Every second, customer interactions, operational databases, and SaaS applications generate massive volumes of information.
It’s not collecting the data that’s the key challenge. It’s the task of connecting data with the systems and people who need it most. When engineering teams have to manually stitch together fragmented data from across the business, reports get delayed, analytics fall out of sync, and AI initiatives fail before they even make it to production.
To make data useful the instant it’s born, enterprises often rely on automated data pipelines. At the scale that modern businesses operate, a data pipeline acts as the circulatory system of the organization. It continuously pumps vital, enriched information from isolated systems into the cloud data warehouses, lakehouses, and AI applications that drive strategic decisions.
In this guide to data pipelines, we’ll break down exactly what a data pipeline is, explore the core components of its architecture, and explain why moving from traditional batch processing to real-time streaming is essential for any modern data strategy.
What is a Data Pipeline?
A data pipeline is a set of automated processes that extract data from various sources, transform it into a usable format, and load it into a destination for storage, analytics, or machine learning. By eliminating manual data extraction, data pipelines ensure that information flows securely and consistently from where it’s generated to where it is needed.
Why are Data Pipelines Important?
Data pipelines are significant because they bridge the critical gap between raw data generation and actionable business value. Without them, data engineers are forced to spend countless hours manually extracting, cleaning, and loading data. This reliance on manual intervention creates brittle workflows, delays reporting, and leaves decision-makers relying on stale dashboards.
A robust data pipeline automates this entire lifecycle. By ensuring that business leaders, data scientists, and operational systems have immediate, reliable access to trustworthy data, pipelines accelerate time-to-market and enable real-time customer personalization. More importantly, they provide the sturdy, continuous data foundation required for enterprise AI initiatives. When data flows freely, securely, and automatically, the entire organization is empowered to move faster and make better decisions.
The Core Components of Data Pipeline Architecture
To understand how a data pipeline delivers this enterprise-wide value, it’s helpful to look under the hood. While every organization’s infrastructure is unique to their specific tech stack, modern data pipeline architecture relies on three core components: ingestion, transformation, and storage.
Data Ingestion (The Source)
This is where the pipeline begins. Data ingestion involves securely extracting data from its origin point. In a modern enterprise, data rarely lives in just one place. A pipeline must be capable of pulling information from a vast array of sources, including SaaS applications (like Salesforce), relational databases (such as MySQL or PostgreSQL), and real-time event streams via Webhooks or message brokers. A high-performing ingestion layer handles massive volumes of data seamlessly, without bottlenecking or impacting the performance of the critical source systems generating the data.
Data Transformation (The Process)
Raw data is rarely ready in its original state to be used, whether for analysis or to power systems downstream. It’s often messy, duplicated, incomplete, or formatted incorrectly. The data transformation stage acts as the processing engine of the pipeline, systematically cleaning, deduplicating, filtering, and formatting the data. This step is absolutely critical; without it, downstream analytics and AI models will produce inaccurate insights based on flawed inputs. “Clean” analytics require rigorous, in-flight transformations to ensure data quality, structure, and compliance before it ever reaches the warehouse.
Data Storage (The Destination)
The final stage of the architecture involves delivering the processed, enriched data to a target system where it can be queried, analyzed, or fed directly into machine learning models. Modern data destinations typically include cloud data warehouses like Snowflake, lakehouses like Databricks, or highly scalable cloud storage solutions like Amazon S3. The choice of destination is crucial, as it often dictates the pipeline’s overall structure and processing paradigm, ensuring the data lands in a format optimized for the business’s specific AI and analytics workloads.
Types of Data Pipelines
Not all data pipelines operate the same way. The architecture you choose dictates how fast your data moves and how it’s processed along the way. Understanding the differences between these types is critical for choosing a solution that meets your business’s need for speed and scalability.
Batch Processing vs. Stream Processing
Historically, data pipelines relied heavily on batch processing. In a batch pipeline, data is collected over a period of time and moved in large, scheduled chunks, often overnight. While batch processing works fine for historical reporting where latency isn’t a problem, it leaves your data fundamentally stale. If you’re trying to power an AI agent, personalize a customer’s retail experience, or catch fraudulent transactions as they happen, yesterday’s data just won’t cut it.
That’s where stream processing comes in. Streaming pipelines process data continuously, the instant it’s born. Instead of waiting for a scheduled window, data flows in real time, unlocking immediate business intelligence and ensuring high availability for critical applications.
A highly efficient, enterprise-grade variant of stream processing is Change Data Capture (CDC). Instead of routinely scanning an entire database to see what changed—which puts a massive, degrading load on your source systems—Striim’s modern data pipelines utilize CDC to listen directly to the database’s transaction logs. It instantly captures only the specific inserts, updates, or deletes and streams them downstream in milliseconds. This makes your data pipelines incredibly efficient and resource-friendly, directly driving business value by ensuring your decision-makers and AI models are continuously fueled with fresh, decision-ready data.
