Imagine searching for products on an online store by simply typing “best eco-friendly toys for toddlers under $50” and getting instant, accurate results—while the inventory is synchronized seamlessly across multiple databases. This blog dives into how we built a real-time AI-powered hybrid search system to make that vision a reality. Leveraging Striim’s advanced data streaming and real-time embedding generation capabilities, we tackled challenges like ensuring low-latency data synchronization, efficiently creating vector embeddings, and automating inventory updates.
We’ll walk you through the design decisions that balanced consistency, efficiency, and scalability and discuss opportunities to expand this solution to broader Retrieval-Augmented Generation (RAG) use cases. Whether you’re building cutting-edge AI search systems or optimizing hybrid cloud architectures, this post offers practical insights to elevate your projects.
What is RAG?
Retrieval-Augmented Generation (RAG) enhances the capabilities of large language models by incorporating external data retrieval into the generation process. It allows the model to fetch relevant documents or data dynamically, ensuring responses are more accurate and context-aware. RAG bridges the gap between static model knowledge and real-time information, which is crucial for applications that require up-to-date insights. This hybrid approach significantly improves response relevance, especially in domains like e-commerce and customer service.
Why Vector Embeddings and Similarity Search?
Vector embeddings translate natural language text into numerical representations that capture semantic meaning. This allows for efficient similarity searches, enabling the discovery of products even if queries differ from stored descriptions. Embedding-based search supports fuzziness, matching results that aren’t exact but are contextually relevant. This is essential for natural language search, as it interprets user intent beyond simple keyword matching. The combination of embeddings and similarity search improves the user experience by providing more accurate and diverse search results.

Why Real-time RAG Instead of Batch-Based Data Sync?
Real-time RAG ensures that inventory changes are reflected instantly in the search engine, eliminating stale or outdated results. Unlike batch-based sync, which can introduce latency, real-time pipelines offer continuous updates, improving accuracy for fast-moving inventory. This minimizes the risk of selling unavailable products and enhances customer satisfaction. Real-time synchronization also supports dynamic environments where product data changes frequently, aligning search capabilities with the latest inventory state.
How We Designed the Embedding Generator for Performance
In designing the Vector Embedding Generator, we addressed the challenges associated with token estimation, handling oversized input data, and managing edge cases such as null or empty input strings. These design considerations ensure that the embedding generation process remains robust, efficient, and compatible with various AI models.
Token Estimation and Handling Large Data
Google Vertex AI
Vertex AI simplifies handling large data inputs by silently truncating input data that exceeds the token limit and returning an embedding based on the truncated input. While this approach ensures that embeddings are always generated regardless of input size, it raises concerns about data loss affecting embedding quality. We have an ongoing effort to analyze how this truncation impacts embeddings and whether improvements can be made to mitigate potential quality issues.
OpenAI
OpenAI enforces strict token limits, returning an error if input data exceeds the threshold (e.g., 2048 or 3092 tokens). To handle this, we integrated a tokenizer library into the Embedding Generator’s backend to estimate token counts before sending data to the API. The process involves:
- Token Count Estimation: Input strings are tokenized to determine the estimated token count.
- Iterative Truncation: If the token count exceeds the model’s limit, we truncate the input to 75% of its current size and recalculate the token count. This loop continues until the token count falls within the model’s threshold.
- Submission to Model: The truncated input is then sent to OpenAI for embedding generation.
For instance, if an OpenAI model has a token limit of 3092 and the estimated token count for incoming data is 4000, the system will truncate the input to approximately 3000 tokens (75%) and re-estimate. This iterative process ensures compliance with the token limit without manual intervention.
Handling Null or Empty Input
When generating embeddings, edge cases like null or empty input can result in API errors or undefined behavior. To prevent such scenarios, we adopted a solution inspired by discussions in the OpenAI developer forum: the use of a default vector.
Characteristics of the Default Vector:
- Dimensionality: Matches the size of embeddings generated by the specific model (e.g., 1536 dimensions for OpenAI’s text-embedding-ada-002).
- Structure: The vector contains a value of 1.0 at the first index, with all other indices set to 0.0.
- Example:[1.0, 0.0, 0.0, … , 0.0]
By returning this default vector, we ensure the system gracefully handles cases where input data is invalid or missing, enabling downstream processes to continue operating without interruptions.
