striim-node image with
the latest version as shown below. Modify COMPANY_NAME, FIRST_NAME, LAST_NAME and COMPANY_EMAIL_ADDRESS for the 7-days free trial use or if you have a license key, you can modify the license key section from yaml file.
Upload the yaml file to your google cloud.
Run the following command to deploy with the yaml file. The pods will take some time to start and run successfully:
kubectl create -f {YAML_FILE_NAME>
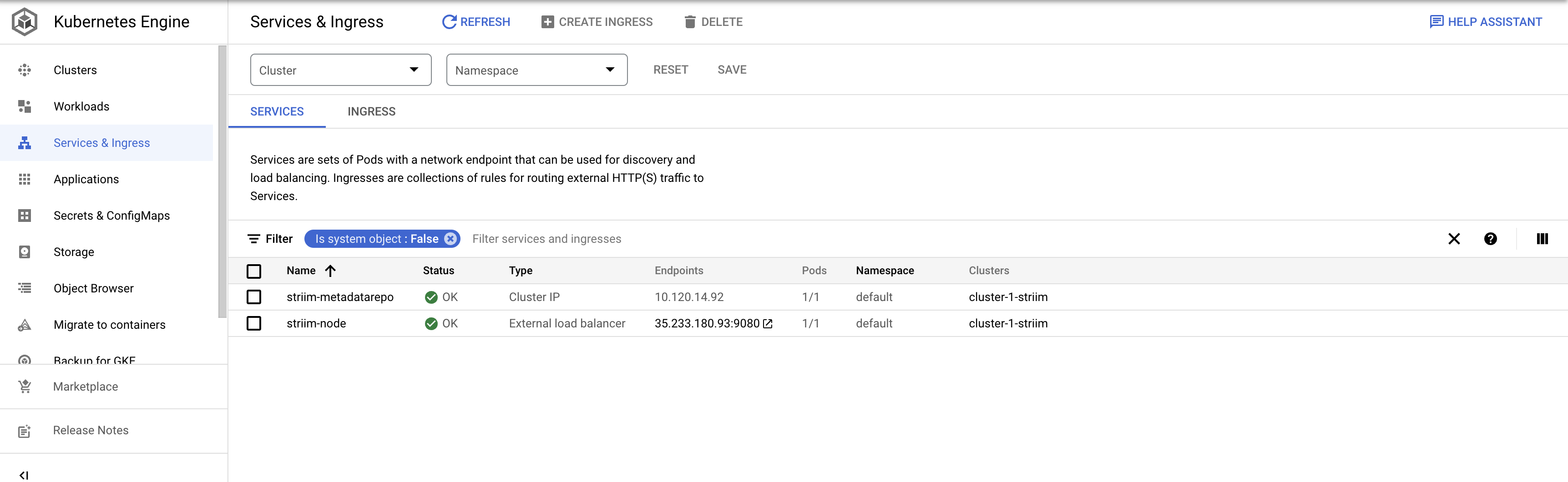
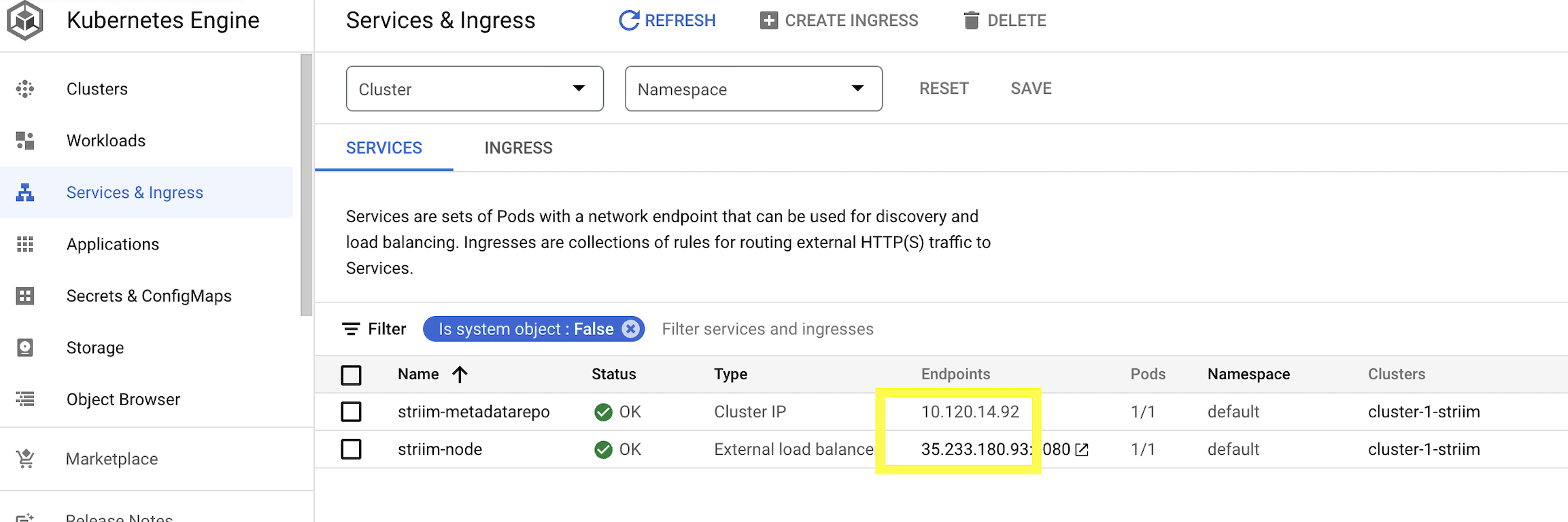
Go to Services & Ingress to check if the pods are created successfully. The OK status indicate the pods are up and running
Step 2: Configure the KeyStore Password
Enter the pod running Striim-node by running the following command.
Kubectl logs {striim-node-***pod name}
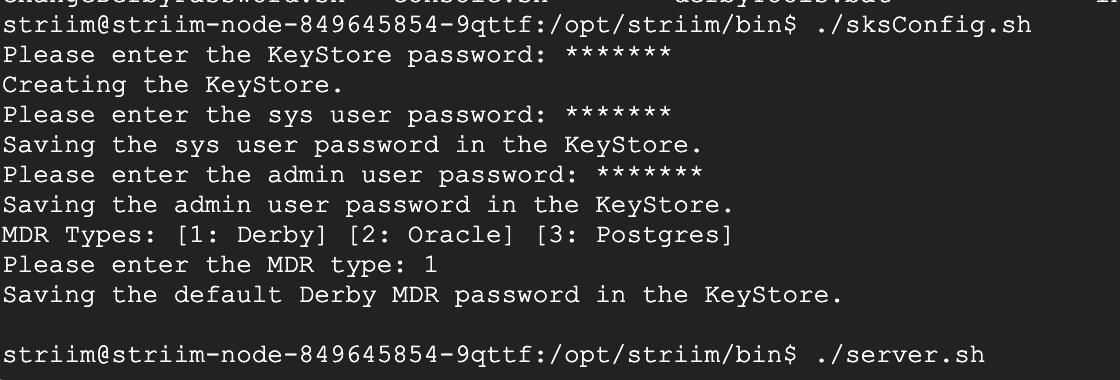
Enter the directory /opt/striim/bin/ and run the sksConfig.sh file to set the KeyStore passwords.
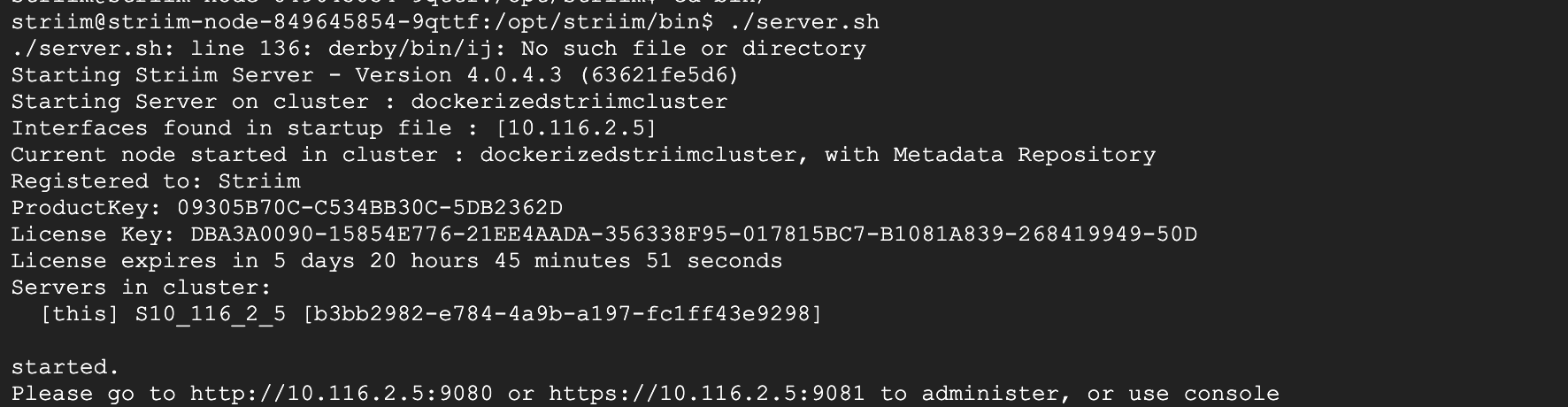
Run the server.sh file to launch Striim server through the K8 cluster. When prompted for cluster name, enter dockerizedstriimcluster or the name of cluster from yaml file.
Step 3: Access Striim Server UI
To create and run data streaming applications from UI, click on the Endpoint of strim-node as shown below. This will redirect you to Striim User Interface.
Step 4: Create and Run the postgres CDC to BigQuery streaming App
Once you are in the UI, you can follow the same steps shown in this recipe to create a postgres to Bigquery streaming app from wizard.
Monitoring Event logs and Polling Striim’s Rest API
You can use the Monitor page in the web UI to retrieve summary information for the cluster and each of its applications, servers and agent. To learn more about the monitoring guide, please refer to this documentation.
You can also poll Striim’s rest API to access the data stream for monitoring the SLAs of data flow. For example, integrating the application with dbt to ensure if source data freshness is meeting the SLAs defined for the project. An authentication token must be included in
all REST API calls using the
token parameter. You can get a token using any REST client. The CLI command to request a token is:.
curl -X POST -d'username=admin&password=******' http://{server IP}:9080/security/authenticate</code> gcloud container clusters get-credentials</code> curl -X POST
-d'username=admin&password=******' http://34.127.3.58:9080/security/authenticate
{"token":"01ecc591-****-1fe1-9448-4640d**0e52*"}sweta_prabha@cloudshell:~ (striim-growth-team)$
</code>
To learn more about Striim’s Rest API, refer to the API guide, r from Striim’s documentation.
Deploying Striim on Google Kubernetes Engine
Step 1: Deploy Striim on Google Kubernetes using YAML file
You can find the YAML file here. Make necessary changes to deploy Striim on Kubernetes
Step 2: Configure the KeyStore Password
Please follow the recipe to configure keystore password
Step 3: Create the Striim app on Striim server deployed using Kubernetes
Use the app wizard from UI to create a Striim app as shown in the recipe
Step 4: Run the Striim app
Deploy and run real-time data streaming app
Wrapping Up: Start Your Free Trial
Our tutorial showed you how a striim app can be run and deployed in Google Kubernetes cluster, a widely used container orchestration tool. Now you can integrate Striim with scalable applications managed within K8 clusters. With Striim’s integration with major
databases
and data warehouses and powerful CDC capabilities, data streaming and analytics becomes very fast and efficient.
As always, feel free to reach out to our integration experts to schedule a demo, or try Striim for free here.
Tools you need
Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.
Kubernetes
Kubernetes is an open-source container orchestration tool for automatic deployment and scaling of containerized applications.
Google BigQuery
BigQuery is a serverless, highly scalable multicloud data warehouse.
Replicate data from PostgreSQL to Snowflake in real time with Change Data Capture
Stream data from PostgreSQL to Snowflake
Benefits
Operational Analytics
Visualize real time data with Refresh View on Snowflake
Capture Data Updates in real time
Use Striim’s PostgreSQL CDC reader for real-time data replication
Build Real-Time Analytical ModelsUse dbt to build Real-Time analytical and ML models
On this page
Overview
Striim is a unified data streaming and integration product that offers change capture (CDC) enabling continuous replication from popular databases such as Oracle, SQLServer, PostgreSQL and many others to target data warehouses like BigQuery and Snowflake.
Change Data Capture is a critical process desired by many companies to stay up to date with most recent data. This enables efficient real-time decision making which is important for stakeholders. Striim platform facilitates simple to use, real-time data
integration, replication, and analytics with cloud scale and security.
In this tutorial, we will walk you through a use case where data is replicated from PostgreSQL to Snowflake in real time. Change events are extracted from a PostgreSQL database as they are created and then streamed to Snowflake hosted on Microsoft Azure. Follow this recipe to learn how to secure your data pipeline by creating an SSH tunnel on Striim cloud through a jump host.
Core Striim Components
PostgreSQL CDC: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
Snowflake Writer: Striim’s Snowflake Writer writes to one or more existing tables in Snowflake. Events are staged to local storage, Azure Storage, or AWS S3, then written to Snowflake as per the Upload Policy setting.
Step 1: Launch Striim Server and connect the Postgres instance with replication attribute
Please refer to postgres CDC to BigQuery recipe to learn how to create a replication user and replication slot for the postgres database and tables. Striim collaborates with Snowflake to provide Striim’s cloud service through Snowflake’s partner connect.
Follow the steps below to connect Striim server to postgres instance containing the source database:
Launch Striim in Snowflake Partner Connect by clicking on “Partner Connect” in the top right corner of the navigation bar.
In the next window, you can launch Striim and sign up for a free trial.
Create your first Striim Service to move data to Snowflake.
Launch the new service and use app wizard to stream data from PostgresCDC to Snowflake and Select Source and Target under create app from wizard:
Give a name to your app and establish the connection between striim server and postgres instance .
Step 1 :
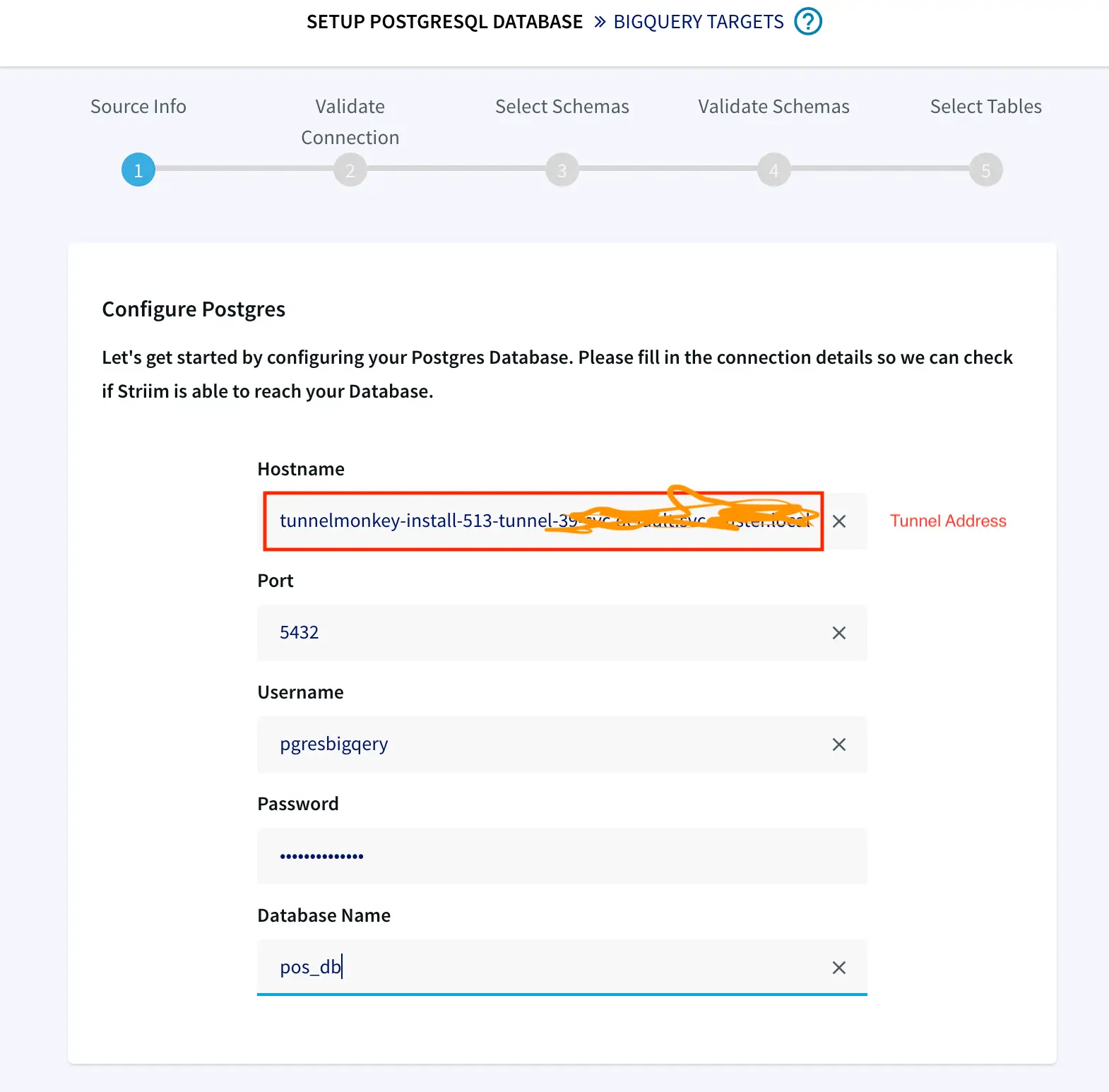
Hostname: IP address of postgres instance
Port : For postgres, port is 5432
Username & Password: User with replication attribute that has access to source database
Database Name: Source Database
Step 2 :The wizard will check and validate the connection between source to striim server
Step 3 :Select the schema that will be replicated
Step 4 :The selected schema is validated
Step 5 :Select the tables to be streamed
Step 2: Configure the target (Snowflake on Azure Cloud)
Once the connection with the source database and tables is established, we will configure the target where the data is replicated to.
The connection url has the following format: jdbc:snowflake://YOUR_HOST-2.azure.snowflakecomputing.com:***?warehouse=warehouse_name &db=RETAILCDC&schema=public
Step 3: Deploy and Run the Striim app for Fast Data Streaming
After the source and targets are configured and connection is established successfully, the app is ready to stream change data capture on the source table and replicate it onto the target snowflake table. When there is an
update on the source table, the updated data is streamed through striim app to the target table on snowflake.
Step 4: Refresh View on Snowflake
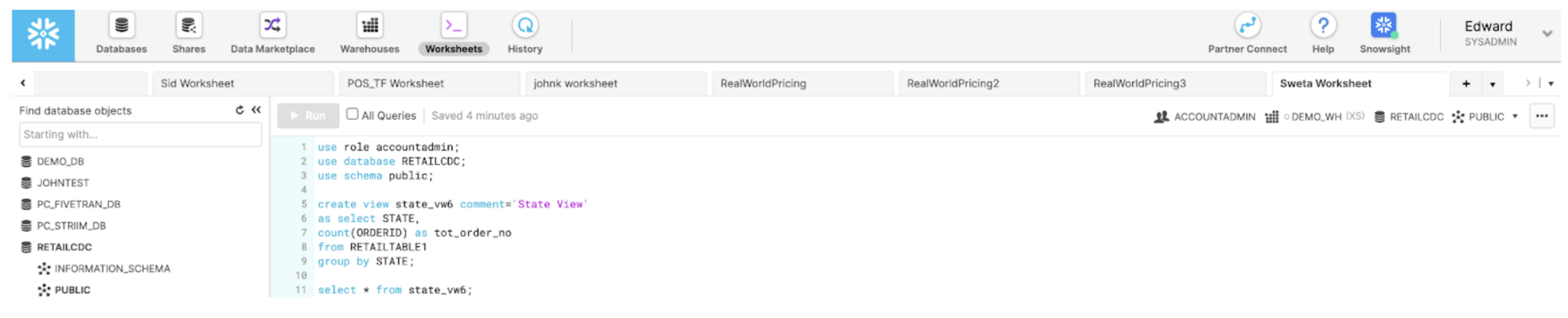
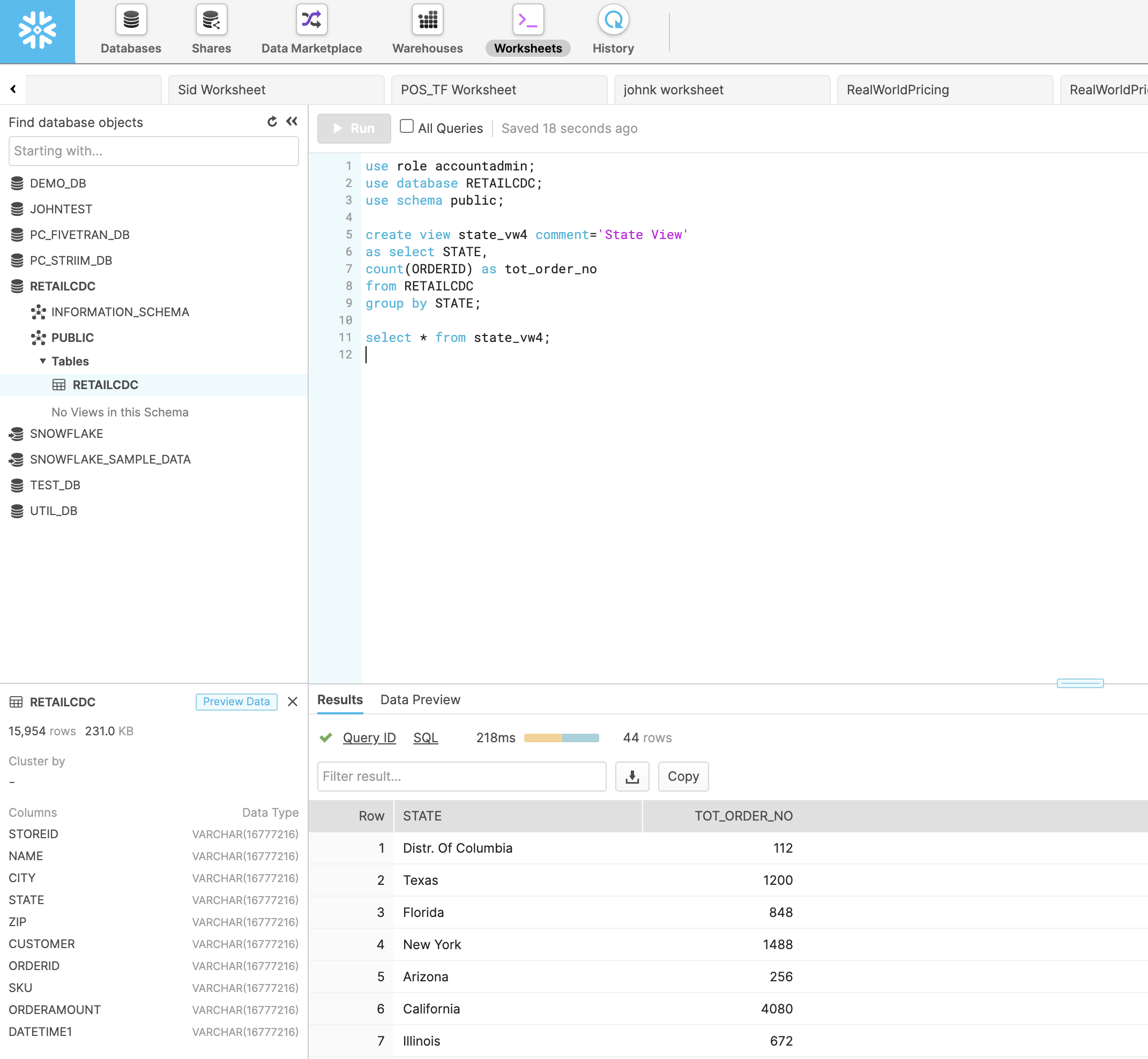
With Striim as the data streaming platform, real-time analytics can be done on target databases. In snowflake, you can write a query for refresh view of the incoming data in real-time. In this tutorial, a view is created that aggregates the total number of orders in each state at any given time.
Video Walkthrough
Here is the video showing all the steps in streaming Change Data from postgres to Snowflake and refresh view of updated data on snowflake.
Setting Up Postgres to Snowflake Streaming Application
Step 1: Download the data and Sample TQL file from our github repo
You can download the TQL files for streaming app our github repository. Deploy the Striim app on your Striim server.
Step 2: Configure your Postgres source and Snowflake target and add it to the source and target components of the app
Set up your source and target and add the details in striim app
Step 3: Run the app for fast Data Streaming
Deploy your streaming app and run it for real-time data replication
Step 4: Set up refresh view in Snowflake
Follow the recipe to write a query for refresh view of real-time data
Wrapping Up: Start Your Free Trial
Our tutorial showed you how easy it is to stream data from PostgreSQL CDC to Snowflake, a leading cloud data warehouse and do real-time analytics with a refresh view. By constantly moving your data into BigQuery, you could now start building analytics or machine learning models on top, all with minimal impact to your current systems. You could also start ingesting and normalizing more datasets with Striim to fully take advantage of your data.
As always, feel free to reach out to our integration experts to schedule a demo, or try Striim for free here.
Tools you need
Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.
Snowflake
Snowflake is a cloud-native relational data warehouse that offers flexible and scalable architecture for storage, compute and cloud services.
Stream Data from PostgreSQL to Google BigQuery with Striim Cloud – Part 2
Use Striim Cloud to stream CDC data securely from PostgreSQL database into Google BigQuery
Benefits
Operational Analytics
Visualize real time data with Striim’s powerful Analytic Dashboard
Capture Data Updates in real time
Use Striim’s postgrescdc reader for real time data updates
Build Real-Time Analytical ModelsUse dbt to build Real-Time analytical and ML models
On this page
Overview
In part 1 of PostgreSQL to Bigquery streaming, we have shown how data can be securely replicated between Postgres database and Bigquery. In this
recipe we will walk you through a Striim application capturing change data from postgres database and replicating to bigquery for real time visualization.
In addition to CDC connectors, Striim has hundreds of automated adapters for file-based data (logs, xml, csv), IoT data (OPCUA, MQTT), and applications such as Salesforce and SAP. Our SQL-based stream processing engine makes it easy to
enrich and normalize data before it’s written to Snowflake.
Traditionally Data warehouses that required data to be transferred use batch processing but with Striim’s streaming platform data can be replicated in real-time efficiently with added cost.
Data loses its value over time and businesses need to be updated with most recent data in order to make the right decisions that are vital to overall growth.
In this tutorial, we’ll walk you through how to create a replica slot to stream change data from postgres tables to bigquery and use the in-flght data to generate analytical dashboards.
Core Striim Components
PostgreSQL CDC: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
Continuous Query : Striim Continuous queries are are continually running SQL queries that act on real-time data and may be used to filter, aggregate, join, enrich, and transform events.
Window: A window bounds real-time data by time, event count or both. A window is required for an application to aggregate or perform calculations on data, populate the dashboard, or send alerts when conditions deviate from normal parameters.
BigQueryWriter: Striim’s BigQueryWriter writes the data from various supported sources into Google’s BigQuery data warehouse to support real time data warehousing and reporting.
Step 1: Create a Replication Slot
For this recipe, we will host our app in Striim Cloud but there is always a free trial to visualize the power of Striim’s Change Data Capture.
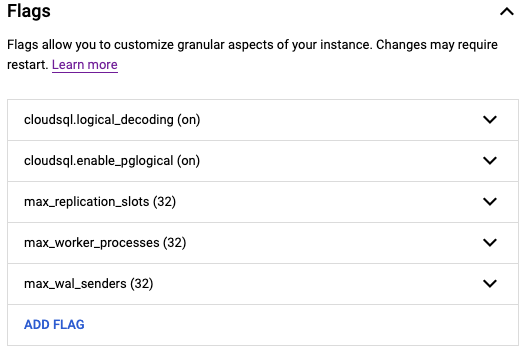
For CDC application on a postgres database, make sure the following flags are enabled for the postgres instance:
Create a user with replication attribute by running the following command on google cloud console:
CREATE USER replication_user WITH REPLICATION IN ROLE cloudsqlsuperuser LOGIN PASSWORD ‘yourpassword’;
Follow the steps below to set up your replication slot for change data capture:
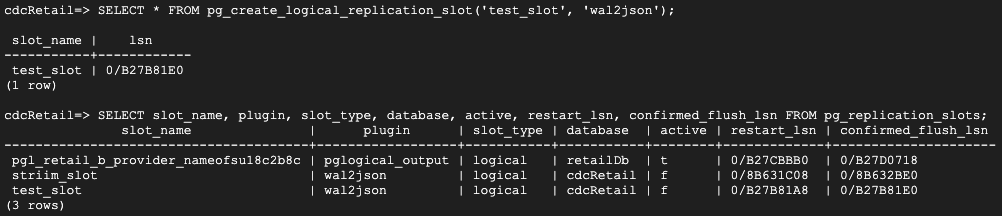
Create a logical slot with wal2json plugin.
