By combining the transformative abilities of Striim and Snowflake, organizations will enjoy unprecedentedly powerful real-time anomaly detection. Striim’s seamless data integration and streaming capabilities, paired with Snowflake’s scalable cloud data platform, allow businesses to monitor and analyze their data in real time.
This integration enhances the detection of irregular patterns and potential threats, ensuring rapid response and mitigation. Leveraging both platforms’ strengths, companies can achieve higher operational intelligence and security, making real-time anomaly detection more effective and accessible than before.
We’re here to walk you through the steps necessary to implement real-time anomaly detection. We’ll also dive deeper into the goals of leveraging Snowflake and Stream for real-time anomaly detection.
What are the Goals of Leveraging Striim and Snowflake for Real-Time Anomaly Detection?
The central goal of leveraging Striim and Snowflake is to make anomaly detection possible down to the second.
Let’s dial in on some of the specific goals your organization can accomplish thanks to leveraging Striim and Snowflake.
Transform Raw Data into AI-generated Actions and Insights in Seconds
In today’s fast-paced business environment, the ability to quickly transform raw data into actionable insights is crucial. Leveraging Striim and Snowflake allows organizations to achieve this in seconds, providing a significant competitive advantage.
Striim’s real-time data integration capabilities ensure that data is continuously captured and processed, while Snowflake’s powerful analytics platform rapidly analyzes this data. The integration enables AI algorithms to immediately generate insights and trigger actions based on detected anomalies. This rapid processing not only enhances the speed and accuracy of decision-making but also allows businesses to proactively address potential issues before they escalate, resulting in improved operational efficiency and reduced risk.
Ingest Near Real-Time Point of Sales (POS) Training and Live Data into Snowflake Using Striim CDC Application
For retail and service industries, timely and accurate POS data is crucial. Using Striim’s Change Data Capture (CDC) application, businesses can ingest near real-time POS data into Snowflake, ensuring that training and live data are always up-to-date.
Striim’s CDC technology captures changes from various sources and delivers them to Snowflake in real time, enabling rapid analysis and reporting. This allows businesses to quickly identify sales trends, monitor inventory levels, and detect anomalies, leading to more informed decisions, optimized inventory management, and improved customer experience.
Predicting Anomalies in POS Data with Snowflake Cortex and Striim
Leveraging Snowflake Cortex and Striim, businesses can build and deploy machine learning models to detect anomalies in Point of Sale (POS) data efficiently. Snowflake Cortex offers an integrated platform for developing and training models directly within Snowflake, utilizing its data warehousing and computing power.
Striim enhances this process by providing real-time data integration and streaming capabilities. Striim can seamlessly ingest and prepare POS data for analysis, ensuring it is clean and up-to-date. Once prepared, Snowflake Cortex trains the model to identify patterns and anomalies in historical data.
After training, the model is deployed to monitor live POS data in real time, with Striim enabling continuous data streaming. This setup flags any unusual transactions or patterns promptly, allowing businesses to address potential issues like fraud or inefficiencies proactively.
By combining Snowflake Cortex and Striim, organizations gain powerful, real-time insights to enhance anomaly detection and safeguard their operations.
Detect Abnormalities in Recent POS Data with Snowflake’s Anomaly Detection Model
Your organization can also use Snowflake’s anomaly detection model in conjunction with Striim to identify irregularities in your recent POS data. Striim’s real-time data integration capabilities continuously stream and update POS data, ensuring that Snowflake’s model analyzes the most current information.
This combination allows for swift detection of unusual transactions or patterns, providing timely insights into potential issues such as fraud or operational inefficiencies. By integrating Striim’s data handling with Snowflake’s advanced analytics, you can effectively monitor and address abnormalities as they occur.
