
With Striim now on Snowflake Partner Connect, customers can start loading their data in minutes with one-click access to a proven and intuitive cloud-based data integration service – Harsha Kapre, Director of Product Management at Snowflake
Data Integration for Snowflake: Announcing Striim on Partner Connect
At Striim, we value building real-time data integration solutions for cloud data warehouses. Snowflake has become a leading Cloud Data Platform by making it easy to address some of the key challenges in modern data management such as
- Building a 360 view of the customer
- Combining historical and real-time data
- Handling large scale IoT device data
- Aggregating data for machine learning purposes
It only took you minutes to get up and running with Snowflake. So, it should be just as easy to move your data into Snowflake with an intuitive cloud-based data integration service.
To give you an equally seamless data integration experience, we’re happy to announce that Striim is now available as a cloud service directly on Snowflake Partner Connect.
“Striim simplifies and accelerates the movement of real-time enterprise data to Snowflake with an easy and scalable pay-as-you-go model,” Director of Product Management at Snowflake, Harsha Kapre said. “With Striim now on Snowflake Partner Connect, customers can start loading their data in minutes with one-click access to a proven and intuitive cloud-based data integration service.”
John Kutay, Director of Product Growth at Striim, highlights the simplicity of Striim’s cloud service on Partner Connect: “We focused on delivering an experience tailored towards Snowflake customers; making it easy to bridge the gap between operational databases and Snowflake via self-service schema migration, initial data sync, and change data capture.”
A Quick Tutorial
We’ll dive into a tutorial on how you can use Striim on Partner Connect to create schemas and move data into Snowflake in minutes. We’ll cover the following in the tutorial:
- Launch Striim’s cloud service directly from the Snowflake UI
- Migrate schemas from your source database. We will be using MySQL for this example, but the steps are almost exactly the same other databases (Oracle, PostgreSQL, SQLServer, and more).
- Perform initial load: move millions of rows in minutes all during your free trial of Striim
- Kick off a real-time replication pipeline using change data capture.
- Monitoring your data integration pipelines with real-time dashboards and rule-based alerts
But first a little background!
What is Striim?
At a high level, Striim is a next generation Cloud Data Integration product that offers change data capture (CDC) enabling real-time data integration from popular databases such as Oracle, SQLServer, PostgreSQL and many others.
In addition to CDC connectors, Striim has hundreds of automated adapters for file-based data (logs, xml, csv), IoT data (OPCUA, MQTT), and applications such as Salesforce and SAP. Our SQL-based stream processing engine makes it easy to enrich and normalize data before it’s written to Snowflake.
Our focus on usability and scalability has driven adoption from customers like Attentia, Belgium-based HR and well-being company, and Inspyrus, a Silicon Valley-based invoice processing company, that chose Striim for data integration to Snowflake.
What is Change Data Capture?
While many products focus on batch data integration, Striim specializes in helping you build continuous, real-time database replication pipelines using change data capture (CDC).This keeps the target system in sync with the source database to address real-time requirements.
Before we dive into an example pipeline, we’ll briefly go over the concept of Change Data Capture (CDC). CDC is the process of tailing the database’s change logs, turning database events such as inserts, updates, deletes, and relevant DDL statements into a stream of immutable events, and applying those changes to a target database or data warehouse.
Change data capture is also a useful software abstraction for other software applications such as version control and event sourcing.

Striim brings decades of experience delivering change data capture products that work in mission-critical environments. The founding team at Striim was the executive (and technical) team at GoldenGate Software (now Oracle GoldenGate). Now Striim is offering CDC as an easy-to-use, cloud-based product for data integration.
Migrating data to Snowflake in minutes with Striim’s cloud service
Let’s dive into how you can start moving data into Snowflake in minutes using our platform. In a few simple steps, this example shows how you can move transactional data from MySQL to Snowflake. Let’s get started:
1. Launch Striim in Snowflake Partner Connect
In your Snowflake UI, navigate to “Partner Connect” by clicking the link in the top right corner of the navigation bar. There you can find and launch Striim.

2. Sign Up For a Striim Free Trial
Striim’s free trial gives you seven calendar days of the full product offering to get started. But we’ll get you up and running with schema migration and database replication in a matter of minutes.


3. Create your first Striim Service.
A Striim Service is an encapsulated SaaS application that dedicates the software and fully managed compute resources you need to accomplish a specific workload; in this case we’re creating a service to help you move data to Snowflake! We’re also available to assist with you via chat in the bottom right corner of your screen.

4. Start moving data with Striim’s step-by-step wizards.
In this case, the MySQL to Snowflake is selected. As you can see, Striim supports data integration for a wide-range of database sources – all available in the free trial.

5. Select your schemas and tables from your source database


6. Start migrating your schemas and data
After select your tables, simply click ‘Next’ and your data migration pipeline will begin!