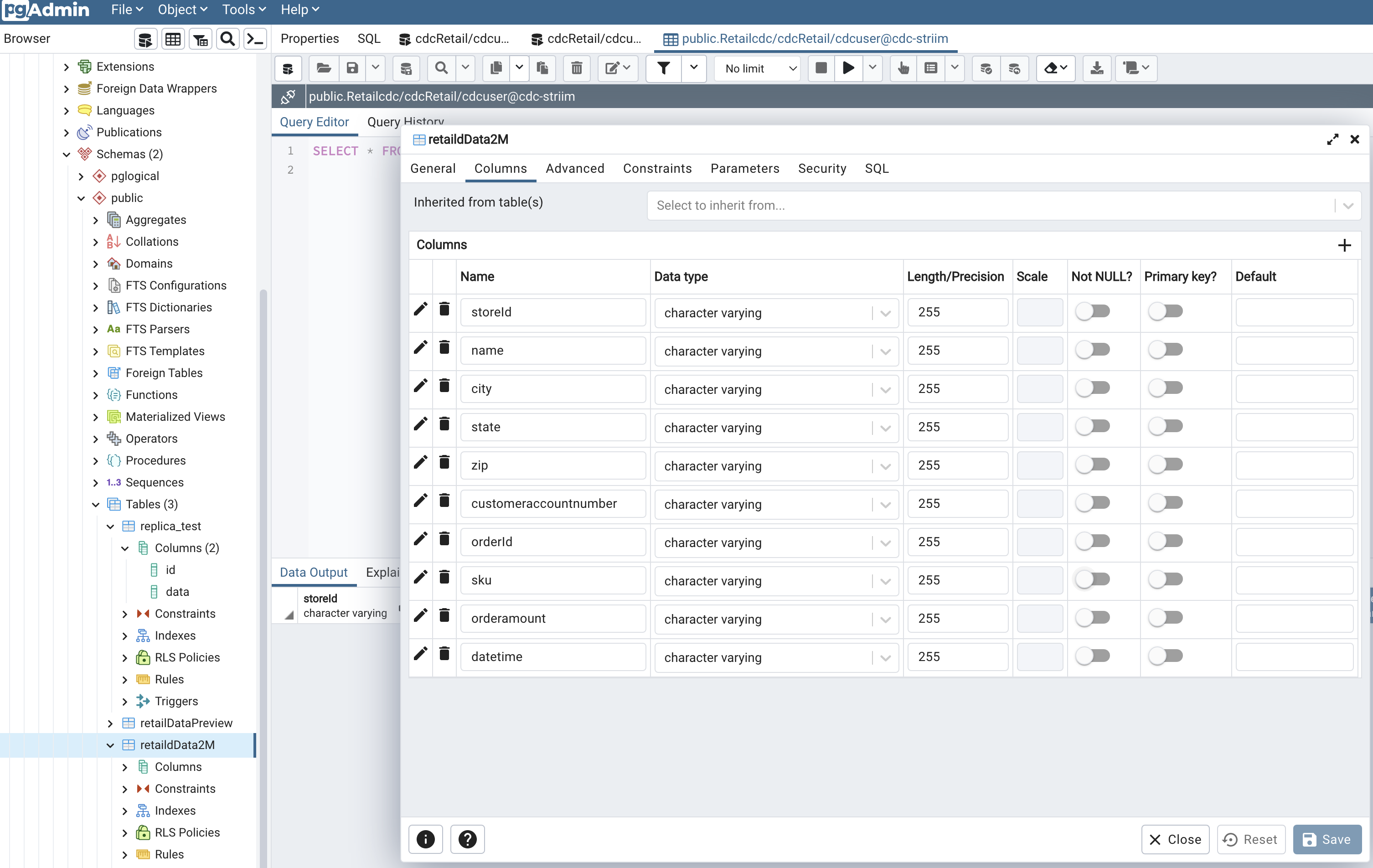
Create table that needs to be replicated for capturing changes in data. I have used PgAdmin, which is a UI for postgres database management system to create my table and insert data into it.
Step 2: Configure CDC app on Striim Server
Follow the steps described in part 1 for creating an app from scratch. You can find the TQL file for this app in our git repository.
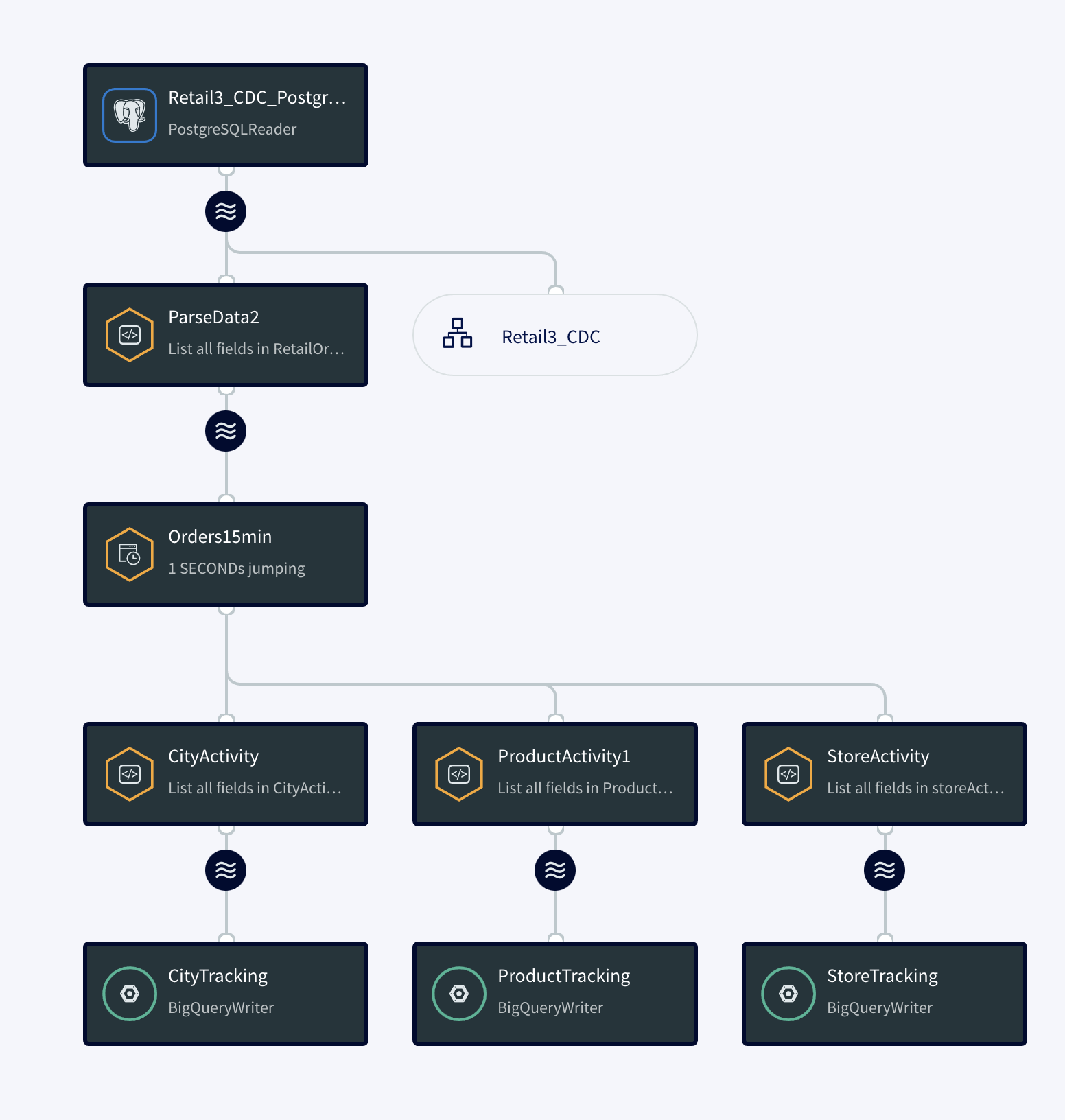
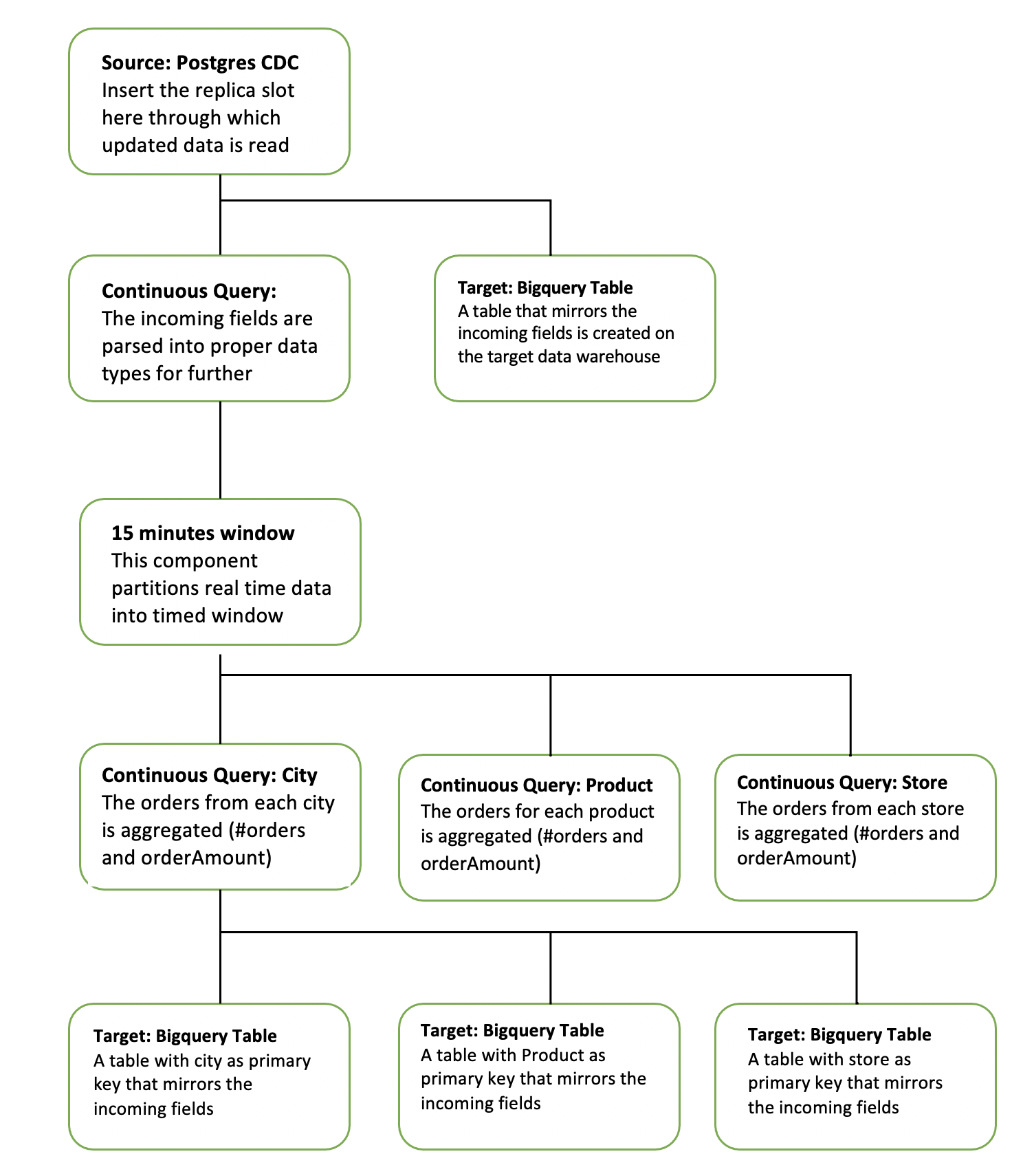
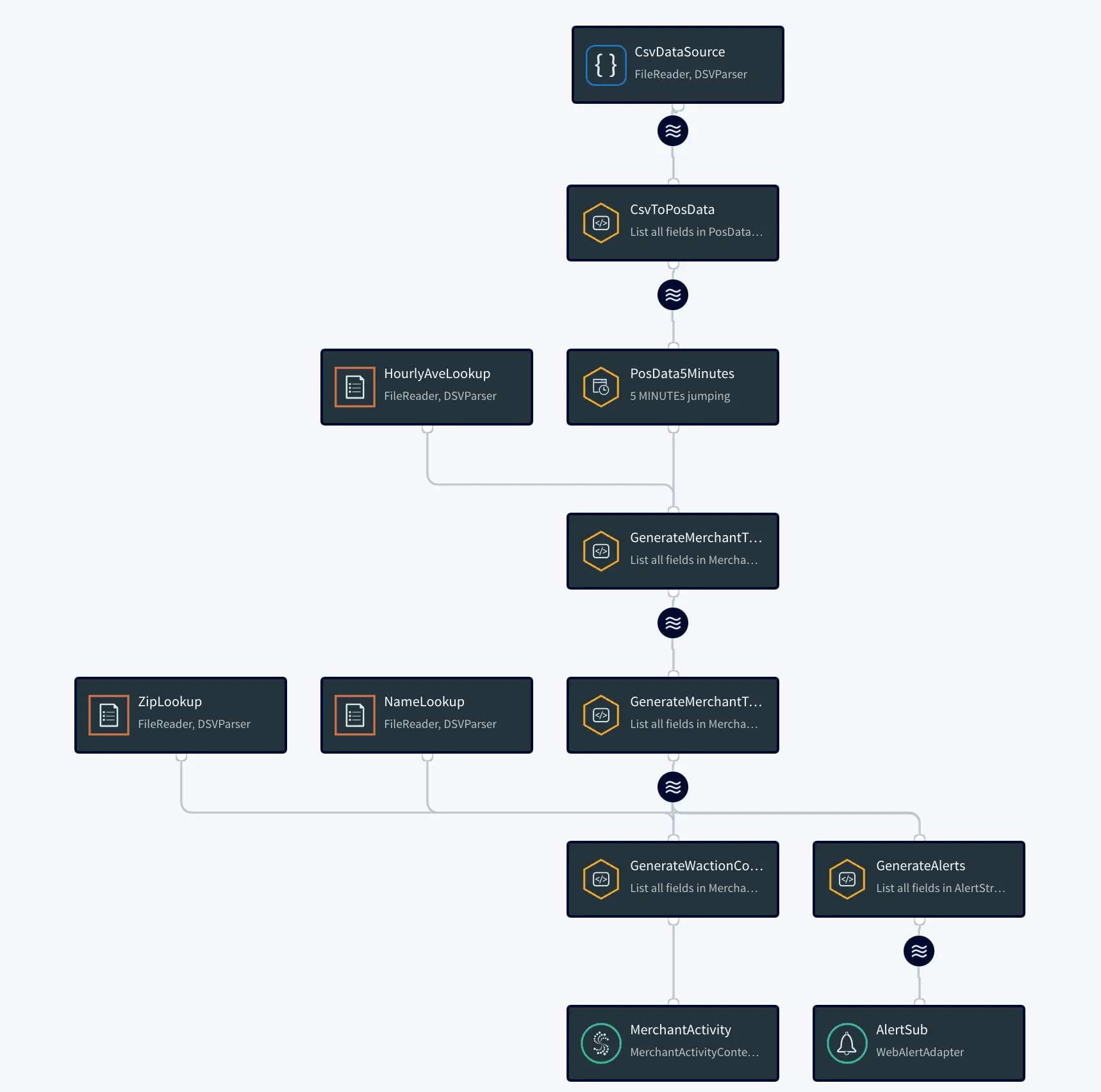
The diagram below simplifies each component of the app.
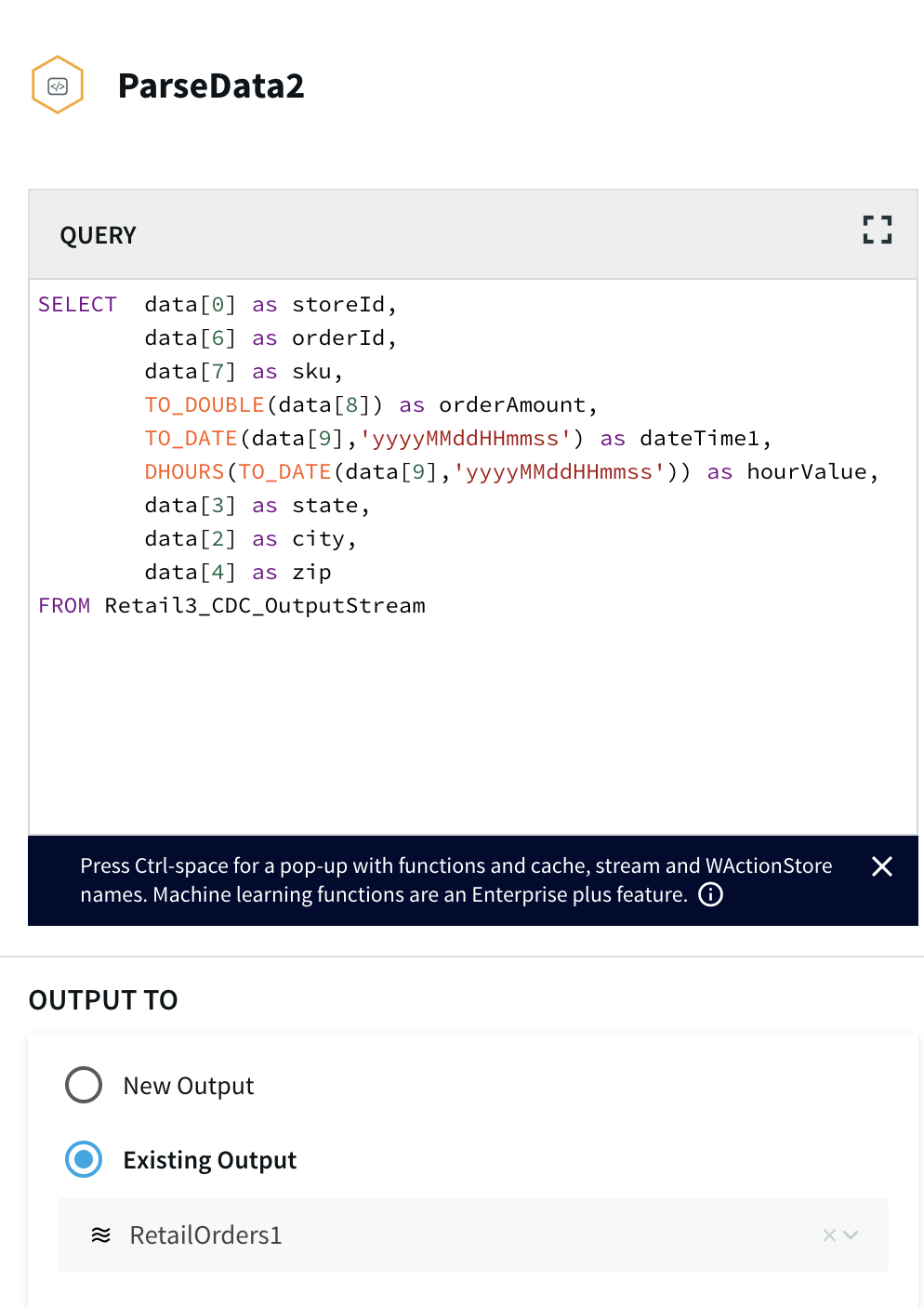
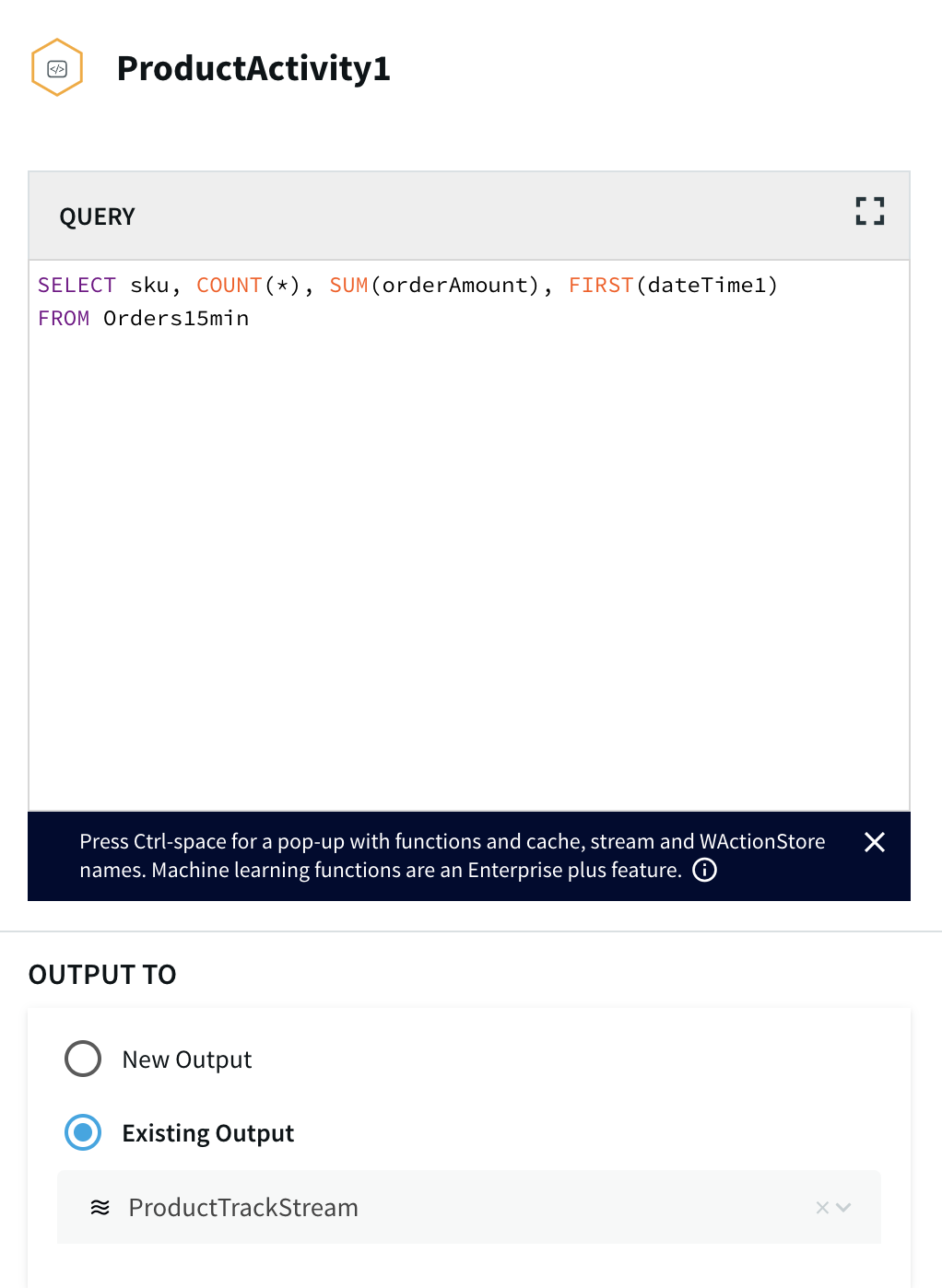
The continuous query is a sql-based query that is used to query the database.The following queries are for ParseData2 where data is transformed into proper data type for further processing and ProductActivity1 where product data is aggregated to derive useful insights about each product.
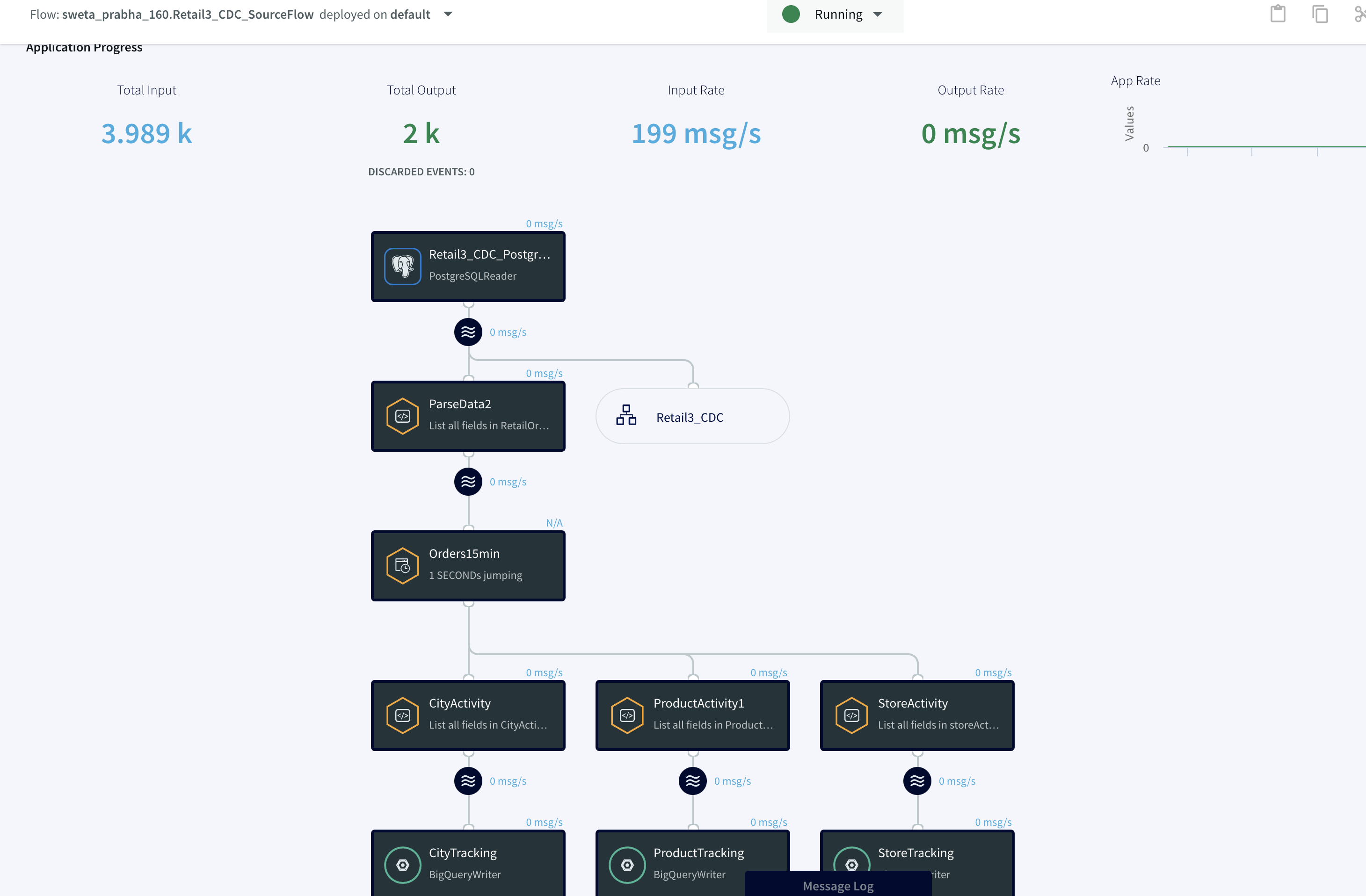
Step 3: Deploy and Run the Striim app for Fast Data Streaming
In this step you will deploy and run the final app to visualize the power of Change Data Capture in Striim’s next generation technology.
Setting Up the Postgres to BigQuery Streaming Application
Step 1: Follow this recipe to create a Replication Slot and user for Change Data Capture
The replication user reads change data from your source database and replicates it to the target in real-time.
Step 2: Download the dataset and TQL file from our github repo and set up your Postgres Source and BigQuery Target.
You can find the csv dataset in our github repo. Set up your BigQuery dataset and table that will act as a target for the streaming application
Step 3: Configure source and target components in the app
Configure the source and target components in the striim app. Please follow the detailed steps from our recipe.
Step 4: Run the streaming app
Deploy and run real-time data streaming app
Wrapping Up: Start Your Free Trial
Our tutorial showed you how easy it is to capture change data from PostgreSQL to Google BigQuery, a leading cloud data warehouse. By constantly moving your data into BigQuery, you could now start building analytics or machine learning models on top, all
with minimal impact to your current systems. You could also start ingesting and normalizing more datasets with Striim to fully take advantage of your data when combined with the power of BigQuery..
As always, feel free to reach out to our integration experts to schedule a demo, or try Striim for free here.
Tools you need
Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.
Google BigQuery
BigQuery is a serverless, highly scalable multicloud data warehouse.
Oracle Change Data Capture – An Event-Driven Architecture for Cloud Adoption
How to replace batch ETL by event-driven distributed stream processing
Benefits
Operational Analytics Use non-intrusive CDC to Kafka to create persistent streams that can be accessed by multiple consumers and automatically reflect upstream schema changes
Empower Your TeamsGive teams across your organization a real-time view of your Oracle database transactions.Get Analytics-Ready DataGet your data ready for analytics before it lands in the cloud. Process and analyze in-flight data with scalable streaming SQL.
On this page
Overview
All businesses rely on data. Historically, this data resided in monolithic databases, and batch ETL processes were used to move that data to warehouses and other data stores for reporting and analytics purposes. As businesses modernize, looking to the cloud for analytics, and striving for real-time data insights, they often find that these databases are difficult to completely replace, yet the data and transactions happening within them are essential for analytics. With over 80% of businesses noting that the volume & velocity of their data is rapidly increasing, scalable cloud adoption and change data capture from databases like Oracle, SQLServer, MySQL and others is more critical than ever before. Oracle change data capture is specifically one area where companies are seeing an influx of modern data integration use cases.
To resolve this, more and more companies are moving to event-driven architectures, because of the dynamic distributed scalability which makes sharing large volumes of data across systems possible.
In this post we will look at an example which replaces batch ETL by event-driven distributed stream processing: Oracle change data capture events are extracted as they are created; enriched with in-memory, SQL-based denormalization; then delivered to the Mongodb to provide scalable, real-time, low-cost analytics, without affecting the source database. We will also look at using the enriched events, optionally backed by Kafka, to incrementally add other event-driven applications or services.
Continuous Data Collection, Processing, Delivery, and Analytics with the Striim Platform
Event-Driven Architecture Patterns
Most business data is produced as a sequence of events, or an event stream: for example, web or mobile app interactions, devices, sensors, bank transactions, all continuously generate events. Even the current state of a database is the outcome of a sequence of events.
Treating state as the result of a sequence of events forms the core of several event-driven patterns.
