We are pleased to announce the general availability of Striim 3.9.8 with a rich set of features that span multiple areas, including advanced data security, enhanced development productivity, data accountability, performance and scalability, and extensibility with new data targets.

The new release brings many new features that are summarized here:
 Let’s review the key themes and features of the new release starting with the security topic.
Let’s review the key themes and features of the new release starting with the security topic.
Advanced Platform and Adapter Security:
With a sharp focus on business-critical systems and use cases, the Striim team has been boosting the platform’s security features for the last several years. However, in version 3.9.8, we introduced a broad range of advanced security features to both the platform and its adapters to provide users with robust security for the end-to-end solution, and higher control for managing data security.
The new platform security features include the following components:
- Striim KeyStore, which is a secured, centralized repository based on Java Keystore, for storing passwords and encryption keys, streamlines security management across the platform.
- Ultra-secure algorithms for user password encryption across all parts of the platform reducing platform’s vulnerabilities to external or internal breaches.
- Stronger encryption support for inter-node cluster communication with internally generated, long string password and unified security management for all nodes and agents.
- Multi-layered application security via advanced support for exporting and importing pipeline applications within the platform. In Striim, all password properties of an application are encrypted using their own keys. When exporting applications containing passwords or other encrypted property values, you can now add a second level of encryption with a passphrase that will be required at the time of import, to strengthen the application security.
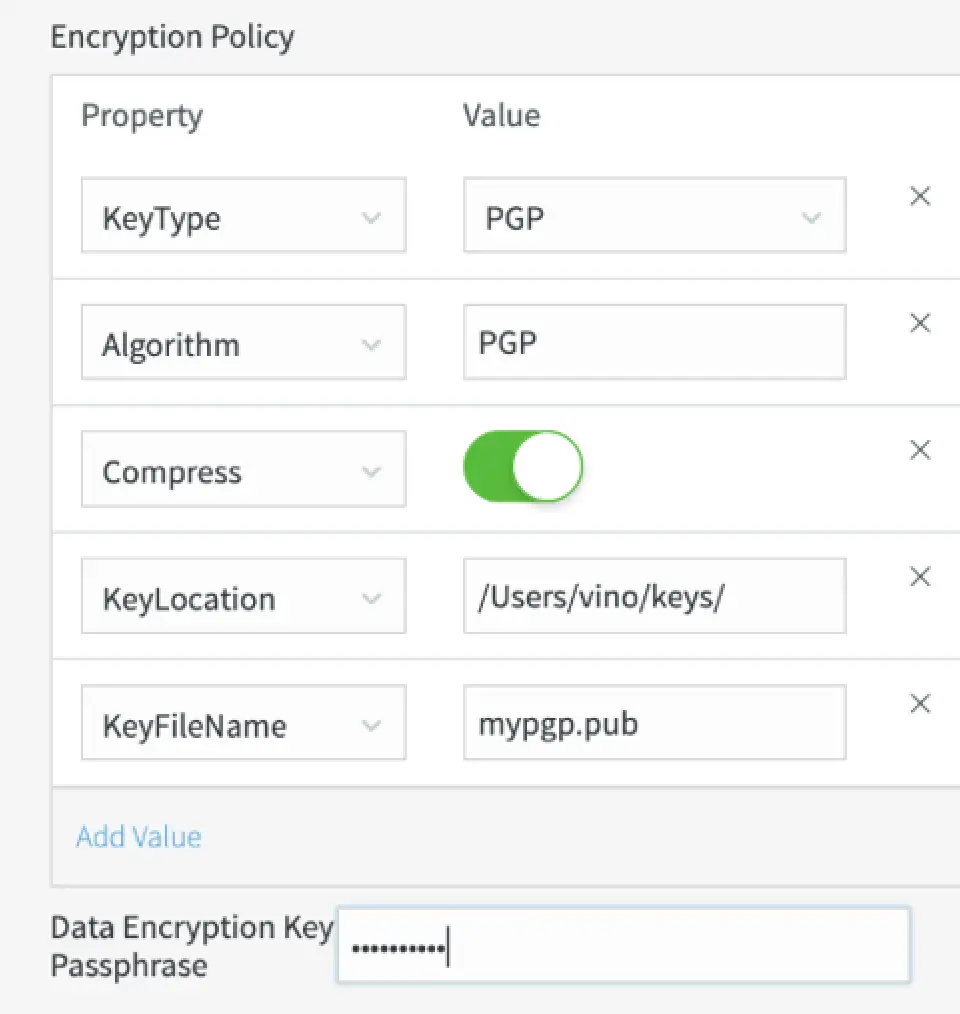
- Encryption support using customer provided key for securing permanent files, via the File Writer, and for the intermediate temporary files via the Google Cloud Storage Writer. Supported encryption algorithm types include RSA, AES and PGP. You can generate keys for encrypting by multiple tools available online or using in house Java program and easily configure the encryption settings of the adapters via the Encryption policy property on the UI.