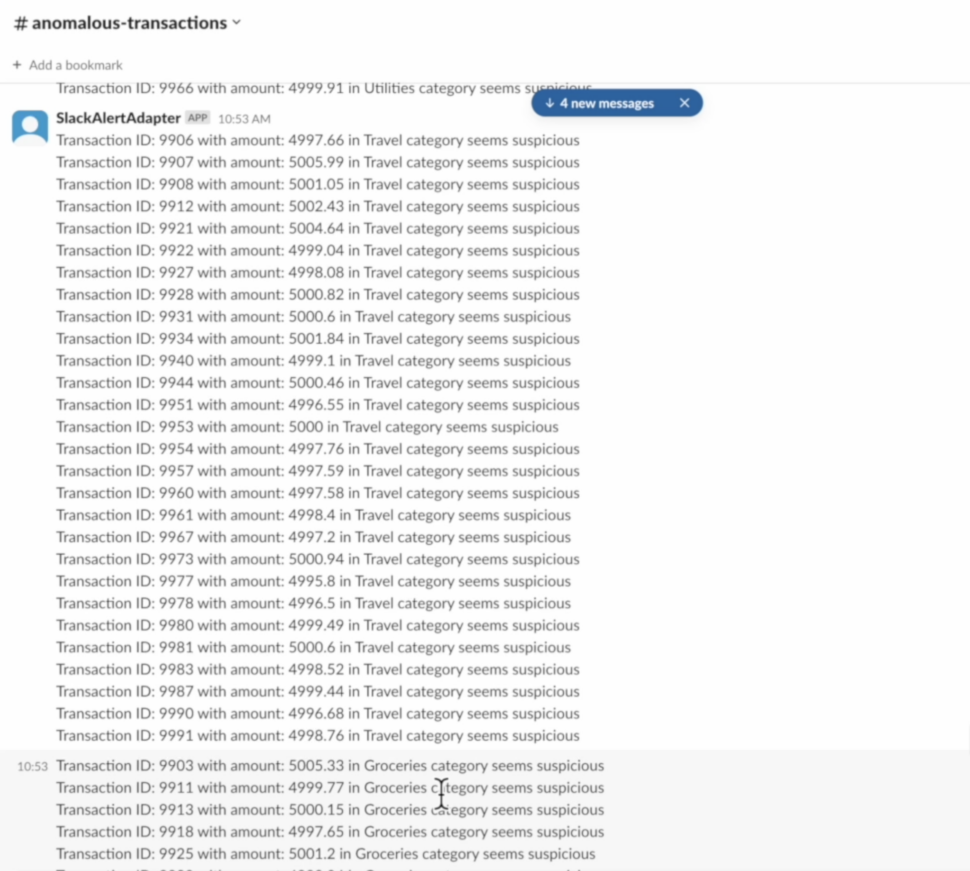
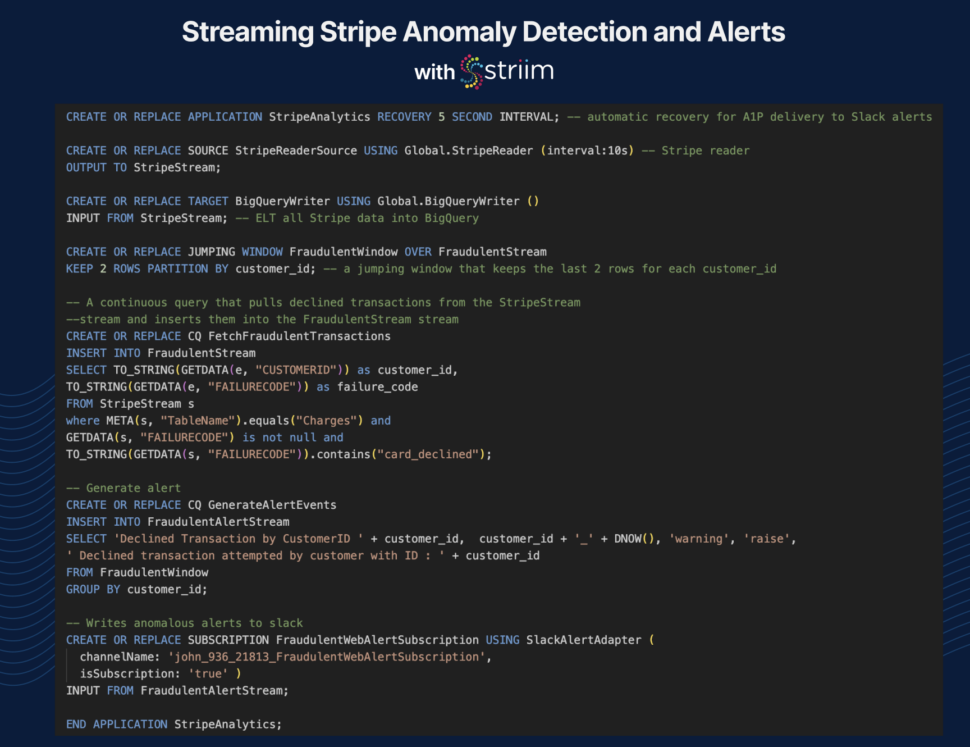
Use Striim to Continuously Monitor Anomalies and Send Slack Alerts for Unusual Transactions
When an unusual transaction is detected, Striim automatically sends instant alerts to your Slack channel, allowing for prompt investigation and response. This seamless integration provides timely notifications and helps you address potential issues quickly, ensuring more efficient management of your transactional data.