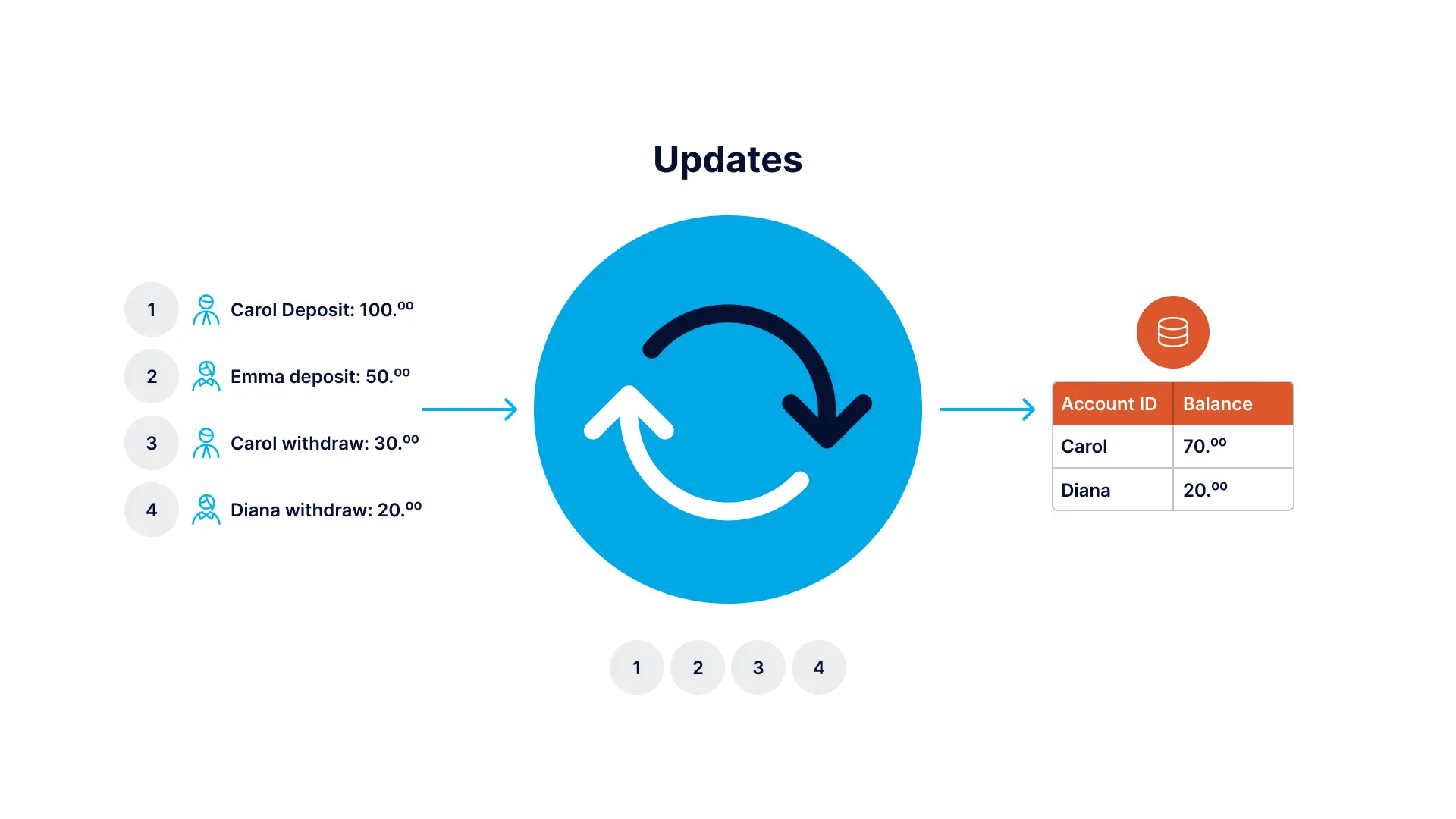
Event Sourcing is an architectural pattern in which the state of the application is determined by a sequence of events. As an example, imagine that each “event” is an incremental update to an entry in a database. In this case, the state of a particular entry is simply the accumulation of events pertaining to that entry. In the example below the stream contains the queue of all deposit and withdrawal events, and the database table persists the current account balances.
Imagine Each Event as a Change to an Entry in a Database
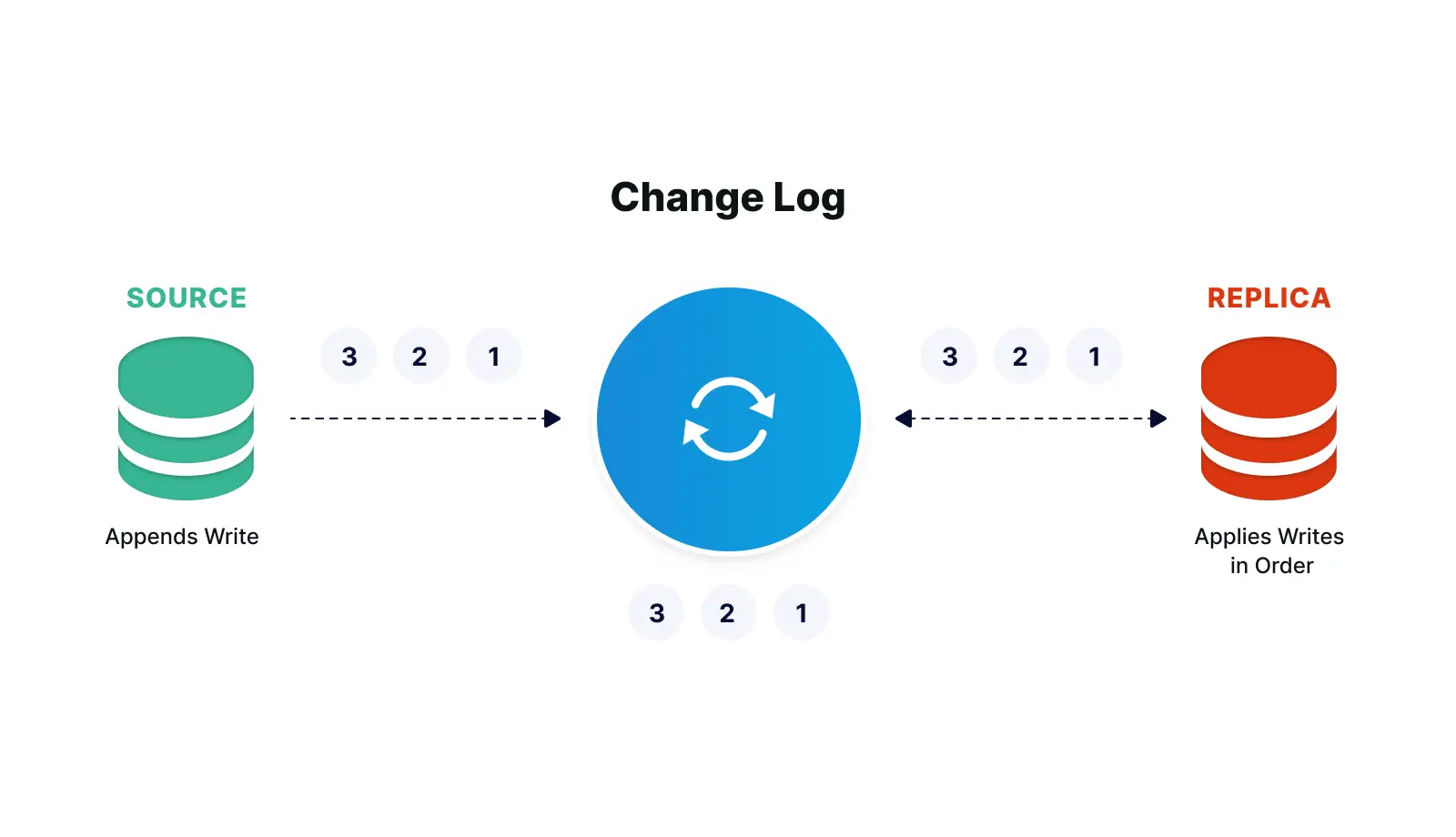
The events in the stream can be used to reconstruct the current account balances in the database, but not the other way around. Databases can be replicated with a technology called Change Data Capture (CDC), which collects the changes being applied to a source database, as soon as they occur by monitoring its change log, turns them into a stream of events, then applies those changes to a target database. Source code version control is another well known example of this, where the current state of a file is some base version, plus the accumulation of all changes that have been made to it.
The Change Log can be used to Replicate a Database
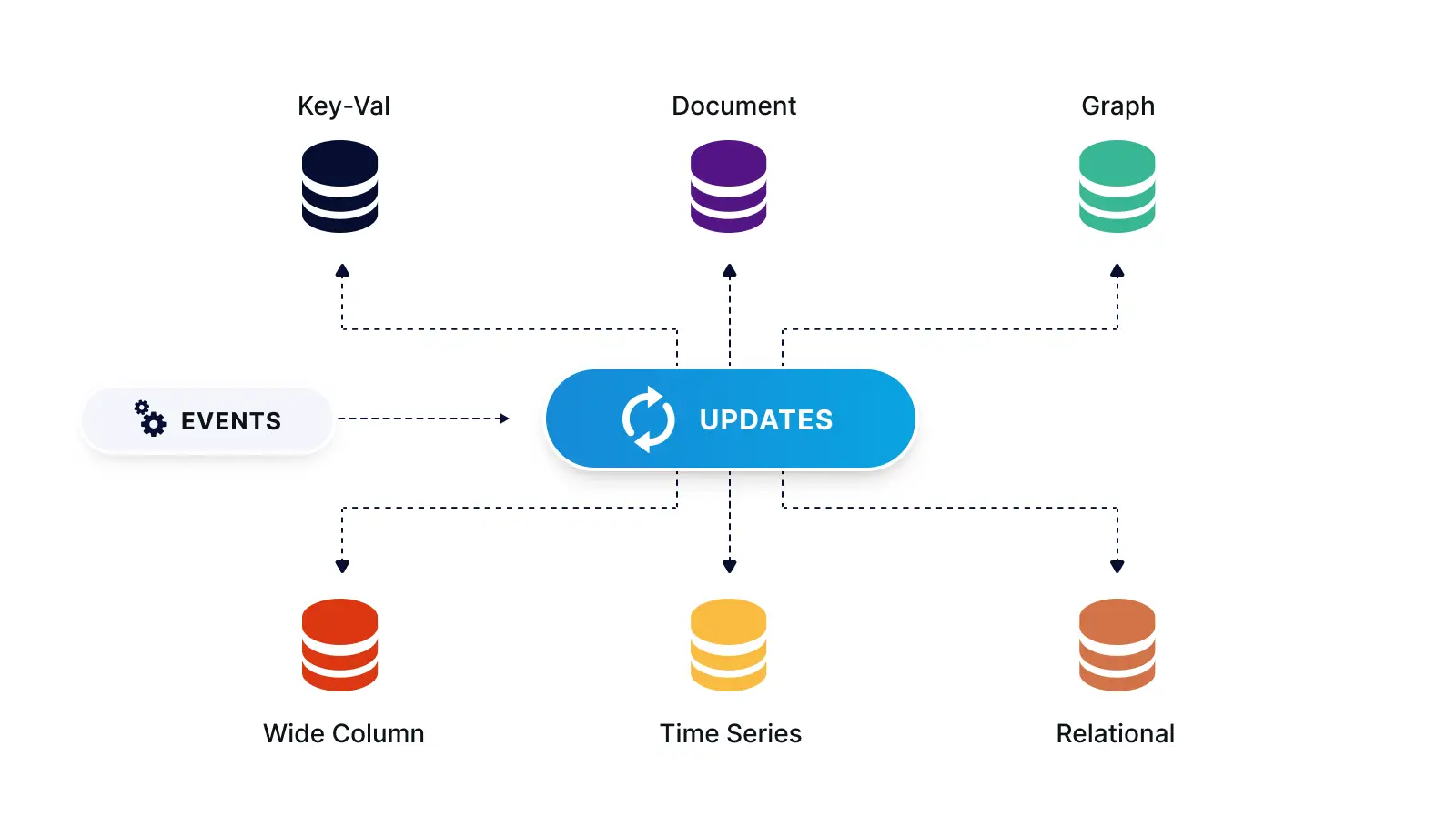
What if you need to have the same set of data for different databases, for different types of use? With a stream, the same message can be processed by different consumers for different purposes. As shown below, the stream can act as a distribution point, where, following the polygot persistence pattern, events can be delivered to a variety of data stores, each using the most suited technology for a particular use case or materialized view.
Streaming Events Delivered to a Variety of Data Stores
Event-Driven Streaming ETL Use Case Example
Below is a diagram of the Event-Driven Streaming ETL use case example:
Event-Driven Streaming ETL Use Case Diagram
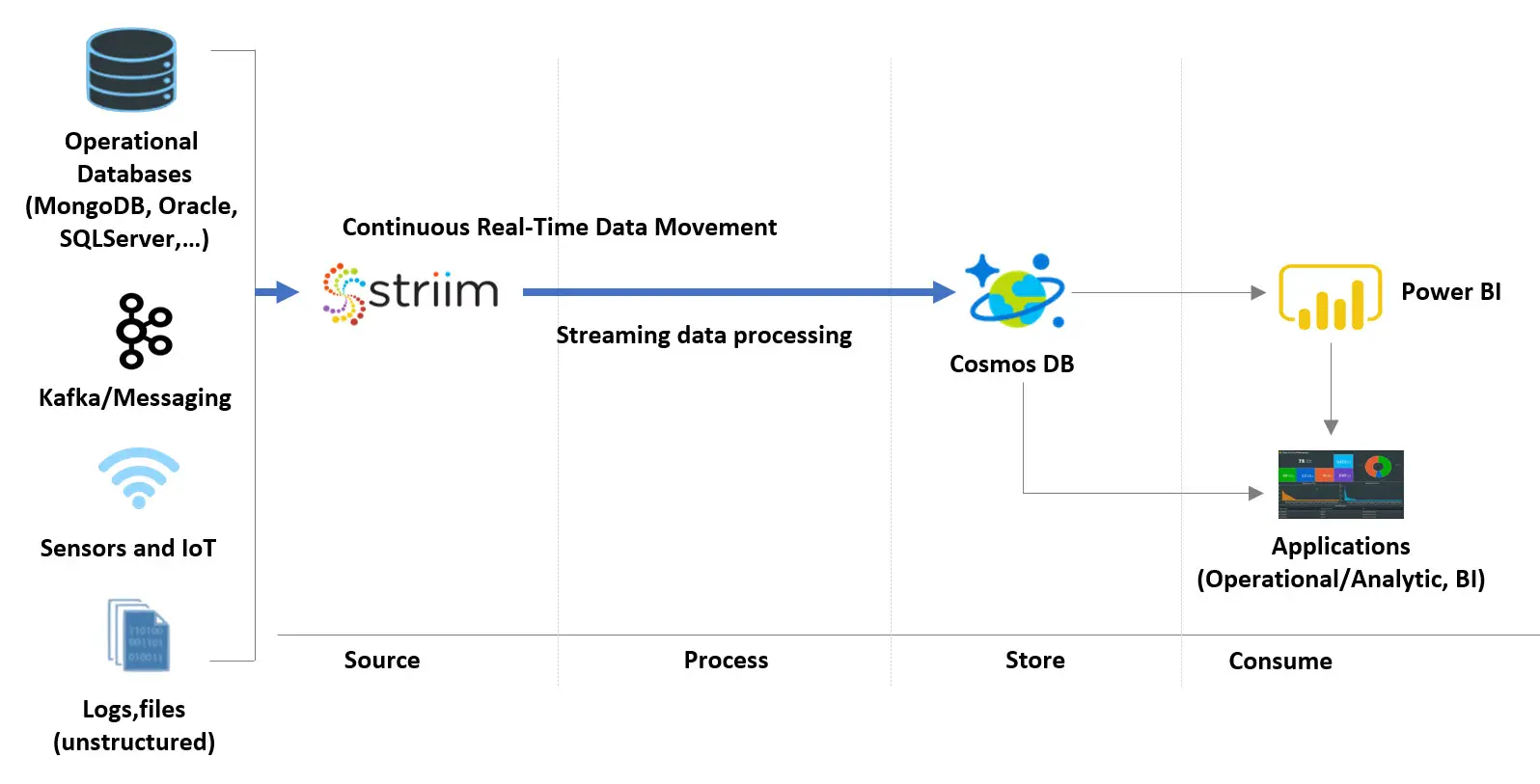
Striim’s low-impact, real-time Oracle change data capture (CDC) feature is used to stream database changes (inserts, updates and deletes) from an Operational Oracle database into Striim
CDC Events are enriched and denormalized with Streaming SQL and Cached data, in order to make relevant data available together
Enriched, denormalized events are streamed to CosmosDB for real-time analytics
Enriched streaming events can be monitored in real time with the Striim Web UI, and are available for further Streaming SQL analysis, wizard-based dashboards, and other applications in the cloud. You can use Striim by signing up for free Striim Developer or Striim Cloud trial.
Striim can simultaneously ingest data from other sources like Kafka and log files so all data is streamed with equal consistency. Please follow the instructions below to learn how to build a Oracle CDC to NoSQL MongoDB real-time streaming application:
Step1: Generate Schemas in your Oracle Database
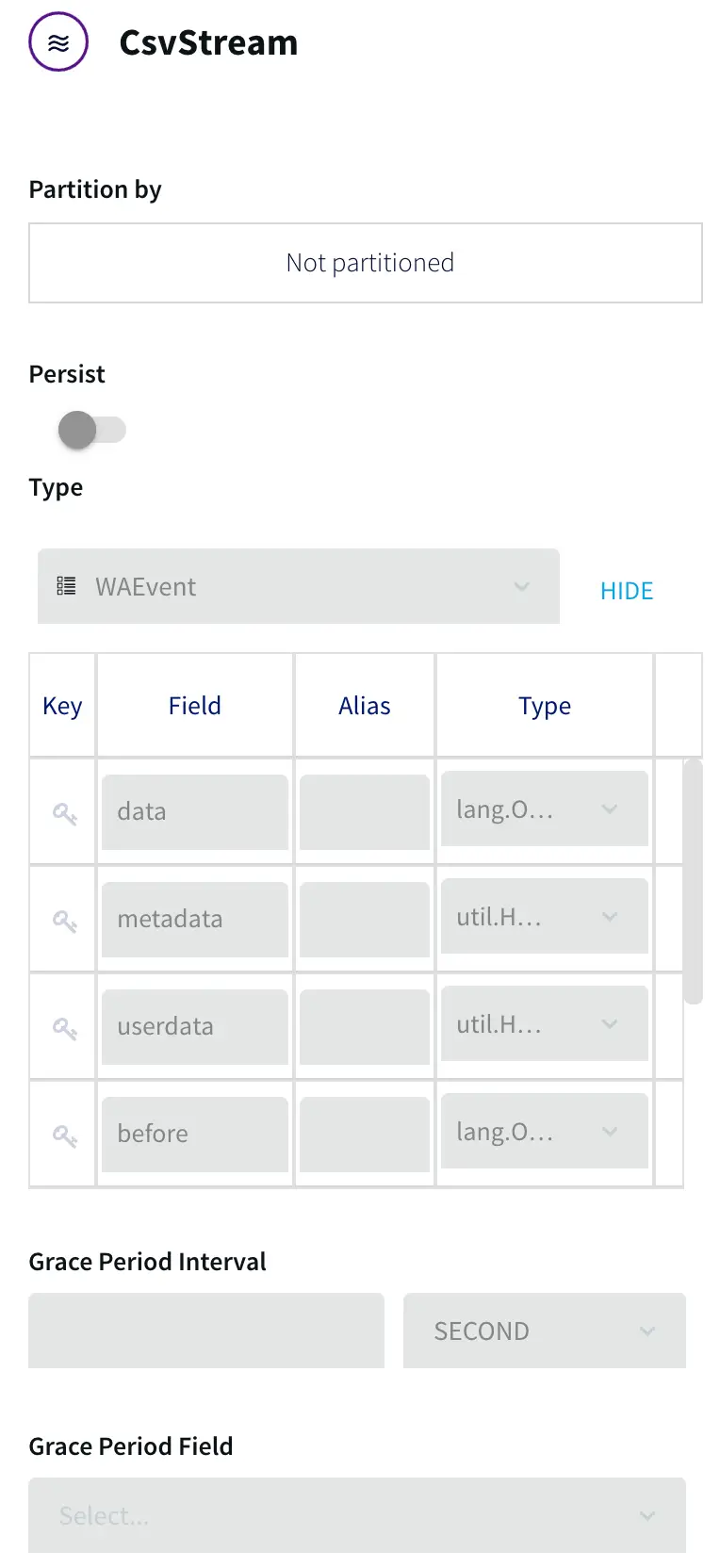
You can find the csv data file in our github repository. Use the following schema to create two empty tables in your source database:
The HOSPITAL_DATA table, containing details about each hospital would be used as a cache to enrich our real-time data stream.
Insert the data from this csv file to the above table.
The HOSPITAL_COMPLICATIONS_DATA contains details of complications in various hospitals. Ideally the data is streamed in real-time but for our tutorial, we will import csv data for CDC.
Step 2: Replacing Batch Extract with Real Time Streaming of CDC Order Events
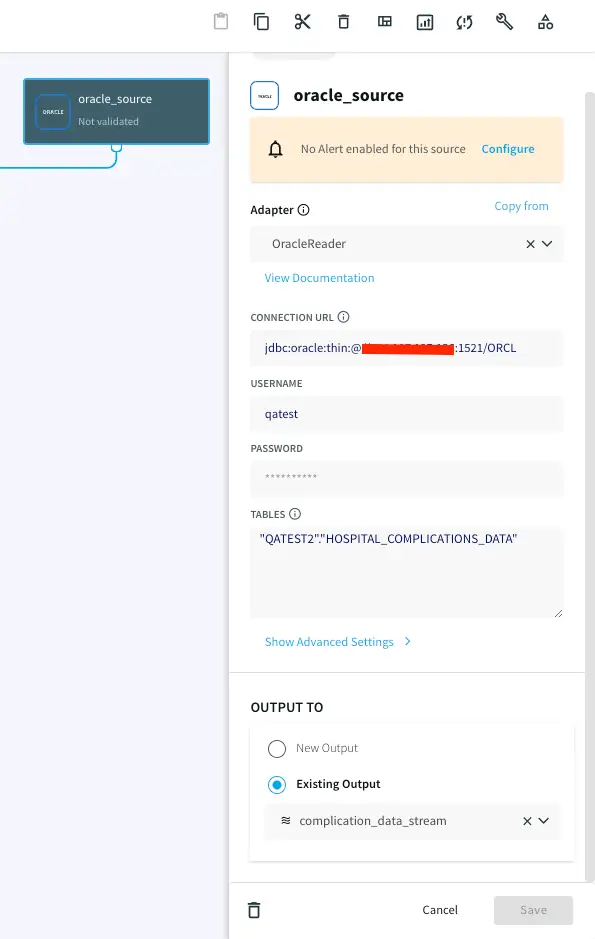
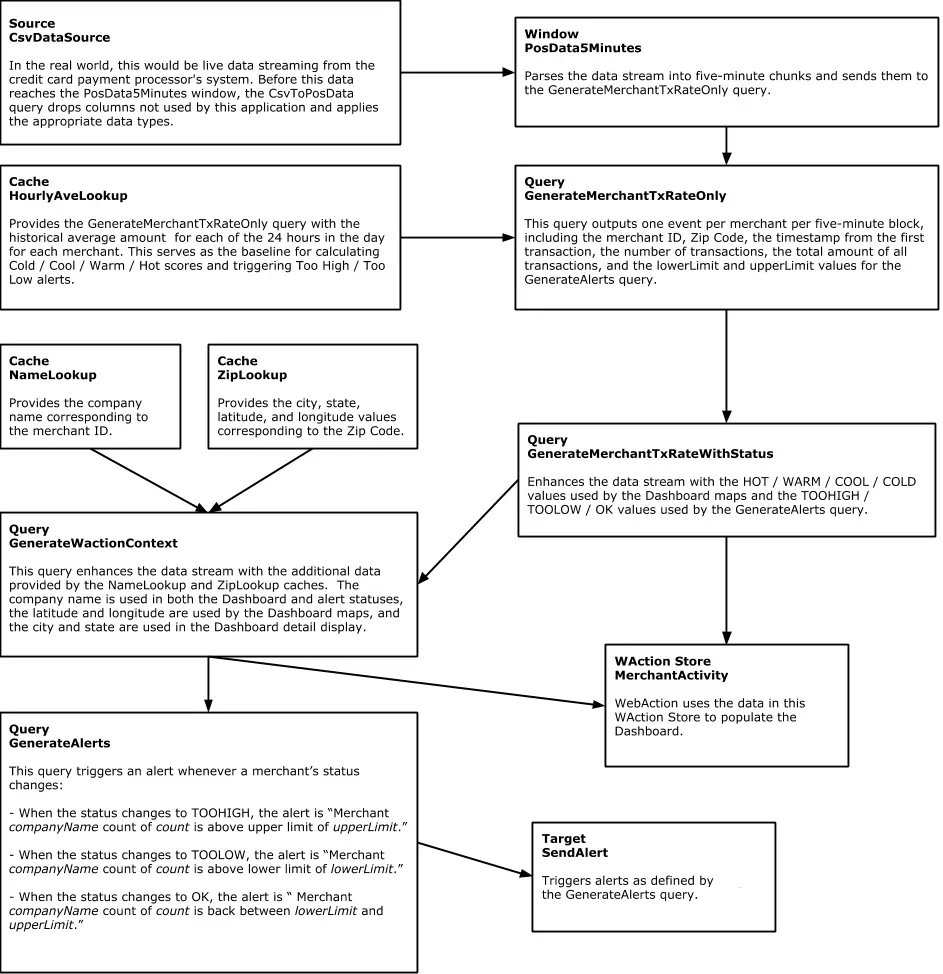
Striim’s easy-to-use CDC wizards automate the creation of applications that leverage change data capture, to stream events as they are created, from various source systems to various targets. In this example, shown below, we use Striim’s OracleReader (Oracle Change Data Capture) to read the hospital incident data in real-time and stream these insert, update, delete operations, as soon as the transactions commit, into Striim, without impacting the performance of the source database. Configure your source database by entering the hostname, username, password and table names.
Step 3: NULL Value handling
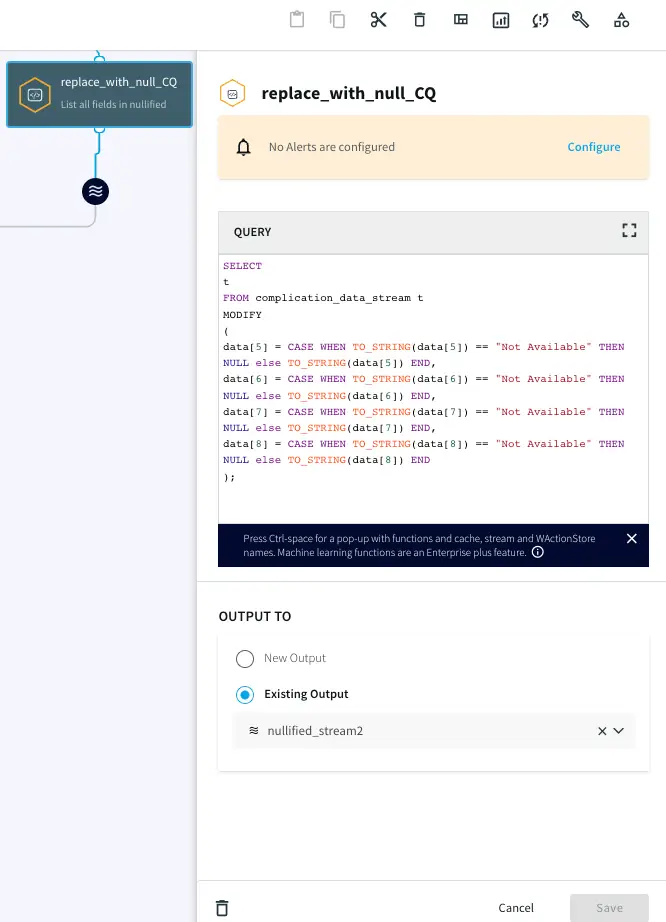
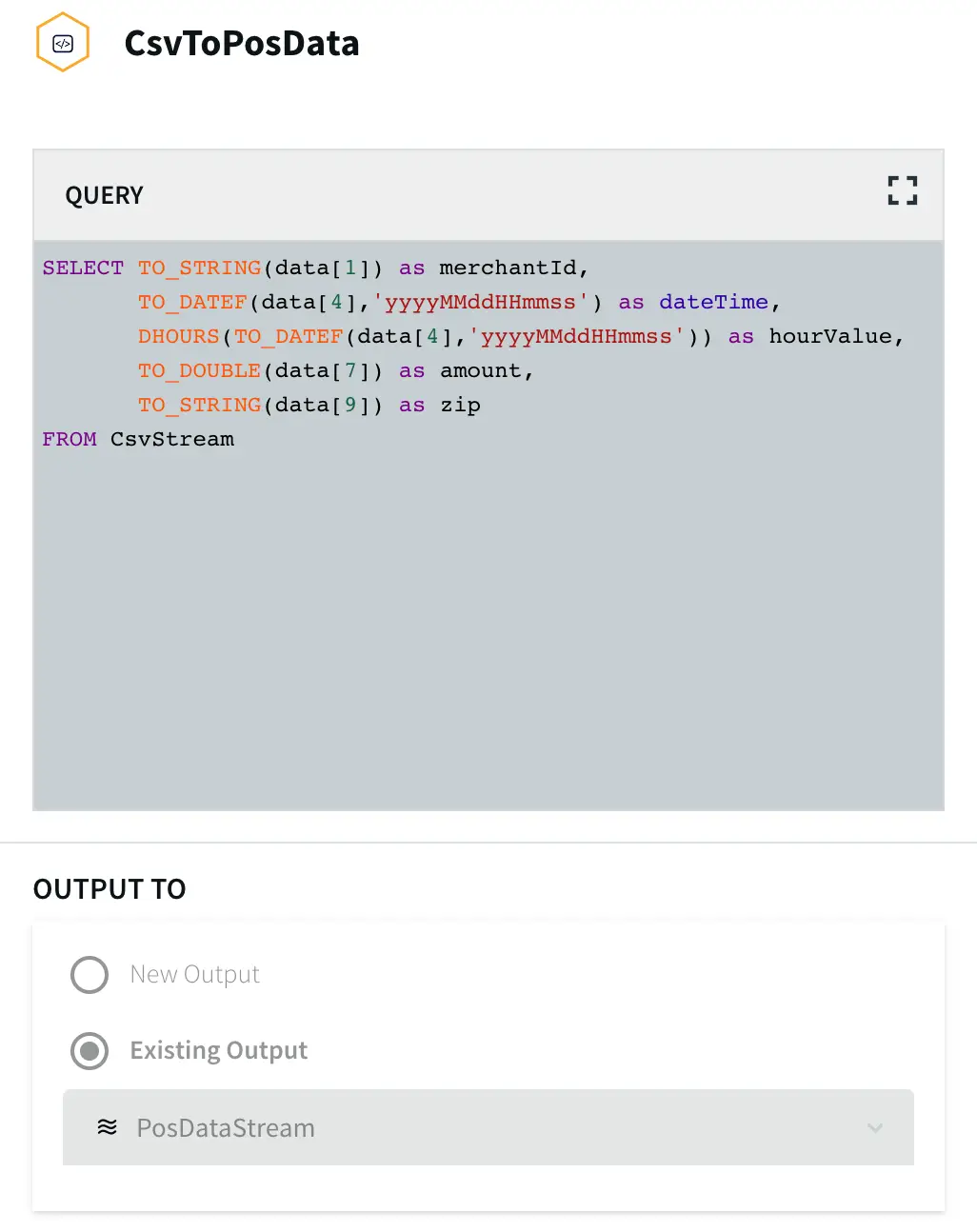
The data contains “Not Available” strings in some of the rows. Striim can manipulate the data in real-time to convert it into Null values using a Continuous Query component. Use the following query to change “Not Available” strings to Null:
SELECT
t
FROM complication_data_stream t
MODIFY
(
data[5] = CASE WHEN TO_STRING(data[5]) == "Not Available" THEN NULL else TO_STRING(data[5]) END,
data[6] = CASE WHEN TO_STRING(data[6]) == "Not Available" THEN NULL else TO_STRING(data[6]) END,
data[7] = CASE WHEN TO_STRING(data[7]) == "Not Available" THEN NULL else TO_STRING(data[7]) END,
data[8] = CASE WHEN TO_STRING(data[8]) == "Not Available" THEN NULL else TO_STRING(data[8]) END
);
Step 4: Using Continuous Query for Data Processing
The hospital_complications_data has a column COMPARED_TO_NATIONAL that indicates how the particular complication compares to national average. We will process this data to generate a column called ‘SCORE_COMPARISON’ that is in the scale of GOOD, BAD, OUTLIER or NULL and is easier to read. If “Number of Cases too small”, then the SCORE_COMPARISON is “Outlier” and if “worse than national average”, then the SCORE_COMPARISON is BAD otherwise GOOD.