7. Monitor your data pipelines in the Flow Designer
As your data starts moving, you’ll have a full view into the amount of data being ingested and written into Snowflake including the distribution of inserts, updates, deletes, primary key changes and more.



For a deeper drill down, our application monitor gives even more insights into low-level compute metrics that impact your integration latency.

Real-Time Database Replication to Snowflake with Change Data Capture
Striim makes it easy to sync your schema migration and CDC applications.
While Striim makes it just as easy to build these pipelines, there are some prerequisites to configuring CDC from most databases that are outside the scope of Striim.
To use MySQLReader, the adapter that performs CDC, an administrator with the necessary privileges must create a user for use by the adapter and assign it the necessary privileges:
CREATE USER 'striim' IDENTIFIED BY '******';
GRANT REPLICATION SLAVE ON *.* TO 'striim';
GRANT REPLICATION CLIENT ON *.* TO 'striim';
GRANT SELECT ON *.* TO 'striim';</code>
The MySQL 8 caching_sha2_password authentication plugin is not supported in this release. The mysql_native_password plugin is required. The minimum supported version is 5.5 and higher.
The REPLICATION privileges must be granted on *.*. This is a limitation of MySQL.
You may use any other valid name in place of striim. Note that by default MySQL does not allow remote logins by root.
Replace ****** with a secure password.
You may narrow the SELECT statement to allow access only to those tables needed by your application. In that case, if other tables are specified in the MySQLReader properties, Striim will return an error that they do not exist.
MYSQL BINARY LOG SETUP
MySQLReader reads from the MySQL binary log. If your MySQL server is using replication, the binary log is enabled, otherwise it may be disabled.
For MySQL, the property name for enabling the binary log, its default setting, and how and where you change that setting vary depending on the operating system and your MySQL configuration, so see the documentation for the version of MySQL you are running for instructions.
If the binary log is not enabled, Striim’s attempts to read it will fail with errors such as the following:
2016-04-25 19:05:40,377 @ -WARN hz._hzInstance_1_striim351_0423.cached.thread-2
com.webaction.runtime.Server.startSources (Server.java:2477) Failure in Starting
Sources.
java.lang.Exception: Problem with the configuration of MySQL
Row logging must be specified.
Binary logging is not enabled.
The server ID must be specified.
Add --binlog-format=ROW to the mysqld command line or add binlog-format=ROW to your
my.cnf file
Add --bin-log to the mysqld command line or add bin-log to your my.cnf file
Add --server-id=n where n is a positive number to the mysqld command line or add
server-id=n to your my.cnf file
at com.webaction.proc.MySQLReader_1_0.checkMySQLConfig(MySQLReader_1_0.java:605) ...</code>
Once those prerequisites are completed, you can run the MySQL CDC wizard and start replicating data from your database right where your schema migration and initial load left off.
Maximum Uptime with Guaranteed Delivery, Monitoring and Alerts
Striim gives your team full visibility into your data pipelines with the following monitoring capabilities:
- Rule-based, real-time alerts where you can define your custom alert criteria
- Real-time monitoring tailored to your metrics
- Exactly-once processing (E1P) guarantees

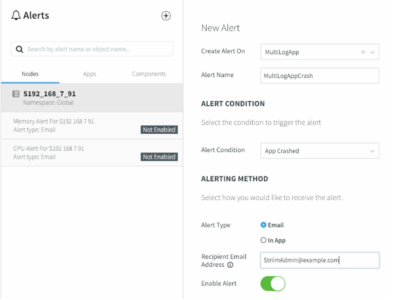
Striim uses a built-in stream processing engine that allows high volume data ingest and processing for Snowflake ETL purposes.
Conclusion
To summarize, Striim on Snowflake Partner Connect provides an easy-to-use cloud data integration service for Snowflake. The service comes with a 7-day free trial, giving you ample time to begin your journey to bridge your operational data with your Snowflake Data Warehouse.
Visit our Striim for Snowflake webpage for a deeper dive into solutions such as
- How to migrate data from Oracle to Snowflake using Change Data Capture
- How to migrate data from SQL Server to Snowflake using Change Data Capture
- Teradata to Snowflake migrations
- AWS Redshift to Snowflake migrations
- Moving IoT data to Snowflake (OPCUA, MQTT)
- Moving data from AWS S3 to Snowflake
As always, feel free to reach out to our integration experts to schedule a demo.










 Building continuous, streaming data pipelines from on-premises databases to production cloud databases for critical workloads requires a secure, scalable, and reliable integration solution. Especially if you have enterprise database sources that cannot tolerate performance degradation, traditional batch ETL will not suffice. Striim’s low-impact
Building continuous, streaming data pipelines from on-premises databases to production cloud databases for critical workloads requires a secure, scalable, and reliable integration solution. Especially if you have enterprise database sources that cannot tolerate performance degradation, traditional batch ETL will not suffice. Striim’s low-impact 


