ETL vs. ELT
Another way to categorize pipelines is by when the data transformation happens.
ETL (Extract, Transform, Load) is the traditional approach. Here, data is extracted from the source, transformed in a middle-tier processing engine, and then loaded into the destination. This is highly valuable when you need to rigorously cleanse, filter, or mask sensitive data before it ever reaches your data warehouse or AI model.
ELT (Extract, Load, Transform) flips the script. In an ELT pipeline, raw data is extracted and loaded directly into the destination system as quickly as possible. The transformations happen after the data has landed. This approach has become incredibly popular because it leverages the massive, scalable compute power of modern cloud data warehouses like Snowflake or BigQuery to handle the heavy lifting of transformation. Understanding ETL vs. ELT differences helps engineering teams decide whether they need in-flight processing for strict compliance or post-load processing for raw speed.
Use Cases of Data Pipelines and Real World Examples
Connecting data from point A to point B may sound like a purely technical exercise. But in practice, modern data pipelines drive some of the most critical, revenue-generating functions in the enterprise. Here is how companies are putting data pipelines to work in the real world:
1. Omnichannel Retail and Inventory Syncing
For retail giants, a delay of even a few minutes in inventory updates can lead to overselling, stockouts, and frustrated customers. Using real-time streaming data pipelines, companies like Macy’s capture millions of transactions and inventory changes from their operational databases and stream them to their analytics platforms in milliseconds. This continuous flow of data enables perfectly synced omnichannel experiences, ensuring that the sweater a customer sees online is actually available in their local store.
2. Real-Time Fraud Detection
In the financial services sector, the delay associated with batch processing is a fundamental liability. Fraud detection models require instant context to be effective. A streaming data pipeline continuously feeds transactional data into machine learning models the moment a card is swiped. This allows automated systems to flag, isolate, and block suspicious activity in sub-second latency, stopping fraud before the transaction even completes.
3. Powering Agentic AI and RAG Architectures
As enterprises move beyond simple chatbots into autonomous, “agentic” AI, these systems require a continuous feed of accurate, real-time context. Data pipelines serve as the crucial infrastructure here, actively pumping fresh enterprise data into vector databases to support Retrieval-Augmented Generation (RAG). By feeding AI models with up-to-the-millisecond data, companies ensure their AI agents make decisions based on the current state of the business, rather than hallucinating based on stale information.
7 Must-Have Features of Modern Data Pipelines
To create an effective modern data pipeline, incorporating these seven key features is essential. Though not an exhaustive list, these elements are crucial for helping your team make faster and more informed business decisions.
1. Real-Time Data Processing and Analytics
The number one requirement of a successful data pipeline is its ability to load, transform, and analyze data in near real time. This enables business to quickly act on insights. To begin, it’s essential that data is ingested without delay from multiple sources. These sources may range from databases, IoT devices, messaging systems, and log files. For databases, log-based Change Data Capture (CDC) is the gold standard for producing a stream of real-time data.
Real-time, continuous data processing is superior to batch-based processing because the latter takes hours or even days to extract and transfer information. Because of this significant processing delay, businesses are unable to make timely decisions, as data is outdated by the time it’s finally transferred to the target. This can result in major consequences. For example, a lucrative social media trend may rise, peak, and fade before a company can spot it, or a security threat might be spotted too late, allowing malicious actors to execute on their plans.
Real-time data pipelines equip business leaders with the knowledge necessary to make data-fueled decisions. Whether you’re in the healthcare industry or logistics, being data-driven is equally important. Here’s an example: Suppose your fleet management business uses batch processing to analyze vehicle data. The delay between data collection and processing means you only see updates every few hours, leading to slow responses to issues like engine failures or route inefficiencies. With real-time data processing, you can monitor vehicle performance and receive instant alerts, allowing for immediate action and improving overall fleet efficiency.
2. Scalable Cloud-Based Architecture
Modern data pipelines rely on scalable, cloud-based architecture to handle varying workloads efficiently. Unlike traditional pipelines, which struggle with parallel processing and fixed resources, cloud-based pipelines leverage the flexibility of the cloud to automatically scale compute and storage resources up or down based on demand.
In this architecture, compute resources are distributed across independent clusters, which can grow both in number and size quickly and infinitely while maintaining access to a shared dataset. This setup allows for predictable data processing times as additional resources can be provisioned instantly to accommodate spikes in data volume.