SELECT
CASE WHEN TO_STRING(data[4]) =="Not Available" or TO_STRING(data[4]) =="Number of Cases Too Small"
THEN putUserData(t, 'SCORE_COMPARISON', "OUTLIER")
WHEN TO_STRING(data[4]) =="Worse than the National Rate"
THEN putUserData(t, 'SCORE_COMPARISON', "BAD")
WHEN TO_STRING(data[4]) =="Better than the National Rate" OR TO_STRING(data[4]) =="No Different than the National Rate"
THEN putUserData(t, 'SCORE_COMPARISON', "GOOD")
ELSE putUserData(t, 'SCORE_COMPARISON', NULL)
END
FROM nullified_stream2 t;
Step 5: Utilizing Caches For Enrichment
Relational Databases typically have a normalized schema which makes storage efficient, but causes joins for queries, and does not scale well horizontally. NoSQL databases typically have a denormalized schema which scales across a cluster because data that is read together is stored together.
With a normalized schema, a lot of the data fields will be in the form of IDs. This is very efficient for the database, but not very useful for downstream queries or analytics without any meaning or context. In this example we want to enrich the raw Orders data with reference data from the SalesRep table, correlated by the Order Sales_Rep_ID, to produce a denormalized record including the Sales Rep Name and Email information in order to make analysis easier by making this data available together.
Since the Striim platform is a high-speed, low latency, SQL-based stream processing platform, reference data also needs to be loaded into memory so that it can be joined with the streaming data without slowing things down. This is achieved through the use of the Cache component. Within the Striim platform, caches are backed by a distributed in-memory data grid that can contain millions of reference items distributed around a Striim cluster. Caches can be loaded from database queries, Hadoop, or files, and maintain data in-memory so that joining with them can be very fast. In this example, shown below, the cache is loaded with a query on the SalesRep table using the Striim DatabaseReader.
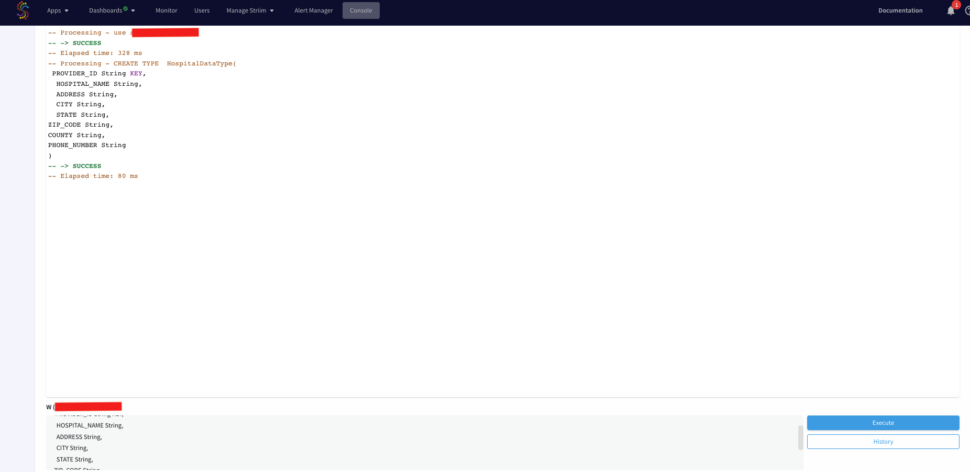
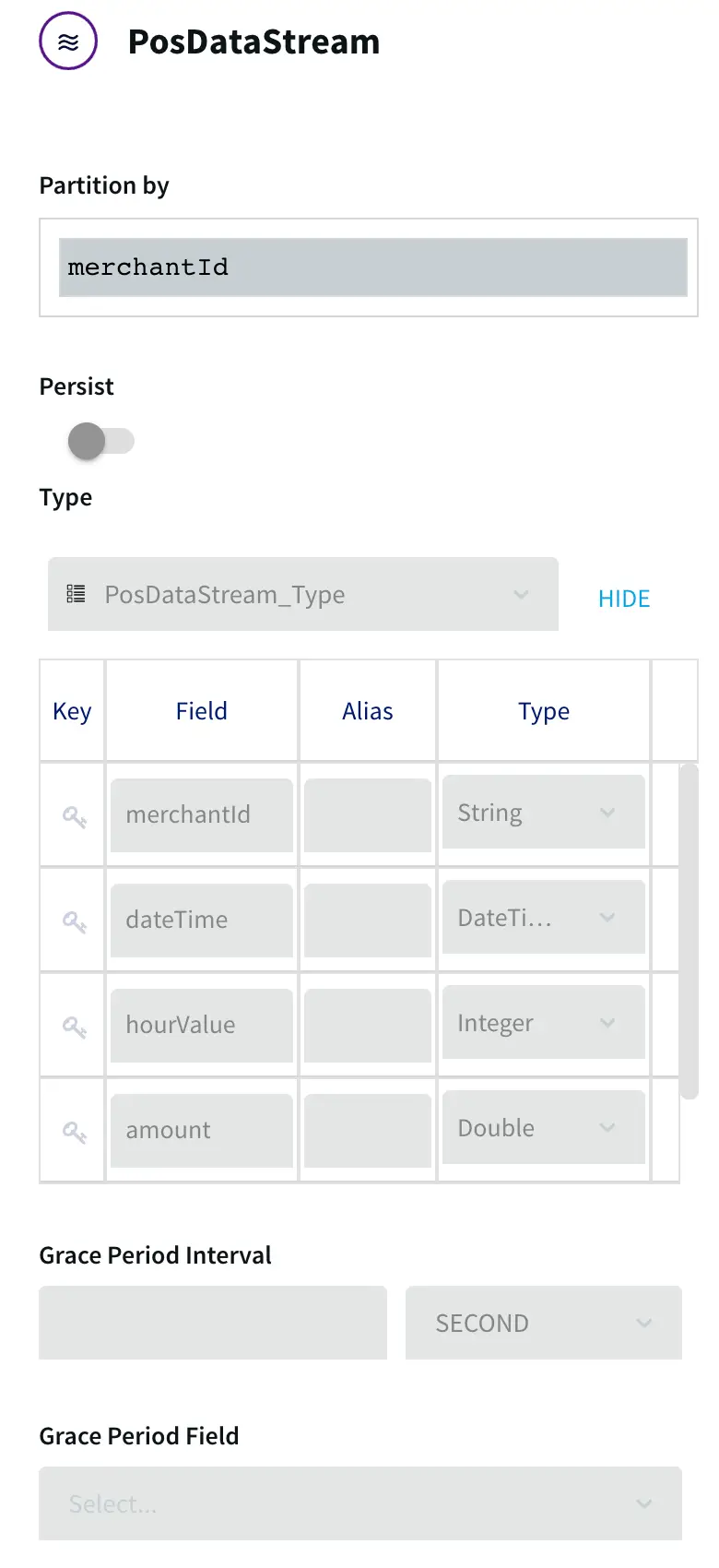
First we will define a cache type from the console. Run the following query from your console.
CREATE TYPE HospitalDataType(
PROVIDER_ID String KEY,
HOSPITAL_NAME String,
ADDRESS String,
CITY String,
STATE String,
ZIP_CODE String,
COUNTY String,
PHONE_NUMBER String
);
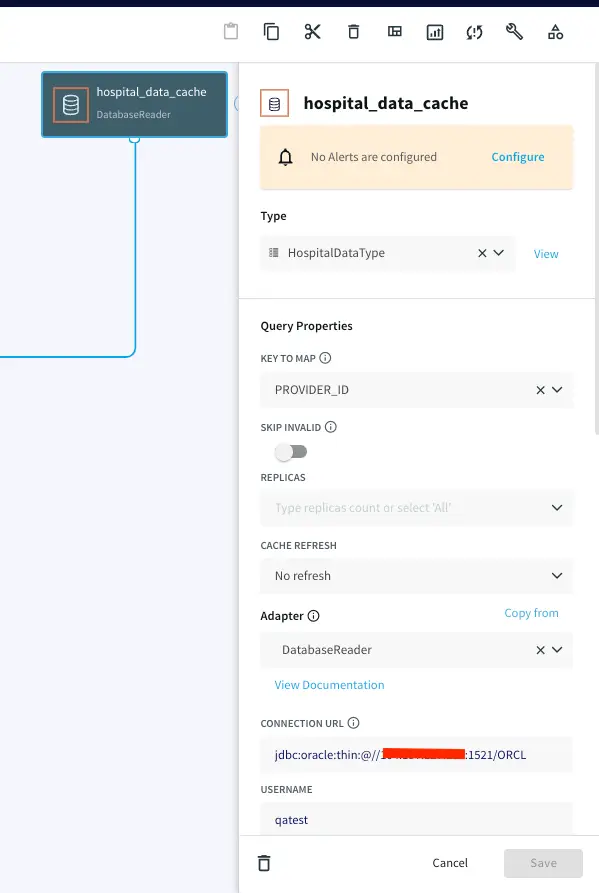
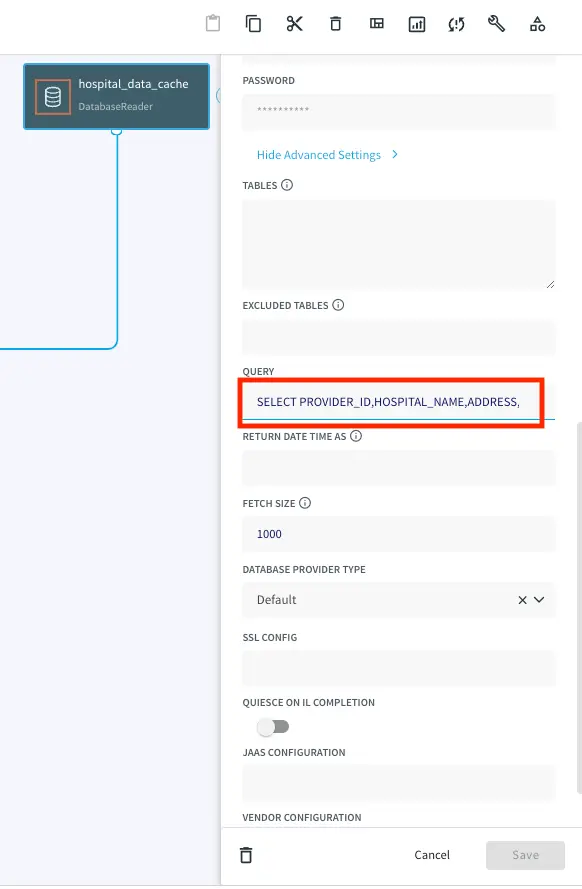
Now, drag a DB Cache component from the list of Striim Components on the left and enter your database details. The table will be queried to join with the streaming data.
Query:
SELECT PROVIDER_ID,HOSPITAL_NAME,ADDRESS,CITY,STATE,ZIP_CODE,COUNTY,PHONE_NUMBER FROM QATEST2.HOSPITAL_DATA;
Step 6: Joining Streaming and Cache Data For Real Time Transforming and Enrichment With SQL
We can process and enrich data-in-motion using continuous queries written in Striim’s SQL-based stream processing language. Using a SQL-based language is intuitive for data processing tasks, and most common SQL constructs can be utilized in a streaming environment. The main differences between using SQL for stream processing, and its more traditional use as a database query language, are that all processing is in-memory, and data is processed continuously, such that every event on an input data stream to a query can result in an output.
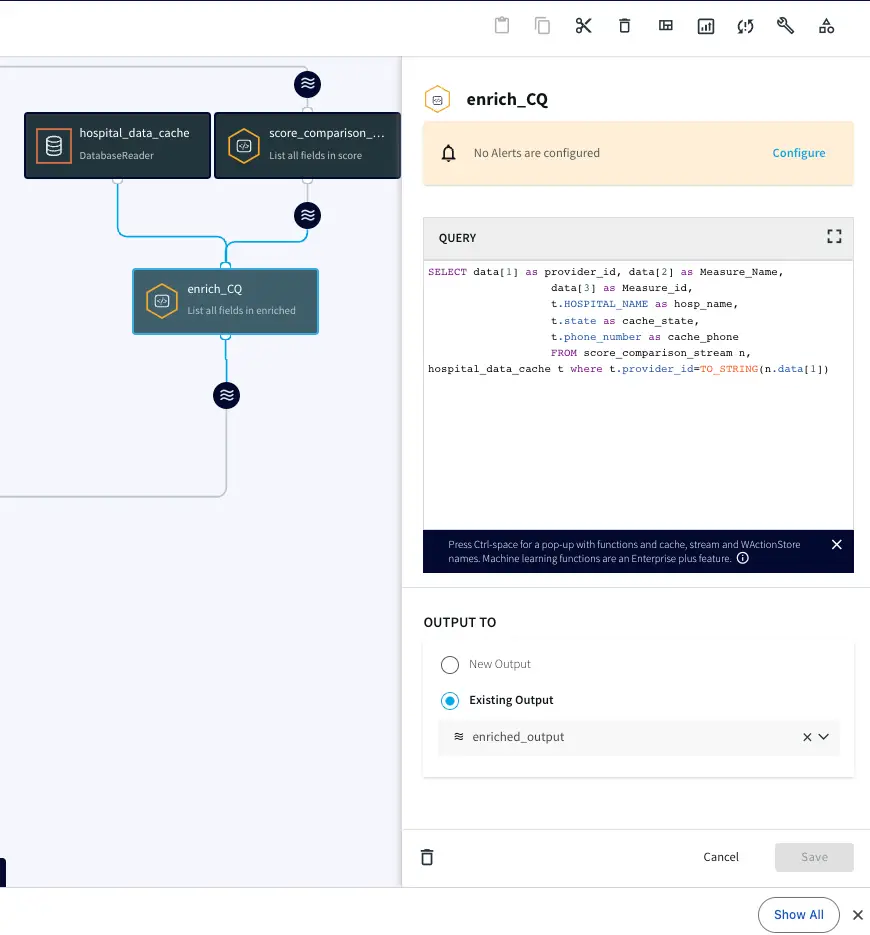
This is the query we will use to process and enrich the incoming data stream:
SELECT data[1] as provider_id, data[2] as Measure_Name, data[3] as Measure_id,
t.HOSPITAL_NAME as hosp_name,
t.state as cache_state,
t.phone_number as cache_phone
FROM score_comparison_stream n, hospital_data_cache t where t.provider_id=TO_STRING(n.data[1]);
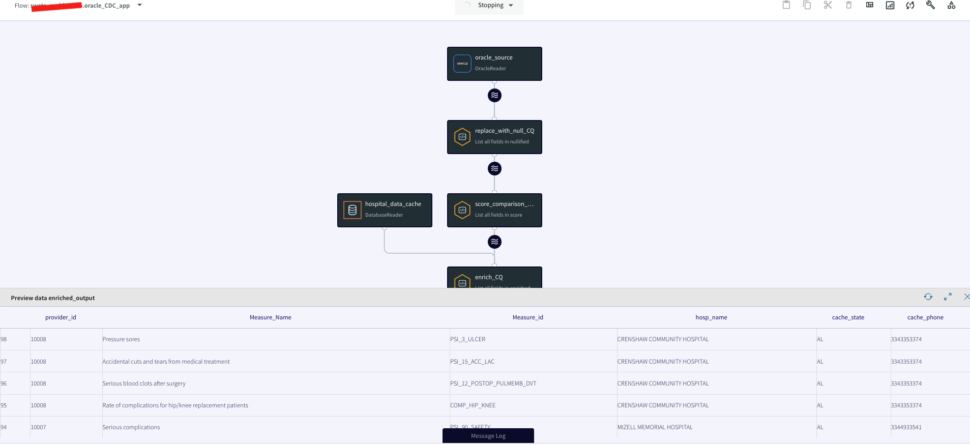
In this query, we enriched our streaming data using cache data about hospital details. The result of this query is to continuously output enriched (denormalized) events, shown below, for every CDC event that occurs for the HOSPITAL_COMPLICATIONS_DATA table. So with this approach we can join streams from an Oracle Change Data Capture reader with cached data for enrichment.
Step 7: Loading the Enriched Data to the Cloud for Real Time Analytics
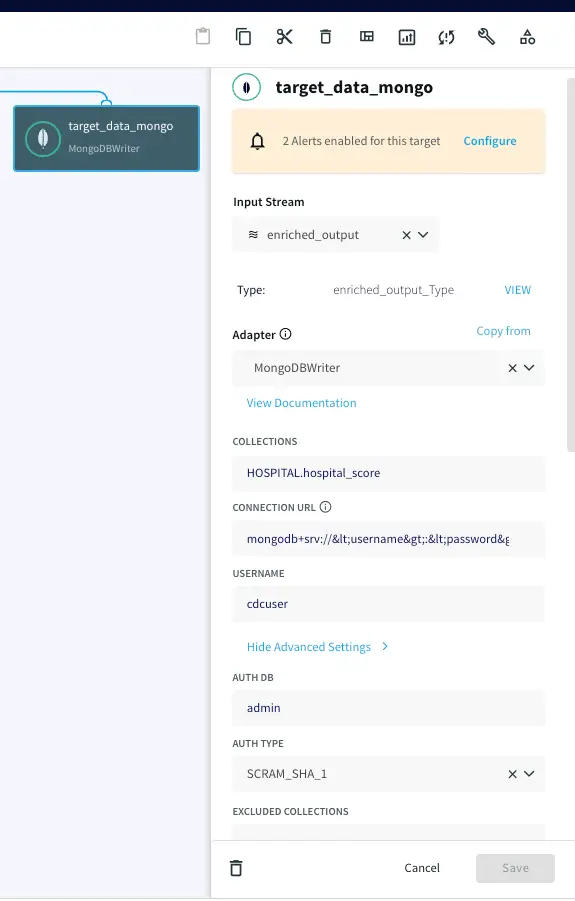
Now the Oracle CDC (Oracle change data capture) data, streamed and enriched through Striim, can be stored simultaneously in NoSQL Mongodb using Mongodb writer. Enter the connection url for your mongodb Nosql database in the following format and enter your username, password and collections name.
Step 8: Running the Oracle CDC to Mongodb streaming application
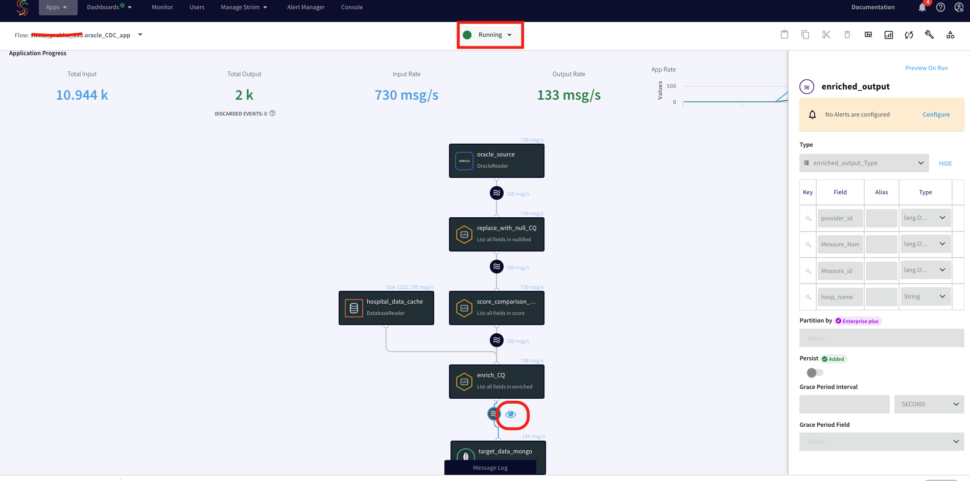
Now that the striim app is configured, you will deploy and run the CDC application. You can also download the TQL file (passphrase: striimrecipes) from our github repository and configure your own source and targets. Import the csv file to HOSPITAL_COMPLICATIONS_DATA table on your source database after the striim app has started running. The Change data capture is streamed through the various components for enrichment and processing. You can click on the ‘eye’ next to each stream component to see the data in real-time.
Using Kafka for Streaming Replay and Application Decoupling
The enriched stream of order events can be backed by or published to Kafka for stream persistence, laying the foundation for streaming replay and application decoupling. Striim’s native integration with Apache Kafka makes it quick and easy to leverage Kafka to make every data source re-playable, enabling recovery even for streaming sources that cannot be rewound. This also acts to decouple applications, enabling multiple applications to be powered by the same data source, and for new applications, caches or views to be added later.
Streaming SQL for Aggregates
We can further use Striim’s Streaming SQL on the denormalized data to make a real time stream of summary metrics about the events being processed available to Striim Real-Time Dashboards and other applications. For example, to create a running count of each measure_id in the last hour, from the stream of enriched orders, you would use a window, and the familiar group by clause.
CREATE WINDOW IncidentWindow
OVER EnrichCQ
KEEP WITHIN 1 HOUR
PARTITION BY Measure_id;he familiar group by clause.
SELECT Measure_id,
COUNT(*) as MeasureCount,
FROM IncidentWindow
GROUP BY Measure_id;
Monitoring
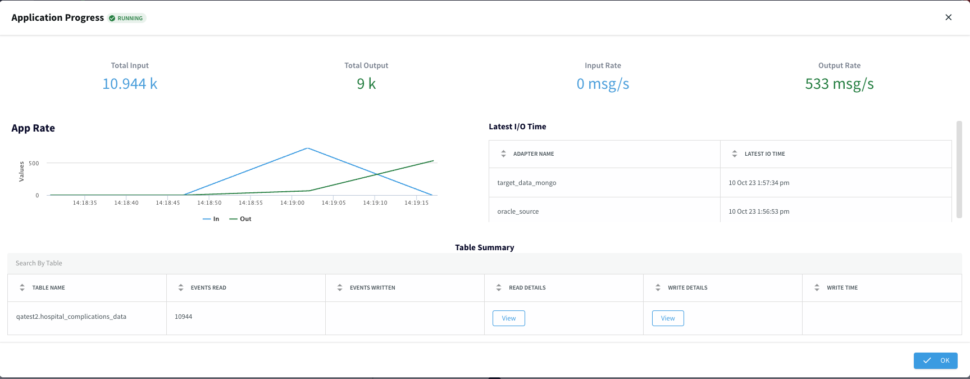
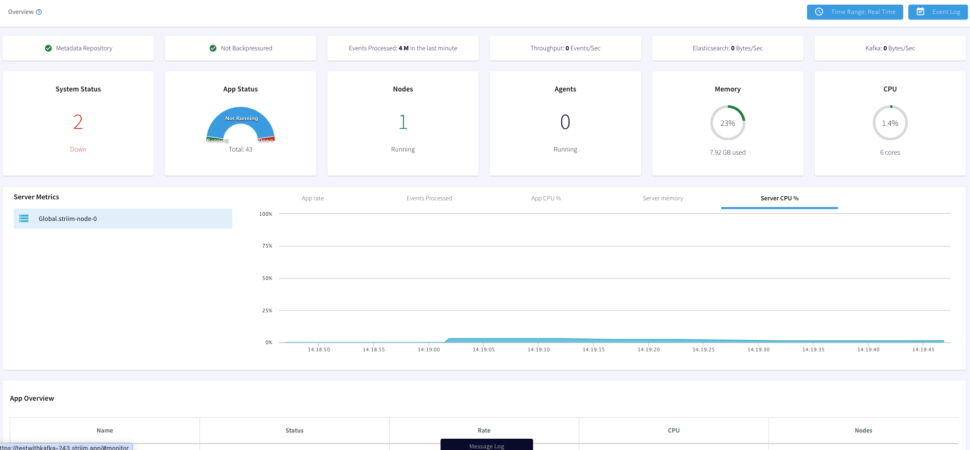
With the Striim Monitoring Web UI we can now monitor our data pipeline with real-time information for the cluster, application components, servers, and agents. The Main monitor page allows to visualize summary statistics for Events
Processed, App CPU%, Server Memory, or Server CPU%. Below the Monitor App page displays our App Resources, Performance and Components.
Summary
In this blog post, we discussed how we can use Striim to:
Use streaming SQL and caches to easily denormalize data in order to make relevant data available together
Load streaming enriched data to Mongodb for real-time analytics
Use Kafka for persistent streams
Create rolling aggregates with streaming SQL
Continuously monitor data pipelines
Wrapping Up
Striim’s power is in its ability to ingest data from various sources and stream it to the same (or different) destinations. This means data going through Striim is held to the same standard of replication, monitoring, and reliability.
In conclusion, this recipe showcased a shift from batch ETL to event-driven distributed stream processing. By capturing Oracle change data events in real-time, enriching them through in-memory, SQL-based denormalization, and seamlessly delivering to the Azure Cloud, we achieved scalable, cost-effective analytics without disrupting the source database. Moreover, the enriched events, optionally supported by Kafka, offer the flexibility to incrementally integrate additional event-driven applications or services.
To give anything you’ve seen in this recipe a try, sign up for our developer edition or sign up for Striim Cloud free trial.
Stream Data from PostgreSQL to Google BigQuery with Striim Cloud – Part 1
Use Striim Cloud to stream data securely from PostgreSQL database into Google BigQuery
Benefits
Operational Analytics
Analyze real-time operational, transactional data from PostgreSQL in BigQuery
Secure Data Transfer
Secure data-at-rest and in-flight with simple SSH tunnel configuration and automatic encryption
Build Real-Time Analytical ModelsUse the power of Real Time Data Streaming to build Real-Time analytical and ML models
On this page
Overview
Striim is a next generation Cloud Data Integration product that offers change data capture (CDC) enabling continuous replication from popular databases
such as Oracle, SQLServer, PostgreSQL and many others.
In addition to CDC connectors, Striim has hundreds of automated adapters for file-based data (logs, xml, csv), IoT data (OPCUA, MQTT), and applications such as Salesforce and SAP. Our SQL-based stream processing engine makes it easy to
enrich and normalize data before it’s written to targets like BigQuery and Snowflake.
Traditionally Data warehouses that required data to be transferred use batch processing but with Striim’s streaming platform data can be replicated in real-time efficiently.
Securing the in-flight data is very important in any real world application. A jump host creates an encrypted public connection into a secure environment.
In this tutorial, we’ll walk you through how to create a secure SSH tunnel between Striim cloud and your on-premise/cloud databases with an example where data is streamed securely from PostgreSQL database into Google
BigQuery through SSH tunneling.
Core Striim Components
PostgreSQL Reader: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
BigQueryWriter: Striim’s BigQueryWriter writes the data from various supported sources into Google’s BigQuery data warehouse to support real time data warehousing and reporting.
(Optional) Step 1: Secure connectivity to your database
Striim provides multiple methods for secure connectivity to your database. For Striim Developer, you can allowlist the IP address in your email invite.
In Striim Cloud, you can either allow your service IP or follow the below steps to configure a jump server.