Summary of Implementation:
- Preprocessing
- Estimate token counts and handle truncation for models with strict token limits (OpenAI).
- Allow silent truncation for models like Google Vertex AI but analyze its impact.
- Error Handling
- For null or empty data, return a default vector matching the model’s embedding dimensions.
- Scalability
- These mechanisms are integrated seamlessly into the Embedding Generator, ensuring compatibility across multiple data streams and models without manual intervention.
This design enables developers to generate embeddings confidently, knowing that token limits and edge cases are managed effectively.
Tutorial: Using the Embeddings Generator for Search

An e-commerce company aims to build an AI-powered hybrid search that enables users to describe their needs in natural language.
Their inventory management system is in Oracle database and the store front search database is maintained in the Azure PostgetSQL.
Current problem statements are:
- Data Synchronization: Inventory data from Oracle must be replicated in real-time to the storefront’s search engine to ensure data consistency and avoid stale information.
- Vector Embedding Generation: Product descriptions need vector embeddings to facilitate similarity searches. The storefront must support storing and querying these embeddings.
- Real-Time Updates: Ongoing changes in the inventory (such as product details or stock updates) need to be reflected immediately in the search engine.
- Embedding Updates: Updates to products in the inventory should trigger real-time embedding regeneration to prevent outdated or inaccurate similarity search results.
Solution
Striim has all the necessary features for the use case and the problem statements described.
- Readers to capture initial snapshot and real-time changes from Oracle database.
- Embedding generator to generate vector embeddings for text content.
- Writers to deliver the data along with the embeddings to Postgres database.
Striim Features :
- Readers: Capture the initial snapshot and ongoing real-time changes from the Oracle database.
- Embedding Generator: Creates vector embeddings for product descriptions.
- Writers: Deliver updated data and embeddings to the PostgreSQL database.
PostgreSQL with pgvector:
- Supports storing vector embeddings as a specific data type.
- Enables similarity search functionality directly within the database.
Note: The search engine for this solution is implemented in Python for demonstration purposes. OpenAI is used for embedding generation and for summarisation of the results.

Design Choices and Rationale
- Striim for Data Integration: Chosen for its seamless real-time change capture (CDC) from Oracle to PostgreSQL.
- Alternative could be to have an independent application/script periodically but would be inefficient and expensive to have this developed for the initial load and change data capture, also would be difficult to maintain over a period of time for various data sources which might also need to be synced to the store front database (Postgres)
- OpenAI Embeddings: Ensures high-quality embeddings compatible across pipeline stages.
- Striim Embedding generator: Enables in-flight embedding generation while the data is being synced instead of having to move the data separately and then generate and update the embedding.
- Alternative is to have separate listeners/triggers/scripts in the search front database (Postgres) to generate and update the embeddings every time the data changes. This could be very expensive and not be very accurate as the data changes and the embedding changes can go out of sync.
- pgvector: Facilitates native vector searches, reducing system complexity.
- Alternative design choices were to choose the standalone vector databases but they do not provide the flexibility pgvector provides as we can store the actual data and the embeddings in a relational database setup compared to vector databases where we need to maintain metadata for each vector database and cross lookup for actual data from a different database/source while summarising the similarity search results. Eg., the embeddings would be in one place which needs to be queried using similarity search query whereas price or rating-based filters need to be applied elsewhere.
- Python Search Engine: Provides flexibility and integration simplicity.
- This is a convenient choice to make use of the python libraries, more details are included in the upcoming sections
Future Work
- Expand embedding model options beyond OpenAI and make it generic
- This is already done for the Striim Embedding generator as it supports VertexAI as well. We could consider supporting self-hosted models.
- Expand the support for non-textual input.
- Expand the implementation to generically cover any use case and have the application interface integrated with Striim UI.
- Current implementation as a proof of concept is tightly coupled with the e-commerce use case and it’s data set.