Cloud-based data pipelines offer agility and elasticity, enabling businesses to adapt to trends without extensive planning. For example, a company anticipating a summer sales surge can rapidly increase processing power to handle the increased data load, ensuring timely insights and operational efficiency. Without such elasticity, businesses would struggle to respond swiftly to changing trends and data demands.
3. Fault-Tolerant Architecture
It’s possible for data pipeline failure to occur while information is in transit. Thankfully, modern pipelines are designed to mitigate these risks and ensure high reliability. Today’s data pipelines feature a distributed architecture that offers immediate failover and robust alerts for node, application, and service failures. Because of this, we consider fault-tolerant architecture a must-have.
In a fault-tolerant setup, if one node fails, another node within the cluster seamlessly takes over, ensuring continuous operation without major disruptions. This distributed approach enhances the overall reliability and availability of data pipelines, minimizing the impact on mission-critical processes.
4. Exactly-Once Processing (E1P)
Data loss and duplication are critical issues in data pipelines that need to be addressed for reliable data processing. Modern pipelines incorporate Exactly-Once Processing (E1P) to ensure data integrity. This involves advanced checkpointing mechanisms that precisely track the status of events as they move through the pipeline.
Checkpointing records the processing progress and coordinates with data replay features from many data sources, enabling the pipeline to rewind and resume from the correct point in case of failures. For sources without native data replay capabilities, persistent messaging systems within the pipeline facilitate data replay and checkpointing, ensuring each event is processed exactly once. This technical approach is essential for maintaining data consistency and accuracy across the pipeline.
5. Self-Service Management
Modern data pipelines facilitate seamless integration between a wide range of tools, including data integration platforms, data warehouses, data lakes, and programming languages. This interconnected approach enables teams to create, manage, and automate data pipelines with ease and minimal intervention.
In contrast, traditional data pipelines often require significant manual effort to integrate various external tools for data ingestion, transfer, and analysis. This complexity can lead to bottlenecks when building the pipelines, as well as extended maintenance time. Additionally, legacy systems frequently struggle with diverse data types, such as structured, semi-structured, and unstructured data.
Contemporary pipelines simplify data management by supporting a wide array of data formats and automating many processes. This reduces the need for extensive in-house resources and enables businesses to more effectively leverage data with less effort.
6. Capable of Processing High Volumes of Data in Various Formats
It’s predicted that the world will generate 181 zettabytes of data by 2025. To get a better understanding of how tremendous that is, consider this: one zettabyte alone is equal to about 1 trillion gigabytes.
Since unstructured and semi-structured data account for 80% of the data collected by companies, modern data pipelines need to be capable of efficiently processing these diverse data types. This includes handling semi-structured formats such as JSON, HTML, and XML, as well as unstructured data like log files, sensor data, and weather data.
A robust big data pipeline must be adept at moving and unifying data from various sources, including applications, sensors, databases, and log files. The pipeline should support near-real-time processing, which involves standardizing, cleaning, enriching, filtering, and aggregating data. This ensures that disparate data sources are integrated and transformed into a cohesive format for accurate analysis and actionable insights.
7. Prioritizes Efficient Data Pipeline Development
Modern data pipelines are crafted with DataOps principles, which integrate diverse technologies and processes to accelerate development and delivery cycles. DataOps focuses on automating the entire lifecycle of data pipelines, ensuring timely data delivery to stakeholders.
By streamlining pipeline development and deployment, organizations can more easily adapt to new data sources and scale their pipelines as needed. Testing becomes more straightforward as pipelines are developed in the cloud, allowing engineers to quickly create test scenarios that mirror existing environments. This allows thorough testing and adjustments before final deployment, optimizing the efficiency of data pipeline development.
Why Your Business Needs a Modern Data Pipeline
In today’s digital economy, failing to connect your data is just as dangerous as failing to collect it. The primary threat to enterprise agility is the persistence of data silos—isolated pockets of information trapped across disparate departments, legacy systems, and disconnected SaaS applications. When data isn’t universally accessible, it isn’t truly useful. Silos stall critical business decisions, fracture the customer experience, and prevent leadership from seeing a unified picture of company performance.
Modern data pipelines are the antidote to data silos. By continuously extracting and unifying information from across the tech stack, pipelines democratize data access, ensuring that every department—from sales to supply chain—operates from the same single source of truth.
Furthermore, you simply can’t have AI without a steady stream of data. While 78% of companies have implemented some form of AI, a recent BCG Global report noted that only 26% are driving tangible value from it. The blocker isn’t the AI models themselves; it’s the lack of fresh, contextual data feeding them. Data pipelines empower machine learning and agentic AI by providing a continuous, reliable, and governed stream of enterprise context, shifting AI from an experimental novelty into a production-grade business driver.