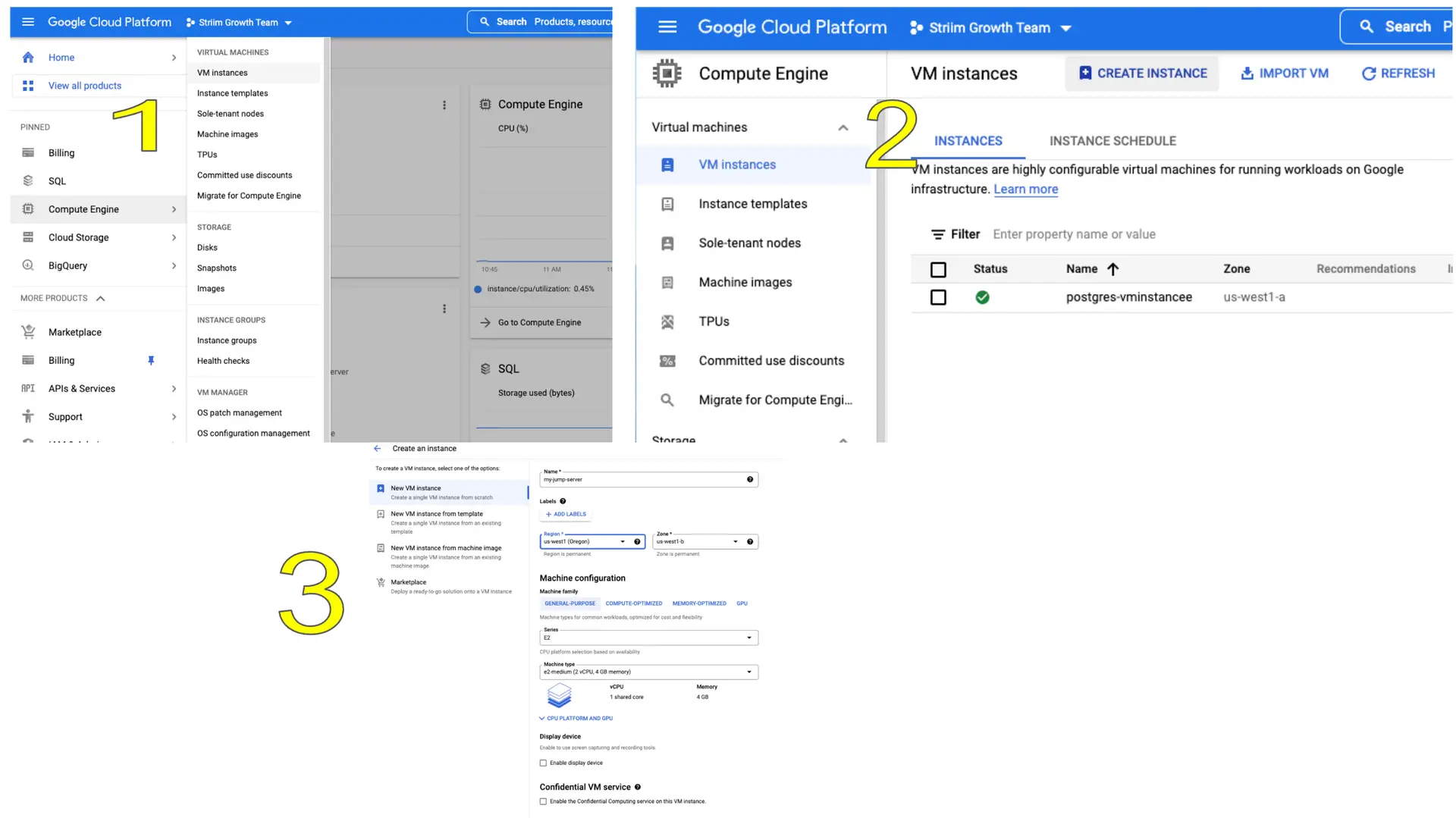
Follow the steps below to set up your jump server on Google Compute Engine:
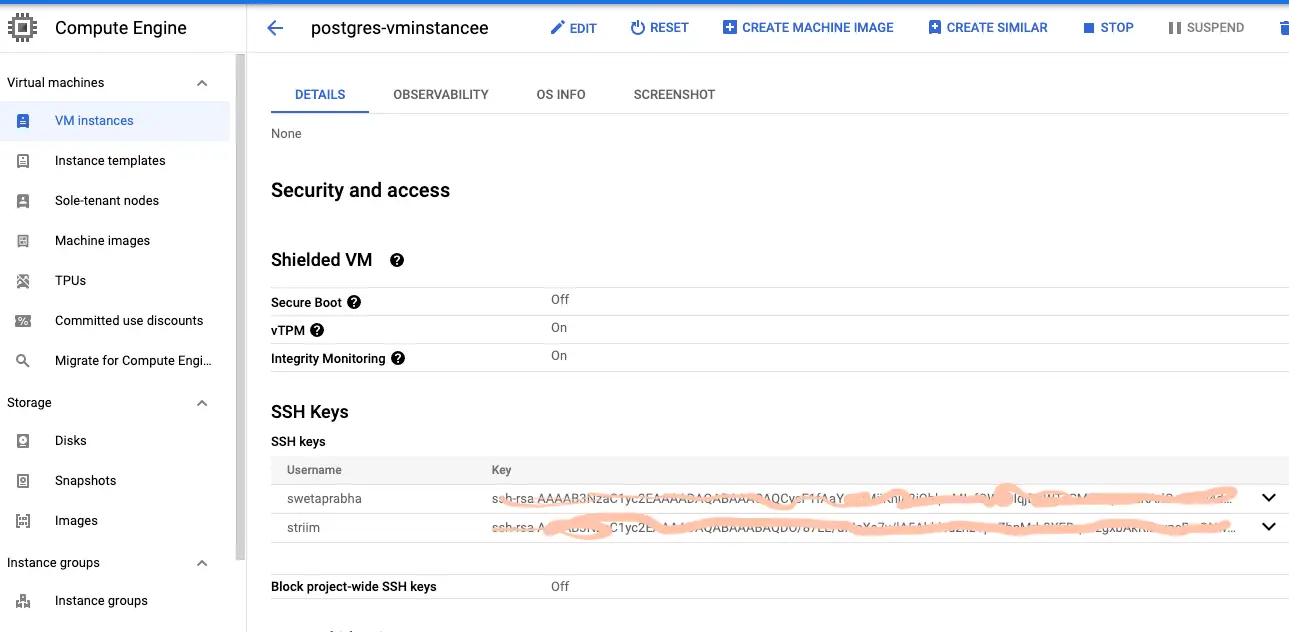
Go to google cloud console -> Compute Engine -> VM instances and create a new VM instance that would act as the jump server.
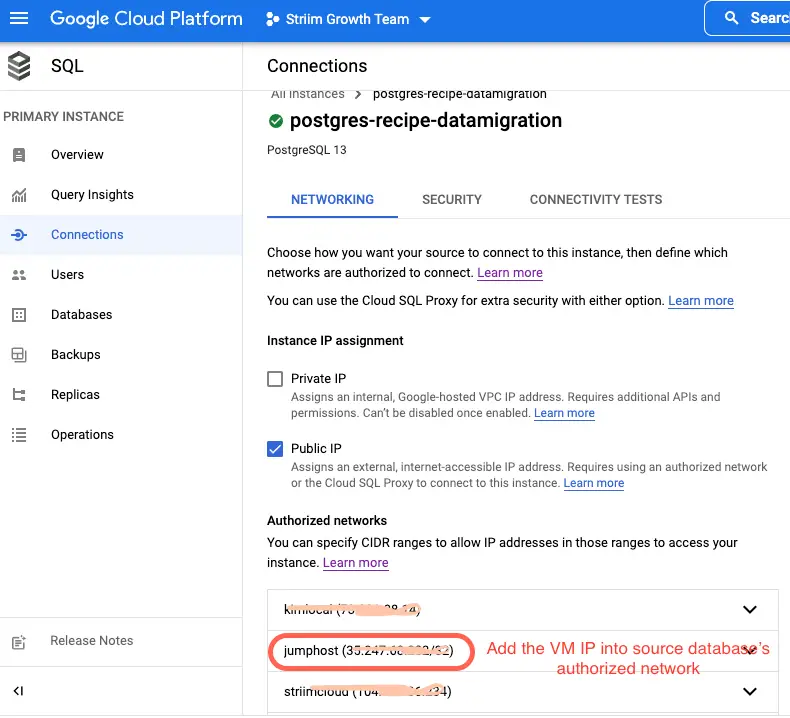
Add the jump server’s IP address to authorized networks of source database, in this case postgres instance
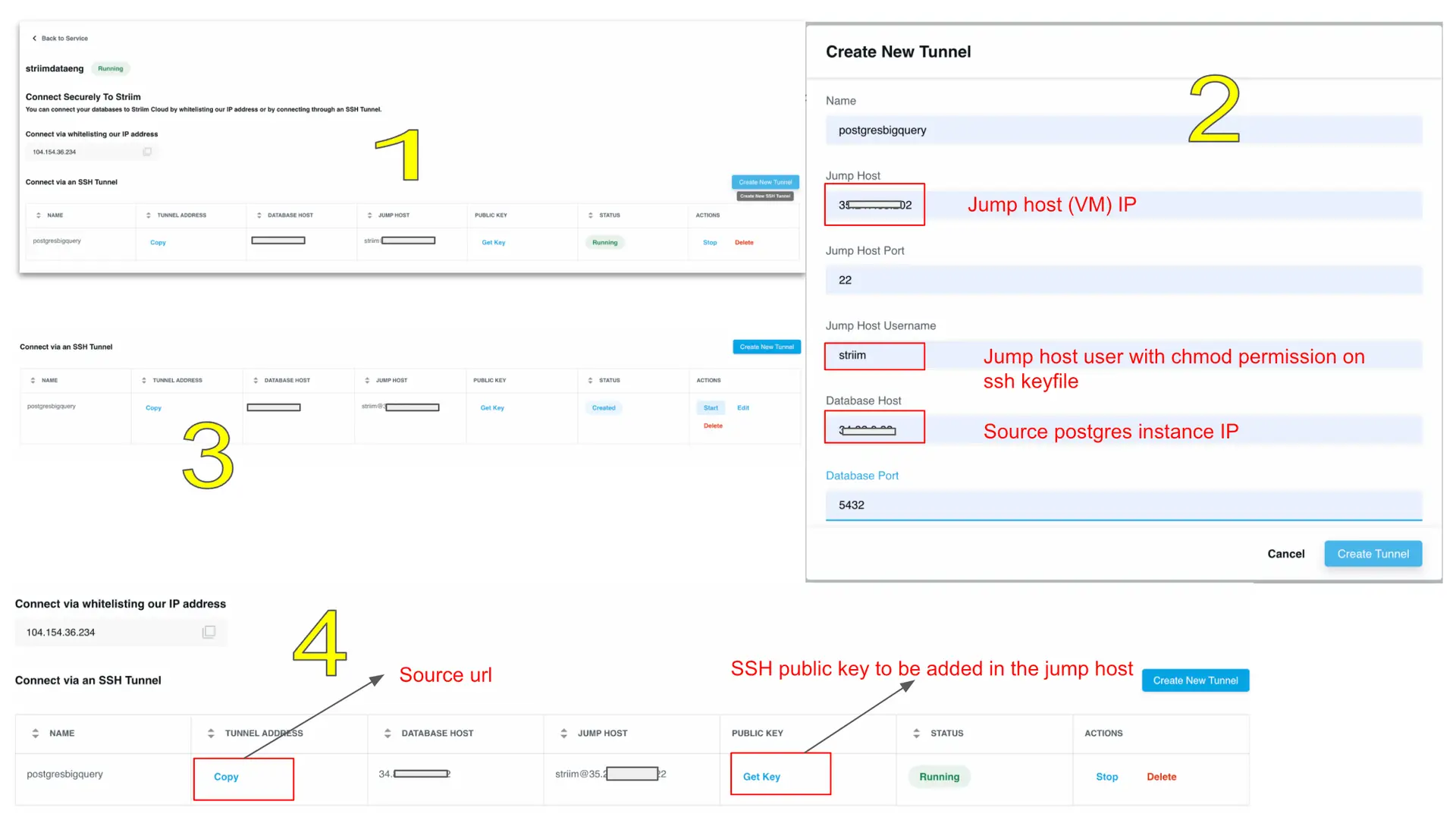
Step 2: Create SSH tunnel on Striim Cloud
Once the jump host is set up, an SSH tunnel will be created from Striim Cloud UI to establish a connection to the source database through the jump server.
Follow the steps below to configure an SSH tunnel between source database and Striim cloud:
Go to striim cloud console and launch a service instance. Under security create a new SSH tunnel and configure it as below.
Go to jump server (VM instance) and add the service key copied from the above step’
Now Striim server is integrated with both postgres and Bigquery and we are ready to configure Striim app for data migration.
Step 3: Launch Striim Server and Connect the Postgres Instance
For this recipe, we will host our app in Striim Cloud but there is always a free trial to see the power of Striim’s Change Data Capture.
Follow the steps below to connect Striim server to postgres instance containing the source database:
Click on Apps to display the app management screen:
Click on Create app :
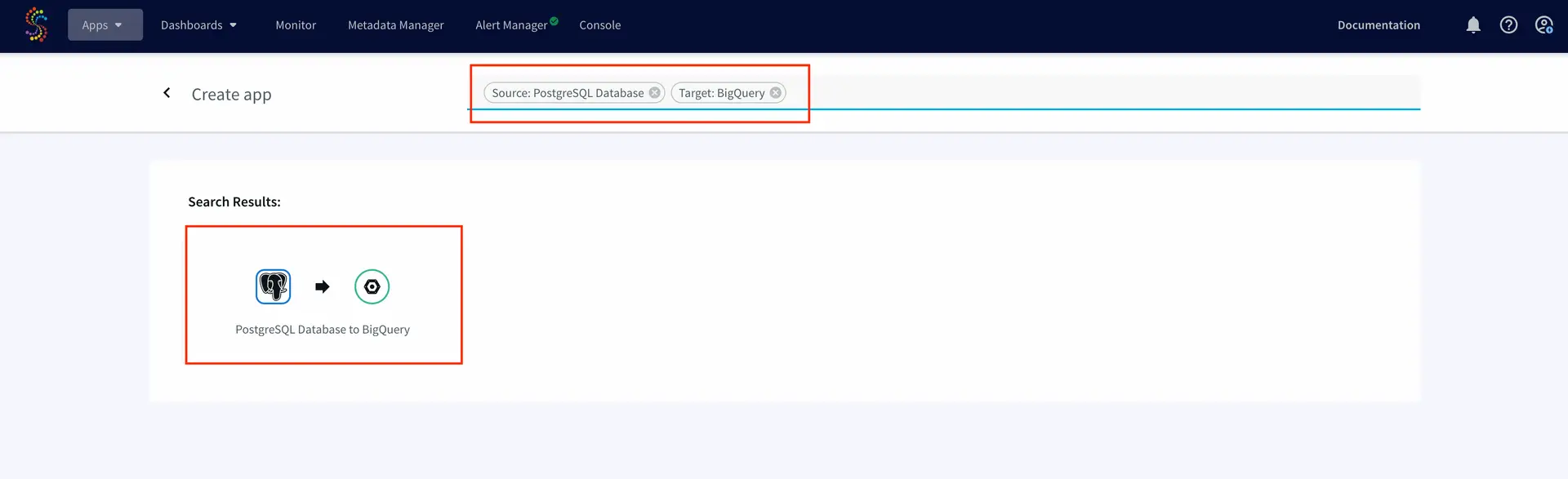
Select Source and Target under create app from wizard:
Give a name to your app and establish the connection between striim server and postgres instance.
Once the connection between posgres and striim server is established, we will link the target data warehouse, in this case Google Bigquery. Striim also offers schema conversion feature where table schema can be validated for both source and target that
helps in migration of source schema to the target database.
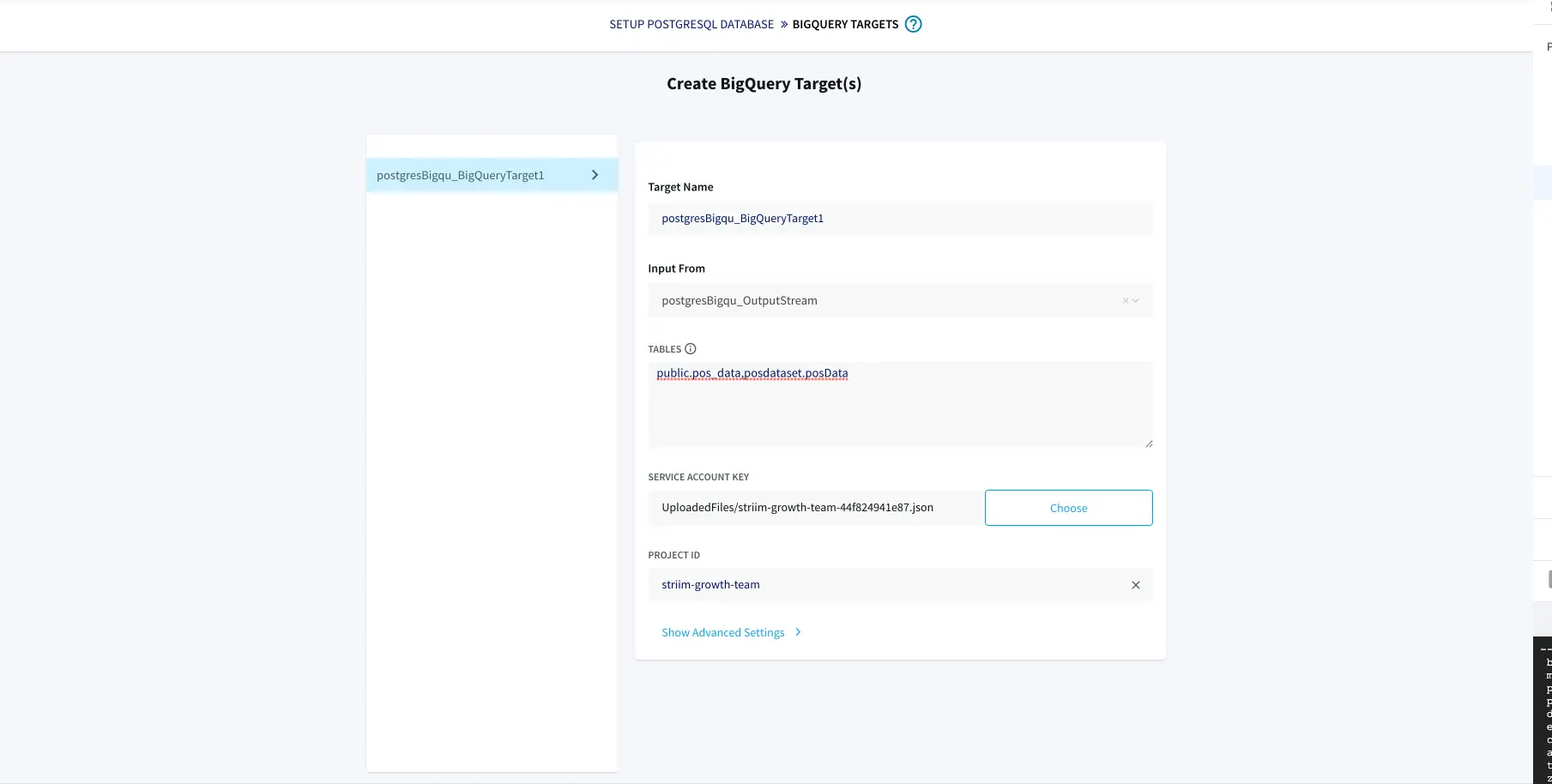
Step 4: Targeting Google Bigquery
You have to make sure the instance of Bigquery mirrors the tables in the source database.This can be done from Google Cloud Console interface.Under the project inside Google Bigquery, create the dataset and an emty table containing all the columns that is populated
with data migrated from postgres database.
Follow the steps below to create a new dataset in Bigquery and integrating with Striim app using a service account:
Create a dataset with tables mirroring the source schema.
Go back to app wizard and enter the service key of your BigQuery instance to connect the app with target data warehouse
Now Striim server is integrated with both postgres and Bigquery and we are ready to configure Striim app for data migration.
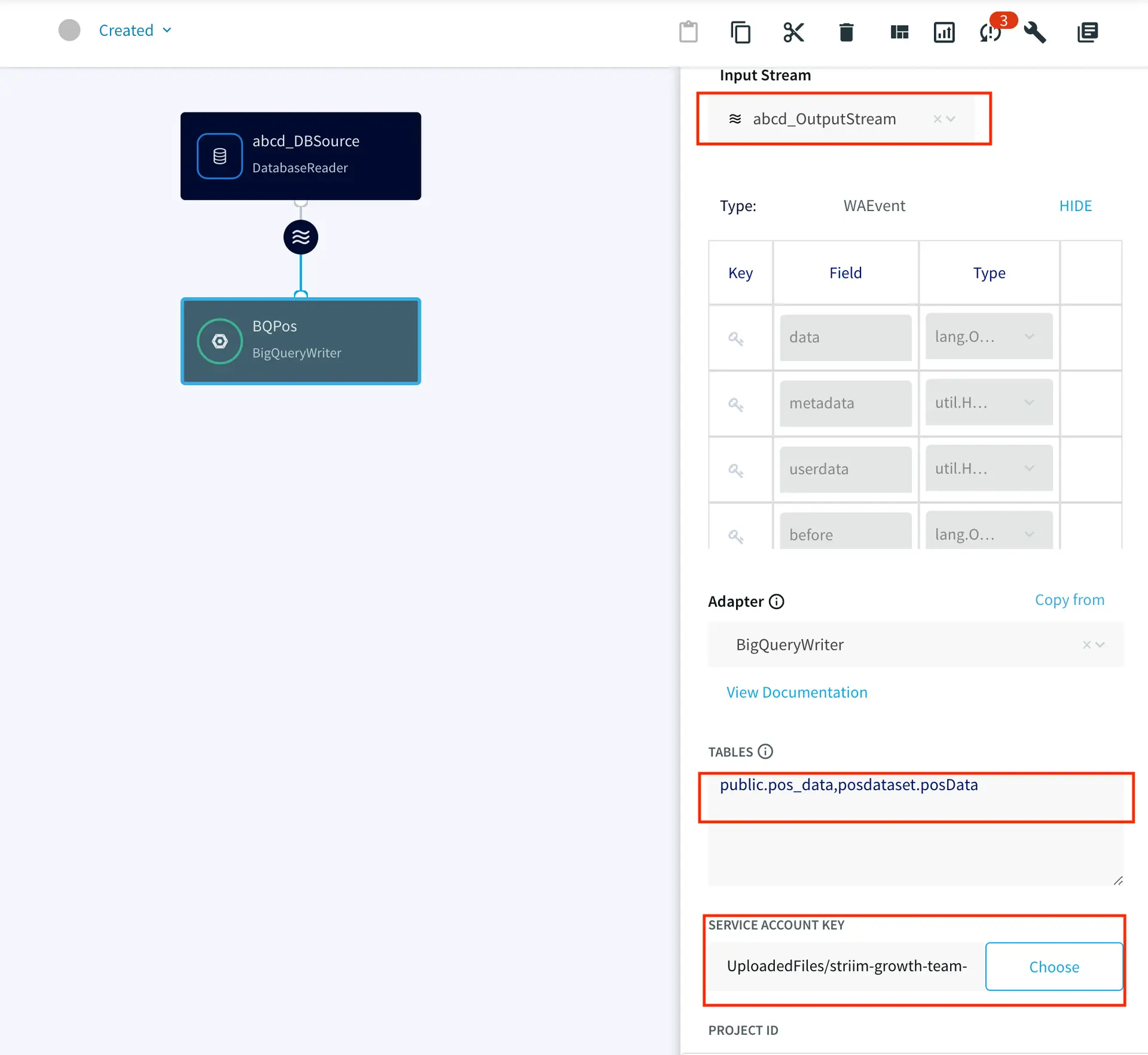
Step 5: Configure Striim app using UI
With source, target and Striim server integrated for data migration, a few configuration on the easy to understand app UI is made before deploying and running the app.
Click on source and add the connection url (tunnel address), user name and password in proper format:
Click on target and add the input stream, source and target tables and upload the service key for Bigquery instance
Now the app is good to go for deployment and data migration.
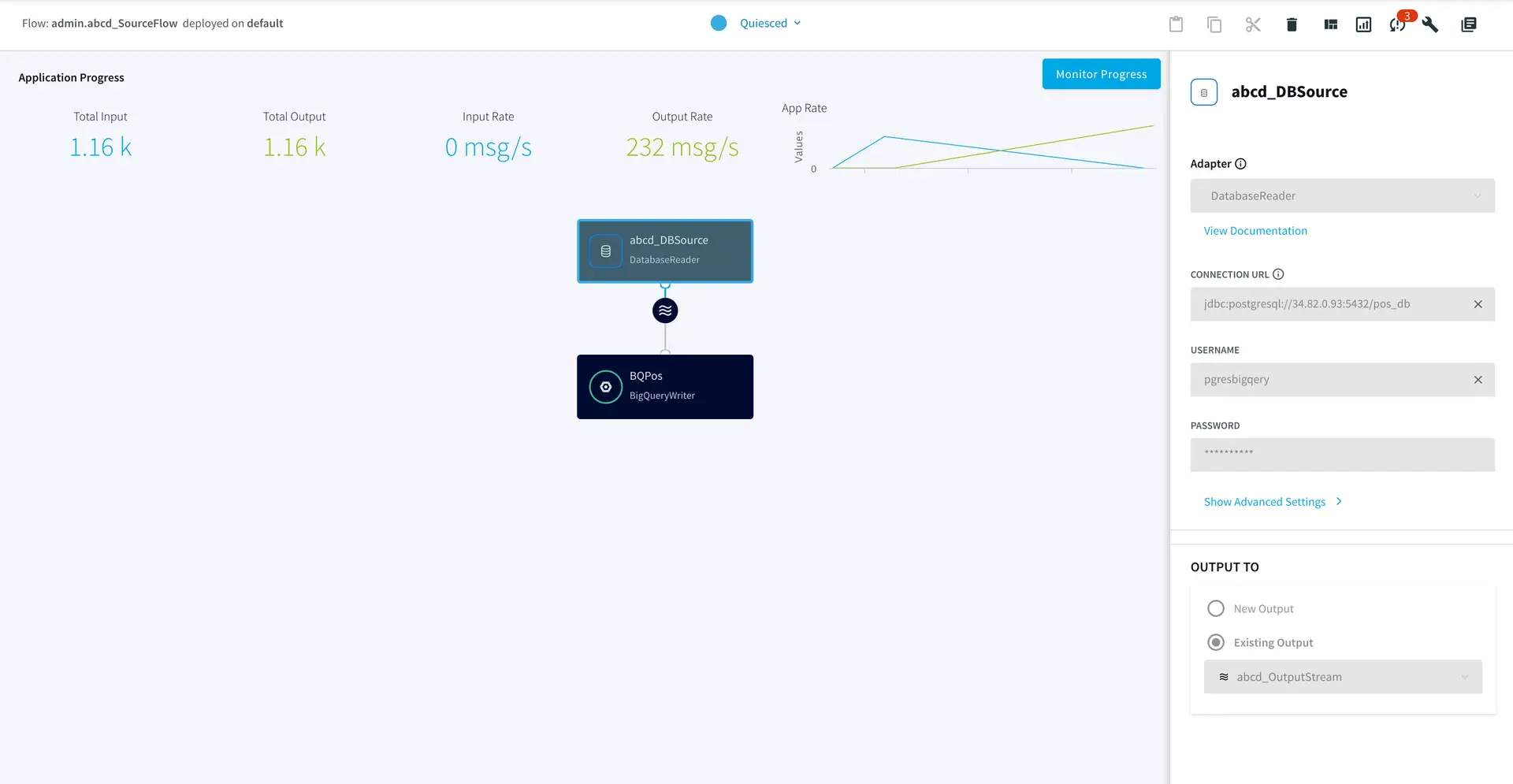
Step 6: Deploy and Run the Striim app for Fast Data Migration
In this section you will deploy and run the final app to visualize the power of Change Data Capture in Striim’s next generation technology.
Setting up the Postgres to BigQuery Streaming App
Step 1: Follow the recipe to configure your jump server and SSh tunnel to Striim cloud.
Step 2: Set up your Postgres Source and BigQuery Target.
Step 3: Create Postgres to BQ Striim app using wizard as shown in the recipe
Step 4: Migrate your data from source to Target by deploying your striim app
Wrapping Up: Start Your Free Trial
Our tutorial showed you how easy it is to migrate data from PostgreSQL to Google BigQuery, a leading cloud data warehouse. By constantly moving your data into BigQuery, you could now start building analytics or machine
learning models on top, all with
minimal impact to your current systems. You could also start ingesting and normalizing more datasets with Striim to fully take advantage of your data when combined with the power of BigQuery.
As always, feel free to reach out to our integration experts to schedule a demo, or try Striim for free here.
Tools you need
Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.
Google BigQuery
BigQuery is a serverless, highly scalable multicloud data warehouse.
Google Compute Engine
Google Compute Engine offers a scalable number of Virtual Machines. In this use case a VM instance will serve as jump host for SSH tunneling
Real-Time Hotspot Detection For Transportation with Striim and BigQuery
Detect and visualize cab booking hotspots using Striim and BigQuery
Benefits
Analyze Real-Time Operational DataStriim facilitates lightning speed data transfer that enables tracking of real-time booking data for strategic decisionsDetect Hotspots in Real TimeWith Striim’s live dashboard millions of data can be processed to capture booking updates at different geographical locationsPerform Real-time Analytics with Fast data replicationWith CDC technology live data from multiple sources can be replicated to the cloud for access across multiple teams for analytics
On this page
Overview
Transportation services like Uber and Lyft require streaming data with real-time processing for actionable insights on a minute-by-minute basis. While batch data can provide powerful insight on medium or long-term trends, in this age live data analytics is an essential component of enterprise decision making. It is said data loses its importance within 30 minutes of generation. To facilitate better performance for companies that hugely depend on live data, Striim offers continuous data ingestion from multiple data sources in real-time. With Striim’s powerful log-based Change Data Capture platform, database transactions can be captured and processed in real-time along with data migration to multiple clouds. This technology can be used by all e-commerce, food-delivery platforms, transportation services, and many others that harnesses real-time analytics to generate value. In this blog, I have shown how real-time cab booking data can be streamed to Striim’s platform and processed in-flight for real-time visualization through Striim’s dashboard and simultaneous data migration to BigQuery at the same time.