Step-by-step instructions
Set up Striim Developer 5.0
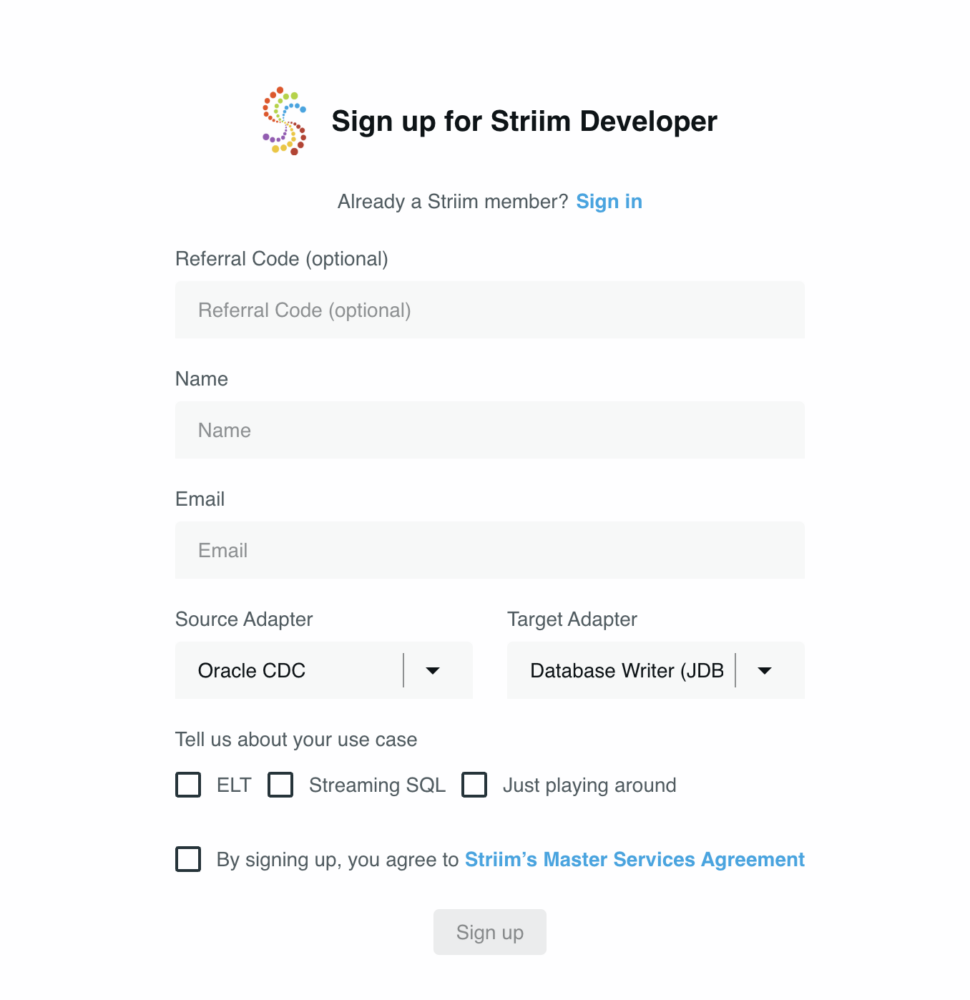
- Sign up for Striim developer edition for free at https://signup-developer.striim.com/.
- Select Oracle CDC as the source and Database Writer as the target in the sign-up form.
Prepare the dataset
The dataset can be downloaded from this link: https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/main/cloud-sql/postgres/pgvector/data/retail_toy_dataset.csv
(selected set of 800 toys from the Kaggle dataset – https://www.kaggle.com/datasets/promptcloud/walmart-product-details-2020)
Have the above data imported into Oracle. Please use the following table definition to import the data :
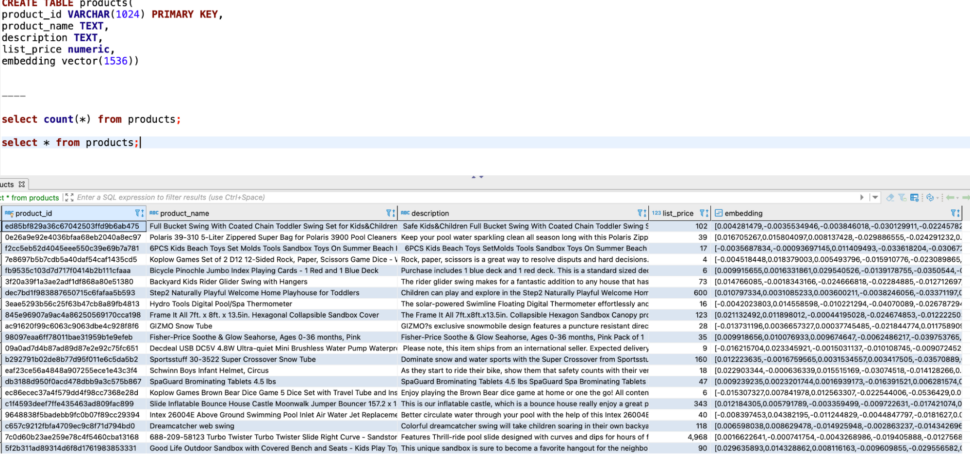
A peek into the data :

Create Embedding generator
Go to StriimAI -> Vector Embeddings Generator and create a new Embeddings Generator
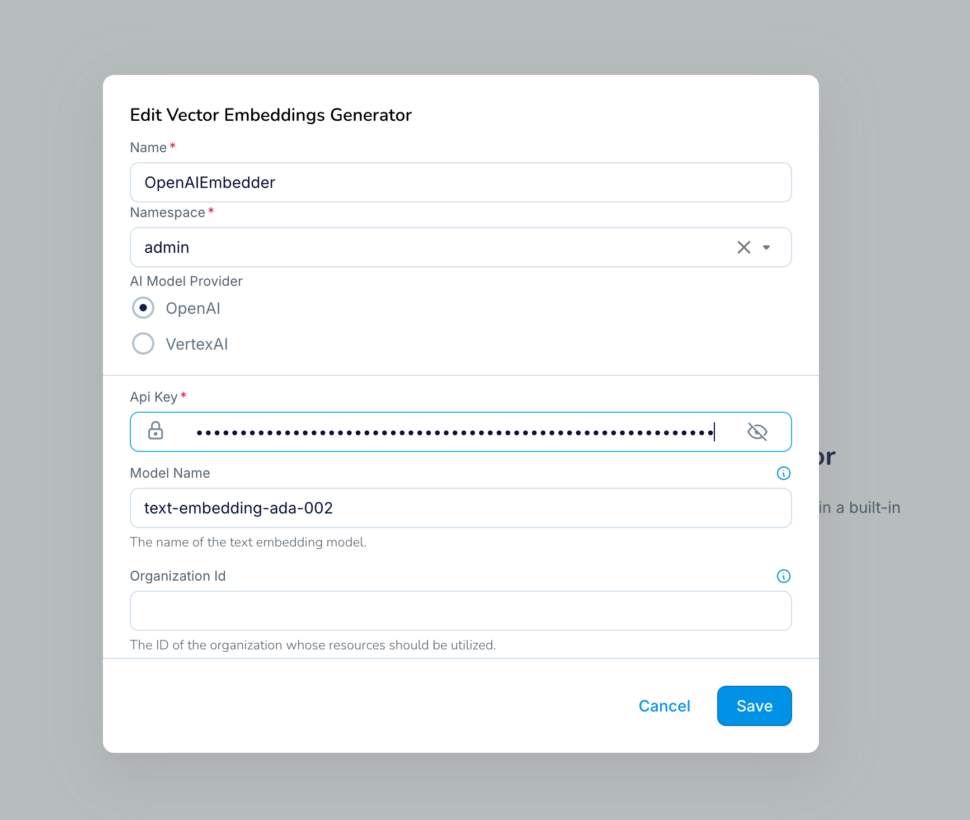
- Provide a unique name for the embedding generator.
- Choose OpenAI as model provider
- Enter the API key copied over from your OpenAI platform account – https://platform.openai.com/settings/organization/api-keys
- Enter “text-embedding-ada-002” as the model
- The same model should be used in the Python code for converting the user query into embedding before similarity search as well.
- Later in this blog, the above embedding generator will be used in the pipeline for generating vectors using a Striim builtin function – generateEmbeddings()
Setup the automated data pipeline from Oracle to Postgres
Go to Apps -> Create An App -> Choose Oracle as Source and Azure Postgres as Target
Follow the guided wizard flow to configure the pipeline with source, target connection details and the table selection. In the review screen, make sure to choose the “Save & Exit option”
Note: Please follow the prerequisites for Oracle CDC from Striim doc – https://striim.com/docs/en/configuring-oracle-to-use-oracle-reader.html

The table used in Postgres :
Please note that the embedding column is created additionally in Postgres.