Now that you know the goals of leveraging Striim and Snowflake, let’s dive deeper into implementation.
Implementation Details
Here is the high level architecture and data flow of the solution:
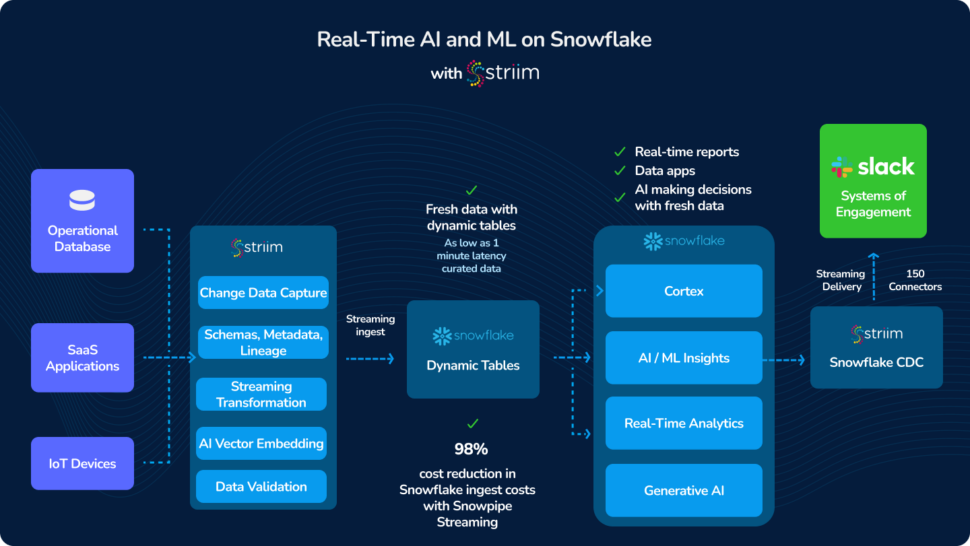
Generate POS Data
The POS (Point of Sales) Training dataset was synthetically created using a Python script and then loaded into MySQL. Here is the snippet of Python script that generates the data:
# Function to create training dataset of credit card transactions
def create_training_data(num_transactions):
data = {
'TRANSACTION_ID': range(1, num_transactions + 1),
'AMOUNT': np.random.normal(loc=50, scale=10, size=num_transactions), # Normal transactions
'CATEGORY': np.random.choice(['Groceries', 'Utilities', 'Entertainment', 'Travel'], size=num_transactions),
'TXN_TIMESTAMP': pd.date_range(start='2024-02-01', periods=num_transactions, freq='T') # Incrementing timestamps
}
df = pd.DataFrame(data)
return df
# Function to create live dataset with 1% of anomalous data
def create_live_data(num_transactions):
data = {
'TRANSACTION_ID': range(1, num_transactions + 1),
# generate 1% of anomalous data by changing the mean value
'AMOUNT': np.append(np.random.normal(loc=50, scale=10, size=int(0.99*num_transactions)),
np.random.normal(loc=5000, scale=3, size=num_transactions-int(0.99*num_transactions))),
'CATEGORY': np.random.choice(['Groceries', 'Utilities', 'Entertainment', 'Travel'], size=num_transactions),
'TXN_TIMESTAMP': pd.date_range(start='2024-05-01', periods=num_transactions, freq='T') # Incrementing timestamps
}
df = pd.DataFrame(data)
return df
# Function to load the dataframe to table using sqlalchemy
def load_records(conn_obj, df, target_table, params):
database = params['database']
start_time = time.time()
print(f"load_records start time: {start_time}")
print(conn_obj['engine'])
if conn_obj['type'] == 'sqlalchemy':
df.to_sql(target_table, con=conn_obj['engine'], if_exists=params['if_exists'], index=params['use_index'])
print(f"load_records end time: {time.time()}")
Striim – Streaming Data Ingest
Striim CDC Application loads data continuously from MySQL to Snowflake tables using Snowpipe Streaming API. POS transactions training data span 79 days starting from (2024-02-01 to 2024-04-20).