Gain a Competitive Edge with Striim
Data pipelines are crucial for moving, transforming, and storing data, helping organizations gain key insights. Modernizing these pipelines is essential to handle increasing data complexity and size, ultimately enabling faster and better decision-making.
Striim provides a robust streaming data pipeline solution with integration across hundreds of sources and targets, including databases, message queues, log files, data lakes, and IoT. Plus, our platform features scalable in-memory streaming SQL for real-time data processing and analysis. Schedule a demo for a personalized walkthrough to experience Striim.
FAQs
What is the difference between a data pipeline and a data warehouse?
A data pipeline is the automated transportation system that moves and processes data, whereas a data warehouse is the final storage destination where that data lands. Think of the pipeline as the plumbing infrastructure that filters and pumps water, and the data warehouse as the reservoir where the clean water is stored for future use. You need the pipeline to ensure the data warehouse is constantly fueled with accurate, up-to-date information.
Do I need a data pipeline for small data sets?
Yes, even organizations dealing with smaller data volumes benefit immensely from data pipelines. Manual data extraction and manipulation—such as routinely exporting CSVs from a SaaS app to build a weekly spreadsheet—is highly error-prone and wastes valuable employee time. A simple pipeline automates these repetitive tasks, ensuring your data is always perfectly synced, formatted, and ready for analysis, regardless of its size.
Is a data pipeline the same as an API?
No, they are different but complementary technologies. An API (Application Programming Interface) is essentially a doorway that allows two distinct software applications to communicate and share data with each other. A data pipeline, on the other hand, is a broader automated workflow that often uses APIs to extract data from multiple sources, runs that data through complex transformations, and loads it into a centralized database for analytics.













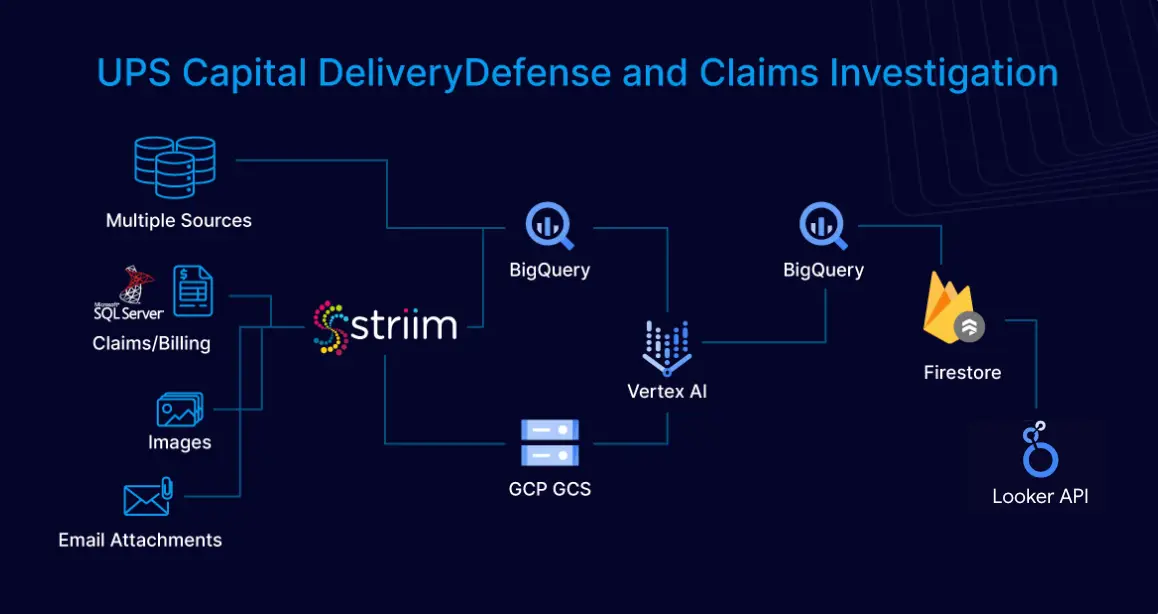






 By utilizing Striim, Inspyrus ingested real-time data from an OLTP database, loaded it into Snowflake, and transformed it there. It then used an intelligence tool to visualize this data and create rich reports for users. As a result, Inspyrus users are able to view reports in real time and utilize insights immediately to fuel better decisions.
By utilizing Striim, Inspyrus ingested real-time data from an OLTP database, loaded it into Snowflake, and transformed it there. It then used an intelligence tool to visualize this data and create rich reports for users. As a result, Inspyrus users are able to view reports in real time and utilize insights immediately to fuel better decisions. 