Video Walkthrough
Core Striim Components
File Reader: Reads files from disk using a compatible parser.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
Continuous Query : Striim Continuous queries are are continually running SQL queries that act on real-time data and may be used to filter, aggregate, join, enrich, and transform events.
Window: A window bounds real-time data by time, event count or both. A window is required for an application to aggregate or perform calculations on data, populate the dashboard, or send alerts when conditions deviate from normal parameters.
WAction and WActionStore: A WActionStore stores event data from one or more sources based on criteria defined in one or more queries. These events may be related using common key fields.
BigQueryWriter: Striim’s BigQueryWriter writes the data from various supported sources into Google’s BigQuery data warehouse to support real time data warehousing and reporting.
Dashboard: A Striim dashboard gives you a visual representation of data read and written by a Striim application
Using Striim for CDC
Change Data Capture has gained popularity in the last decade as companies have realized the power of real-time data analysis from OLTP databases. In this example, data is acquired from a CSV file and streamed with a window of 30 minutes. Due to memory limitation, the window was kept for 30 minutes for better visualization. Ideally, Striim can handle a window of even 1 second when the amount of data is huge. The data was also processed inside Striim and the change was captured and migrated to BigQuery data warehouse.
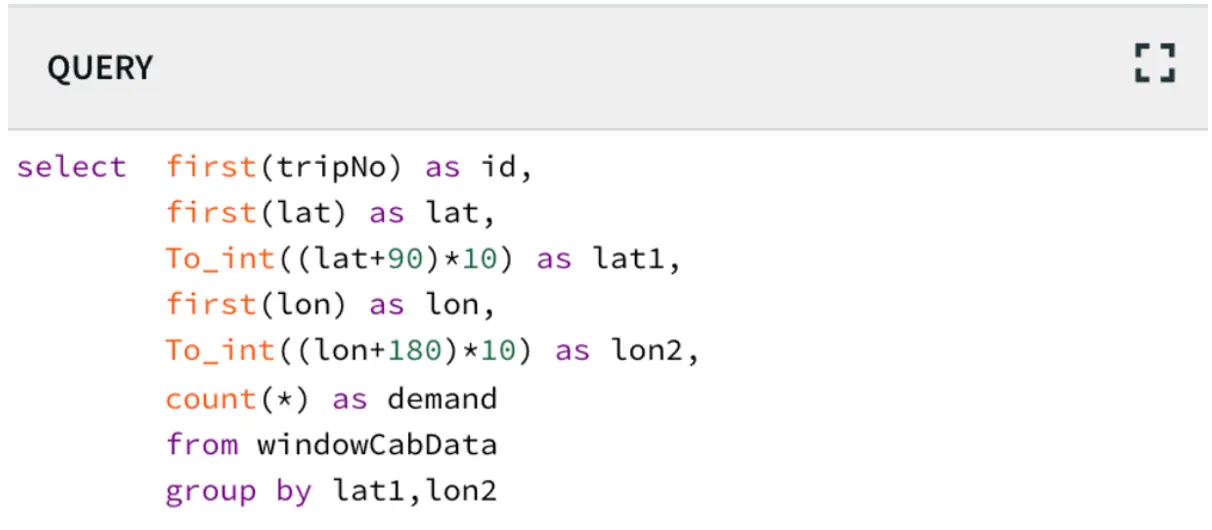
The dataset used in this example contains 4.5 million uber booking data that contains 5 features, DateTime, latitude, longitude, and TLC base company at NYC. The goal is to stream the data through Striim’s CDC platform and detect the areas that have more bookings (hotspots) every 30 minutes. The latitude and longitude value was converted using the following query to cluster them into certain areas
The following steps were followed before deploying the app
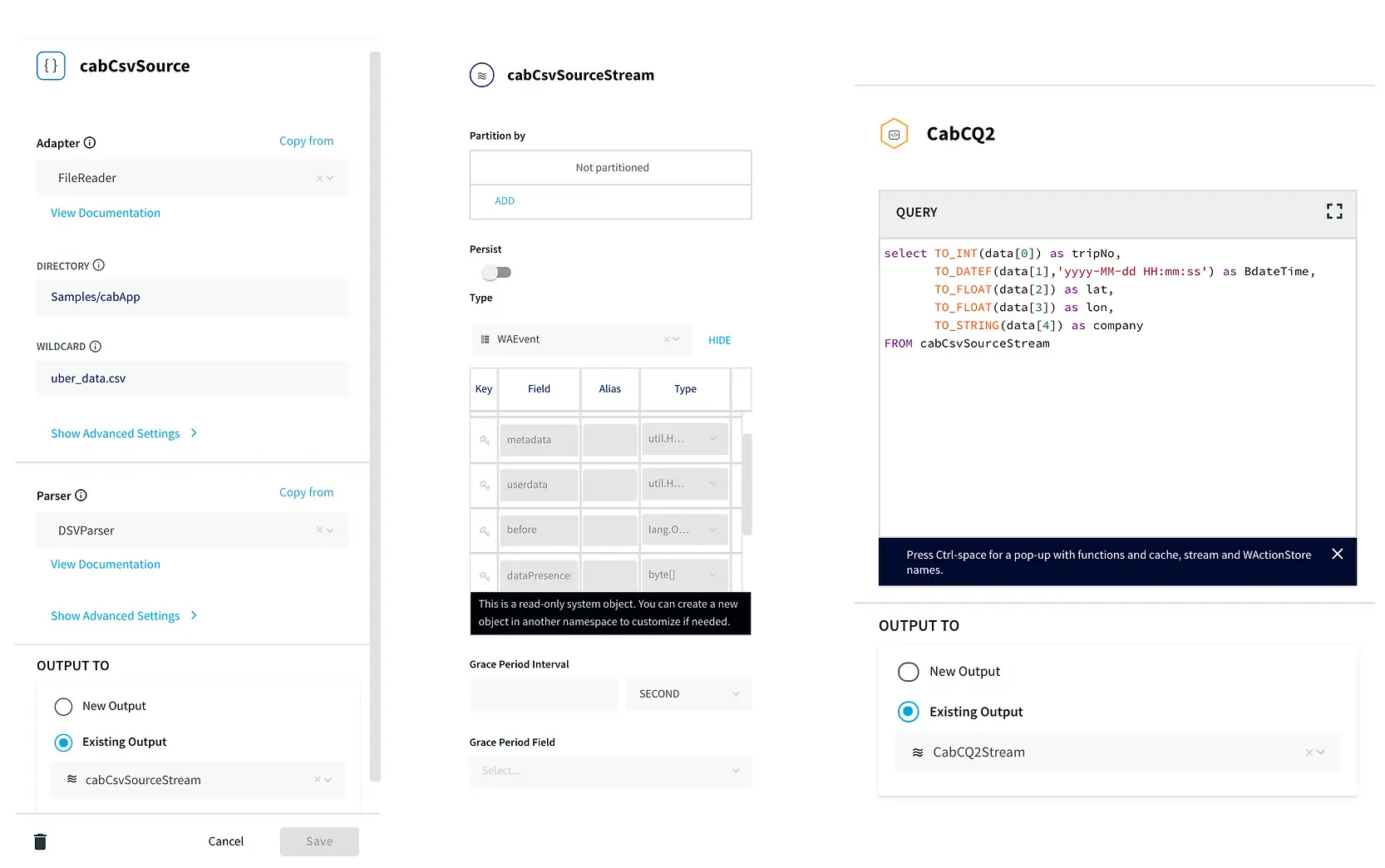
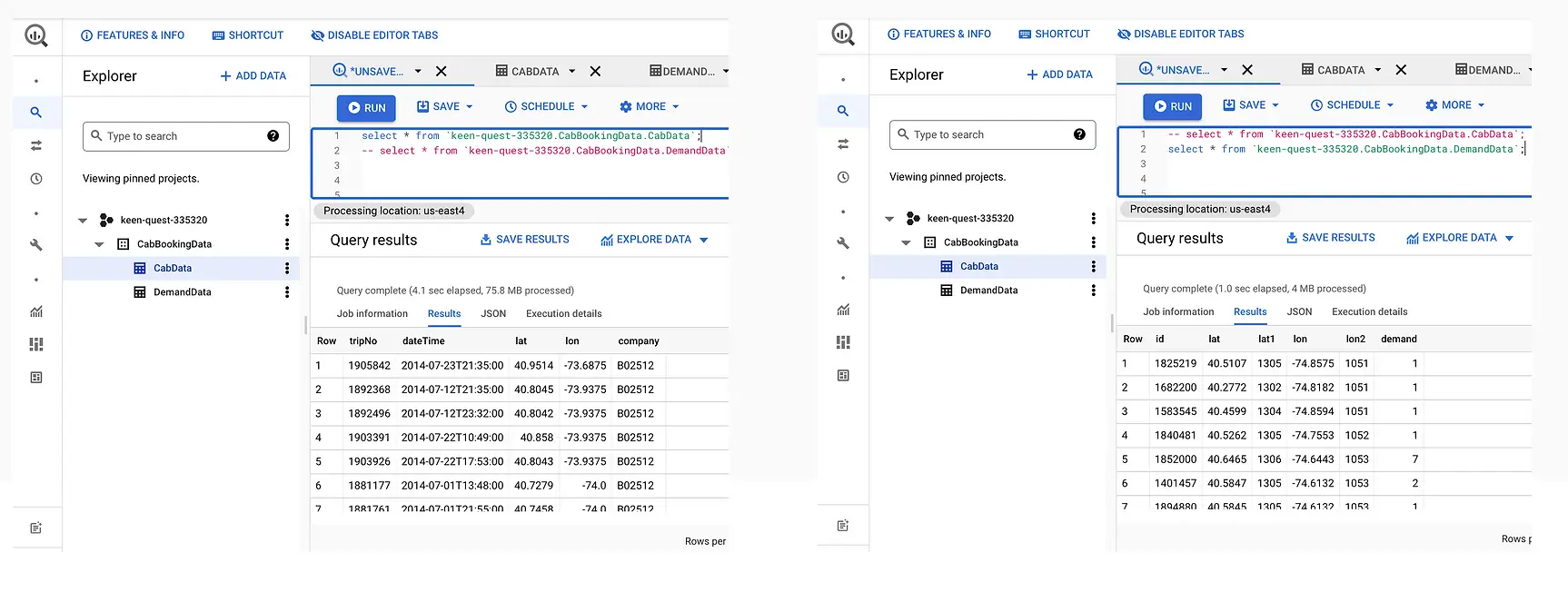
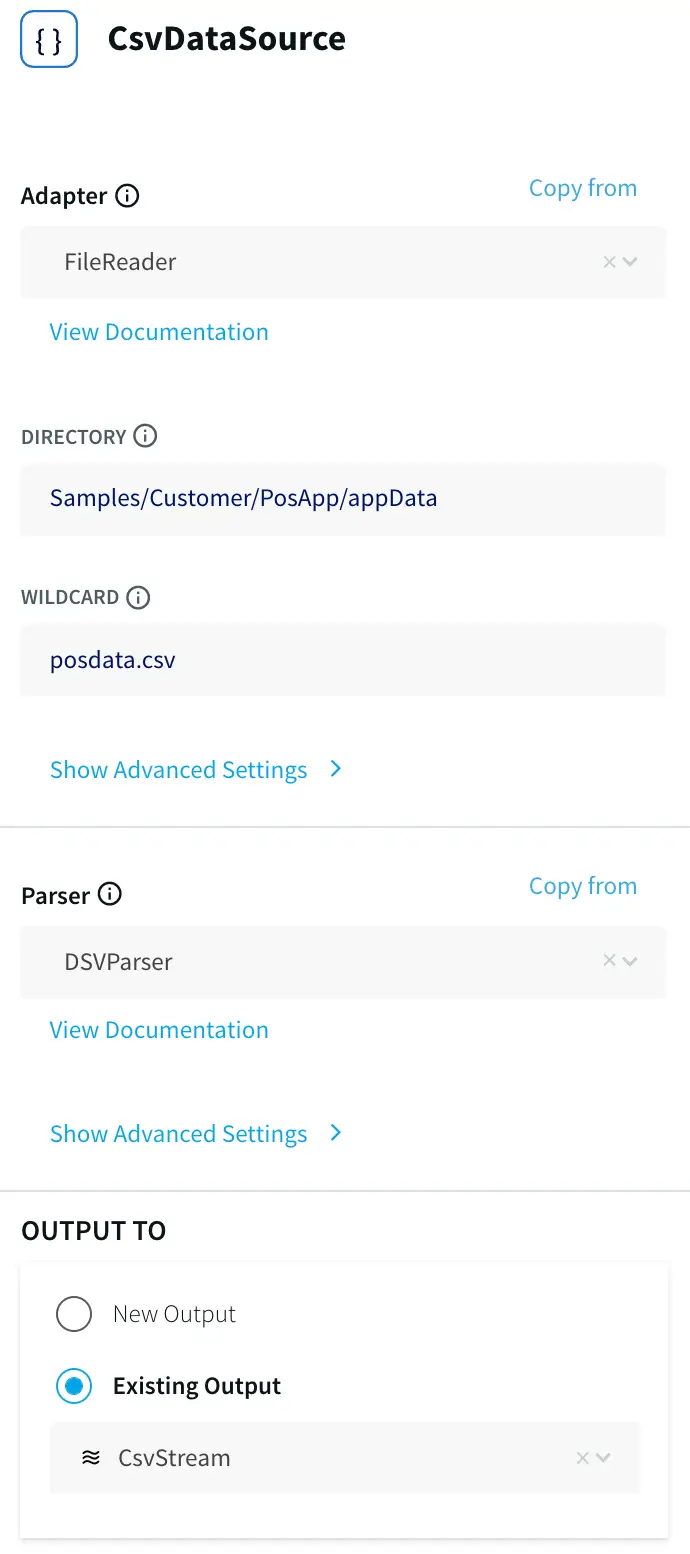
Step 1: Reading Data from CSV and Streaming into Continuous Query through stream
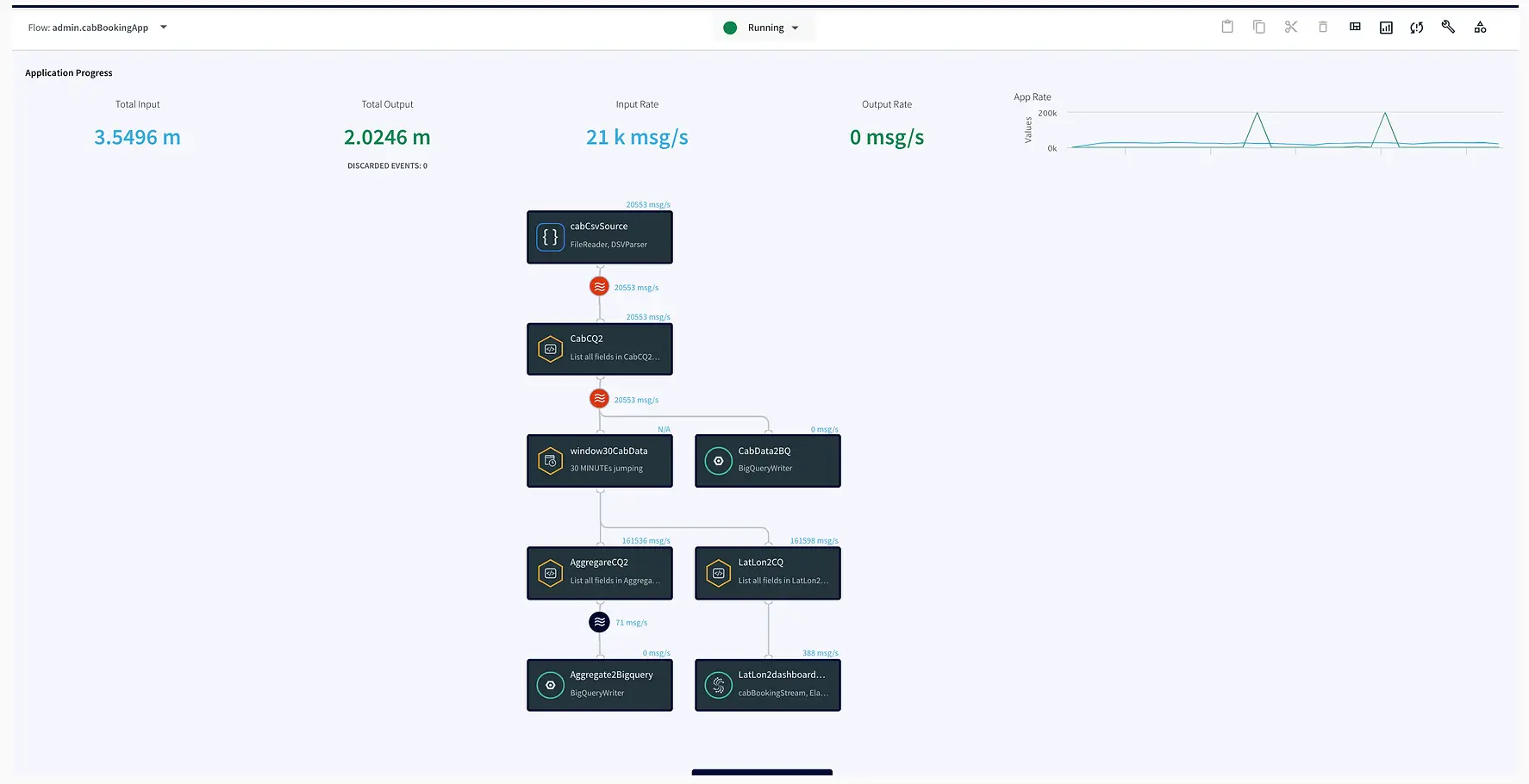
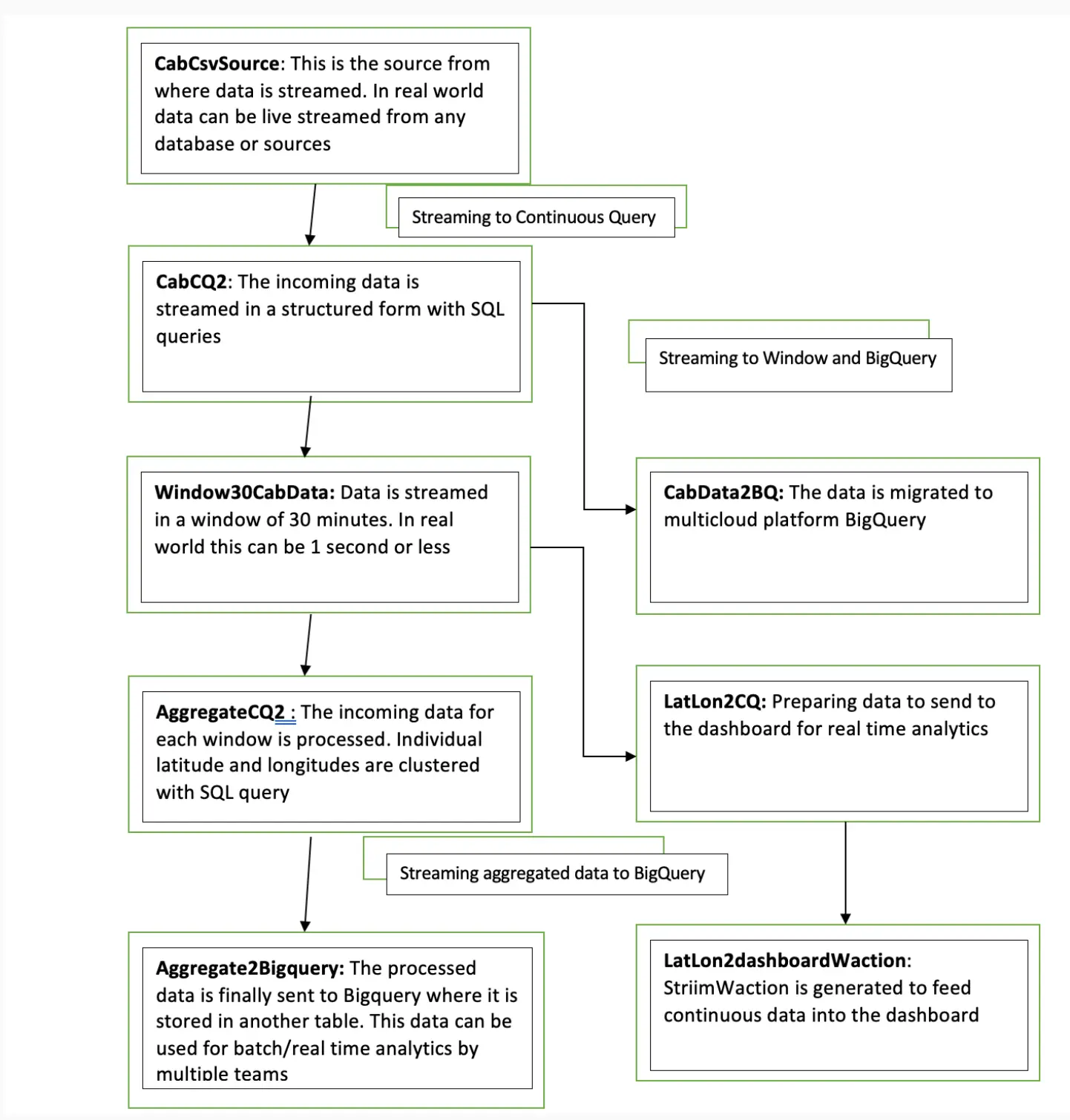
In this step, the data is read from the data source using a delim-separated parser (cabCsvSource) with FileReader adapter used for CSV source. The data is then streamed into cabCSvSourceStream which reaches cabCQ for continuous query. The SQL query at CabCQ2 converts the incoming data into required format
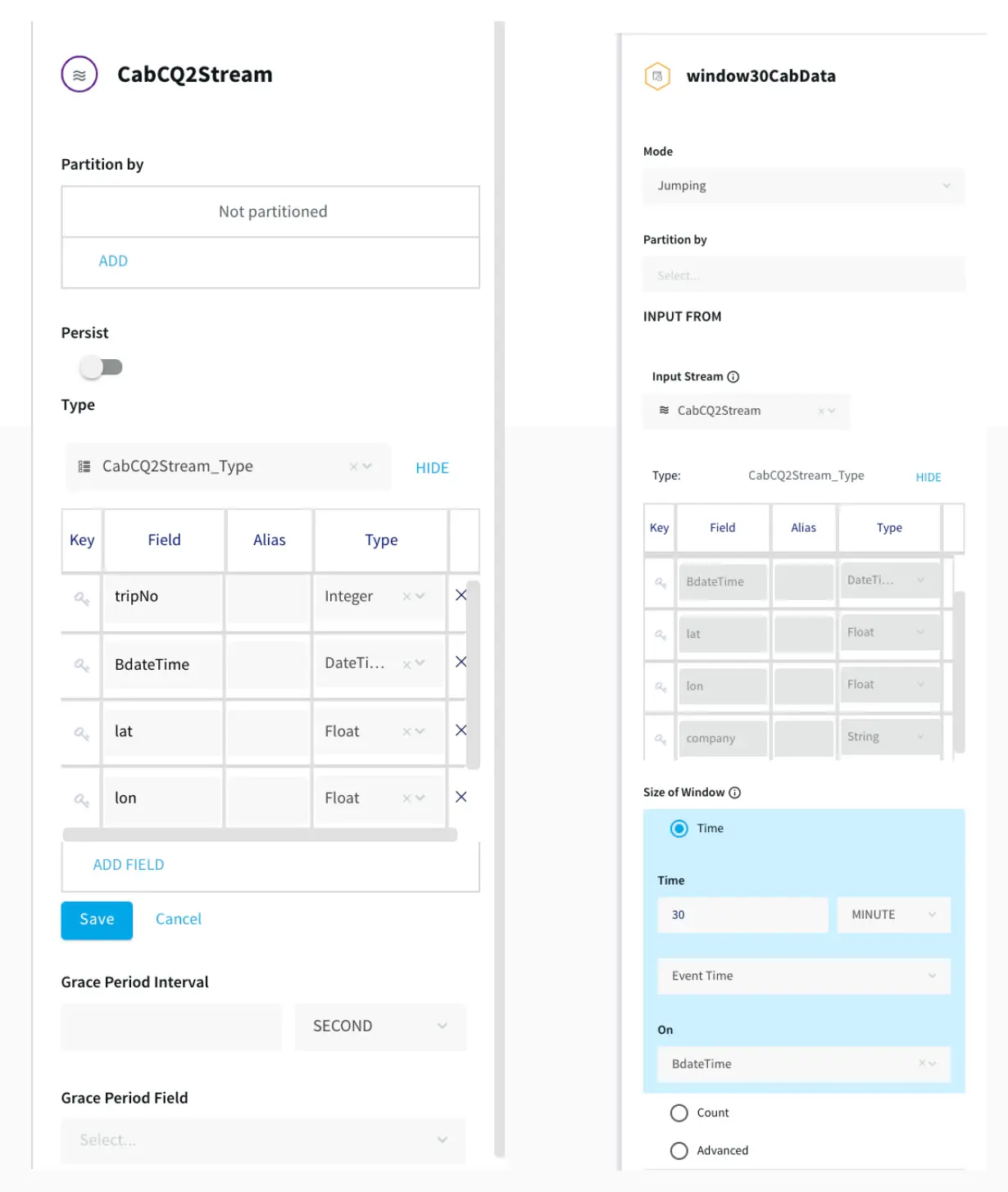
Step 2: Sending the data for processing in Striim as well as into BigQuery
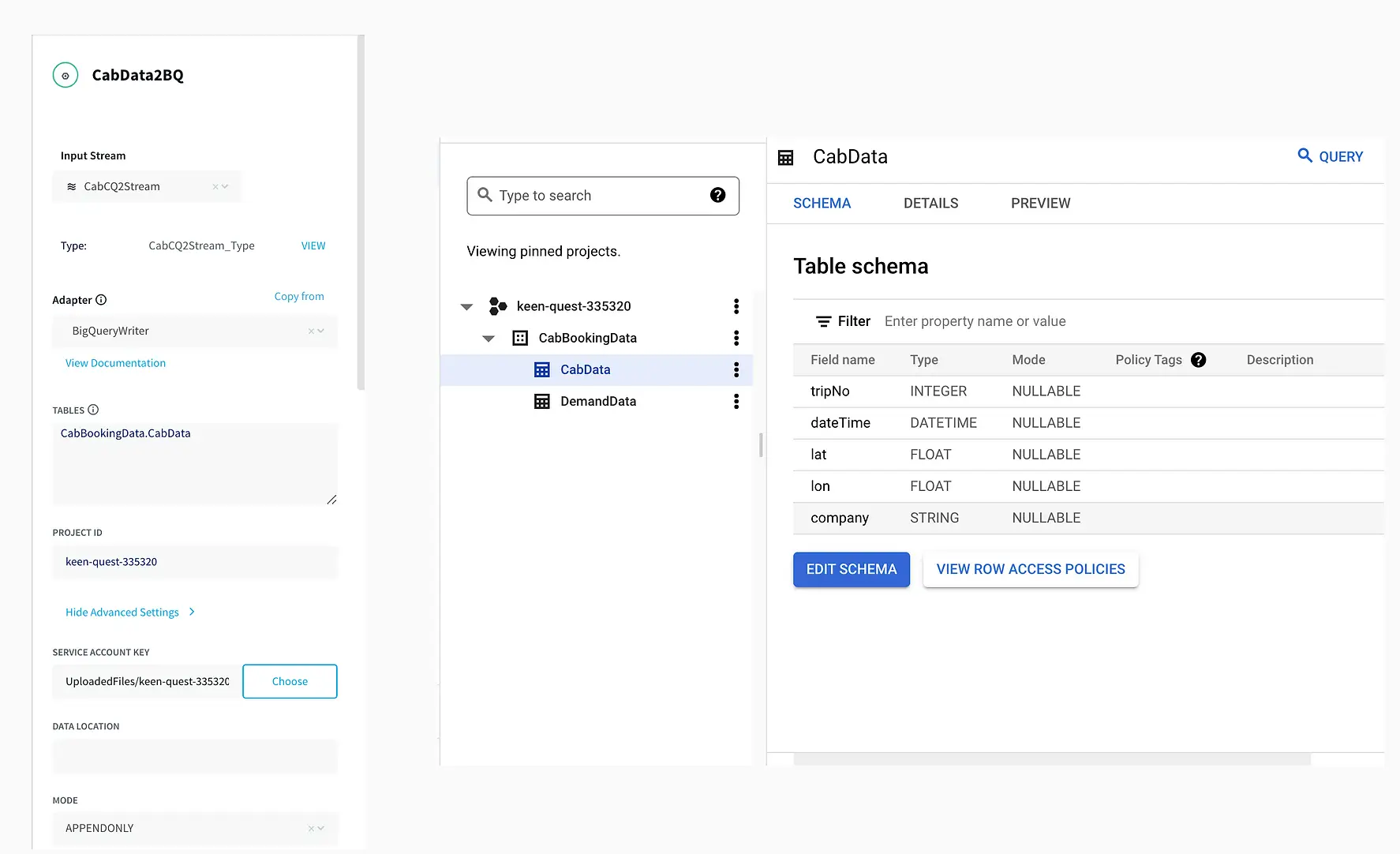
The data returned from the continuous query is then sent for processing through a 30-minute window and also migrated to BigQuery for storage. This is a unique feature of the Striim platform that allows data migration and processing at the same time. The data transferred to Bigquery can be used by various teams for analytics while Striim’s processing gives valuable insights through its dashboard.