Customize the Striim pipeline
- Go back to the pipeline using Apps -> View All Apps
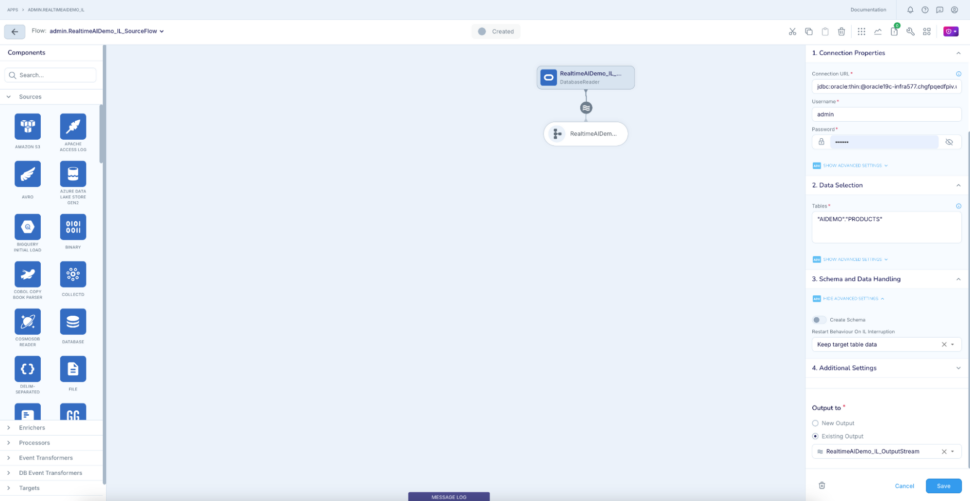
- Open the IL app RealTimeAIDemo_IL
- Open the reader configuration -> Disable “Create Schema” under “Schema and Data Handling” as we are creating the schema on Postgres already.
Click the output stream of the reader and add a Continuous Query component (CQ) to it to generate embeddings for the description column using the embedding generator we created above.
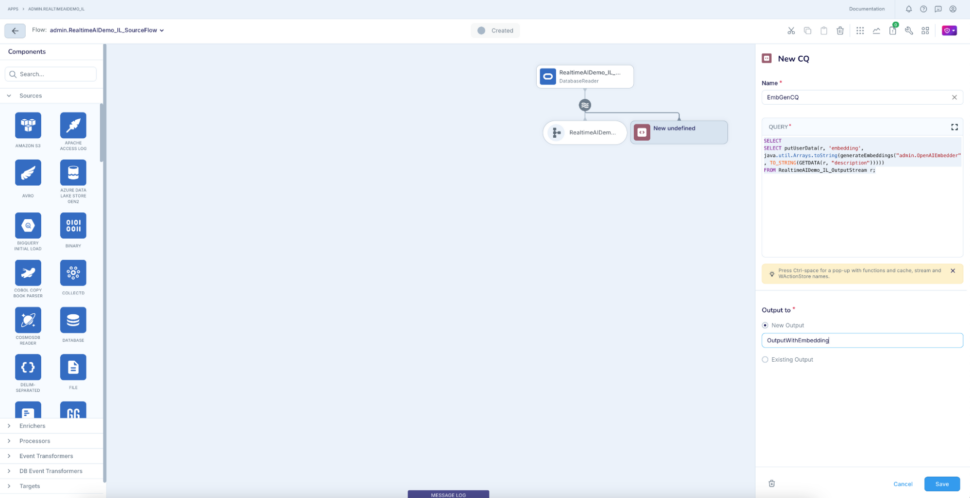
The CQ essentially puts the embeddings into the userdata section of the source event, which can be used to write to the embedding column in Postgres table.
Here the output of the generateEmbedding() function will be placed as part of the ‘embedding’ section (as part of the user data) in the source event.