Overall, these new security features enable:
- Enhanced platform and adapter security for hybrid cloud deployments and mission-critical environments
- Strengthened end-to-end data protection from ingestion to file delivery
- Enhanced compliance with strict security policies and regulations
- Secured application sharing between platform users
Improved Data Accountability:
Striim version 3.9.8 includes an application-specific exception store for storing events discarded by the application, including discarded records. The feature allows viewing discarded records and their details in real time. You can configure this feature with a simple on/off option when building an application. With this feature, Striim improves its accountability for all data passing through the platform and allows users to build applications for replaying and processing discarded records.
Enhanced Application Development Support and Ease of Use
The new release also includes features that accelerate and ease developing integration applications, especially in high-volume data environments.
- A New Enrichment Transformer: Expanding the existing library of out-of-the-box transformers, the new enrichment transformer function allows you to enrich your streaming data in-flight without any manual coding step. You only need Striim’s drag and drop UI to create a real-time data pipeline that performs in-memory data lookups. With this transformer, you can, for example, add City Name and County Name fields to an event containing Zip Code.
![]()
- External Lookups: Striim provides an in-memory data cache to enrich data in-flight at very high speeds. With the new release, Striim gives you the option to enrich data with lookups from external data stores. The platform can now execute a database query to fetch data from an external database and return the data as a batch. The external lookup option helps users avoid preloading data in the Striim cache. This is especially beneficial for lookups from or joining with large data sets. External lookups also eliminate the need for a cache refresh since the data is fetched from the external database. The external lookups are supported for all major databases, including Oracle, SQL Server, MySQL, PostgreSQL, HPE NonStop.
- The Option to Use Sample Data for Continuous Queries: With this ability, Striim reduces the data required for computation or displaying results via the dashboards. You can select to use only a portion of your streaming data for the application, if your use case can benefit from this approach. As a result, it increases the speed for computation and displaying the results, especially when working with very large data volumes.
- Dynamic Output Names for Writers: The Striim platform makes it now easy to organize and consume the files and objects on the target system by giving flexible options for naming them. Striim file and object output names can include data, metadata, and user data field values from the source event. This dynamic output naming feature is available for the following targets: Azure Data Lake Store Gen 1 and Gen 2, Azure Blob Storage, Azure File Storage, Google Cloud Storage, Apache HDFS, Amazon S3.
- Event-Augmented Kafka Message Header: Starting with Apache Kafka v11, Striim 3.9.8 introduced a new property called MessageHeader that enriches the Kafka message header with a mix of the event’s dynamic and static values before delivering with sub-second latency. With the help of the additional contextual information, downstream consumer application can rapidly determine how to use the messages arriving via Striim.
- Simplified User Experience: The new UI for configuring complex adapter properties, such as rollover policy, flush policy, encryption policy, speeds new application development.