The connection between Striim and BigQuery is set up through a service account that allows Striim application to access BigQuery. A table structure is created within BigQuery instance that replicates the schema of incoming stream of data.
Step 3: Aggregating Data using Continuous Query
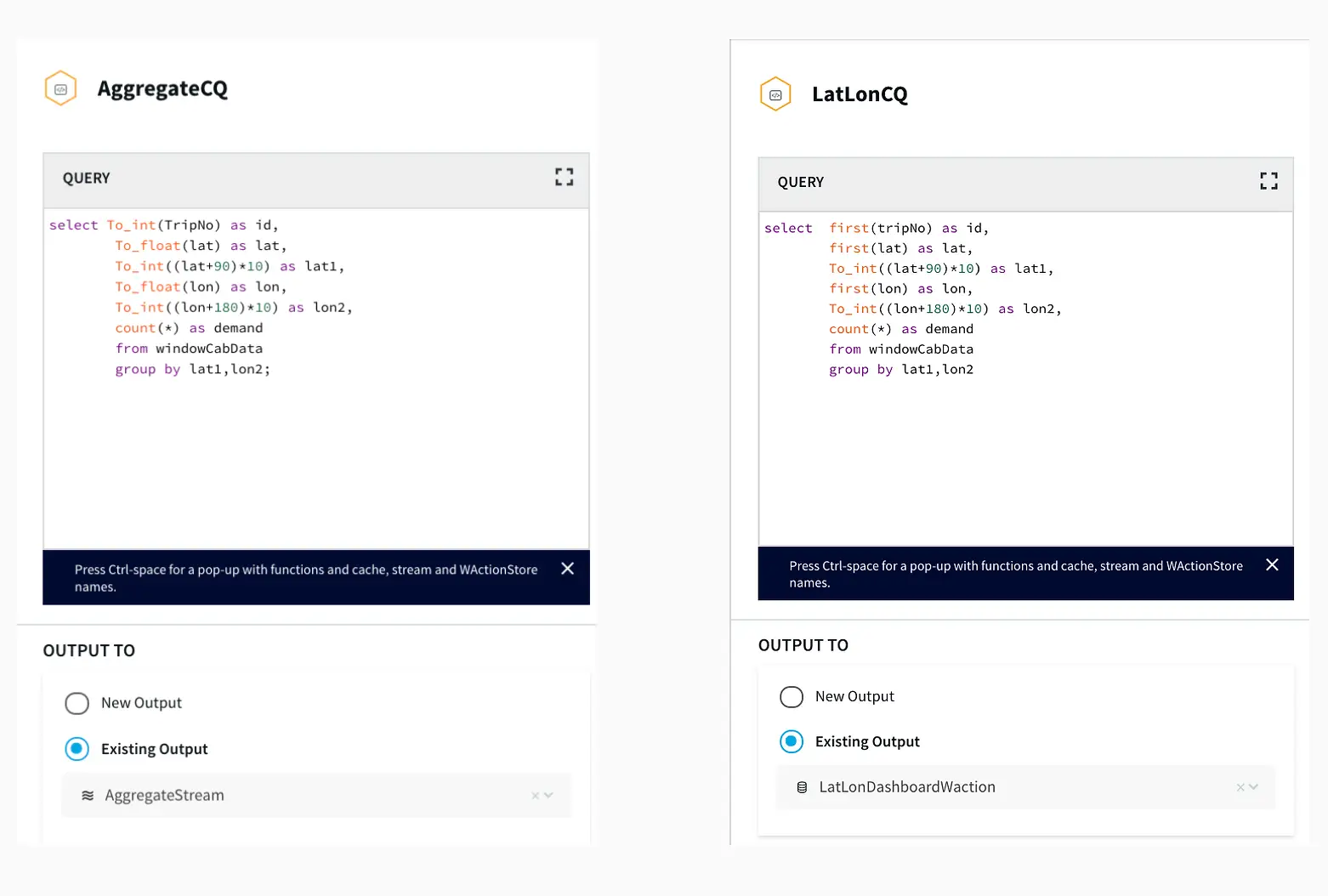
After the data is captured, a query is applied on each window that clusters the latitudes and longitudes of pickup locations into discrete areas and returns the aggregate demand of each area in those 30 minutes. There is a slight difference between the clustering query that goes into BigQuery(AggregateCQ) and the one that goes into StriimWaction(LatLonCQ). The data in StriimWaction is used for dashboard tracking hotspots, so the first latitude and longitude value is taken as the estimate of area. The data that goes into BigQuery returns all latitude longitude values and could be used for further analytics.
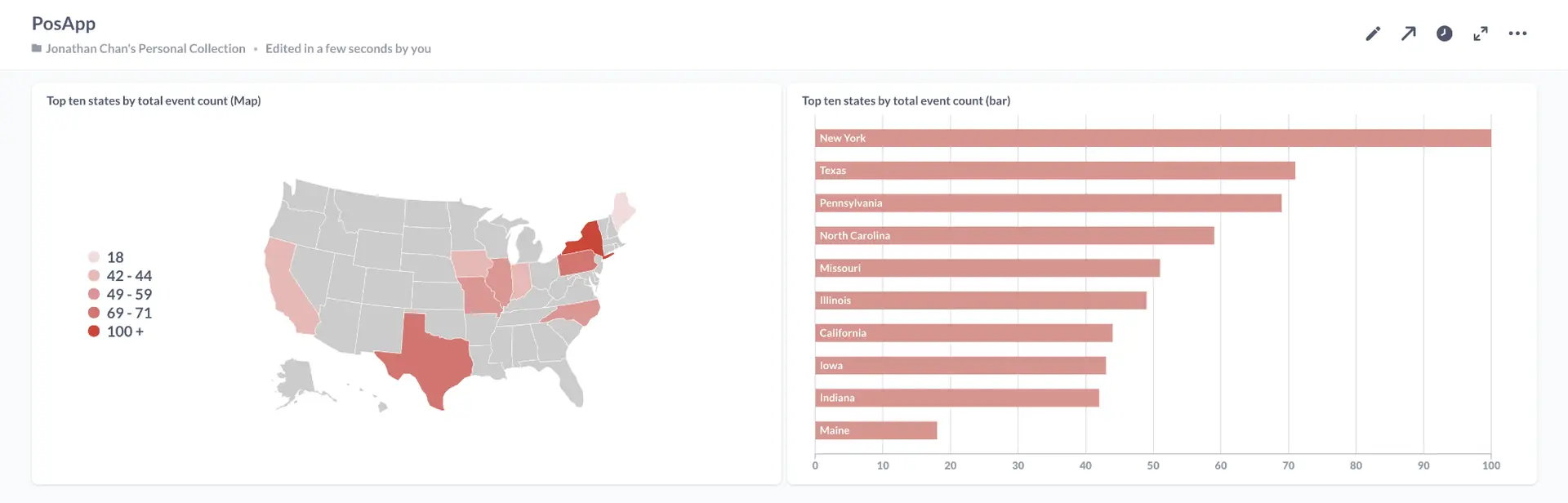
Striim’s Dashboard for Real Time Analytics
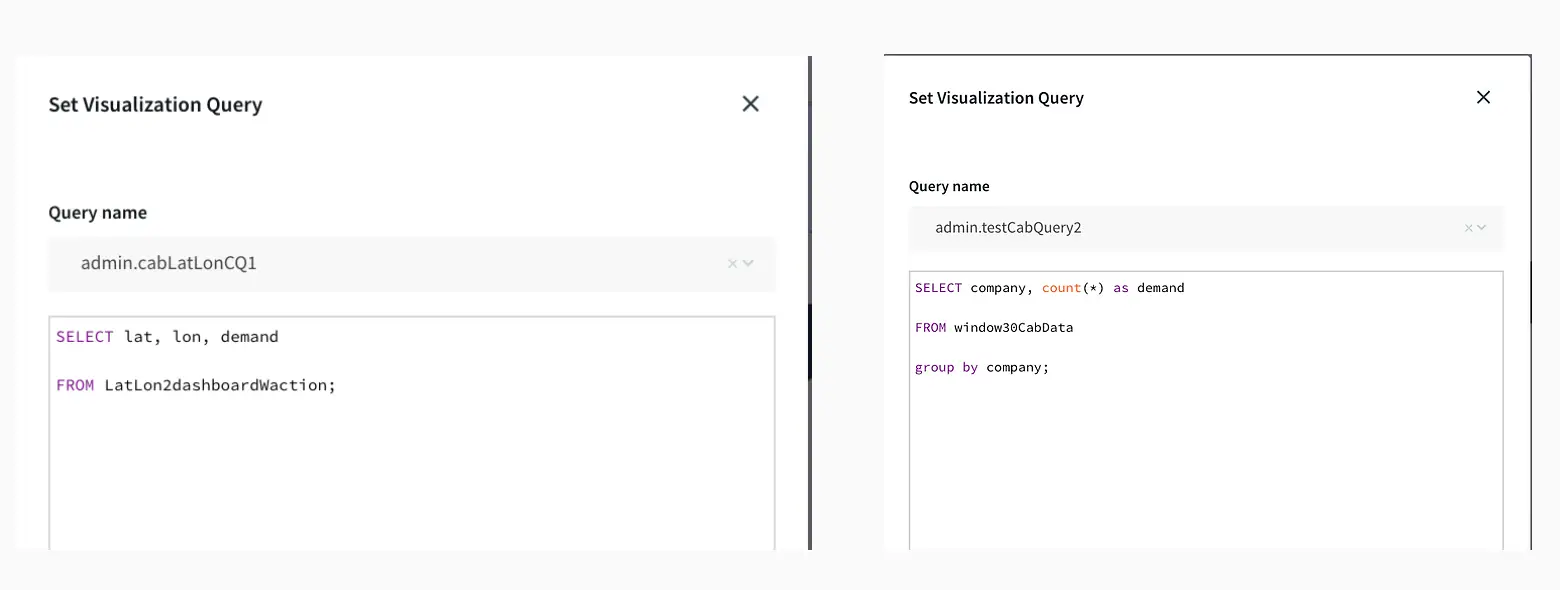
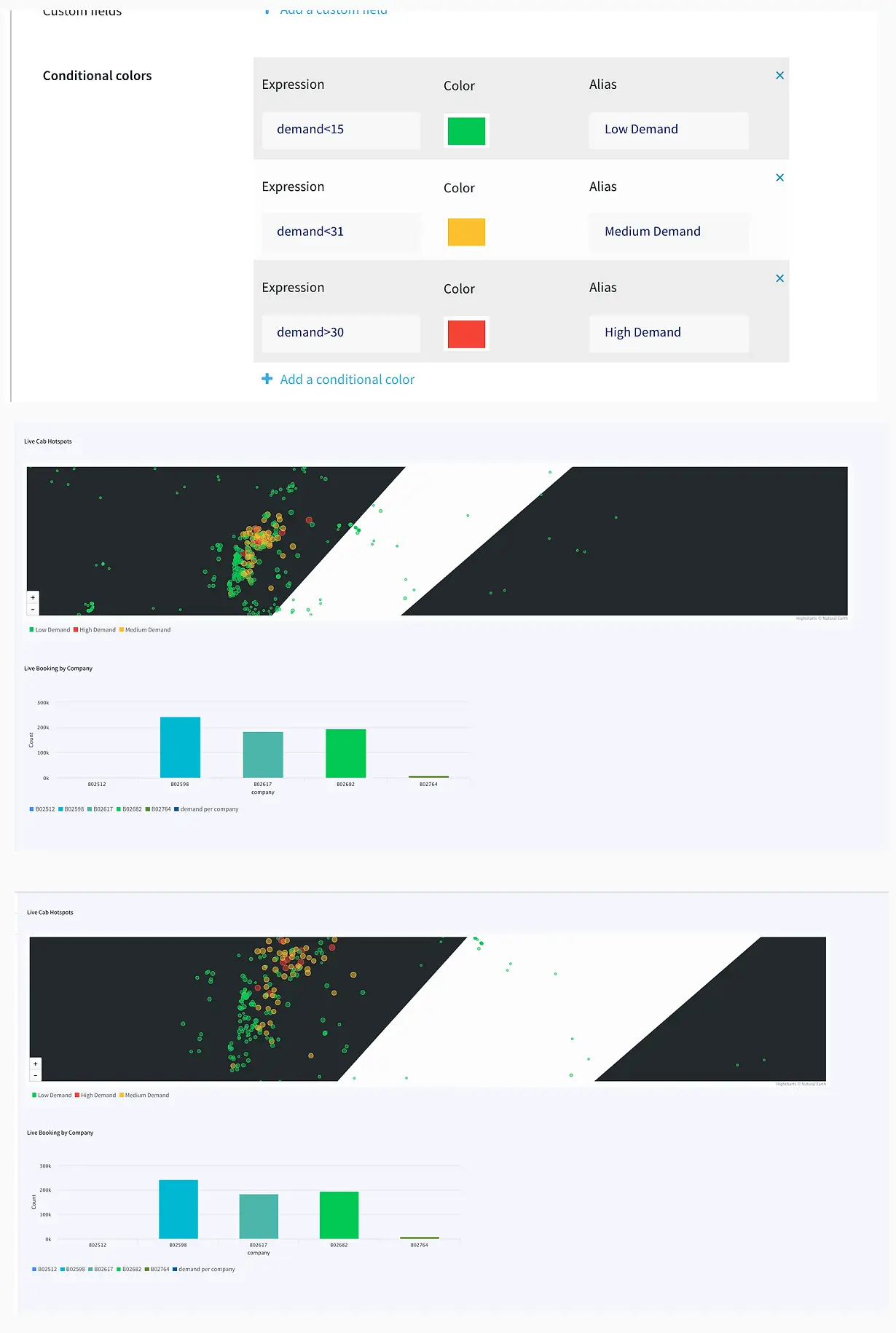
The dashboard ingested data from two different streams. The window30CabData provided data to the bar chart that tracked the number of vehicles from each company every 30 mins and the vector map fetched data from LatLon2dashboardWaction that had the aggregated count of bookings for every area in a 30-minute window. As seen from the dashboard snippet below, the dashboard was configured to return red for high demand (>30), yellow for medium demand (between 15-30), and green for low demand(less than 15). This can be very useful to companies for real-time tracking analytics and data migration. The dashboard has two components, a query where data is fetched from the app and processed as required. The other component is configuration, where specifications on visualization are entered. The SQL queries below show the query for the vector map and bar chart. The two snippets from the dashboard show an instant of booking at different locations and the number of vehicles from each TCL company.
Migrating Data to BigQuery
Finally, the aggregated data along with the source data was migrated to BigQuery. Migration to BigQuery followed the same process of creating a table schema that mirrored the structure of incoming data from Striim.
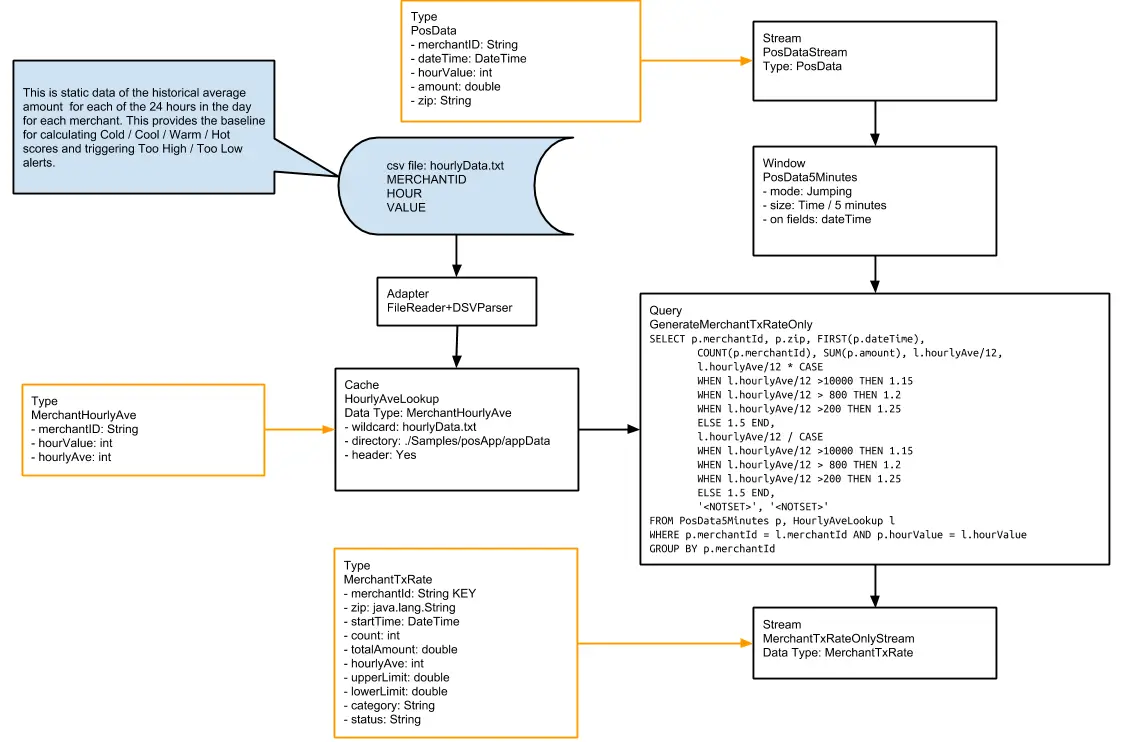
Flowchart
Below is the UI of cabBookingApp that tracks bookings within a given time window and returns aggregated demand in a Striim dashboard. The app also streams data from source to BigQuery .
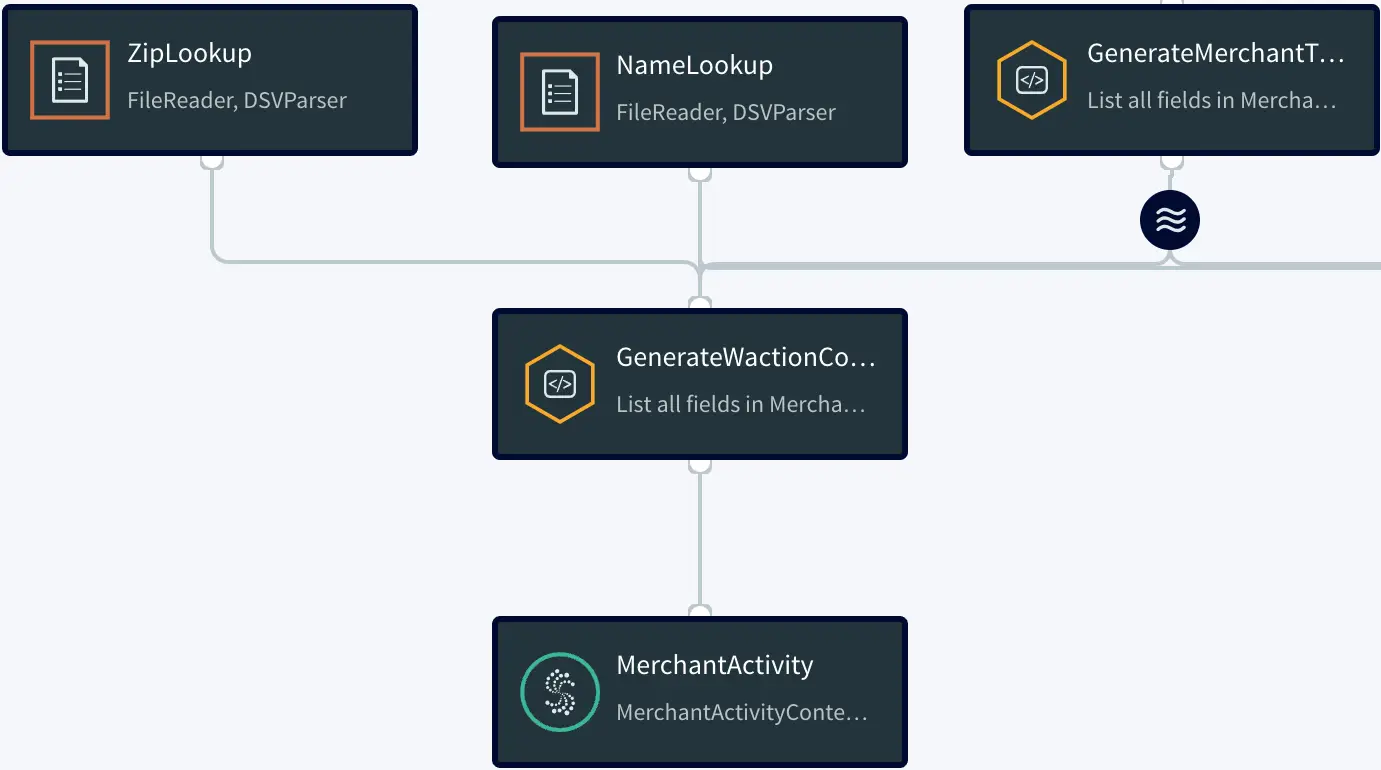
Here is an overview of each component from the flowchart:
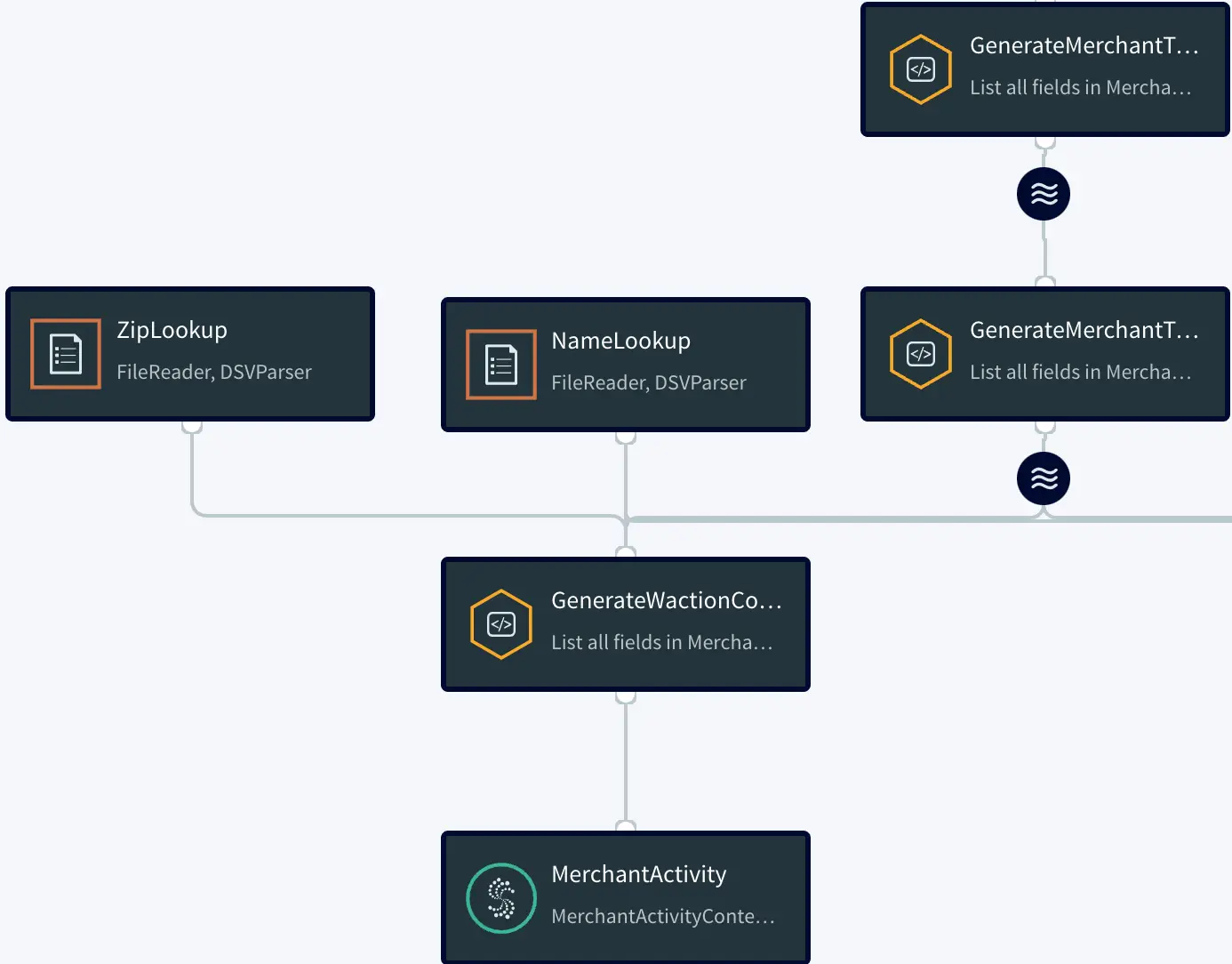
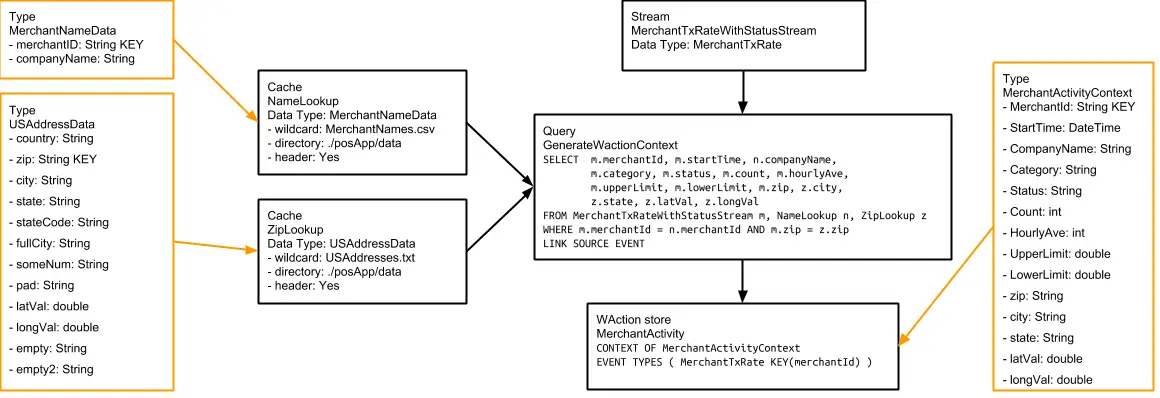
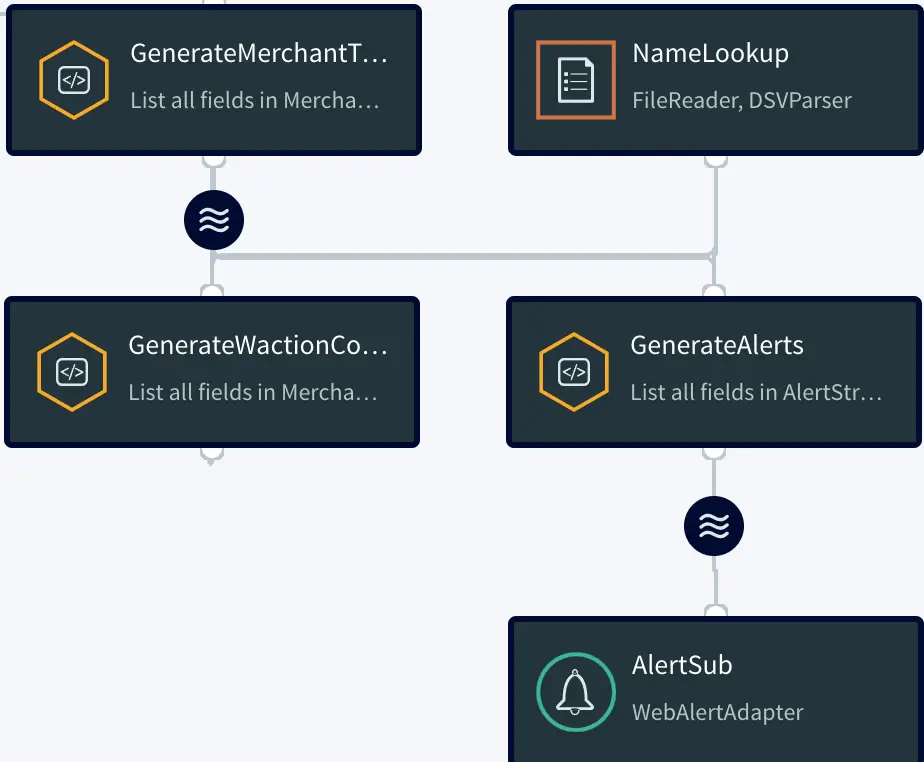
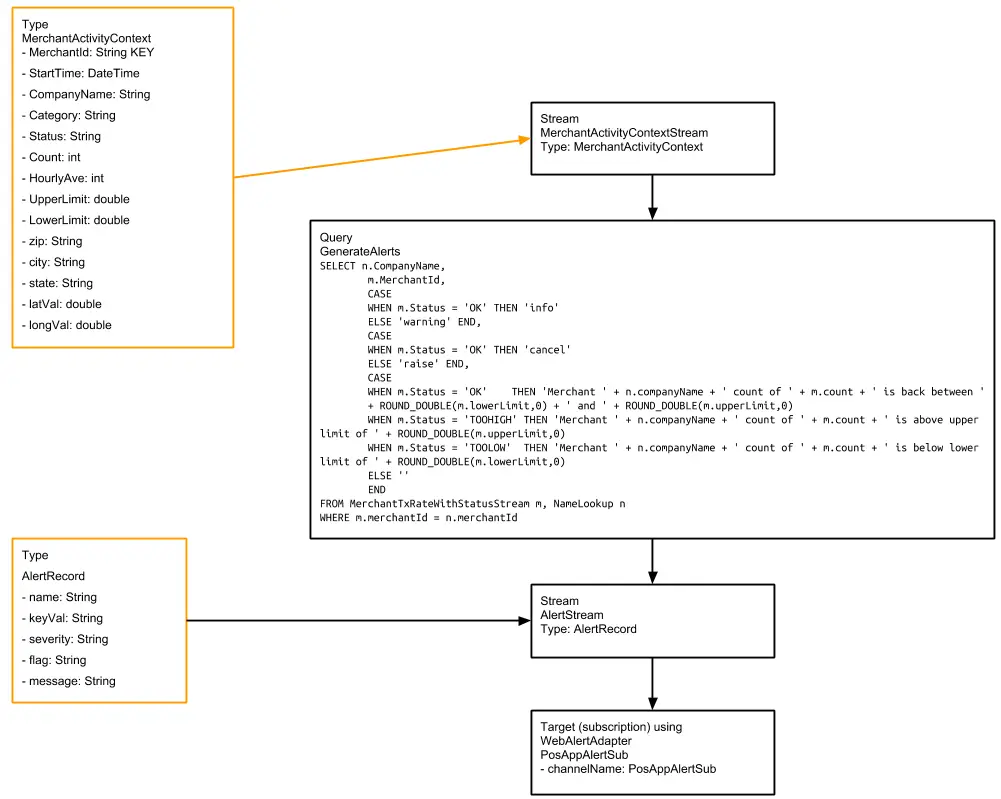
Setting Up the Tracking Application
Step 1: Download the data and Sample TQL file from our github repo
You can download the TQL files for streaming app and lag monitor app from our github repository. Deploy the Striim app on your Striim server.