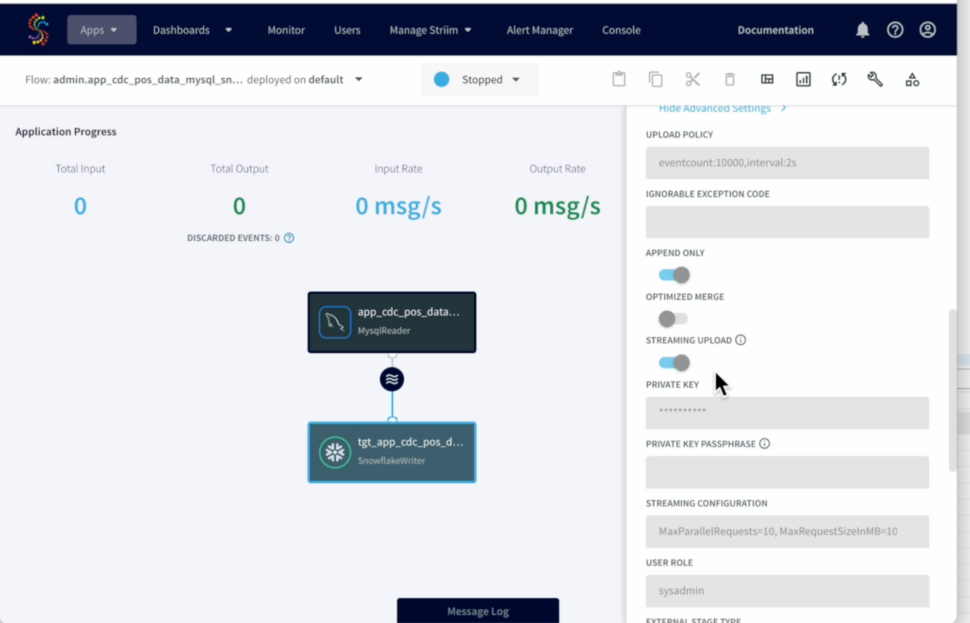
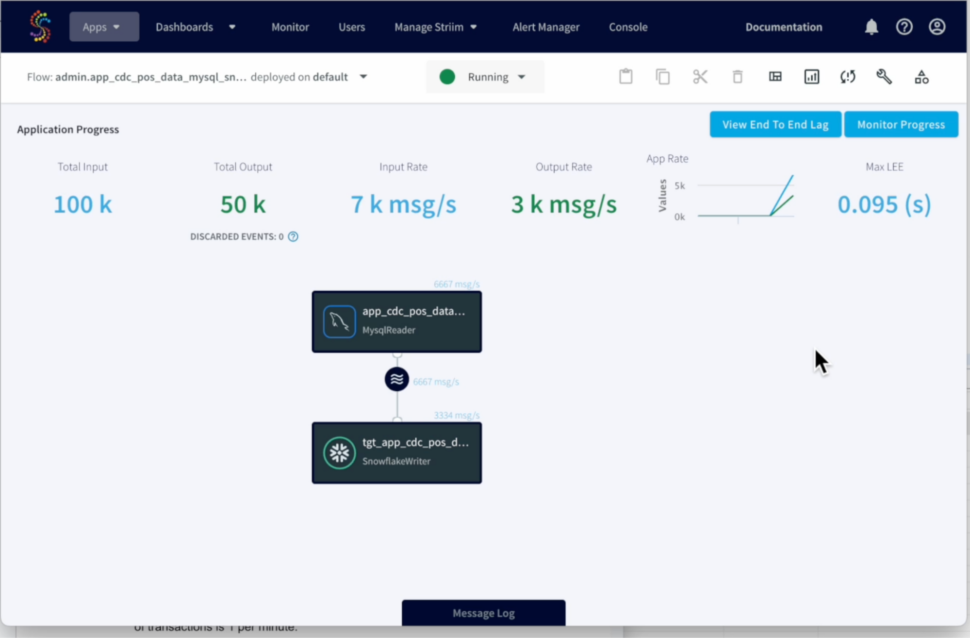
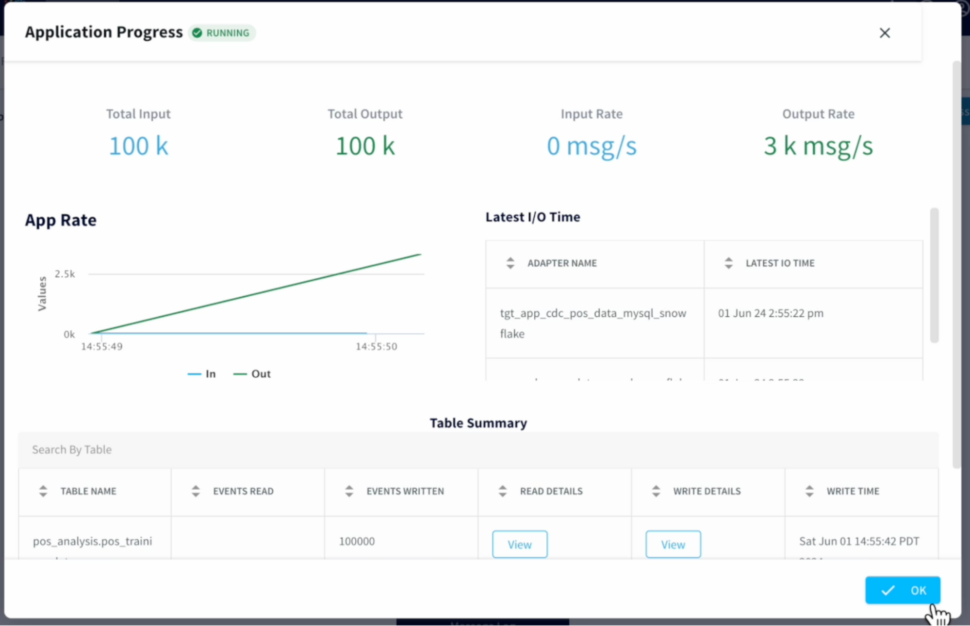
Build Anomaly Detection Model in Snowflake
Step 1: Create the table POS_TRAINING_DATA_RAW to store the training data.
CREATE OR REPLACE TABLE pos_training_data_raw (
Transaction_ID bigint DEFAULT NULL,
Amount double DEFAULT NULL,
Category text,
txn_timestamp timestamp_tz(9) DEFAULT NULL,
operation_name varchar(80),
src_event_timestamp timestamp_tz(9)
);
Step 2: Create the dynamic table dyn_pos_training_data to keep only the latest version of transactions that have not been deleted.
CREATE OR REPLACE DYNAMIC TABLE dyn_pos_training_data
LAG = '1 minute'
WAREHOUSE = 'DEMO_WH'
AS
SELECT * EXCLUDE (score,operation_name ) from (
SELECT
TRANSACTION_ID,
AMOUNT,
CATEGORY,
TO_TIMESTAMP_NTZ(TXN_TIMESTAMP) as TXN_TIMESTAMP_NTZ,
OPERATION_NAME,
ROW_NUMBER() OVER (
partition by TRANSACTION_ID order by SRC_EVENT_TIMESTAMP desc) as score
FROM POS_TRAINING_DATA_RAW
WHERE CATEGORY IS NOT NULL
)
WHERE score = 1 and operation_name != 'DELETE';
Step 3: Create the view vw_pos_category_training_data_raw so that it can be used as input to train the time-series anomaly detection model.
create or replace view VW_POS_CATEGORY_TRAINING_DATA(
TRANSACTION_ID,
AMOUNT,
CATEGORY,
TXN_TIMESTAMP_NTZ
) as
SELECT
MAX(TRANSACTION_ID) AS TRANSACTION_ID,
AVG(AMOUNT) AS AMOUNT,
CATEGORY AS CATEGORY,
DATE_TRUNC('HOUR', TXN_TIMESTAMP_NTZ) as TXN_TIMESTAMP_NTZ
FROM DYN_POS_TRAINING_DATA
GROUP BY ALL
;
Step 4: Time-series anomaly detection model
In this implementation, Snowflake Cortex’s in-built anomaly detection function is used. Here is the brief description of the algorithm from Snowflake documentation:
“The anomaly detection algorithm is powered by a gradient boosting machine (GBM). Like an ARIMA model, it uses a differencing transformation to model data with a non-stationary trend and uses auto-regressive lags of the historical target data as model variables.