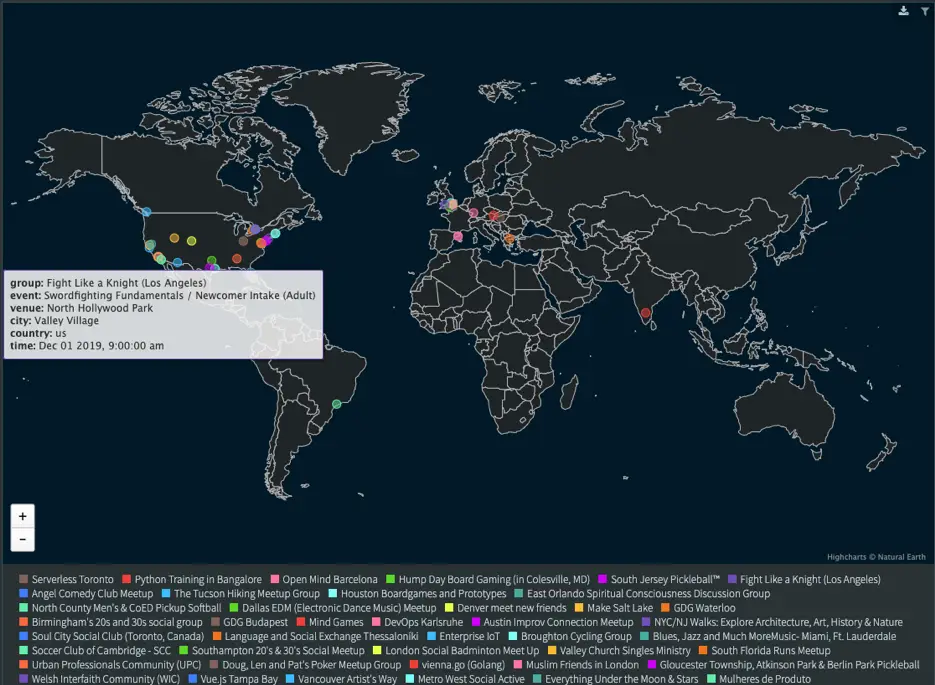
- New sample application for real-time dashboards: Striim version 3.9.8 added a new sample dashboarding application that uses real-time data from meetup-website and displays in details of the meet-up events happening around the globe using demonstrates the Vector Map visualization.
Other platform improvements for ease of use and manageability include:
- The Open Processor component, which allows bringing external code into the Striim platform, can be loaded and unloaded dynamically without having to restart Striim.
- The Striim REST API allows safely deleting or post-processing the files processed by the Striim File Reader.
- The Striim REST API for application monitoring reports consolidated statistics of various application components within a specified time range.
Increased Performance and Scalability:
For further improving performance and scalability, we have multiple features, including dynamic partitioning and performance fine-tuning for writers:
- Dynamic Partitioning with Higher-Level of Control: Partitions allow parallel processing of the events in the stream by splitting them across multiple servers in the deployment. Striim’s partitioning distributes events dynamically at run-time across server nodes in a cluster and enables high performance and easy scalability. In prior releases, Striim used one or more fields of the events in the stream as key for partitioning. In the new release, users have additional, flexible options for distributing and processing large data volumes in streams or windows. Striim 3.9.8 allows partitioning key to be one or more expressions composed with the fields of the events in the stream. Striim’s flexible partitioning enables load-balancing applications that are deployed on multi-node clusters and process large data volumes. Windows-based partitioning enables grouping the events in windows that can, for example, be consumed by specific downstream writers. As a result, you can perform load-balancing across multiple writers to improve writing performance.
- Writer Fine-Tuning Options: Striim 3.9.8 now offers the ability to configure the number of parallel threads for writing into the target system and simplifies writer configuration for achieving even higher throughput from the platform. The fine-tuning option is available for the following list of writers at this time: Azure Synapse Analytics and Azure SQL Data Warehouse, Google BigQuery, Google Cloud Spanner, Azure Cosmos DB, Apache HBase, Apache Kudu, MapR Database, Amazon Redshift, and Snowflake.
Increased Extensibility with New Data Targets
- The Striim platform now supports SAP Hana as a target with direct integration. SAP Hana customers can now stream real-time data from a diverse set of sources into the platform with in-flight, in-memory data processing. With the availability of real-time data pipelines to SAP Hana, deployed on-premises or in the cloud, customers can rapidly develop time-sensitive analytics applications that transform their business operations.
- Expanding the HTTP Reader capabilities to send custom responses back to the requestor. The HTTP Reader can now defer responding until events reach a corresponding HTTP Writer. This feature enables users to build REST services using Striim.
Other extensibility improvements are:
- Improved support for handling special characters for table names in Oracle and SQL Server databases
- Hazelcast Writer supports multi-column primary keys to enable more complex Hot Cache use cases
- Performance improvement options for the SQL Server CDC Reader
These are only a portion of the new features of Striim 3.9.8. There is more to discover. If you would like to learn more about the new release, please reach out to schedule a demo with a Striim expert.