Step 2: Configure your CSV source and BigQuery target and add it to the source and target components of the app
You can find the csv dataset in our github repo. Set up your BigQuery dataset and table that will act as a target for the streaming application
Step 3: Follow the recipe to create Striim Dashboard for real-time analytics
The recipe gives a detail on how to set up a Striim dashboard for this use case
Step 4: Run your app and dashboard
Deploy and run your app and dashboard for real-time tracking and analytics
Why Striim?
Striim is a single platform for real-time data ingestion, stream processing, pipeline monitoring, and real-time delivery with validation. It uses low-impact Change Data Capture technology to migrate a wide variety of high-volume, high-velocity data from enterprise databases in real-time. Using Striim’s in-flight data processing and real-time dashboard, companies can generate maximum value from streaming data. Enterprises dealing with astronomical data can incorporate Striim to maximize profit with real-time strategic decisions. Striim is used by companies like Google, Macy’s, and Gartner for real-time data migration and analytics. In this data-driven age, generate maximum profit for your company using Striim’s CDC-powered platform.
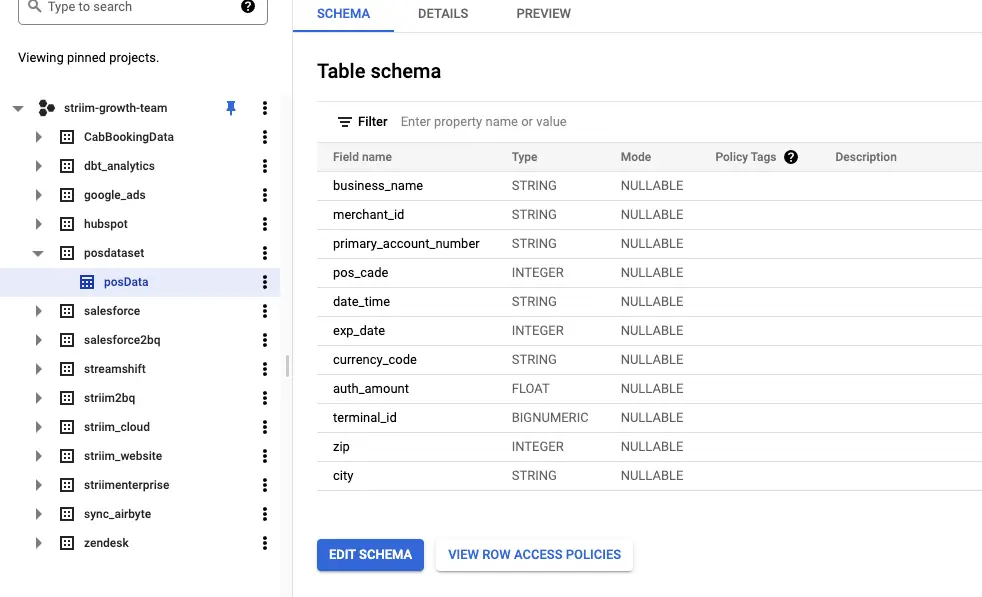
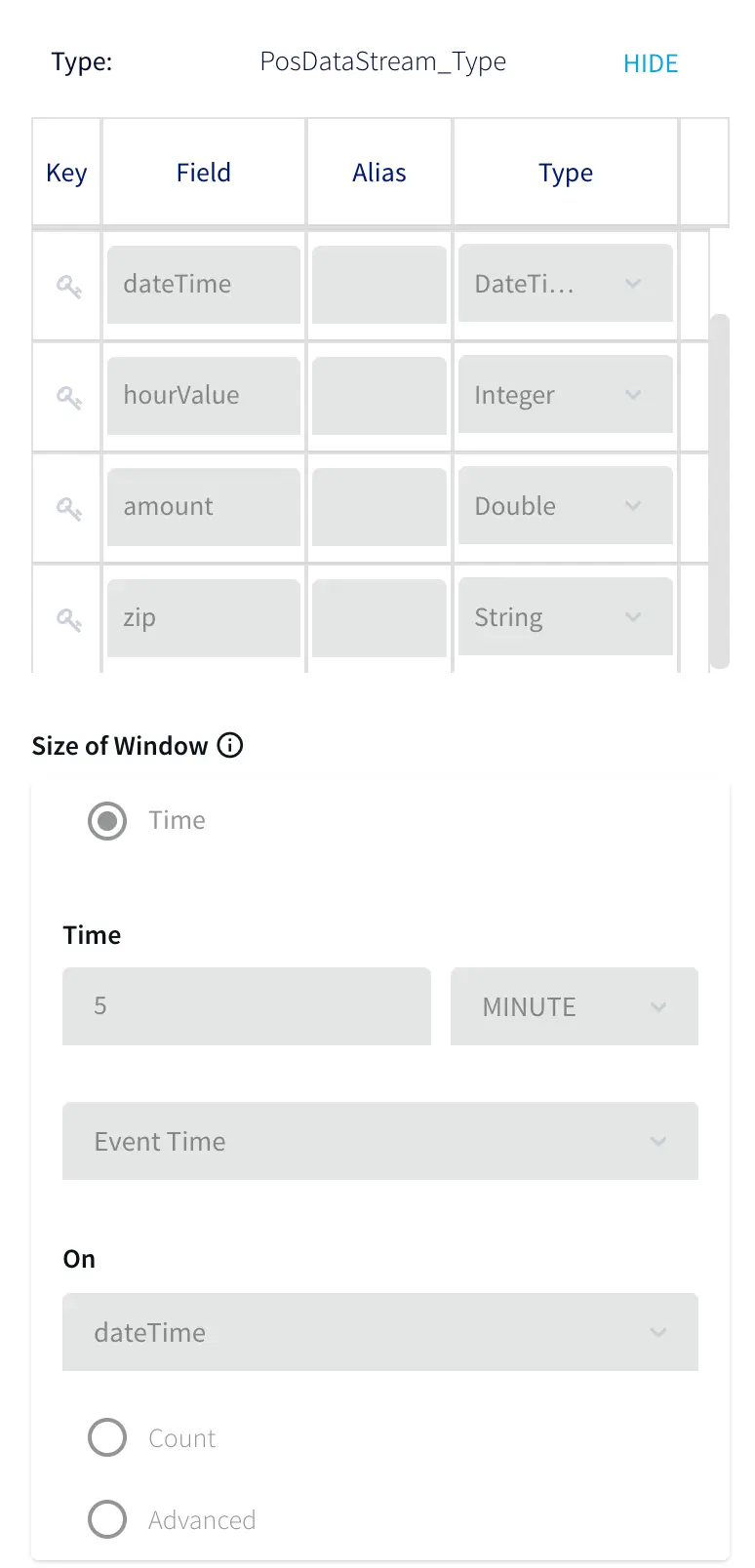
Real-Time Point-of-Sale (POS) Analytics with Striim and BigQuery
How to use Striim to generate transaction reports and send alerts when transaction counts are higher or lower than average
Benefits
Detect Anomalies in Real Time
Generate reports on transaction activity and get alerts when transaction counts deviate from the meanManage Inventory Levels
Monitor your stock levels in real time and get notified when stock is lowGet a Live View of Your Sales
Use POS Analytics to get real-time insights into customer purchases
On this page
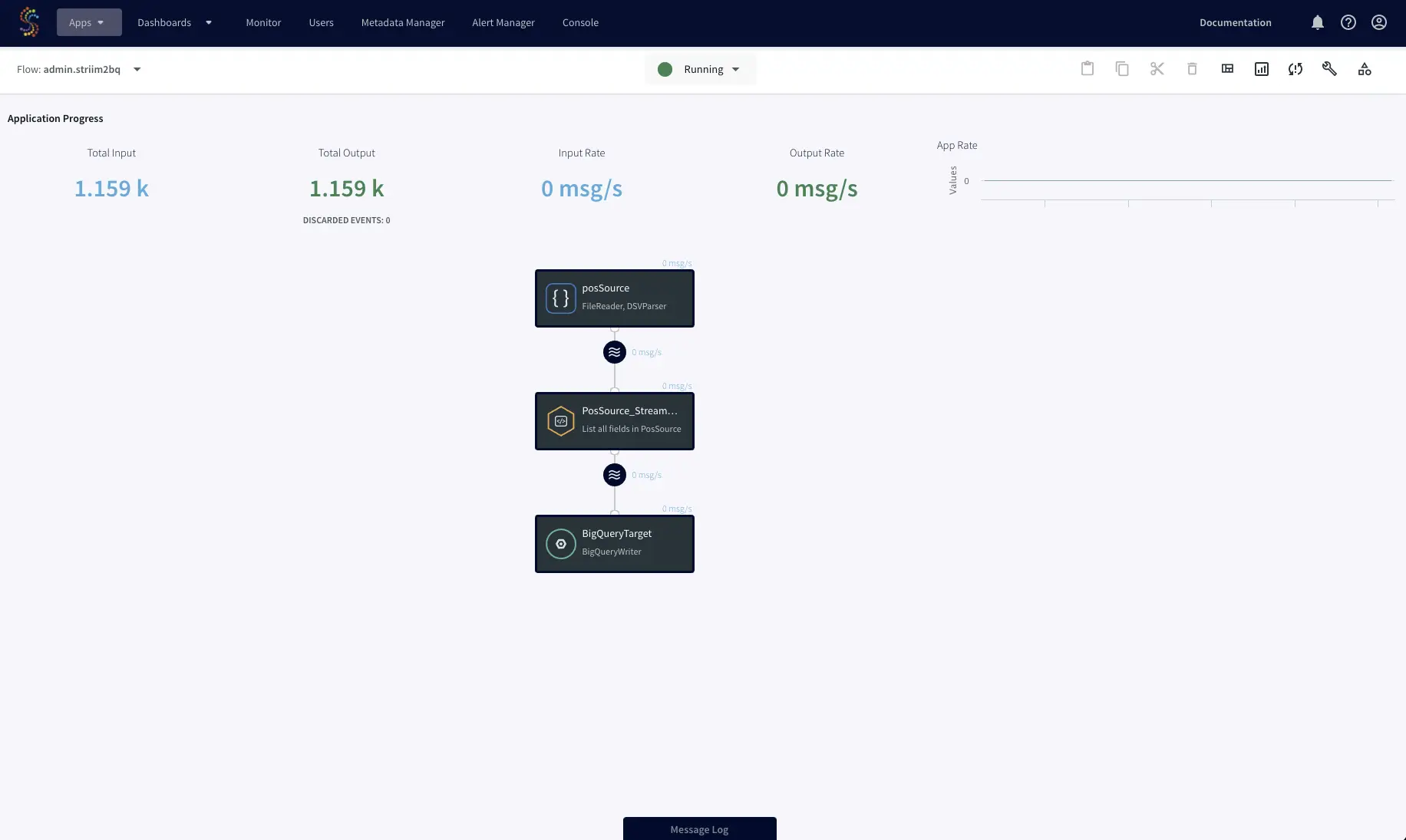
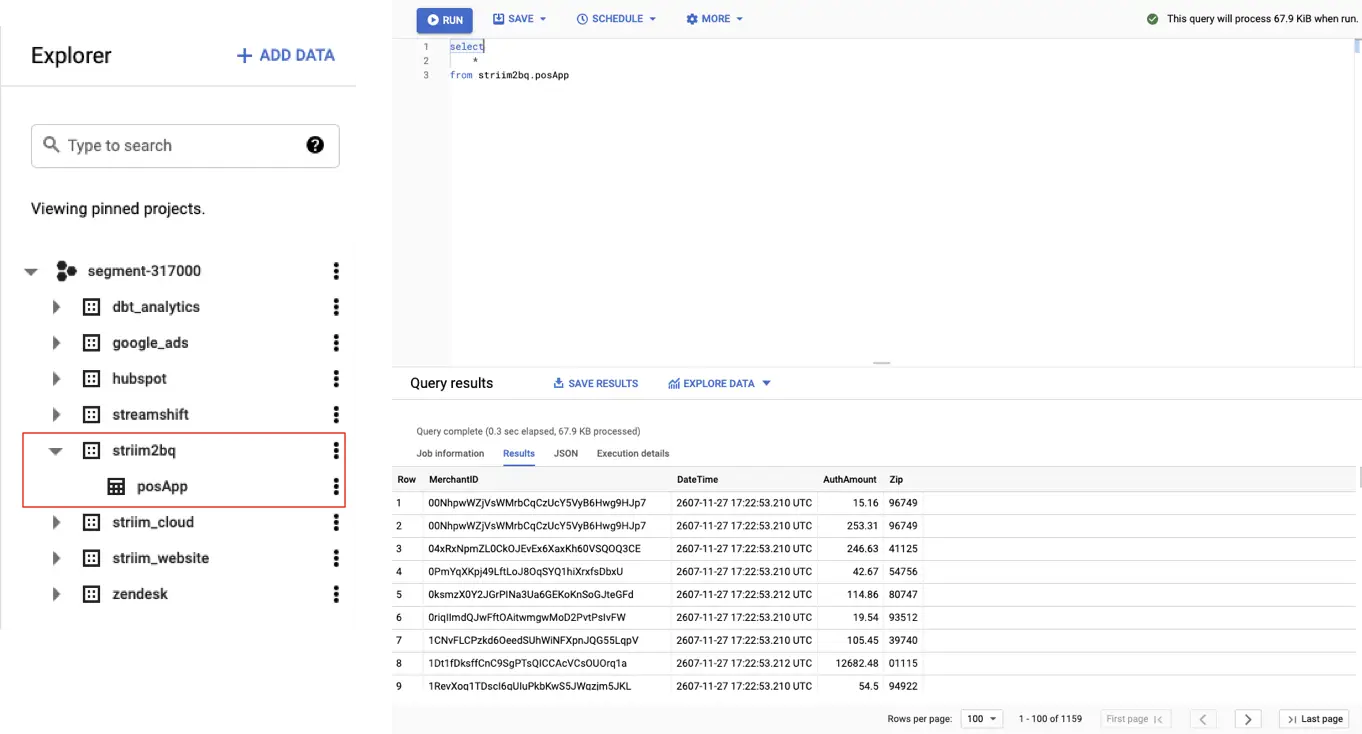
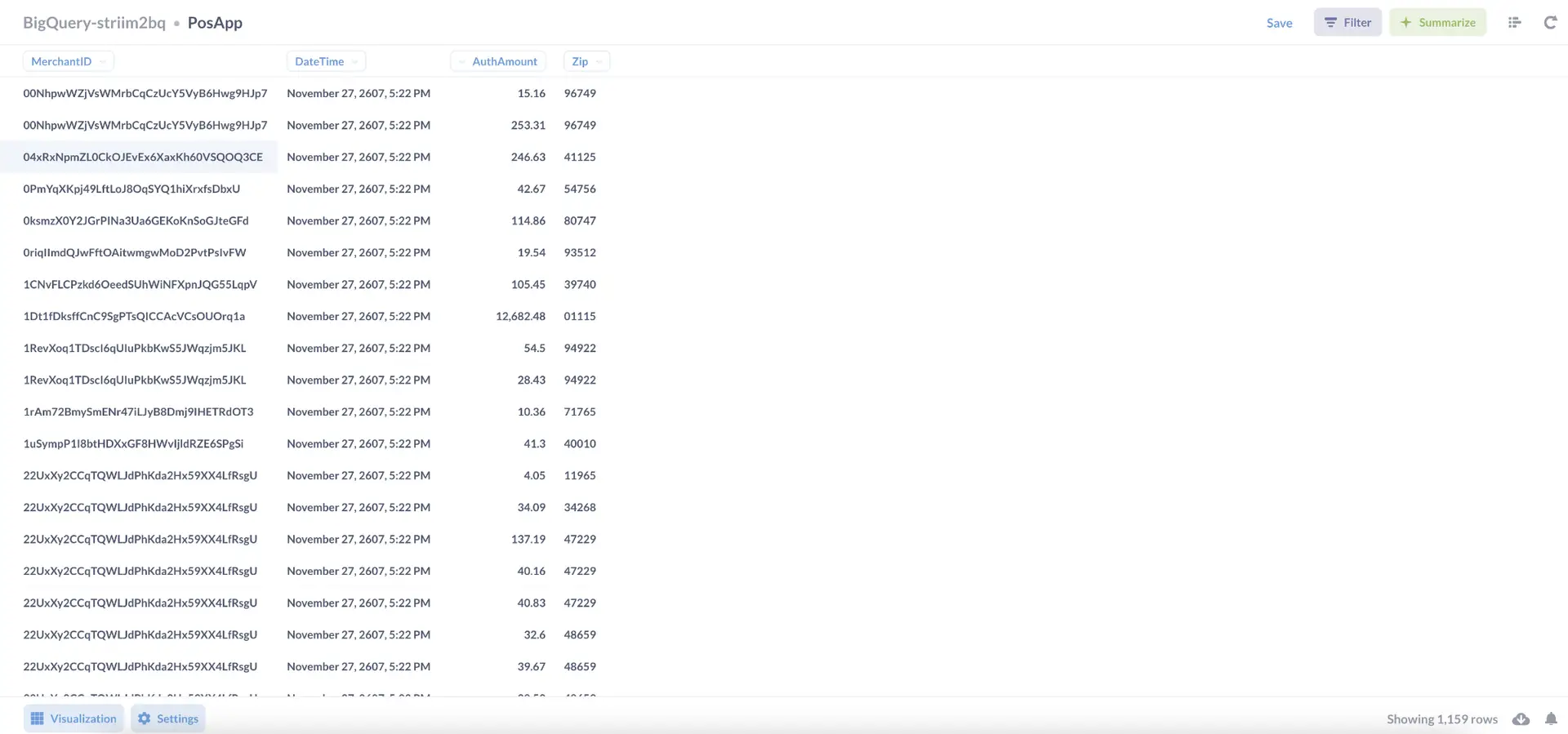
Analyze point-of-sale retail data in real-time with Striim, BigQuery, and the BI tool of your choice.
Streaming Change Data Capture – Striim
Streaming Data Pipelines in SQL – Striim
Streaming Data Visualiztion – Striim
Cloud Data Warehouse with incremental views – BigQuery
Reporting & BI – Metabase
Overview
Before following the instructions below, sign up for Striim Developer to run through this tutorial (no credit card required).
In the web UI, from the top menu, select Apps > View All Apps.
If you don’t see PosApp anywhere on the page (you may need to expand the Samples group) , download the TQL from Striim’s GitHub page. select Create App > Import TQL file, navigate to Striim/Samples/PosApp, double-click PosApp.tql, enter Samples as the namespace, and click Import.
At the bottom right corner of the PosApp tile, select … > Manage Flow. The Flow Designer displays a graphical representation of the application flow:
The following is simplified diagram of that flow:
Step 1: Acquire Data
Striim has hundreds of connectors including change data capture from databases such as Oracle, SQLServer, MySQL, and PostgreSQL.
In this example, we’ll use a simple file source. We call this a ‘Source’ component in Striim.
Double-clicking CsvDataSource opens it for editing:
This is the primary data source for this application. In a real-world application, it would be real-time data. Here, the data comes from a comma-delimited file, posdata.csv. Here are the first two lines of that file:
BUSINESS NAME,MERCHANT ID,PRIMARY ACCOUNT NUMBER,POS DATA CODE,DATETIME,EXP DATE,CURRENCY CODE,AUTH AMOUNT,TERMINAL ID,ZIP,CITY,COMPANY
1,D6RJPwyuLXoLqQRQcOcouJ26KGxJSf6hgbu,6705362103919221351,0,20130312173210,0916,USD,2.20,5150279519809946,41363,Quicksand
In Striim terms, each line of the file is an event, which in many ways is comparable to a row in a SQL database table, and and can be used in similar ways. Click Show Advanced Settings to see the DSVParser properties:
The True setting for the header property indicates that the first line contains field labels that are not to be treated as data.
The “Output to” stream CsvStream automatically inherits the WAEvent type associated with the CSVReader:
The only field used by this application is “data”, an array containing the delimited fields.
Step 2: Filter The Data Stream
CsvDataSource outputs the data to CsvStream, which is the input for the query CsvToPosData:
This CQ converts the comma-delimited fields from the source into typed fields in a stream that can be consumed by other Striim components. Here, “data” refers to the array mentioned above, and the number in brackets specifies a field from the array, counting from zero. Thus data[1] is MERCHANT ID,
data[4] is DATETIME, data[7] is AUTH AMOUNT, and data[9] is ZIP.
TO_STRING, TO_DATEF, and TO_DOUBLE functions cast the fields as the types to be used in the Output to stream. The DATETIME field from the source is converted to both a dateTime value, used as the event
timestamp by the application, and (via the DHOURS function) an integer hourValue, which is used to look up historical hourly averages from the HourlyAveLookup cache, discussed below.
The other six fields are discarded. Thus the first line of data from posdata.csv has at this point been code-reduced to five values:
D6RJPwyuLXoLqQRQcOcouJ26KGxJSf6hgbu (merchantId)
20130312173210 (DateTime)
17 (hourValue)
2.20 (amount)
41363 (zip)
The CsvToPosDemo query outputs the processed data to PosDataStream:
PosDataStream assigns the five remaining fields the names and data types in the order listed above:
PRIMARY ACCOUNT NUMBER to merchantID
DATETIME to dateTime
the DATETIME substring to hourValue
AUTH AMOUNT to amount
ZIP to zip
Step 3: Define the Data Set
PosDataStream passes the data to the window PosData5Minutes:
A window is in many ways comparable to a table in a SQL database, just as the events it contains are comparable to rows in a table. The Mode and Size settings determine how many events the window will contain and how it will be refreshed. With the Mode set to Jumping, this window is refreshed with a
completely new set of events every five minutes. For example, if the first five-minute set of events received when the application runs from 1:00 pm through 1:05 pm, then the next set of events will run from 1:06 through 1:10, and so on. (If the Mode were set to Sliding, the window continuously add new
events and drop old ones so at to always contain the events of the most recent five minutes.)
Step 4: Process and Enhance the Data
The PosData5Minutes window sends each five-minute set of data to the GenerateMerchantTxRateOnly query. As you can see from the following schema diagram, this query is fairly complex:
The GenerateMerchantTxRateOnly query combines data from the PosData5Minutes event stream with data from the HourlyAveLookup cache. A cache is similar to a source, except that the data is static rather than real-time. In the real world, this data would come from a periodically updated table in the
payment processor’s system containing historical averages of the number of transactions processed for each merchant for each hour of each day of the week (168 values per merchant). In this sample application, the source is a file, hourlyData.txt, which to simplify the sample data set has only 24 values
per merchant, one for each hour in the day.
For each five-minute set of events received from the PosData5Minutes window, the GenerateMerchantTxRateOnly query ouputs one event for each merchantID found in the set to MerchantTxRateOnlyStream, which applies the MerchantTxRate type. The easiest way to summarize what is happening in the above diagram
is to describe where each of the fields in the MerchantTxRateOnlySteam comes from:
field
description
TQL
merchantId
the merchantID field from PosData5Minutes
SELECT p.merchantID
zip
the zip field from PosData5Minutes
SELECT … p.zip
startTime
the dateTime field for the first event for the merchantID in the five-minute set from PosData5Minutes
SELECT … FIRST(p.dateTime)
count
count of events for the merchantID in the five-minute set from PosData5Minutes
SELECT … COUNT(p.merchantID)
totalAmount
sum of amount field values for the merchantID in the five-minute set from PosData5Minutes
SELECT … SUM(p.amount)
hourlyAve
the hourlyAve value for the current hour from HourlyAveLookup, divided by 12 to give the five-minute average
SELECT … l.hourlyAve/12 …
WHERE … p.hourValue = l.hourValue
upperLimit
the hourlyAve value for the current hour from HourlyAveLookup, divided by 12, then multiplied by 1.15 if the value is 200 or less, 1.2 if the value is between 201 and 800, 1.25 if the value is between 801 and 10,000, or 1.5 if the value is over 10,000
SELECT …l.hourlyAve/12 * CASE
WHEN l.hourlyAve/12 >10000 THEN 1.15
WHEN l.hourlyAve/12 > 800 THEN 1.2
WHEN l.hourlyAve/12 > 200 THEN 1.25
ELSE 1.5 END
lowerLimit
the hourlyAve value for the current hour from HourlyAveLookup, divided by 12, then divided by 1.15 if the value is 200 or less, 1.2 if the value is between 201 and 800, 1.25 if the value is between 801 and 10,000, or 1.5 if the value is over 10,000
SELECT …l.hourlyAve/12 / CASE
WHEN l.hourlyAve/12 >10000 THEN 1.15
WHEN l.hourlyAve/12 > 800 THEN 1.2
WHEN l.hourlyAve/12 > 200 THEN 1.25
ELSE 1.5 END
category, status
placeholders for values to be added
SELECT … '<NOTSET>'
The MerchantTxRateOnlyStream passes this output to the GenerateMerchantTxRateWithStatus query, which populates the category and status fields by evaluating the count, upperLimit, and lowerLimit fields:
SELECT merchantId,
zip,
startTime,
count,
totalAmount,
hourlyAve,
upperLimit,
lowerLimit,
CASE
WHEN count > 10000 THEN 'HOT'
WHEN count > 800 THEN 'WARM'
WHEN count > 200 THEN 'COOL'
ELSE 'COLD' END,
CASE
WHEN count > upperLimit THEN 'TOOHIGH'
WHEN count < lowerLimit THEN 'TOOLOW'
ELSE 'OK' END
FROM MerchantTxRateOnlyStream
The category values are used by the Dashboard to color-code the map points. The status values are used by the GenerateAlerts query.
The output from the GenerateMerchantTxRateWithStatus query goes to MerchantTxRateWithStatusStream.
Step 5: Populate the Dashbhoard
The GenerateWactionContent query enhances the data from MerchantTxRateWithStatusStream with the merchant’s company, city, state, and zip code, and the latitude and longitude to position the merchant on the map, then populates the MerchantActivity WActionstore:
In a real-world application, the data for the NameLookup cache would come from a periodically updated table in the payment processor’s system, but the data for the ZipLookup cache might come from a file such as the one used in this sample application.
When the application finishes processing all the test data, the WActionStore will contain 423 WActions, one for each merchant. Each WAction includes the merchant’s context information (MerchantId, StartTime, CompanyName, Category, Status, Count, HourlyAve, UpperLimit, LowerLimit, Zip, City, State,
LatVal, and LongVal) and all events for that merchant from the MerchantTxRateWithStatusStream (merchantId, zip, String, startTime, count, totalAmount, hourlyAvet, upperLimit, lowerLimit, category, and status for each of 40 five-minute blocks). This data is used to populate the dashboard, as detailed in PosAppDash.
Step 6: Trigger Alerts
MerchantTxRateWithStatusStream sends the detailed event data to the GenerateAlerts query, which triggers alerts based on the Status value:
When a merchant’s status changes to TOOLOW or TOOHIGH, Striim will send an alert such as, “WARNING – alert from Striim – POSUnusualActivity – 2013-12-20 13:55:14 – Merchant Urban Outfitters Inc. count of 12012 is below lower limit of 13304.347826086958.” The “raise” value for the flag field instructs the subscription not to send another alert until the status returns to OK.
When the status returns to OK, Striim will send an alert such as, “INFO – alert from Striim – POSUnusualActivity – 2013-12-20 14:02:27 – Merchant Urban Outfitters Inc. count of 15853 is back between 13304.347826086958 and 17595.0.” The “cancel” value for the flag field instructs the subscription to send an alert the next time the status changes to TOOLOW or TOOHIGH. See Sending alerts from applications for more information on info, warning, raise, and cancel.
Step 7: Stream data to BigQuery
Now you can stream the enriched point-of-sale analytical data to cloud data platforms such as BigQuery, Snowflake, and Redshift. In this example, we’re going to stream the data to BigQuery for storage and analysis.
Striim can stream data into BigQuery in real-time while optimizing costs with partition pruning on merge operations. After the data is loaded into BigQuery, your team can analyze it with your business intelligence tool of choice. In this example we’re generating the reports in Metabase.
Get Started
Try this recipe yourself for free by signing up for a trial or talking to sales team for hands-on guidance. Striim can be deployed on your laptop, in a docker container, or directly on your cloud-service provider of
choice.
Tools you need
Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
Google BigQuery
BigQuery is a serverless, highly scalable multicloud data warehouse.
BI Tool (Metabase)
Metabase is an open source business intelligence tool.