Additionally, the algorithm uses rolling averages of historical target data to help predict trends, and automatically produces cyclic calendar variables (such as day of week and week of year) from timestamp data”.
Currently, Snowflake Cortex’s Anomaly detection model expects time-series data to have no gaps in intervals, i.e. the timestamps in the data must represent fixed time intervals. To fix this problem, data is aggregated to the nearest hour using the date_trunc function on the timestamp column (for example: DATE_TRUNC(‘HOUR’, TXN_TIMESTAMP_NTZ)). Please look at the definition of the view vw_pos_training_data_raw above.
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION POS_MODEL_BY_CATEGORY(
INPUT_DATA => SYSTEM$REFERENCE('VIEW', 'VW_POS_CATEGORY_TRAINING_DATA'),
SERIES_COLNAME => 'CATEGORY',
TIMESTAMP_COLNAME => 'TXN_TIMESTAMP_NTZ',
TARGET_COLNAME => 'AMOUNT',
LABEL_COLNAME =>''
);
Detect Anomalies – Actual Data
Step 5: Create the table POS_LIVE_DATA_RAW to store the actual transactions.
CREATE OR REPLACE TABLE pos_live_data_raw (
Transaction_ID bigint DEFAULT NULL,
Amount double DEFAULT NULL,
Category text,
txn_timestamp timestamp_tz(9) DEFAULT NULL,
operation_name varchar(80),
src_event_timestamp timestamp_tz(9)
);
Step 6: Create a stream on pos_live_data_raw to capture the incremental changes
Dynamic tables currently have a minimum latency of 1 minute. To workaround this and minimize latencies, create a stream on pos_live_data_raw table.
create or replace stream st_pos_live_data_raw on table pos_live_data_raw;
Step 7: Create the view vw_pos_category_live_data_new to be used as input to anomaly detection function
View gets the incremental changes on pos_live_data_raw from the stream, de-dupes the data , removes deleted records and aggregates the transactions by the hour of transaction time.
create or replace view VW_POS_CATEGORY_LIVE_DATA_NEW(
TRANSACTION_ID,
AMOUNT,
CATEGORY,
TXN_TIMESTAMP_NTZ
) as
with raw_data as (
SELECT
TRANSACTION_ID,
AMOUNT,
CATEGORY,
TO_TIMESTAMP_NTZ(TXN_TIMESTAMP) as TXN_TIMESTAMP_NTZ,
METADATA$ACTION OPERATION_NAME,
ROW_NUMBER() OVER (
partition by TRANSACTION_ID order by SRC_EVENT_TIMESTAMP desc) as score
FROM ST_POS_LIVE_DATA_RAW
WHERE CATEGORY IS NOT NULL
),
deduped_raw_data as (
SELECT * EXCLUDE (score,operation_name )
FROM raw_data
WHERE score = 1 and operation_name != 'DELETE'
)
SELECT
max(TRANSACTION_ID) as transaction_id,
avg(AMOUNT) as amount,
CATEGORY as category ,
date_trunc('hour', TXN_TIMESTAMP_NTZ) as txn_timestamp_ntz
FROM deduped_raw_data
GROUP BY ALL
;
Step 8: Create the dynamic table dyn_pos_live_data to keep only the latest version of live transactions that have not been deleted.
-- dyn_pos_live_data
CREATE OR REPLACE DYNAMIC TABLE dyn_pos_live_data
LAG = '1 minute'
WAREHOUSE = 'DEMO_WH'
AS
SELECT * EXCLUDE (score,operation_name ) from (
SELECT
TRANSACTION_ID,
AMOUNT,
CATEGORY,
TO_TIMESTAMP_NTZ(TXN_TIMESTAMP) as TXN_TIMESTAMP_NTZ,
OPERATION_NAME,
ROW_NUMBER() OVER (
partition by TRANSACTION_ID order by SRC_EVENT_TIMESTAMP desc) as score
FROM POS_LIVE_DATA_RAW
WHERE CATEGORY IS NOT NULL
)
WHERE score = 1 and operation_name != 'DELETE';
Step 9: Call DETECT_ANOMALIES to identify records that are anomalies.
In the following code block, incremental changes are read from vw_pos_category_live_data_new and the detect_anomalies function is called, results of the detect_anomalies function are stored in pos_anomaly_results_table and alert messages are generated and stored in pos_anomaly_alert_messages.