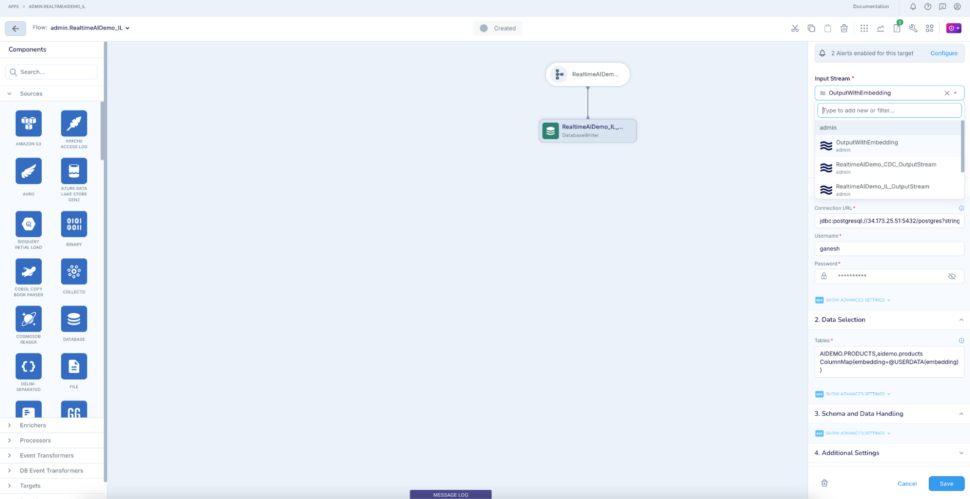
Click to the target and change the input stream to the output of CQ (OutputWithEmbedding). In the Tables property, also add a mapping for embedding column under Data Selection :
AIDEMO.PRODUCTS,aidemo.products ColumnMap(embedding=@USERDATA(embedding)
This will insert or update the ‘embedding’ column of the Postgres table with the generated vectors from the generateEmbedding() call. This column holds the vector value of the ‘description’ column value.
Perform the same steps for the CDC app in the pipeline as well.
- Go back to the pipeline using Apps -> View All Apps
- Open the CDC app RealTimeAIDemo_CDC and perform the same steps as done for the RealTimeAIDemo_IL application (i.e calling generateEmbedding function and columnMap())
Create Gen AI application using python
Next step is to build a python application, which does the following:
- Accepts user query in natural text for searching a product
- Converts the Query to embeddings using Open AI
- Performs similarity search using PG vector extension functionality in Azure Database for PostgreSQL
- Returns a response generated using LLM service with the top matching product details
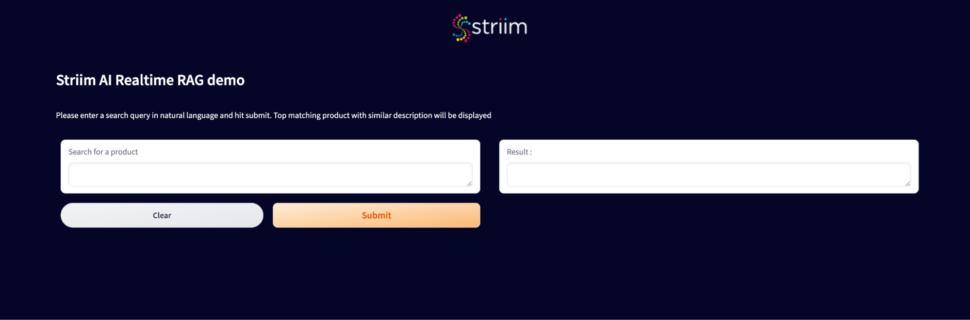
- Please click here to download this python application.
- asyncpg is used to connect to Postgres
- OpenAIEmbeddings (langchain.embeddings) is used to generate embeddings for the user query
- Please note that you need to use the same model in the Striim embedding generator
- langchain.chains.summarize is used for summarisation (model used : gpt-3.5-turbo-instruct)
- Query used to perform the similarity search :
-
- Similarity threshold of 0.7, max matches of 5 are used as experimentation but only one closest result is picked for summarisation
- gradio is used to present in a simple UI
Start the pipeline to perform the initial snapshot load
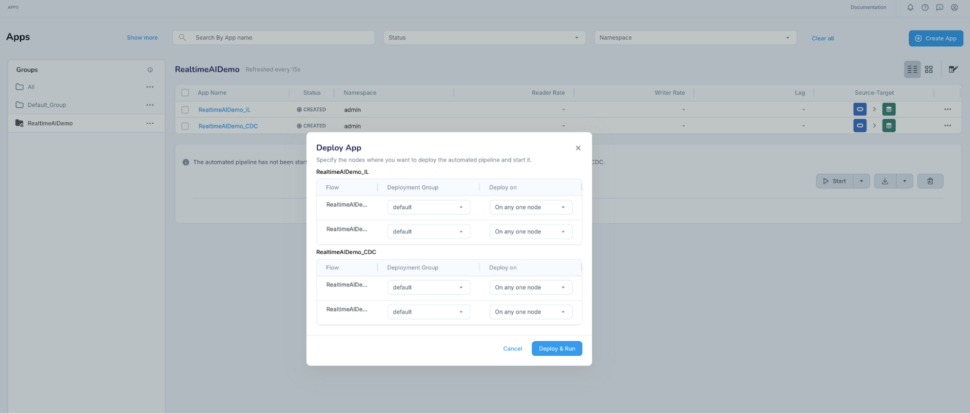
Once the initial load is complete, the pipeline will automatically transition to CDC phase. Verify the data in Postgres table and confirm that embeddings are stored as well.
Run the similarity search python application and verify that it fetches the results using the similarity search of pgvector.

Capture the real-time changes from the Oracle database and generate on the fly vector conversion
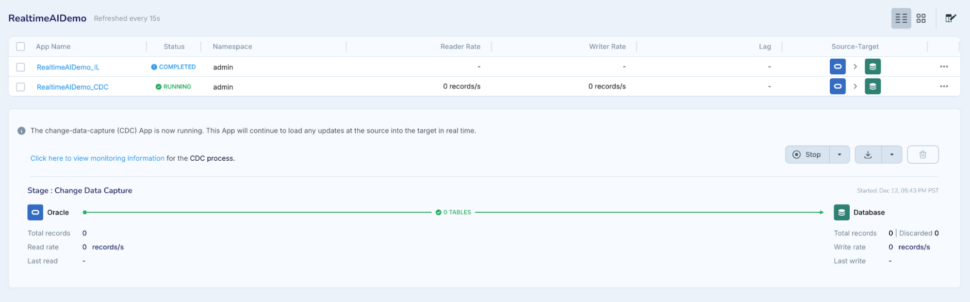
Perform a simple change in your source Oracle database to make a better product description for the product with id : ’20e597d8836d9e5fa29f2bd877fc3e0a’
Striim pipeline would instantly capture the change and deliver it to the Postgres table along with the updated vector embedding.

Run the same query in the search interface to notice that a fresh result shows up :
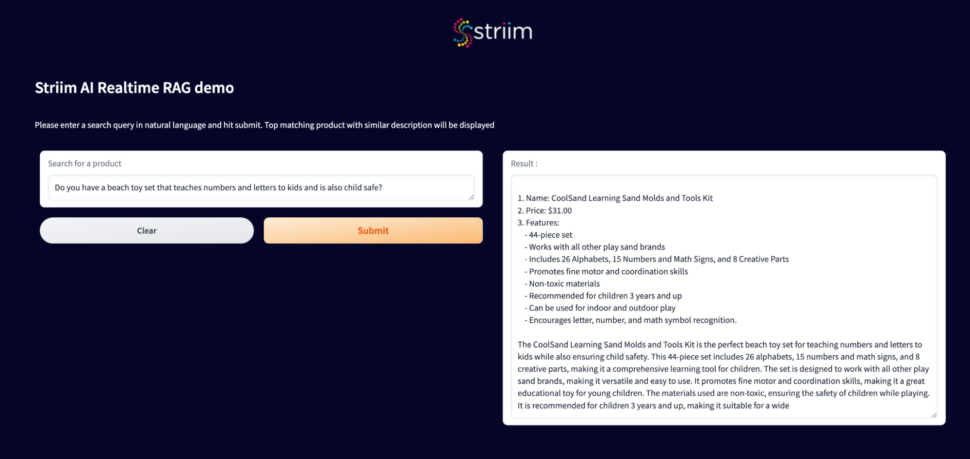
Now the same query would result in a different product id since the query works against the recently updated data in the Oracle database.
There we go! Real-time integration and consistent data everywhere!
Conclusion
Experience the power of real-time RAG with Striim. Get a demo or start your free trial today to see how we enable context-aware, natural language-based search with real-time data consistency—delivering smarter, faster, and more responsive customer experiences!
References and credits
Inspired by the Google notebook which showcased the use case and also had reference to the curated dataset: Building AI-powered data-driven applications using pgvector, LangChain and LLMs



