With Snowflake notebooks, the anomaly detection and generation of alert messages below can be scheduled to run every two minutes.
truncate table pos_anomaly_results_table;
create or replace transient table stg_pos_category_live_data
as
select *
from vw_pos_category_live_data_new;
-- alter table pos_anomaly_alert_messages set change_tracking=true;
-- vw_dyn_pos_category_live_data is the old view
CALL POS_MODEL_BY_CATEGORY!DETECT_ANOMALIES(
INPUT_DATA => SYSTEM$REFERENCE('TABLE', 'STG_POS_CATEGORY_LIVE_DATA'),
SERIES_COLNAME => 'CATEGORY',
TIMESTAMP_COLNAME =>'TXN_TIMESTAMP_NTZ',
TARGET_COLNAME => 'AMOUNT'
);
set detect_anomalies_query_id = last_query_id();
insert into pos_anomaly_results_table
with get_req_seq as (
select s_pos_anomaly_results_req_id.nextval as request_id
)
select
t.*,
grs.request_id,
current_timestamp(9)::timestamp_ltz as dw_created_ts
from table(result_scan($detect_anomalies_query_id)) t
, get_req_seq as grs
;
set curr_ts = (select current_timestamp);
insert into pos_anomaly_alert_messages
with anomaly_details as (
select
series, ts, y, forecast, lower_bound, upper_bound
from pos_anomaly_results_table
where is_anomaly = True
--and series = 'Groceries'
),
ld as (
SELECT
*,
date_trunc('hour', TXN_TIMESTAMP_NTZ) as ts
FROM DYN_POS_LIVE_DATA
)
select
ld.category as name,
max(ld.transaction_id) as keyval,
max(ld.ts) as txn_timestamp,
'warning' as severity,
'raise' as flag,
listagg(
'Transaction ID: ' || to_char(ld.transaction_id) || ' with amount: ' || to_char(round(amount,2)) || ' in ' || ld.category || ' category seems suspicious', ' n') as message
from ld
inner join anomaly_details ad
on ld.category = ad.series
and ld.ts = ad.ts
where ld.amount 1.5*ad.upper_bound
group by all
;
Step 10: Create Slack Alerts Application in Striim
Create a CDC Application in Striim to continuously monitor anomaly alert results and messages and send Slack alerts for unusual or anomalous transactions.
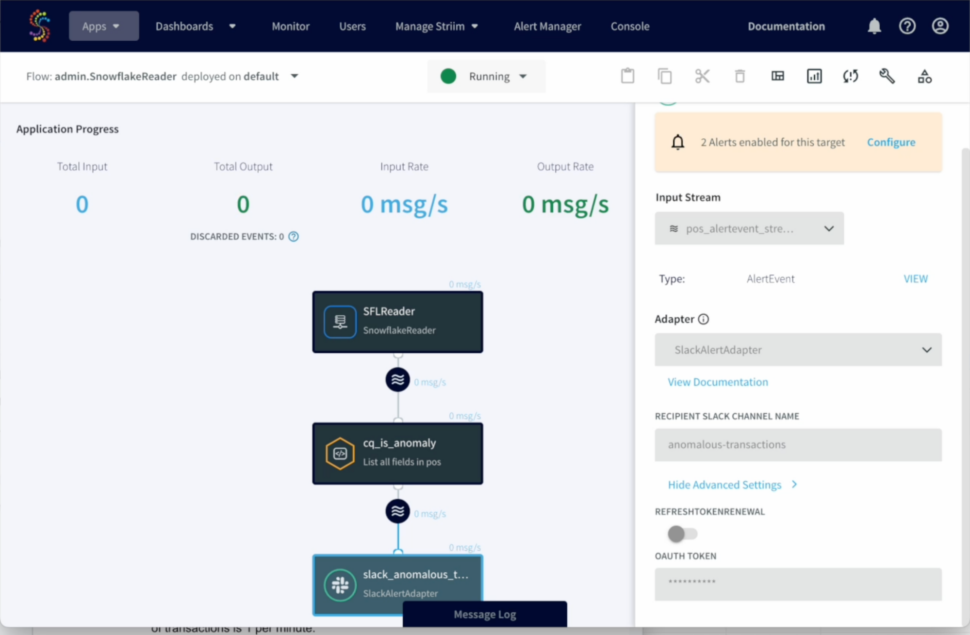
Here is a sample output of Slack alert messages of anomalous transactions: